
מטא נתונים של TensorFlow Lite מספקים תקן לתיאורי מודלים. המטא נתונים הם מקור חשוב לידע על מה שהמודל עושה ומידע הקלט/פלט שלו. המטא נתונים מורכבים משניהם
- חלקים קריא אנושיים אשר מעבירים את השיטות הטובות ביותר בעת השימוש במודל, וכן
- חלקים קריאים במכונה שניתן למנף אותם על ידי מחוללי קוד, כגון מחולל הקוד של TensorFlow Lite Android ותכונת Android Studio ML Binding .
כל דגמי התמונות שפורסמו ב- TensorFlow Hub אוכלסו במטא נתונים.
מודל עם פורמט מטא נתונים
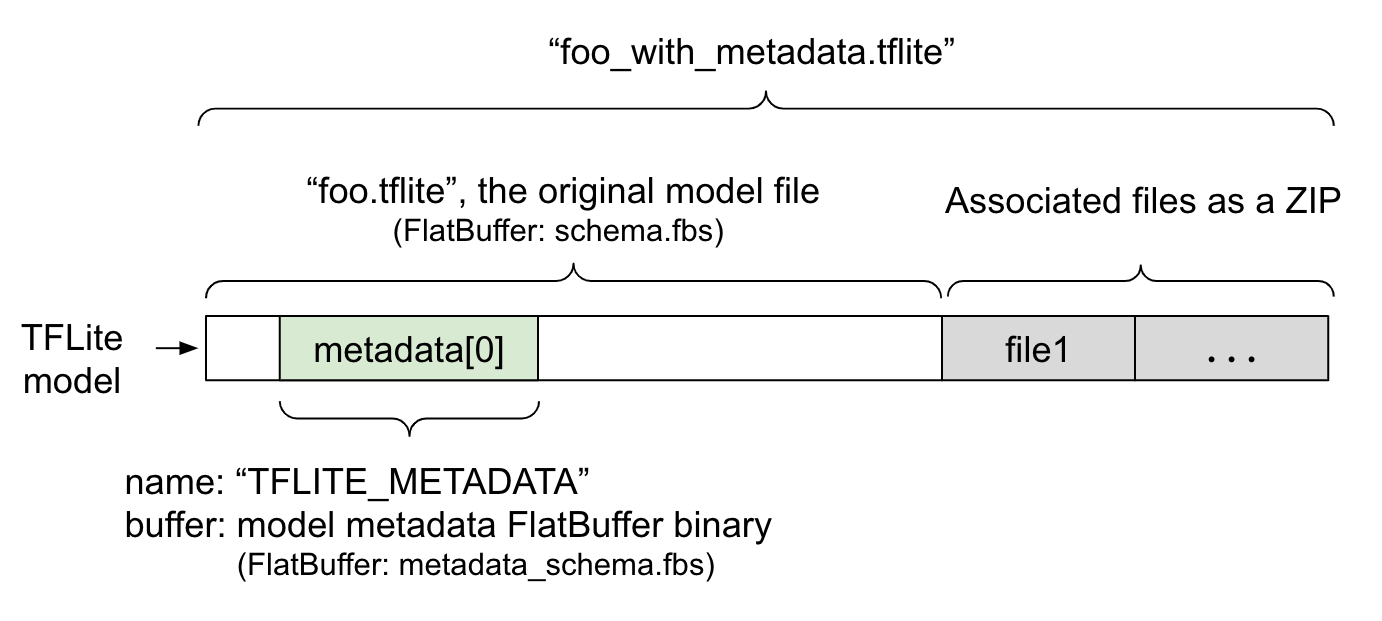
מטא נתונים של מודל מוגדרים ב- metadata_schema.fbs , קובץ FlatBuffer . כפי שמוצג באיור 1, הוא מאוחסן בשדה המטא נתונים של סכימת המודל TFLite , תחת השם, "TFLITE_METADATA" . דגמים מסוימים עשויים להגיע עם קבצים משויכים, כגון קבצי תוויות סיווג . קבצים אלה משורשרים לסוף קובץ הדגם המקורי כ-ZIP באמצעות מצב "הוסף" של ZipFile (מצב 'a' ). TFLite Interpreter יכול לצרוך את פורמט הקובץ החדש באותו אופן כמו קודם. ראה אריזת הקבצים המשויכים למידע נוסף.
ראה את ההוראה שלהלן כיצד לאכלס, להמחיש ולקרוא מטא נתונים.
הגדר את כלי המטא נתונים
לפני הוספת מטא נתונים למודל שלך, תצטרך להגדיר סביבת תכנות Python להפעלת TensorFlow. יש מדריך מפורט כיצד להגדיר זאת כאן .
לאחר הגדרת סביבת התכנות Python, תצטרך להתקין כלי עבודה נוספים:
pip install tflite-support
כלי מטא נתונים של TensorFlow Lite תומך ב- Python 3.
הוספת מטא נתונים באמצעות Flatbuffers Python API
ישנם שלושה חלקים למטא נתונים של המודל בסכימה :
- מידע על הדגם - תיאור כולל של הדגם וכן פריטים כגון תנאי רישיון. ראה ModelMetadata .
- מידע קלט - תיאור התשומות והעיבוד המקדים הנדרש כגון נורמליזציה. ראה SubGraphMetadata.input_tensor_metadata .
- מידע פלט - תיאור הפלט והעיבוד לאחר הנדרש כגון מיפוי לתוויות. ראה SubGraphMetadata.output_tensor_metadata .
מכיוון ש-TensorFlow Lite תומך רק בתת-גרף בודד בשלב זה, מחולל הקוד של TensorFlow Lite ותכונת Android Studio ML Binding ישתמשו ב- ModelMetadata.name ו- ModelMetadata.description , במקום SubGraphMetadata.name ו- SubGraphMetadata.description , בעת הצגת מטא נתונים ויצירת קוד.
סוגי קלט/פלט נתמכים
מטא-נתונים של TensorFlow Lite עבור קלט ופלט אינם מתוכננים עם סוגי מודלים ספציפיים בחשבון אלא סוגי קלט ופלט. זה לא משנה מה המודל עושה מבחינה פונקציונלית, כל עוד סוגי הקלט והפלט מורכבים מהדברים הבאים או שילוב של הדברים הבאים, הוא נתמך על ידי מטא נתונים של TensorFlow Lite:
- תכונה - מספרים שהם מספרים שלמים ללא סימן או צפים32.
- תמונה - מטא נתונים תומכים כעת בתמונות RGB ובגווני אפור.
- תיבה תוחמת - תיבות תוחמות בצורה מלבנית. הסכימה תומכת במגוון סכימות מספור .
ארוז את הקבצים המשויכים
דגמי TensorFlow Lite עשויים להגיע עם קבצים משויכים שונים. לדוגמה, למודלים של שפה טבעית יש בדרך כלל קבצי ווקאב הממפים חלקי מילים למזהי מילים; מודלים לסיווג עשויים לכלול קובצי תוויות המציינים קטגוריות אובייקטים. ללא הקבצים המשויכים (אם יש), מודל לא יתפקד היטב.
כעת ניתן לאגד את הקבצים המשויכים למודל דרך ספריית המטא נתונים Python. הדגם החדש של TensorFlow Lite הופך לקובץ zip המכיל גם את הדגם וגם את הקבצים המשויכים. ניתן לפרוק אותו עם כלי zip נפוצים. פורמט הדגם החדש הזה ממשיך להשתמש באותה סיומת קובץ, .tflite . זה תואם למסגרת TFLite ולפרשן הקיימים. ראה ארוז מטא נתונים וקבצים משויכים למודל לפרטים נוספים.
ניתן לתעד את פרטי הקובץ המשויכים במטא נתונים. בהתאם לסוג הקובץ ולאן מצורף הקובץ (כלומר ModelMetadata , SubGraphMetadata ו- TensorMetadata ), מחולל הקוד של TensorFlow Lite Android עשוי להחיל עיבוד מקדים/אחרי באופן אוטומטי על האובייקט. עיין בסעיף <Codegen usage> של כל סוג קובץ משויך בסכימה לפרטים נוספים.
פרמטרי נורמליזציה וקונטיזציה
נורמליזציה היא טכניקת עיבוד מקדים של נתונים בלמידת מכונה. מטרת הנורמליזציה היא לשנות את הערכים לסולם משותף, מבלי לעוות הבדלים בטווחי הערכים.
קוונטיזציה של מודלים היא טכניקה המאפשרת ייצוגי דיוק מופחתים של משקלים ובאופן אופציונלי, הפעלות הן לאחסון והן לחישוב.
במונחים של עיבוד מקדים ואחרי עיבוד, נורמליזציה וקונטיזציה הם שני שלבים עצמאיים. הנה הפרטים.
| נוֹרמָלִיזָצִיָה | כימות | |
|---|---|---|
דוגמה לערכי הפרמטרים של תמונת הקלט ב-MobileNet עבור מודלים צפים וכמותיים, בהתאמה. | דגם צף : - ממוצע: 127.5 - תקן: 127.5 דגם כמותי : - ממוצע: 127.5 - תקן: 127.5 | דגם צף : - נקודת אפס: 0 - קנה מידה: 1.0 דגם כמותי : - נקודת אפס: 128.0 - קנה מידה: 0.0078125f |
מתי להפעיל? | תשומות : אם נתוני הקלט מנורמלים באימון, יש לנרמל את נתוני הקלט של ההסקה בהתאם. פלטים : נתוני פלט לא ינורמלו באופן כללי. | מודלים צפים אינם זקוקים לכימות. מודל קוונטי עשוי להזדקק לכימות בעיבוד טרום/אחרי ואולי לא. זה תלוי בסוג הנתונים של טנסור הקלט/פלט. - טנסורים צפים: אין צורך בכימות בעיבוד לפני/אחרי. Quant op ו-dequant op אפויים בגרף המודל. - טנסורים int8/uint8: צריך קוונטיזציה בעיבוד קדם/אחרי. |
נוּסחָה | normalized_input = (קלט - ממוצע) / std | לכימות עבור תשומות : q = f / סולם + נקודת אפס דקוונטיזציה לתפוקות : f = (q - zeroPoint) * סולם |
איפה הפרמטרים | מולא על ידי יוצר המודל ומאוחסן במטא נתונים של המודל, כאפשרויות NormalizationOptions | מתמלא אוטומטית על ידי ממיר TFLite, ומאוחסן בקובץ דגם tflite. |
| איך מקבלים את הפרמטרים? | דרך ה- MetadataExtractor API [2] | דרך TFLite Tensor API [1] או דרך MetadataExtractor API [2] |
| האם מודלים צפים וכמותי חולקים את אותו ערך? | כן, למודלים של float ו-quant יש את אותם פרמטרים של נורמליזציה | לא, מודל הצוף אינו זקוק לכימות. |
| האם מחולל קוד TFLite או כריכת Android Studio ML מייצרים אותו אוטומטית בעיבוד נתונים? | כן | כן |
[1] TensorFlow Lite Java API ו- TensorFlow Lite C++ API .
[2] ספריית מחלץ המטא נתונים
בעת עיבוד נתוני תמונה עבור דגמי uint8, לעיתים מדלגים על נורמליזציה וקונטיזציה. זה בסדר לעשות זאת כאשר ערכי הפיקסלים נמצאים בטווח של [0, 255]. אבל באופן כללי, אתה תמיד צריך לעבד את הנתונים לפי פרמטרי הנורמליזציה והכימות כאשר ישים.
ספריית המשימות של TensorFlow Lite יכולה לטפל בנורמליזציה עבורך אם תגדיר NormalizationOptions במטא נתונים. עיבוד quantization ו-dequantization הוא תמיד מובלע.
דוגמאות
תוכל למצוא דוגמאות לאופן שבו יש לאכלס את המטא נתונים עבור סוגים שונים של מודלים כאן:
סיווג תמונה
הורד את הסקריפט כאן , המאכלס מטא נתונים ל- mobilnet_v1_0.75_160_quantized.tflite . הפעל את הסקריפט כך:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
כדי לאכלס מטא נתונים עבור מודלים אחרים של סיווג תמונות, הוסף את מפרט המודל כך לסקריפט. שאר המדריך הזה ידגיש כמה מהסעיפים המרכזיים בדוגמה של סיווג התמונות כדי להמחיש את המרכיבים המרכזיים.
צלול עמוק לתוך דוגמה לסיווג תמונה
מידע על הדגם
מטא נתונים מתחילים ביצירת מידע דגם חדש:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
מידע קלט/פלט
סעיף זה מראה לך כיצד לתאר את חתימת הקלט והפלט של הדגם שלך. מטא נתונים אלה עשויים לשמש מחוללי קוד אוטומטיים ליצירת קוד לפני ואחרי עיבוד. כדי ליצור מידע קלט או פלט על טנזור:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
קלט תמונה
תמונה היא סוג קלט נפוץ ללמידת מכונה. מטא נתונים של TensorFlow Lite תומכים במידע כגון מרחב צבע ומידע עיבוד מוקדם כגון נורמליזציה. המימד של התמונה אינו מצריך מפרט ידני מכיוון שהוא כבר מסופק על ידי צורת טנזור הקלט וניתן להסיק אותו אוטומטית.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
פלט תווית
ניתן למפות תווית לטנזור פלט באמצעות קובץ משויך באמצעות TENSOR_AXIS_LABELS .
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
צור את המטא נתונים Flatbuffers
הקוד הבא משלב את מידע הדגם עם מידע הקלט והפלט:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
ארוז מטא נתונים וקבצים משויכים למודל
לאחר יצירת המטא נתונים Flatbuffers, המטא נתונים וקובץ התווית נכתבים לקובץ TFLite באמצעות שיטת populate :
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
אתה יכול לארוז כמה קבצים משויכים שתרצה לתוך המודל דרך load_associated_files . עם זאת, נדרש לארוז לפחות את הקבצים המתועדים במטא נתונים. בדוגמה זו, אריזת קובץ התווית היא חובה.
דמיין את המטא נתונים
אתה יכול להשתמש ב-Netron כדי להמחיש את המטא נתונים שלך, או שאתה יכול לקרוא את המטא נתונים ממודל TensorFlow Lite לפורמט json באמצעות MetadataDisplayer :
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio תומך גם בהצגת מטא נתונים באמצעות התכונה Android Studio ML Binding .
ניהול גרסאות של מטא נתונים
סכימת המטא נתונים מנוסחת הן על ידי מספר הגירסה הסמנטי, העוקב אחר השינויים בקובץ הסכימה, והן על ידי זיהוי הקובץ Flatbuffers, המציין את תאימות הגרסה האמיתית.
מספר הגירסה הסמנטית
סכימת המטא נתונים מנוסחת על ידי מספר הגירסה הסמנטי , כגון MAJOR.MINOR.PATCH. הוא עוקב אחר שינויים בסכימה בהתאם לכללים כאן . ראה את ההיסטוריה של שדות שנוספו לאחר גרסה 1.0.0 .
זיהוי קובץ ה-Flatbuffers
ניהול גרסאות סמנטי מבטיח את התאימות אם מקפידים על הכללים, אבל זה לא מרמז על אי התאימות האמיתית. כשמגבירים את המספר MAJOR, זה לא בהכרח אומר שהתאימות לאחור נשברת. לכן, אנו משתמשים בזיהוי הקובץ של Flatbuffers , file_identifier , כדי לציין את התאימות האמיתית של סכימת המטא נתונים. מזהה הקובץ הוא בן 4 תווים בדיוק. הוא מקובע לסכימת מטא נתונים מסוימת ואינו נתון לשינויים על ידי משתמשים. אם יש לשבור את התאימות לאחור של סכימת המטא נתונים מסיבה כלשהי, הקובץ_מזהה יתגבר, למשל, מ-"M001" ל-"M002". ה-File_identifier צפוי להשתנות בתדירות נמוכה בהרבה מ-metadata_version.
גרסת מנתח המטא נתונים המינימלית הדרושה
גרסת מנתח המטא-נתונים המינימלית הדרושה היא הגרסה המינימלית של מנתח המטא-נתונים (הקוד שנוצר על ידי Flatbuffers) שיכולה לקרוא את המטא-נתונים Flatbuffers במלואם. הגרסה היא למעשה מספר הגרסה הגדול ביותר מבין הגרסאות של כל השדות המאוכלסים והגרסה התואמת הקטנה ביותר המצוינת על ידי מזהה הקובץ. גרסת מנתח המטא נתונים המינימלית הנחוצה מאוכלסת באופן אוטומטי על ידי MetadataPopulator כאשר המטא נתונים מאוכלסים במודל TFLite. עיין במחלץ המטא נתונים לקבלת מידע נוסף על אופן השימוש בגרסת מנתח המטא נתונים המינימלית הדרושה.
קרא את המטא נתונים ממודלים
ספריית Metadata Extractor היא כלי נוח לקריאת המטא נתונים והקבצים המשויכים ממודלים על פני פלטפורמות שונות (ראה את גרסת Java וגרסת C++ ). אתה יכול לבנות כלי משלך לחילוץ מטא נתונים בשפות אחרות באמצעות ספריית Flatbuffers.
קרא את המטא נתונים ב-Java
כדי להשתמש בספריית Metadata Extractor באפליקציית Android שלך, אנו ממליצים להשתמש ב- TensorFlow Lite Metadata AAR המתארח ב- MavenCentral . הוא מכיל את המחלקה MetadataExtractor , כמו גם את ה-FlatBuffers Java bindings עבור סכימת המטא נתונים וסכימת המודל .
אתה יכול לציין זאת בתלות build.gradle שלך באופן הבא:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
כדי להשתמש בצילומי מצב לילי, ודא שהוספת מאגר תמונות מצב של Sonatype .
אתה יכול לאתחל אובייקט MetadataExtractor עם ByteBuffer שמצביע על המודל:
public MetadataExtractor(ByteBuffer buffer);
ה- ByteBuffer חייב להישאר ללא שינוי במשך כל חייו של אובייקט MetadataExtractor . האתחול עלול להיכשל אם מזהה הקובץ Flatbuffers של המטא-נתונים של המודל אינו תואם לזה של מנתח המטא-נתונים. ראה גירסאות מטא נתונים למידע נוסף.
עם מזהי קבצים תואמים, מחלץ המטא נתונים יקרא בהצלחה מטא נתונים שנוצרו מכל הסכימות בעבר ובעתיד עקב מנגנון התאימות קדימה ואחורה של Flatbuffers. עם זאת, לא ניתן לחלץ שדות מסכימות עתידיות על ידי מחלצי מטא נתונים ישנים יותר. גרסת המנתח המינימלית הדרושה של המטא נתונים מציינת את הגרסה המינימלית של מנתח המטא נתונים שיכולה לקרוא את המטא נתונים Flatbuffers במלואם. אתה יכול להשתמש בשיטה הבאה כדי לוודא אם מתקיים תנאי גרסת המנתח המינימלי הנחוץ:
public final boolean isMinimumParserVersionSatisfied();
מותר להעביר מודל ללא מטא נתונים. עם זאת, הפעלת שיטות שקוראות מהמטא נתונים יגרום לשגיאות זמן ריצה. אתה יכול לבדוק אם למודל יש מטא נתונים על ידי הפעלת שיטת hasMetadata :
public boolean hasMetadata();
MetadataExtractor מספק פונקציות נוחות עבורך כדי לקבל את המטא נתונים של טנזורי הקלט/פלט. לדוגמה,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
למרות שסכימת המודל של TensorFlow Lite תומכת במספר תת-גרפים, מתורגמן TFLite תומך כרגע רק בתת-גרף בודד. לכן, MetadataExtractor משמיט את אינדקס התת-גרף כארגומנט קלט בשיטות שלו.
קרא את הקבצים המשויכים מדגמים
מודל TensorFlow Lite עם מטא נתונים וקבצים משויכים הוא בעצם קובץ zip שניתן לפרוק עם כלי zip נפוצים כדי לקבל את הקבצים המשויכים. לדוגמה, אתה יכול לפתוח את mobilenet_v1_0.75_160_quantized ולחלץ את קובץ התווית במודל באופן הבא:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
אתה יכול גם לקרוא קבצים משויכים דרך ספריית Metadata Extractor.
ב-Java, העבר את שם הקובץ לשיטת MetadataExtractor.getAssociatedFile :
public InputStream getAssociatedFile(String fileName);
באופן דומה, ב-C++, ניתן לעשות זאת בשיטה, ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;