

Il compito di identificare ciò che rappresenta un audio è chiamato classificazione audio . Un modello di classificazione audio è addestrato a riconoscere vari eventi audio. Ad esempio, puoi addestrare un modello a riconoscere eventi che rappresentano tre eventi diversi: battere le mani, schioccare le dita e digitare. TensorFlow Lite fornisce modelli pre-addestrati ottimizzati che puoi distribuire nelle tue applicazioni mobili. Scopri di più sulla classificazione audio utilizzando TensorFlow qui .
L'immagine seguente mostra l'output del modello di classificazione audio su Android.
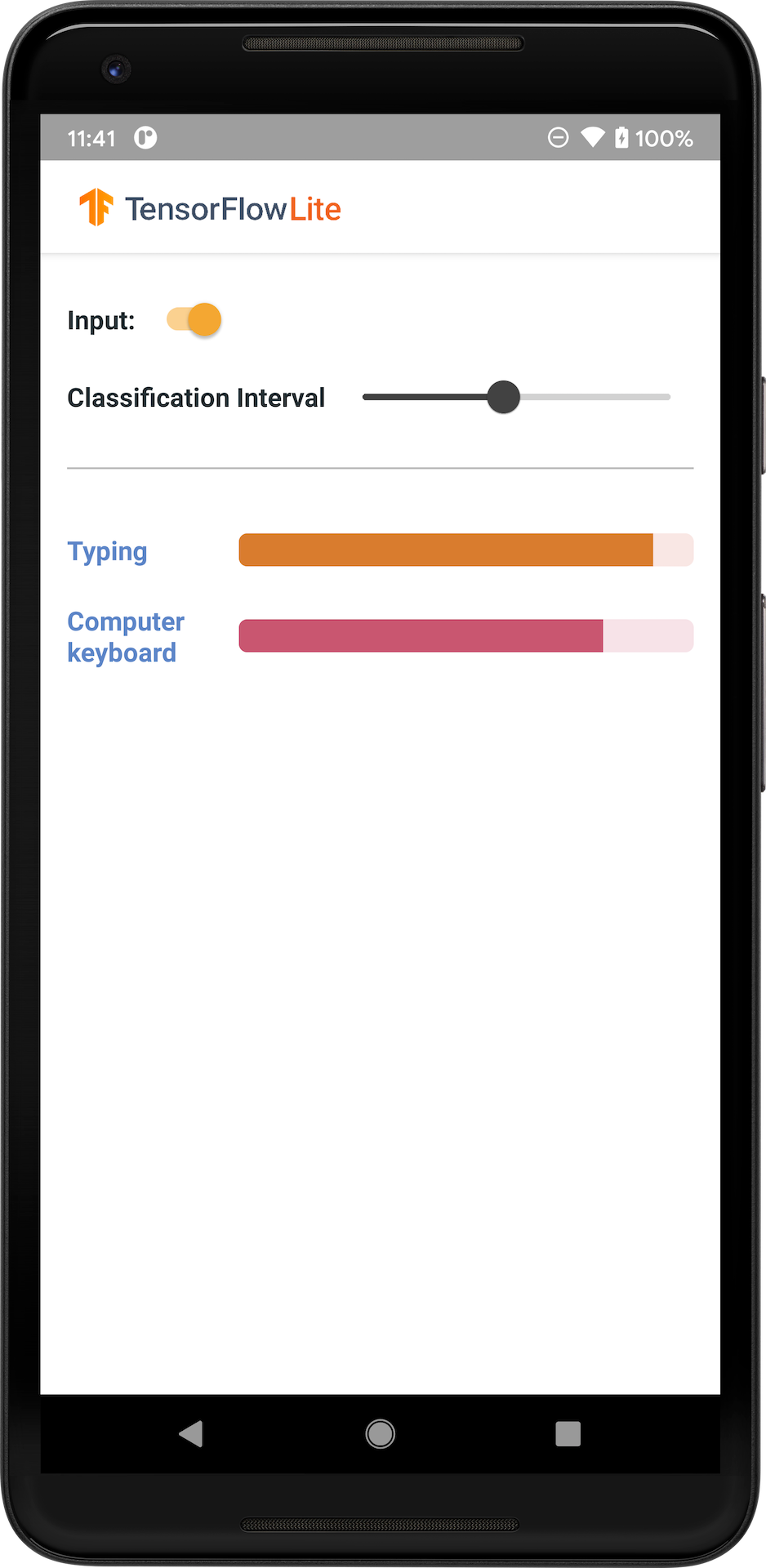
Iniziare
Se non conosci TensorFlow Lite e lavori con Android, ti consigliamo di esplorare le seguenti applicazioni di esempio che possono aiutarti a iniziare.
Puoi sfruttare l'API pronta all'uso della libreria attività TensorFlow Lite per integrare modelli di classificazione audio in poche righe di codice. Puoi anche creare la tua pipeline di inferenza personalizzata utilizzando la libreria di supporto TensorFlow Lite .
L'esempio Android riportato di seguito illustra l'implementazione utilizzando la libreria attività TFLite
Visualizza l'esempio di Android
Se utilizzi una piattaforma diversa da Android/iOS o se hai già familiarità con le API TensorFlow Lite , scarica il modello iniziale e i file di supporto (se applicabili).
Scarica il modello iniziale da TensorFlow Hub
Descrizione del Modello
YAMNet è un classificatore di eventi audio che accetta la forma d'onda audio come input ed effettua previsioni indipendenti per ciascuno dei 521 eventi audio dall'ontologia AudioSet . Il modello utilizza l'architettura MobileNet v1 ed è stato addestrato utilizzando il corpus AudioSet. Questo modello è stato originariamente rilasciato nel TensorFlow Model Garden, dove si trova il codice sorgente del modello, il checkpoint del modello originale e una documentazione più dettagliata.
Come funziona
Esistono due versioni del modello YAMNet convertito in TFLite:
YAMNet È il modello di classificazione audio originale, con dimensioni di input dinamiche, adatto per Transfer Learning, distribuzione Web e mobile. Ha anche un output più complesso.
YAMNet/classification è una versione quantizzata con un input di frame a lunghezza fissa più semplice (15600 campioni) e restituisce un singolo vettore di punteggi per 521 classi di eventi audio.
Ingressi
Il modello accetta un array Tensor o NumPy 1-D float32 di lunghezza 15600 contenente una forma d'onda di 0,975 secondi rappresentata come campioni mono da 16 kHz nell'intervallo [-1.0, +1.0] .
Uscite
Il modello restituisce un tensore di forma 2-D float32 (1, 521) contenente i punteggi previsti per ciascuna delle 521 classi nell'ontologia AudioSet supportate da YAMNet. L'indice della colonna (0-520) del tensore dei punteggi viene mappato al nome della classe AudioSet corrispondente utilizzando la mappa delle classi YAMNet, che è disponibile come file associato yamnet_label_list.txt compresso nel file del modello. Vedi sotto per l'utilizzo.
Usi idonei
È possibile utilizzare YAMNet
- come classificatore di eventi audio autonomo che fornisce una base di riferimento ragionevole per un'ampia varietà di eventi audio.
- come estrattore di funzionalità di alto livello: l'output di incorporamento 1024-D di YAMNet può essere utilizzato come funzionalità di input di un altro modello che può quindi essere addestrato su una piccola quantità di dati per un compito particolare. Ciò consente di creare rapidamente classificatori audio specializzati senza richiedere molti dati etichettati e senza dover addestrare un modello di grandi dimensioni end-to-end.
- come avvio a caldo: i parametri del modello YAMNet possono essere utilizzati per inizializzare parte di un modello più ampio che consente una messa a punto e un'esplorazione del modello più rapide.
Limitazioni
- Gli output del classificatore di YAMNet non sono stati calibrati tra le classi, quindi non puoi trattare direttamente gli output come probabilità. Per ogni determinata attività, molto probabilmente dovrai eseguire una calibrazione con dati specifici dell'attività che ti consentano di assegnare soglie di punteggio e ridimensionamento adeguati per classe.
- YAMNet è stato addestrato su milioni di video di YouTube e, sebbene questi siano molto diversi, può ancora verificarsi una discrepanza di dominio tra il video medio di YouTube e gli input audio previsti per una determinata attività. Dovresti aspettarti di fare una certa quantità di messa a punto e calibrazione per rendere YAMNet utilizzabile in qualsiasi sistema che costruisci.
Personalizzazione del modello
I modelli preaddestrati forniti sono addestrati per rilevare 521 classi audio diverse. Per un elenco completo delle classi, vedere il file label nel repository del modello .
È possibile utilizzare una tecnica nota come trasferimento dell'apprendimento per riqualificare un modello in modo che riconosca le classi non presenti nel set originale. Ad esempio, potresti riqualificare il modello per rilevare più canti di uccelli. Per fare ciò, avrai bisogno di una serie di audio di formazione per ciascuna delle nuove etichette che desideri addestrare. Il modo consigliato è utilizzare la libreria TensorFlow Lite Model Maker che semplifica il processo di addestramento di un modello TensorFlow Lite utilizzando un set di dati personalizzato, in poche righe di codice. Utilizza l'apprendimento del trasferimento per ridurre la quantità di dati e tempo di addestramento richiesti. Puoi anche imparare dall'apprendimento tramite trasferimento per il riconoscimento audio come esempio di apprendimento tramite trasferimento.
Ulteriori letture e risorse
Utilizza le seguenti risorse per ulteriori informazioni sui concetti relativi alla classificazione audio: