

Video sınıflandırma, bir videonun neyi temsil ettiğini belirlemeye yönelik makine öğrenimi görevidir. Bir video sınıflandırma modeli, farklı eylemler veya hareketler gibi bir dizi benzersiz sınıf içeren bir video veri kümesi üzerinde eğitilir. Model, video karelerini girdi olarak alır ve her sınıfın videoda temsil edilme olasılığını çıkarır.
Video sınıflandırma ve görüntü sınıflandırma modellerinin her ikisi de görüntüleri, önceden tanımlanmış sınıflara ait olan görüntülerin olasılıklarını tahmin etmek için girdi olarak kullanır. Bununla birlikte, bir video sınıflandırma modeli aynı zamanda bir videodaki eylemleri tanımak için bitişik kareler arasındaki uzaysal-zamansal ilişkileri de işler.
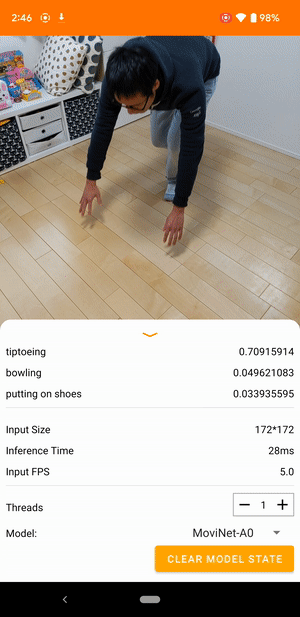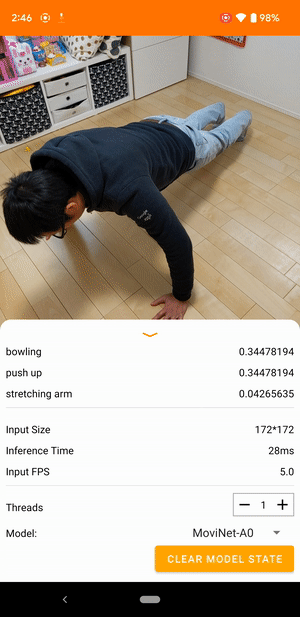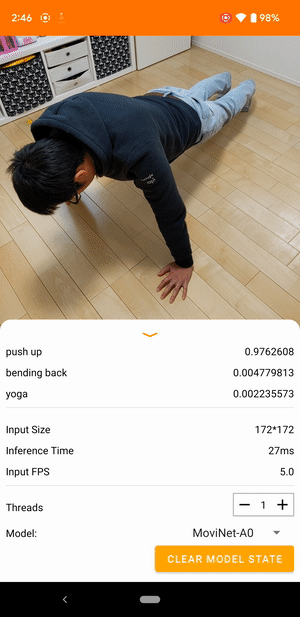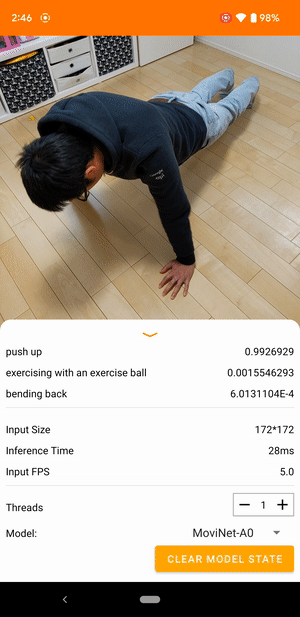
Örneğin, bir video eylemi tanıma modeli koşma, alkışlama ve el sallama gibi insan eylemlerini tanımlayacak şekilde eğitilebilir. Aşağıdaki resim Android'deki bir video sınıflandırma modelinin çıktısını göstermektedir.
Başlamak
Android veya Raspberry Pi dışında bir platform kullanıyorsanız veya TensorFlow Lite API'lerine zaten aşina iseniz başlangıç video sınıflandırma modelini ve destekleyici dosyaları indirin. TensorFlow Lite Destek Kitaplığını kullanarak kendi özel çıkarım işlem hattınızı da oluşturabilirsiniz.
Meta veriler içeren başlangıç modelini indirin
TensorFlow Lite'ta yeniyseniz ve Android veya Raspberry Pi ile çalışıyorsanız başlamanıza yardımcı olacak aşağıdaki örnek uygulamaları inceleyin.
Android
Android uygulaması, sürekli video sınıflandırması için cihazın arka kamerasını kullanır. Çıkarım , TensorFlow Lite Java API'si kullanılarak gerçekleştirilir. Demo uygulaması, çerçeveleri sınıflandırır ve tahmin edilen sınıflandırmaları gerçek zamanlı olarak görüntüler.
Ahududu Pi
Raspberry Pi örneği, sürekli video sınıflandırması gerçekleştirmek için Python ile TensorFlow Lite'ı kullanıyor. Gerçek zamanlı video sınıflandırması gerçekleştirmek için Raspberry Pi'yi Pi Kamera gibi bir kameraya bağlayın. Kameradan sonuçları görüntülemek için Raspberry Pi'ye bir monitör bağlayın ve Pi kabuğuna erişmek için SSH'yi kullanın (Pi'ye klavye bağlamayı önlemek için).
Başlamadan önce Raspberry Pi'nizi Raspberry Pi OS (tercihen Buster'a güncellenmiş) ile kurun .
Model Açıklaması
Mobil Video Ağları ( MoViNet'ler ), mobil cihazlar için optimize edilmiş etkili video sınıflandırma modelleri ailesidir. MoViNet'ler, çeşitli büyük ölçekli video eylemi tanıma veri kümelerinde son teknoloji ürünü doğruluk ve verimlilik sergileyerek, onları video eylemi tanıma görevleri için çok uygun hale getirir.
TensorFlow Lite için MoviNet modelinin üç çeşidi vardır: MoviNet-A0 , MoviNet-A1 ve MoviNet-A2 . Bu değişkenler, 600 farklı insan eylemini tanımak için Kinetics-600 veri kümesiyle eğitildi. MoviNet-A0 en küçük, en hızlı ve en az doğru olanıdır. MoviNet-A2 en büyük, en yavaş ve en doğru olanıdır. MoviNet-A1, A0 ve A2 arasında bir uzlaşmadır.
Nasıl çalışır
Eğitim sırasında, videolar ve bunlarla ilgili etiketler için bir video sınıflandırma modeli sağlanır. Her etiket, modelin tanımayı öğreneceği ayrı bir kavramın veya sınıfın adıdır. Video eylemi tanıma için videolar insan eylemlerinden oluşacak ve etiketler ilgili eylem olacaktır.
Video sınıflandırma modeli, yeni videoların eğitim sırasında verilen sınıflardan herhangi birine ait olup olmadığını tahmin etmeyi öğrenebilir. Bu sürece çıkarım denir. Önceden var olan bir modeli kullanarak yeni video sınıflarını tanımlamak için transfer öğrenimini de kullanabilirsiniz.
Model, sürekli video alan ve gerçek zamanlı yanıt veren bir akış modelidir. Model bir video akışı aldığında, eğitim veri kümesindeki sınıflardan herhangi birinin videoda temsil edilip edilmediğini tanımlar. Her kare için model, videonun sınıfı temsil etme olasılığıyla birlikte bu sınıfları döndürür. Belirli bir zamandaki örnek çıktı aşağıdaki gibi görünebilir:
| Aksiyon | Olasılık |
|---|---|
| meydan dansı | 0,02 |
| iplik geçirme iğnesi | 0,08 |
| titreyen parmaklar | 0.23 |
| El sallayarak | 0,67 |
Çıktıdaki her eylem, eğitim verilerindeki bir etikete karşılık gelir. Olasılık, eylemin videoda görüntülenme olasılığını belirtir.
Model girişleri
Model, giriş olarak bir RGB video karesi akışını kabul eder. Giriş videosunun boyutu esnektir ancak ideal olarak model eğitim çözünürlüğü ve kare hızıyla eşleşir:
- MoviNet-A0 : 5 fps'de 172 x 172
- MoviNet-A1 : 5 fps'de 172 x 172
- MoviNet-A1 : 5 fps'de 224 x 224
Giriş videolarının, ortak görüntü giriş kurallarına uygun olarak 0 ile 1 aralığında renk değerlerine sahip olması beklenir.
Model ayrıca dahili olarak önceki çerçevelerden toplanan bilgileri kullanarak her çerçevenin bağlamını da analiz eder. Bu, model çıktısından dahili durumların alınması ve gelecek çerçeveler için modele geri beslenmesi yoluyla gerçekleştirilir.
Model çıktıları
Model bir dizi etiketi ve bunlara karşılık gelen puanları döndürür. Puanlar, her sınıf için tahmini temsil eden logit değerlerdir. Bu puanlar softmax işlevi ( tf.nn.softmax ) kullanılarak olasılıklara dönüştürülebilir.
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Dahili olarak, model çıktısı aynı zamanda modeldeki dahili durumları da içerir ve bunu gelecek kareler için modele geri besler.
Performans kıyaslamaları
Performans kıyaslama numaraları, kıyaslama aracıyla oluşturulur. MoviNet'ler yalnızca CPU'yu destekler.
Model performansı, bir modelin belirli bir donanım parçası üzerinde çıkarım yapması için geçen süre ile ölçülür. Daha düşük bir süre daha hızlı bir model anlamına gelir. Doğruluk, modelin bir videodaki bir sınıfı ne sıklıkla doğru şekilde sınıflandırdığıyla ölçülür.
| Model adı | Boyut | Kesinlik * | Cihaz | İŞLEMCİ ** |
|---|---|---|---|---|
| MoviNet-A0 (Tamsayı nicemlenmiş) | 3,1 MB | %65 | Piksel 4 | 5 ms |
| Piksel 3 | 11 ms | |||
| MoviNet-A1 (Tamsayı nicemlenmiş) | 4,5 MB | %70 | Piksel 4 | 8 ms |
| Piksel 3 | 19 ms | |||
| MoviNet-A2 (Tamsayı nicemlenmiş) | 5,1 MB | %72 | Piksel 4 | 15 ms |
| Piksel 3 | 36 ms |
* Kinetics-600 veri setinde ölçülen en iyi 1 doğruluk.
** Gecikme, 1 iş parçacıklı CPU üzerinde çalışırken ölçülmüştür.
Modeli özelleştirme
Önceden eğitilmiş modeller , Kinetics-600 veri kümesinden 600 insan eylemini tanıyacak şekilde eğitilmiştir. Orijinal sette olmayan insan eylemlerini tanıyacak şekilde bir modeli yeniden eğitmek için transfer öğrenmeyi de kullanabilirsiniz. Bunu yapmak için modele dahil etmek istediğiniz yeni eylemlerin her biri için bir dizi eğitim videosuna ihtiyacınız var.
Özel verilere ilişkin modellerin ince ayarı hakkında daha fazla bilgi için MoViNets deposuna ve MoViNets eğitimine bakın.
Daha fazla okuma ve kaynaklar
Bu sayfada tartışılan kavramlar hakkında daha fazla bilgi edinmek için aşağıdaki kaynakları kullanın: