
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
אומדנים משומרים הם דרכים מהירות וקלות לאמן דגמי TFL למקרי שימוש טיפוסיים. מדריך זה מתאר את השלבים הדרושים ליצירת אומדן משומר TFL.
להכין
התקנת חבילת TF Lattice:
pip install tensorflow-lattice
ייבוא חבילות נדרשות:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
הורדת מערך הנתונים של UCI Statlog (לב):
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
df = pd.read_csv(csv_file)
target = df.pop('target')
train_size = int(len(df) * 0.8)
train_x = df[:train_size]
train_y = target[:train_size]
test_x = df[train_size:]
test_y = target[train_size:]
df.head()
הגדרת ערכי ברירת המחדל המשמשים לאימון במדריך זה:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
עמודות תכונה
באשר לכל אומדן TF אחרות, הצרכים הנתונים שיועברו במעריך, שהוא בדרך כלל באמצעות input_fn ו מנותח באמצעות FeatureColumns .
# Feature columns.
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect
feature_columns = [
fc.numeric_column('age', default_value=-1),
fc.categorical_column_with_vocabulary_list('sex', [0, 1]),
fc.numeric_column('cp'),
fc.numeric_column('trestbps', default_value=-1),
fc.numeric_column('chol'),
fc.categorical_column_with_vocabulary_list('fbs', [0, 1]),
fc.categorical_column_with_vocabulary_list('restecg', [0, 1, 2]),
fc.numeric_column('thalach'),
fc.categorical_column_with_vocabulary_list('exang', [0, 1]),
fc.numeric_column('oldpeak'),
fc.categorical_column_with_vocabulary_list('slope', [0, 1, 2]),
fc.numeric_column('ca'),
fc.categorical_column_with_vocabulary_list(
'thal', ['normal', 'fixed', 'reversible']),
]
אומדני TFL משומרים משתמשים בסוג עמודת התכונה כדי להחליט באיזה סוג שכבת כיול להשתמש. אנו משתמשים tfl.layers.PWLCalibration שכבה עבור עמודות תכונה מספריות וגם tfl.layers.CategoricalCalibration שכבה עבור עמודות תכונת קטגורים.
שים לב שעמודות תכונה קטגוריות אינן עוטפות על ידי עמודת תכונה הטמעה. הם מוזנים ישירות לאומדן.
יצירת input_fn
באשר לכל אומדן אחר, אתה יכול להשתמש ב-input_fn כדי להזין נתונים למודל לצורך הדרכה והערכה. מערכי TFL יכולים לחשב אוטומטית כמות של תכונות ולהשתמש בהן כנקודות מפתח עבור שכבת הכיול PWL. לשם כך, הם דורשים העברת feature_analysis_input_fn , הדומה האימון input_fn אבל עם עידן בודד או subsample של נתונים.
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
num_threads=1)
# feature_analysis_input_fn is used to collect statistics about the input.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
# Note that we only need one pass over the data.
num_epochs=1,
num_threads=1)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=test_x,
y=test_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=1,
num_threads=1)
# Serving input fn is used to create saved models.
serving_input_fn = (
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=fc.make_parse_example_spec(feature_columns)))
תצורות תכונה
כיול Feature ותצורות לכל תכונה נקבעים באמצעות tfl.configs.FeatureConfig . תצורות Feature כוללות מגבלות מונוטוניות, לכול תכונת הסדרה (ראה tfl.configs.RegularizerConfig ), וגדל סריג עבור דגמי סריג.
אם אין תצורה מוגדרת עבור תכונת קלט, בתצורת ברירת מחדל tfl.config.FeatureConfig משמשת.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
# By default, input keypoints of pwl are quantiles of the feature.
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='cp',
pwl_calibration_num_keypoints=4,
# Keypoints can be uniformly spaced.
pwl_calibration_input_keypoints='uniform',
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='chol',
# Explicit input keypoint initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
monotonicity='increasing',
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='trestbps',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='thalach',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='oldpeak',
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
),
tfl.configs.FeatureConfig(
name='ca',
pwl_calibration_num_keypoints=4,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
),
]
מודל ליניארי מכויל
כדי לבנות TFL משומר אומדן, לבנות תצורת מודל מ tfl.configs . מודל ליניארי מכויל נבנה באמצעות tfl.configs.CalibratedLinearConfig . הוא מחיל כיול חלקי-ליניארי וקטגורי על תכונות הקלט, ואחריו שילוב ליניארי וכיול פלט אופציונלי חלקי-ליניארי. בעת שימוש בכיול פלט או כאשר מוגדרים גבולות פלט, השכבה הליניארית תחיל ממוצע משוקלל על תשומות מכוילות.
דוגמה זו יוצרת מודל ליניארי מכויל על 5 התכונות הראשונות. אנו משתמשים tfl.visualization להתוות את מודל גרף עם חלקות כיל.
# Model config defines the model structure for the estimator.
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs,
use_bias=True,
output_calibration=True,
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated linear test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
2021-09-30 20:54:06.660239: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Calibrated linear test AUC: 0.834586501121521
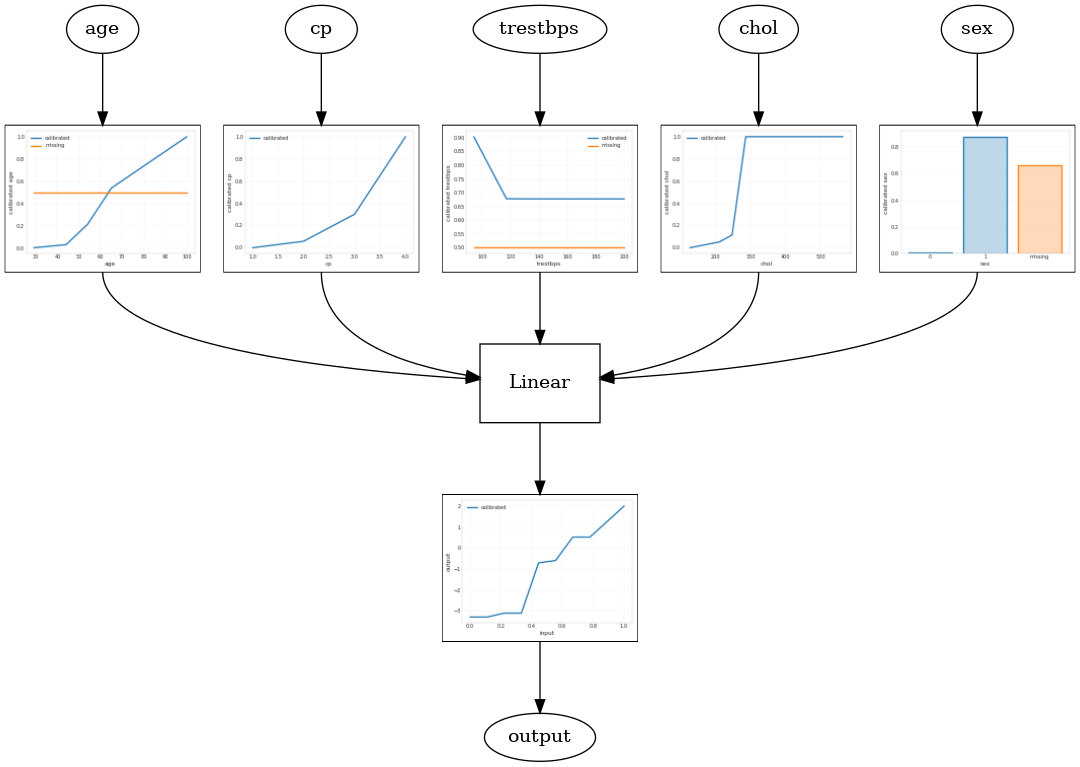
דגם סריג מכויל
מודל סריג מכויל נבנה באמצעות tfl.configs.CalibratedLatticeConfig . מודל סריג מכויל מיישם כיול חלקי-ליניארי וקטגורי על תכונות הקלט, ואחריו מודל סריג וכיול פלט אופציונלי חלקי-ליניארי.
דוגמה זו יוצרת מודל סריג מכויל על 5 התכונות הראשונות.
# This is calibrated lattice model: Inputs are calibrated, then combined
# non-linearly using a lattice layer.
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=feature_configs,
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-4),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated lattice test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
Calibrated lattice test AUC: 0.8427318930625916
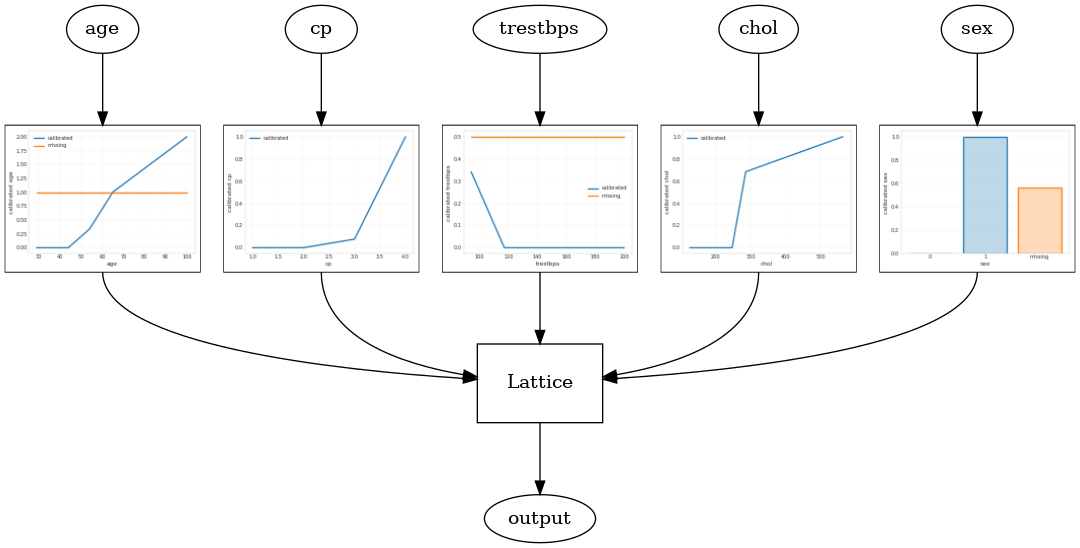
אנסמבל סריג מכויל
כאשר מספר התכונות גדול, אתה יכול להשתמש במודל אנסמבל, שיוצר מספר סריג קטן יותר עבור תת-קבוצות של התכונות וממוצע את הפלט שלהן במקום ליצור רק סריג ענק אחד. מודלי סריג אנסמבל בנוי באמצעות tfl.configs.CalibratedLatticeEnsembleConfig . מודל אנסמבל סריג מכויל מחיל כיול חלקי-ליניארי וקטגורי על תכונת הקלט, ואחריו מכלול של דגמי סריג וכיול פלט אופציונלי חלקי-ליניארי.
אנסמבל סריג אקראי
תצורת המודל הבאה משתמשת בתת-קבוצה אקראית של תכונות עבור כל סריג.
# This is random lattice ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
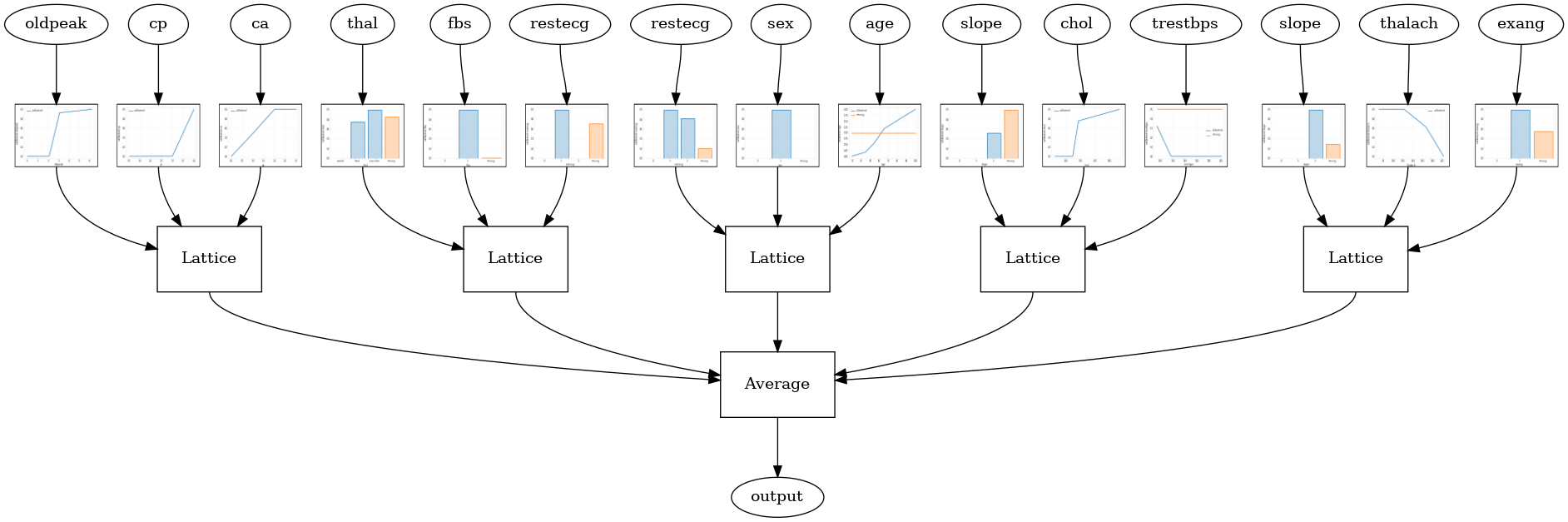
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.9003759026527405
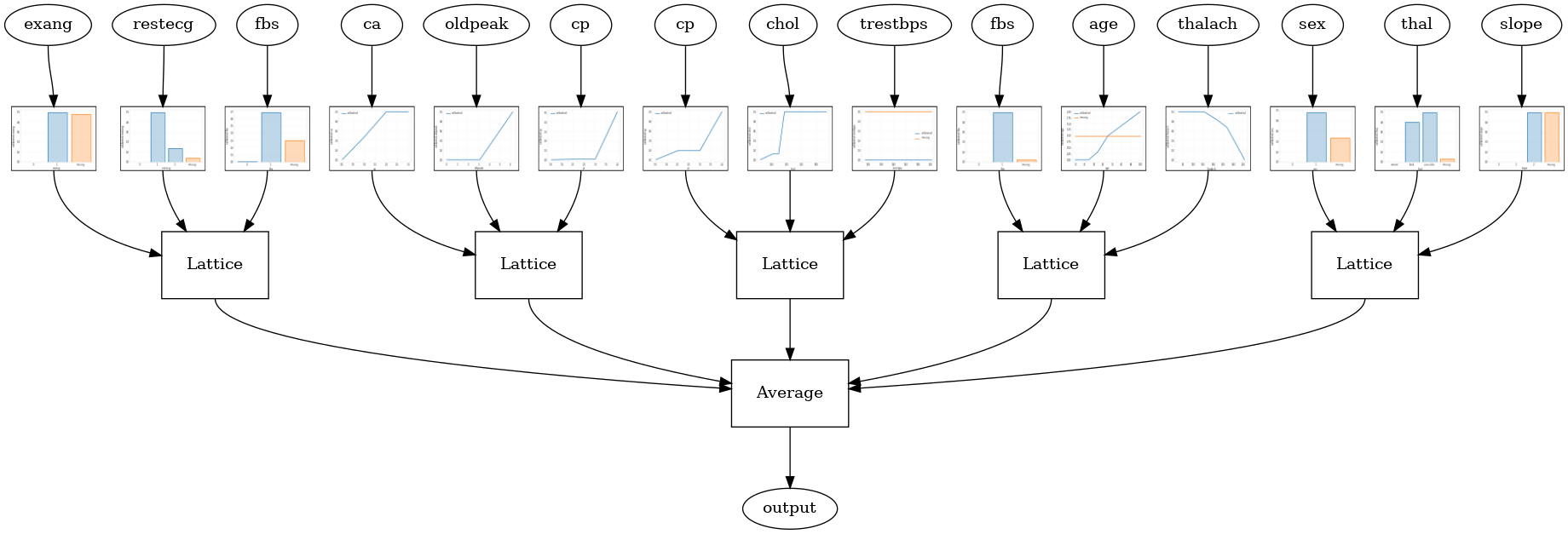
אנסמבל סריג אקראי של RTL Layer
את תצורת מודל הבאה משתמשת tfl.layers.RTL שכבת המשתמשת משנה אקראית של תכונות עבור כל סריג. נציין כי tfl.layers.RTL תומך רק אילוצים מונוטוניות ואת חייבת להיות באותו גודל סריג עבור כל התכונות לא הסדרת שידורי תכונה. שים לב ששימוש tfl.layers.RTL שכבה מאפשר לך סולם כדי רכבים הרבה יותר גדולים מאשר שימוש נפרד tfl.layers.Lattice מקרים.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is RTL layer ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
lattices='rtl_layer',
feature_configs=rtl_layer_feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.8903509378433228
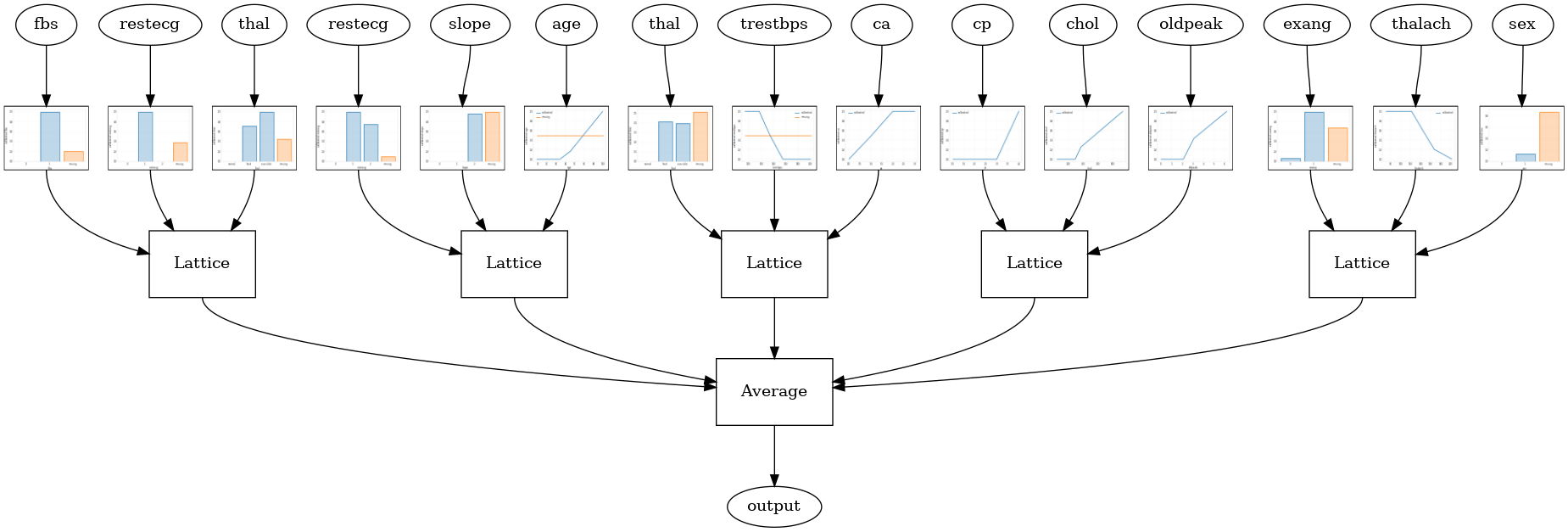
אנסמבל סריג קריסטלים
TFL מספק גם אלגוריתם סדר היוריסטית תכונה, שנקרא קריסטלים . ילדי קריסטל אלגוריתם רכבות ראשונות מודל prefitting שהערכות pairwise אינטראקציות תכונה. לאחר מכן הוא מסדר את ההרכב הסופי כך שתכונות עם יותר אינטראקציות לא ליניאריות נמצאות באותם סריג.
עבור דגמים קריסטלים, תצטרך גם לספק prefitting_input_fn המשמש לאמן את המודל prefitting, כפי שתואר לעיל. דגם ההתאמה המוקדם אינו צריך להיות מאומן באופן מלא, אז כמה עידנים אמורים להספיק.
prefitting_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=PREFITTING_NUM_EPOCHS,
num_threads=1)
לאחר מכן תוכל ליצור מודל קריסטל ידי קביעת lattice='crystals' ב config מודל.
# This is Crystals ensemble model with separate calibration: model output is
# the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
# prefitting_input_fn is required to train the prefitting model.
prefitting_input_fn=prefitting_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
prefitting_optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Crystals ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Crystals ensemble test AUC: 0.8840851783752441
אתה יכול לתכנן כייל תכונה ולקרוא פרטים נוספים באמצעות tfl.visualization מודול.
_ = tfl.visualization.plot_feature_calibrator(model_graph, "age")
_ = tfl.visualization.plot_feature_calibrator(model_graph, "restecg")

