

Klasifikasi video adalah tugas pembelajaran mesin untuk mengidentifikasi apa yang diwakili oleh video. Model klasifikasi video dilatih pada kumpulan data video yang berisi sekumpulan kelas unik, seperti tindakan atau gerakan yang berbeda. Model menerima frame video sebagai input dan output probabilitas setiap kelas terwakili dalam video.
Model klasifikasi video dan klasifikasi gambar menggunakan gambar sebagai masukan untuk memprediksi probabilitas gambar tersebut termasuk dalam kelas yang telah ditentukan. Namun, model klasifikasi video juga memproses hubungan spatio-temporal antara frame yang berdekatan untuk mengenali tindakan dalam video.
Misalnya, model pengenalan tindakan video dapat dilatih untuk mengidentifikasi tindakan manusia seperti berlari, bertepuk tangan, dan melambai. Gambar berikut menunjukkan keluaran model klasifikasi video di Android.
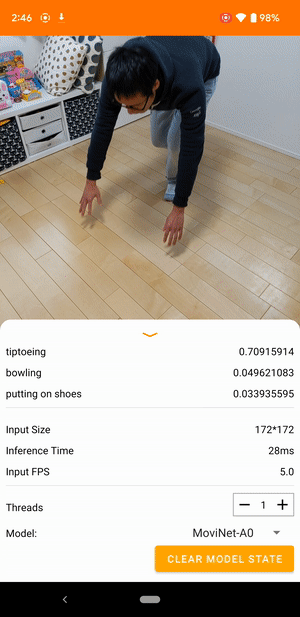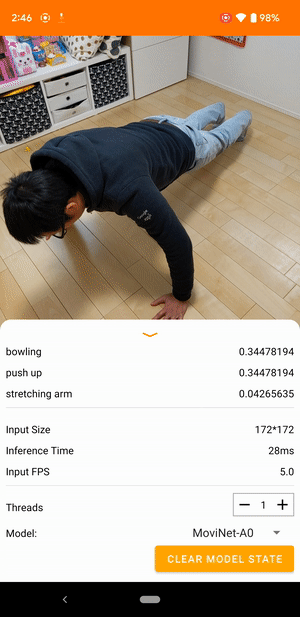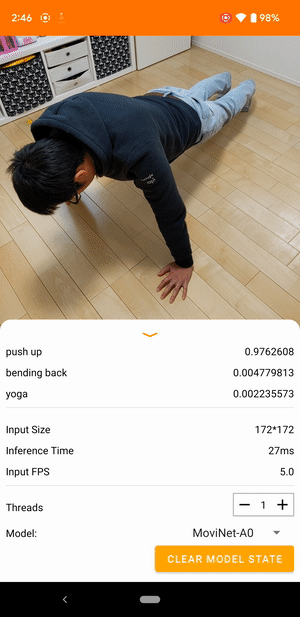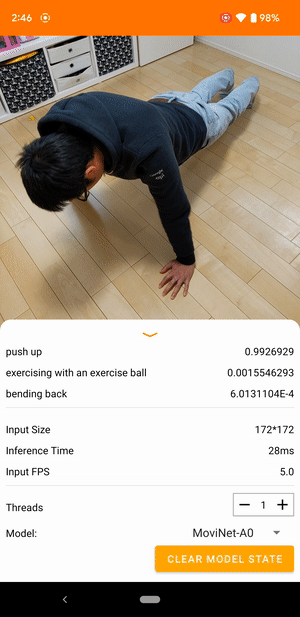
Memulai
Jika Anda menggunakan platform selain Android atau Raspberry Pi, atau jika Anda sudah familiar dengan TensorFlow Lite API , download model klasifikasi video pemula dan file pendukungnya. Anda juga dapat membuat pipeline inferensi kustom Anda sendiri menggunakan Support Library TensorFlow Lite .
Unduh model pemula dengan metadata
Jika Anda baru menggunakan TensorFlow Lite dan menggunakan Android atau Raspberry Pi, jelajahi contoh aplikasi berikut untuk membantu Anda memulai.
Android
Aplikasi Android menggunakan kamera belakang perangkat untuk klasifikasi video berkelanjutan. Inferensi dilakukan menggunakan TensorFlow Lite Java API . Aplikasi demo mengklasifikasikan bingkai dan menampilkan prediksi klasifikasi secara real time.
Raspberry Pi
Contoh Raspberry Pi menggunakan TensorFlow Lite dengan Python untuk melakukan klasifikasi video berkelanjutan. Hubungkan Raspberry Pi ke kamera, seperti Pi Camera, untuk melakukan klasifikasi video waktu nyata. Untuk melihat hasil dari kamera, sambungkan monitor ke Raspberry Pi dan gunakan SSH untuk mengakses shell Pi (untuk menghindari menghubungkan keyboard ke Pi).
Sebelum memulai, atur Raspberry Pi Anda dengan Raspberry Pi OS (sebaiknya diperbarui ke Buster).
Deskripsi model
Jaringan Video Seluler ( MoViNets ) adalah rangkaian model klasifikasi video efisien yang dioptimalkan untuk perangkat seluler. MoViNets menunjukkan akurasi dan efisiensi tercanggih pada beberapa kumpulan data pengenalan tindakan video berskala besar, menjadikannya sangat cocok untuk tugas pengenalan tindakan video .
Ada tiga varian model MoviNet untuk TensorFlow Lite: MoviNet-A0 , MoviNet-A1 , dan MoviNet-A2 . Varian ini dilatih dengan kumpulan data Kinetics-600 untuk mengenali 600 tindakan manusia yang berbeda. MoviNet-A0 adalah yang terkecil, tercepat, dan paling tidak akurat. MoviNet-A2 adalah yang terbesar, paling lambat, dan paling akurat. MoviNet-A1 adalah kompromi antara A0 dan A2.
Bagaimana itu bekerja
Selama pelatihan, model klasifikasi video diberikan video dan label terkaitnya. Setiap label adalah nama konsep, atau kelas berbeda, yang akan dipelajari oleh model untuk dikenali. Untuk pengenalan tindakan video , video tersebut akan berisi tindakan manusia dan labelnya akan menjadi tindakan terkait.
Model klasifikasi video dapat belajar memprediksi apakah video baru termasuk dalam kelas mana pun yang disediakan selama pelatihan. Proses ini disebut inferensi . Anda juga dapat menggunakan pembelajaran transfer untuk mengidentifikasi kelas video baru dengan menggunakan model yang sudah ada sebelumnya.
Modelnya adalah model streaming yang menerima video terus menerus dan merespons secara real time. Saat model menerima aliran video, model tersebut mengidentifikasi apakah ada kelas dari kumpulan data pelatihan yang terwakili dalam video. Untuk setiap frame, model mengembalikan kelas-kelas ini, bersama dengan probabilitas bahwa video mewakili kelas tersebut. Contoh keluaran pada waktu tertentu mungkin terlihat sebagai berikut:
| Tindakan | Kemungkinan |
|---|---|
| menari persegi | 0,02 |
| jarum penusuk | 0,08 |
| memutar-mutar jari | 0,23 |
| Melambaikan tangan | 0,67 |
Setiap tindakan di keluaran berhubungan dengan label di data pelatihan. Probabilitas menunjukkan kemungkinan bahwa tindakan tersebut ditampilkan dalam video.
Masukan model
Model menerima aliran bingkai video RGB sebagai masukan. Ukuran video input fleksibel, namun idealnya cocok dengan resolusi pelatihan model dan kecepatan frame:
- MoviNet-A0 : 172 x 172 pada 5 fps
- MoviNet-A1 : 172 x 172 pada 5 fps
- MoviNet-A1 : 224 x 224 pada 5 fps
Video masukan diharapkan memiliki nilai warna dalam rentang 0 dan 1, mengikuti konvensi masukan gambar yang umum.
Secara internal, model juga menganalisis konteks setiap frame dengan menggunakan informasi yang dikumpulkan di frame sebelumnya. Hal ini dicapai dengan mengambil status internal dari keluaran model dan memasukkannya kembali ke dalam model untuk frame berikutnya.
Keluaran model
Model ini mengembalikan serangkaian label dan skornya yang sesuai. Skor tersebut merupakan nilai logit yang mewakili prediksi setiap kelas. Skor ini dapat dikonversi menjadi probabilitas dengan menggunakan fungsi softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Secara internal, keluaran model juga mencakup status internal dari model dan memasukkannya kembali ke dalam model untuk frame berikutnya.
Tolok ukur kinerja
Angka tolok ukur kinerja dihasilkan dengan alat tolok ukur . MoviNets hanya mendukung CPU.
Performa model diukur dengan jumlah waktu yang diperlukan model untuk menjalankan inferensi pada perangkat keras tertentu. Waktu yang lebih rendah berarti model yang lebih cepat. Akurasi diukur dengan seberapa sering model mengklasifikasikan kelas dalam video dengan benar.
| Nama model | Ukuran | Akurasi * | Perangkat | CPU** |
|---|---|---|---|---|
| MoviNet-A0 (Bilangan bulat terkuantisasi) | 3,1 MB | 65% | Piksel 4 | 5 ms |
| Piksel 3 | 11 ms | |||
| MoviNet-A1 (Bilangan bulat terkuantisasi) | 4,5 MB | 70% | Piksel 4 | 8 ms |
| Piksel 3 | 19 ms | |||
| MoviNet-A2 (Bilangan bulat terkuantisasi) | 5,1 MB | 72% | Piksel 4 | 15 ms |
| Piksel 3 | 36 mdtk |
* Akurasi peringkat 1 teratas diukur pada kumpulan data Kinetics-600 .
** Latensi diukur saat dijalankan pada CPU dengan 1-thread.
Kustomisasi model
Model yang telah dilatih sebelumnya dilatih untuk mengenali 600 tindakan manusia dari kumpulan data Kinetics-600 . Anda juga dapat menggunakan pembelajaran transfer untuk melatih ulang model agar dapat mengenali tindakan manusia yang tidak ada dalam rangkaian aslinya. Untuk melakukan hal ini, Anda memerlukan serangkaian video pelatihan untuk setiap tindakan baru yang ingin Anda masukkan ke dalam model.
Untuk informasi selengkapnya tentang menyempurnakan model pada data khusus, lihat repo MoViNets dan tutorial MoViNets .
Bacaan dan sumber lebih lanjut
Gunakan sumber daya berikut untuk mempelajari lebih lanjut tentang konsep yang dibahas di halaman ini: