
| | |  GitHub でソースを表示 GitHub でソースを表示 |
個別のレコメンドは、メディアコンテンツの検索、ショッピングの商品提案、アプリの次のレコメンドなど、モバイルデバイス上のさまざまなユースケースで広く使用されています。ユーザーのプライバシーを尊重しながらアプリで個別のレコメンドを提供することに興味がある場合には、以下の例とツールキットの検討をお勧めします。
注意: モデルをカスタマイズするには、TensorFlow Lite Model Maker を試してください。
はじめに
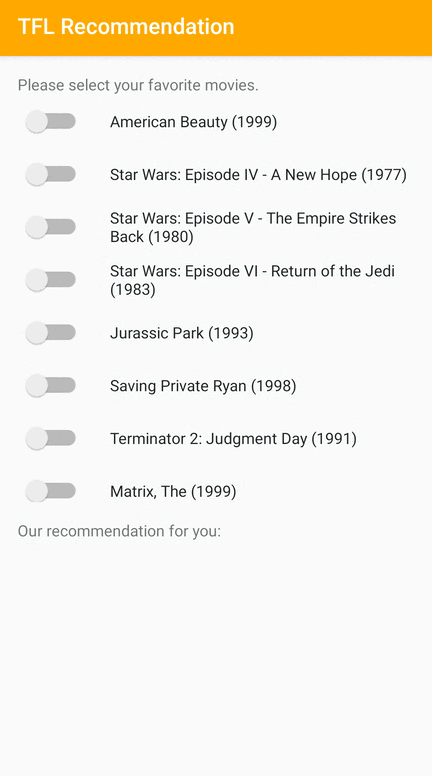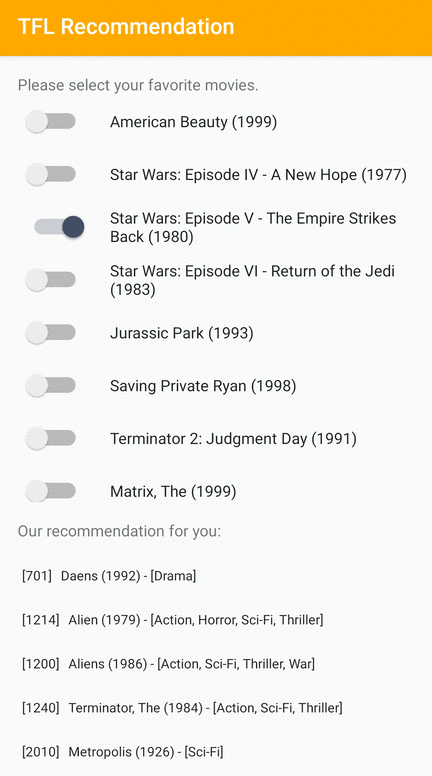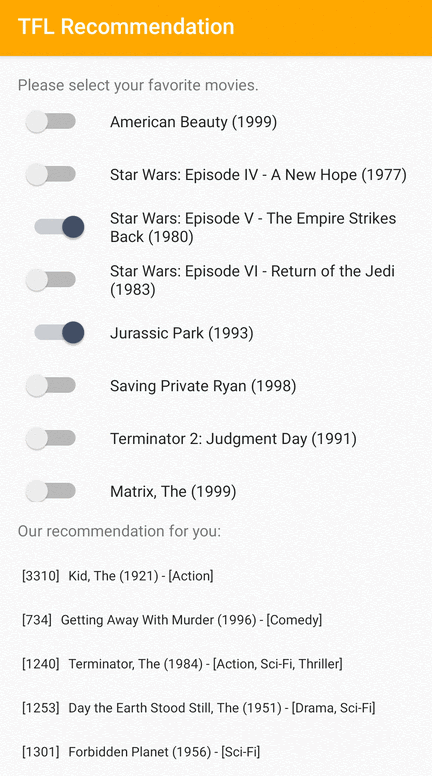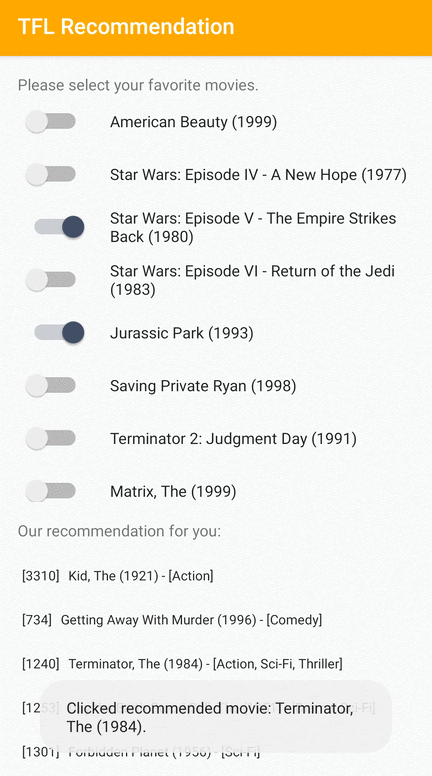
Android 上でユーザーに関連するアイテムを推奨する方法を実演する TensorFlow Lite のサンプルアプリを提供しています。
Android 以外のプラットフォームを使用する場合、または、すでに TensorFlow Lite API に精通している場合は、レコメンドスターターモデルをダウンロードしてください。
スターターモデルをダウンロードする
また、構成可能な方法で独自のモデルをトレーニングするためのトレーニングスクリプトも GitHub で提供されています。
モデルアーキテクチャの理解
Sequential にユーザー履歴をエンコードするコンテキストエンコーダと、予測されたレコメンドをエンコードするラベルエンコーダから成る、デュアルエンコーダ モデルアーキテクチャを活用しています。コンテキストエンコーディングとラベルエンコーディング間の類似性は、予測された候補がユーザーのニーズを満たす可能性を表現するために使用されます。
このコードベースでは、Sequential なユーザー履歴のエンコーディング手法を 3 種類提供しています。
- Bag of Words エンコーダ (BOW): コンテキストの順序を考慮しないでユーザーアクティビティの埋め込みを平均化します。
- 畳み込みニューラルネットワークエンコーダ (CNN): 畳み込みニューラルネットワークの複数のレイヤーを適用してコンテキストエンコーディングを生成します。
- 再帰ニューラルネットワークエンコーダ (RNN): 再帰ニューラルネットワークを適用してコンテキストシーケンスをエンコードします。
各ユーザーアクティビティをモデル化するには、アクティビティ項目の ID (ID ベース)、項目の複数の特徴 (特徴ベース)、またはその両方の組み合わせを使用できます。特徴ベースのモデルでは、複数の特徴を使用して、ユーザーの動作が集合的にエンコードされます。このコードベースでは、構成可能な方法で ID ベースまたは特徴ベースのモデルを作成できます。
トレーニング後、レコメンド候補に上位 K 予測を直接提供できる、TensorFlow Lite モデルがエクスポートされます。
独自のトレーニングデータを使用する
トレーニング済みモデルに加え、オープンソースのツールキットを GitHub で提供しているので、独自のデータを使用してモデルをトレーニングすることができます。本チュートリアルでは、ツールキットの使い方、そしてトレーニング済みモデルを独自のモバイルアプリにデプロイする方法を学ぶことができます。
独自のデータセットを用いてレコメンドモデルをトレーニングする場合は、このチュートリアルに従い、ここで使用したのと同じ手法を適用してください。
使用例
例として、ID ベースのアプローチと特徴ベースのアプローチの両方を使用して、リコメンドモデルをトレーニングしました。ID ベースのモデルでは、動画 ID のみを入力として取ります。特徴ベースのモデルでは、動画 ID と動画ジャンル ID を入力として取ります。次の入出力の例を確認してください。
入力
コンテキスト動画 ID:
- The Lion King (ID: 362)
- Toy Story (ID: 1)
- (その他)
コンテキスト動画ジャンル ID:
- アニメ (ID: 15)
- キッズ (ID: 9)
- ミュージカル (ID: 13)
- アニメ (ID: 15)
- キッズ (ID: 9)
- コメディ (ID: 2)
- (その他)
出力:
- リコメンドされた動画 ID:
- Toy Story 2 (ID: 3114)
- (その他)
注意: このトレーニング済みモデルは、研究目的のために MovieLens データセットに基づいて構築されています。
パフォーマンスベンチマーク
パフォーマンスベンチマークの数値は、ここで説明するツールで生成されます。
| モデル名 | モデルサイズ | デバイス | CPU |
|---|---|---|---|
| リコメンド (入力は動画 ID) | 0.52 Mb | Pixel 3 | 0.09ms* |
| Pixel 4 | 0.05ms* | ||
| リコメンド (入力は動画 ID と動画ジャンル) | 1.3 Mb | Pixel 3 | 0.13ms* |
| Pixel 4 | 0.06ms* |
- 4 つのスレッドを使用。
独自のトレーニングデータを使用する
トレーニング済みモデルに加え、オープンソースのツールキットを GitHub で提供しているので、独自のデータを使用してモデルをトレーニングすることができます。本チュートリアルでは、ツールキットの使い方、そしてトレーニング済みモデルを独自のモバイルアプリにデプロイする方法を学ぶことができます。
独自のデータセットを用いてレコメンドモデルをトレーニングする場合は、このチュートリアルに従い、ここで使用したのと同じ手法を適用してください。
独自のデータによるモデルカスタマイズのヒント
このデモアプリケーションに統合されている事前トレーニング済みモデルは MovieLens データセットでトレーニングしていますが、独自のデータに基づいて、語彙サイズ、埋め込み次元、入力コンテキストの長さなどのモデル構成を変更することができます。以下にヒントを示します。
入力コンテキストの長さ: 入力コンテキストの最適な長さはデータセットによって異なります。ラベルのイベントの長期的関心と短期的コンテキストとの相関関係に基づいて、入力コンテキストの長さを選択することをお勧めします。
エンコーダタイプの選択: 入力コンテキストの長さに基づいて適切なエンコーダのタイプを選択することをお勧めします。Bag of Words エンコーダは入力コンテキストの長さが短い場合(例えば 10 未満)でよく機能しますが、CNN や RNN エンコーダは入力コンテキストの長さが長い場合により優れた要約力を発揮します。
基本の特徴を使用して、項目またはユーザーアクティビティを表すと、メモリ消費量が減り、デバイスに適合しやすくなるため、モデルパフォーマンスが改善され、新しい項目への対応が効果的になり、埋め込みスペースが減る可能性があります。