
A quantização pós-treinamento é uma técnica de conversão que pode reduzir o tamanho do modelo e, ao mesmo tempo, melhorar a latência da CPU e do acelerador de hardware, com pouca degradação na precisão do modelo. Você pode quantizar um modelo flutuante do TensorFlow já treinado ao convertê-lo para o formato TensorFlow Lite usando o TensorFlow Lite Converter .
Métodos de otimização
Existem várias opções de quantização pós-treinamento para você escolher. Aqui está uma tabela resumida das opções e dos benefícios que elas oferecem:
| Técnica | Benefícios | Hardware |
|---|---|---|
| Quantização de faixa dinâmica | 4x menor, aceleração de 2x-3x | CPU |
| Quantização inteira completa | 4x menor, 3x+ aceleração | CPU, Edge TPU, microcontroladores |
| Quantização Float16 | 2x menor, aceleração de GPU | CPU, GPU |
A árvore de decisão a seguir pode ajudar a determinar qual método de quantização pós-treinamento é melhor para seu caso de uso:
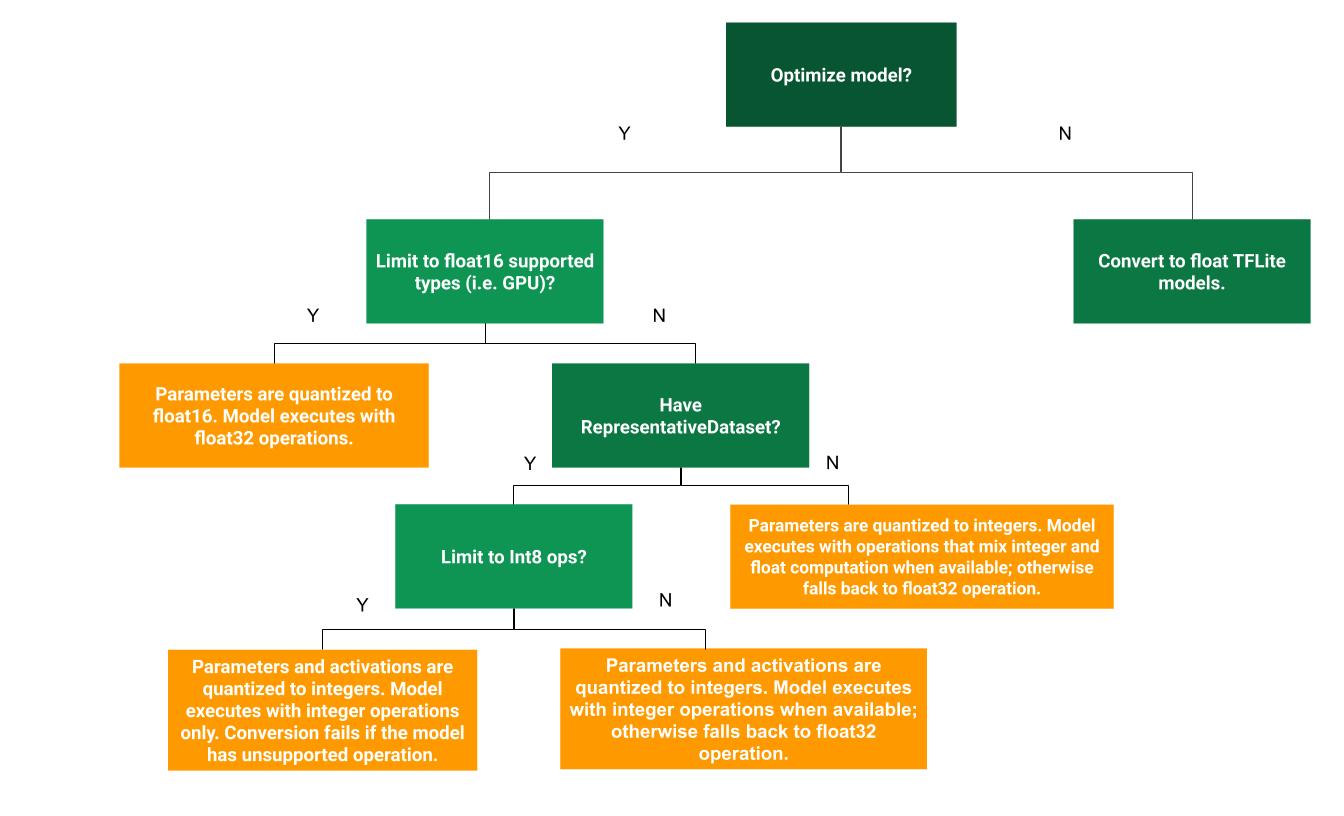
Quantização de faixa dinâmica
A quantização de faixa dinâmica é um ponto de partida recomendado porque fornece uso reduzido de memória e computação mais rápida sem a necessidade de fornecer um conjunto de dados representativo para calibração. Este tipo de quantização quantiza estaticamente apenas os pesos de ponto flutuante para inteiro no tempo de conversão, o que fornece 8 bits de precisão:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Para reduzir ainda mais a latência durante a inferência, os operadores de "faixa dinâmica" quantizam dinamicamente as ativações com base em sua faixa de 8 bits e realizam cálculos com pesos e ativações de 8 bits. Essa otimização fornece latências próximas às inferências de ponto totalmente fixo. No entanto, as saídas ainda são armazenadas usando ponto flutuante, de modo que o aumento da velocidade das operações de faixa dinâmica é menor do que um cálculo completo de ponto fixo.
Quantização inteira completa
Você pode obter mais melhorias de latência, reduções no pico de uso de memória e compatibilidade com dispositivos ou aceleradores de hardware somente com números inteiros, certificando-se de que toda a matemática do modelo seja quantizada por números inteiros.
Para quantização inteira completa, você precisa calibrar ou estimar o intervalo, ou seja, (min, max) de todos os tensores de ponto flutuante no modelo. Ao contrário dos tensores constantes, como pesos e vieses, tensores variáveis, como entrada do modelo, ativações (saídas de camadas intermediárias) e saída do modelo não podem ser calibrados, a menos que executemos alguns ciclos de inferência. Como resultado, o conversor requer um conjunto de dados representativo para calibrá-los. Este conjunto de dados pode ser um pequeno subconjunto (cerca de 100-500 amostras) dos dados de treinamento ou validação. Consulte a função representative_dataset() abaixo.
Na versão TensorFlow 2.7, você pode especificar o conjunto de dados representativo por meio de uma assinatura como no exemplo a seguir:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Se houver mais de uma assinatura no modelo do TensorFlow fornecido, você poderá especificar vários conjuntos de dados especificando as chaves de assinatura:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Você pode gerar o conjunto de dados representativo fornecendo uma lista de tensores de entrada:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Desde a versão 2.7 do TensorFlow, recomendamos usar a abordagem baseada em assinatura em vez da abordagem baseada em lista de tensores de entrada porque a ordem do tensor de entrada pode ser facilmente invertida.
Para fins de teste, você pode usar um conjunto de dados fictício da seguinte maneira:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Inteiro com fallback flutuante (usando entrada/saída flutuante padrão)
Para quantizar totalmente um modelo, mas usar operadores float quando eles não tiverem uma implementação inteira (para garantir que a conversão ocorra sem problemas), use as seguintes etapas:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Apenas números inteiros
A criação de modelos somente inteiros é um caso de uso comum do TensorFlow Lite para microcontroladores e TPUs Coral Edge .
Além disso, para garantir a compatibilidade apenas com dispositivos inteiros (como microcontroladores de 8 bits) e aceleradores (como o Coral Edge TPU), você pode impor a quantização completa de números inteiros para todas as operações, incluindo entrada e saída, usando as seguintes etapas:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Quantização Float16
Você pode reduzir o tamanho de um modelo de ponto flutuante quantizando os pesos para float16, o padrão IEEE para números de ponto flutuante de 16 bits. Para habilitar a quantização de pesos float16, use as seguintes etapas:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
As vantagens da quantização float16 são as seguintes:
- Reduz o tamanho do modelo em até metade (uma vez que todos os pesos passam a ter metade do seu tamanho original).
- Causa perda mínima de precisão.
- Ele suporta alguns delegados (por exemplo, o delegado GPU) que podem operar diretamente nos dados float16, resultando em uma execução mais rápida do que os cálculos float32.
As desvantagens da quantização float16 são as seguintes:
- Não reduz a latência tanto quanto uma quantização para matemática de ponto fixo.
- Por padrão, um modelo quantizado float16 irá "desquantizar" os valores dos pesos para float32 quando executado na CPU. (Observe que o delegado da GPU não realizará essa desquantização, pois pode operar em dados float16.)
Somente números inteiros: ativações de 16 bits com pesos de 8 bits (experimental)
Este é um esquema de quantização experimental. É semelhante ao esquema "somente número inteiro", mas as ativações são quantizadas com base em seu intervalo de 16 bits, os pesos são quantizados em números inteiros de 8 bits e a polarização é quantizada em números inteiros de 64 bits. Isto é ainda referido como quantização 16x8.
A principal vantagem desta quantização é que ela pode melhorar significativamente a precisão, mas apenas aumentar ligeiramente o tamanho do modelo.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Se a quantização 16x8 não for suportada para alguns operadores no modelo, então o modelo ainda poderá ser quantizado, mas os operadores não suportados serão mantidos em flutuação. A opção a seguir deve ser adicionada ao target_spec para permitir isso.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Exemplos de casos de uso em que as melhorias de precisão fornecidas por este esquema de quantização incluem:
- super-resolução,
- processamento de sinal de áudio, como cancelamento de ruído e formação de feixe,
- remoção de ruído de imagem,
- Reconstrução HDR a partir de uma única imagem.
A desvantagem desta quantização é:
- Atualmente a inferência é visivelmente mais lenta que o número inteiro completo de 8 bits devido à falta de implementação otimizada do kernel.
- Atualmente é incompatível com os delegados TFLite acelerados por hardware existentes.
Um tutorial para este modo de quantização pode ser encontrado aqui .
Precisão do modelo
Como os pesos são quantizados após o treinamento, pode haver perda de precisão, principalmente em redes menores. Modelos totalmente quantizados pré-treinados são fornecidos para redes específicas no TensorFlow Hub . É importante verificar a precisão do modelo quantizado para verificar se qualquer degradação na precisão está dentro dos limites aceitáveis. Existem ferramentas para avaliar a precisão do modelo TensorFlow Lite .
Alternativamente, se a queda na precisão for muito alta, considere usar o treinamento com reconhecimento de quantização . No entanto, fazer isso requer modificações durante o treinamento do modelo para adicionar nós de quantização falsos, enquanto as técnicas de quantização pós-treinamento nesta página usam um modelo pré-treinado existente.
Representação para tensores quantizados
A quantização de 8 bits aproxima os valores de ponto flutuante usando a seguinte fórmula.
\[real\_value = (int8\_value - zero\_point) \times scale\]
A representação tem duas partes principais:
Pesos por eixo (também conhecidos como por canal) ou por tensor representados por valores de complemento de dois int8 no intervalo [-127, 127] com ponto zero igual a 0.
Ativações/entradas por tensor representadas por valores de complemento de dois int8 no intervalo [-128, 127], com ponto zero no intervalo [-128, 127].
Para uma visão detalhada do nosso esquema de quantização, consulte nossas especificações de quantização . Os fornecedores de hardware que desejam se conectar à interface delegada do TensorFlow Lite são incentivados a implementar o esquema de quantização descrito lá.