
|
|
|
 View source on GitHub View source on GitHub
|
|
|
One of the most exciting developments in deep learning to come out recently is artistic style transfer, or the ability to create a new image, known as a pastiche, based on two input images: one representing the artistic style and one representing the content.

Using this technique, we can generate beautiful new artworks in a range of styles.

If you are new to TensorFlow Lite and are working with Android, we recommend exploring the following example applications that can help you get started.
If you are using a platform other than Android or iOS, or you are already familiar with the TensorFlow Lite APIs, you can follow this tutorial to learn how to apply style transfer on any pair of content and style image with a pre-trained TensorFlow Lite model. You can use the model to add style transfer to your own mobile applications.
The model is open-sourced on GitHub. You can retrain the model with different parameters (e.g. increase content layers' weights to make the output image look more like the content image).
Understand the model architecture
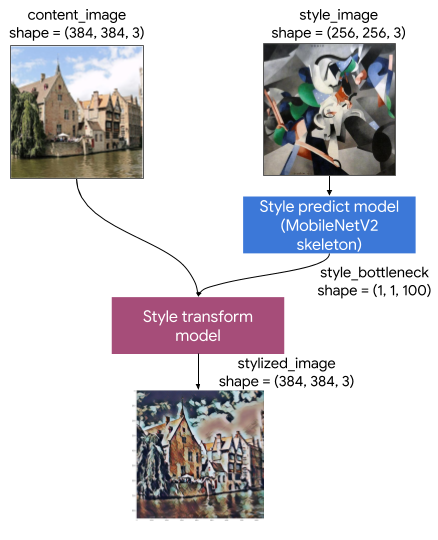
This Artistic Style Transfer model consists of two submodels:
- Style Prediciton Model: A MobilenetV2-based neural network that takes an input style image to a 100-dimension style bottleneck vector.
- Style Transform Model: A neural network that takes apply a style bottleneck vector to a content image and creates a stylized image.
If your app only needs to support a fixed set of style images, you can compute their style bottleneck vectors in advance, and exclude the Style Prediction Model from your app's binary.
Setup
Import dependencies.
import tensorflow as tf
print(tf.__version__)
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12,12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import time
import functools
Download the content and style images, and the pre-trained TensorFlow Lite models.
content_path = tf.keras.utils.get_file('belfry.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/belfry-2611573_1280.jpg')
style_path = tf.keras.utils.get_file('style23.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/style23.jpg')
style_predict_path = tf.keras.utils.get_file('style_predict.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/prediction/1?lite-format=tflite')
style_transform_path = tf.keras.utils.get_file('style_transform.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/transfer/1?lite-format=tflite')
Pre-process the inputs
- The content image and the style image must be RGB images with pixel values being float32 numbers between [0..1].
- The style image size must be (1, 256, 256, 3). We central crop the image and resize it.
- The content image must be (1, 384, 384, 3). We central crop the image and resize it.
# Function to load an image from a file, and add a batch dimension.
def load_img(path_to_img):
img = tf.io.read_file(path_to_img)
img = tf.io.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
img = img[tf.newaxis, :]
return img
# Function to pre-process by resizing an central cropping it.
def preprocess_image(image, target_dim):
# Resize the image so that the shorter dimension becomes 256px.
shape = tf.cast(tf.shape(image)[1:-1], tf.float32)
short_dim = min(shape)
scale = target_dim / short_dim
new_shape = tf.cast(shape * scale, tf.int32)
image = tf.image.resize(image, new_shape)
# Central crop the image.
image = tf.image.resize_with_crop_or_pad(image, target_dim, target_dim)
return image
# Load the input images.
content_image = load_img(content_path)
style_image = load_img(style_path)
# Preprocess the input images.
preprocessed_content_image = preprocess_image(content_image, 384)
preprocessed_style_image = preprocess_image(style_image, 256)
print('Style Image Shape:', preprocessed_style_image.shape)
print('Content Image Shape:', preprocessed_content_image.shape)
Visualize the inputs
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
plt.subplot(1, 2, 1)
imshow(preprocessed_content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(preprocessed_style_image, 'Style Image')
Run style transfer with TensorFlow Lite
Style prediction
# Function to run style prediction on preprocessed style image.
def run_style_predict(preprocessed_style_image):
# Load the model.
interpreter = tf.lite.Interpreter(model_path=style_predict_path)
# Set model input.
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
interpreter.set_tensor(input_details[0]["index"], preprocessed_style_image)
# Calculate style bottleneck.
interpreter.invoke()
style_bottleneck = interpreter.tensor(
interpreter.get_output_details()[0]["index"]
)()
return style_bottleneck
# Calculate style bottleneck for the preprocessed style image.
style_bottleneck = run_style_predict(preprocessed_style_image)
print('Style Bottleneck Shape:', style_bottleneck.shape)
Style transform
# Run style transform on preprocessed style image
def run_style_transform(style_bottleneck, preprocessed_content_image):
# Load the model.
interpreter = tf.lite.Interpreter(model_path=style_transform_path)
# Set model input.
input_details = interpreter.get_input_details()
interpreter.allocate_tensors()
# Set model inputs.
interpreter.set_tensor(input_details[0]["index"], preprocessed_content_image)
interpreter.set_tensor(input_details[1]["index"], style_bottleneck)
interpreter.invoke()
# Transform content image.
stylized_image = interpreter.tensor(
interpreter.get_output_details()[0]["index"]
)()
return stylized_image
# Stylize the content image using the style bottleneck.
stylized_image = run_style_transform(style_bottleneck, preprocessed_content_image)
# Visualize the output.
imshow(stylized_image, 'Stylized Image')
Style blending
We can blend the style of content image into the stylized output, which in turn making the output look more like the content image.
# Calculate style bottleneck of the content image.
style_bottleneck_content = run_style_predict(
preprocess_image(content_image, 256)
)
# Define content blending ratio between [0..1].
# 0.0: 0% style extracts from content image.
# 1.0: 100% style extracted from content image.
content_blending_ratio = 0.5
# Blend the style bottleneck of style image and content image
style_bottleneck_blended = content_blending_ratio * style_bottleneck_content \
+ (1 - content_blending_ratio) * style_bottleneck
# Stylize the content image using the style bottleneck.
stylized_image_blended = run_style_transform(style_bottleneck_blended,
preprocessed_content_image)
# Visualize the output.
imshow(stylized_image_blended, 'Blended Stylized Image')
Performance Benchmarks
Performance benchmark numbers are generated with the tool described here.
| Model name | Model size | Device | NNAPI | CPU | GPU |
|---|---|---|---|---|---|
| Style prediction model (int8) | 2.8 Mb | Pixel 3 (Android 10) | 142ms | 14ms | |
| Pixel 4 (Android 10) | 5.2ms | 6.7ms | |||
| iPhone XS (iOS 12.4.1) | 10.7ms | ||||
| Style transform model (int8) | 0.2 Mb | Pixel 3 (Android 10) | 540ms | ||
| Pixel 4 (Android 10) | 405ms | ||||
| iPhone XS (iOS 12.4.1) | 251ms | ||||
| Style prediction model (float16) | 4.7 Mb | Pixel 3 (Android 10) | 86ms | 28ms | 9.1ms |
| Pixel 4 (Android 10) | 32ms | 12ms | 10ms | ||
| Style transfer model (float16) | 0.4 Mb | Pixel 3 (Android 10) | 1095ms | 545ms | 42ms |
| Pixel 4 (Android 10) | 603ms | 377ms | 42ms |
* 4 threads used.
** 2 threads on iPhone for the best performance.