
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
はじめに
画像分類モデルには数百個のパラメータがあります。モデルをゼロからトレーニングするには、ラベル付きの多数のトレーニングデータと膨大なトレーニング性能が必要となります。転移学習とは、関連するタスクでトレーニングされたモデルの一部を取り出して新しいモデルで再利用することで、学習の大部分を省略するテクニックを指します。
この Colab では、より大規模で一般的な ImageNet データセットでトレーニングされた、TensorFlow Hub のトレーニング済み TF2 SavedModel を使用して画像特徴量を抽出することで、5 種類の花を分類する Keras モデルの構築方法を実演します。オプションとして、特徴量抽出器を新たに追加される分類器とともにトレーニング(「ファインチューニング」)することができます。
代替ツールをお探しですか?
これは、TensorFlow のコーディングチュートリアルです。TensorFlow または TF Lite モデルを構築するだけのツールをお探しの方は、PIP パッケージ tensorflow-hub[make_image_classifier] によってインストールされる make_image_classifier コマンドラインツール、またはこちらの TF Lite Colab をご覧ください。
セットアップ
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
print("TF version:", tf.__version__)
print("Hub version:", hub.__version__)
print("GPU is", "available" if tf.config.list_physical_devices('GPU') else "NOT AVAILABLE")
2024-01-11 19:59:24.086086: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 19:59:24.086129: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 19:59:24.087797: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered TF version: 2.15.0 Hub version: 0.15.0 GPU is available
使用する TF2 SavedModel モジュールを選択する
手始めに、https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4 を使用します。同じ URL を、SavedModel を識別するコードに使用できます。またブラウザで使用すれば、そのドキュメントを表示することができます。(ここでは TF1 Hub 形式のモデルは機能しないことに注意してください。)
画像特徴量ベクトルを生成するその他の TF2 モデルは、こちらをご覧ください。
試すことのできるモデルはたくさんあります。下のセルから別のモデルを選択し、ノートブックの指示に従ってください。
model_name = "efficientnetv2-xl-21k" # @param ['efficientnetv2-s', 'efficientnetv2-m', 'efficientnetv2-l', 'efficientnetv2-s-21k', 'efficientnetv2-m-21k', 'efficientnetv2-l-21k', 'efficientnetv2-xl-21k', 'efficientnetv2-b0-21k', 'efficientnetv2-b1-21k', 'efficientnetv2-b2-21k', 'efficientnetv2-b3-21k', 'efficientnetv2-s-21k-ft1k', 'efficientnetv2-m-21k-ft1k', 'efficientnetv2-l-21k-ft1k', 'efficientnetv2-xl-21k-ft1k', 'efficientnetv2-b0-21k-ft1k', 'efficientnetv2-b1-21k-ft1k', 'efficientnetv2-b2-21k-ft1k', 'efficientnetv2-b3-21k-ft1k', 'efficientnetv2-b0', 'efficientnetv2-b1', 'efficientnetv2-b2', 'efficientnetv2-b3', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'bit_s-r50x1', 'inception_v3', 'inception_resnet_v2', 'resnet_v1_50', 'resnet_v1_101', 'resnet_v1_152', 'resnet_v2_50', 'resnet_v2_101', 'resnet_v2_152', 'nasnet_large', 'nasnet_mobile', 'pnasnet_large', 'mobilenet_v2_100_224', 'mobilenet_v2_130_224', 'mobilenet_v2_140_224', 'mobilenet_v3_small_100_224', 'mobilenet_v3_small_075_224', 'mobilenet_v3_large_100_224', 'mobilenet_v3_large_075_224']
model_handle_map = {
"efficientnetv2-s": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_s/feature_vector/2",
"efficientnetv2-m": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_m/feature_vector/2",
"efficientnetv2-l": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_l/feature_vector/2",
"efficientnetv2-s-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_s/feature_vector/2",
"efficientnetv2-m-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_m/feature_vector/2",
"efficientnetv2-l-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_l/feature_vector/2",
"efficientnetv2-xl-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_xl/feature_vector/2",
"efficientnetv2-b0-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b0/feature_vector/2",
"efficientnetv2-b1-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b1/feature_vector/2",
"efficientnetv2-b2-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b2/feature_vector/2",
"efficientnetv2-b3-21k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_b3/feature_vector/2",
"efficientnetv2-s-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2",
"efficientnetv2-m-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_m/feature_vector/2",
"efficientnetv2-l-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_l/feature_vector/2",
"efficientnetv2-xl-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_xl/feature_vector/2",
"efficientnetv2-b0-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b0/feature_vector/2",
"efficientnetv2-b1-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b1/feature_vector/2",
"efficientnetv2-b2-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b2/feature_vector/2",
"efficientnetv2-b3-21k-ft1k": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_b3/feature_vector/2",
"efficientnetv2-b0": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b0/feature_vector/2",
"efficientnetv2-b1": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b1/feature_vector/2",
"efficientnetv2-b2": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b2/feature_vector/2",
"efficientnetv2-b3": "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b3/feature_vector/2",
"efficientnet_b0": "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1",
"efficientnet_b1": "https://tfhub.dev/tensorflow/efficientnet/b1/feature-vector/1",
"efficientnet_b2": "https://tfhub.dev/tensorflow/efficientnet/b2/feature-vector/1",
"efficientnet_b3": "https://tfhub.dev/tensorflow/efficientnet/b3/feature-vector/1",
"efficientnet_b4": "https://tfhub.dev/tensorflow/efficientnet/b4/feature-vector/1",
"efficientnet_b5": "https://tfhub.dev/tensorflow/efficientnet/b5/feature-vector/1",
"efficientnet_b6": "https://tfhub.dev/tensorflow/efficientnet/b6/feature-vector/1",
"efficientnet_b7": "https://tfhub.dev/tensorflow/efficientnet/b7/feature-vector/1",
"bit_s-r50x1": "https://tfhub.dev/google/bit/s-r50x1/1",
"inception_v3": "https://tfhub.dev/google/imagenet/inception_v3/feature-vector/4",
"inception_resnet_v2": "https://tfhub.dev/google/imagenet/inception_resnet_v2/feature-vector/4",
"resnet_v1_50": "https://tfhub.dev/google/imagenet/resnet_v1_50/feature-vector/4",
"resnet_v1_101": "https://tfhub.dev/google/imagenet/resnet_v1_101/feature-vector/4",
"resnet_v1_152": "https://tfhub.dev/google/imagenet/resnet_v1_152/feature-vector/4",
"resnet_v2_50": "https://tfhub.dev/google/imagenet/resnet_v2_50/feature-vector/4",
"resnet_v2_101": "https://tfhub.dev/google/imagenet/resnet_v2_101/feature-vector/4",
"resnet_v2_152": "https://tfhub.dev/google/imagenet/resnet_v2_152/feature-vector/4",
"nasnet_large": "https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/4",
"nasnet_mobile": "https://tfhub.dev/google/imagenet/nasnet_mobile/feature_vector/4",
"pnasnet_large": "https://tfhub.dev/google/imagenet/pnasnet_large/feature_vector/4",
"mobilenet_v2_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/4",
"mobilenet_v2_130_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_130_224/feature_vector/4",
"mobilenet_v2_140_224": "https://tfhub.dev/google/imagenet/mobilenet_v2_140_224/feature_vector/4",
"mobilenet_v3_small_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5",
"mobilenet_v3_small_075_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_small_075_224/feature_vector/5",
"mobilenet_v3_large_100_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5",
"mobilenet_v3_large_075_224": "https://tfhub.dev/google/imagenet/mobilenet_v3_large_075_224/feature_vector/5",
}
model_image_size_map = {
"efficientnetv2-s": 384,
"efficientnetv2-m": 480,
"efficientnetv2-l": 480,
"efficientnetv2-b0": 224,
"efficientnetv2-b1": 240,
"efficientnetv2-b2": 260,
"efficientnetv2-b3": 300,
"efficientnetv2-s-21k": 384,
"efficientnetv2-m-21k": 480,
"efficientnetv2-l-21k": 480,
"efficientnetv2-xl-21k": 512,
"efficientnetv2-b0-21k": 224,
"efficientnetv2-b1-21k": 240,
"efficientnetv2-b2-21k": 260,
"efficientnetv2-b3-21k": 300,
"efficientnetv2-s-21k-ft1k": 384,
"efficientnetv2-m-21k-ft1k": 480,
"efficientnetv2-l-21k-ft1k": 480,
"efficientnetv2-xl-21k-ft1k": 512,
"efficientnetv2-b0-21k-ft1k": 224,
"efficientnetv2-b1-21k-ft1k": 240,
"efficientnetv2-b2-21k-ft1k": 260,
"efficientnetv2-b3-21k-ft1k": 300,
"efficientnet_b0": 224,
"efficientnet_b1": 240,
"efficientnet_b2": 260,
"efficientnet_b3": 300,
"efficientnet_b4": 380,
"efficientnet_b5": 456,
"efficientnet_b6": 528,
"efficientnet_b7": 600,
"inception_v3": 299,
"inception_resnet_v2": 299,
"nasnet_large": 331,
"pnasnet_large": 331,
}
model_handle = model_handle_map.get(model_name)
pixels = model_image_size_map.get(model_name, 224)
print(f"Selected model: {model_name} : {model_handle}")
IMAGE_SIZE = (pixels, pixels)
print(f"Input size {IMAGE_SIZE}")
BATCH_SIZE = 16
Selected model: efficientnetv2-xl-21k : https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_xl/feature_vector/2 Input size (512, 512)
Flowers データセットをセットアップする
入力は、選択されたモジュールに合わせてサイズ変更されます。データセットを拡張することで(読み取られるたびに画像をランダムに歪みを加える)、特にファインチューニング時のトレーニングが改善されます。
data_dir = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228813984/228813984 [==============================] - 1s 0us/step
def build_dataset(subset):
return tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=.20,
subset=subset,
label_mode="categorical",
# Seed needs to provided when using validation_split and shuffle = True.
# A fixed seed is used so that the validation set is stable across runs.
seed=123,
image_size=IMAGE_SIZE,
batch_size=1)
train_ds = build_dataset("training")
class_names = tuple(train_ds.class_names)
train_size = train_ds.cardinality().numpy()
train_ds = train_ds.unbatch().batch(BATCH_SIZE)
train_ds = train_ds.repeat()
normalization_layer = tf.keras.layers.Rescaling(1. / 255)
preprocessing_model = tf.keras.Sequential([normalization_layer])
do_data_augmentation = False
if do_data_augmentation:
preprocessing_model.add(
tf.keras.layers.RandomRotation(40))
preprocessing_model.add(
tf.keras.layers.RandomTranslation(0, 0.2))
preprocessing_model.add(
tf.keras.layers.RandomTranslation(0.2, 0))
# Like the old tf.keras.preprocessing.image.ImageDataGenerator(),
# image sizes are fixed when reading, and then a random zoom is applied.
# If all training inputs are larger than image_size, one could also use
# RandomCrop with a batch size of 1 and rebatch later.
preprocessing_model.add(
tf.keras.layers.RandomZoom(0.2, 0.2))
preprocessing_model.add(
tf.keras.layers.RandomFlip(mode="horizontal"))
train_ds = train_ds.map(lambda images, labels:
(preprocessing_model(images), labels))
val_ds = build_dataset("validation")
valid_size = val_ds.cardinality().numpy()
val_ds = val_ds.unbatch().batch(BATCH_SIZE)
val_ds = val_ds.map(lambda images, labels:
(normalization_layer(images), labels))
Found 3670 files belonging to 5 classes. Using 2936 files for training. Found 3670 files belonging to 5 classes. Using 734 files for validation.
モデルを定義する
Hub モジュールを使用して、線形分類器を feature_extractor_layer の上に配置するだけで定義できます。
高速化するため、トレーニング不可能な feature_extractor_layer から始めますが、ファインチューニングを実施して精度を高めることもできます。
do_fine_tuning = False
print("Building model with", model_handle)
model = tf.keras.Sequential([
# Explicitly define the input shape so the model can be properly
# loaded by the TFLiteConverter
tf.keras.layers.InputLayer(input_shape=IMAGE_SIZE + (3,)),
hub.KerasLayer(model_handle, trainable=do_fine_tuning),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(len(class_names),
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
Building model with https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_xl/feature_vector/2
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 1280) 207615832
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 5) 6405
=================================================================
Total params: 207622237 (792.02 MB)
Trainable params: 6405 (25.02 KB)
Non-trainable params: 207615832 (791.99 MB)
_________________________________________________________________
モデルをトレーニングする
model.compile(
optimizer=tf.keras.optimizers.SGD(learning_rate=0.005, momentum=0.9),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1),
metrics=['accuracy'])
steps_per_epoch = train_size // BATCH_SIZE
validation_steps = valid_size // BATCH_SIZE
hist = model.fit(
train_ds,
epochs=5, steps_per_epoch=steps_per_epoch,
validation_data=val_ds,
validation_steps=validation_steps).history
Epoch 1/5 1/183 [..............................] - ETA: 1:52:17 - loss: 2.6761 - accuracy: 0.1875 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1705003243.156430 162420 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 183/183 [==============================] - 323s 2s/step - loss: 0.8854 - accuracy: 0.8921 - val_loss: 0.7000 - val_accuracy: 0.9347 Epoch 2/5 183/183 [==============================] - 290s 2s/step - loss: 0.6304 - accuracy: 0.9541 - val_loss: 0.5608 - val_accuracy: 0.9667 Epoch 3/5 183/183 [==============================] - 286s 2s/step - loss: 0.5825 - accuracy: 0.9603 - val_loss: 0.5395 - val_accuracy: 0.9653 Epoch 4/5 183/183 [==============================] - 286s 2s/step - loss: 0.5705 - accuracy: 0.9661 - val_loss: 0.5450 - val_accuracy: 0.9639 Epoch 5/5 183/183 [==============================] - 285s 2s/step - loss: 0.5294 - accuracy: 0.9753 - val_loss: 0.5530 - val_accuracy: 0.9639
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["accuracy"])
plt.plot(hist["val_accuracy"])
[<matplotlib.lines.Line2D at 0x7f214a750d90>]
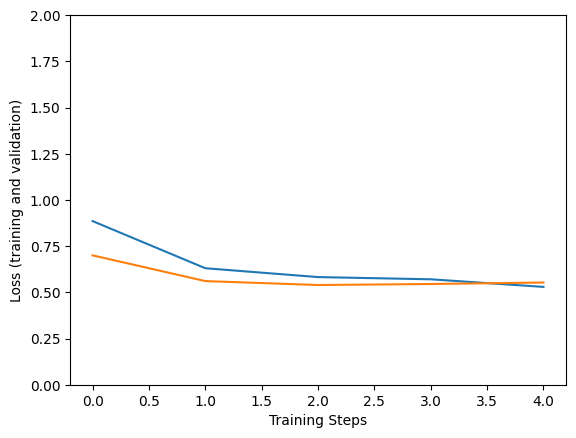
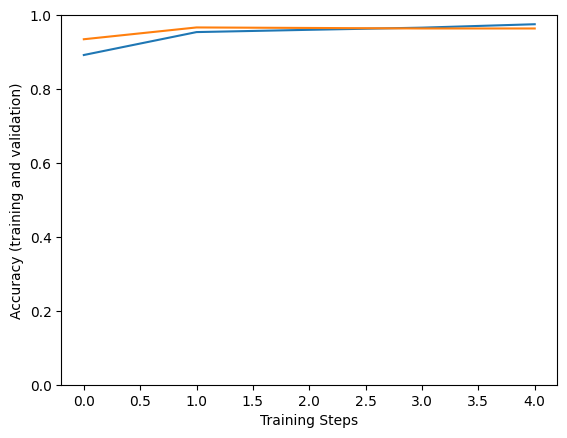
検証データの画像でモデルが機能するか試してみましょう。
x, y = next(iter(val_ds))
image = x[0, :, :, :]
true_index = np.argmax(y[0])
plt.imshow(image)
plt.axis('off')
plt.show()
# Expand the validation image to (1, 224, 224, 3) before predicting the label
prediction_scores = model.predict(np.expand_dims(image, axis=0))
predicted_index = np.argmax(prediction_scores)
print("True label: " + class_names[true_index])
print("Predicted label: " + class_names[predicted_index])

1/1 [==============================] - 6s 6s/step True label: sunflowers Predicted label: sunflowers
最後に次のようにして、トレーニングされたモデルを、TF Serving または TF Lite(モバイル)用に保存することができます。
saved_model_path = f"/tmp/saved_flowers_model_{model_name}"
tf.saved_model.save(model, saved_model_path)
INFO:tensorflow:Assets written to: /tmp/saved_flowers_model_efficientnetv2-xl-21k/assets INFO:tensorflow:Assets written to: /tmp/saved_flowers_model_efficientnetv2-xl-21k/assets
オプション: TensorFlow Lite にデプロイする
TensorFlow Lite では、TensorFlow モデルをモバイルおよび IoT デバイスにデプロイすることができます。以下のコードには、トレーニングされたモデルを TF Lite に変換して、TensorFlow Model Optimization Toolkit のポストトレーニングツールを適用する方法が示されています。最後に、結果の質を調べるために、変換したモデルを TF Lite Interpreter で実行しています。
- 最適化せずに変換すると、前と同じ結果が得られます(丸め誤差まで)。
- データなしで最適化して変換すると、モデルの重みを 8 ビットに量子化しますが、それでもニューラルネットワークアクティベーションの推論では浮動小数点数計算が使用されます。これにより、モデルのサイズが約 4 倍に縮小されるため、モバイルデバイスの CPU レイテンシが改善されます。
- 最上部の、ニューラルネットワークアクティベーションの計算は、量子化の範囲を調整するために小規模な参照データセットが提供される場合、8 ビット整数に量子化されます。モバイルデバイスでは、これにより推論がさらに高速化されるため、EdgeTPU などのアクセラレータで実行することが可能となります。
Optimization settings
optimize_lite_model = False
num_calibration_examples = 60
representative_dataset = None
if optimize_lite_model and num_calibration_examples:
# Use a bounded number of training examples without labels for calibration.
# TFLiteConverter expects a list of input tensors, each with batch size 1.
representative_dataset = lambda: itertools.islice(
([image[None, ...]] for batch, _ in train_ds for image in batch),
num_calibration_examples)
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
if optimize_lite_model:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if representative_dataset: # This is optional, see above.
converter.representative_dataset = representative_dataset
lite_model_content = converter.convert()
with open(f"/tmp/lite_flowers_model_{model_name}.tflite", "wb") as f:
f.write(lite_model_content)
print("Wrote %sTFLite model of %d bytes." %
("optimized " if optimize_lite_model else "", len(lite_model_content)))
2024-01-11 20:25:57.979361: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:378] Ignored output_format. 2024-01-11 20:25:57.979412: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:381] Ignored drop_control_dependency. Summary on the non-converted ops: --------------------------------- * Accepted dialects: tfl, builtin, func * Non-Converted Ops: 879, Total Ops 2180, % non-converted = 40.32 % * 879 ARITH ops - arith.constant: 879 occurrences (f32: 878, i32: 1) (f32: 94) (f32: 358) (f32: 80) (f32: 1) (f32: 342) (f32: 81) (f32: 342) Wrote TFLite model of 826217852 bytes.
interpreter = tf.lite.Interpreter(model_content=lite_model_content)
# This little helper wraps the TFLite Interpreter as a numpy-to-numpy function.
def lite_model(images):
interpreter.allocate_tensors()
interpreter.set_tensor(interpreter.get_input_details()[0]['index'], images)
interpreter.invoke()
return interpreter.get_tensor(interpreter.get_output_details()[0]['index'])
num_eval_examples = 50
eval_dataset = ((image, label) # TFLite expects batch size 1.
for batch in train_ds
for (image, label) in zip(*batch))
count = 0
count_lite_tf_agree = 0
count_lite_correct = 0
for image, label in eval_dataset:
probs_lite = lite_model(image[None, ...])[0]
probs_tf = model(image[None, ...]).numpy()[0]
y_lite = np.argmax(probs_lite)
y_tf = np.argmax(probs_tf)
y_true = np.argmax(label)
count +=1
if y_lite == y_tf: count_lite_tf_agree += 1
if y_lite == y_true: count_lite_correct += 1
if count >= num_eval_examples: break
print("TFLite model agrees with original model on %d of %d examples (%g%%)." %
(count_lite_tf_agree, count, 100.0 * count_lite_tf_agree / count))
print("TFLite model is accurate on %d of %d examples (%g%%)." %
(count_lite_correct, count, 100.0 * count_lite_correct / count))
INFO: Created TensorFlow Lite XNNPACK delegate for CPU. TFLite model agrees with original model on 50 of 50 examples (100%). TFLite model is accurate on 50 of 50 examples (100%).