
| | |
مقدمة
نماذج اللغات الكبيرة (LLMs) هي فئة من نماذج التعلم الآلي التي يتم تدريبها لإنشاء نص بناءً على مجموعات بيانات كبيرة. يمكن استخدامها لمهام معالجة اللغة الطبيعية (NLP)، بما في ذلك إنشاء النص والإجابة على الأسئلة والترجمة الآلية. إنهم يعتمدون على بنية المحولات ويتم تدريبهم على كميات هائلة من البيانات النصية، والتي غالبًا ما تتضمن مليارات الكلمات. حتى حاملي شهادات LLM ذات النطاق الأصغر، مثل GPT-2، يمكنهم تقديم أداء مثير للإعجاب. إن تحويل نماذج TensorFlow إلى نموذج أخف وأسرع ومنخفض الطاقة يسمح لنا بتشغيل نماذج الذكاء الاصطناعي التوليدية على الجهاز، مع فوائد تحسين أمان المستخدم لأن البيانات لن تترك جهازك أبدًا.
يوضح لك دليل التشغيل هذا كيفية إنشاء تطبيق Android باستخدام TensorFlow Lite لتشغيل Keras LLM ويقدم اقتراحات لتحسين النموذج باستخدام تقنيات القياس، والتي بخلاف ذلك قد تتطلب قدرًا أكبر من الذاكرة وقدرة حسابية أكبر للتشغيل.
لقد قمنا بفتح إطار عمل تطبيق Android الخاص بنا والذي يمكن لأي برنامج TFLite LLMs متوافق توصيله. فيما يلي عرضان تجريبيان:
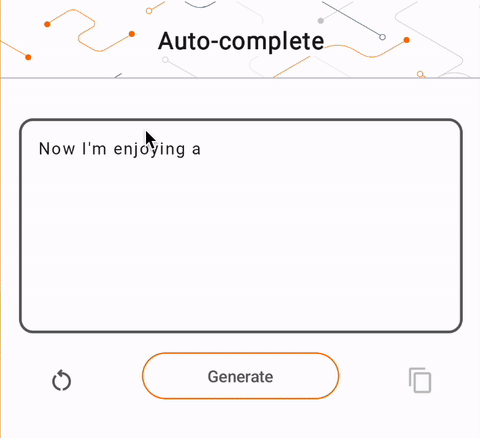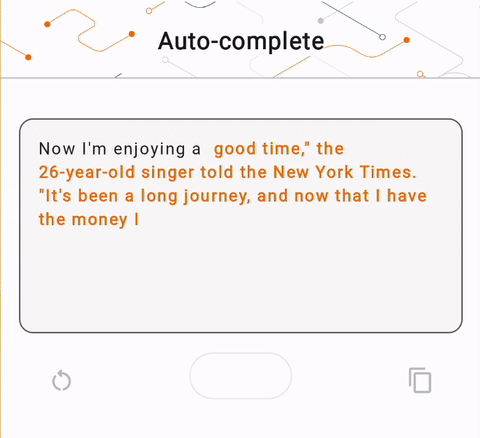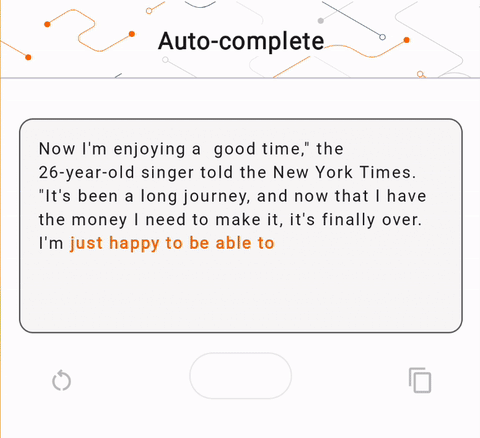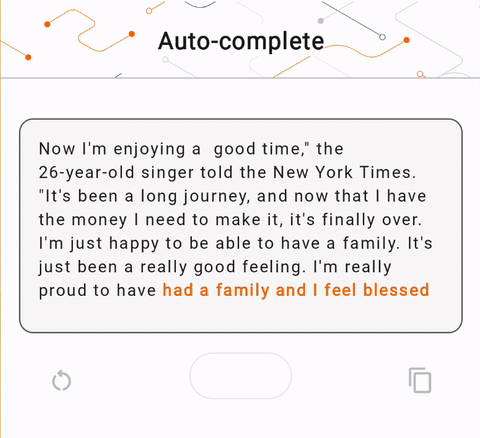
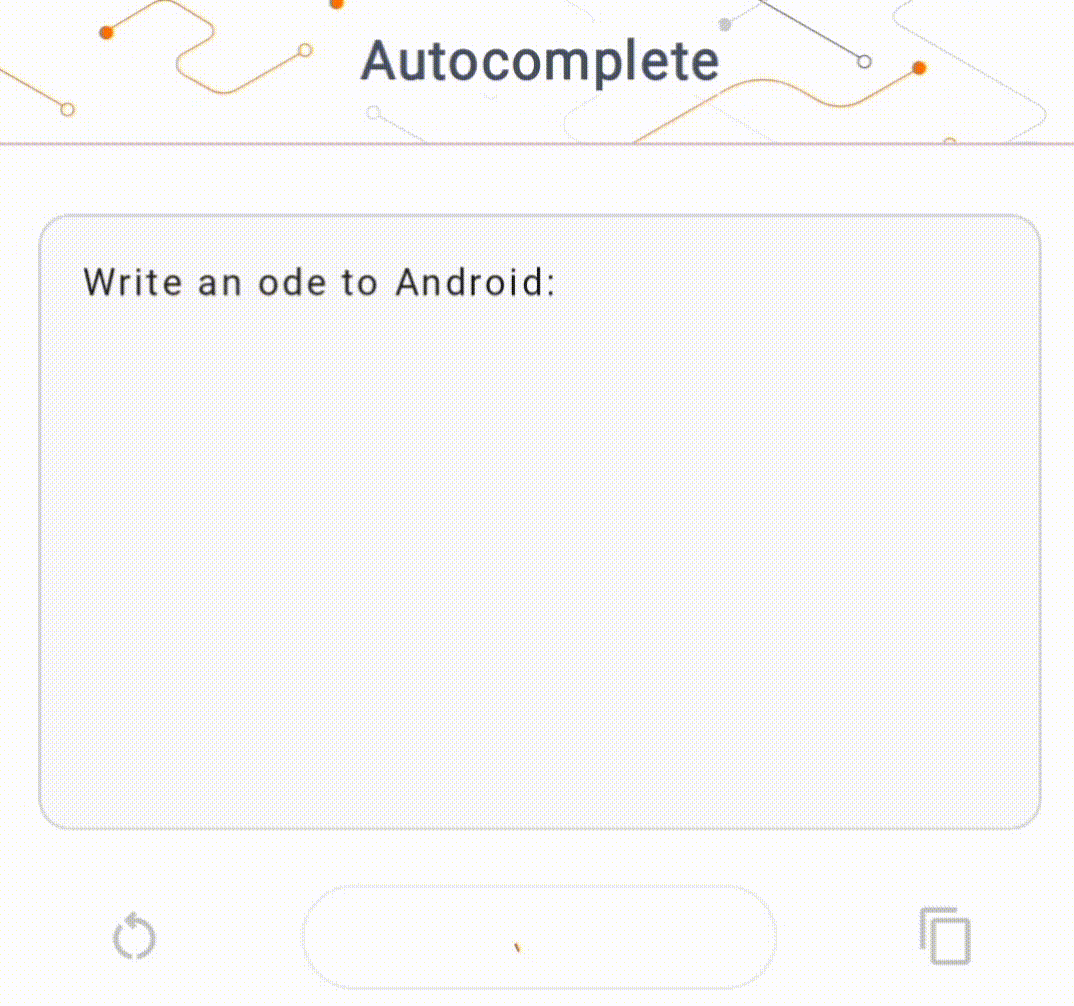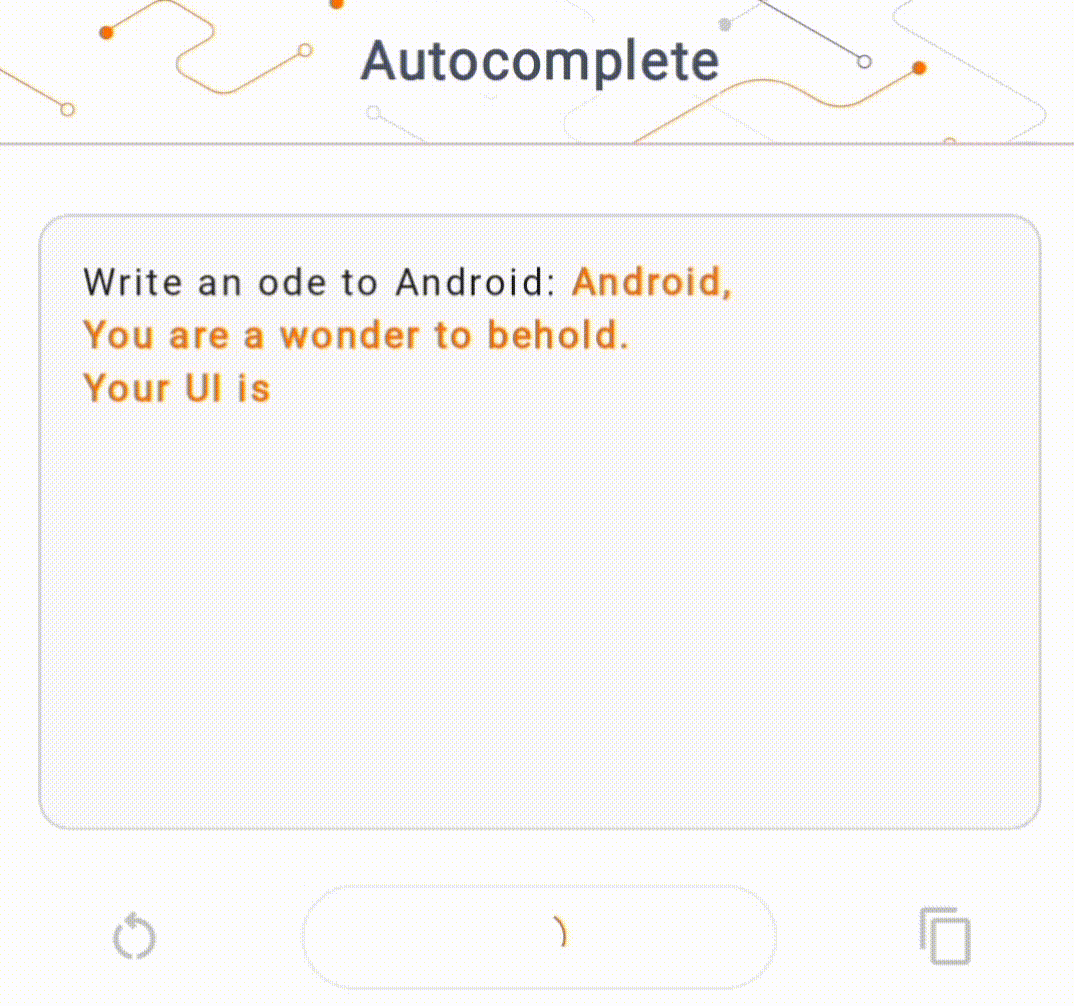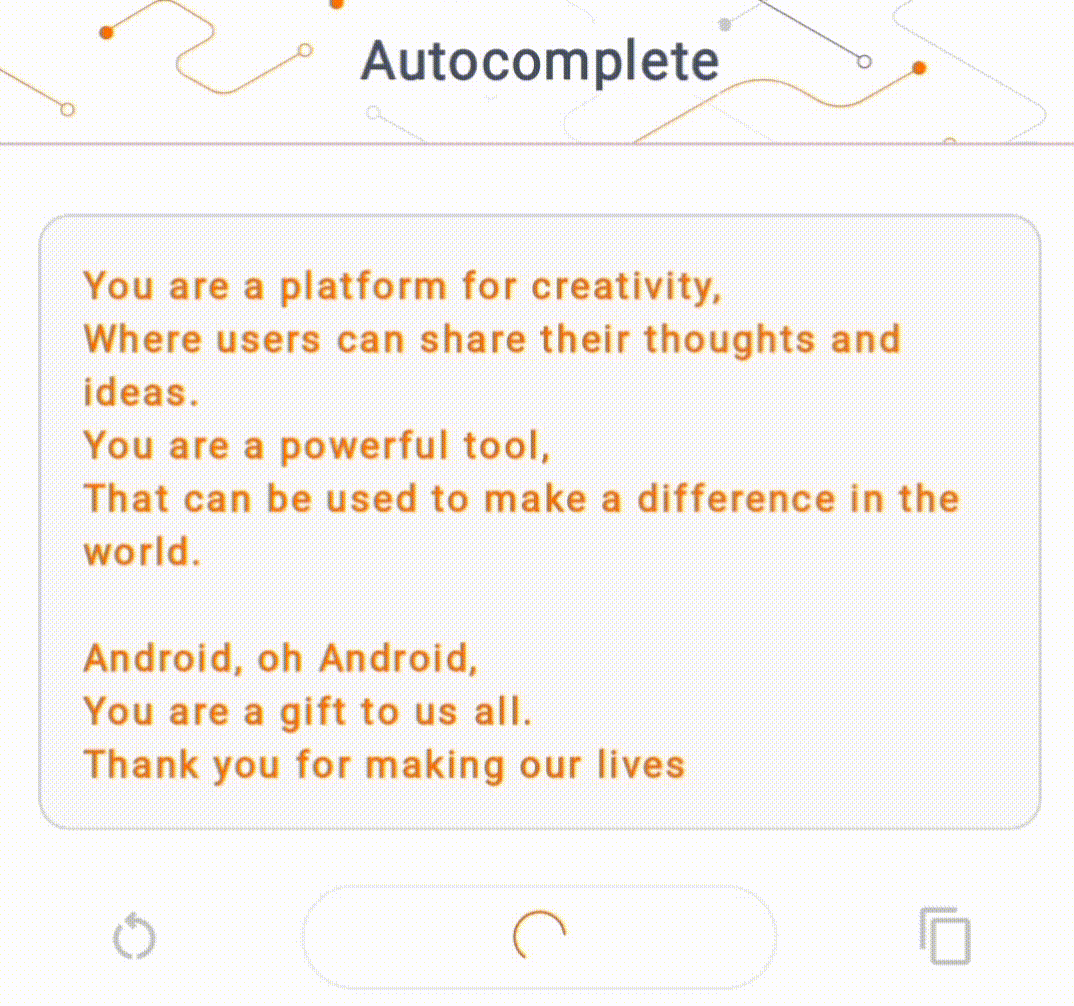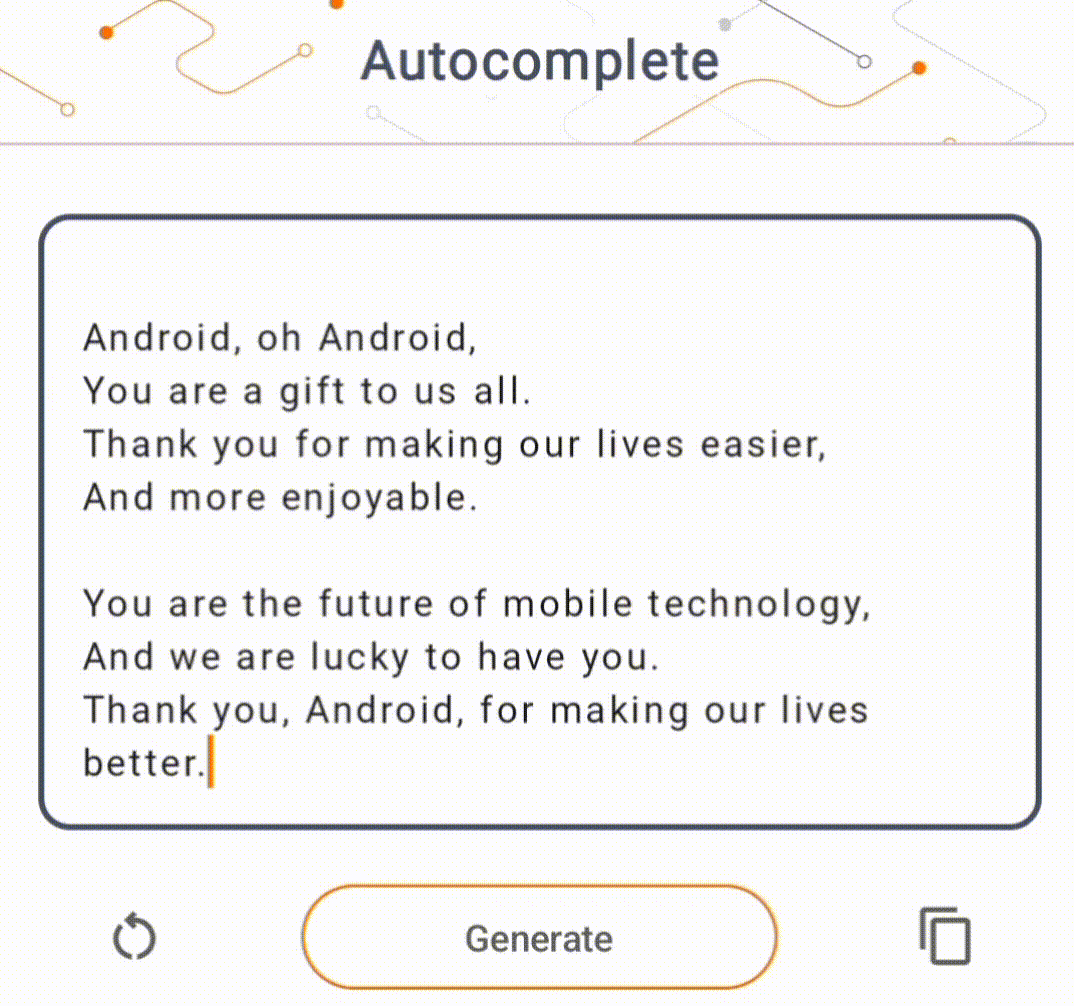
- في الشكل 1، استخدمنا نموذج Keras GPT-2 لتنفيذ مهام إكمال النص على الجهاز.
- في الشكل 2، قمنا بتحويل نسخة من نموذج PaLM المضبوط للتعليمات (1.5 مليار معلمة) إلى TFLite وتم تنفيذها من خلال وقت تشغيل TFLite.
خطوط إرشاد
التأليف النموذجي
في هذا العرض التوضيحي، سوف نستخدم KerasNLP للحصول على نموذج GPT-2. KerasNLP هي مكتبة تحتوي على أحدث النماذج المدربة مسبقًا لمهام معالجة اللغة الطبيعية، ويمكنها دعم المستخدمين خلال دورة التطوير بأكملها. يمكنك الاطلاع على قائمة النماذج المتوفرة في مستودع KerasNLP . يتم إنشاء سير العمل من مكونات معيارية تتمتع بأوزان وبنيات حديثة محددة مسبقًا عند استخدامها خارج الصندوق ويمكن تخصيصها بسهولة عند الحاجة إلى مزيد من التحكم. يمكن إنشاء نموذج GPT-2 من خلال الخطوات التالية:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
إحدى القواسم المشتركة بين هذه الأسطر الثلاثة من التعليمات البرمجية هي طريقة from_preset() ، والتي ستعمل على إنشاء مثيل لجزء Keras API من بنية و/أو أوزان محددة مسبقًا، وبالتالي تحميل النموذج المُدرب مسبقًا. من مقتطف الشفرة هذا، ستلاحظ أيضًا ثلاثة مكونات معيارية:
Tokenizer : يحول إدخال السلسلة الأولية إلى معرفات رمزية صحيحة مناسبة لطبقة Keras Embedding. يستخدم GPT-2 رمز ترميز زوج البايت (BPE) على وجه التحديد.
المعالج المسبق : طبقة لترميز وتعبئة المدخلات التي سيتم إدخالها في نموذج Keras. هنا، سيقوم المعالج المسبق بتوسيع موتر معرفات الرمز المميز إلى طول محدد (256) بعد الترميز.
العمود الفقري : نموذج Keras الذي يتبع بنية العمود الفقري لمحولات SoTA وله الأوزان المحددة مسبقًا.
بالإضافة إلى ذلك، يمكنك التحقق من التنفيذ الكامل لنموذج GPT-2 على GitHub .
تحويل النموذج
TensorFlow Lite عبارة عن مكتبة متنقلة لنشر الأساليب على الأجهزة المحمولة ووحدات التحكم الدقيقة وأجهزة الحافة الأخرى. الخطوة الأولى هي تحويل نموذج Keras إلى تنسيق TensorFlow Lite أكثر إحكاما باستخدام محول TensorFlow Lite، ثم استخدام مترجم TensorFlow Lite، الذي تم تحسينه بدرجة كبيرة للأجهزة المحمولة، لتشغيل النموذج المحول.
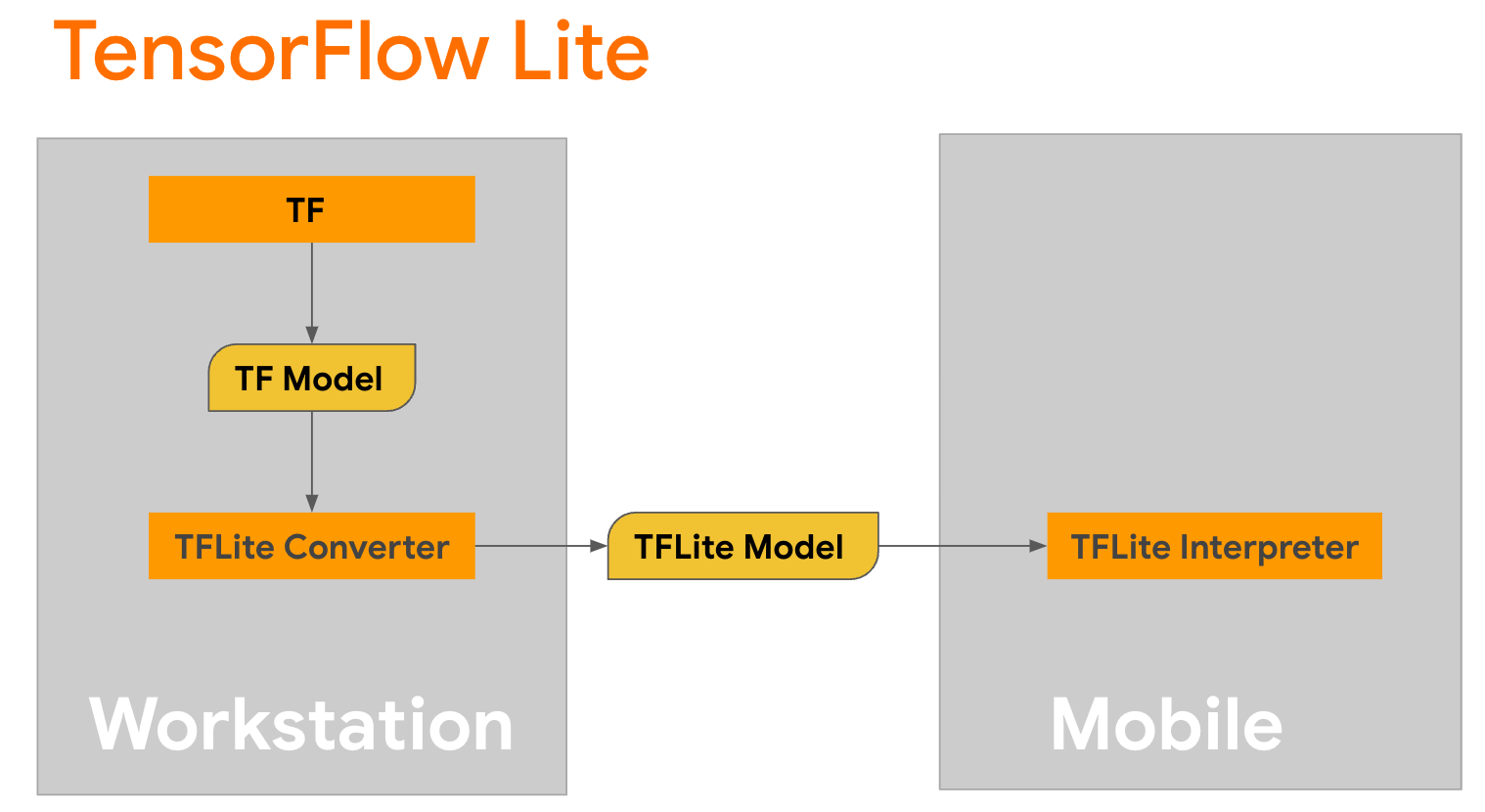 ابدأ باستخدام وظيفة
ابدأ باستخدام وظيفة generate() من GPT2CausalLM التي تقوم بإجراء التحويل. لف وظيفة generate() لإنشاء وظيفة TensorFlow ملموسة:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
لاحظ أنه يمكنك أيضًا استخدام from_keras_model() من TFLiteConverter لإجراء التحويل.
الآن حدد وظيفة مساعدة ستقوم بتشغيل الاستدلال باستخدام مدخلات ونموذج TFLite. عمليات النص TensorFlow ليست عمليات مدمجة في وقت تشغيل TFLite، لذلك ستحتاج إلى إضافة هذه العمليات المخصصة حتى يتمكن المترجم من الاستدلال على هذا النموذج. تقبل هذه الوظيفة المساعدة إدخالاً ووظيفة تقوم بإجراء التحويل، وهي وظيفة generator() المحددة أعلاه.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
يمكنك تحويل النموذج الآن:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
توضيح
طبق TensorFlow Lite تقنية تحسين تسمى التكميم والتي يمكنها تقليل حجم النموذج وتسريع الاستدلال. من خلال عملية التكميم، يتم تعيين العوامات 32 بت إلى أعداد صحيحة أصغر 8 بت، وبالتالي تقليل حجم النموذج بعامل 4 من أجل تنفيذ أكثر كفاءة على الأجهزة الحديثة. هناك عدة طرق للقيام بالتكميم في TensorFlow. يمكنك زيارة صفحات تحسين نموذج TFLite ومجموعة أدوات تحسين نموذج TensorFlow لمزيد من المعلومات. يتم شرح أنواع الكميات بإيجاز أدناه.
هنا، ستستخدم تقدير النطاق الديناميكي بعد التدريب على نموذج GPT-2 عن طريق تعيين علامة تحسين المحول على tf.lite.Optimize.DEFAULT ، وبقية عملية التحويل هي نفسها كما هو مفصل من قبل. لقد اختبرنا أنه باستخدام تقنية التكميم هذه، يبلغ زمن الوصول حوالي 6.7 ثانية على Pixel 7 مع ضبط الحد الأقصى لطول الإخراج على 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
النطاق الديناميكي
يُعد تكميم النطاق الديناميكي نقطة البداية الموصى بها لتحسين النماذج الموجودة على الجهاز. يمكن أن يؤدي ذلك إلى تقليل حجم النموذج بمقدار 4 أضعاف تقريبًا، ويُعد نقطة بداية موصى بها لأنه يوفر استخدامًا أقل للذاكرة وحسابًا أسرع دون الحاجة إلى توفير مجموعة بيانات تمثيلية للمعايرة. يقوم هذا النوع من القياس الكمي بشكل ثابت فقط بتكميم الأوزان من النقطة العائمة إلى عدد صحيح 8 بت في وقت التحويل.
FP16
يمكن أيضًا تحسين نماذج النقطة العائمة عن طريق تحديد كمية الأوزان للنوع float16. تتمثل مزايا تكمية float16 في تقليل حجم النموذج بما يصل إلى النصف (حيث تصبح جميع الأوزان نصف حجمها)، مما يتسبب في الحد الأدنى من فقدان الدقة، ودعم مندوبي GPU الذين يمكنهم العمل مباشرة على بيانات float16 (مما يؤدي إلى حساب أسرع من float32) بيانات). لا يزال من الممكن تشغيل النموذج الذي تم تحويله إلى أوزان float16 على وحدة المعالجة المركزية دون تعديلات إضافية. يتم مضاعفة أوزان float16 إلى float32 قبل الاستدلال الأول، مما يسمح بتقليل حجم النموذج مقابل الحد الأدنى من التأثير على زمن الوصول والدقة.
تكمية الأعداد الصحيحة الكاملة
يعمل تكميم الأعداد الصحيحة الكاملة على تحويل أرقام الفاصلة العائمة ذات 32 بت، بما في ذلك الأوزان وعمليات التنشيط، إلى أقرب أعداد صحيحة ذات 8 بتات. يؤدي هذا النوع من التكميم إلى نموذج أصغر مع زيادة سرعة الاستدلال، وهو أمر ذو قيمة كبيرة عند استخدام وحدات التحكم الدقيقة. يوصى بهذا الوضع عندما تكون عمليات التنشيط حساسة للتكميم.
تكامل تطبيقات أندرويد
يمكنك اتباع مثال Android هذا لدمج طراز TFLite الخاص بك في تطبيق Android.
المتطلبات الأساسية
إذا لم تكن قد قمت بذلك بالفعل، فقم بتثبيت Android Studio ، باتباع الإرشادات الموجودة على موقع الويب.
- أندرويد ستوديو 2022.2.1 أو أعلى.
- جهاز Android أو محاكي Android مزود بذاكرة تزيد عن 4G
البناء والتشغيل باستخدام Android Studio
- افتح Android Studio، ومن شاشة الترحيب، حدد فتح مشروع Android Studio موجود .
- من نافذة Open File أو Project التي تظهر، انتقل إلى دليل
lite/examples/generative_ai/androidوحدده من أي مكان قمت باستنساخ نموذج TensorFlow Lite من GitHub repo فيه. - قد تحتاج أيضًا إلى تثبيت منصات وأدوات مختلفة وفقًا لرسائل الخطأ.
- أعد تسمية نموذج .tflite المحول إلى
autocomplete.tfliteوانسخه إلى المجلدapp/src/main/assets/. - حدد القائمة Build -> Make Project لإنشاء التطبيق. (Ctrl+F9، حسب الإصدار الخاص بك).
- انقر فوق القائمة تشغيل -> تشغيل "التطبيق" . (Shift+F10، حسب الإصدار لديك)
وبدلاً من ذلك، يمكنك أيضًا استخدام مجمّع Gradle لإنشائه في سطر الأوامر. يرجى الرجوع إلى وثائق Gradle لمزيد من المعلومات.
(اختياري) إنشاء ملف .aar
افتراضيًا، يقوم التطبيق تلقائيًا بتنزيل ملفات .aar المطلوبة. ولكن إذا كنت ترغب في إنشاء ملف خاص بك، فانتقل إلى المجلد app/libs/build_aar/ run ./build_aar.sh . سيقوم هذا البرنامج النصي بسحب العمليات الضرورية من TensorFlow Text وإنشاء aar لمشغلي Select TF.
بعد التجميع، يتم إنشاء ملف جديد tftext_tflite_flex.aar . استبدل ملف .aar في المجلد app/libs/ وأعد إنشاء التطبيق.
لاحظ أنك لا تزال بحاجة إلى تضمين tensorflow-lite aar القياسي في ملف gradle الخاص بك.
حجم نافذة السياق
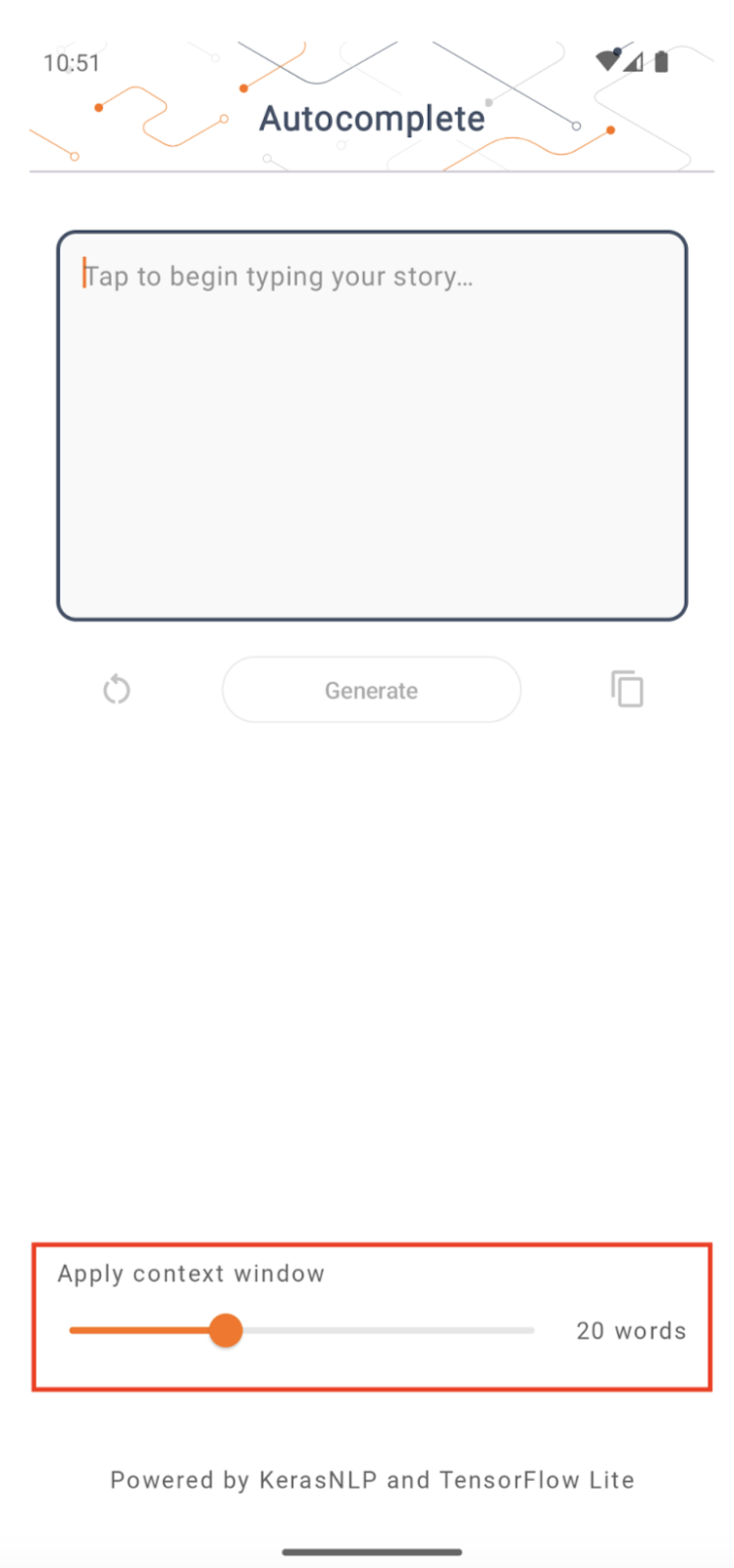
يحتوي التطبيق على معلمة قابلة للتغيير "حجم نافذة السياق"، وهو أمر ضروري لأن LLMs اليوم بشكل عام لديها حجم سياق ثابت مما يحد من عدد الكلمات/الرموز المميزة التي يمكن إدخالها في النموذج كـ "مطالبة" (لاحظ أن كلمة "word" ليست بالضرورة يعادل "الرمز المميز" في هذه الحالة، نظرًا لاختلاف طرق الترميز). وهذا الرقم مهم لأنه:
- إذا تم تحديده بشكل صغير جدًا، فلن يكون للنموذج سياق كافٍ لإنشاء مخرجات ذات معنى
- عند ضبطه على حجم كبير جدًا، لن يكون للنموذج مساحة كافية للعمل به (نظرًا لأن تسلسل الإخراج يشمل الموجه)
يمكنك تجربتها، لكن ضبطها على 50% تقريبًا من طول تسلسل الإخراج يعد بداية جيدة.
السلامة والذكاء الاصطناعي المسؤول
كما هو مذكور في إعلان OpenAI GPT-2 الأصلي، هناك محاذير وقيود ملحوظة في نموذج GPT-2. في الواقع، تواجه LLMs اليوم عمومًا بعض التحديات المعروفة مثل الهلوسة، والإنصاف، والتحيز؛ وذلك لأن هذه النماذج يتم تدريبها على بيانات العالم الحقيقي، مما يجعلها تعكس قضايا العالم الحقيقي.
تم إنشاء هذا الدرس التطبيقي حول التعليمات البرمجية فقط لتوضيح كيفية إنشاء تطبيق مدعوم من LLMs باستخدام أدوات TensorFlow. النموذج الذي تم إنتاجه في هذا الدرس التطبيقي للبرمجة مخصص للأغراض التعليمية فقط وليس مخصصًا للاستخدام الإنتاجي.
يتطلب استخدام إنتاج LLM اختيارًا مدروسًا لمجموعات بيانات التدريب وإجراءات تخفيف شاملة للسلامة. إحدى هذه الوظائف المقدمة في تطبيق Android هذا هي مرشح الألفاظ النابية، الذي يرفض مدخلات المستخدم السيئة أو مخرجات النموذج. إذا تم اكتشاف أي لغة غير لائقة، فسيقوم التطبيق في المقابل برفض هذا الإجراء. لمعرفة المزيد حول الذكاء الاصطناعي المسؤول في سياق LLMs، تأكد من مشاهدة الجلسة الفنية للتطوير الآمن والمسؤول باستخدام نماذج اللغة التوليدية في Google I/O 2023 وراجع مجموعة أدوات الذكاء الاصطناعي المسؤول .