

A tarefa de identificar o que um áudio representa é chamada de classificação de áudio . Um modelo de classificação de áudio é treinado para reconhecer vários eventos de áudio. Por exemplo, você pode treinar um modelo para reconhecer eventos que representam três eventos diferentes: bater palmas, estalar os dedos e digitar. O TensorFlow Lite fornece modelos pré-treinados otimizados que você pode implantar em seus aplicativos móveis. Saiba mais sobre classificação de áudio usando o TensorFlow aqui .
A imagem a seguir mostra a saída do modelo de classificação de áudio no Android.
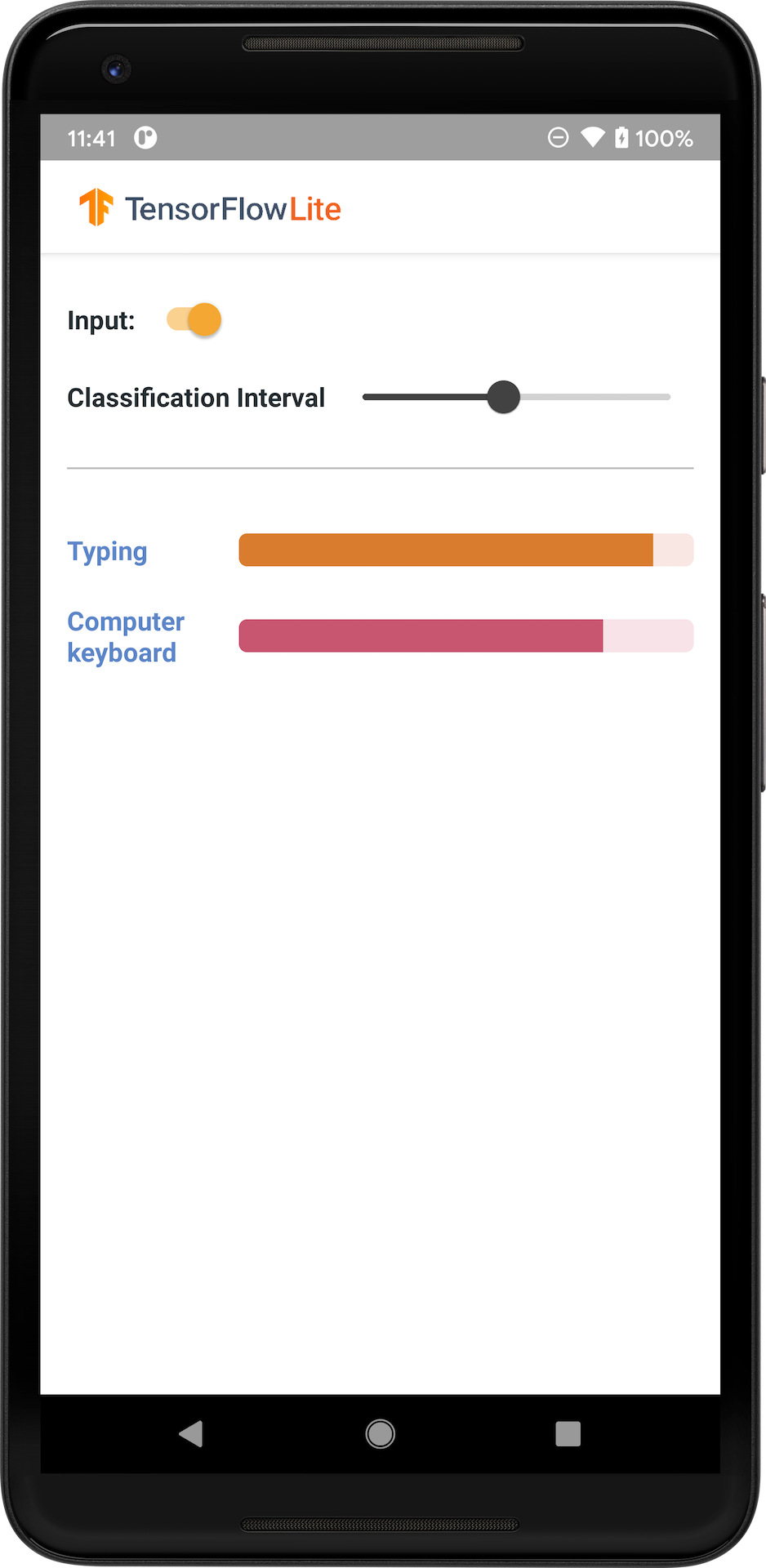
iniciar
Se você é novo no TensorFlow Lite e está trabalhando com Android, recomendamos explorar os exemplos de aplicativos a seguir que podem ajudá-lo a começar.
Você pode aproveitar a API pronta para uso da biblioteca de tarefas do TensorFlow Lite para integrar modelos de classificação de áudio em apenas algumas linhas de código. Você também pode criar seu próprio pipeline de inferência personalizado usando a Biblioteca de suporte do TensorFlow Lite .
O exemplo Android abaixo demonstra a implementação usando a biblioteca de tarefas TFLite
Se você estiver usando uma plataforma diferente de Android/iOS ou se já estiver familiarizado com as APIs do TensorFlow Lite , faça download do modelo inicial e dos arquivos de suporte (se aplicável).
Baixe o modelo inicial do TensorFlow Hub
Descrição do modelo
YAMNet é um classificador de eventos de áudio que usa a forma de onda de áudio como entrada e faz previsões independentes para cada um dos 521 eventos de áudio da ontologia AudioSet . O modelo utiliza a arquitetura MobileNet v1 e foi treinado utilizando o corpus AudioSet. Este modelo foi lançado originalmente no TensorFlow Model Garden, onde está o código-fonte do modelo, o ponto de verificação do modelo original e uma documentação mais detalhada.
Como funciona
Existem duas versões do modelo YAMNet convertido para TFLite:
YAMNet É o modelo original de classificação de áudio, com tamanho de entrada dinâmico, adequado para transferência de aprendizagem, implantação na Web e móvel. Ele também tem uma saída mais complexa.
YAMNet/classificação é uma versão quantizada com uma entrada de quadro de comprimento fixo mais simples (15.600 amostras) e retorna um único vetor de pontuações para 521 classes de eventos de áudio.
Entradas
O modelo aceita um Tensor float32 1-D ou matriz NumPy de comprimento 15600 contendo uma forma de onda de 0,975 segundos representada como amostras mono de 16 kHz no intervalo [-1.0, +1.0] .
Resultados
O modelo retorna um tensor float32 2-D de formato (1, 521) contendo as pontuações previstas para cada uma das 521 classes na ontologia AudioSet que são suportadas pelo YAMNet. O índice da coluna (0-520) do tensor de pontuações é mapeado para o nome da classe AudioSet correspondente usando o YAMNet Class Map, que está disponível como um arquivo associado yamnet_label_list.txt compactado no arquivo de modelo. Veja abaixo o uso.
Usos adequados
YAMNet pode ser usado
- como um classificador de eventos de áudio independente que fornece uma linha de base razoável para uma ampla variedade de eventos de áudio.
- como um extrator de recursos de alto nível: a saída de incorporação 1024-D do YAMNet pode ser usada como recursos de entrada de outro modelo que pode então ser treinado em uma pequena quantidade de dados para uma tarefa específica. Isso permite criar rapidamente classificadores de áudio especializados sem exigir muitos dados rotulados e sem precisar treinar um modelo grande de ponta a ponta.
- como um início a quente: os parâmetros do modelo YAMNet podem ser usados para inicializar parte de um modelo maior, o que permite um ajuste fino e uma exploração do modelo mais rápidos.
Limitações
- As saídas do classificador YAMNet não foram calibradas entre classes, portanto você não pode tratar diretamente as saídas como probabilidades. Para qualquer tarefa, você provavelmente precisará realizar uma calibração com dados específicos da tarefa, o que permite atribuir limites e escalas de pontuação por classe adequados.
- O YAMNet foi treinado em milhões de vídeos do YouTube e, embora sejam muito diversos, ainda pode haver uma incompatibilidade de domínio entre o vídeo médio do YouTube e as entradas de áudio esperadas para qualquer tarefa. Você deve esperar fazer alguns ajustes e calibrações para tornar o YAMNet utilizável em qualquer sistema que você construir.
Personalização do modelo
Os modelos pré-treinados fornecidos são treinados para detectar 521 classes de áudio diferentes. Para obter uma lista completa de classes, consulte o arquivo de rótulos no repositório do modelo .
Você pode usar uma técnica conhecida como aprendizagem por transferência para treinar novamente um modelo para reconhecer classes que não estão no conjunto original. Por exemplo, você pode treinar novamente o modelo para detectar vários cantos de pássaros. Para fazer isso, você precisará de um conjunto de áudios de treinamento para cada um dos novos rótulos que deseja treinar. A forma recomendada é usar a biblioteca TensorFlow Lite Model Maker que simplifica o processo de treinamento de um modelo TensorFlow Lite usando conjunto de dados customizado, em poucas linhas de código. Ele usa aprendizagem por transferência para reduzir a quantidade de dados e tempo de treinamento necessários. Você também pode aprender com Aprendizagem por transferência para reconhecimento de áudio como um exemplo de aprendizagem por transferência.
Leitura adicional e recursos
Use os seguintes recursos para aprender mais sobre conceitos relacionados à classificação de áudio: