

La clasificación de videos es la tarea de aprendizaje automático de identificar lo que representa un video. Un modelo de clasificación de videos se entrena en un conjunto de datos de videos que contiene un conjunto de clases únicas, como diferentes acciones o movimientos. El modelo recibe fotogramas de vídeo como entrada y genera la probabilidad de que cada clase esté representada en el vídeo.
Los modelos de clasificación de videos y de imágenes utilizan imágenes como entradas para predecir las probabilidades de que aquellas imágenes pertenezcan a clases predefinidas. Sin embargo, un modelo de clasificación de vídeo también procesa las relaciones espacio-temporales entre fotogramas adyacentes para reconocer las acciones en un vídeo.
Por ejemplo, se puede entrenar un modelo de reconocimiento de acciones de video para identificar acciones humanas como correr, aplaudir y saludar. La siguiente imagen muestra el resultado de un modelo de clasificación de videos en Android.
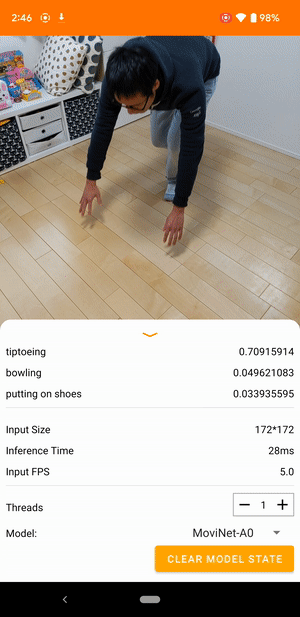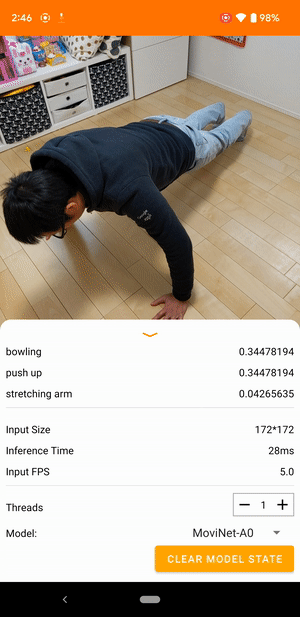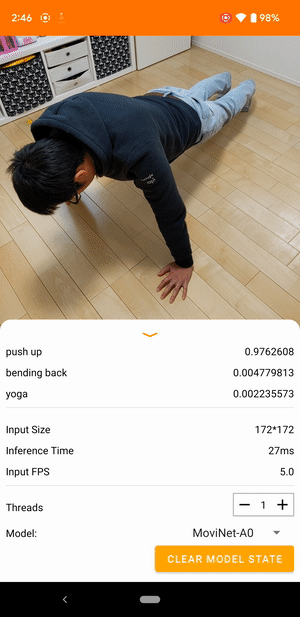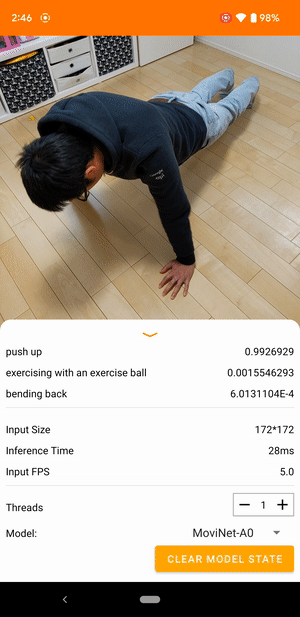
Empezar
Si está utilizando una plataforma que no sea Android o Raspberry Pi, o si ya está familiarizado con las API de TensorFlow Lite , descargue el modelo de clasificación de videos inicial y los archivos de soporte. También puede crear su propio canal de inferencia personalizado utilizando la biblioteca de soporte de TensorFlow Lite .
Descargar el modelo inicial con metadatos
Si es nuevo en TensorFlow Lite y está trabajando con Android o Raspberry Pi, explore las siguientes aplicaciones de ejemplo para ayudarlo a comenzar.
Androide
La aplicación de Android utiliza la cámara trasera del dispositivo para la clasificación continua de vídeos. La inferencia se realiza utilizando la API Java de TensorFlow Lite . La aplicación de demostración clasifica fotogramas y muestra las clasificaciones previstas en tiempo real.
Frambuesa Pi
El ejemplo de Raspberry Pi utiliza TensorFlow Lite con Python para realizar una clasificación de video continua. Conecte la Raspberry Pi a una cámara, como Pi Camera, para realizar una clasificación de video en tiempo real. Para ver los resultados de la cámara, conecte un monitor a la Raspberry Pi y use SSH para acceder al shell del Pi (para evitar conectar un teclado al Pi).
Antes de comenzar, configure su Raspberry Pi con el sistema operativo Raspberry Pi (preferiblemente actualizado a Buster).
Descripcion del modelo
Las redes de vídeo móviles ( MoViNets ) son una familia de modelos eficientes de clasificación de vídeos optimizados para dispositivos móviles. MoViNets demuestra precisión y eficiencia de última generación en varios conjuntos de datos de reconocimiento de acciones de video a gran escala, lo que los hace muy adecuados para tareas de reconocimiento de acciones de video .
Hay tres variantes del modelo MoviNet para TensorFlow Lite: MoviNet-A0 , MoviNet-A1 y MoviNet-A2 . Estas variantes fueron entrenadas con el conjunto de datos Kinetics-600 para reconocer 600 acciones humanas diferentes. MoviNet-A0 es el más pequeño, más rápido y menos preciso. MoviNet-A2 es el más grande, el más lento y el más preciso. MoviNet-A1 es un compromiso entre A0 y A2.
Cómo funciona
Durante la capacitación, se proporciona un modelo de clasificación de videos y sus etiquetas asociadas. Cada etiqueta es el nombre de un concepto o clase distinta que el modelo aprenderá a reconocer. Para el reconocimiento de acciones de video , los videos serán de acciones humanas y las etiquetas serán la acción asociada.
El modelo de clasificación de videos puede aprender a predecir si los videos nuevos pertenecen a alguna de las clases proporcionadas durante la capacitación. Este proceso se llama inferencia . También puede utilizar el aprendizaje por transferencia para identificar nuevas clases de vídeos utilizando un modelo preexistente.
El modelo es un modelo de streaming que recibe vídeo continuo y responde en tiempo real. A medida que el modelo recibe una transmisión de video, identifica si alguna de las clases del conjunto de datos de entrenamiento está representada en el video. Para cada cuadro, el modelo devuelve estas clases, junto con la probabilidad de que el video represente la clase. Un resultado de ejemplo en un momento dado podría verse así:
| Acción | Probabilidad |
|---|---|
| baile cuadrado | 0,02 |
| aguja de enhebrar | 0,08 |
| jugueteando con los dedos | 0,23 |
| Mano que saluda | 0,67 |
Cada acción en la salida corresponde a una etiqueta en los datos de entrenamiento. La probabilidad denota la probabilidad de que la acción se muestre en el vídeo.
Entradas del modelo
El modelo acepta un flujo de fotogramas de vídeo RGB como entrada. El tamaño del vídeo de entrada es flexible, pero lo ideal es que coincida con la resolución y la velocidad de fotogramas del entrenamiento del modelo:
- MoviNet-A0 : 172 x 172 a 5 fps
- MoviNet-A1 : 172 x 172 a 5 fps
- MoviNet-A1 : 224 x 224 a 5 fps
Se espera que los vídeos de entrada tengan valores de color dentro del rango de 0 y 1, siguiendo las convenciones de entrada de imágenes comunes.
Internamente, el modelo también analiza el contexto de cada cuadro utilizando información recopilada en cuadros anteriores. Esto se logra tomando estados internos de la salida del modelo y reintroduciéndolos en el modelo para los siguientes fotogramas.
Salidas del modelo
El modelo devuelve una serie de etiquetas y sus puntuaciones correspondientes. Las puntuaciones son valores logit que representan la predicción para cada clase. Estas puntuaciones se pueden convertir en probabilidades utilizando la función softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Internamente, la salida del modelo también incluye estados internos del modelo y los devuelve al modelo para los próximos fotogramas.
Puntos de referencia de rendimiento
Los números de referencia de rendimiento se generan con la herramienta de evaluación comparativa . MoviNets sólo soporta CPU.
El rendimiento del modelo se mide por la cantidad de tiempo que le toma a un modelo ejecutar la inferencia en una pieza de hardware determinada. Un tiempo menor implica un modelo más rápido. La precisión se mide por la frecuencia con la que el modelo clasifica correctamente una clase en un vídeo.
| Nombre del modelo | Tamaño | Exactitud * | Dispositivo | UPC ** |
|---|---|---|---|---|
| MoviNet-A0 (Cuantificación entera) | 3,1 megas | sesenta y cinco% | Píxel 4 | 5 ms |
| Píxel 3 | 11 ms | |||
| MoviNet-A1 (Cuantificación entera) | 4,5MB | 70% | Píxel 4 | 8 ms |
| Píxel 3 | 19 ms | |||
| MoviNet-A2 (Cuantificación entera) | 5,1 megas | 72% | Píxel 4 | 15 ms |
| Píxel 3 | 36 ms |
* Precisión máxima medida en el conjunto de datos Kinetics-600 .
** Latencia medida cuando se ejecuta en CPU con 1 subproceso.
Personalización del modelo
Los modelos previamente entrenados están entrenados para reconocer 600 acciones humanas del conjunto de datos Kinetics-600 . También puede utilizar el aprendizaje por transferencia para volver a entrenar un modelo para que reconozca acciones humanas que no están en el conjunto original. Para ello, necesitas un conjunto de vídeos formativos para cada una de las nuevas acciones que quieras incorporar al modelo.
Para obtener más información sobre cómo ajustar modelos en datos personalizados, consulte el repositorio de MoViNets y el tutorial de MoViNets .
Más lecturas y recursos
Utilice los siguientes recursos para obtener más información sobre los conceptos tratados en esta página: