
เริ่มต้น
TensorFlow Hub เป็นพื้นที่เก็บข้อมูลที่ครอบคลุมของโมเดลที่ได้รับการฝึกอบรมล่วงหน้า ซึ่งพร้อมสำหรับการปรับแต่งอย่างละเอียดและปรับใช้ได้ทุกที่ ดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมล่าสุดด้วยโค้ดจำนวนน้อยที่สุดด้วยไลบรารี tensorflow_hub
บทช่วยสอนต่อไปนี้จะช่วยคุณในการเริ่มต้นใช้งานและปรับใช้โมเดลจาก TF Hub ตามความต้องการของคุณ บทช่วยสอนแบบโต้ตอบช่วยให้คุณแก้ไขและดำเนินการตามการเปลี่ยนแปลงของคุณ คลิกปุ่ม เรียกใช้ใน Google Colab ที่ด้านบนของบทแนะนำแบบโต้ตอบเพื่อปรับแต่ง
สำหรับผู้เริ่มต้น
หากคุณไม่คุ้นเคยกับแมชชีนเลิร์นนิงและ TensorFlow คุณสามารถเริ่มต้นด้วยการดูภาพรวมของวิธีการจัดประเภทรูปภาพและข้อความ การตรวจจับวัตถุในภาพ หรือโดยการจัดสไตล์รูปภาพของคุณเอง เช่น งานศิลปะที่มีชื่อเสียง:

การจำแนกรูปภาพ
สร้างโมเดล Keras ที่ด้านบนของตัวแยกประเภทรูปภาพที่ได้รับการฝึกมาล่วงหน้าเพื่อแยกความแตกต่างของดอกไม้
จำแนกข้อความด้วย BERT
ใช้ BERT เพื่อสร้างแบบจำลอง Keras เพื่อแก้ไขงานวิเคราะห์ความคิดเห็นในการจัดประเภทข้อความการถ่ายโอนสไตล์
ให้โครงข่ายประสาทเทียมวาดภาพใหม่ในสไตล์ของ Picasso, van Gogh หรือชอบภาพสไตล์ของคุณเอง
การตรวจจับวัตถุ
ตรวจจับวัตถุในภาพโดยใช้โมเดล เช่น FasterRCNN หรือ SSDสำหรับนักพัฒนาที่มีประสบการณ์
ดูบทช่วยสอนขั้นสูงเพิ่มเติมเกี่ยวกับวิธีใช้โมเดล NLP รูปภาพ เสียง และวิดีโอจาก TensorFlow Hub
แบบฝึกหัด NLP
แก้ไขงาน NLP ทั่วไปด้วยโมเดลจาก TensorFlow Hub ดูบทช่วยสอน NLP ที่มีอยู่ทั้งหมดในการนำทางด้านซ้าย
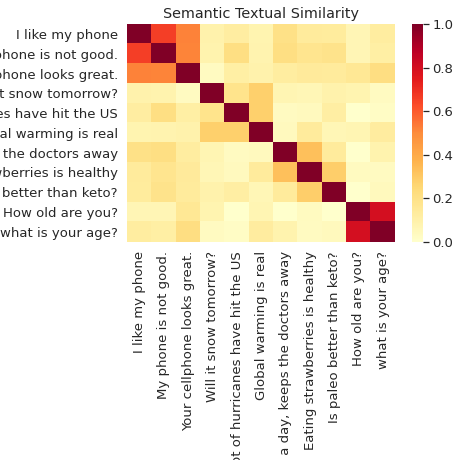
ความคล้ายคลึงกันทางความหมาย
จำแนกและเปรียบเทียบประโยคตามความหมายด้วย Universal Sentence Encoder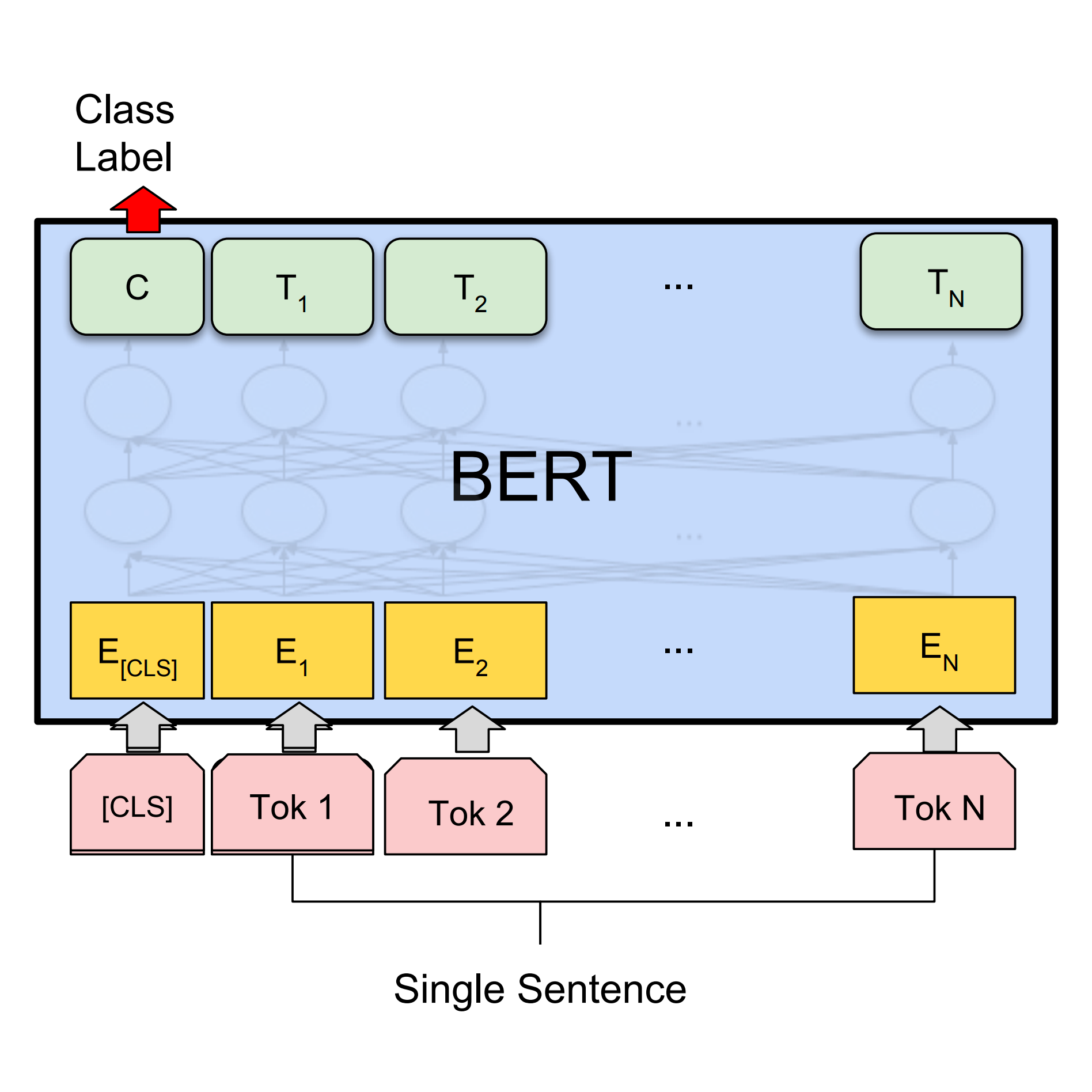
BERT บน TPU
ใช้ BERT เพื่อแก้ปัญหาการวัดประสิทธิภาพ GLUE ที่ทำงานบน TPUMultilingual Universal Sentence Encoder Q&A
ตอบคำถามข้ามภาษาจากชุดข้อมูล SQuaD โดยใช้แบบจำลอง Q&A ของตัวเข้ารหัสประโยคสากลหลายภาษากวดวิชาภาพ
สำรวจวิธีใช้ GAN โมเดลความละเอียดสูง และอื่นๆ ดูบทแนะนำเกี่ยวกับรูปภาพทั้งหมดที่มีอยู่ในการนำทางด้านซ้าย

GANS สำหรับการสร้างภาพ
สร้างใบหน้าปลอมและสอดแทรกระหว่างใบหน้าโดยใช้ GAN
สุดยอดความละเอียด
เพิ่มความละเอียดของภาพที่ลดขนาดตัวอย่าง
ส่วนขยายรูปภาพ
เติมส่วนที่ปิดบังของภาพที่กำหนดแบบฝึกหัดเสียง
สำรวจบทช่วยสอนโดยใช้โมเดลที่ผ่านการฝึกอบรมสำหรับข้อมูลเสียง รวมถึงการรู้จำระดับเสียงและการจัดประเภทเสียง
การจดจำระดับเสียง
บันทึกตัวเองร้องเพลงและตรวจจับระดับเสียงของคุณโดยใช้โมเดล SPICE
การจำแนกเสียง
ใช้โมเดล YAMNet เพื่อจัดประเภทเสียงเป็น 521 คลาสเหตุการณ์เสียงจากคลังข้อมูล AudioSet-YouTubeวิดีโอสอน
ลองใช้โมเดล ML ที่ได้รับการฝึกอบรมสำหรับข้อมูลวิดีโอสำหรับการรู้จำการดำเนินการ การแก้ไขวิดีโอ และอื่นๆ

การรับรู้การกระทำ
ตรวจจับการกระทำอย่างใดอย่างหนึ่งจากทั้งหมด 400 รายการในวิดีโอโดยใช้โมเดล Inflated 3D ConvNet
การแก้ไขวิดีโอ
สอดแทรกระหว่างเฟรมวิดีโอโดยใช้ Inbetweening กับ 3D Convolutions