

La classificazione dei video è l'attività di machine learning che consiste nell'identificare ciò che rappresenta un video. Un modello di classificazione video viene addestrato su un set di dati video che contiene una serie di classi univoche, come azioni o movimenti diversi. Il modello riceve fotogrammi video come input e restituisce la probabilità che ciascuna classe venga rappresentata nel video.
Entrambi i modelli di classificazione video e di classificazione delle immagini utilizzano le immagini come input per prevedere le probabilità che tali immagini appartengano a classi predefinite. Tuttavia, un modello di classificazione video elabora anche le relazioni spazio-temporali tra fotogrammi adiacenti per riconoscere le azioni in un video.
Ad esempio, un modello di riconoscimento delle azioni video può essere addestrato per identificare azioni umane come correre, battere le mani e agitare. L'immagine seguente mostra l'output di un modello di classificazione video su Android.
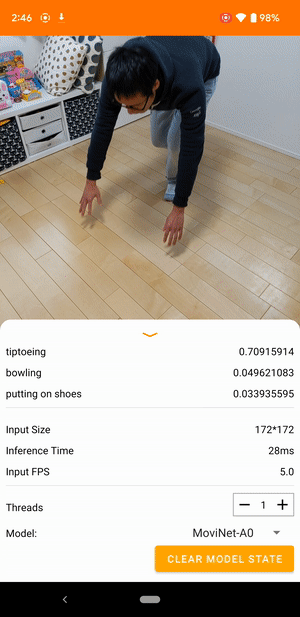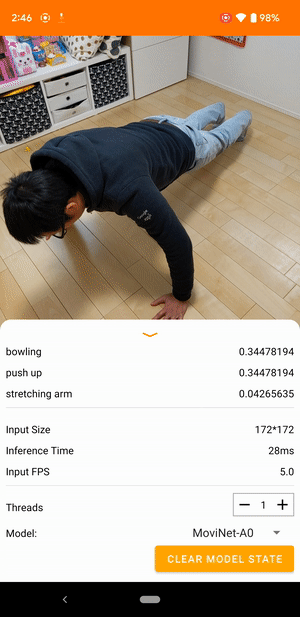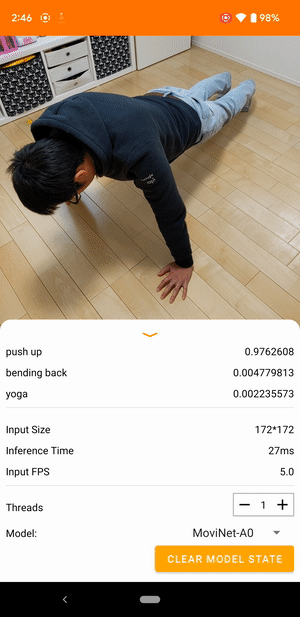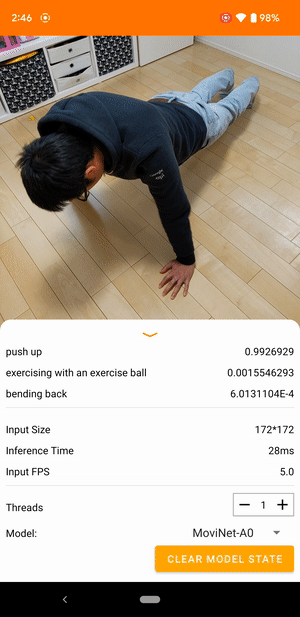
Iniziare
Se utilizzi una piattaforma diversa da Android o Raspberry Pi o se hai già familiarità con le API TensorFlow Lite , scarica il modello di classificazione video iniziale e i file di supporto. Puoi anche creare la tua pipeline di inferenza personalizzata utilizzando la libreria di supporto TensorFlow Lite .
Scarica il modello iniziale con metadati
Se non conosci TensorFlow Lite e lavori con Android o Raspberry Pi, esplora le seguenti applicazioni di esempio per aiutarti a iniziare.
Androide
L'applicazione Android utilizza la fotocamera posteriore del dispositivo per la classificazione video continua. L'inferenza viene eseguita utilizzando l' API Java TensorFlow Lite . L'app demo classifica i frame e visualizza le classificazioni previste in tempo reale.
Lampone Pi
L'esempio Raspberry Pi utilizza TensorFlow Lite con Python per eseguire la classificazione video continua. Collega il Raspberry Pi a una fotocamera, come Pi Camera, per eseguire la classificazione video in tempo reale. Per visualizzare i risultati dalla fotocamera, collega un monitor al Raspberry Pi e utilizza SSH per accedere alla shell Pi (per evitare di collegare una tastiera al Pi).
Prima di iniziare, configura il tuo Raspberry Pi con il sistema operativo Raspberry Pi (preferibilmente aggiornato a Buster).
Descrizione del Modello
Le reti video mobili ( MoViNets ) sono una famiglia di modelli di classificazione video efficienti ottimizzati per dispositivi mobili. I MoViNet dimostrano precisione ed efficienza all'avanguardia su diversi set di dati di riconoscimento di azioni video su larga scala, rendendoli particolarmente adatti per attività di riconoscimento di azioni video .
Esistono tre varianti del modello MoviNet per TensorFlow Lite: MoviNet-A0 , MoviNet-A1 e MoviNet-A2 . Queste varianti sono state addestrate con il set di dati Kinetics-600 per riconoscere 600 diverse azioni umane. MoviNet-A0 è il più piccolo, il più veloce e il meno preciso. MoviNet-A2 è il più grande, il più lento e il più preciso. MoviNet-A1 è un compromesso tra A0 e A2.
Come funziona
Durante la formazione viene fornito un modello di classificazione video dei video e delle relative etichette associate. Ogni etichetta è il nome di un concetto, o classe, distinto che il modello imparerà a riconoscere. Per il riconoscimento delle azioni video , i video riguarderanno azioni umane e le etichette saranno l'azione associata.
Il modello di classificazione video può imparare a prevedere se i nuovi video appartengono a una delle classi fornite durante la formazione. Questo processo è chiamato inferenza . Puoi anche utilizzare l'apprendimento tramite trasferimento per identificare nuove classi di video utilizzando un modello preesistente.
Il modello è un modello di streaming che riceve video continuo e risponde in tempo reale. Quando il modello riceve un flusso video, identifica se una qualsiasi delle classi del set di dati di training è rappresentata nel video. Per ogni fotogramma, il modello restituisce queste classi, insieme alla probabilità che il video rappresenti la classe. Un esempio di output in un dato momento potrebbe apparire come segue:
| Azione | Probabilità |
|---|---|
| ballo di piazza | 0,02 |
| ago da infilatura | 0,08 |
| giocherellare con le dita | 0,23 |
| Agitando la mano | 0,67 |
Ogni azione nell'output corrisponde a un'etichetta nei dati di addestramento. La probabilità indica la probabilità che l'azione venga visualizzata nel video.
Ingressi del modello
Il modello accetta come input un flusso di fotogrammi video RGB. La dimensione del video in input è flessibile, ma idealmente corrisponde alla risoluzione di addestramento del modello e al frame rate:
- MoviNet-A0 : 172 x 172 a 5 fps
- MoviNet-A1 : 172 x 172 a 5 fps
- MoviNet-A1 : 224 x 224 a 5 fps
Si prevede che i video in input abbiano valori di colore compresi nell'intervallo tra 0 e 1, seguendo le comuni convenzioni di input delle immagini .
Internamente, il modello analizza anche il contesto di ciascun frame utilizzando le informazioni raccolte nei frame precedenti. Ciò si ottiene prendendo gli stati interni dall'output del modello e reimmettendoli nel modello per i fotogrammi successivi.
Risultati del modello
Il modello restituisce una serie di etichette e i punteggi corrispondenti. I punteggi sono valori logit che rappresentano la previsione per ciascuna classe. Questi punteggi possono essere convertiti in probabilità utilizzando la funzione softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Internamente, l'output del modello include anche gli stati interni del modello e li reinserisce nel modello per i fotogrammi successivi.
Benchmark delle prestazioni
I numeri dei benchmark delle prestazioni vengono generati con lo strumento di benchmarking . I MoviNet supportano solo la CPU.
Le prestazioni del modello vengono misurate in base alla quantità di tempo necessaria affinché un modello esegua l'inferenza su un determinato componente hardware. Un tempo inferiore implica un modello più veloce. La precisione viene misurata in base alla frequenza con cui il modello classifica correttamente una classe in un video.
| Nome del modello | Misurare | Precisione * | Dispositivo | PROCESSORE ** |
|---|---|---|---|---|
| MoviNet-A0 (intero quantizzato) | 3,1MB | 65% | Pixel 4 | 5 ms |
| Pixel 3 | 11 ms | |||
| MoviNet-A1 (intero quantizzato) | 4,5MB | 70% | Pixel 4 | 8 ms |
| Pixel 3 | 19 ms | |||
| MoviNet-A2 (numero intero quantizzato) | 5,1MB | 72% | Pixel 4 | 15 ms |
| Pixel 3 | 36 ms |
* Precisione di prim'ordine misurata sul set di dati Kinetics-600 .
** Latenza misurata durante l'esecuzione su CPU con 1 thread.
Personalizzazione del modello
I modelli preaddestrati sono addestrati per riconoscere 600 azioni umane dal set di dati Kinetics-600 . È inoltre possibile utilizzare l'apprendimento tramite trasferimento per riqualificare un modello in modo che riconosca le azioni umane che non sono presenti nel set originale. Per fare ciò, hai bisogno di una serie di video di formazione per ciascuna delle nuove azioni che desideri incorporare nel modello.
Per ulteriori informazioni sulla messa a punto dei modelli sui dati personalizzati, vedere il repository MoViNets e il tutorial MoViNets .
Ulteriori letture e risorse
Utilizza le seguenti risorse per ulteriori informazioni sui concetti discussi in questa pagina: