
| | |
Introducción
Los modelos de lenguaje extenso (LLM) son una clase de modelos de aprendizaje automático que están capacitados para generar texto basado en grandes conjuntos de datos. Se pueden usar para tareas de procesamiento de lenguaje natural (NLP), incluida la generación de texto, la respuesta a preguntas y la traducción automática. Se basan en la arquitectura de Transformer y se entrenan en cantidades masivas de datos de texto, que a menudo involucran miles de millones de palabras. Incluso los LLM de menor escala, como GPT-2, pueden funcionar de manera impresionante. Convertir los modelos de TensorFlow en un modelo más liviano, rápido y de bajo consumo nos permite ejecutar modelos generativos de IA en el dispositivo, con los beneficios de una mejor seguridad para el usuario porque los datos nunca saldrán de su dispositivo.
Este runbook le muestra cómo compilar una aplicación de Android con TensorFlow Lite para ejecutar un LLM de Keras y brinda sugerencias para la optimización del modelo mediante técnicas de cuantificación, que de otro modo requerirían una cantidad mucho mayor de memoria y una mayor potencia computacional para ejecutarse.
Hemos abierto nuestro marco de aplicación de Android al que se puede conectar cualquier LLM TFLite compatible. Aquí hay dos demostraciones:
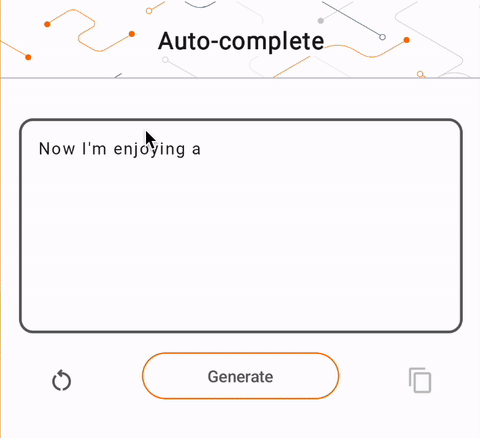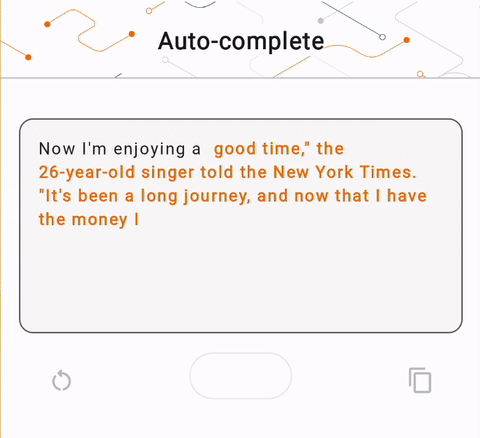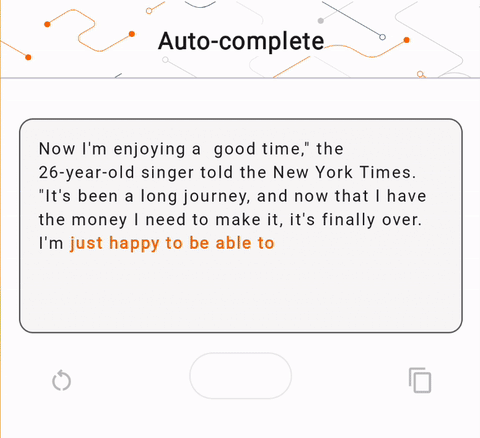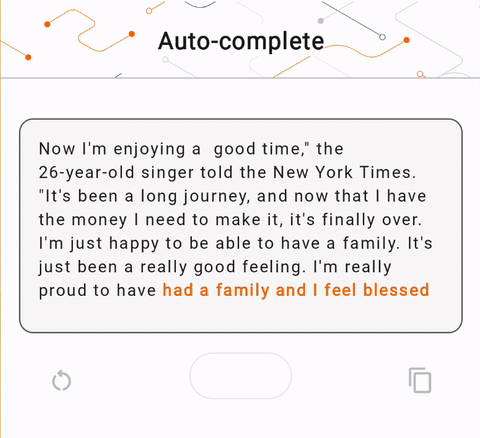
- En la Figura 1, usamos un modelo Keras GPT-2 para realizar tareas de finalización de texto en el dispositivo.
- En la Figura 2, convertimos una versión del modelo PaLM ajustado por instrucciones (1500 millones de parámetros) a TFLite y lo ejecutamos a través del tiempo de ejecución de TFLite.
Guías
Creación de modelos
Para esta demostración, usaremos KerasNLP para obtener el modelo GPT-2. KerasNLP es una biblioteca que contiene modelos preentrenados de última generación para tareas de procesamiento de lenguaje natural y puede ayudar a los usuarios durante todo su ciclo de desarrollo. Puedes ver la lista de modelos disponibles en el repositorio de KerasNLP . Los flujos de trabajo se construyen a partir de componentes modulares que tienen pesos y arquitecturas preestablecidos de última generación cuando se usan listos para usar y se pueden personalizar fácilmente cuando se necesita más control. La creación del modelo GPT-2 se puede hacer con los siguientes pasos:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Una característica común entre estas tres líneas de código es el método from_preset() , que creará una instancia de la parte de la API de Keras desde una arquitectura y/o pesos preestablecidos, por lo tanto, cargará el modelo preentrenado. A partir de este fragmento de código, también notará tres componentes modulares:
Tokenizer : convierte una entrada de cadena sin formato en identificadores de token enteros adecuados para una capa de incrustación de Keras. GPT-2 utiliza específicamente el tokenizador de codificación de pares de bytes (BPE).
Preprocesador : capa para tokenizar y empaquetar entradas para alimentar un modelo de Keras. Aquí, el preprocesador rellenará el tensor de identificadores de token a una longitud específica (256) después de la tokenización.
Backbone : modelo de Keras que sigue la arquitectura backbone del transformador SoTA y tiene los pesos preestablecidos.
Además, puede consultar la implementación completa del modelo GPT-2 en GitHub .
Conversión de modelo
TensorFlow Lite es una biblioteca móvil para implementar métodos en dispositivos móviles, microcontroladores y otros dispositivos perimetrales. El primer paso es convertir un modelo de Keras a un formato TensorFlow Lite más compacto mediante el convertidor TensorFlow Lite y luego usar el intérprete TensorFlow Lite, que está altamente optimizado para dispositivos móviles, para ejecutar el modelo convertido.
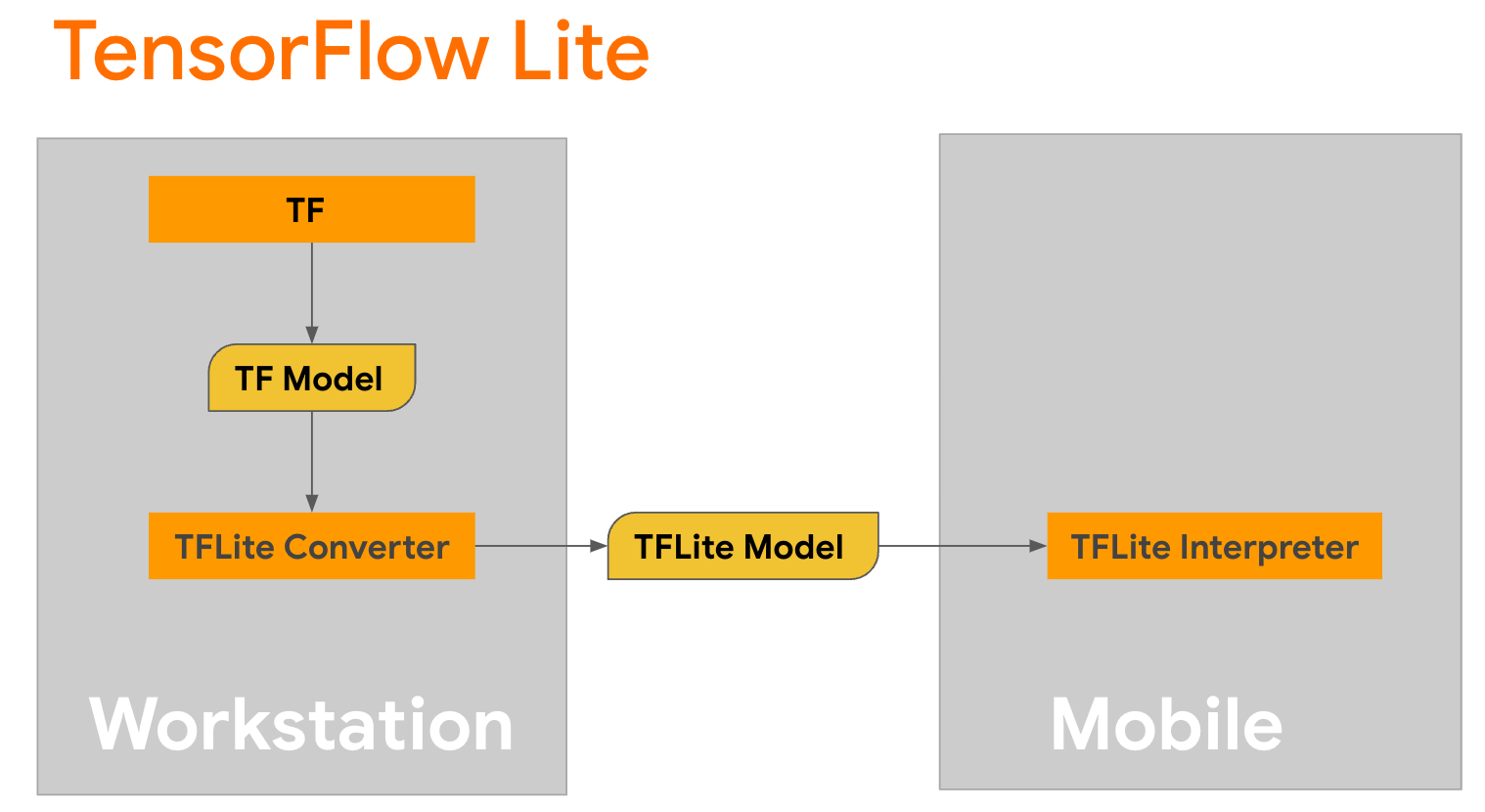 Comience con la función
Comience con la función generate() de GPT2CausalLM que realiza la conversión. Envuelva la función generate() para crear una función TensorFlow concreta:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Tenga en cuenta que también puede usar from_keras_model() de TFLiteConverter para realizar la conversión.
Ahora defina una función auxiliar que ejecutará la inferencia con una entrada y un modelo TFLite. Las operaciones de texto de TensorFlow no son operaciones integradas en el tiempo de ejecución de TFLite, por lo que deberá agregar estas operaciones personalizadas para que el intérprete haga inferencias en este modelo. Esta función auxiliar acepta una entrada y una función que realiza la conversión, a saber, la función generator() definida anteriormente.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Puede convertir el modelo ahora:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
cuantización
TensorFlow Lite ha implementado una técnica de optimización llamada cuantificación que puede reducir el tamaño del modelo y acelerar la inferencia. A través del proceso de cuantificación, los valores flotantes de 32 bits se asignan a enteros más pequeños de 8 bits, lo que reduce el tamaño del modelo en un factor de 4 para una ejecución más eficiente en hardware moderno. Hay varias formas de cuantificar en TensorFlow. Puede visitar las páginas de optimización del modelo TFLite y kit de herramientas de optimización del modelo TensorFlow para obtener más información. Los tipos de cuantificaciones se explican brevemente a continuación.
Aquí, utilizará la cuantificación del rango dinámico posterior al entrenamiento en el modelo GPT-2 configurando el indicador de optimización del convertidor en tf.lite.Optimize.DEFAULT , y el resto del proceso de conversión es el mismo que se detalló anteriormente. Probamos que con esta técnica de cuantificación, la latencia es de alrededor de 6,7 segundos en Pixel 7 con una longitud de salida máxima establecida en 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Gama dinámica
La cuantificación del rango dinámico es el punto de partida recomendado para optimizar los modelos en el dispositivo. Puede lograr una reducción de aproximadamente 4 veces en el tamaño del modelo y es un punto de partida recomendado, ya que proporciona un uso de memoria reducido y un cálculo más rápido sin tener que proporcionar un conjunto de datos representativo para la calibración. Este tipo de cuantificación cuantifica estáticamente solo los pesos desde el punto flotante hasta el entero de 8 bits en el momento de la conversión.
FP16
Los modelos de coma flotante también se pueden optimizar cuantificando los pesos al tipo float16. Las ventajas de la cuantificación de float16 son la reducción del tamaño del modelo a la mitad (ya que todos los pesos se convierten en la mitad de su tamaño), lo que provoca una pérdida mínima de precisión y admite delegados de GPU que pueden operar directamente en datos de float16 (lo que da como resultado un cálculo más rápido que en float32). datos). Un modelo convertido a pesos float16 aún puede ejecutarse en la CPU sin modificaciones adicionales. Los pesos de float16 se muestrean a float32 antes de la primera inferencia, lo que permite una reducción en el tamaño del modelo a cambio de un impacto mínimo en la latencia y la precisión.
Cuantificación completa de enteros
La cuantificación completa de enteros convierte los números de punto flotante de 32 bits, incluidos los pesos y las activaciones, a los enteros de 8 bits más cercanos. Este tipo de cuantificación da como resultado un modelo más pequeño con mayor velocidad de inferencia, lo que es increíblemente valioso cuando se usan microcontroladores. Este modo se recomienda cuando las activaciones son sensibles a la cuantización.
Integración de aplicaciones de Android
Puede seguir este ejemplo de Android para integrar su modelo TFLite en una aplicación de Android.
requisitos previos
Si aún no lo ha hecho, instale Android Studio , siguiendo las instrucciones del sitio web.
- Android Studio 2022.2.1 o superior.
- Un dispositivo Android o un emulador de Android con más de 4G de memoria
Construir y ejecutar con Android Studio
- Abra Android Studio y, en la pantalla de bienvenida, seleccione Abrir un proyecto de Android Studio existente .
- Desde la ventana Abrir archivo o proyecto que aparece, navegue y seleccione el directorio
lite/examples/generative_ai/androiddesde donde clonó el repositorio de GitHub de muestra de TensorFlow Lite. - También es posible que deba instalar varias plataformas y herramientas de acuerdo con los mensajes de error.
- Cambie el nombre del modelo .tflite convertido a
autocomplete.tflitey cópielo en la carpetaapp/src/main/assets/. - Seleccione el menú Build -> Make Project para construir la aplicación. (Ctrl+F9, según su versión).
- Haga clic en el menú Ejecutar -> Ejecutar 'aplicación' . (Shift+F10, dependiendo de su versión)
Alternativamente, también puede usar el contenedor gradle para construirlo en la línea de comando. Consulte la documentación de Gradle para obtener más información.
(Opcional) Creación del archivo .aar
De forma predeterminada, la aplicación descarga automáticamente los archivos .aar necesarios. Pero si desea crear el suyo propio, cambie a app/libs/build_aar/ folder run ./build_aar.sh . Este script extraerá las operaciones necesarias de TensorFlow Text y creará el aar para los operadores Select TF.
Después de la compilación, se genera un nuevo archivo tftext_tflite_flex.aar . Reemplace el archivo .aar en la carpeta app/libs/ y vuelva a compilar la aplicación.
Tenga en cuenta que aún debe incluir el estándar tensorflow-lite aar en su archivo gradle.
Tamaño de la ventana de contexto
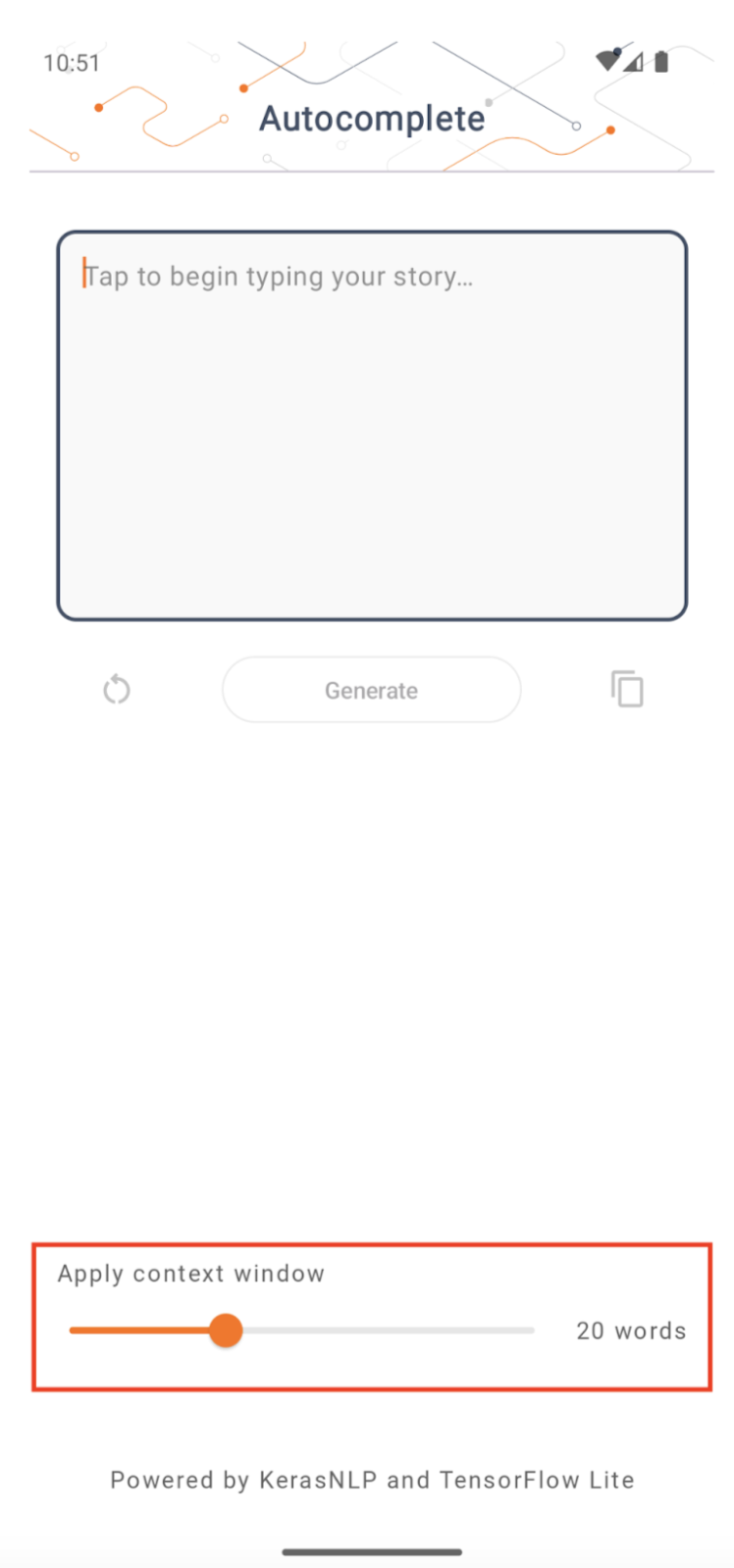
La aplicación tiene un parámetro modificable 'tamaño de ventana de contexto', que es necesario porque los LLM de hoy en día generalmente tienen un tamaño de contexto fijo que limita la cantidad de palabras/tokens que se pueden introducir en el modelo como 'mensaje' (tenga en cuenta que 'palabra' no es necesariamente equivalente a 'token' en este caso, debido a los diferentes métodos de tokenización). Este número es importante porque:
- Al configurarlo demasiado pequeño, el modelo no tendrá suficiente contexto para generar resultados significativos
- Configurándolo demasiado grande, el modelo no tendrá suficiente espacio para trabajar (ya que la secuencia de salida incluye el indicador)
Puede experimentar con él, pero configurarlo en ~50% de la longitud de la secuencia de salida es un buen comienzo.
Seguridad e IA Responsable
Como se señaló en el anuncio original de OpenAI GPT-2 , existen limitaciones y advertencias notables con el modelo GPT-2. De hecho, los LLM de hoy en día generalmente tienen algunos desafíos bien conocidos, como alucinaciones, equidad y parcialidad; esto se debe a que estos modelos están entrenados en datos del mundo real, lo que los hace reflejar problemas del mundo real.
Este laboratorio de código se creó solo para demostrar cómo crear una aplicación con tecnología de LLM con herramientas de TensorFlow. El modelo producido en este laboratorio de código tiene fines educativos únicamente y no está diseñado para su uso en producción.
El uso de producción de LLM requiere una cuidadosa selección de conjuntos de datos de capacitación y mitigaciones de seguridad integrales. Una de esas funciones que se ofrece en esta aplicación de Android es el filtro de blasfemias, que rechaza las malas entradas del usuario o las salidas del modelo. Si se detecta algún lenguaje inapropiado, la aplicación a cambio rechazará esa acción. Para obtener más información sobre la IA responsable en el contexto de los LLM, asegúrese de ver la sesión técnica Desarrollo seguro y responsable con modelos de lenguaje generativo en Google I/O 2023 y consulte el kit de herramientas de IA responsable .