
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
בידול אוטומטי והדרגתיים
בידול אוטומטי שימושי ליישום אלגוריתמים של למידת מכונה כגון התפשטות לאחור לאימון רשתות עצביות.
במדריך זה, תחקור דרכים לחישוב מעברי צבע עם TensorFlow, במיוחד בביצוע נלהב .
להכין
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
מעברי מחשוב
כדי להבדיל באופן אוטומטי, TensorFlow צריך לזכור אילו פעולות מתרחשות באיזה סדר במהלך המעבר קדימה . לאחר מכן, במהלך המעבר לאחור , TensorFlow חוצה את רשימת הפעולות הזו בסדר הפוך כדי לחשב שיפועים.
קלטות שיפוע
TensorFlow מספקת את ה-API tf.GradientTape עבור בידול אוטומטי; כלומר, חישוב שיפוע של חישוב ביחס לתשומות מסוימות, בדרך כלל tf.Variable s. TensorFlow "מתעד" פעולות רלוונטיות המבוצעות בהקשר של tf.GradientTape על גבי "טייפ". לאחר מכן TensorFlow משתמש בקלטת זו כדי לחשב את ההדרגות של חישוב "מוקלט" באמצעות הבחנה במצב הפוך .
הנה דוגמה פשוטה:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
לאחר שרשמת כמה פעולות, השתמש ב- GradientTape.gradient(target, sources) כדי לחשב את השיפוע של יעד כלשהו (לעיתים קרובות הפסד) ביחס למקור כלשהו (לעיתים קרובות משתני המודל):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
הדוגמה שלמעלה משתמשת בסקלרים, אבל tf.GradientTape עובד באותה קלות על כל טנסור:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
כדי לקבל את שיפוע loss ביחס לשני המשתנים, ניתן להעביר את שניהם כמקורות לשיטת gradient . הקלטת גמישה לגבי אופן העברת המקורות והיא תקבל כל שילוב מקונן של רשימות או מילונים ותחזיר את הגרדיאנט בנוי באותו אופן (ראה tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
לשיפוע ביחס לכל מקור יש את צורת המקור:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
הנה שוב חישוב הגרדיאנט, הפעם מעביר מילון משתנים:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
שיפועים ביחס לדגם
מקובל לאסוף tf.Variables לתוך tf.Module או לאחת מתת-המחלקות שלו ( layers.Layer , keras.Model ) לצורך בדיקה וייצוא .
ברוב המקרים, תרצה לחשב גרדיאנטים ביחס למשתנים הניתנים לאימון של המודל. מכיוון שכל תת-המחלקות של tf.Module צוברות את המשתנים שלהן במאפיין Module.trainable_variables , אתה יכול לחשב את ההדרגות האלה בכמה שורות קוד:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
שליטה במה שהקלטת צופה
התנהגות ברירת המחדל היא להקליט את כל הפעולות לאחר גישה ל- tf.Variable לאימון. הסיבות לכך הן:
- הקלטת צריכה לדעת אילו פעולות להקליט במעבר קדימה כדי לחשב את השיפועים במעבר אחורה.
- הקלטת מכילה הפניות ליציאות ביניים, כך שלא תרצו להקליט פעולות מיותרות.
- מקרה השימוש הנפוץ ביותר כולל חישוב גרדיאנט של הפסד ביחס לכל המשתנים הניתנים לאימון של המודל.
לדוגמה, הפריטים הבאים לא מצליחים לחשב שיפוע מכיוון שה- tf.Tensor אינו "נצפה" כברירת מחדל, וה- tf.Variable אינו ניתן לאימון:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
אתה יכול לרשום את המשתנים הנצפים על ידי הקלטת באמצעות שיטת GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape מספק ווים שנותנים למשתמש שליטה על מה הוא צופה או לא.
כדי להקליט מעברי צבע ביחס ל- tf.Tensor , עליך לקרוא ל- GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
לעומת זאת, כדי להשבית את התנהגות ברירת המחדל של צפייה בכל tf.Variables , הגדר watch_accessed_variables=False בעת יצירת קלטת השיפוע. חישוב זה משתמש בשני משתנים, אך רק מחבר את הגרדיאנט של אחד המשתנים:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
מכיוון ש- GradientTape.watch לא נקרא ב- x0 , לא מחושב שיפוע ביחס אליו:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
תוצאות ביניים
אתה יכול גם לבקש שיפועים של הפלט ביחס לערכי ביניים המחושבים בתוך ההקשר tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
כברירת מחדל, המשאבים המוחזקים על ידי GradientTape משוחררים ברגע שנקראת שיטת GradientTape.gradient . כדי לחשב שיפועים מרובים על אותו חישוב, צור סרט שיפוע עם persistent=True . זה מאפשר שיחות מרובות לשיטת gradient כאשר משאבים משתחררים כאשר אובייקט הקלטת נאסף אשפה. לדוגמה:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
הערות על ביצועים
ישנה תקורה זעירה הקשורה לביצוע פעולות בהקשר של סרט שיפוע. עבור הביצוע הנלהב ביותר, זו לא תהיה עלות בולטת, אך עדיין עליך להשתמש בהקשר של קלטת סביב האזורים שבהם הדבר נדרש.
קלטות שיפוע משתמשות בזיכרון כדי לאחסן תוצאות ביניים, כולל כניסות ויציאות, לשימוש במהלך המעבר לאחור.
למען היעילות, חלק מהמבצעים (כמו
ReLU) אינם צריכים לשמור על תוצאות הביניים שלהם והם נגזמים במהלך המעבר קדימה. עם זאת, אם אתה משתמש ב-persistent=Trueבקלטת שלך, שום דבר לא מושלך ושיא השימוש בזיכרון שלך יהיה גבוה יותר.
שיפועים של מטרות לא סקלריות
שיפוע הוא ביסודו פעולה על סקלר.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
לפיכך, אם אתה שואל את השיפוע של מטרות מרובות, התוצאה עבור כל מקור היא:
- השיפוע של סכום המטרות, או שווה ערך
- סכום ההדרגות של כל מטרה.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
באופן דומה, אם היעד/ים אינם סקלריים, שיפוע הסכום מחושב:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
זה עושה את זה פשוט לקחת את השיפוע של הסכום של אוסף הפסדים, או את השיפוע של הסכום של חישוב הפסד אלמנט.
אם אתה צריך שיפוע נפרד עבור כל פריט, עיין ב- Jacobians .
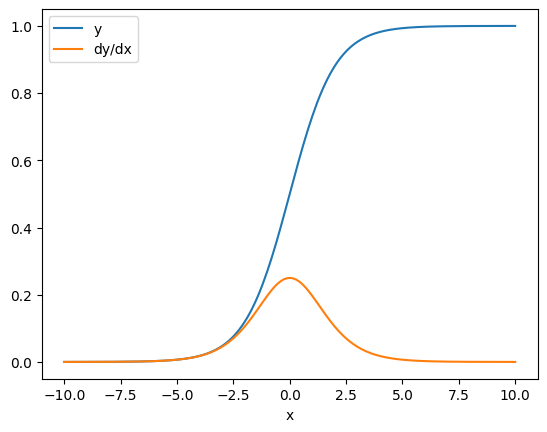
במקרים מסוימים אתה יכול לדלג על היעקוביאן. לחישוב של אלמנט, שיפוע הסכום נותן את הנגזרת של כל אלמנט ביחס לאלמנט הקלט שלו, שכן כל אלמנט הוא בלתי תלוי:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
בקרת זרימה
מכיוון שקלטת שיפוע מקליטת פעולות תוך כדי ביצוען, זרימת הבקרה של Python מטופלת באופן טבעי (לדוגמה, הצהרות if and while ).
כאן נעשה שימוש במשתנה אחר בכל ענף של if . השיפוע מתחבר רק למשתנה ששימש:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
רק זכור שהצהרות הבקרה עצמן אינן ניתנות להבדלה, כך שהן בלתי נראות למיטובים מבוססי גרדיאנט.
בהתאם לערך של x בדוגמה שלמעלה, הקלטת מתעדת result = v0 או result = v1**2 . השיפוע ביחס ל- x הוא תמיד None .
dx = tape.gradient(result, x)
print(dx)
None
קבלת שיפוע של None
כאשר יעד אינו מחובר למקור, תקבל שיפוע של None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
כאן z כמובן לא מחובר ל- x , אבל יש כמה דרכים פחות ברורות שבהן ניתן לנתק שיפוע.
1. החליף משתנה בטנזור
בסעיף "שליטה במה שהטייפ צופה" ראית שהקלטת תצפה אוטומטית ב- tf.Variable אבל לא ב- tf.Tensor .
אחת השגיאות הנפוצות היא החלפת tf.Variable בטעות ב- tf.Tensor , במקום להשתמש ב- Variable.assign כדי לעדכן את ה- tf.Variable . הנה דוגמה:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. עשה חישובים מחוץ ל-TensorFlow
הקלטת לא יכולה להקליט את נתיב השיפוע אם החישוב יוצא מ-TensorFlow. לדוגמה:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. לקח מעברי צבע דרך מספר שלם או מחרוזת
מספרים שלמים ומיתרים אינם ניתנים להבדלה. אם נתיב חישוב משתמש בסוגי נתונים אלה, לא יהיה שיפוע.
אף אחד לא מצפה שהמחרוזות יהיו ניתנות להבדלה, אבל קל ליצור בטעות קבוע int או משתנה אם לא מציינים את dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow אינו מטיל אוטומטית בין סוגים, כך שבפועל, לעתים קרובות תקבל שגיאת סוג במקום שיפוע חסר.
4. לקח שיפועים דרך אובייקט מצבי
מצב מפסיק שיפועים. כשאתה קורא מאובייקט מצבי, הקלטת יכולה לראות רק את המצב הנוכחי, לא את ההיסטוריה שהובילה אליו.
tf.Tensor אינו ניתן לשינוי. אתה לא יכול לשנות טנזור ברגע שהוא נוצר. יש לזה ערך , אבל אין לו מדינה . כל הפעולות שנדונו עד כה גם הן חסרות מצב: הפלט של tf.matmul תלוי רק בכניסות שלו.
ל- tf.Variable יש מצב פנימי - הערך שלו. כאשר אתה משתמש במשתנה, המצב נקרא. זה נורמלי לחשב שיפוע ביחס למשתנה, אבל המצב של המשתנה חוסם חישובי שיפוע ללכת רחוק יותר אחורה. לדוגמה:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
באופן דומה, tf.data.Dataset iterators ו- tf.queue s הם מצביים, ויעצרו את כל ההדרגות בטנסורים שעוברים דרכם.
לא נרשם שיפוע
חלק tf.Operation רשומות כבלתי ניתנות להבדלה ויחזירו None . לאחרים אין שיפוע רשום .
הדף tf.raw_ops מראה לאילו פעולות ברמה נמוכה יש הדרגות רשומות.
אם תנסה לקחת שיפוע דרך הפעלה צפה שאין לה שיפוע רשום, הקלטת תגרום לשגיאה במקום להחזיר None צורה בשקט. כך אתה יודע שמשהו השתבש.
לדוגמה, הפונקציה tf.image.adjust_contrast עוטפת את raw_ops.AdjustContrastv2 , שיכול להיות בעל שיפוע אך השיפוע אינו מיושם:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
אם אתה צריך להבדיל באמצעות אופציה זו, תצטרך ליישם את הגרדיאנט ולרשום אותו (באמצעות tf.RegisterGradient ) או להטמיע מחדש את הפונקציה באמצעות פעולות אחרות.
אפסים במקום אין
במקרים מסוימים יהיה נוח לקבל 0 במקום None עבור מעברים לא מחוברים. אתה יכול להחליט מה להחזיר כשיש לך מעברי צבע לא מחוברים באמצעות הארגומנט unconnected_gradients :
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)