

המשימה של זיהוי מה מייצג אודיו נקראת סיווג אודיו . מודל סיווג אודיו מאומן לזהות אירועי אודיו שונים. לדוגמה, אתה יכול לאמן מודל לזהות אירועים המייצגים שלושה אירועים שונים: מחיאת כפיים, הצמדת אצבע והקלדה. TensorFlow Lite מספק מודלים שעברו הכשרה מותאמים מראש שתוכל לפרוס ביישומים הניידים שלך. למידע נוסף על סיווג אודיו באמצעות TensorFlow כאן .
התמונה הבאה מציגה את הפלט של מודל סיווג האודיו באנדרואיד.
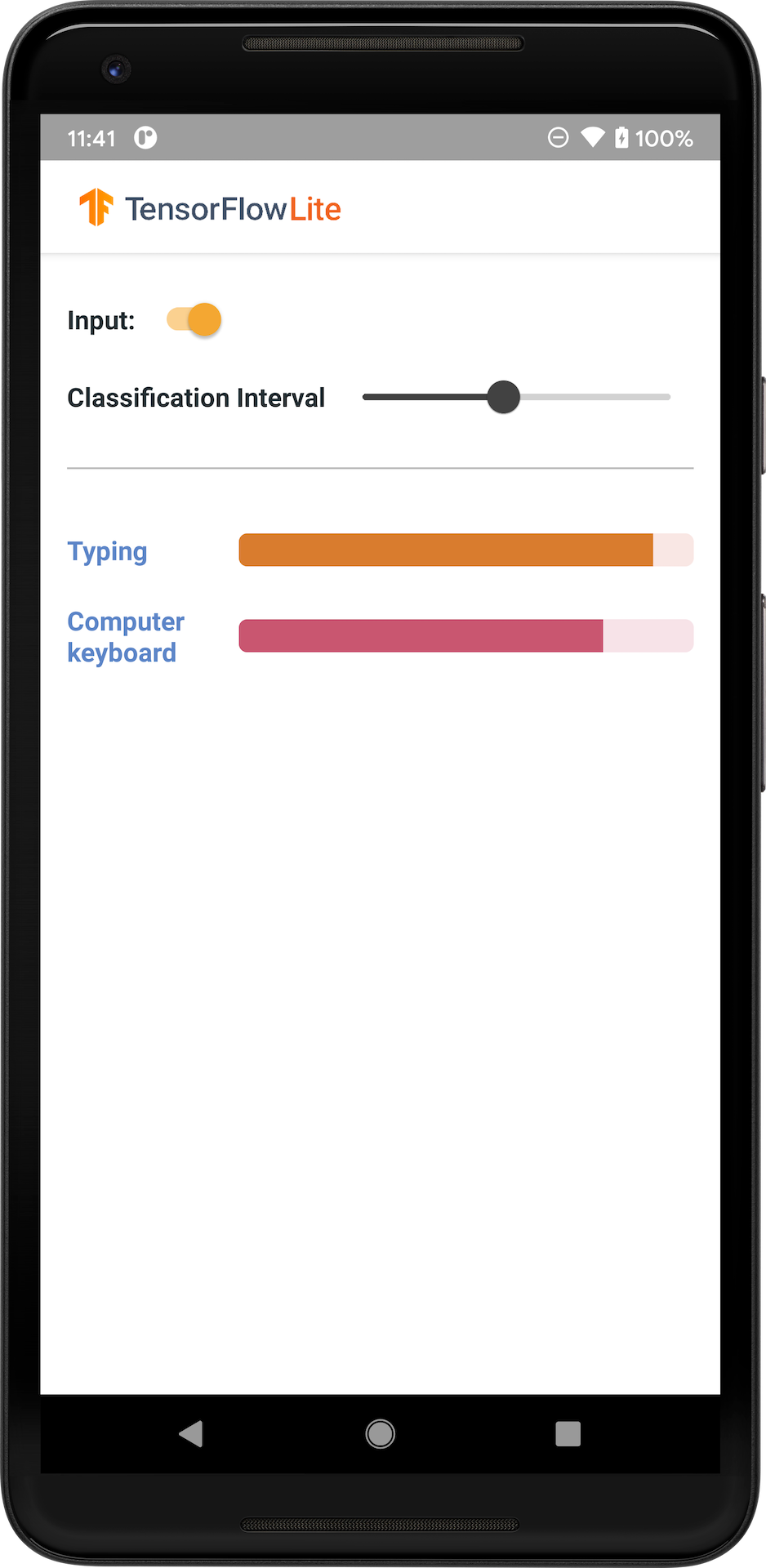
להתחיל
אם אתה חדש ב-TensorFlow Lite ועובד עם אנדרואיד, אנו ממליצים לחקור את האפליקציות לדוגמה הבאות שיכולות לעזור לך להתחיל.
אתה יכול למנף את ה-API מחוץ לקופסה מספריית המשימות TensorFlow Lite כדי לשלב מודלים של סיווג אודיו בכמה שורות קוד בלבד. אתה יכול גם לבנות צינור מסקנות מותאם אישית משלך באמצעות ספריית התמיכה של TensorFlow Lite .
דוגמה אנדרואיד להלן מדגימה את היישום באמצעות ספריית המשימות TFLite
אם אתה משתמש בפלטפורמה שאינה אנדרואיד/iOS, או אם אתה כבר מכיר את ממשקי ה-API של TensorFlow Lite , הורד את דגם ההתחלה והקבצים התומכים (אם רלוונטי).
הורד את דגם המתחיל מ- TensorFlow Hub
תיאור הדגם
YAMNet הוא מסווג אירועי אודיו שלוקח צורת גל אודיו כקלט ומבצע תחזיות עצמאיות עבור כל אחד מ-521 אירועי אודיו מהאונטולוגיה של AudioSet . המודל משתמש בארכיטקטורת MobileNet v1 והוכשר באמצעות קורפוס AudioSet. דגם זה שוחרר במקור בגן המודלים של TensorFlow, שם נמצא קוד המקור של הדגם, נקודת ביקורת הדגם המקורית ותיעוד מפורט יותר.
איך זה עובד
ישנן שתי גרסאות של מודל YAMNet שהומרו ל-TFLite:
YAMNet הוא מודל סיווג האודיו המקורי, עם גודל קלט דינמי, המתאים לפריסה של העברת למידה, אינטרנט ונייד. יש לו גם פלט מורכב יותר.
YAMNet/סיווג היא גרסה כמותית עם קלט מסגרת באורך קבוע פשוט יותר (15600 דגימות) ומחזירה וקטור בודד של ציונים עבור 521 כיתות אירועי שמע.
תשומות
המודל מקבל מערך 1-D float32 Tensor או NumPy באורך 15600 המכיל צורת גל של 0.975 שניות המיוצגת כדגימות מונו של 16 קילו-הרץ בטווח [-1.0, +1.0] .
פלטים
המודל מחזיר צורה 2-D float32 Tensor (1, 521) המכיל את הציונים החזויים עבור כל אחת מ-521 המחלקות באונטולוגיה של AudioSet הנתמכות על ידי YAMNet. אינדקס העמודות (0-520) של טנסור הציונים ממופה לשם המחלקה המתאימה של AudioSet באמצעות מפת הכיתה של YAMNet, הזמינה כקובץ משויך yamnet_label_list.txt ארוז בקובץ המודל. ראה למטה לשימוש.
שימושים מתאימים
ניתן להשתמש ב-YAMNet
- כמסווג אירועי אודיו עצמאי המספק קו בסיס סביר על פני מגוון רחב של אירועי אודיו.
- כמחלץ תכונה ברמה גבוהה: ניתן להשתמש בפלט הטמעת 1024-D של YAMNet כתכונות הקלט של דגם אחר אשר לאחר מכן ניתן לאמן אותו על כמות קטנה של נתונים עבור משימה מסוימת. זה מאפשר ליצור במהירות מסווגי אודיו מיוחדים מבלי לדרוש הרבה נתונים מסומנים וללא צורך בהכשרת דגם גדול מקצה לקצה.
- כהתחלה חמה: ניתן להשתמש בפרמטרי המודל של YAMNet כדי לאתחל חלק מדגם גדול יותר המאפשר כוונון מהיר יותר וחקר מודלים.
מגבלות
- פלטי המסווגים של YAMNet לא כוייל בין מחלקות, כך שלא ניתן להתייחס ישירות לפלטים כהסתברויות. עבור כל משימה נתונה, סביר להניח שתצטרכו לבצע כיול עם נתונים ספציפיים למשימה, המאפשרים לכם להקצות ספי ניקוד ושינוי קנה מידה מתאימים לכל כיתה.
- YAMNet הוכשרה על מיליוני סרטוני YouTube ולמרות שהם מגוונים מאוד, עדיין יכולה להיות חוסר התאמה בתחום בין סרטון YouTube הממוצע לבין כניסות האודיו הצפויות לכל משימה נתונה. אתה צריך לצפות לבצע כמות מסוימת של כוונון עדין וכיול כדי להפוך את YAMNet לשימוש בכל מערכת שאתה בונה.
התאמה אישית של הדגם
הדגמים המאומנים מראש שסופקו מאומנים לזהות 521 כיתות אודיו שונות. לרשימה מלאה של מחלקות, עיין בקובץ התוויות במאגר המודלים .
אתה יכול להשתמש בטכניקה המכונה למידה העברה כדי לאמן מחדש מודל לזהות שיעורים שאינם בסט המקורי. לדוגמה, אתה יכול לאמן מחדש את המודל לזהות שירי ציפורים מרובים. כדי לעשות זאת, תזדקק לסט של שמע אימון עבור כל אחת מהתוויות החדשות שברצונך לאמן. הדרך המומלצת היא להשתמש בספריית TensorFlow Lite Model Maker אשר מפשטת את תהליך האימון של מודל TensorFlow Lite באמצעות מערך נתונים מותאם אישית, במספר שורות קודים. הוא משתמש בלימוד העברה כדי להפחית את כמות הנתונים והזמן הנדרשים לאימון. אתה יכול גם ללמוד מ- Transfer Learning לזיהוי שמע כדוגמה ללמידת העברה.
קריאה נוספת ומשאבים
השתמש במשאבים הבאים כדי ללמוד עוד על מושגים הקשורים לסיווג אודיו: