
| | |  Ver fuente en GitHub Ver fuente en GitHub |
Las recomendaciones personalizadas se usan ampliamente para una variedad de casos de uso en dispositivos móviles, como la recuperación de contenido multimedia, la sugerencia de productos de compra y la recomendación de la próxima aplicación. Si está interesado en proporcionar recomendaciones personalizadas en su aplicación respetando la privacidad del usuario, le recomendamos explorar el siguiente ejemplo y kit de herramientas.
Empezar
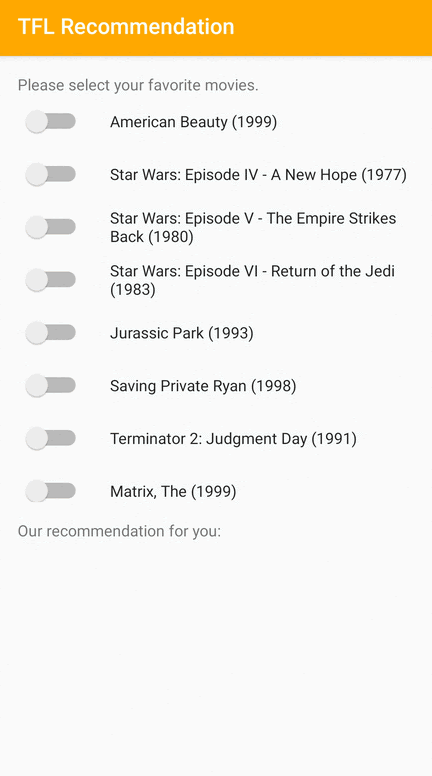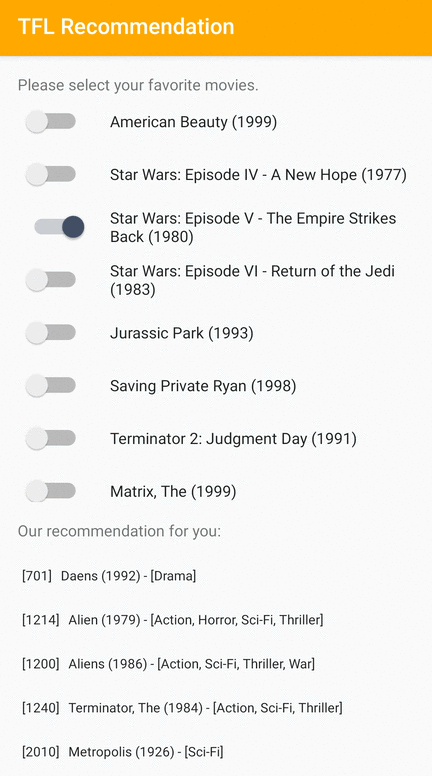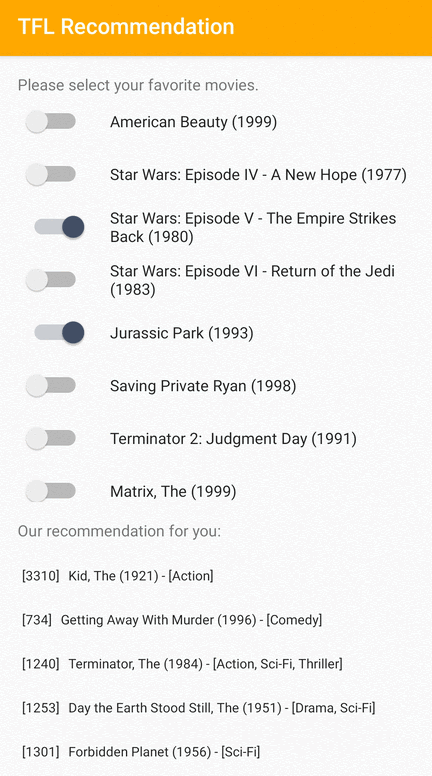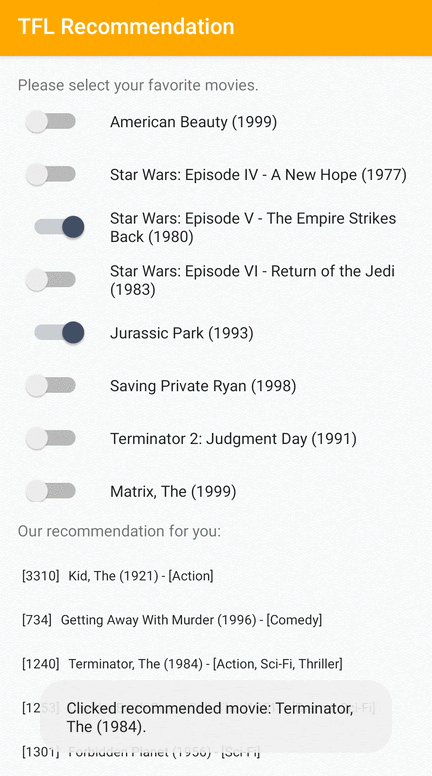
Proporcionamos una aplicación de muestra de TensorFlow Lite que demuestra cómo recomendar elementos relevantes a los usuarios en Android.
Si usa una plataforma que no sea Android, o si ya está familiarizado con las API de TensorFlow Lite, puede descargar nuestro modelo de recomendación para principiantes.
También proporcionamos un script de entrenamiento en Github para entrenar tu propio modelo de forma configurable.
Comprender la arquitectura del modelo
Aprovechamos una arquitectura de modelo de codificador dual, con codificador de contexto para codificar el historial de usuario secuencial y codificador de etiquetas para codificar el candidato de recomendación previsto. La similitud entre las codificaciones de contexto y etiqueta se utiliza para representar la probabilidad de que el candidato predicho satisfaga las necesidades del usuario.
Con este código base se proporcionan tres técnicas diferentes de codificación de historial de usuario secuencial:
- Codificador de bolsa de palabras (BOW): promedia las incrustaciones de las actividades del usuario sin considerar el orden del contexto.
- Codificador de red neuronal convolucional (CNN): aplica múltiples capas de redes neuronales convolucionales para generar codificación de contexto.
- Codificador de red neuronal recurrente (RNN): aplica una red neuronal recurrente para codificar una secuencia de contexto.
Para modelar la actividad de cada usuario, podríamos usar el ID del elemento de actividad (basado en ID), o múltiples funciones del elemento (basado en funciones), o una combinación de ambos. El modelo basado en funciones que utiliza múltiples funciones para codificar colectivamente el comportamiento de los usuarios. Con esta base de código, puede crear modelos basados en ID o basados en funciones de forma configurable.
Después del entrenamiento, se exportará un modelo de TensorFlow Lite que puede proporcionar directamente predicciones top-K entre los candidatos a recomendación.
Usa tus datos de entrenamiento
Además del modelo entrenado, proporcionamos un conjunto de herramientas de código abierto en GitHub para entrenar modelos con sus propios datos. Puede seguir este tutorial para aprender a usar el kit de herramientas e implementar modelos entrenados en sus propias aplicaciones móviles.
Siga este tutorial para aplicar la misma técnica utilizada aquí para entrenar un modelo de recomendación utilizando sus propios conjuntos de datos.
Ejemplos
Como ejemplos, entrenamos modelos de recomendación con enfoques basados en ID y en características. El modelo basado en ID toma solo los ID de películas como entrada, y el modelo basado en características toma tanto ID de películas como ID de género de películas como entradas. Encuentre los siguientes ejemplos de entradas y salidas.
Entradas
ID de películas contextuales:
- El Rey León (ID: 362)
- Historia del juguete (ID: 1)
- (y más)
ID de género de película de contexto:
- Animación (Número: 15)
- Infantil (DNI: 9)
- Musical (Número: 13)
- Animación (Número: 15)
- Infantil (DNI: 9)
- Comedia (Número: 2)
- (y más)
Salidas:
- ID de películas recomendadas:
- Toy Story 2 (ID: 3114)
- (y más)
Puntos de referencia de rendimiento
Los números de referencia de rendimiento se generan con la herramienta que se describe aquí .
| Nombre del modelo | Tamaño del modelo | Dispositivo | UPC |
|---|---|---|---|
| recomendación (ID de la película como entrada) | 0.52 MB | Píxel 3 | 0,09 ms* |
| Píxel 4 | 0,05 ms* | ||
| recomendación (ID de película y género de película como entradas) | 1.3 MB | Píxel 3 | 0,13 ms* |
| Píxel 4 | 0,06ms* |
* 4 hilos utilizados.
Usa tus datos de entrenamiento
Además del modelo entrenado, proporcionamos un conjunto de herramientas de código abierto en GitHub para entrenar modelos con sus propios datos. Puede seguir este tutorial para aprender a usar el kit de herramientas e implementar modelos entrenados en sus propias aplicaciones móviles.
Siga este tutorial para aplicar la misma técnica utilizada aquí para entrenar un modelo de recomendación utilizando sus propios conjuntos de datos.
Consejos para la personalización del modelo con sus datos
El modelo preentrenado integrado en esta aplicación de demostración está entrenado con el conjunto de datos de MovieLens , es posible que desee modificar la configuración del modelo en función de sus propios datos, como el tamaño del vocabulario, las dimensiones incrustadas y la longitud del contexto de entrada. Aquí hay algunos consejos:
Longitud del contexto de entrada: la mejor longitud del contexto de entrada varía según los conjuntos de datos. Sugerimos seleccionar la longitud del contexto de entrada en función de cuánto se correlacionan los eventos de etiqueta con los intereses a largo plazo frente al contexto a corto plazo.
Selección del tipo de codificador: sugerimos seleccionar el tipo de codificador en función de la longitud del contexto de entrada. El codificador de bolsa de palabras funciona bien para una longitud de contexto de entrada corta (por ejemplo, <10), los codificadores CNN y RNN brindan una mayor capacidad de resumen para una longitud de contexto de entrada larga.
El uso de características subyacentes para representar elementos o actividades del usuario podría mejorar el rendimiento del modelo, acomodar mejor los elementos nuevos, posiblemente reducir la escala de los espacios incrustados, por lo tanto, reducir el consumo de memoria y ser más amigable en el dispositivo.