
شروع شدن
TensorFlow Hub یک مخزن جامع از مدل های از پیش آموزش دیده آماده برای تنظیم دقیق و قابل استقرار در هر مکانی است. جدیدترین مدل های آموزش دیده را با حداقل کد با کتابخانه tensorflow_hub کنید.
آموزشهای زیر به شما کمک میکند تا با استفاده از مدلهای TF Hub برای نیازهای خود و بهکارگیری آنها شروع کنید. آموزش های تعاملی به شما امکان می دهد آنها را تغییر دهید و با تغییرات خود آنها را اجرا کنید. روی دکمه Run in Google Colab در بالای یک آموزش تعاملی کلیک کنید تا آن را به هم بزنید.
برای مبتدی ها
اگر با یادگیری ماشین و TensorFlow آشنا نیستید، میتوانید با دریافت یک نمای کلی از نحوه طبقهبندی تصاویر و متن، تشخیص اشیاء در تصاویر، یا با سبکسازی تصاویر خود مانند آثار هنری معروف، شروع کنید:

طبقه بندی تصویر
یک مدل Keras در بالای طبقهبندی تصویر از پیش آموزشدیده بسازید تا گلها را متمایز کنید.
طبقه بندی متن با BERT
از BERT برای ساخت یک مدل Keras برای حل یک تکلیف تجزیه و تحلیل احساسات طبقه بندی متن استفاده کنید.انتقال سبک
اجازه دهید یک شبکه عصبی تصویری را به سبک پیکاسو، ون گوگ یا مانند تصویر سبک خودتان دوباره ترسیم کند.
تشخیص شی
اشیاء را در تصاویر با استفاده از مدل هایی مانند FasterRCNN یا SSD تشخیص دهید.برای توسعه دهندگان با تجربه
آموزش های پیشرفته تر را برای نحوه استفاده از مدل های NLP، تصاویر، صدا و ویدیو از TensorFlow Hub بررسی کنید.
آموزش های NLP
وظایف رایج NLP را با مدل های TensorFlow Hub حل کنید. تمام آموزش های NLP موجود را در ناوبری سمت چپ مشاهده کنید.
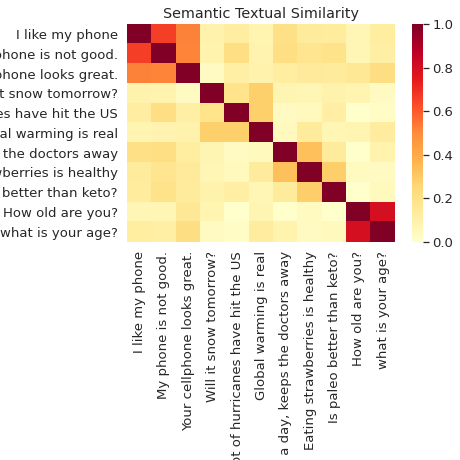
تشابه معنایی
دسته بندی و مقایسه معنایی جملات با رمزگذار جملات جهانی.
BERT در TPU
از BERT برای حل وظایف بنچمارک GLUE که روی TPU اجرا می شوند، استفاده کنید.پرسش و پاسخ رمزگذار جملات جهانی چند زبانه
با استفاده از مدل پرسش و پاسخ رمزگذار جملات جهانی چندزبانه، به سؤالات چند زبانه از مجموعه داده SQuAD پاسخ دهید.آموزش تصویری
نحوه استفاده از GAN، مدلهای وضوح فوقالعاده و موارد دیگر را کاوش کنید. تمام آموزش های تصویری موجود را در ناوبری سمت چپ مشاهده کنید.

GANS برای تولید تصویر
چهره های مصنوعی تولید کنید و با استفاده از GAN بین آن ها درون یابی کنید.
وضوح فوق العاده
وضوح تصاویر پاییننمونهشده را افزایش دهید.
پسوند تصویر
قسمت پوشانده شده تصاویر داده شده را پر کنید.آموزش های صوتی
آموزشها را با استفاده از مدلهای آموزشدیده برای دادههای صوتی از جمله تشخیص زیر و بم و طبقهبندی صدا کاوش کنید.

تشخیص گام
در حال آواز خواندن خود را ضبط کنید و با استفاده از مدل SPICE میزان صدای خود را تشخیص دهید.
طبقه بندی صدا
از مدل YAMNet برای طبقه بندی صداها به عنوان 521 کلاس رویداد صوتی از مجموعه AudioSet-YouTube استفاده کنید.آموزش های تصویری
مدلهای آموزشدیده ML را برای دادههای ویدیویی برای تشخیص عملکرد، درونیابی ویدیویی و موارد دیگر امتحان کنید.

تشخیص عمل
با استفاده از مدل Inflated 3D ConvNet یکی از 400 اقدام را در یک ویدیو شناسایی کنید.
درون یابی ویدئویی
با استفاده از Inbetweening با کانولوشن های سه بعدی، بین فریم های ویدیویی درون یابی کنید.