
Nos últimos anos, houve um aumento de novas camadas gráficas diferenciáveis que podem ser inseridas em arquiteturas de redes neurais. De transformadores espaciais a renderizadores gráficos diferenciáveis, essas novas camadas aproveitam o conhecimento adquirido ao longo de anos de pesquisa em visão computacional e gráficos para construir arquiteturas de rede novas e mais eficientes. A modelagem explícita de prioris e restrições geométricas em redes neurais abre as portas para arquiteturas que podem ser treinadas de forma robusta, eficiente e, mais importante, de forma autossupervisionada.
Em alto nível, um pipeline de computação gráfica requer uma representação de objetos 3D e seu posicionamento absoluto na cena, uma descrição do material de que são feitos, luzes e uma câmera. Essa descrição de cena é então interpretada por um renderizador para gerar uma renderização sintética.
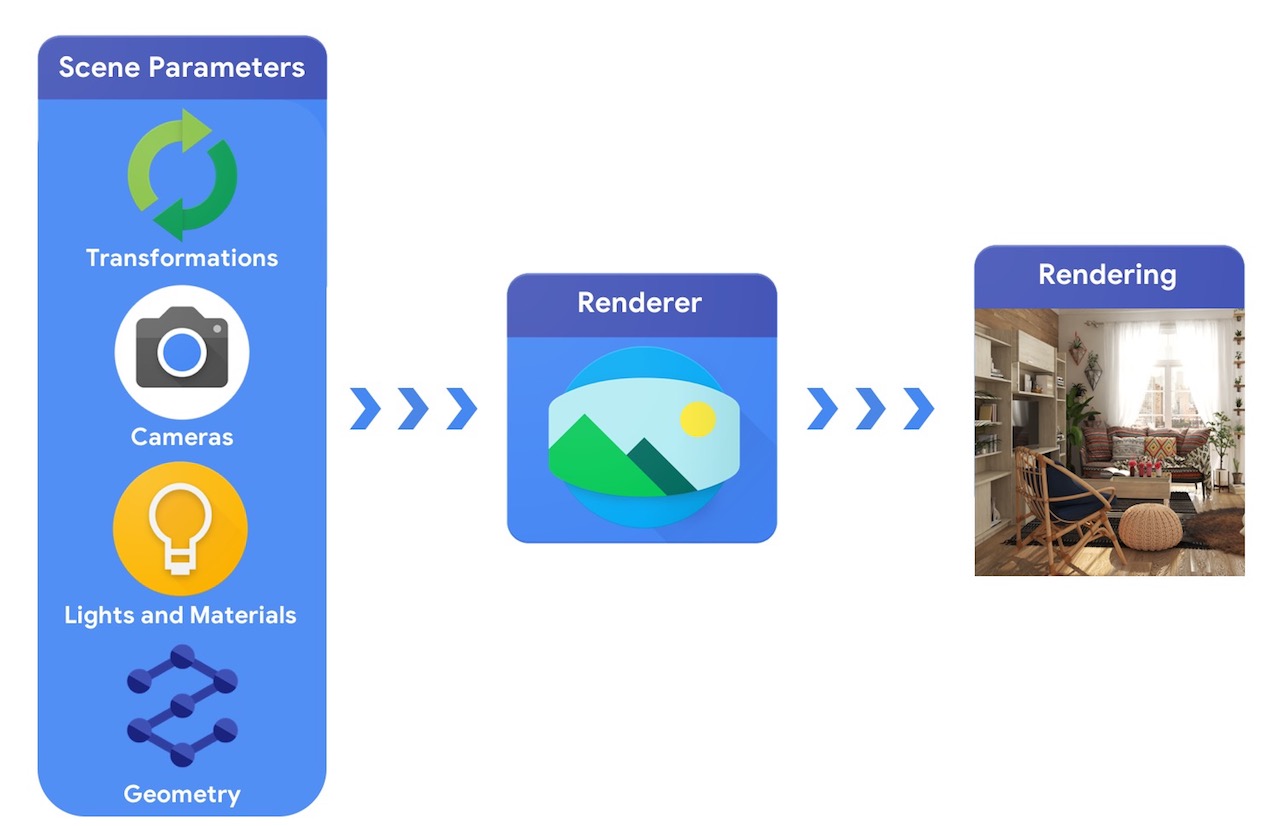
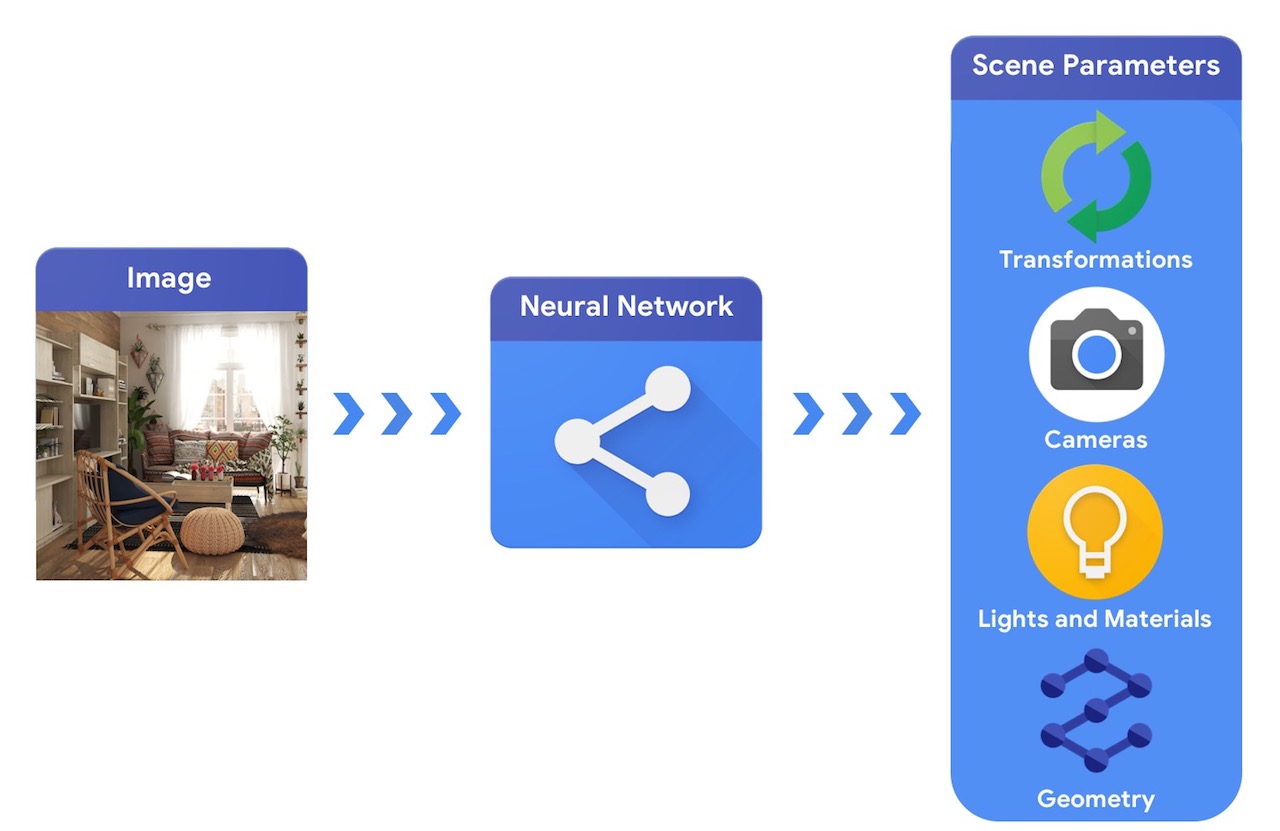
Em comparação, um sistema de visão computacional partiria de uma imagem e tentaria inferir os parâmetros da cena. Isso permite a previsão de quais objetos estão na cena, de quais materiais são feitos e a posição e orientação tridimensional.
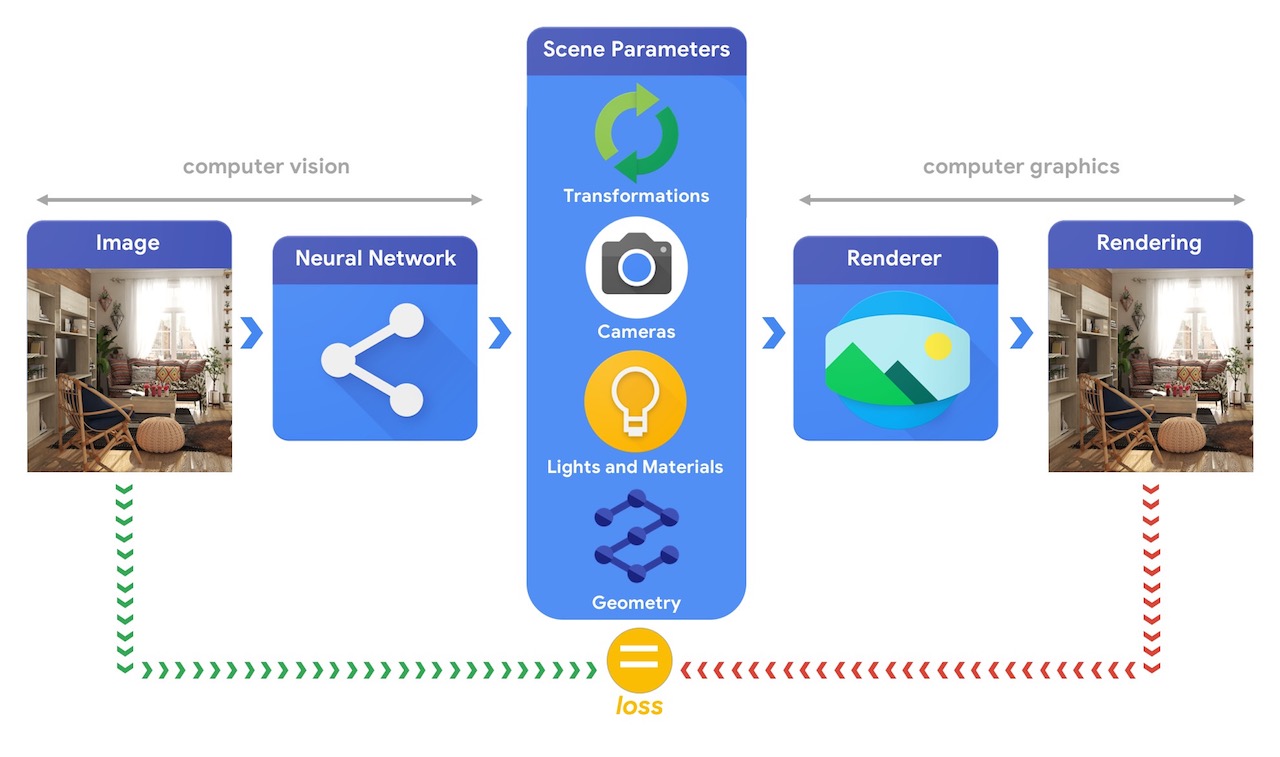
O treinamento de sistemas de aprendizado de máquina capazes de resolver essas tarefas complexas de visão 3D geralmente requer grandes quantidades de dados. Como rotular dados é um processo caro e complexo, é importante ter mecanismos para projetar modelos de aprendizado de máquina que possam compreender o mundo tridimensional enquanto são treinados sem muita supervisão. A combinação de técnicas de visão computacional e computação gráfica oferece uma oportunidade única de aproveitar as vastas quantidades de dados não rotulados prontamente disponíveis. Conforme ilustrado na imagem abaixo, isso pode, por exemplo, ser alcançado usando análise por síntese onde o sistema de visão extrai os parâmetros da cena e o sistema gráfico renderiza uma imagem baseada neles. Se a renderização corresponder à imagem original, o sistema de visão extraiu com precisão os parâmetros da cena. Nessa configuração, a visão computacional e a computação gráfica andam de mãos dadas, formando um único sistema de aprendizado de máquina semelhante a um autoencoder, que pode ser treinado de forma autossupervisionada.
O Tensorflow Graphics está sendo desenvolvido para ajudar a enfrentar esses tipos de desafios e, para isso, fornece um conjunto de camadas de geometria e gráficos diferenciáveis (por exemplo, câmeras, modelos de refletância, transformações espaciais, convoluções de malha) e funcionalidades de visualizador 3D (por exemplo, 3D TensorBoard) que pode ser usado para treinar e depurar seus modelos de aprendizado de máquina de sua escolha.