
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
هذا البرنامج التعليمي هو نظرة عامة على القيود والمعوقات التي توفرها مكتبة TensorFlow Lattice (TFL). هنا نستخدم مقدرات TFL المعلبة في مجموعات البيانات التركيبية ، لكن لاحظ أن كل شيء في هذا البرنامج التعليمي يمكن أن يتم أيضًا باستخدام نماذج تم إنشاؤها من طبقات TFL Keras.
قبل المتابعة ، تأكد من تثبيت جميع الحزم المطلوبة في وقت التشغيل (كما تم استيرادها في خلايا التعليمات البرمجية أدناه).
يثبت
تثبيت حزمة TF Lattice:
pip install -q tensorflow-lattice
استيراد الحزم المطلوبة:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
القيم الافتراضية المستخدمة في هذا الدليل:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
مجموعة بيانات التدريب لتصنيف المطاعم
تخيل سيناريو مبسطًا حيث نريد تحديد ما إذا كان المستخدمون سينقرون على نتيجة بحث مطعم أم لا. تتمثل المهمة في توقع نسبة النقر إلى الظهور (CTR) في ضوء ميزات الإدخال:
- متوسط تقييم (
avg_rating): ميزة رقمية مع القيم في النطاق [1،5]. - عدد المشاركات (
num_reviews): ميزة رقمية مع القيم توج في 200، والتي نستخدمها كمقياس للالأناقة. - تصنيف الدولار (
dollar_rating): ميزة القاطع مع قيم السلسلة في مجموعة { "D"، "DD"، "DDD"، "DDDD"}.
نقوم هنا بإنشاء مجموعة بيانات تركيبية حيث يتم إعطاء نسبة النقر إلى الظهور الحقيقية بواسطة الصيغة:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
حيث \(b(\cdot)\) يترجم كل dollar_rating إلى قيمة أساسية:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
تعكس هذه الصيغة أنماط المستخدم النموذجية. على سبيل المثال ، نظرًا لإصلاح كل شيء آخر ، يفضل المستخدمون المطاعم ذات التقييمات الأعلى من حيث النجوم ، وستتلقى مطاعم "\ $ \ $" نقرات أكثر من "\ $" ، متبوعة بـ "\ $ \ $ \ $" و "\ $ \ $ \ $" \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
دعنا نلقي نظرة على المخططات الكنتورية لوظيفة نسبة النقر إلى الظهور هذه.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
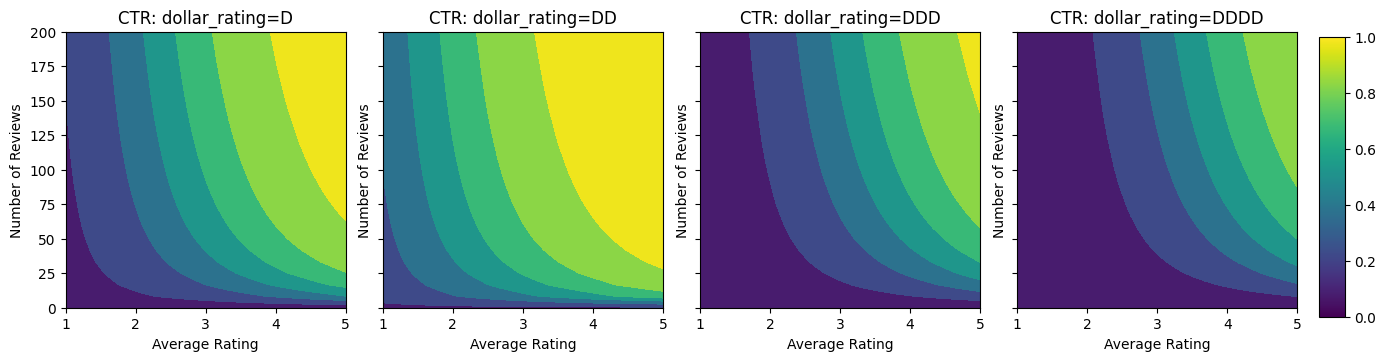
تحضير البيانات
نحن الآن بحاجة إلى إنشاء مجموعات البيانات الاصطناعية الخاصة بنا. نبدأ بإنشاء مجموعة بيانات محاكاة للمطاعم وخصائصها.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
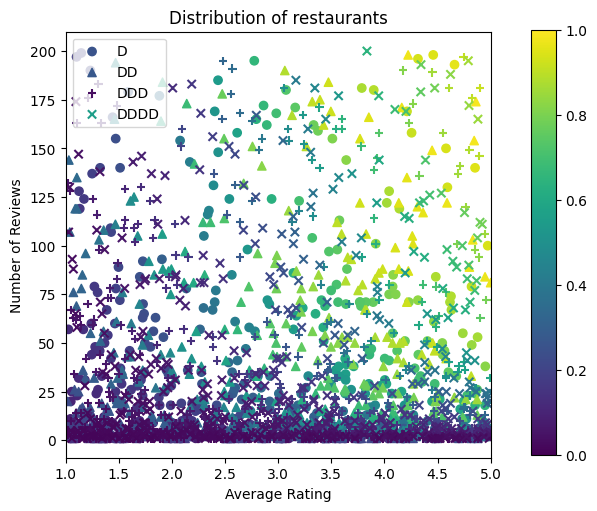
دعونا ننتج مجموعات بيانات التدريب والتحقق والاختبار. عندما يتم عرض مطعم في نتائج البحث ، يمكننا تسجيل تفاعل المستخدم (النقر أو عدم النقر) كنقطة عينة.
من الناحية العملية ، غالبًا لا يمر المستخدمون بجميع نتائج البحث. هذا يعني أنه من المحتمل أن يرى المستخدمون فقط المطاعم التي تعتبر "جيدة" بالفعل من خلال نموذج التصنيف الحالي المستخدم. نتيجة لذلك ، غالبًا ما تكون المطاعم "الجيدة" أكثر إعجابًا وتمثيلًا زائدًا في مجموعات بيانات التدريب. عند استخدام المزيد من الميزات ، يمكن أن تحتوي مجموعة بيانات التدريب على فجوات كبيرة في الأجزاء "السيئة" من مساحة الميزة.
عند استخدام النموذج للترتيب ، غالبًا ما يتم تقييمه بناءً على جميع النتائج ذات الصلة بتوزيع أكثر اتساقًا لا يتم تمثيله جيدًا بواسطة مجموعة بيانات التدريب. قد يفشل نموذج مرن ومعقد في هذه الحالة بسبب الإفراط في تجهيز نقاط البيانات الممثلة بشكل مفرط وبالتالي يفتقر إلى التعميم. علينا التعامل مع هذه المشكلة عن طريق تطبيق المعرفة مجال لإضافة قيود الشكل الذي توجيه النموذج لتقديم تنبؤات معقولة عندما لا يمكن اعتقالهما من مجموعة البيانات التدريب.
في هذا المثال ، تتكون مجموعة بيانات التدريب في الغالب من تفاعلات المستخدم مع المطاعم الجيدة والشائعة. تحتوي مجموعة بيانات الاختبار على توزيع موحد لمحاكاة إعداد التقييم الذي تمت مناقشته أعلاه. لاحظ أن مجموعة بيانات الاختبار هذه لن تكون متاحة في إعدادات المشكلة الحقيقية.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

تحديد المدخلات المستخدمة للتدريب والتقييم:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
تركيب الأشجار المتدرجة
لنبدأ مع ميزات اثنين فقط: avg_rating و num_reviews .
نقوم بإنشاء بعض الوظائف المساعدة للتخطيط وحساب مقاييس التحقق من الصحة والاختبار.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
يمكننا ملاءمة أشجار القرار المعزز بالتدرج اللوني TensorFlow في مجموعة البيانات:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

على الرغم من أن النموذج قد التقط الشكل العام لنسبة النقر إلى الظهور الحقيقية ولديه مقاييس تحقق جيدة ، إلا أنه يحتوي على سلوك غير بديهي في عدة أجزاء من مساحة الإدخال: تنخفض نسبة النقر إلى الظهور المقدرة مع زيادة متوسط التقييم أو عدد المراجعات. ويرجع ذلك إلى نقص نقاط العينة في المناطق التي لا تغطيها مجموعة بيانات التدريب جيدًا. النموذج ببساطة ليس لديه طريقة لاستنتاج السلوك الصحيح فقط من البيانات.
لحل هذه المشكلة ، نفرض قيود الشكل على أن النموذج يجب أن ينتج قيمًا متزايدة بشكل رتيب فيما يتعلق بكل من متوسط التقييم وعدد المراجعات. سنرى لاحقًا كيفية تنفيذ ذلك في TFL.
تركيب DNN
يمكننا تكرار نفس الخطوات مع مصنف DNN. يمكننا أن نلاحظ نمطًا مشابهًا: عدم وجود نقاط عينة كافية مع عدد قليل من المراجعات يؤدي إلى استقراء غير منطقي. لاحظ أنه على الرغم من أن مقياس التحقق أفضل من حل الشجرة ، إلا أن مقياس الاختبار أسوأ بكثير.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

قيود الشكل
تركز TensorFlow Lattice (TFL) على فرض قيود الشكل لحماية سلوك النموذج خارج بيانات التدريب. يتم تطبيق قيود الشكل هذه على طبقات TFL Keras. التفاصيل الخاصة بهم يمكن العثور عليها في ورقة JMLR لدينا .
في هذا البرنامج التعليمي ، نستخدم مقدرات TF المعلبة لتغطية قيود الأشكال المختلفة ، لكن لاحظ أنه يمكن تنفيذ كل هذه الخطوات باستخدام النماذج التي تم إنشاؤها من طبقات TFL Keras.
كما هو الحال مع أي مقدر TensorFlow الآخرين، المعلبة TFL المقدرات استخدام الأعمدة ميزة لتحديد صيغة إدخال واستخدام input_fn التدريب لتمرير في البيانات. يتطلب استخدام مقدرات TFL المعلبة أيضًا:
- والتكوين نموذج: تحديد بنية نموذجية ولكل ميزة قيود الشكل وregularizers.
- وinput_fn تحليل اخبارى: لTF input_fn تمرير البيانات لTFL التهيئة.
للحصول على وصف أكثر شمولاً ، يرجى الرجوع إلى البرنامج التعليمي للمقدرات المعلب أو مستندات API.
رتابة
نعالج أولاً مخاوف الرتابة عن طريق إضافة قيود الشكل الرتيبة إلى كلتا الميزتين.
لإرشاد TFL لفرض قيود الشكل، فإننا تحديد المعوقات في التكوينات الميزة. يظهر البرمجية التالية كيف يمكننا تتطلب أن يكون الناتج زيادة monotonically فيما يتعلق بكل من num_reviews و avg_rating عن طريق وضع monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
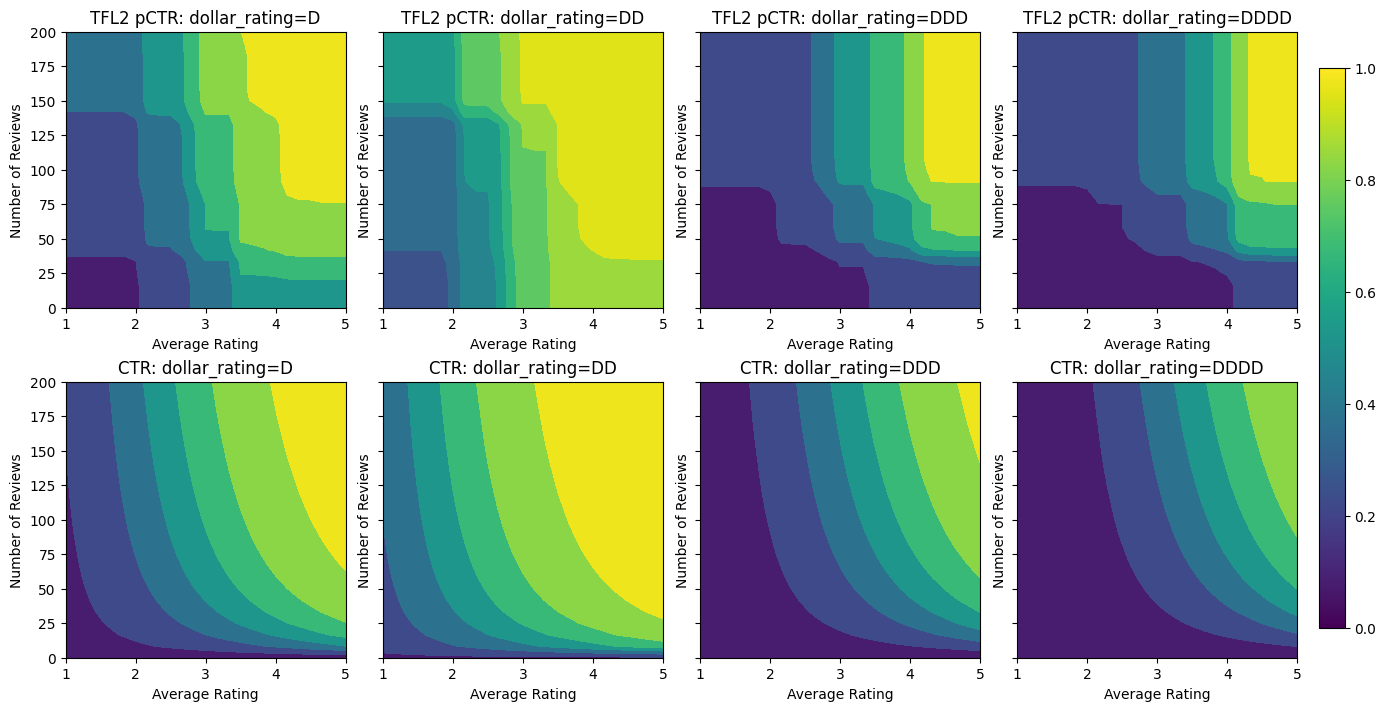
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

باستخدام CalibratedLatticeConfig يخلق المصنف المعلبة التي تطبق لأول مرة تدريج لكل المدخلات (قطعة من الحكمة دالة خطية لميزات رقمية) تليها طبقة شعرية لغير خطيا فتيل الميزات معايرة. يمكننا استخدام tfl.visualization لتصور نموذج. على وجه الخصوص ، تُظهر المؤامرة التالية جهازَي المعايرة المدربين المتضمنين في المصنف المعلب.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

مع القيود المضافة ، ستزداد نسبة النقر إلى الظهور المقدرة دائمًا مع زيادة متوسط التقييم أو زيادة عدد المراجعات. يتم ذلك عن طريق التأكد من أن أجهزة المعايرة والشبكة رتيبة.
تناقص العوائد
تناقص الغلة يعني أن ارتفاعا هامشيا زيادة قيمة ميزة معينة ستنخفض ونحن زيادة قيمة. في حالتنا نحن نتوقع أن num_reviews ميزة تتبع هذا النمط، حتى نتمكن من تكوين تدريج وفقا لذلك. لاحظ أنه يمكننا تحليل العوائد المتناقصة إلى شرطين كافيين:
- المعاير يتزايد بشكل رتيب ، و
- المعاير مقعر.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
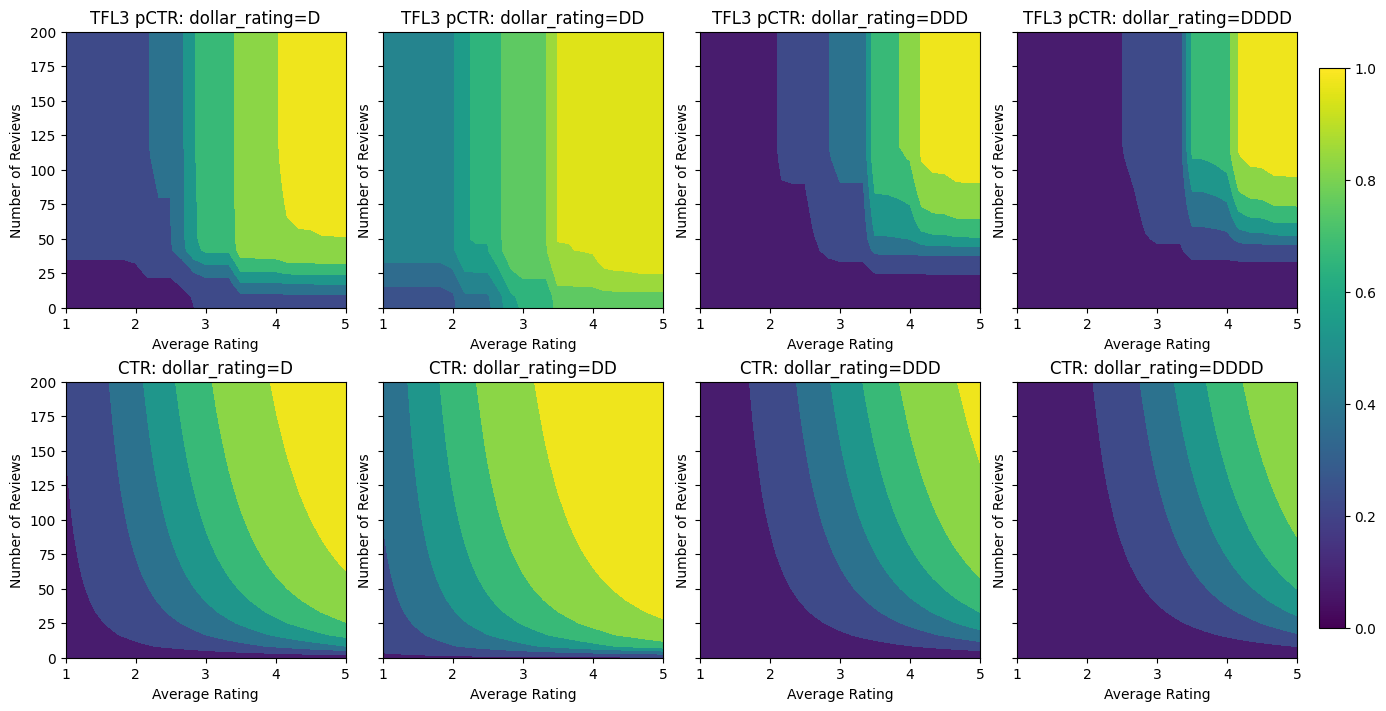

لاحظ كيف يتحسن مقياس الاختبار عن طريق إضافة قيد التقعر. حبكة التنبؤ تشبه بشكل أفضل الحقيقة الأساسية.
2D الشكل القيد: الثقة
تقييم 5 نجوم لمطعم مع مراجعة واحدة أو اثنتين فقط من المحتمل أن يكون تقييمًا غير موثوق به (قد لا يكون المطعم جيدًا في الواقع) ، في حين أن تصنيف 4 نجوم لمطعم مع مئات التعليقات يكون أكثر موثوقية (المطعم هو من المحتمل أن تكون جيدة في هذه الحالة). يمكننا أن نرى أن عدد التعليقات الخاصة بمطعم ما يؤثر على مقدار الثقة التي نضعها في متوسط تقييمه.
يمكننا ممارسة قيود الثقة TFL لإبلاغ النموذج بأن القيمة الأكبر (أو الأصغر) لميزة واحدة تشير إلى مزيد من الاعتماد أو الثقة بميزة أخرى. ويتم ذلك عن طريق وضع reflects_trust_in التكوين في التكوين الميزة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

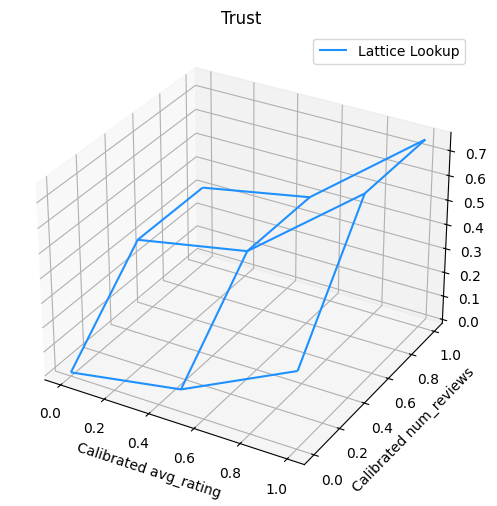
يعرض المخطط التالي وظيفة الشبكة المدربة. بسبب القيد الثقة، فإننا نتوقع أن القيم أكبر من معايرة num_reviews ستجبر أعلى المنحدر فيما يتعلق معايرة avg_rating ، مما أدى إلى تحرك أكثر أهمية في إخراج شعرية.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
تنعيم المعايرات
دعونا الآن نلقي نظرة على تدريج من avg_rating . على الرغم من أنه يتزايد بشكل رتيب ، إلا أن التغييرات في منحدراته مفاجئة ويصعب تفسيرها. التي تشير إلى أننا قد ترغب في النظر في تمهيد هذا تدريج باستخدام الإعداد regularizer في regularizer_configs .
نحن هنا تطبيق wrinkle regularizer للحد من التغيرات في انحناء. يمكنك أيضا استخدام laplacian regularizer لشد تدريج و hessian regularizer لجعله أكثر الخطية.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


أصبحت أدوات المعايرة الآن سلسة ، ونسبة النقر إلى الظهور المقدرة الإجمالية تتطابق بشكل أفضل مع الحقيقة الأساسية. ينعكس هذا في كل من مقياس الاختبار وفي المؤامرات الكنتورية.
الرتابة الجزئية للمعايرة الفئوية
حتى الآن كنا نستخدم ميزتين فقط من السمات الرقمية في النموذج. سنضيف هنا ميزة ثالثة باستخدام طبقة معايرة فئوية. مرة أخرى نبدأ بإعداد الدالات المساعدة للتخطيط والحساب المتري.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
إشراك السمة الثالثة، dollar_rating ، يجب أن نذكر أن ملامح القاطع تتطلب معالجة مختلفة قليلا في TFL، على حد سواء باعتبارها العمود ميزة وكما التكوين الميزة. نحن هنا نفرض قيود الرتابة الجزئية التي يجب أن تكون مخرجات مطاعم "DD" أكبر من مطاعم "D" عندما يتم إصلاح جميع المدخلات الأخرى. ويتم ذلك باستخدام monotonicity الإعداد في التكوين الميزة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


يُظهر جهاز المعايرة الفئوية هذا تفضيل إخراج النموذج: DD> D> DDD> DDDD ، وهو ما يتوافق مع إعدادنا. لاحظ أن هناك أيضًا عمودًا للقيم المفقودة. على الرغم من عدم وجود ميزة مفقودة في بيانات التدريب والاختبار الخاصة بنا ، إلا أن النموذج يوفر لنا احتسابًا للقيمة المفقودة في حالة حدوثها أثناء تقديم نموذج المصب.
هنا أيضا يمكننا رسم الظهور المتوقعة لهذا النموذج مشروطا dollar_rating . لاحظ أنه تم استيفاء جميع القيود التي طلبناها في كل شريحة.
معايرة الخرج
بالنسبة لجميع نماذج TFL التي دربناها حتى الآن ، تقوم الطبقة الشبكية (المشار إليها باسم "الشبكة" في الرسم البياني للنموذج) بإخراج تنبؤ النموذج مباشرةً. في بعض الأحيان لا نكون متأكدين مما إذا كان يجب إعادة قياس إخراج الشبكة لإصدار مخرجات النموذج:
- الميزات هي \(log\) التهم في حين أن التسميات هي التهم الموجهة إليه.
- تم تكوين الشبكة بحيث تحتوي على عدد قليل جدًا من الرؤوس ولكن توزيع الملصق معقد نسبيًا.
في هذه الحالات ، يمكننا إضافة معاير آخر بين خرج الشبكة وإخراج النموذج لزيادة مرونة النموذج. دعنا هنا نضيف طبقة معايرة بها 5 نقاط رئيسية إلى النموذج الذي أنشأناه للتو. نضيف أيضًا منظمًا لمعاير الإخراج للحفاظ على سلاسة الوظيفة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


يوضح مقياس الاختبار النهائي والمخططات كيف يمكن أن يساعد استخدام قيود الفطرة السليمة النموذج على تجنب السلوك غير المتوقع والاستقراء بشكل أفضل لمساحة الإدخال بالكامل.
و| | | عرض المصدر على جيثب | |
ملخص
هذا البرنامج التعليمي هو نظرة عامة على القيود والمعوقات التي توفرها مكتبة TensorFlow Lattice (TFL). هنا نستخدم مقدرات TFL المعلبة في مجموعات البيانات التركيبية ، لكن لاحظ أن كل شيء في هذا البرنامج التعليمي يمكن أن يتم أيضًا باستخدام نماذج تم إنشاؤها من طبقات TFL Keras.
قبل المتابعة ، تأكد من تثبيت جميع الحزم المطلوبة في وقت التشغيل (كما تم استيرادها في خلايا التعليمات البرمجية أدناه).
يثبت
تثبيت حزمة TF Lattice:
pip install -q tensorflow-lattice
استيراد الحزم المطلوبة:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
القيم الافتراضية المستخدمة في هذا الدليل:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
مجموعة بيانات التدريب لتصنيف المطاعم
تخيل سيناريو مبسطًا حيث نريد تحديد ما إذا كان المستخدمون سينقرون على نتيجة بحث مطعم أم لا. تتمثل المهمة في توقع نسبة النقر إلى الظهور (CTR) في ضوء ميزات الإدخال:
- متوسط تقييم (
avg_rating): ميزة رقمية مع القيم في النطاق [1،5]. - عدد المشاركات (
num_reviews): ميزة رقمية مع القيم توج في 200، والتي نستخدمها كمقياس للالأناقة. - تصنيف الدولار (
dollar_rating): ميزة القاطع مع قيم السلسلة في مجموعة { "D"، "DD"، "DDD"، "DDDD"}.
نقوم هنا بإنشاء مجموعة بيانات تركيبية حيث يتم إعطاء نسبة النقر إلى الظهور الحقيقية بواسطة الصيغة:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
حيث \(b(\cdot)\) يترجم كل dollar_rating إلى قيمة أساسية:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
تعكس هذه الصيغة أنماط المستخدم النموذجية. على سبيل المثال ، نظرًا لإصلاح كل شيء آخر ، يفضل المستخدمون المطاعم ذات التقييمات الأعلى من حيث النجوم ، وستتلقى مطاعم "\ $ \ $" نقرات أكثر من "\ $" ، متبوعة بـ "\ $ \ $ \ $" و "\ $ \ $ \ $" \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
دعنا نلقي نظرة على المخططات الكنتورية لوظيفة نسبة النقر إلى الظهور هذه.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
تحضير البيانات
نحن الآن بحاجة إلى إنشاء مجموعات البيانات الاصطناعية الخاصة بنا. نبدأ بإنشاء مجموعة بيانات محاكاة للمطاعم وخصائصها.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
دعونا ننتج مجموعات بيانات التدريب والتحقق والاختبار. عندما يتم عرض مطعم في نتائج البحث ، يمكننا تسجيل تفاعل المستخدم (النقر أو عدم النقر) كنقطة عينة.
من الناحية العملية ، غالبًا لا يمر المستخدمون بجميع نتائج البحث. هذا يعني أنه من المحتمل أن يرى المستخدمون فقط المطاعم التي تعتبر "جيدة" بالفعل من خلال نموذج التصنيف الحالي المستخدم. نتيجة لذلك ، غالبًا ما تكون المطاعم "الجيدة" أكثر إعجابًا وتمثيلًا زائدًا في مجموعات بيانات التدريب. عند استخدام المزيد من الميزات ، يمكن أن تحتوي مجموعة بيانات التدريب على فجوات كبيرة في الأجزاء "السيئة" من مساحة الميزة.
عند استخدام النموذج للترتيب ، غالبًا ما يتم تقييمه بناءً على جميع النتائج ذات الصلة بتوزيع أكثر اتساقًا لا يتم تمثيله جيدًا بواسطة مجموعة بيانات التدريب. قد يفشل نموذج مرن ومعقد في هذه الحالة بسبب الإفراط في تجهيز نقاط البيانات الممثلة بشكل مفرط وبالتالي يفتقر إلى التعميم. علينا التعامل مع هذه المشكلة عن طريق تطبيق المعرفة مجال لإضافة قيود الشكل الذي توجيه النموذج لتقديم تنبؤات معقولة عندما لا يمكن اعتقالهما من مجموعة البيانات التدريب.
في هذا المثال ، تتكون مجموعة بيانات التدريب في الغالب من تفاعلات المستخدم مع المطاعم الجيدة والشائعة. تحتوي مجموعة بيانات الاختبار على توزيع موحد لمحاكاة إعداد التقييم الذي تمت مناقشته أعلاه. لاحظ أن مجموعة بيانات الاختبار هذه لن تكون متاحة في إعدادات المشكلة الحقيقية.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
تحديد المدخلات المستخدمة للتدريب والتقييم:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
تركيب الأشجار المتدرجة
لنبدأ مع ميزات اثنين فقط: avg_rating و num_reviews .
نقوم بإنشاء بعض الوظائف المساعدة للتخطيط وحساب مقاييس التحقق من الصحة والاختبار.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
يمكننا ملاءمة أشجار القرار المعزز بالتدرج اللوني TensorFlow في مجموعة البيانات:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
على الرغم من أن النموذج قد التقط الشكل العام لنسبة النقر إلى الظهور الحقيقية ولديه مقاييس تحقق جيدة ، إلا أنه يحتوي على سلوك غير بديهي في عدة أجزاء من مساحة الإدخال: تنخفض نسبة النقر إلى الظهور المقدرة مع زيادة متوسط التقييم أو عدد المراجعات. ويرجع ذلك إلى نقص نقاط العينة في المناطق التي لا تغطيها مجموعة بيانات التدريب جيدًا. النموذج ببساطة ليس لديه طريقة لاستنتاج السلوك الصحيح فقط من البيانات.
لحل هذه المشكلة ، نفرض قيود الشكل على أن النموذج يجب أن ينتج قيمًا متزايدة بشكل رتيب فيما يتعلق بكل من متوسط التقييم وعدد المراجعات. سنرى لاحقًا كيفية تنفيذ ذلك في TFL.
تركيب DNN
يمكننا تكرار نفس الخطوات مع مصنف DNN. يمكننا أن نلاحظ نمطًا مشابهًا: عدم وجود نقاط عينة كافية مع عدد قليل من المراجعات يؤدي إلى استقراء غير منطقي. لاحظ أنه على الرغم من أن مقياس التحقق أفضل من حل الشجرة ، إلا أن مقياس الاختبار أسوأ بكثير.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
قيود الشكل
تركز TensorFlow Lattice (TFL) على فرض قيود الشكل لحماية سلوك النموذج خارج بيانات التدريب. يتم تطبيق قيود الشكل هذه على طبقات TFL Keras. التفاصيل الخاصة بهم يمكن العثور عليها في ورقة JMLR لدينا .
في هذا البرنامج التعليمي ، نستخدم مقدرات TF المعلبة لتغطية قيود الأشكال المختلفة ، لكن لاحظ أنه يمكن تنفيذ كل هذه الخطوات باستخدام النماذج التي تم إنشاؤها من طبقات TFL Keras.
كما هو الحال مع أي مقدر TensorFlow الآخرين، المعلبة TFL المقدرات استخدام الأعمدة ميزة لتحديد صيغة إدخال واستخدام input_fn التدريب لتمرير في البيانات. يتطلب استخدام مقدرات TFL المعلبة أيضًا:
- والتكوين نموذج: تحديد بنية نموذجية ولكل ميزة قيود الشكل وregularizers.
- وinput_fn تحليل اخبارى: لTF input_fn تمرير البيانات لTFL التهيئة.
للحصول على وصف أكثر شمولاً ، يرجى الرجوع إلى البرنامج التعليمي للمقدرات المعلب أو مستندات API.
رتابة
نعالج أولاً مخاوف الرتابة عن طريق إضافة قيود الشكل الرتيبة إلى كلتا الميزتين.
لإرشاد TFL لفرض قيود الشكل، فإننا تحديد المعوقات في التكوينات الميزة. يظهر البرمجية التالية كيف يمكننا تتطلب أن يكون الناتج زيادة monotonically فيما يتعلق بكل من num_reviews و avg_rating عن طريق وضع monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
باستخدام CalibratedLatticeConfig يخلق المصنف المعلبة التي تطبق لأول مرة تدريج لكل المدخلات (قطعة من الحكمة دالة خطية لميزات رقمية) تليها طبقة شعرية لغير خطيا فتيل الميزات معايرة. يمكننا استخدام tfl.visualization لتصور نموذج. على وجه الخصوص ، تُظهر المؤامرة التالية جهازَي المعايرة المدربين المتضمنين في المصنف المعلب.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
مع القيود المضافة ، ستزداد نسبة النقر إلى الظهور المقدرة دائمًا مع زيادة متوسط التقييم أو زيادة عدد المراجعات. يتم ذلك عن طريق التأكد من أن أجهزة المعايرة والشبكة رتيبة.
تناقص العوائد
تناقص الغلة يعني أن ارتفاعا هامشيا زيادة قيمة ميزة معينة ستنخفض ونحن زيادة قيمة. في حالتنا نحن نتوقع أن num_reviews ميزة تتبع هذا النمط، حتى نتمكن من تكوين تدريج وفقا لذلك. لاحظ أنه يمكننا تحليل العوائد المتناقصة إلى شرطين كافيين:
- المعاير يتزايد بشكل رتيب ، و
- المعاير مقعر.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
لاحظ كيف يتحسن مقياس الاختبار عن طريق إضافة قيد التقعر. حبكة التنبؤ تشبه بشكل أفضل الحقيقة الأساسية.
2D الشكل القيد: الثقة
تقييم 5 نجوم لمطعم مع مراجعة واحدة أو اثنتين فقط من المحتمل أن يكون تقييمًا غير موثوق به (قد لا يكون المطعم جيدًا في الواقع) ، في حين أن تصنيف 4 نجوم لمطعم مع مئات التعليقات يكون أكثر موثوقية (المطعم هو من المحتمل أن تكون جيدة في هذه الحالة). يمكننا أن نرى أن عدد التعليقات الخاصة بمطعم ما يؤثر على مقدار الثقة التي نضعها في متوسط تقييمه.
يمكننا ممارسة قيود الثقة TFL لإبلاغ النموذج بأن القيمة الأكبر (أو الأصغر) لميزة واحدة تشير إلى مزيد من الاعتماد أو الثقة بميزة أخرى. ويتم ذلك عن طريق وضع reflects_trust_in التكوين في التكوين الميزة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
يعرض المخطط التالي وظيفة الشبكة المدربة. بسبب القيد الثقة، فإننا نتوقع أن القيم أكبر من معايرة num_reviews ستجبر أعلى المنحدر فيما يتعلق معايرة avg_rating ، مما أدى إلى تحرك أكثر أهمية في إخراج شعرية.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
تنعيم المعايرات
دعونا الآن نلقي نظرة على تدريج من avg_rating . على الرغم من أنه يتزايد بشكل رتيب ، إلا أن التغييرات في منحدراته مفاجئة ويصعب تفسيرها. التي تشير إلى أننا قد ترغب في النظر في تمهيد هذا تدريج باستخدام الإعداد regularizer في regularizer_configs .
نحن هنا تطبيق wrinkle regularizer للحد من التغيرات في انحناء. يمكنك أيضا استخدام laplacian regularizer لشد تدريج و hessian regularizer لجعله أكثر الخطية.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
أصبحت أدوات المعايرة الآن سلسة ، ونسبة النقر إلى الظهور المقدرة الإجمالية تتطابق بشكل أفضل مع الحقيقة الأساسية. ينعكس هذا في كل من مقياس الاختبار وفي المؤامرات الكنتورية.
الرتابة الجزئية للمعايرة الفئوية
حتى الآن كنا نستخدم ميزتين فقط من السمات الرقمية في النموذج. سنضيف هنا ميزة ثالثة باستخدام طبقة معايرة فئوية. مرة أخرى نبدأ بإعداد الدالات المساعدة للتخطيط والحساب المتري.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
إشراك السمة الثالثة، dollar_rating ، يجب أن نذكر أن ملامح القاطع تتطلب معالجة مختلفة قليلا في TFL، على حد سواء باعتبارها العمود ميزة وكما التكوين الميزة. نحن هنا نفرض قيود الرتابة الجزئية التي يجب أن تكون مخرجات مطاعم "DD" أكبر من مطاعم "D" عندما يتم إصلاح جميع المدخلات الأخرى. ويتم ذلك باستخدام monotonicity الإعداد في التكوين الميزة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
يُظهر جهاز المعايرة الفئوية هذا تفضيل إخراج النموذج: DD> D> DDD> DDDD ، وهو ما يتوافق مع إعدادنا. لاحظ أن هناك أيضًا عمودًا للقيم المفقودة. على الرغم من عدم وجود ميزة مفقودة في بيانات التدريب والاختبار الخاصة بنا ، إلا أن النموذج يوفر لنا احتسابًا للقيمة المفقودة في حالة حدوثها أثناء تقديم نموذج المصب.
هنا أيضا يمكننا رسم الظهور المتوقعة لهذا النموذج مشروطا dollar_rating . لاحظ أنه تم استيفاء جميع القيود التي طلبناها في كل شريحة.
معايرة الخرج
بالنسبة لجميع نماذج TFL التي دربناها حتى الآن ، تقوم الطبقة الشبكية (المشار إليها باسم "الشبكة" في الرسم البياني للنموذج) بإخراج تنبؤ النموذج مباشرةً. في بعض الأحيان لا نكون متأكدين مما إذا كان يجب إعادة قياس إخراج الشبكة لإصدار مخرجات النموذج:
- الميزات هي \(log\) التهم في حين أن التسميات هي التهم الموجهة إليه.
- تم تكوين الشبكة بحيث تحتوي على عدد قليل جدًا من الرؤوس ولكن توزيع الملصق معقد نسبيًا.
في هذه الحالات ، يمكننا إضافة معاير آخر بين خرج الشبكة وإخراج النموذج لزيادة مرونة النموذج. دعنا هنا نضيف طبقة معايرة بها 5 نقاط رئيسية إلى النموذج الذي أنشأناه للتو. نضيف أيضًا منظمًا لمعاير الإخراج للحفاظ على سلاسة الوظيفة.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
يوضح مقياس الاختبار النهائي والمخططات كيف يمكن أن يساعد استخدام قيود الفطرة السليمة النموذج على تجنب السلوك غير المتوقع والاستقراء بشكل أفضل لمساحة الإدخال بالكامل.