
| | |
Introduction
Les grands modèles linguistiques (LLM) sont une classe de modèles d'apprentissage automatique entraînés pour générer du texte basé sur de grands ensembles de données. Ils peuvent être utilisés pour des tâches de traitement du langage naturel (NLP), notamment la génération de texte, la réponse aux questions et la traduction automatique. Ils sont basés sur l'architecture Transformer et sont formés sur d'énormes quantités de données textuelles, impliquant souvent des milliards de mots. Même les LLM à plus petite échelle, tels que GPT-2, peuvent fonctionner de manière impressionnante. La conversion des modèles TensorFlow en un modèle plus léger, plus rapide et à faible consommation nous permet d'exécuter des modèles d'IA génératifs sur l'appareil, avec les avantages d'une meilleure sécurité des utilisateurs, car les données ne quitteront jamais votre appareil.
Ce runbook vous montre comment créer une application Android avec TensorFlow Lite pour exécuter un Keras LLM et fournit des suggestions d'optimisation de modèle à l'aide de techniques de quantification, qui autrement nécessiteraient une quantité de mémoire et une puissance de calcul beaucoup plus importantes.
Nous avons open source notre cadre d'application Android auquel tous les LLM TFLite compatibles peuvent se connecter. Voici deux démos :
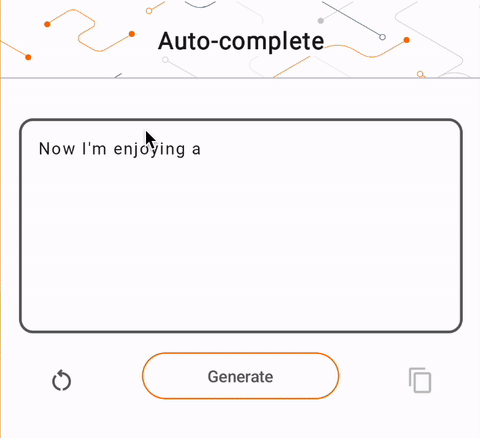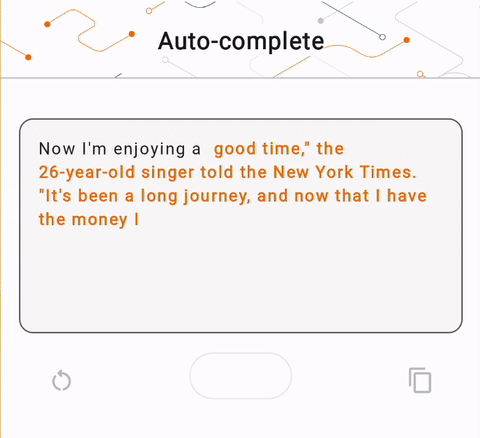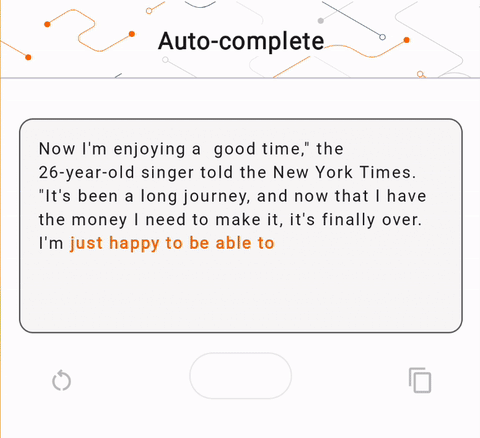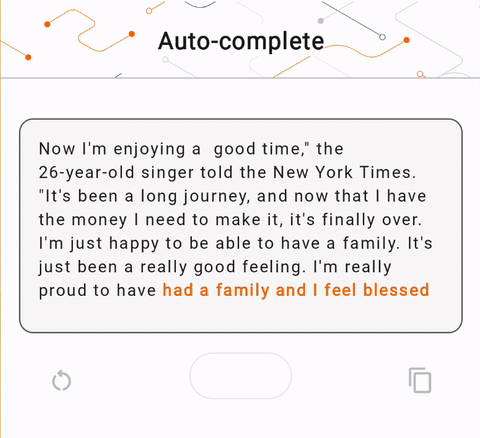
- Dans la figure 1, nous avons utilisé un modèle Keras GPT-2 pour effectuer des tâches de complétion de texte sur l'appareil.
- Dans la figure 2, nous avons converti une version du modèle PaLM optimisé pour les instructions (1,5 milliard de paramètres) en TFLite et exécuté via le runtime TFLite.
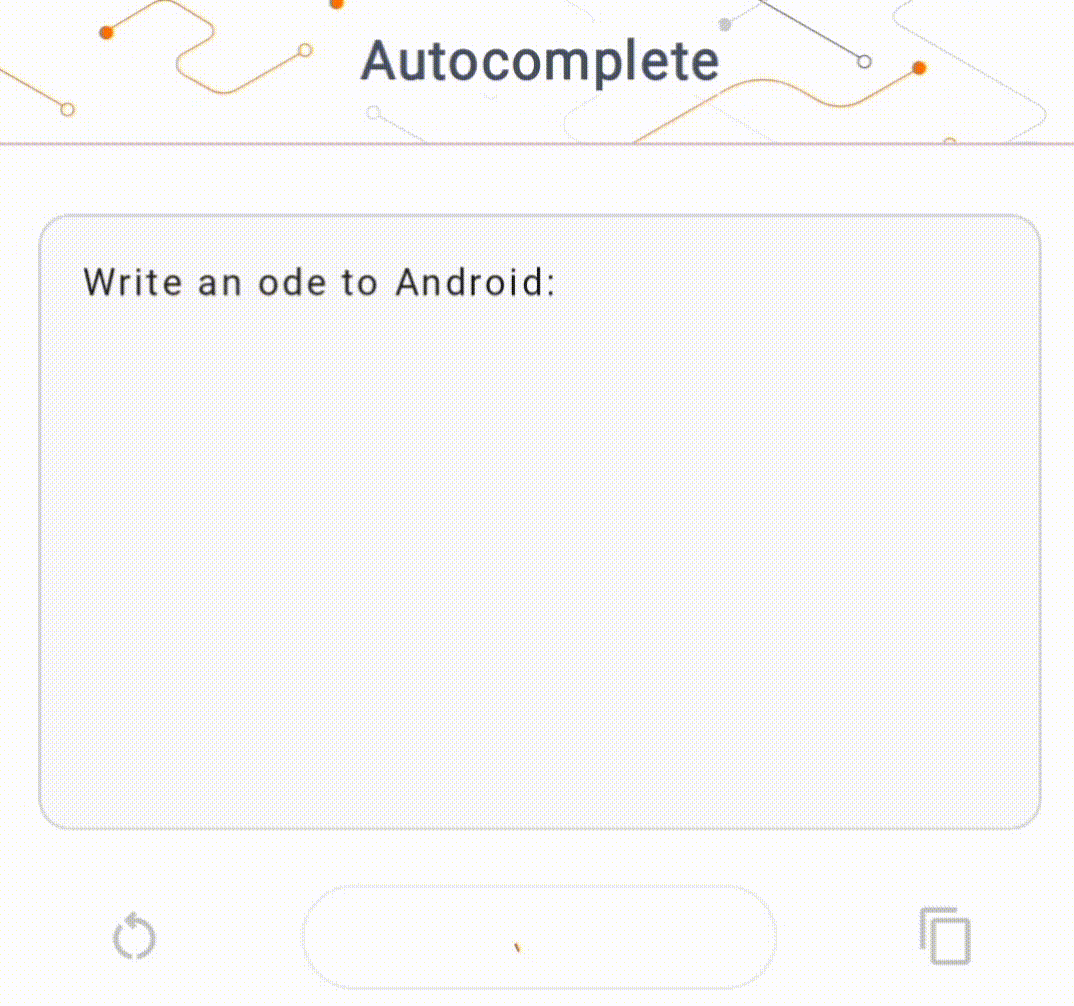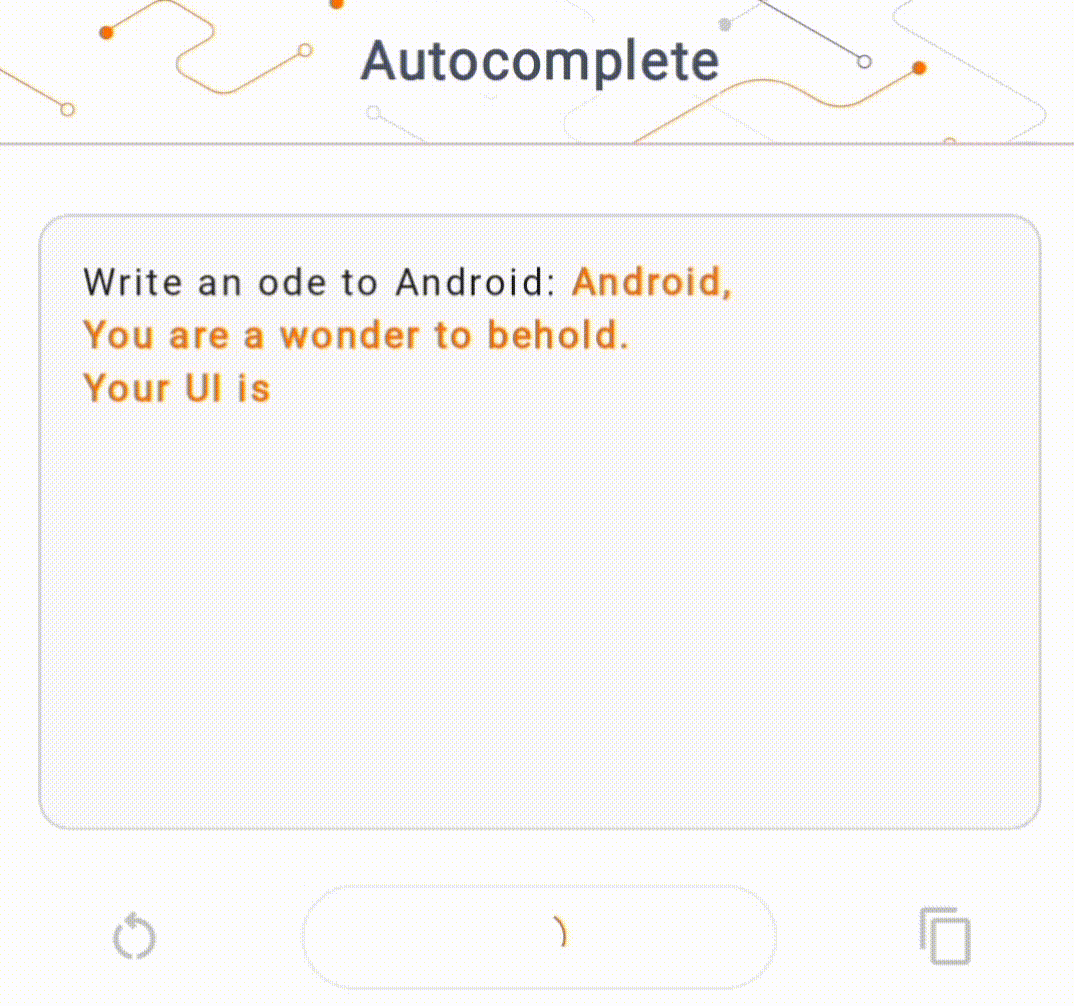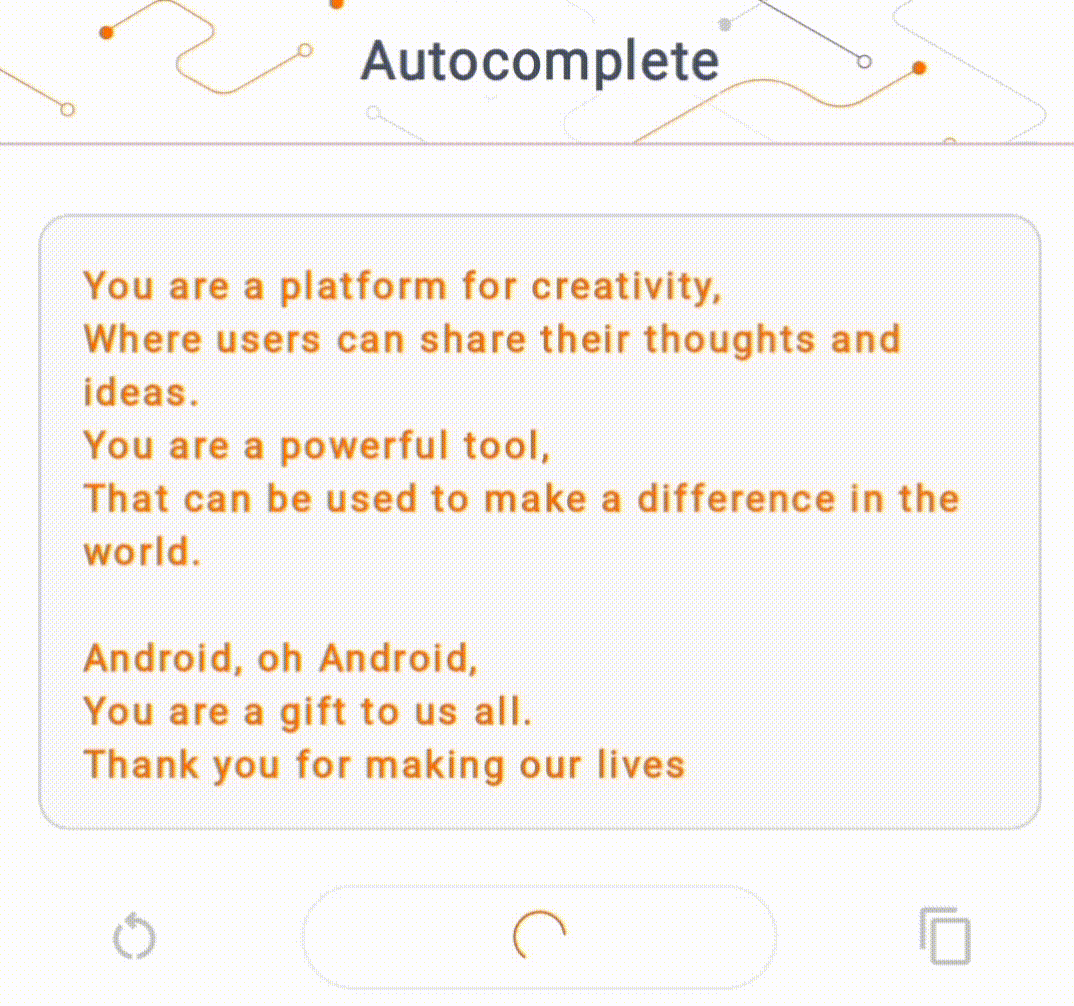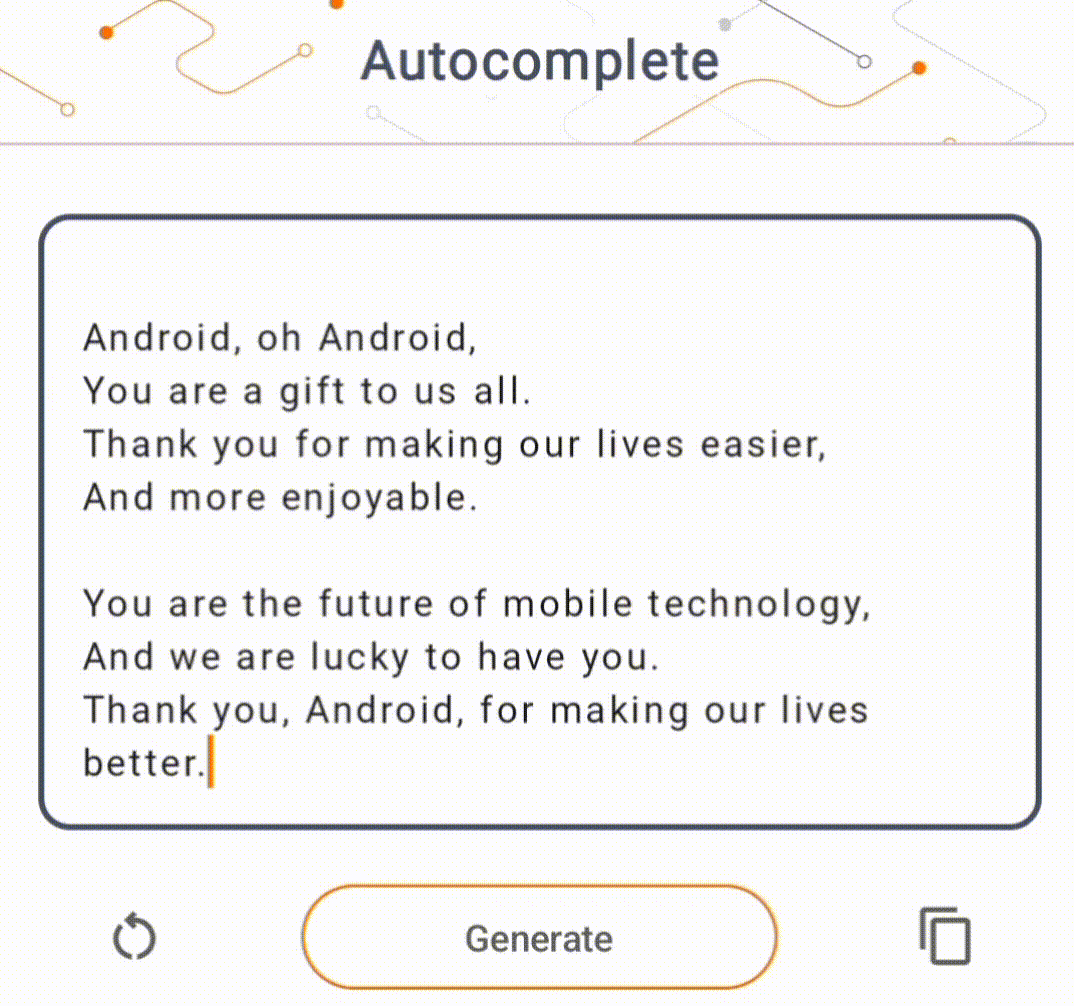
Guides
Création de modèles
Pour cette démonstration, nous utiliserons KerasNLP pour obtenir le modèle GPT-2. KerasNLP est une bibliothèque qui contient des modèles pré-entraînés de pointe pour les tâches de traitement du langage naturel et peut accompagner les utilisateurs tout au long de leur cycle de développement. Vous pouvez voir la liste des modèles disponibles dans le référentiel KerasNLP . Les flux de travail sont construits à partir de composants modulaires dotés de poids et d'architectures prédéfinis de pointe lorsqu'ils sont utilisés prêts à l'emploi et sont facilement personnalisables lorsqu'un contrôle accru est nécessaire. La création du modèle GPT-2 peut être effectuée en suivant les étapes suivantes :
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Un point commun entre ces trois lignes de code est la méthode from_preset() , qui instanciera la partie de l'API Keras à partir d'une architecture et/ou de poids prédéfinis, chargeant ainsi le modèle pré-entraîné. À partir de cet extrait de code, vous remarquerez également trois composants modulaires :
Tokenizer : convertit une entrée de chaîne brute en ID de jeton entier adaptés à une couche Keras Embedding. GPT-2 utilise spécifiquement le tokenizer d'encodage par paire d'octets (BPE).
Préprocesseur : couche pour la tokenisation et le packaging des entrées à introduire dans un modèle Keras. Ici, le préprocesseur complétera le tenseur des ID de jeton à une longueur spécifiée (256) après la tokenisation.
Backbone : modèle Keras qui suit l'architecture de base du transformateur SoTA et a les poids prédéfinis.
De plus, vous pouvez consulter l'implémentation complète du modèle GPT-2 sur GitHub .
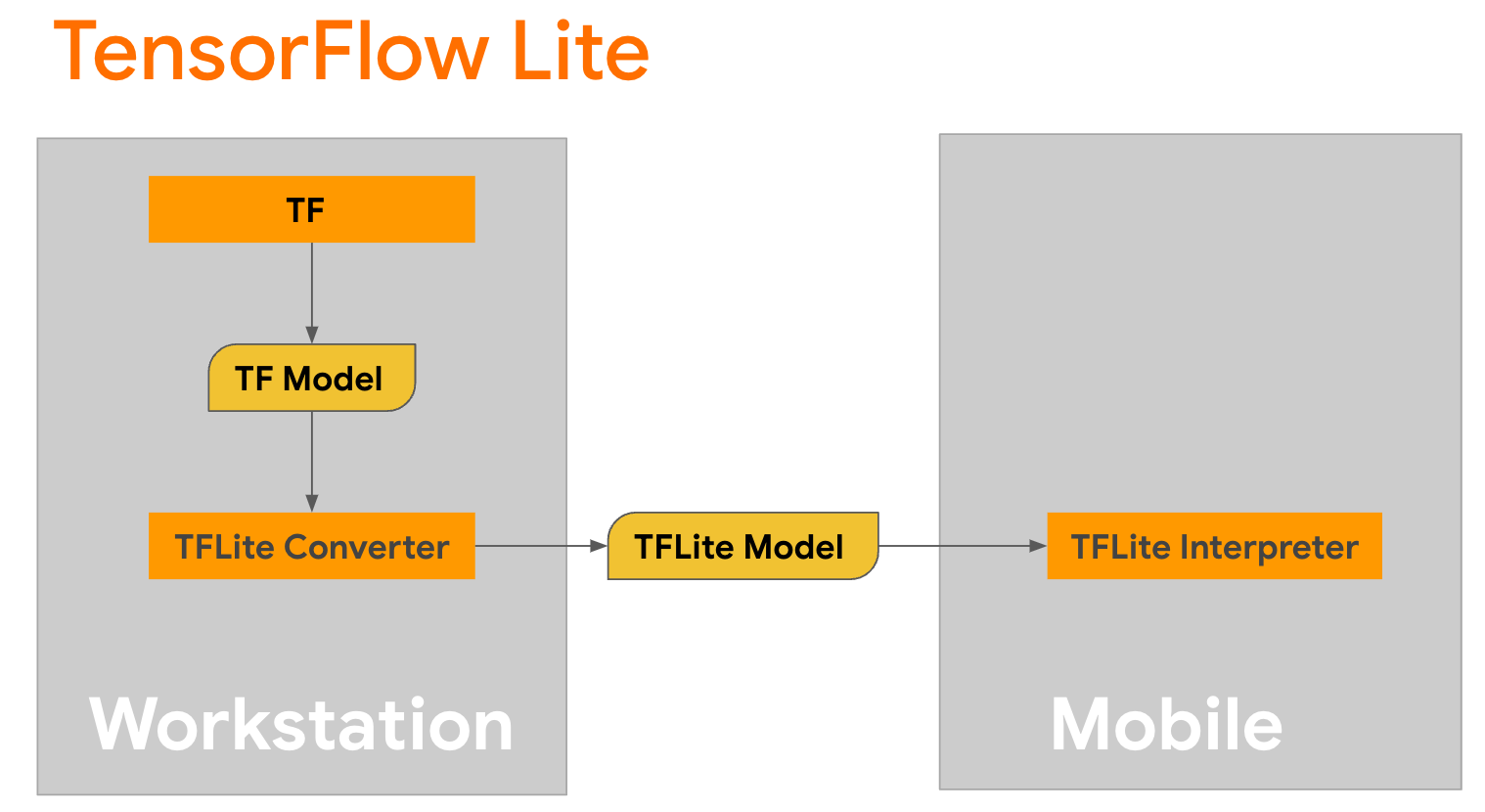
Conversion de modèle
TensorFlow Lite est une bibliothèque mobile permettant de déployer des méthodes sur des appareils mobiles, des microcontrôleurs et d'autres appareils de périphérie. La première étape consiste à convertir un modèle Keras en un format TensorFlow Lite plus compact à l'aide du convertisseur TensorFlow Lite , puis à utiliser l' interpréteur TensorFlow Lite , hautement optimisé pour les appareils mobiles, pour exécuter le modèle converti.
 Commencez par la fonction
Commencez par la fonction generate() de GPT2CausalLM qui effectue la conversion. Enveloppez la fonction generate() pour créer une fonction TensorFlow concrète :
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Notez que vous pouvez également utiliser from_keras_model() de TFLiteConverter afin d'effectuer la conversion.
Définissez maintenant une fonction d'assistance qui exécutera l'inférence avec une entrée et un modèle TFLite. Les opérations de texte TensorFlow ne sont pas des opérations intégrées au runtime TFLite, vous devrez donc ajouter ces opérations personnalisées pour que l'interpréteur puisse faire des inférences sur ce modèle. Cette fonction d'assistance accepte une entrée et une fonction qui effectue la conversion, à savoir la fonction generator() définie ci-dessus.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Vous pouvez convertir le modèle maintenant :
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Quantification
TensorFlow Lite a mis en œuvre une technique d'optimisation appelée quantification qui peut réduire la taille du modèle et accélérer l'inférence. Grâce au processus de quantification, les flottants de 32 bits sont mappés sur des entiers plus petits de 8 bits, réduisant ainsi la taille du modèle d'un facteur 4 pour une exécution plus efficace sur les matériels modernes. Il existe plusieurs façons d'effectuer une quantification dans TensorFlow. Vous pouvez visiter les pages Optimisation du modèle TFLite et Boîte à outils d'optimisation du modèle TensorFlow pour plus d'informations. Les types de quantifications sont expliqués brièvement ci-dessous.
Ici, vous utiliserez la quantification de la plage dynamique post-entraînement sur le modèle GPT-2 en définissant l'indicateur d'optimisation du convertisseur sur tf.lite.Optimize.DEFAULT , et le reste du processus de conversion est le même que celui détaillé précédemment. Nous avons testé qu'avec cette technique de quantification, la latence est d'environ 6,7 secondes sur le Pixel 7 avec une longueur de sortie maximale définie sur 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Plage dynamique
La quantification de la plage dynamique est le point de départ recommandé pour optimiser les modèles sur l'appareil. Il permet de réduire d'environ 4 fois la taille du modèle et constitue un point de départ recommandé car il permet une utilisation réduite de la mémoire et un calcul plus rapide sans que vous ayez à fournir un ensemble de données représentatif pour l'étalonnage. Ce type de quantification quantifie statiquement uniquement les poids de la virgule flottante à l'entier 8 bits au moment de la conversion.
PC16
Les modèles à virgule flottante peuvent également être optimisés en quantifiant les poids au type float16. Les avantages de la quantification float16 sont de réduire la taille du modèle jusqu'à la moitié (puisque tous les poids deviennent la moitié de leur taille), entraînant une perte de précision minimale et prenant en charge les délégués GPU qui peuvent opérer directement sur les données float16 (ce qui entraîne un calcul plus rapide que sur float32). données). Un modèle converti en poids float16 peut toujours fonctionner sur le processeur sans modifications supplémentaires. Les poids float16 sont suréchantillonnés en float32 avant la première inférence, ce qui permet une réduction de la taille du modèle en échange d'un impact minimal sur la latence et la précision.
Quantification entière complète
La quantification entière complète convertit les nombres à virgule flottante de 32 bits, y compris les poids et les activations, en entiers de 8 bits les plus proches. Ce type de quantification aboutit à un modèle plus petit avec une vitesse d'inférence accrue, ce qui est extrêmement précieux lors de l'utilisation de microcontrôleurs. Ce mode est recommandé lorsque les activations sont sensibles à la quantification.
Intégration de l'application Android
Vous pouvez suivre cet exemple Android pour intégrer votre modèle TFLite dans une application Android.
Conditions préalables
Si vous ne l'avez pas déjà fait, installez Android Studio en suivant les instructions sur le site Web.
- Android Studio 2022.2.1 ou supérieur.
- Un appareil Android ou un émulateur Android avec plus de 4 Go de mémoire
Construire et exécuter avec Android Studio
- Ouvrez Android Studio et, depuis l'écran de bienvenue, sélectionnez Ouvrir un projet Android Studio existant .
- Dans la fenêtre Ouvrir un fichier ou un projet qui apparaît, accédez au répertoire
lite/examples/generative_ai/androidet sélectionnez-le à partir de l'endroit où vous avez cloné l'exemple de dépôt GitHub TensorFlow Lite. - Vous devrez peut-être également installer diverses plates-formes et outils en fonction des messages d'erreur.
- Renommez le modèle .tflite converti en
autocomplete.tfliteet copiez-le dans le dossierapp/src/main/assets/. - Sélectionnez le menu Build -> Make Project pour créer l'application. (Ctrl+F9, selon votre version).
- Cliquez sur le menu Exécuter -> Exécuter 'app' . (Maj+F10, selon votre version)
Alternativement, vous pouvez également utiliser le wrapper gradle pour le créer dans la ligne de commande. Veuillez vous référer à la documentation Gradle pour plus d'informations.
(Facultatif) Création du fichier .aar
Par défaut, l'application télécharge automatiquement les fichiers .aar nécessaires. Mais si vous souhaitez créer le vôtre, passez au dossier app/libs/build_aar/ run ./build_aar.sh . Ce script extraira les opérations nécessaires de TensorFlow Text et créera l'aar pour les opérateurs Select TF.
Après compilation, un nouveau fichier tftext_tflite_flex.aar est généré. Remplacez le fichier .aar dans le dossier app/libs/ et reconstruisez l'application.
Notez que vous devez toujours inclure l'aar tensorflow-lite standard dans votre fichier gradle.
Taille de la fenêtre contextuelle
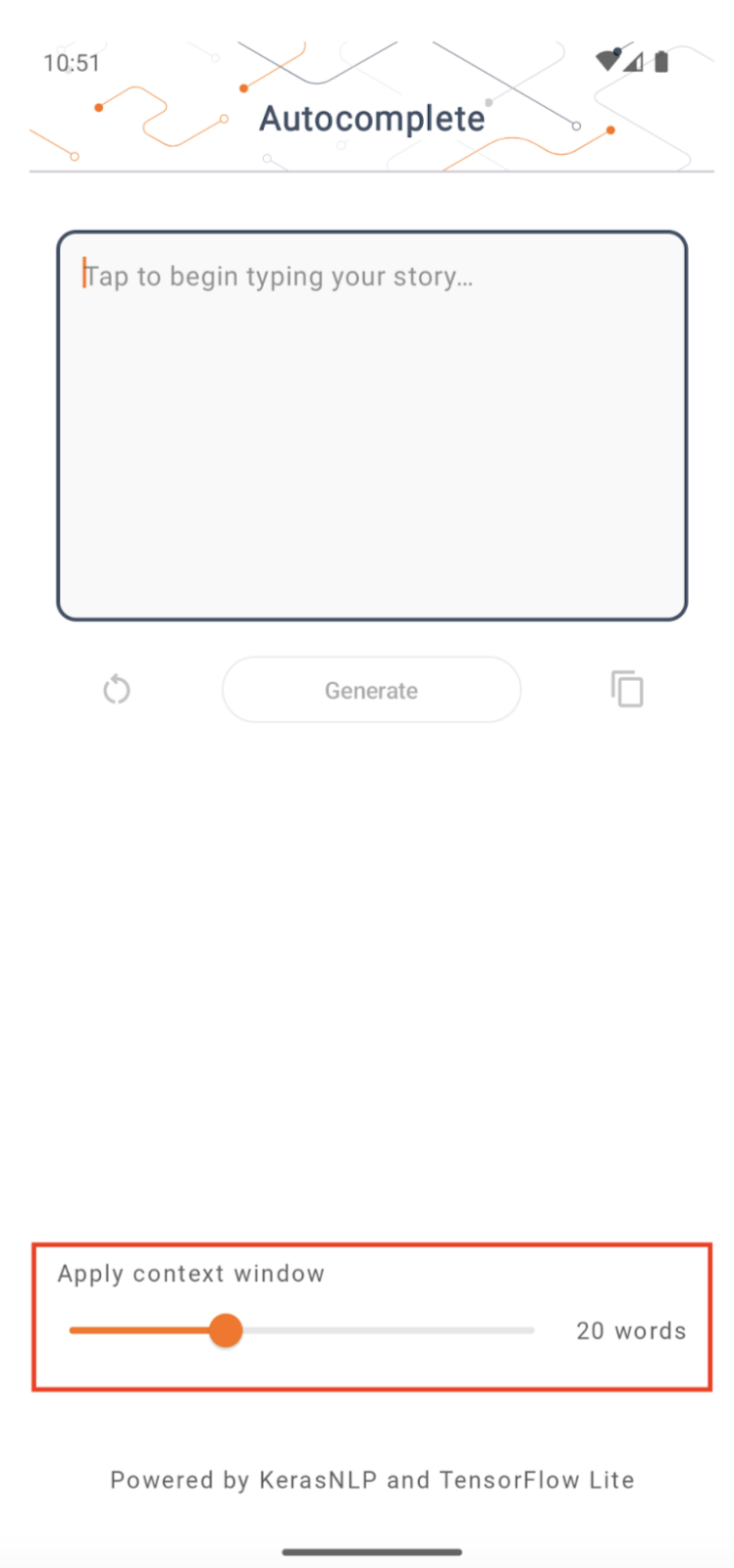
L'application dispose d'un paramètre modifiable « taille de la fenêtre de contexte », qui est nécessaire car les LLM d'aujourd'hui ont généralement une taille de contexte fixe qui limite le nombre de mots/jetons pouvant être introduits dans le modèle en tant qu'« invite » (notez que « mot » n'est pas nécessairement équivalent à « jeton » dans ce cas, en raison des différentes méthodes de tokenisation). Ce numéro est important car :
- En le définissant trop petit, le modèle n'aura pas suffisamment de contexte pour générer une sortie significative
- En le définissant trop grand, le modèle n'aura pas assez d'espace pour travailler (puisque la séquence de sortie inclut l'invite)
Vous pouvez l'expérimenter, mais le régler à environ 50 % de la longueur de la séquence de sortie est un bon début.
Sécurité et IA responsable
Comme indiqué dans l' annonce originale d'OpenAI GPT-2 , le modèle GPT-2 présente des mises en garde et des limitations notables . En fait, les LLM d’aujourd’hui présentent généralement des défis bien connus tels que les hallucinations, l’équité et les préjugés ; en effet, ces modèles sont formés sur des données du monde réel, ce qui les fait refléter des problèmes du monde réel.
Cet atelier de programmation est créé uniquement pour montrer comment créer une application basée sur des LLM avec les outils TensorFlow. Le modèle produit dans cet atelier de programmation est uniquement destiné à des fins éducatives et n'est pas destiné à une utilisation en production.
L'utilisation de la production LLM nécessite une sélection réfléchie d'ensembles de données de formation et des mesures d'atténuation de sécurité complètes. L'une de ces fonctionnalités offertes dans cette application Android est le filtre de grossièretés, qui rejette les mauvaises entrées de l'utilisateur ou les mauvaises sorties du modèle. Si un langage inapproprié est détecté, l’application rejettera en retour cette action. Pour en savoir plus sur l'IA responsable dans le contexte des LLM, assurez-vous de regarder la session technique Développement sûr et responsable avec des modèles de langage génératifs à Google I/O 2023 et consultez la boîte à outils de l'IA responsable .