
| | |
giriiş
Büyük dil modelleri (LLM'ler), büyük veri kümelerine dayalı metin oluşturmak üzere eğitilmiş bir makine öğrenimi modelleri sınıfıdır. Metin oluşturma, soru yanıtlama ve makine çevirisi dahil olmak üzere doğal dil işleme (NLP) görevleri için kullanılabilirler. Transformer mimarisini temel alırlar ve genellikle milyarlarca kelimeyi içeren çok büyük miktarda metin verisi üzerinde eğitilirler. GPT-2 gibi daha küçük ölçekteki Yüksek Lisanslar bile etkileyici bir performans sergileyebilir. TensorFlow modellerini daha hafif, daha hızlı ve düşük güçlü bir modele dönüştürmek, veriler cihazınızdan asla ayrılmayacağından daha iyi kullanıcı güvenliği avantajlarıyla üretken yapay zeka modellerini cihazda çalıştırmamıza olanak tanır.
Bu runbook, bir Keras LLM'yi çalıştırmak için TensorFlow Lite ile nasıl bir Android uygulaması oluşturacağınızı gösterir ve aksi takdirde çalıştırmak için çok daha büyük miktarda bellek ve daha fazla hesaplama gücü gerektirecek olan niceleme tekniklerini kullanarak model optimizasyonuna yönelik öneriler sağlar.
Uyumlu herhangi bir TFLite LLM'nin takabileceği Android uygulama çerçevemizi açık kaynaklı hale getirdik. İşte iki demo:
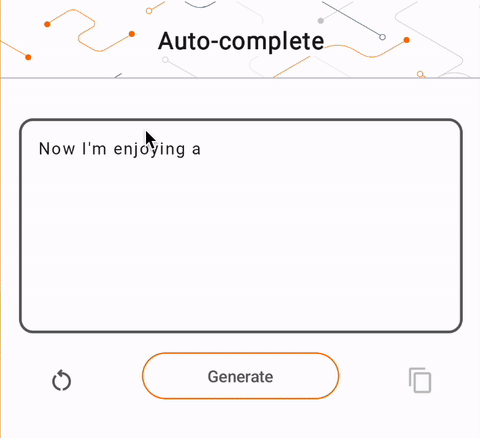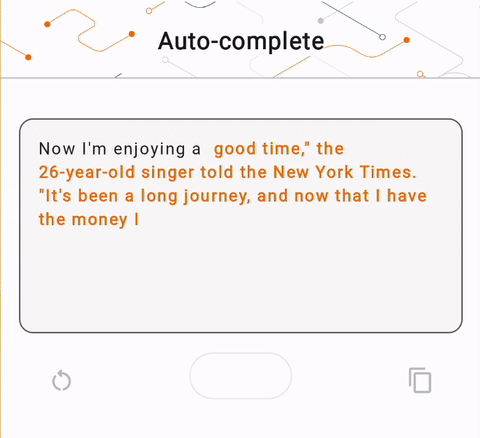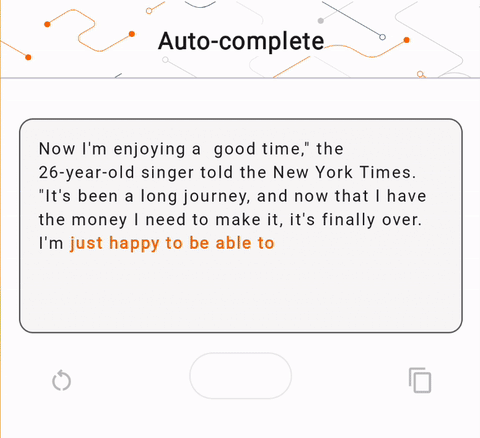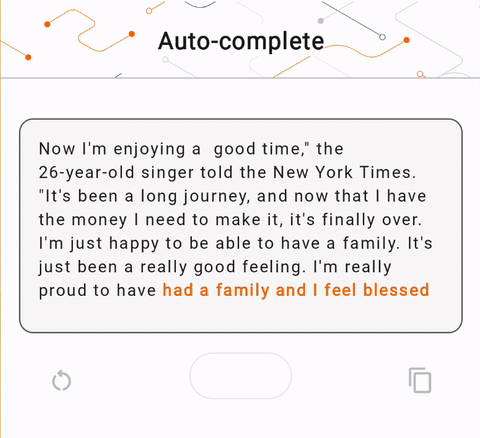
- Şekil 1'de cihazda metin tamamlama görevlerini gerçekleştirmek için Keras GPT-2 modelini kullandık.
- Şekil 2'de, talimat ayarlı PaLM modelinin bir versiyonunu (1,5 milyar parametre) TFLite'a dönüştürdük ve TFLite çalışma zamanı aracılığıyla çalıştırdık.
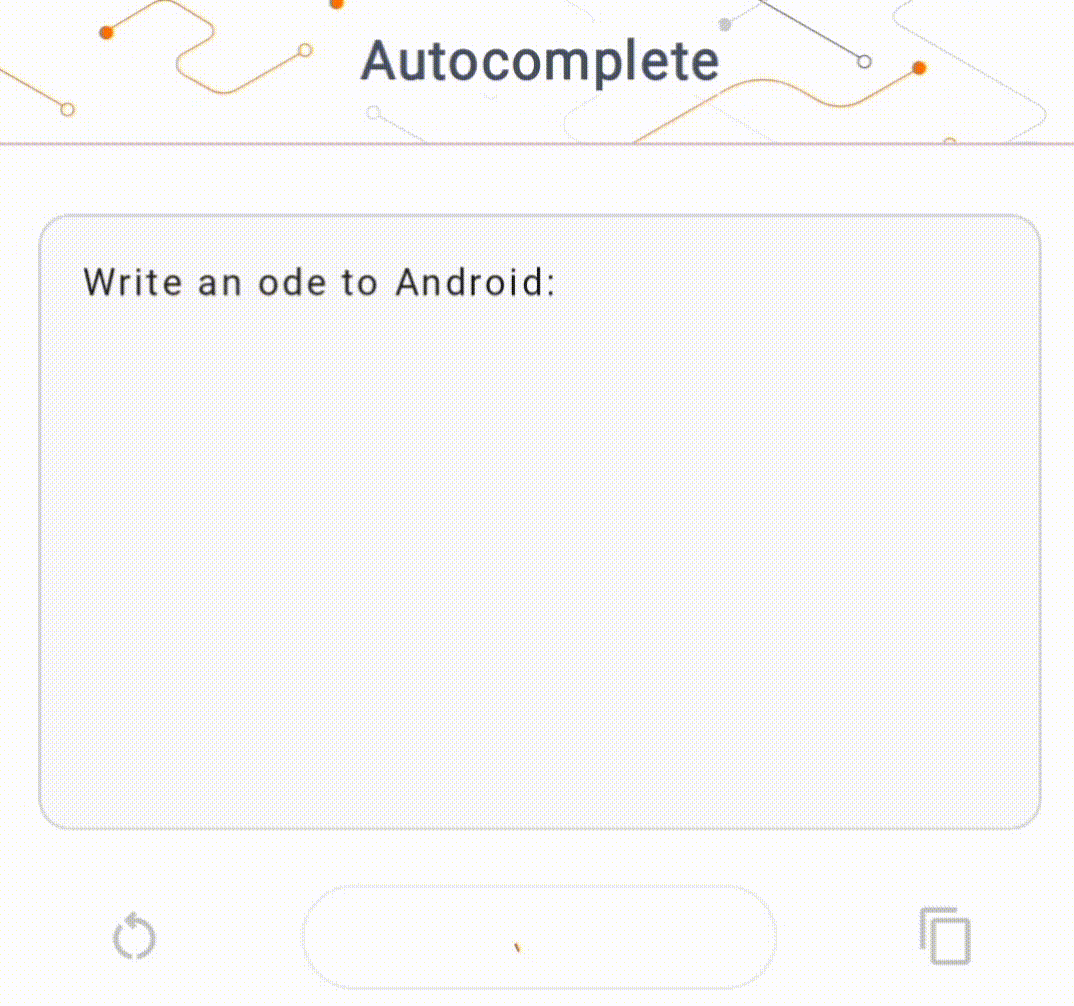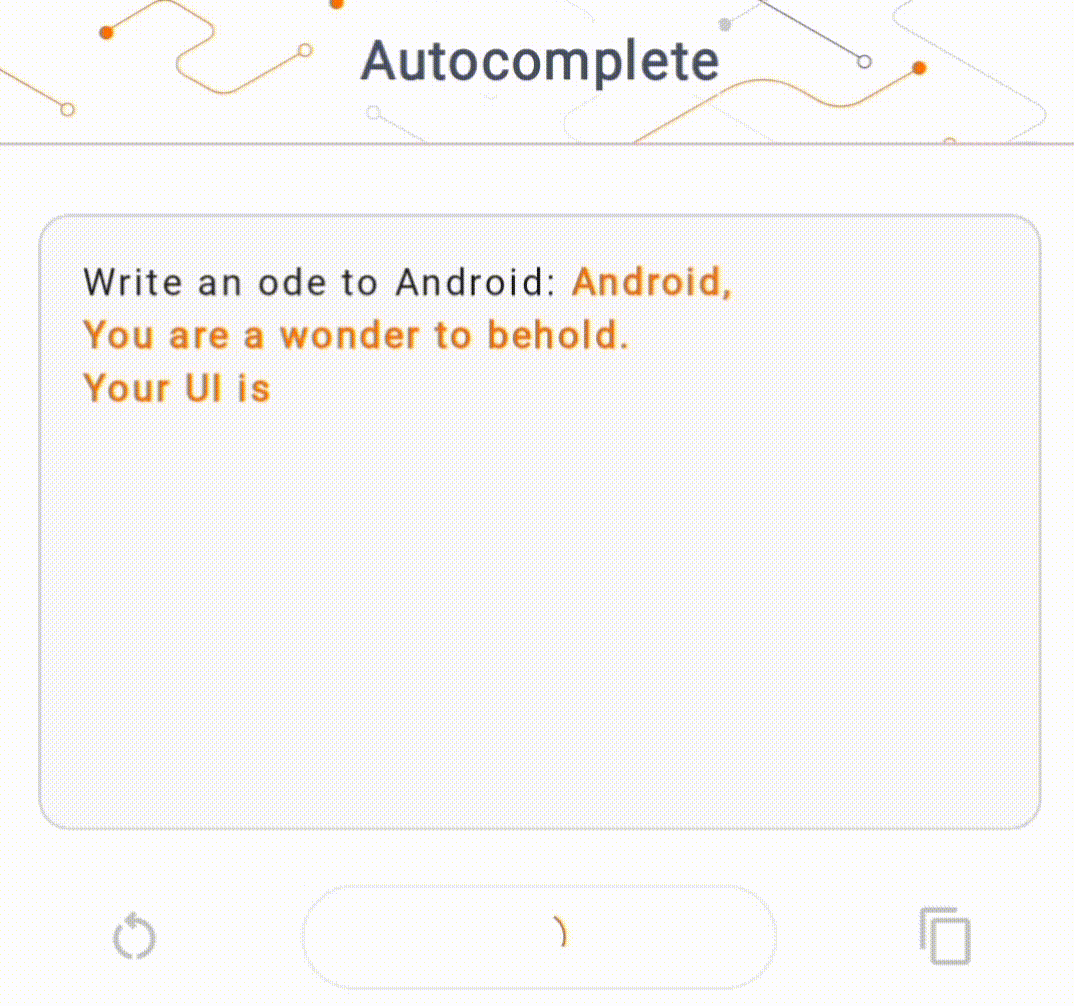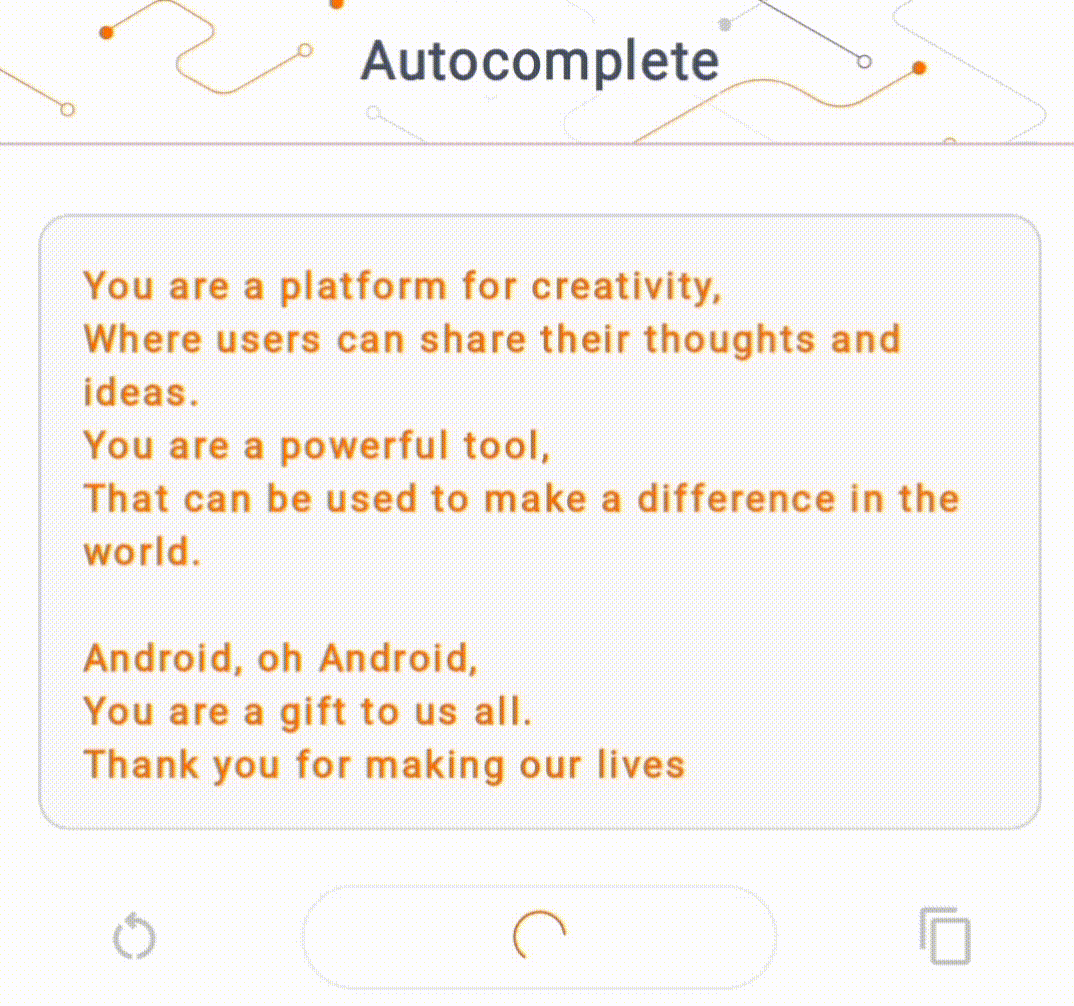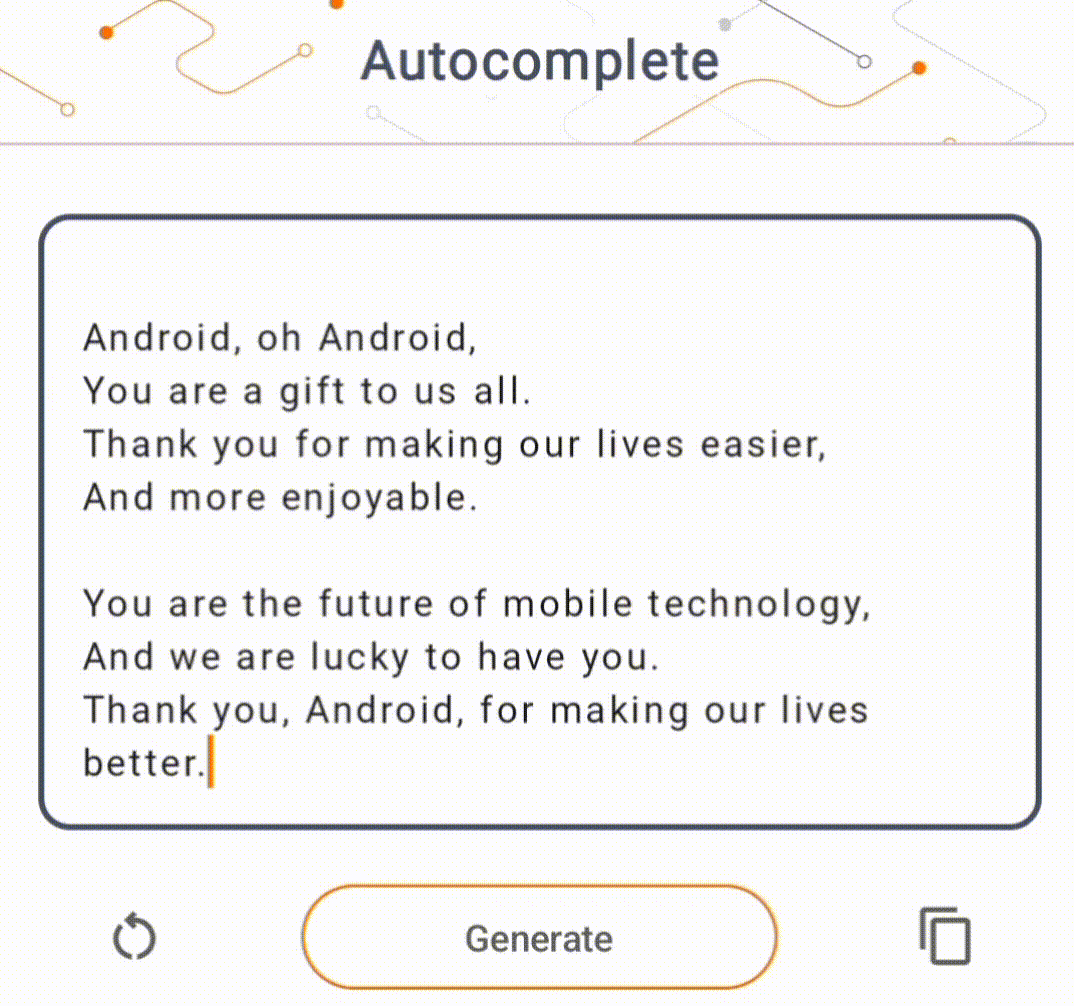
Kılavuzlar
Model yazma
Bu gösterimde GPT-2 modelini elde etmek için KerasNLP'yi kullanacağız. KerasNLP, doğal dil işleme görevleri için son teknolojiye sahip, önceden eğitilmiş modeller içeren ve kullanıcıları tüm geliştirme döngüsü boyunca destekleyebilen bir kütüphanedir. KerasNLP deposunda mevcut modellerin listesini görebilirsiniz. İş akışları, kullanıma hazır kullanıldığında son teknoloji ürünü önceden ayarlanmış ağırlıklara ve mimarilere sahip modüler bileşenlerden oluşturulmuştur ve daha fazla kontrol gerektiğinde kolayca özelleştirilebilir. GPT-2 modelini oluşturmak aşağıdaki adımlarla yapılabilir:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Bu üç kod satırı arasındaki ortak noktalardan biri, Keras API'sinin bir kısmını önceden ayarlanmış bir mimariden ve/veya ağırlıklardan başlatacak ve dolayısıyla önceden eğitilmiş modeli yükleyecek olan from_preset() yöntemidir. Bu kod parçacığında ayrıca üç modüler bileşen göreceksiniz:
Tokenizer : ham dize girişini Keras Gömme katmanına uygun tamsayı belirteç kimliklerine dönüştürür. GPT-2, özellikle bayt çifti kodlama (BPE) belirteçleyicisini kullanır.
Önişlemci : Keras modeline beslenecek girdileri tokenize etmek ve paketlemek için katman. Burada ön işlemci, tokenleştirme sonrasında token kimliklerinin tensörünü belirli bir uzunluğa (256) kadar dolduracaktır.
Omurga : SoTA trafo omurga mimarisini takip eden ve önceden ayarlanmış ağırlıklara sahip Keras modeli.
Ayrıca GitHub'da GPT-2 modelinin tam uygulamasına göz atabilirsiniz.
Model dönüşümü
TensorFlow Lite, mobil cihazlarda, mikro denetleyicilerde ve diğer uç cihazlarda yöntemlerin dağıtımına yönelik bir mobil kitaplıktır. İlk adım, TensorFlow Lite dönüştürücüyü kullanarak bir Keras modelini daha kompakt bir TensorFlow Lite formatına dönüştürmek ve ardından dönüştürülen modeli çalıştırmak için mobil cihazlar için yüksek düzeyde optimize edilmiş TensorFlow Lite yorumlayıcısını kullanmaktır.
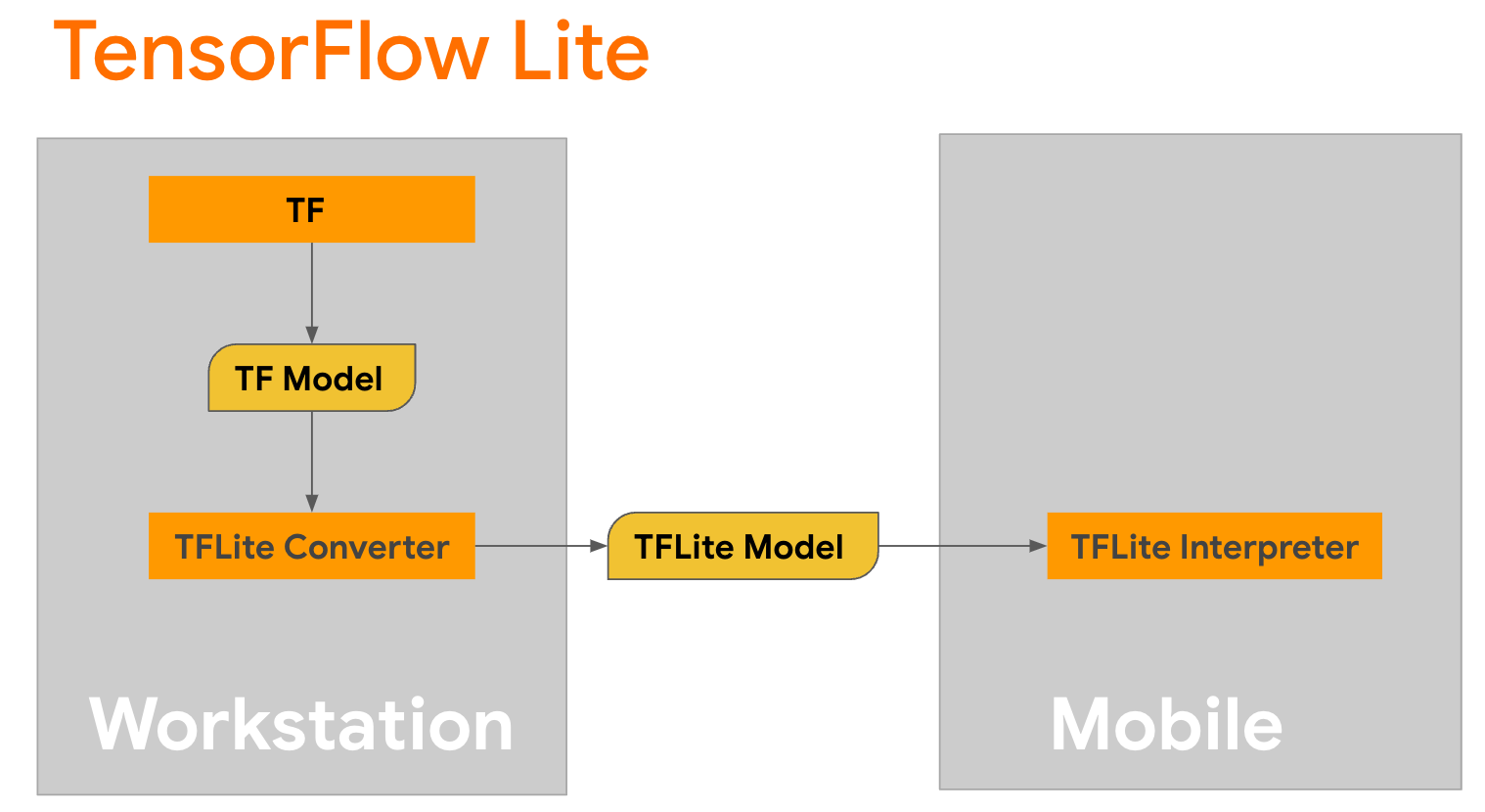 Dönüşümü gerçekleştiren
Dönüşümü gerçekleştiren GPT2CausalLM generate() işleviyle başlayın. Somut bir TensorFlow işlevi oluşturmak için generate() işlevini sarın:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Dönüşümü gerçekleştirmek için TFLiteConverter from_keras_model() işlevini de kullanabileceğinizi unutmayın.
Şimdi bir giriş ve TFLite modeliyle çıkarımı çalıştıracak bir yardımcı fonksiyon tanımlayın. TensorFlow metin işlemleri, TFLite çalışma zamanında yerleşik işlemler değildir, dolayısıyla yorumlayıcının bu model üzerinde çıkarım yapabilmesi için bu özel işlemleri eklemeniz gerekecektir. Bu yardımcı işlev, bir girdiyi ve dönüşümü gerçekleştiren bir işlevi, yani yukarıda tanımlanan generator() işlevini kabul eder.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Modeli şimdi dönüştürebilirsiniz:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Niceleme
TensorFlow Lite, model boyutunu azaltabilen ve çıkarımı hızlandırabilen, niceleme adı verilen bir optimizasyon tekniğini uygulamaya koymuştur. Niceleme işlemi yoluyla, 32 bitlik değişkenler daha küçük 8 bitlik tamsayılarla eşlenir, bu nedenle modern donanımlarda daha verimli yürütme için model boyutu 4 kat azaltılır. TensorFlow'da nicemleme yapmanın birkaç yolu vardır. Daha fazla bilgi için TFLite Model optimizasyonu ve TensorFlow Model Optimizasyon Araç Seti sayfalarını ziyaret edebilirsiniz. Kuantizasyon türleri aşağıda kısaca açıklanmıştır.
Burada, dönüştürücü optimizasyon işaretini tf.lite.Optimize.DEFAULT olarak ayarlayarak GPT-2 modelinde eğitim sonrası dinamik aralık nicelemesini kullanacaksınız ve dönüştürme işleminin geri kalanı daha önce ayrıntılı olarak açıklananla aynıdır. Bu niceleme tekniğiyle gecikmenin Pixel 7'de yaklaşık 6,7 saniye olduğunu ve maksimum çıkış uzunluğunun 100'e ayarlandığını test ettik.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Dinamik Aralık
Dinamik aralık nicelemesi, cihazdaki modelleri optimize etmek için önerilen başlangıç noktasıdır. Model boyutunda yaklaşık 4 kat azalma sağlayabilir ve kalibrasyon için temsili bir veri kümesi sağlamanıza gerek kalmadan daha az bellek kullanımı ve daha hızlı hesaplama sağladığından önerilen bir başlangıç noktasıdır. Bu tür niceleme, dönüşüm zamanında yalnızca kayan noktadan 8 bitlik tam sayıya kadar olan ağırlıkları statik olarak niceler.
FP16
Kayan nokta modelleri, ağırlıkların float16 tipine nicelendirilmesiyle de optimize edilebilir. Float16 nicelemenin avantajları, model boyutunu yarıya kadar azaltmak (tüm ağırlıklar boyutlarının yarısı kadar olacağından), doğrulukta minimum kayba neden olmak ve doğrudan float16 verileri üzerinde çalışabilen GPU delegelerini desteklemektir (bu, float32'ye göre daha hızlı hesaplamayla sonuçlanır). veri). Float16 ağırlıklarına dönüştürülen bir model, ek değişiklikler yapılmadan CPU üzerinde çalışmaya devam edebilir. Float16 ağırlıkları, ilk çıkarımdan önce float32'ye üst örneklenir; bu, gecikme ve doğruluk üzerinde minimum etki karşılığında model boyutunun küçültülmesine izin verir.
Tam Tamsayı Kuantizasyonu
Tam tamsayı nicemleme , ağırlıklar ve aktivasyonlar da dahil olmak üzere 32 bitlik kayan nokta sayılarını en yakın 8 bitlik tam sayılara dönüştürür. Bu tür niceleme, mikrokontrolörler kullanıldığında inanılmaz derecede değerli olan, çıkarım hızının arttığı daha küçük bir modelle sonuçlanır. Aktivasyonlar nicelemeye duyarlı olduğunda bu mod önerilir.
Android Uygulama entegrasyonu
TFLite modelinizi bir Android Uygulamasına entegre etmek için bu Android örneğini takip edebilirsiniz.
Önkoşullar
Henüz yapmadıysanız web sitesindeki talimatları izleyerek Android Studio'yu yükleyin.
- Android Studio 2022.2.1 veya üzeri.
- 4G'den fazla belleğe sahip bir Android cihazı veya Android emülatörü
Android Studio ile Oluşturma ve Çalıştırma
- Android Studio'yu açın ve Hoş Geldiniz ekranından Mevcut bir Android Studio projesini aç'ı seçin.
- Görüntülenen Dosya veya Projeyi Aç penceresinde, TensorFlow Lite örnek GitHub deposunu klonladığınız yerden
lite/examples/generative_ai/androiddizinine gidin ve onu seçin. - Ayrıca hata mesajlarına göre çeşitli platform ve araçları da kurmanız gerekebilir.
- Dönüştürülen .tflite modelini
autocomplete.tfliteolarak yeniden adlandırın veapp/src/main/assets/klasörüne kopyalayın. - Uygulamayı oluşturmak için Oluştur -> Proje Yap menüsünü seçin. (Sürümünüze bağlı olarak Ctrl+F9).
- Çalıştır -> Çalıştır 'uygulamasını' tıklayın. (Shift+F10, sürümünüze bağlı olarak)
Alternatif olarak, komut satırında oluşturmak için gradle sarmalayıcıyı da kullanabilirsiniz. Daha fazla bilgi için lütfen Gradle belgelerine bakın.
(İsteğe bağlı) .aar dosyasını oluşturma
Varsayılan olarak uygulama gerekli .aar dosyalarını otomatik olarak indirir. Ancak kendinizinkini oluşturmak istiyorsanız, app/libs/build_aar/ klasörüne (run ./build_aar.sh ) geçin. Bu komut dosyası, TensorFlow Text'ten gerekli işlemleri alacak ve Select TF operatörleri için aar'ı oluşturacaktır.
Derlemeden sonra yeni bir tftext_tflite_flex.aar dosyası oluşturulur. app/libs/ klasöründeki .aar dosyasını değiştirin ve uygulamayı yeniden oluşturun.
Hala standart tensorflow-lite aar'ı gradle dosyanıza eklemeniz gerektiğini unutmayın.
Bağlam penceresi boyutu

Uygulamanın değiştirilebilir bir 'bağlam penceresi boyutu' parametresi vardır; bu gereklidir, çünkü günümüzde Yüksek Lisans'lar genel olarak modele 'istem' olarak kaç kelimenin/belirtecin beslenebileceğini sınırlayan sabit bir bağlam boyutuna sahiptir ('kelime'nin zorunlu olarak zorunlu olmadığını unutmayın) farklı tokenleştirme yöntemleri nedeniyle bu durumda 'jeton'a eşdeğerdir). Bu sayı önemlidir çünkü:
- Çok küçük ayarlarsanız model, anlamlı çıktı üretmek için yeterli bağlama sahip olmayacaktır.
- Bunu çok büyük ayarlarsanız modelde çalışmak için yeterli alan kalmaz (çıkış sırası istemi de içerdiğinden)
Bununla denemeler yapabilirsiniz, ancak bunu çıkış dizisi uzunluğunun ~%50'sine ayarlamak iyi bir başlangıçtır.
Güvenlik ve Sorumlu Yapay Zeka
Orijinal OpenAI GPT-2 duyurusunda belirtildiği gibi, GPT-2 modelinde dikkate değer uyarılar ve sınırlamalar bulunmaktadır. Aslına bakılırsa, günümüzde Yüksek Lisans'ların genellikle halüsinasyonlar, adalet ve önyargı gibi iyi bilinen bazı zorlukları vardır; Bunun nedeni, bu modellerin gerçek dünya verileriyle eğitilmiş olması ve bu sayede gerçek dünya sorunlarını yansıtmalarıdır.
Bu codelab yalnızca TensorFlow araçlarıyla Yüksek Lisans'lar tarafından desteklenen bir uygulamanın nasıl oluşturulacağını göstermek için oluşturulmuştur. Bu codelab'de üretilen model yalnızca eğitim amaçlıdır ve üretimde kullanıma yönelik değildir.
Yüksek Lisans üretim kullanımı, eğitim veri kümelerinin dikkatli bir şekilde seçilmesini ve kapsamlı güvenlik azaltımlarını gerektirir. Bu Android uygulamasında sunulan işlevselliklerden biri, kötü kullanıcı girişlerini veya model çıktılarını reddeden küfür filtresidir. Uygunsuz bir dil tespit edilirse uygulama, karşılığında bu eylemi reddeder. Yüksek Lisans bağlamında Sorumlu Yapay Zeka hakkında daha fazla bilgi edinmek için Google I/O 2023'teki Üretken Dil Modelleriyle Güvenli ve Sorumlu Gelişim teknik oturumunu izlediğinizden emin olun ve Sorumlu Yapay Zeka Araç Takımı'na göz atın.