
| | |
Giới thiệu
Mô hình ngôn ngữ lớn (LLM) là một lớp mô hình học máy được đào tạo để tạo văn bản dựa trên các tập dữ liệu lớn. Chúng có thể được sử dụng cho các tác vụ xử lý ngôn ngữ tự nhiên (NLP), bao gồm tạo văn bản, trả lời câu hỏi và dịch máy. Họ dựa trên kiến trúc Transformer và được đào tạo về lượng dữ liệu văn bản khổng lồ, thường liên quan đến hàng tỷ từ. Ngay cả LLM ở quy mô nhỏ hơn, chẳng hạn như GPT-2, cũng có thể hoạt động một cách ấn tượng. Việc chuyển đổi mô hình TensorFlow sang mô hình nhẹ hơn, nhanh hơn và tiêu thụ ít năng lượng hơn cho phép chúng tôi chạy các mô hình AI tổng quát trên thiết bị, với lợi ích là bảo mật người dùng tốt hơn vì dữ liệu sẽ không bao giờ rời khỏi thiết bị của bạn.
Cuốn sách này hướng dẫn bạn cách xây dựng một ứng dụng Android với TensorFlow Lite để chạy Keras LLM và cung cấp các đề xuất để tối ưu hóa mô hình bằng cách sử dụng các kỹ thuật lượng tử hóa, nếu không sẽ cần dung lượng bộ nhớ lớn hơn và sức mạnh tính toán lớn hơn để chạy.
Chúng tôi đã mở nguồn khung ứng dụng Android của mình mà mọi LLM TFLite tương thích đều có thể cắm vào. Đây là hai bản demo:
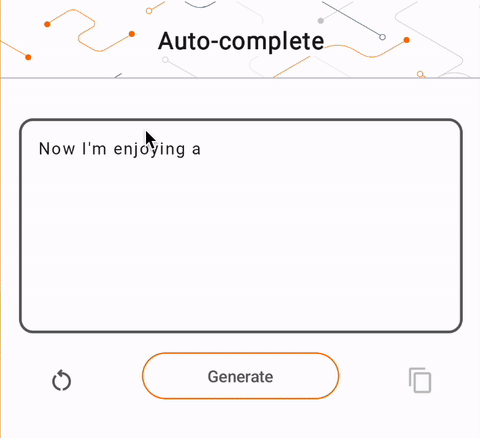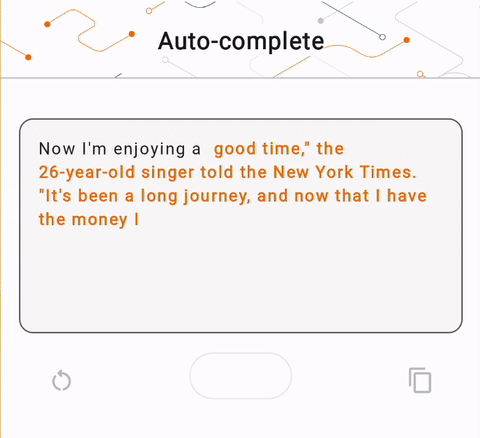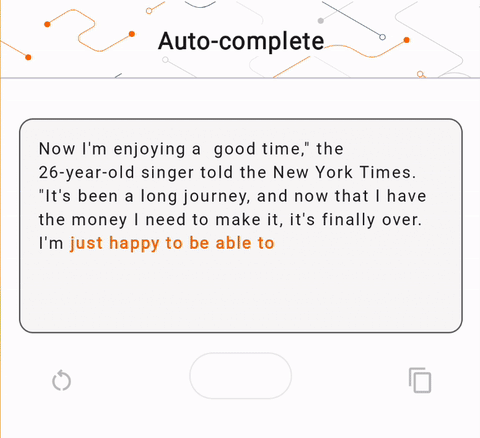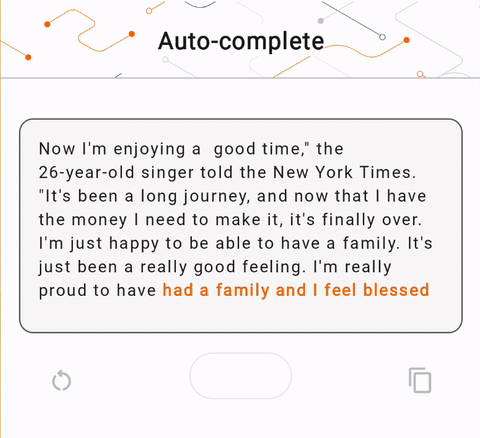
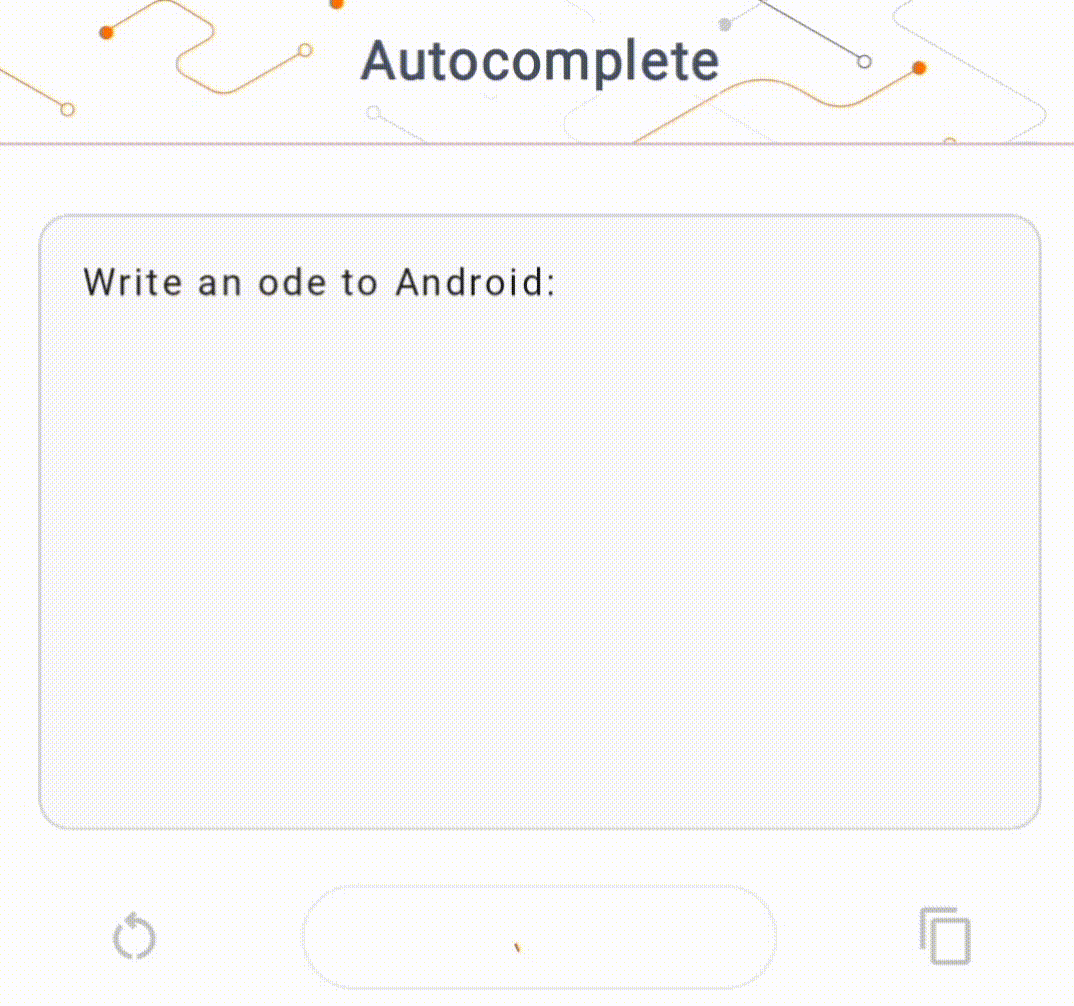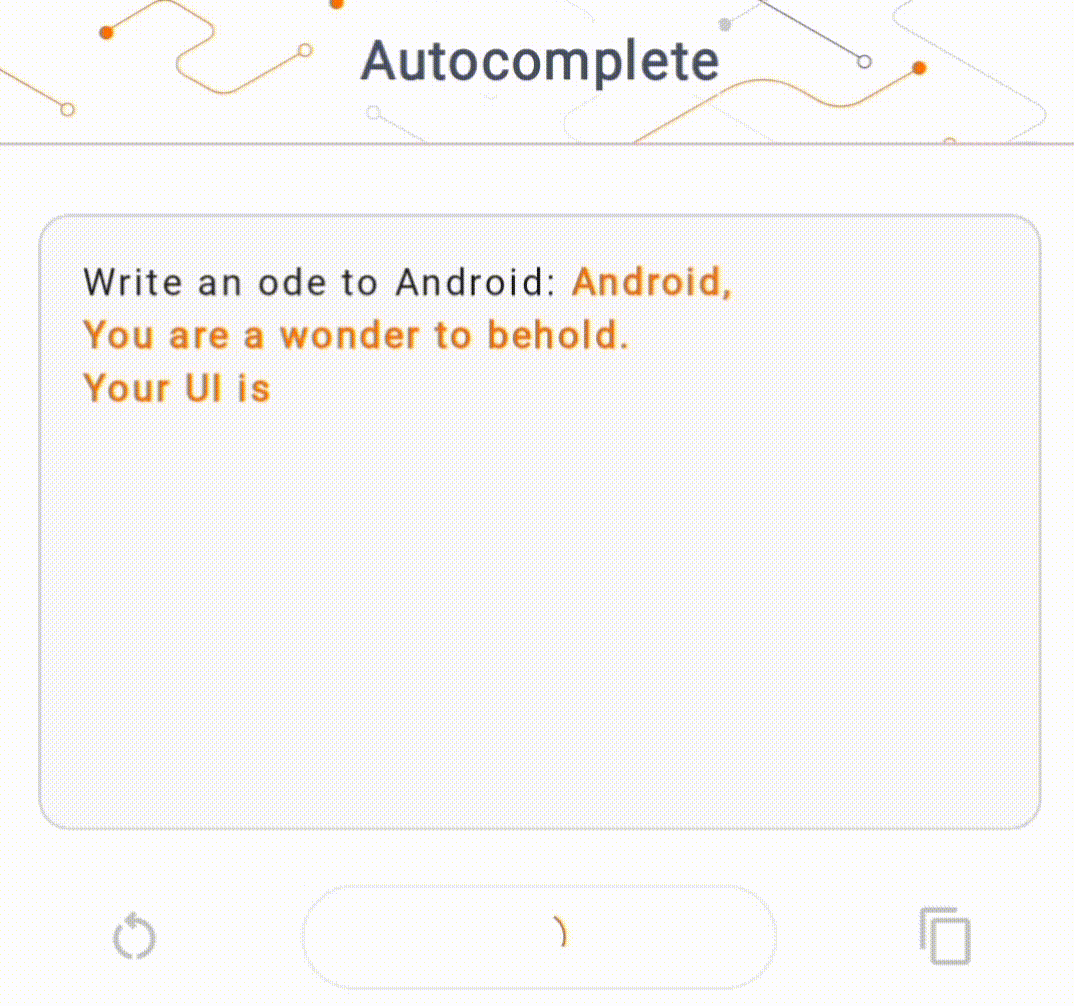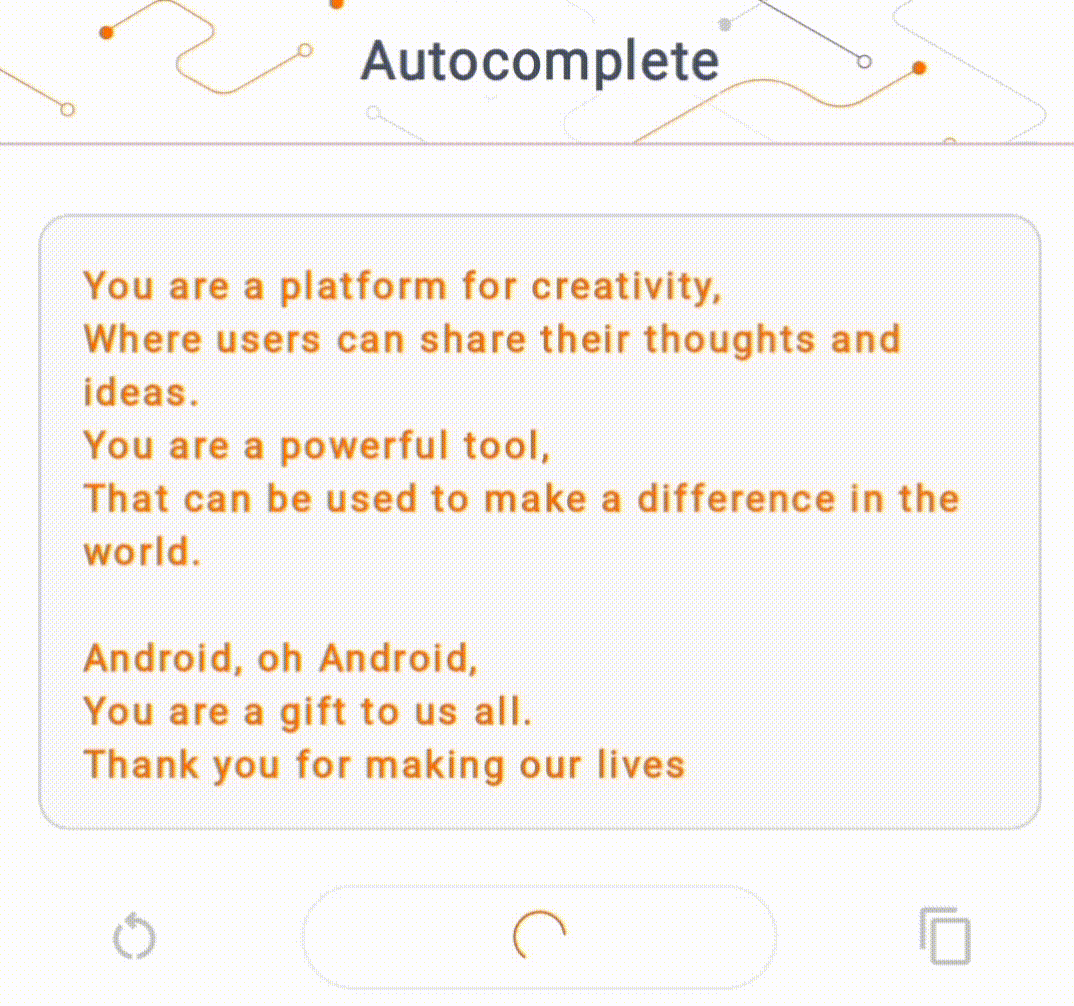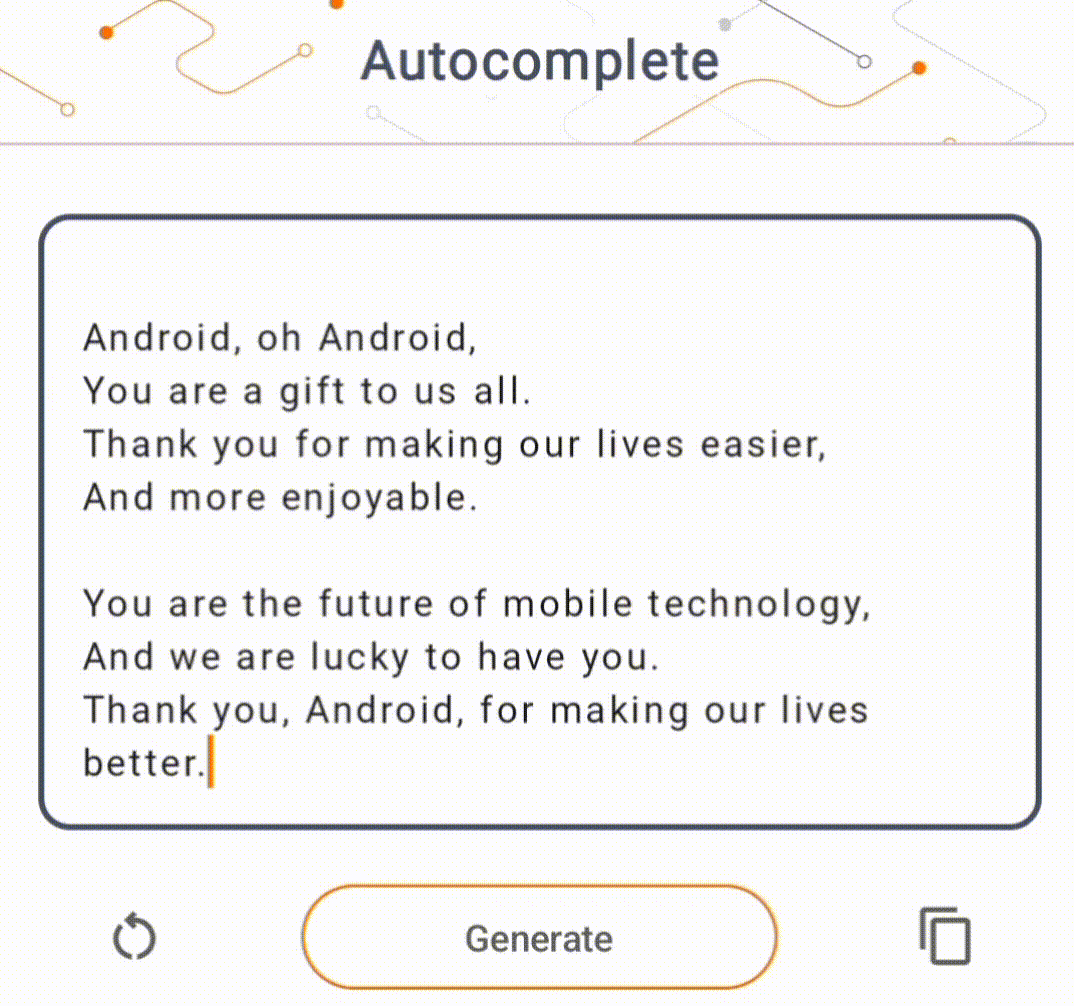
- Trong Hình 1, chúng tôi đã sử dụng mô hình Keras GPT-2 để thực hiện các tác vụ hoàn thành văn bản trên thiết bị.
- Trong Hình 2, chúng tôi đã chuyển đổi một phiên bản của mô hình PaLM được điều chỉnh theo lệnh (1,5 tỷ tham số) sang TFLite và được thực thi thông qua thời gian chạy TFLite.
Hướng dẫn
Tác giả mô hình
Đối với phần trình diễn này, chúng tôi sẽ sử dụng KerasNLP để lấy mô hình GPT-2. KerasNLP là một thư viện chứa các mô hình được đào tạo trước tiên tiến nhất cho các tác vụ xử lý ngôn ngữ tự nhiên và có thể hỗ trợ người dùng trong toàn bộ chu trình phát triển của họ. Bạn có thể xem danh sách các mô hình có sẵn trong kho KerasNLP . Quy trình làm việc được xây dựng từ các thành phần mô-đun có trọng lượng và kiến trúc đặt trước hiện đại khi sử dụng ngay lập tức và có thể dễ dàng tùy chỉnh khi cần kiểm soát nhiều hơn. Việc tạo mô hình GPT-2 có thể được thực hiện bằng các bước sau:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Một điểm chung giữa ba dòng mã này là phương thức from_preset() , phương thức này sẽ khởi tạo một phần API Keras từ kiến trúc và/hoặc trọng số đặt trước, do đó tải mô hình được đào tạo trước. Từ đoạn mã này, bạn cũng sẽ nhận thấy ba thành phần mô-đun:
Tokenizer : chuyển đổi đầu vào chuỗi thô thành ID mã thông báo số nguyên phù hợp với lớp Nhúng Keras. GPT-2 sử dụng cụ thể mã thông báo mã hóa cặp byte (BPE).
Bộ tiền xử lý : lớp để mã hóa và đóng gói các đầu vào được đưa vào mô hình Keras. Tại đây, bộ tiền xử lý sẽ đệm tensor của ID mã thông báo đến độ dài được chỉ định (256) sau khi mã hóa.
Xương sống : Mô hình Keras tuân theo kiến trúc đường trục biến áp SoTA và có trọng số đặt trước.
Ngoài ra, bạn có thể xem quá trình triển khai mô hình GPT-2 đầy đủ trên GitHub .
Chuyển đổi mô hình
TensorFlow Lite là thư viện di động để triển khai các phương pháp trên thiết bị di động, bộ vi điều khiển và các thiết bị biên khác. Bước đầu tiên là chuyển đổi mô hình Keras sang định dạng TensorFlow Lite nhỏ gọn hơn bằng trình chuyển đổi TensorFlow Lite, sau đó sử dụng trình thông dịch TensorFlow Lite, được tối ưu hóa cao cho thiết bị di động, để chạy mô hình đã chuyển đổi.
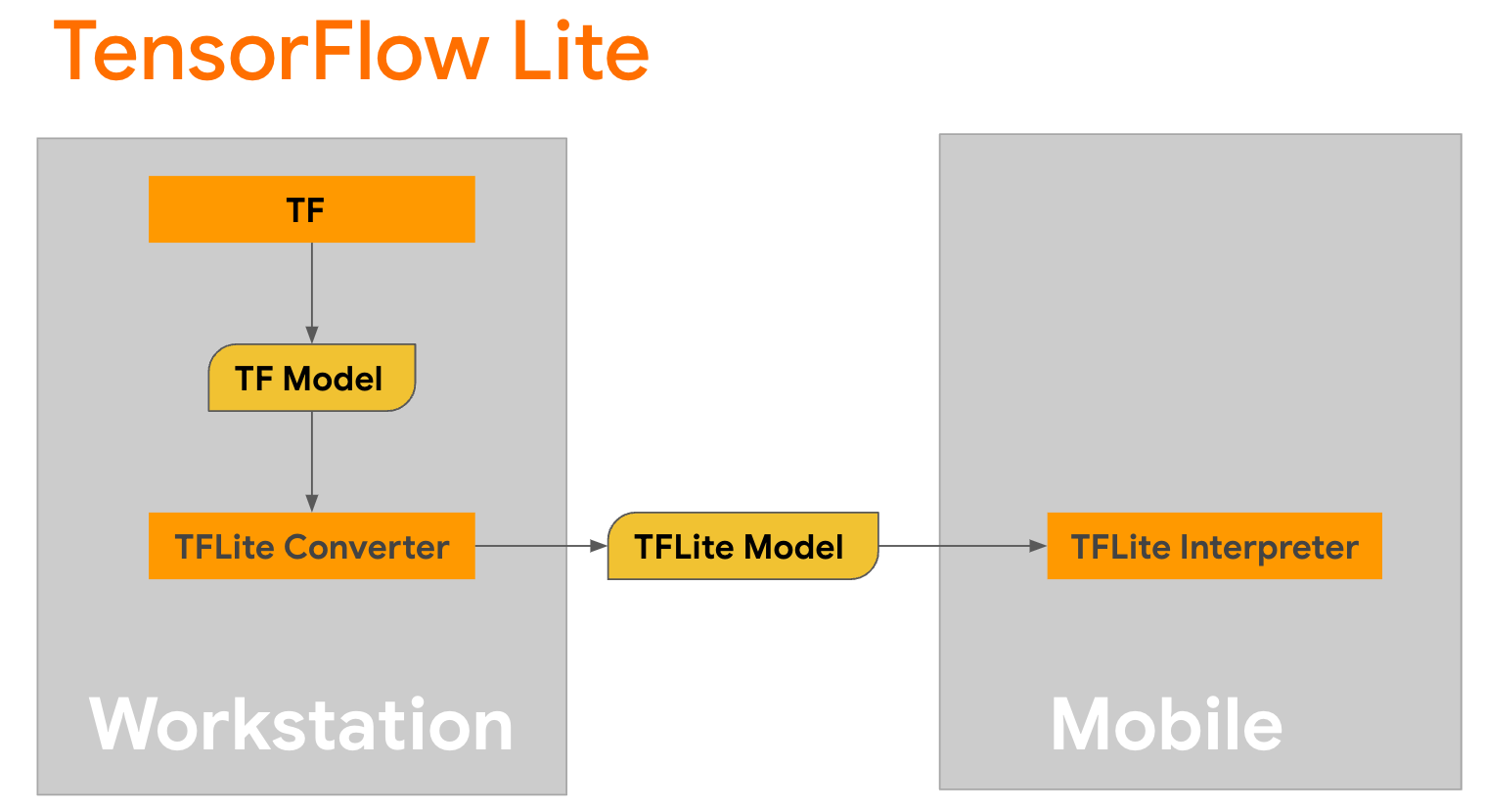 Bắt đầu với hàm
Bắt đầu với hàm generate() từ GPT2CausalLM để thực hiện chuyển đổi. Gói hàm generate() để tạo hàm TensorFlow cụ thể:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Lưu ý rằng bạn cũng có thể sử dụng from_keras_model() từ TFLiteConverter để thực hiện chuyển đổi.
Bây giờ hãy xác định hàm trợ giúp sẽ chạy suy luận với đầu vào và mô hình TFLite. Các hoạt động văn bản TensorFlow không phải là các hoạt động tích hợp trong thời gian chạy TFLite, vì vậy bạn sẽ cần thêm các hoạt động tùy chỉnh này để trình thông dịch suy luận về mô hình này. Hàm trợ giúp này chấp nhận đầu vào và hàm thực hiện chuyển đổi, cụ thể là hàm generator() được xác định ở trên.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Bạn có thể chuyển đổi mô hình ngay bây giờ:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Lượng tử hóa
TensorFlow Lite đã triển khai một kỹ thuật tối ưu hóa gọi là lượng tử hóa , có thể giảm kích thước mô hình và tăng tốc độ suy luận. Thông qua quá trình lượng tử hóa, các số float 32 bit được ánh xạ tới các số nguyên 8 bit nhỏ hơn, do đó giảm kích thước mô hình xuống 4 lần để thực thi hiệu quả hơn trên phần cứng hiện đại. Có một số cách để thực hiện lượng tử hóa trong TensorFlow. Bạn có thể truy cập các trang Tối ưu hóa mô hình TFLite và Bộ công cụ tối ưu hóa mô hình TensorFlow để biết thêm thông tin. Các loại lượng tử hóa được giải thích ngắn gọn dưới đây.
Tại đây, bạn sẽ sử dụng lượng tử hóa phạm vi động sau đào tạo trên mô hình GPT-2 bằng cách đặt cờ tối ưu hóa bộ chuyển đổi thành tf.lite.Optimize.DEFAULT và phần còn lại của quá trình chuyển đổi cũng giống như chi tiết trước đó. Chúng tôi đã kiểm tra rằng bằng kỹ thuật lượng tử hóa này, độ trễ là khoảng 6,7 giây trên Pixel 7 với độ dài đầu ra tối đa được đặt thành 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Phạm vi động
Lượng tử hóa phạm vi động là điểm khởi đầu được đề xuất để tối ưu hóa các mô hình trên thiết bị. Nó có thể giảm kích thước mô hình khoảng 4 lần và là điểm khởi đầu được khuyên dùng vì nó giúp giảm mức sử dụng bộ nhớ và tính toán nhanh hơn mà bạn không cần phải cung cấp tập dữ liệu đại diện để hiệu chỉnh. Kiểu lượng tử hóa này chỉ lượng tử hóa tĩnh các trọng số từ dấu phẩy động đến số nguyên 8 bit tại thời điểm chuyển đổi.
FP16
Các mô hình dấu phẩy động cũng có thể được tối ưu hóa bằng cách lượng tử hóa các trọng số thành loại float16. Ưu điểm của lượng tử hóa float16 là giảm kích thước mô hình xuống một nửa (vì tất cả các trọng số giảm một nửa kích thước của chúng), gây ra sự mất mát tối thiểu về độ chính xác và hỗ trợ các đại biểu GPU có thể hoạt động trực tiếp trên dữ liệu float16 (dẫn đến tính toán nhanh hơn trên float32 dữ liệu). Một mô hình được chuyển đổi sang trọng số float16 vẫn có thể chạy trên CPU mà không cần sửa đổi bổ sung. Các trọng số float16 được lấy mẫu lại thành float32 trước lần suy luận đầu tiên, cho phép giảm kích thước mô hình để đổi lấy tác động tối thiểu đến độ trễ và độ chính xác.
Lượng tử hóa số nguyên đầy đủ
Lượng tử hóa toàn bộ số nguyên đều chuyển đổi các số dấu phẩy động 32 bit, bao gồm trọng số và kích hoạt, thành số nguyên 8 bit gần nhất. Kiểu lượng tử hóa này tạo ra một mô hình nhỏ hơn với tốc độ suy luận tăng lên, điều này cực kỳ có giá trị khi sử dụng bộ vi điều khiển. Chế độ này được khuyên dùng khi kích hoạt nhạy cảm với lượng tử hóa.
Tích hợp ứng dụng Android
Bạn có thể làm theo ví dụ về Android này để tích hợp mô hình TFLite của mình vào Ứng dụng Android.
Điều kiện tiên quyết
Nếu bạn chưa có, hãy cài đặt Android Studio , làm theo hướng dẫn trên trang web.
- Android Studio 2022.2.1 trở lên.
- Thiết bị Android hoặc trình giả lập Android có bộ nhớ lớn hơn 4G
Xây dựng và chạy với Android Studio
- Mở Android Studio và từ màn hình Chào mừng, chọn Mở dự án Android Studio hiện có .
- Từ cửa sổ Mở tệp hoặc Dự án xuất hiện, hãy điều hướng đến và chọn thư mục
lite/examples/generative_ai/androidtừ bất cứ nơi nào bạn sao chép kho GitHub mẫu TensorFlow Lite. - Bạn cũng có thể cần cài đặt nhiều nền tảng và công cụ khác nhau tùy theo thông báo lỗi.
- Đổi tên mô hình .tflite đã chuyển đổi thành
autocomplete.tflitevà sao chép nó vào thư mụcapp/src/main/assets/. - Chọn menu Build -> Make Project để build ứng dụng. (Ctrl+F9, tùy thuộc vào phiên bản của bạn).
- Nhấp vào menu Chạy -> Chạy 'ứng dụng' . (Shift+F10, tùy thuộc vào phiên bản của bạn)
Ngoài ra, bạn cũng có thể sử dụng trình bao bọc lớp để xây dựng nó trong dòng lệnh. Vui lòng tham khảo tài liệu Gradle để biết thêm thông tin.
(Tùy chọn) Xây dựng tệp .aar
Theo mặc định, ứng dụng sẽ tự động tải xuống các tệp .aar cần thiết. Nhưng nếu bạn muốn tự xây dựng, hãy chuyển sang thư mục app/libs/build_aar/ chạy ./build_aar.sh . Tập lệnh này sẽ lấy các hoạt động cần thiết từ Văn bản TensorFlow và xây dựng aar cho các toán tử Chọn TF.
Sau khi biên dịch, một tệp mới tftext_tflite_flex.aar sẽ được tạo. Thay thế tệp .aar trong thư mục app/libs/ và xây dựng lại ứng dụng.
Lưu ý rằng bạn vẫn cần đưa aar tensorflow-lite tiêu chuẩn vào tệp lớp của mình.
Kích thước cửa sổ ngữ cảnh

Ứng dụng này có một tham số có thể thay đổi là 'kích thước cửa sổ ngữ cảnh'. Thông số này cần thiết vì LLM ngày nay thường có kích thước ngữ cảnh cố định nhằm giới hạn số lượng từ/mã thông báo có thể được đưa vào mô hình dưới dạng 'lời nhắc' (lưu ý rằng 'từ' không nhất thiết phải tương đương với 'mã thông báo' trong trường hợp này, do các phương thức mã hóa khác nhau). Con số này rất quan trọng vì:
- Đặt nó quá nhỏ, mô hình sẽ không có đủ ngữ cảnh để tạo ra đầu ra có ý nghĩa
- Đặt nó quá lớn, mô hình sẽ không có đủ chỗ để làm việc (vì chuỗi đầu ra bao gồm lời nhắc)
Bạn có thể thử nghiệm nó, nhưng đặt nó ở mức ~50% độ dài chuỗi đầu ra là một khởi đầu tốt.
AI an toàn và có trách nhiệm
Như đã lưu ý trong thông báo OpenAI GPT-2 ban đầu, có những cảnh báo và hạn chế đáng chú ý với mô hình GPT-2. Trên thực tế, LLM ngày nay nhìn chung có một số thách thức nổi tiếng như ảo giác, tính công bằng và thành kiến; điều này là do những mô hình này được đào tạo dựa trên dữ liệu trong thế giới thực, khiến chúng phản ánh các vấn đề trong thế giới thực.
Lớp học lập trình này được tạo ra chỉ để trình bày cách tạo một ứng dụng được hỗ trợ bởi LLM bằng công cụ TensorFlow. Mô hình được tạo trong lớp học lập trình này chỉ nhằm mục đích giáo dục chứ không nhằm mục đích sử dụng trong sản xuất.
Việc sử dụng sản xuất LLM đòi hỏi phải lựa chọn cẩn thận các tập dữ liệu đào tạo và giảm thiểu an toàn toàn diện. Một chức năng như vậy được cung cấp trong ứng dụng Android này là bộ lọc tục tĩu, loại bỏ đầu vào hoặc đầu ra mô hình xấu của người dùng. Nếu phát hiện bất kỳ ngôn ngữ không phù hợp nào, ứng dụng sẽ từ chối hành động đó. Để tìm hiểu thêm về AI có trách nhiệm trong bối cảnh LLM, hãy nhớ xem phiên kỹ thuật về Phát triển an toàn và có trách nhiệm với Mô hình ngôn ngữ sáng tạo tại Google I/O 2023 và xem Bộ công cụ AI có trách nhiệm .