

Video classification is the machine learning task of identifying what a video represents. A video classification model is trained on a video dataset that contains a set of unique classes, such as different actions or movements. The model receives video frames as input and outputs the probability of each class being represented in the video.
Video classification and image classification models both use images as inputs to predict the probabilities of those images belonging to predefined classes. However, a video classification model also processes the spatio-temporal relationships between adjacent frames to recognize the actions in a video.
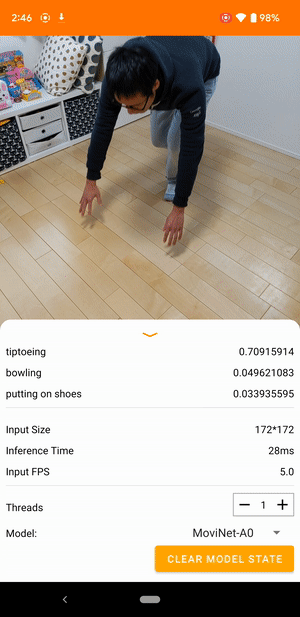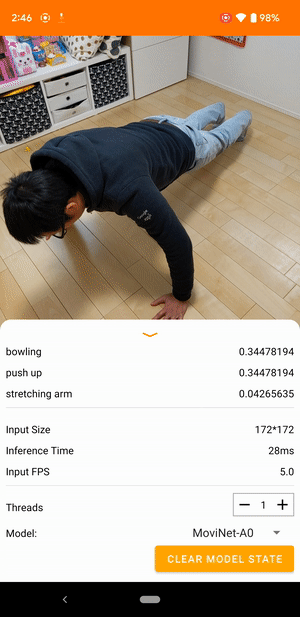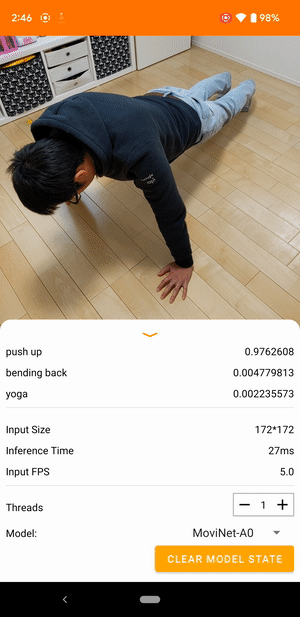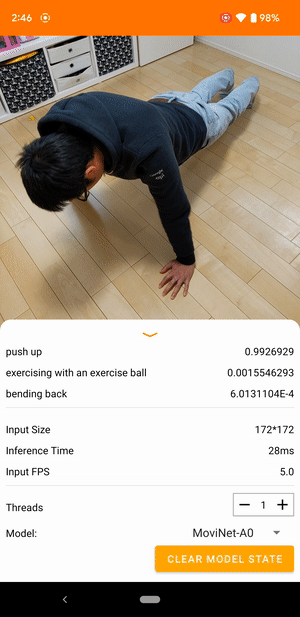
For example, a video action recognition model can be trained to identify human actions like running, clapping, and waving. The following image shows the output of a video classification model on Android.
Get started
If you are using a platform other than Android or Raspberry Pi, or if you are already familiar with the TensorFlow Lite APIs, download the starter video classification model and the supporting files. You can also build your own custom inference pipeline using the TensorFlow Lite Support Library.
Download starter model with metadata
If you are new to TensorFlow Lite and are working with Android or Raspberry Pi, explore the following example applications to help you get started.
Android
The Android application uses the device's back camera for continuous video classification. Inference is performed using the TensorFlow Lite Java API. The demo app classifies frames and displays the predicted classifications in real time.
Raspberry Pi
The Raspberry Pi example uses TensorFlow Lite with Python to perform continuous video classification. Connect the Raspberry Pi to a camera, like Pi Camera, to perform real-time video classification. To view results from the camera, connect a monitor to the Raspberry Pi and use SSH to access the Pi shell (to avoid connecting a keyboard to the Pi).
Before starting, set up your Raspberry Pi with Raspberry Pi OS (preferably updated to Buster).
Model description
Mobile Video Networks (MoViNets) are a family of efficient video classification models optimized for mobile devices. MoViNets demonstrate state-of-the-art accuracy and efficiency on several large-scale video action recognition datasets, making them well-suited for video action recognition tasks.
There are three variants of the MoviNet model for TensorFlow Lite: MoviNet-A0, MoviNet-A1, and MoviNet-A2. These variants were trained with the Kinetics-600 dataset to recognize 600 different human actions. MoviNet-A0 is the smallest, fastest, and least accurate. MoviNet-A2 is the largest, slowest, and most accurate. MoviNet-A1 is a compromise between A0 and A2.
How it works
During training, a video classification model is provided videos and their associated labels. Each label is the name of a distinct concept, or class, that the model will learn to recognize. For video action recognition, the videos will be of human actions and the labels will be the associated action.
The video classification model can learn to predict whether new videos belong to any of the classes provided during training. This process is called inference. You can also use transfer learning to identify new classes of videos by using a pre-existing model.
The model is a streaming model that receives continuous video and responds in real time. As the model receives a video stream, it identifies whether any of the classes from the training dataset are represented in the video. For each frame, the model returns these classes, along with the probability that the video represents the class. An example output at a given time might look as follows:
| Action | Probability |
|---|---|
| square dancing | 0.02 |
| threading needle | 0.08 |
| twiddling fingers | 0.23 |
| Waving hand | 0.67 |
Each action in the output corresponds to a label in the training data. The probability denotes the likelihood that the action is being displayed in the video.
Model inputs
The model accepts a stream of RGB video frames as input. The size of the input video is flexible, but ideally it matches the model training resolution and frame-rate:
- MoviNet-A0: 172 x 172 at 5 fps
- MoviNet-A1: 172 x 172 at 5 fps
- MoviNet-A1: 224 x 224 at 5 fps
The input videos are expected to have color values within the range of 0 and 1, following the common image input conventions.
Internally, the model also analyzes the context of each frame by using information gathered in previous frames. This is accomplished by taking internal states from the model output and feeding it back into the model for upcoming frames.
Model outputs
The model returns a series of labels and their corresponding scores. The scores
are logit values that represent the prediction for each class. These scores can
be converted to probabilities by using the softmax function (tf.nn.softmax).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Internally, the model output also includes internal states from the model and feeds it back into the model for upcoming frames.
Performance benchmarks
Performance benchmark numbers are generated with the benchmarking tool. MoviNets only support CPU.
Model performance is measured by the amount of time it takes for a model to run inference on a given piece of hardware. A lower time implies a faster model. Accuracy is measured by how often the model correctly classifies a class in a video.
| Model Name | Size | Accuracy * | Device | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (Integer quantized) | 3.1 MB | 65% | Pixel 4 | 5 ms |
| Pixel 3 | 11 ms | |||
| MoviNet-A1 (Integer quantized) | 4.5 MB | 70% | Pixel 4 | 8 ms |
| Pixel 3 | 19 ms | |||
| MoviNet-A2 (Integer quantized) | 5.1 MB | 72% | Pixel 4 | 15 ms |
| Pixel 3 | 36 ms |
* Top-1 accuracy measured on the Kinetics-600 dataset.
** Latency measured when running on CPU with 1-thread.
Model customization
The pre-trained models are trained to recognize 600 human actions from the Kinetics-600 dataset. You can also use transfer learning to re-train a model to recognize human actions that are not in the original set. To do this, you need a set of training videos for each of the new actions you want to incorporate into the model.
For more on fine-tuning models on custom data, see the MoViNets repo and MoViNets tutorial.
Further reading and resources
Use the following resources to learn more about concepts discussed on this page: