

การจัดหมวดหมู่วิดีโอ เป็นงานการเรียนรู้ของเครื่องในการระบุว่าวิดีโอแสดงถึงอะไร โมเดลการจัดหมวดหมู่วิดีโอได้รับการฝึกฝนบนชุดข้อมูลวิดีโอที่มีชุดคลาสเฉพาะ เช่น การกระทำหรือการเคลื่อนไหวที่แตกต่างกัน โมเดลจะได้รับเฟรมวิดีโอเป็นอินพุตและเอาท์พุตความน่าจะเป็นของแต่ละคลาสที่แสดงในวิดีโอ
การจัดหมวดหมู่วิดีโอและแบบจำลองการจัดหมวดหมู่รูปภาพใช้รูปภาพเป็นอินพุตเพื่อทำนายความน่าจะเป็นของรูปภาพเหล่านั้นที่อยู่ในคลาสที่กำหนดไว้ล่วงหน้า อย่างไรก็ตาม โมเดลการจัดหมวดหมู่วิดีโอยังประมวลผลความสัมพันธ์เชิงพื้นที่และชั่วคราวระหว่างเฟรมที่อยู่ติดกันเพื่อจดจำการกระทำในวิดีโอ
ตัวอย่างเช่น สามารถฝึกโมเดล การจดจำการกระทำของวิดีโอ เพื่อระบุการกระทำของมนุษย์ เช่น การวิ่ง การปรบมือ และการโบกมือ รูปภาพต่อไปนี้แสดงเอาต์พุตของโมเดลการจัดหมวดหมู่วิดีโอบน Android
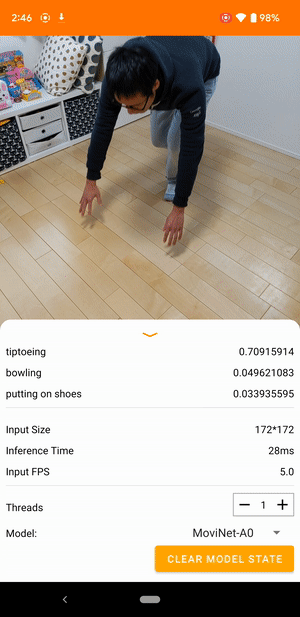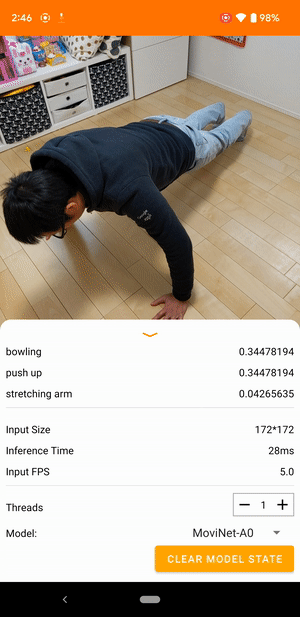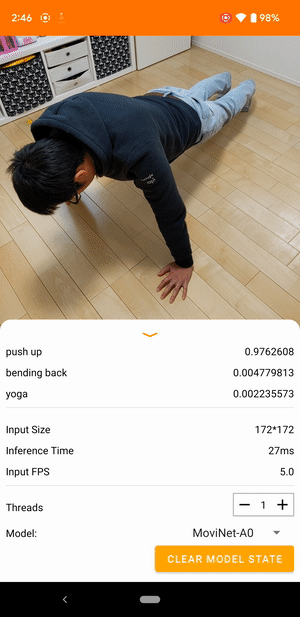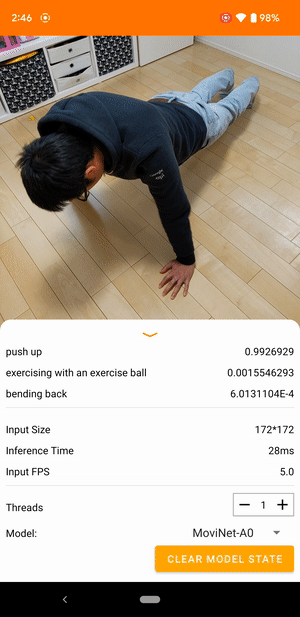
เริ่ม
หากคุณใช้แพลตฟอร์มอื่นที่ไม่ใช่ Android หรือ Raspberry Pi หรือหากคุณคุ้นเคยกับ TensorFlow Lite API อยู่แล้ว ให้ดาวน์โหลดโมเดลการจัดหมวดหมู่วิดีโอเริ่มต้นและไฟล์ที่รองรับ คุณยังสามารถสร้างไปป์ไลน์การอนุมานที่คุณกำหนดเองได้โดยใช้ TensorFlow Lite Support Library
ดาวน์โหลดโมเดลเริ่มต้นพร้อมข้อมูลเมตา
หากคุณยังใหม่กับ TensorFlow Lite และกำลังใช้งาน Android หรือ Raspberry Pi ให้สำรวจแอปพลิเคชันตัวอย่างต่อไปนี้เพื่อช่วยคุณในการเริ่มต้น
หุ่นยนต์
แอปพลิเคชัน Android ใช้กล้องหลังของอุปกรณ์เพื่อจัดหมวดหมู่วิดีโออย่างต่อเนื่อง การอนุมานดำเนินการโดยใช้ TensorFlow Lite Java API แอปสาธิตจะจัดประเภทเฟรมและแสดงการจำแนกประเภทที่คาดการณ์ไว้แบบเรียลไทม์
ราสเบอร์รี่ปี่
ตัวอย่าง Raspberry Pi ใช้ TensorFlow Lite กับ Python เพื่อจัดหมวดหมู่วิดีโออย่างต่อเนื่อง เชื่อมต่อ Raspberry Pi เข้ากับกล้อง เช่น Pi Camera เพื่อจัดหมวดหมู่วิดีโอแบบเรียลไทม์ หากต้องการดูผลลัพธ์จากกล้อง ให้เชื่อมต่อจอภาพกับ Raspberry Pi และใช้ SSH เพื่อเข้าถึงเปลือก Pi (เพื่อหลีกเลี่ยงการเชื่อมต่อแป้นพิมพ์กับ Pi)
ก่อนเริ่มต้น ให้ตั้งค่า Raspberry Pi ของคุณด้วย Raspberry Pi OS (ควรอัปเดตเป็น Buster จะดีกว่า)
คำอธิบายโมเดล
เครือข่ายวิดีโอบนมือถือ ( MoViNets ) คือกลุ่มโมเดลการจัดหมวดหมู่วิดีโอที่มีประสิทธิภาพซึ่งปรับให้เหมาะกับอุปกรณ์เคลื่อนที่ MoViNets แสดงให้เห็นถึงความแม่นยำและประสิทธิภาพที่ล้ำสมัยบนชุดข้อมูลการจดจำการกระทำของวิดีโอขนาดใหญ่หลายชุด ทำให้เหมาะสำหรับงาน การจดจำการกระทำของวิดีโอ
รุ่น MoviNet สำหรับ TensorFlow Lite มีสามรุ่น: MoviNet-A0 , MoviNet-A1 และ MoviNet-A2 ตัวแปรเหล่านี้ได้รับการฝึกอบรมด้วยชุดข้อมูล Kinetics-600 เพื่อจดจำการกระทำของมนุษย์ที่แตกต่างกัน 600 รายการ MoviNet-A0 มีขนาดเล็กที่สุด เร็วที่สุด และแม่นยำน้อยที่สุด MoviNet-A2 ใหญ่ที่สุด ช้าที่สุด และแม่นยำที่สุด MoviNet-A1 เป็นการประนีประนอมระหว่าง A0 และ A2
มันทำงานอย่างไร
ในระหว่างการฝึก โมเดลการจัดหมวดหมู่วิดีโอจะได้รับวิดีโอและ ป้ายกำกับ ที่เกี่ยวข้อง แต่ละป้ายกำกับคือชื่อของแนวคิดหรือคลาสที่แตกต่างกัน ซึ่งโมเดลจะเรียนรู้ที่จะจดจำ สำหรับ การจดจำการกระทำของวิดีโอ วิดีโอจะเป็นการกระทำของมนุษย์และป้ายกำกับจะเป็นการกระทำที่เกี่ยวข้อง
โมเดลการจัดหมวดหมู่วิดีโอสามารถเรียนรู้ที่จะคาดการณ์ว่าวิดีโอใหม่อยู่ในชั้นเรียนใดๆ ที่จัดไว้ให้ระหว่างการฝึกอบรมหรือไม่ กระบวนการนี้เรียกว่า การอนุมาน คุณยังสามารถใช้ การเรียนรู้แบบถ่ายโอน เพื่อระบุคลาสใหม่ของวิดีโอได้โดยใช้โมเดลที่มีอยู่แล้ว
โมเดลนี้เป็นโมเดลสตรีมมิ่งที่รับวิดีโอต่อเนื่องและตอบสนองแบบเรียลไทม์ เมื่อโมเดลได้รับสตรีมวิดีโอ จะระบุว่ามีคลาสใดจากชุดข้อมูลการฝึกอบรมที่แสดงในวิดีโอหรือไม่ สำหรับแต่ละเฟรม โมเดลจะส่งคืนคลาสเหล่านี้ พร้อมกับความน่าจะเป็นที่วิดีโอจะเป็นตัวแทนของคลาสนั้น ตัวอย่างเอาต์พุต ณ เวลาที่กำหนดอาจมีลักษณะดังนี้:
| การกระทำ | ความน่าจะเป็น |
|---|---|
| การเต้นรำแบบสี่เหลี่ยม | 0.02 |
| เข็มสนเข็ม | 0.08 |
| นิ้วกระตุก | 0.23 |
| โบกมือ | 0.67 |
แต่ละการกระทำในเอาต์พุตจะสอดคล้องกับป้ายกำกับในข้อมูลการฝึก ความน่าจะเป็นแสดงถึงความน่าจะเป็นที่การกระทำดังกล่าวจะถูกแสดงในวิดีโอ
อินพุตโมเดล
โมเดลยอมรับสตรีมของเฟรมวิดีโอ RGB เป็นอินพุต ขนาดของวิดีโออินพุตมีความยืดหยุ่น แต่ในทางที่ดีแล้วจะเหมาะกับความละเอียดและอัตราเฟรมของการฝึกโมเดล:
- MoviNet-A0 : 172 x 172 ที่ 5 เฟรมต่อวินาที
- MoviNet-A1 : 172 x 172 ที่ 5 เฟรมต่อวินาที
- MoviNet-A1 : 224 x 224 ที่ 5 เฟรมต่อวินาที
วิดีโออินพุตคาดว่าจะมีค่าสีภายในช่วง 0 และ 1 ตาม รูปแบบการป้อนรูปภาพ ทั่วไป
ภายใน โมเดลยังวิเคราะห์บริบทของแต่ละเฟรมโดยใช้ข้อมูลที่รวบรวมในเฟรมก่อนหน้า ซึ่งสามารถทำได้โดยการนำสถานะภายในจากเอาท์พุตโมเดลและป้อนกลับเข้าไปในโมเดลสำหรับเฟรมที่กำลังจะมาถึง
เอาท์พุตโมเดล
โมเดลส่งคืนชุดป้ายกำกับและคะแนนที่เกี่ยวข้อง คะแนนคือค่า logit ที่แสดงถึงการทำนายสำหรับแต่ละคลาส คะแนนเหล่านี้สามารถแปลงเป็นความน่าจะเป็นได้โดยใช้ฟังก์ชัน softmax ( tf.nn.softmax )
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
ภายใน เอาท์พุตโมเดลยังรวมสถานะภายในจากโมเดลและฟีดกลับเข้าไปในโมเดลสำหรับเฟรมที่กำลังจะมาถึง
เกณฑ์มาตรฐานประสิทธิภาพ
หมายเลขเกณฑ์มาตรฐานประสิทธิภาพสร้างขึ้นด้วย เครื่องมือเปรียบเทียบ MoviNets รองรับเฉพาะ CPU เท่านั้น
ประสิทธิภาพของโมเดลวัดจากระยะเวลาที่ใช้สำหรับโมเดลในการอนุมานบนชิ้นส่วนฮาร์ดแวร์ที่ระบุ เวลาที่น้อยลงหมายถึงโมเดลที่เร็วกว่า ความแม่นยำวัดจากความถี่ที่โมเดลจัดประเภทคลาสในวิดีโอได้อย่างถูกต้อง
| ชื่อรุ่น | ขนาด | ความแม่นยำ * | อุปกรณ์ | ซีพียู ** |
|---|---|---|---|---|
| MoviNet-A0 (ปริมาณจำนวนเต็ม) | 3.1 ลบ | 65% | พิกเซล 4 | 5 มิลลิวินาที |
| พิกเซล 3 | 11 น | |||
| MoviNet-A1 (ปริมาณจำนวนเต็ม) | 4.5 ลบ | 70% | พิกเซล 4 | 8 มิลลิวินาที |
| พิกเซล 3 | 19 น | |||
| MoviNet-A2 (ปริมาณจำนวนเต็ม) | 5.1 ลบ | 72% | พิกเซล 4 | 15 มิลลิวินาที |
| พิกเซล 3 | 36 น |
* ความแม่นยำอันดับ 1 วัดจากชุดข้อมูล Kinetics-600
** เวลาแฝงวัดเมื่อทำงานบน CPU แบบ 1 เธรด
การปรับแต่งโมเดล
โมเดลที่ได้รับการฝึกอบรมล่วงหน้าได้รับการฝึกอบรมให้จดจำการกระทำของมนุษย์ 600 รายการจากชุดข้อมูล Kinetics-600 คุณยังสามารถใช้การเรียนรู้แบบถ่ายโอนเพื่อฝึกแบบจำลองอีกครั้งเพื่อจดจำการกระทำของมนุษย์ที่ไม่ได้อยู่ในชุดดั้งเดิม ในการดำเนินการนี้ คุณต้องมีชุดวิดีโอการฝึกอบรมสำหรับการดำเนินการใหม่แต่ละรายการที่คุณต้องการรวมไว้ในโมเดล
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการปรับแต่งโมเดลอย่างละเอียดเกี่ยวกับข้อมูลที่กำหนดเอง โปรดดูที่ MoViNets repo และ บทช่วยสอน MoViNets
อ่านเพิ่มเติมและแหล่งข้อมูล
ใช้แหล่งข้อมูลต่อไปนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับแนวคิดที่กล่าวถึงในหน้านี้: