
강화 학습을 사용하여 훈련되고 TensorFlow Lite로 배포된 에이전트와 보드 게임을 하세요.
시작하기
TensorFlow Lite를 처음 사용하고 Android로 작업하는 경우, 다음 예제 애플리케이션을 탐색하면 시작하는 데 도움이 됩니다.
Android 이외의 플랫폼을 사용 중이거나 이미 TensorFlow Lite API에 익숙하다면 훈련된 모델을 다운로드할 수 있습니다.
동작 원리
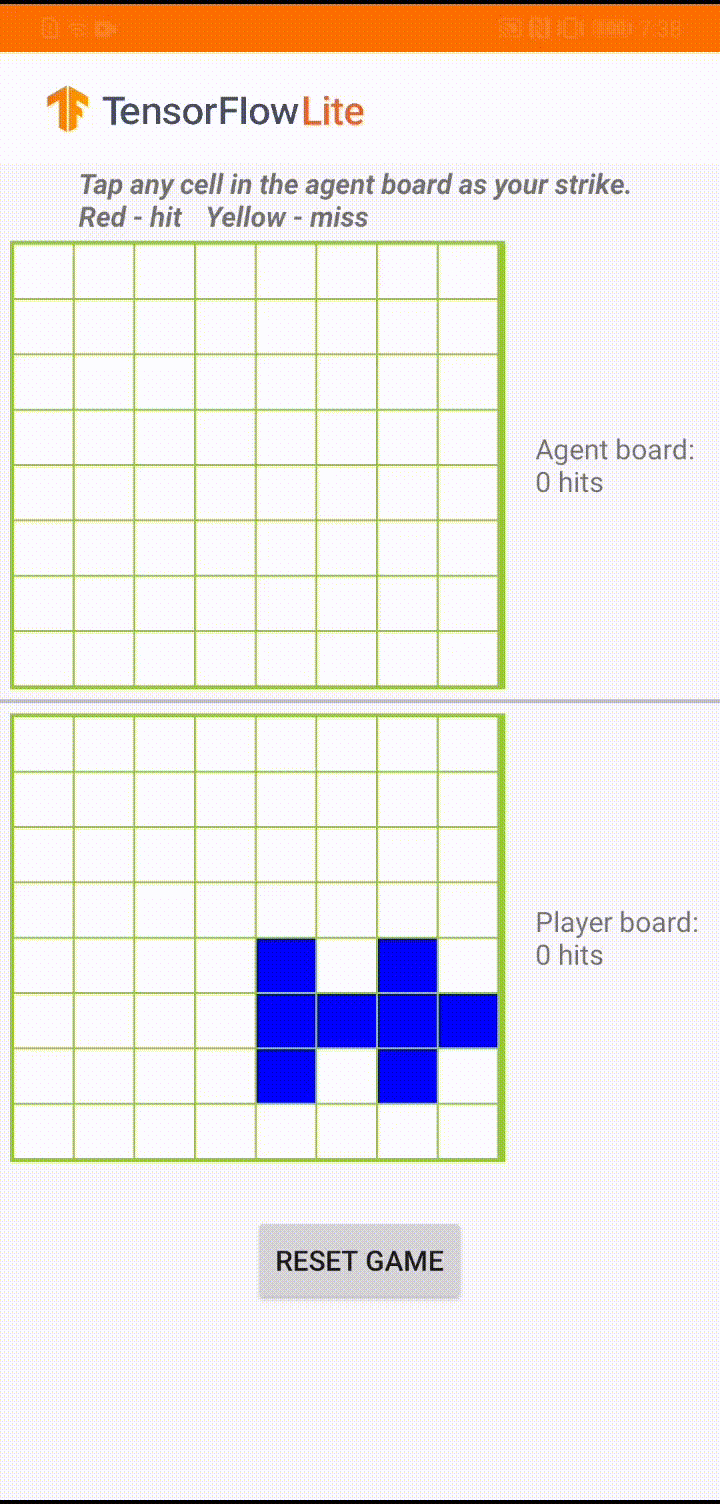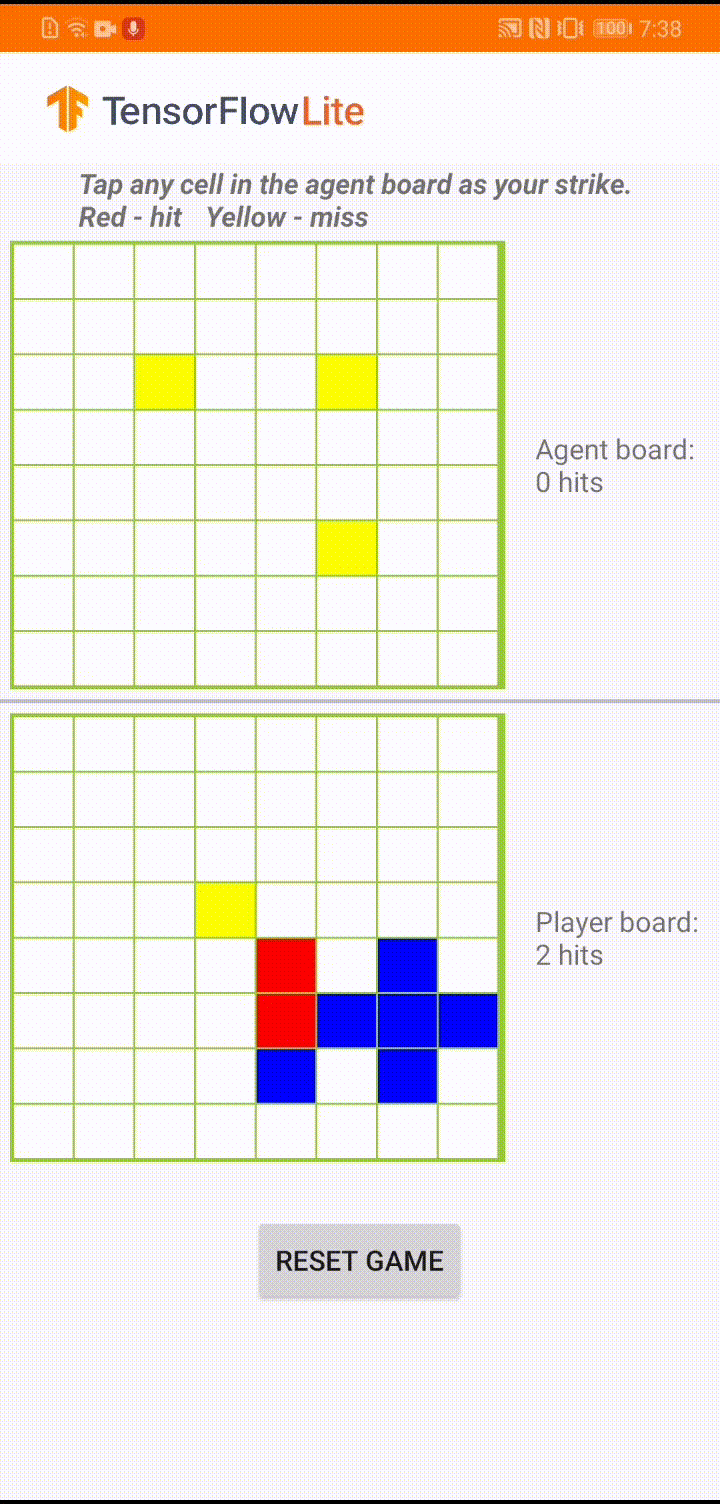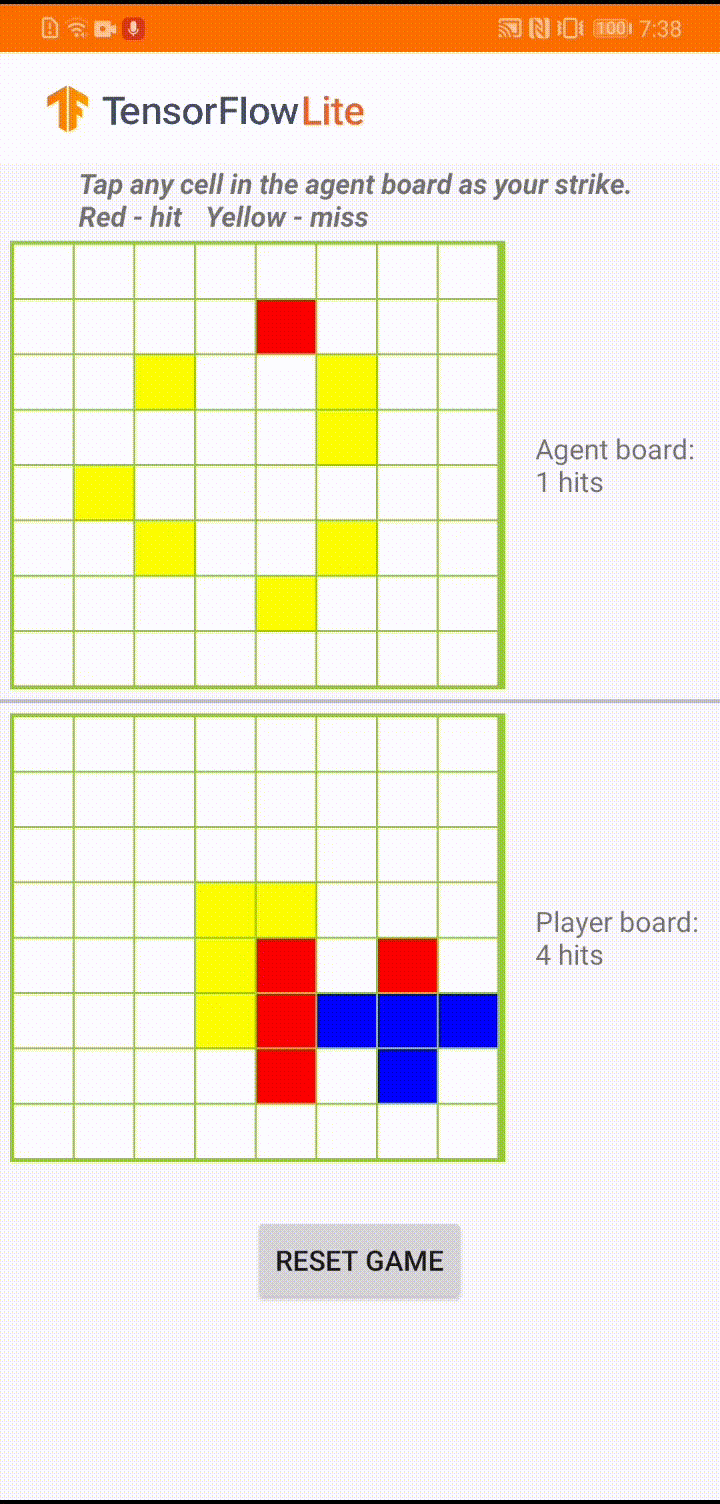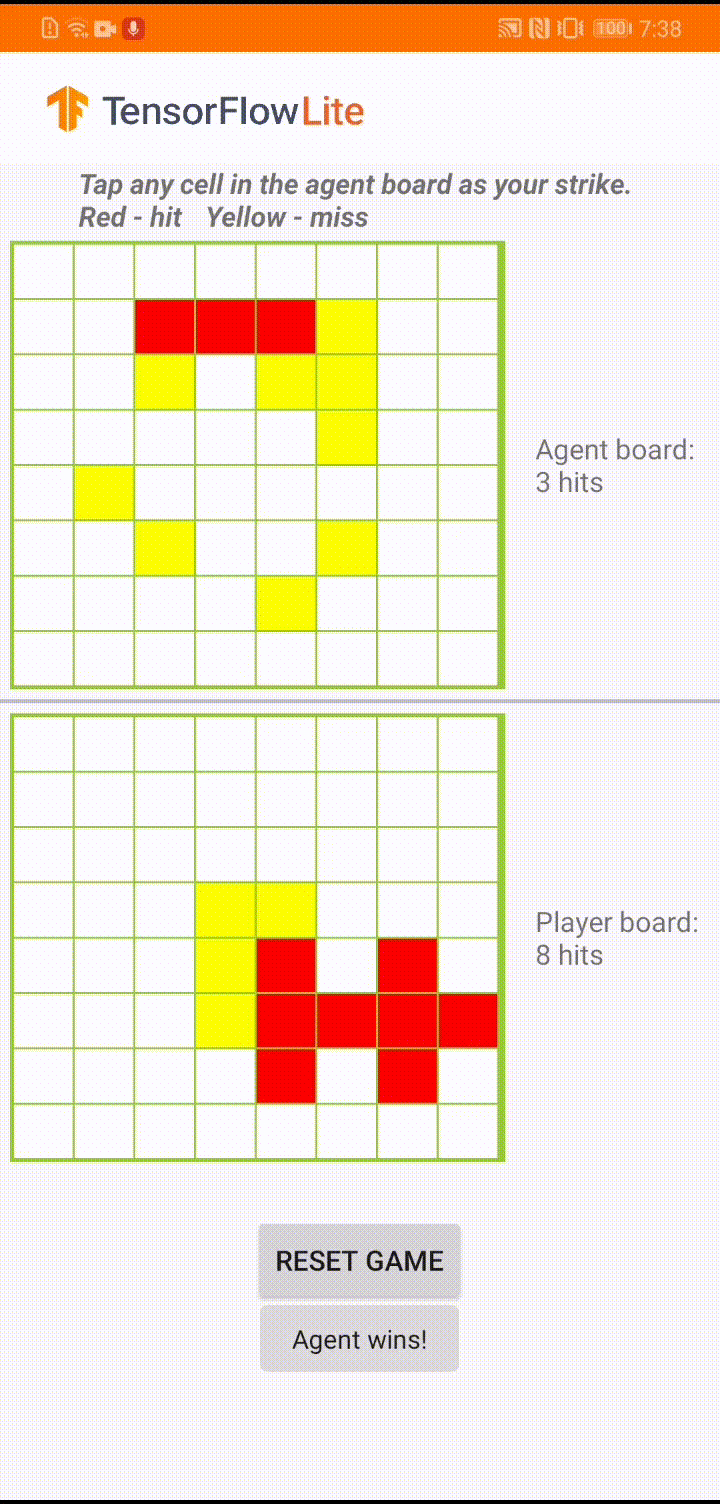
이 모델은 게임 에이전트가 'Plane Strike'라는 작은 보드 게임을 할 수 있도록 제작되었습니다. 이 게임과 규칙에 대한 간략한 소개는 이 README를 참조하세요.
앱의 UI 아래에 인간 플레이어와 대결하는 에이전트를 만들었습니다. 에이전트는 보드 상태를 입력으로 사용하고 64개의 가능한 보드 셀 각각에 대한 예측 점수를 출력하는 3계층 MLP입니다. 이 모델은 정책 그래디언트(REINFORCE)를 사용하여 학습되며 여기에서 학습 코드를 찾을 수 있습니다. 에이전트를 훈련한 후, 모델을 TFLite로 변환하고 Android 앱에 배포합니다.
Android 앱에서 실제 게임 플레이 중 에이전트가 움직일 차례가 되면 에이전트는 인간 플레이어의 보드 상태(하단 보드)를 확인합니다. 여기에는 이전의 성공 및 실패한 공격(적중 및 실패)에 대한 정보가 포함되며, 훈련된 모델을 사용하여 인간 플레이어보다 먼저 게임을 완료할 수 있도록 다음 공격 위치를 예측합니다.
성능 벤치마크
성능 벤치 마크 수치는 여기에 설명된 도구를 사용하여 생성됩니다.
| 모델명 | 모델 크기 | 기기 | CPU |
|---|---|---|---|
| 정책 그래디언트 | 84Kb | Pixel 3(Android 10) | 0.01ms* |
| Pixel 4(Android 10) | 0.01ms* |
- 1개의 스레드가 사용되었습니다.
입력
이 모델은 (1, 8, 8)의 3차원 float32 텐서를 보드 상태로 받아들입니다.
출력
이 모델은 64개의 가능한 공략 위치 각각에 대한 예측 점수로 형상 (1,64)의 2차원 float32 텐서를 반환합니다.
자신의 모델 훈련하기
훈련 코드에서 BOARD_SIZE 매개변수를 변경하여 더 크거나 작은 보드에 대해 자신의 모델을 훈련할 수 있습니다.