

A classificação de vídeo é a tarefa de aprendizado de máquina para identificar o que um vídeo representa. Um modelo de classificação de vídeo é treinado em um conjunto de dados de vídeo que contém um conjunto de classes exclusivas, como diferentes ações ou movimentos. O modelo recebe quadros de vídeo como entrada e gera a probabilidade de cada classe ser representada no vídeo.
Os modelos de classificação de vídeo e de classificação de imagens usam imagens como entradas para prever as probabilidades dessas imagens pertencerem a classes predefinidas. Contudo, um modelo de classificação de vídeo também processa as relações espaço-temporais entre quadros adjacentes para reconhecer as ações em um vídeo.
Por exemplo, um modelo de reconhecimento de ação de vídeo pode ser treinado para identificar ações humanas como correr, bater palmas e acenar. A imagem a seguir mostra a saída de um modelo de classificação de vídeo no Android.
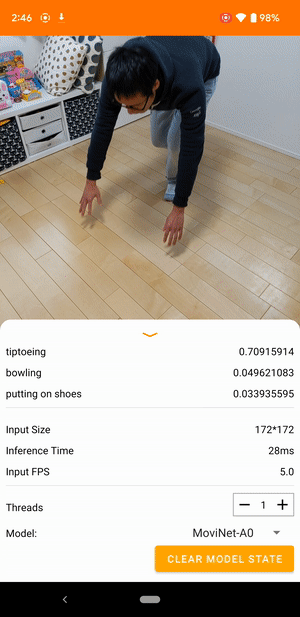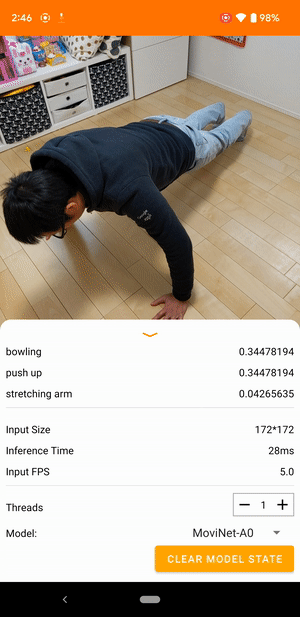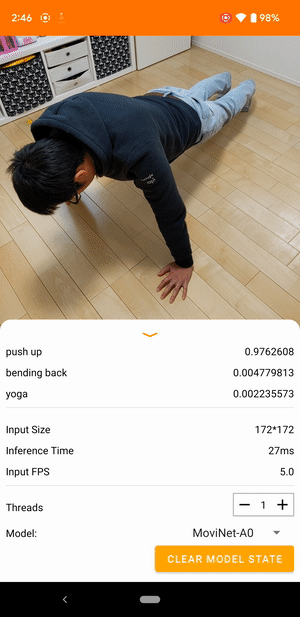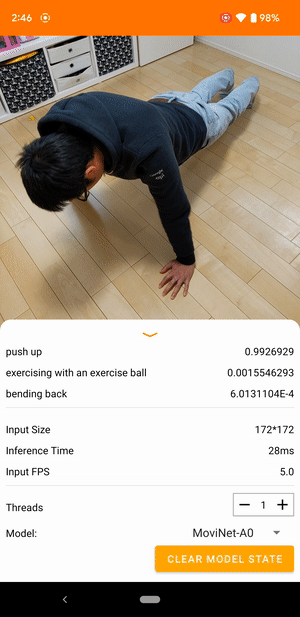
iniciar
Se você estiver usando uma plataforma diferente do Android ou Raspberry Pi, ou se já estiver familiarizado com as APIs do TensorFlow Lite , baixe o modelo inicial de classificação de vídeo e os arquivos de suporte. Você também pode criar seu próprio pipeline de inferência personalizado usando a Biblioteca de suporte do TensorFlow Lite .
Baixe o modelo inicial com metadados
Se você é novo no TensorFlow Lite e está trabalhando com Android ou Raspberry Pi, explore os exemplos de aplicativos a seguir para ajudá-lo a começar.
Android
O aplicativo Android usa a câmera traseira do dispositivo para classificação contínua de vídeo. A inferência é realizada usando a API Java do TensorFlow Lite . O aplicativo de demonstração classifica os quadros e exibe as classificações previstas em tempo real.
Raspberry Pi
O exemplo do Raspberry Pi usa TensorFlow Lite com Python para realizar classificação contínua de vídeo. Conecte o Raspberry Pi a uma câmera, como a Pi Camera, para realizar a classificação de vídeo em tempo real. Para visualizar os resultados da câmera, conecte um monitor ao Raspberry Pi e use SSH para acessar o shell do Pi (para evitar conectar um teclado ao Pi).
Antes de começar, configure seu Raspberry Pi com Raspberry Pi OS (de preferência atualizado para Buster).
Descrição do modelo
Redes Móveis de Vídeo ( MoViNets ) são uma família de modelos eficientes de classificação de vídeo otimizados para dispositivos móveis. Os MoViNets demonstram precisão e eficiência de última geração em vários conjuntos de dados de reconhecimento de ação de vídeo em grande escala, tornando-os adequados para tarefas de reconhecimento de ação de vídeo .
Existem três variantes do modelo MoviNet para TensorFlow Lite: MoviNet-A0 , MoviNet-A1 e MoviNet-A2 . Essas variantes foram treinadas com o conjunto de dados Kinetics-600 para reconhecer 600 ações humanas diferentes. MoviNet-A0 é o menor, mais rápido e menos preciso. MoviNet-A2 é o maior, mais lento e mais preciso. MoviNet-A1 é um compromisso entre A0 e A2.
Como funciona
Durante o treinamento, é fornecido um modelo de classificação de vídeos e seus rótulos associados. Cada rótulo é o nome de um conceito ou classe distinto que o modelo aprenderá a reconhecer. Para reconhecimento de ações de vídeo , os vídeos serão de ações humanas e os rótulos serão as ações associadas.
O modelo de classificação de vídeos pode aprender a prever se novos vídeos pertencem a alguma das aulas fornecidas durante o treinamento. Este processo é chamado de inferência . Você também pode usar a aprendizagem por transferência para identificar novas classes de vídeos usando um modelo pré-existente.
O modelo é um modelo de streaming que recebe vídeo contínuo e responde em tempo real. À medida que o modelo recebe um stream de vídeo, ele identifica se alguma das classes do conjunto de dados de treinamento está representada no vídeo. Para cada quadro, o modelo retorna essas classes, juntamente com a probabilidade de o vídeo representar a classe. Um exemplo de saída em um determinado momento pode ser o seguinte:
| Ação | Probabilidade |
|---|---|
| dança quadrada | 0,02 |
| agulha de enfiar | 0,08 |
| girando os dedos | 0,23 |
| Acenando com a mão | 0,67 |
Cada ação na saída corresponde a um rótulo nos dados de treinamento. A probabilidade denota a probabilidade de a ação estar sendo exibida no vídeo.
Entradas do modelo
O modelo aceita um fluxo de quadros de vídeo RGB como entrada. O tamanho do vídeo de entrada é flexível, mas idealmente corresponde à resolução de treinamento do modelo e à taxa de quadros:
- MoviNet-A0 : 172 x 172 a 5 fps
- MoviNet-A1 : 172 x 172 a 5 fps
- MoviNet-A1 : 224 x 224 a 5 fps
Espera-se que os vídeos de entrada tenham valores de cores na faixa de 0 e 1, seguindo as convenções comuns de entrada de imagem .
Internamente, o modelo também analisa o contexto de cada frame utilizando informações coletadas em frames anteriores. Isso é feito pegando estados internos da saída do modelo e alimentando-os de volta no modelo para os próximos quadros.
Resultados do modelo
O modelo retorna uma série de rótulos e suas pontuações correspondentes. As pontuações são valores logit que representam a previsão para cada classe. Essas pontuações podem ser convertidas em probabilidades usando a função softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Internamente, a saída do modelo também inclui estados internos do modelo e os realimenta no modelo para os próximos quadros.
Referências de desempenho
Os números de benchmark de desempenho são gerados com a ferramenta de benchmarking . MoviNets suporta apenas CPU.
O desempenho do modelo é medido pela quantidade de tempo que um modelo leva para executar inferência em uma determinada peça de hardware. Um tempo menor implica um modelo mais rápido. A precisão é medida pela frequência com que o modelo classifica corretamente uma aula em um vídeo.
| Nome do modelo | Tamanho | Precisão * | Dispositivo | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (quantização inteira) | 3,1MB | 65% | Pixel 4 | 5ms |
| Pixel 3 | 11ms | |||
| MoviNet-A1 (quantização inteira) | 4,5MB | 70% | Pixel 4 | 8ms |
| Pixel 3 | 19ms | |||
| MoviNet-A2 (quantização inteira) | 5,1MB | 72% | Pixel 4 | 15ms |
| Pixel 3 | 36ms |
*Principal precisão medida no conjunto de dados Kinetics-600 .
** Latência medida ao executar em CPU com 1 thread.
Personalização do modelo
Os modelos pré-treinados são treinados para reconhecer 600 ações humanas do conjunto de dados Kinetics-600 . Você também pode usar a aprendizagem por transferência para treinar novamente um modelo para reconhecer ações humanas que não estão no conjunto original. Para fazer isso, você precisa de um conjunto de vídeos de treinamento para cada uma das novas ações que deseja incorporar ao modelo.
Para obter mais informações sobre como ajustar modelos em dados personalizados, consulte o repositório MoViNets e o tutorial MoViNets .
Leitura adicional e recursos
Use os seguintes recursos para aprender mais sobre os conceitos discutidos nesta página: