
TensorFlow Lattice — это библиотека, реализующая гибкие, контролируемые и интерпретируемые модели на основе решеток. Библиотека позволяет вам внедрять знания предметной области в процесс обучения посредством ограничений формы , основанных на здравом смысле или на основе политик. Это делается с помощью набора слоев Keras , которые могут удовлетворять таким ограничениям, как монотонность, выпуклость и парное доверие. Библиотека также предоставляет простые в настройке готовые модели .
Концепции
Этот раздел представляет собой упрощенную версию описания в Monotonic Calibrated Interpolated Look-Up Tables , JMLR 2016.
Решетки
Решетка — это интерполированная справочная таблица, которая может аппроксимировать произвольные отношения ввода-вывода в ваших данных. Он накладывает обычную сетку на пространство ввода и изучает значения для вывода в вершинах сетки. Для контрольной точки \(x\)\(f(x)\) линейно интерполируется из значений решетки, окружающей \(x\).
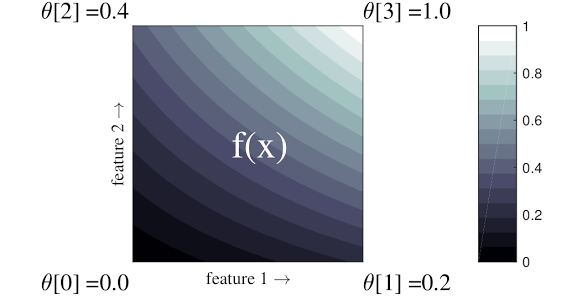
Простой пример выше — это функция с двумя входными функциями и четырьмя параметрами:\(\theta=[0, 0.2, 0.4, 1]\), которые представляют собой значения функции в углах входного пространства; остальная часть функции интерполируется на основе этих параметров.
Функция \(f(x)\) может фиксировать нелинейные взаимодействия между объектами. Вы можете думать о параметрах решетки как о высоте шестов, установленных в земле на регулярной сетке, а результирующая функция подобна ткани, натянутой на четыре шеста.
С элементами \(D\) и двумя вершинами в каждом измерении обычная решетка будет иметь параметры \(2^D\) . Чтобы реализовать более гибкую функцию, вы можете указать более мелкозернистую решетку в пространстве объектов с большим количеством вершин по каждому измерению. Функции решеточной регрессии непрерывны и кусочно бесконечно дифференцируемы.
Калибровка
Допустим, предыдущая примерная решетка представляет собой изученную удовлетворенность пользователя предлагаемой местной кофейней, рассчитанную с использованием функций:
- цена кофе в диапазоне от 0 до 20 долларов
- расстояние до пользователя в диапазоне от 0 до 30 километров
Мы хотим, чтобы наша модель изучала уровень удовлетворенности пользователей с помощью предложения местной кофейни. Решетчатые модели TensorFlow могут использовать кусочно-линейные функции (с tfl.layers.PWLCalibration ) для калибровки и нормализации входных признаков в диапазоне, принятом решеткой: от 0,0 до 1,0 в приведенном выше примере решетки. Ниже показаны примеры таких функций калибровки с 10 ключевыми точками:
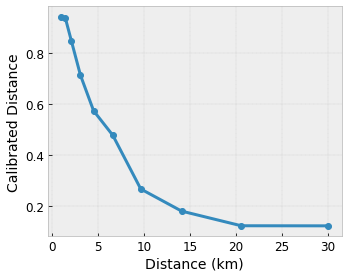
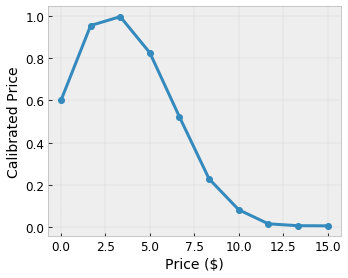
Зачастую полезно использовать квантили признаков в качестве входных ключевых точек. Готовые модели TensorFlow Lattice могут автоматически устанавливать входные ключевые точки для квантилей признаков.
Для категориальных функций TensorFlow Lattice обеспечивает категориальную калибровку (с помощью tfl.layers.CategoricalCalibration ) с аналогичным выходным ограничением для подачи в решетку.
Ансамбли
Количество параметров слоя решетки увеличивается экспоненциально с увеличением количества входных объектов, поэтому плохо масштабируется до очень больших размеров. Чтобы преодолеть это ограничение, TensorFlow Lattice предлагает ансамбли решеток, которые объединяют (в среднем) несколько крошечных решеток, что позволяет модели линейно увеличивать количество функций.
Библиотека предоставляет два варианта этих ансамблей:
Случайные крошечные решетки (RTL): каждая подмодель использует случайное подмножество функций (с заменой).
Кристаллы : Алгоритм «Кристаллы» сначала обучает модель предварительной настройки , которая оценивает взаимодействие парных признаков. Затем он упорядочивает окончательный ансамбль таким образом, чтобы элементы с более нелинейными взаимодействиями находились в одних и тех же решетках.
Почему решетка TensorFlow?
Краткое введение в TensorFlow Lattice вы можете найти в этом посте блога TF .
Интерпретируемость
Поскольку параметры каждого слоя являются выходными данными этого слоя, каждую часть модели легко анализировать, понимать и отлаживать.
Точные и гибкие модели
Используя мелкозернистые решетки, можно получать сколь угодно сложные функции с одним слоем решетки. Использование нескольких слоев калибраторов и решеток часто хорошо работает на практике и может соответствовать или превосходить модели DNN аналогичных размеров.
Ограничения формы здравого смысла
Данные обучения в реальном мире могут не в полной мере отражать данные времени выполнения. Гибкие решения машинного обучения, такие как DNN или леса, часто действуют неожиданно и даже хаотично в частях входного пространства, не охваченных обучающими данными. Такое поведение особенно проблематично, когда могут быть нарушены ограничения политики или справедливости.
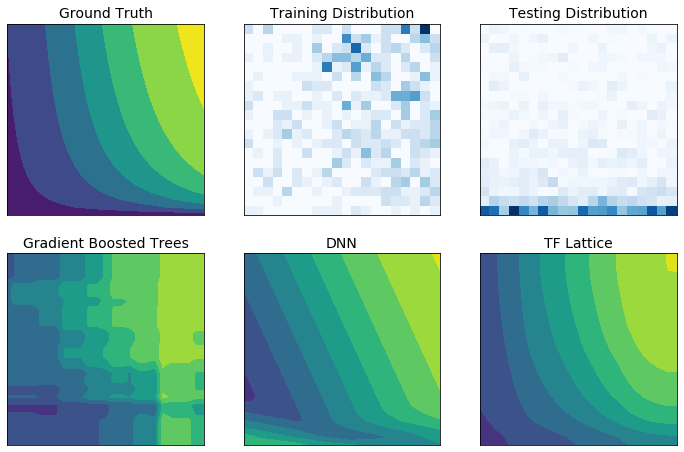
Несмотря на то, что обычные формы регуляризации могут привести к более разумной экстраполяции, стандартные регуляризаторы не могут гарантировать разумное поведение модели во всем входном пространстве, особенно с многомерными входными данными. Переход к более простым моделям с более контролируемым и предсказуемым поведением может привести к серьезному ухудшению точности модели.
TF Lattice позволяет продолжать использовать гибкие модели, но предоставляет несколько вариантов внедрения знаний предметной области в процесс обучения посредством семантически значимых ограничений формы , основанных на здравом смысле или политиках:
- Монотонность : вы можете указать, что выходной сигнал должен только увеличиваться/уменьшаться по отношению к входному. В нашем примере вы можете указать, что увеличение расстояния до кафе должно только уменьшить прогнозируемые предпочтения пользователя.
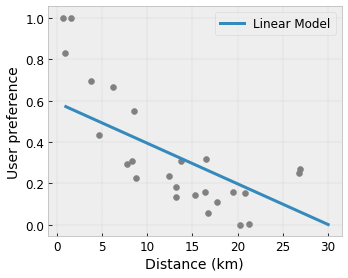
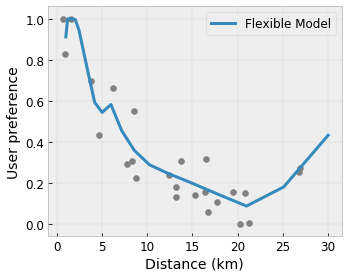
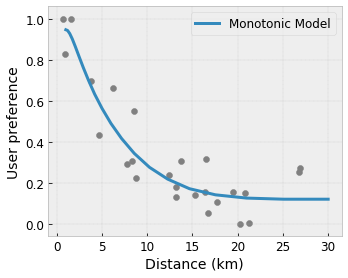
Выпуклость/Вогнутость : вы можете указать, что форма функции может быть выпуклой или вогнутой. В сочетании с монотонностью это может привести к тому, что функция будет представлять убывающую отдачу по отношению к данному признаку.
Унимодальность : вы можете указать, что функция должна иметь уникальный пик или уникальную впадину. Это позволяет вам представлять функции, у которых есть преимущество по отношению к функции.
Парное доверие . Это ограничение работает с парой функций и предполагает, что одна входная функция семантически отражает доверие к другой функции. Например, большее количество отзывов дает вам больше уверенности в среднем звездном рейтинге ресторана. Модель будет более чувствительной к звездному рейтингу (т. е. будет иметь больший наклон относительно рейтинга), когда количество отзывов будет выше.
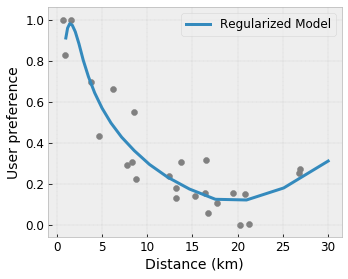
Контролируемая гибкость с помощью регуляризаторов
Помимо ограничений формы, решетка TensorFlow предоставляет ряд регуляризаторов для управления гибкостью и плавностью функции для каждого слоя.
Регуляризатор Лапласа : выходные данные решётки/калибровочных вершин/ключевых точек регуляризуются по значениям их соответствующих соседей. Это приводит к более плоской функции.
Регуляризатор Гессиана : штрафует первую производную калибровочного слоя PWL, чтобы сделать функцию более линейной .
Регуляризатор морщин : штрафует вторую производную калибровочного слоя PWL, чтобы избежать внезапных изменений кривизны. Это делает функцию более плавной.
Регуляризатор кручения : выходные данные решетки будут регуляризованы для предотвращения кручения между элементами. Другими словами, модель будет регуляризована в сторону независимости между вкладами признаков.
Смешивайте и сочетайте с другими слоями Keras.
Вы можете использовать слои TF Lattice в сочетании с другими слоями Keras для построения частично ограниченных или регуляризованных моделей. Например, калибровочные слои решетки или PWL можно использовать на последнем уровне более глубоких сетей, которые включают в себя внедрения или другие слои Keras.
Статьи
- Деонтологическая этика с помощью ограничений формы монотонности , Серена Ванг, Майя Гупта, Международная конференция по искусственному интеллекту и статистике (AISTATS), 2020
- Ограничения формы для функций множеств , Эндрю Коттер, Майя Гупта, Х. Цзян, Эрез Луидор, Джим Мюллер, Таман Нараян, Серена Ван, Тао Чжу. Международная конференция по машинному обучению (ICML), 2019 г.
- Ограничения формы убывающей доходности для интерпретируемости и регуляризации , Майя Гупта, Дара Бахри, Эндрю Коттер, Кевин Канини, Достижения в области нейронных систем обработки информации (NeurIPS), 2018
- Сети с глубокими решетками и частичные монотонные функции , Сынгил Ю, Кевин Канини, Дэвид Динг, Ян Пфайфер, Майя Р. Гупта, Достижения в области нейронных систем обработки информации (NeurIPS), 2017
- Быстрые и гибкие монотонные функции с ансамблями решеток , Махди Милани Фард, Кевин Канини, Эндрю Коттер, Ян Пфайфер, Майя Гупта, Достижения в области нейронных систем обработки информации (NeurIPS), 2016
- Монотонные калиброванные интерполированные справочные таблицы , Майя Гупта, Эндрю Коттер, Ян Пфайфер, Константин Воеводский, Кевин Канини, Александр Мангилов, Войцех Мочидловски, Александр ван Эсбрук, Журнал исследований машинного обучения (JMLR), 2016
- Оптимизированная регрессия для эффективной оценки функций , Эрик Гарсия, Раман Арора, Майя Р. Гупта, Транзакции IEEE при обработке изображений, 2012 г.
- Решетчатая регрессия , Эрик Гарсия, Майя Гупта, Достижения в области нейронных систем обработки информации (NeurIPS), 2009 г.
Учебники и документация по API
Для распространенных архитектур моделей вы можете использовать готовые модели Keras . Вы также можете создавать собственные модели, используя слои TF Lattice Keras , или смешивать их с другими слоями Keras. Подробности можно найти в полной документации API .