

La classification vidéo est la tâche d'apprentissage automatique consistant à identifier ce que représente une vidéo. Un modèle de classification vidéo est entraîné sur un ensemble de données vidéo qui contient un ensemble de classes uniques, telles que différentes actions ou mouvements. Le modèle reçoit des images vidéo en entrée et génère la probabilité que chaque classe soit représentée dans la vidéo.
Les modèles de classification vidéo et de classification d'images utilisent tous deux des images comme entrées pour prédire les probabilités que ces images appartiennent à des classes prédéfinies. Cependant, un modèle de classification vidéo traite également les relations spatio-temporelles entre images adjacentes pour reconnaître les actions dans une vidéo.
Par exemple, un modèle de reconnaissance d'actions vidéo peut être entraîné pour identifier les actions humaines telles que courir, applaudir et saluer. L'image suivante montre la sortie d'un modèle de classification vidéo sur Android.
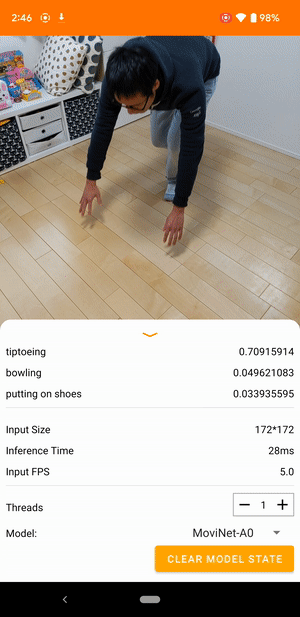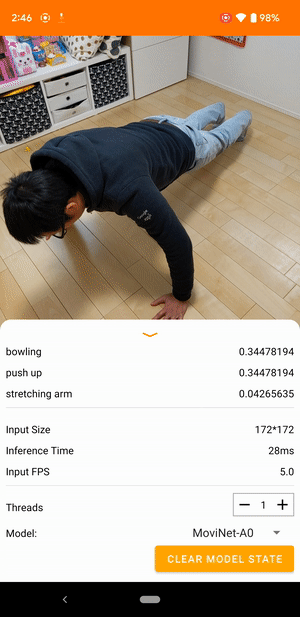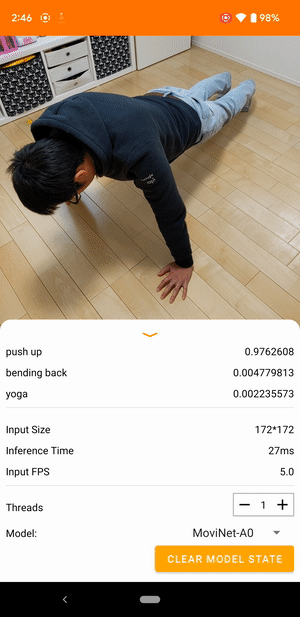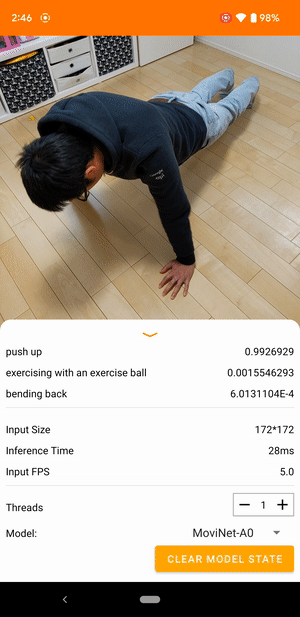
Commencer
Si vous utilisez une plate-forme autre qu'Android ou Raspberry Pi, ou si vous connaissez déjà les API TensorFlow Lite , téléchargez le modèle de classification vidéo de démarrage et les fichiers de support. Vous pouvez également créer votre propre pipeline d'inférence personnalisé à l'aide de la bibliothèque de support TensorFlow Lite .
Télécharger le modèle de démarrage avec métadonnées
Si vous débutez avec TensorFlow Lite et travaillez avec Android ou Raspberry Pi, explorez les exemples d'applications suivants pour vous aider à démarrer.
Android
L'application Android utilise la caméra arrière de l'appareil pour une classification vidéo continue. L'inférence est effectuée à l'aide de l' API Java TensorFlow Lite . L'application de démonstration classe les cadres et affiche les classifications prévues en temps réel.
Tarte aux framboises
L'exemple Raspberry Pi utilise TensorFlow Lite avec Python pour effectuer une classification vidéo continue. Connectez le Raspberry Pi à une caméra, comme la Pi Camera, pour effectuer une classification vidéo en temps réel. Pour afficher les résultats de la caméra, connectez un moniteur au Raspberry Pi et utilisez SSH pour accéder au shell Pi (pour éviter de connecter un clavier au Pi).
Avant de commencer, configurez votre Raspberry Pi avec le système d'exploitation Raspberry Pi (de préférence mis à jour vers Buster).
Description du modèle
Les réseaux vidéo mobiles ( MoViNets ) sont une famille de modèles de classification vidéo efficaces optimisés pour les appareils mobiles. Les MoViNets démontrent une précision et une efficacité de pointe sur plusieurs ensembles de données de reconnaissance d'actions vidéo à grande échelle, ce qui les rend bien adaptés aux tâches de reconnaissance d'actions vidéo .
Il existe trois variantes du modèle MoviNet pour TensorFlow Lite : MoviNet-A0 , MoviNet-A1 et MoviNet-A2 . Ces variantes ont été entraînées avec l'ensemble de données Kinetics-600 pour reconnaître 600 actions humaines différentes. MoviNet-A0 est le plus petit, le plus rapide et le moins précis. MoviNet-A2 est le plus grand, le plus lent et le plus précis. MoviNet-A1 est un compromis entre A0 et A2.
Comment ça fonctionne
Lors de la formation, un modèle de classification vidéo est fourni aux vidéos et à leurs étiquettes associées. Chaque étiquette est le nom d'un concept ou d'une classe distincte que le modèle apprendra à reconnaître. Pour la reconnaissance d'actions vidéo , les vidéos concerneront des actions humaines et les étiquettes seront l'action associée.
Le modèle de classification vidéo peut apprendre à prédire si les nouvelles vidéos appartiennent à l'un des cours dispensés pendant la formation. Ce processus est appelé inférence . Vous pouvez également utiliser l'apprentissage par transfert pour identifier de nouvelles classes de vidéos en utilisant un modèle préexistant.
Le modèle est un modèle de streaming qui reçoit une vidéo continue et répond en temps réel. Lorsque le modèle reçoit un flux vidéo, il identifie si l'une des classes de l'ensemble de données d'entraînement est représentée dans la vidéo. Pour chaque image, le modèle renvoie ces classes, ainsi que la probabilité que la vidéo représente la classe. Un exemple de résultat à un moment donné pourrait ressembler à ceci :
| Action | Probabilité |
|---|---|
| danse carrée | 0,02 |
| aiguille à enfiler | 0,08 |
| se tourner les doigts | 0,23 |
| Agitant la main | 0,67 |
Chaque action dans la sortie correspond à une étiquette dans les données d'entraînement. La probabilité indique la probabilité que l'action soit affichée dans la vidéo.
Entrées du modèle
Le modèle accepte un flux d’images vidéo RVB en entrée. La taille de la vidéo d'entrée est flexible, mais idéalement, elle correspond à la résolution et à la fréquence d'images de l'entraînement du modèle :
- MoviNet-A0 : 172 x 172 à 5 ips
- MoviNet-A1 : 172 x 172 à 5 ips
- MoviNet-A1 : 224 x 224 à 5 ips
Les vidéos d'entrée doivent avoir des valeurs de couleur comprises entre 0 et 1, conformément aux conventions courantes d'entrée d'image .
En interne, le modèle analyse également le contexte de chaque image en utilisant les informations recueillies dans les images précédentes. Ceci est accompli en prenant les états internes de la sortie du modèle et en les réinjectant dans le modèle pour les images à venir.
Résultats du modèle
Le modèle renvoie une série d'étiquettes et leurs scores correspondants. Les scores sont des valeurs logit qui représentent la prédiction pour chaque classe. Ces scores peuvent être convertis en probabilités en utilisant la fonction softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
En interne, la sortie du modèle inclut également les états internes du modèle et les réinjecte dans le modèle pour les images à venir.
Repères de performances
Les numéros de référence de performance sont générés avec l' outil d'analyse comparative . Les MoviNets ne prennent en charge que le processeur.
Les performances du modèle sont mesurées par le temps nécessaire à un modèle pour exécuter l'inférence sur un élément matériel donné. Un temps inférieur implique un modèle plus rapide. La précision est mesurée par la fréquence à laquelle le modèle classe correctement une classe dans une vidéo.
| Nom du modèle | Taille | Précision * | Appareil | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (Entier quantifié) | 3,1 Mo | 65% | Pixel4 | 5 ms |
| Pixel 3 | 11 ms | |||
| MoviNet-A1 (Entier quantifié) | 4,5 Mo | 70% | Pixel4 | 8 ms |
| Pixel 3 | 19 ms | |||
| MoviNet-A2 (Entier quantifié) | 5,1 Mo | 72% | Pixel4 | 15 ms |
| Pixel 3 | 36 ms |
* Précision Top-1 mesurée sur l'ensemble de données Kinetics-600 .
** Latence mesurée lors de l'exécution sur un processeur à 1 thread.
Personnalisation du modèle
Les modèles pré-entraînés sont formés pour reconnaître 600 actions humaines à partir de l'ensemble de données Kinetics-600 . Vous pouvez également utiliser l'apprentissage par transfert pour recycler un modèle afin qu'il reconnaisse les actions humaines qui ne figurent pas dans l'ensemble d'origine. Pour ce faire, vous avez besoin d'un ensemble de vidéos de formation pour chacune des nouvelles actions que vous souhaitez intégrer dans le modèle.
Pour en savoir plus sur le réglage fin des modèles sur des données personnalisées, consultez le référentiel MoViNets et le didacticiel MoViNets .
Lectures complémentaires et ressources
Utilisez les ressources suivantes pour en savoir plus sur les concepts abordés sur cette page :