
שימוש ביחידות עיבוד גרפיות (GPU) להפעלת מודלים של למידת מכונה (ML) שלך יכול לשפר באופן דרמטי את הביצועים של המודל שלך ואת חווית המשתמש של היישומים התומכים ב-ML שלך. במכשירי iOS, אתה יכול לאפשר שימוש בביצוע מואץ של GPU של הדגמים שלך באמצעות נציג . הנציגים פועלים כמנהלי התקנים של חומרה עבור TensorFlow Lite, ומאפשרים לך להריץ את הקוד של הדגם שלך על מעבדי GPU.
דף זה מתאר כיצד להפעיל האצת GPU עבור דגמי TensorFlow Lite באפליקציות iOS. למידע נוסף על השימוש ב-GPU Delegate עבור TensorFlow Lite, כולל שיטות עבודה מומלצות וטכניקות מתקדמות, עיין בדף נציגי GPU .
השתמש ב-GPU עם Interpreter API
TensorFlow Lite Interpreter API מספק קבוצה של ממשקי API למטרות כלליות לבניית יישומי למידת מכונה. ההוראות הבאות מדריכות אותך בהוספת תמיכת GPU לאפליקציית iOS. מדריך זה מניח שכבר יש לך אפליקציית iOS שיכולה להפעיל בהצלחה מודל ML עם TensorFlow Lite.
שנה את ה-Podfile כך שיכלול תמיכה ב-GPU
החל במהדורת TensorFlow Lite 2.3.0, נציג ה-GPU אינו נכלל מהפוד כדי להקטין את הגודל הבינארי. אתה יכול לכלול אותם על ידי ציון מפרט משנה עבור הפוד של TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
אוֹ
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
אתה יכול גם להשתמש TensorFlowLiteObjC או TensorFlowLiteC אם ברצונך להשתמש ב-Objective-C, שזמין עבור גרסאות 2.4.0 ומעלה, או ב-C API.
אתחול והשתמש ב-GPU Delegate
אתה יכול להשתמש ב-GPU Delegate עם TensorFlow Lite Interpreter API עם מספר שפות תכנות. מומלצים Swift ו-Objective-C, אך ניתן להשתמש גם ב-C++ ו-C. שימוש ב-C נדרש אם אתה משתמש בגרסה של TensorFlow Lite קודמת מ-2.4. דוגמאות הקוד הבאות מתארות כיצד להשתמש בנציג עם כל אחת מהשפות הללו.
מָהִיר
import TensorFlowLite
// Load model ...
// Initialize TensorFlow Lite interpreter with the GPU delegate.
let delegate = MetalDelegate()
if let interpreter = try Interpreter(modelPath: modelPath,
delegates: [delegate]) {
// Run inference ...
}
Objective-C
// Import module when using CocoaPods with module support
@import TFLTensorFlowLite;
// Or import following headers manually
#import "tensorflow/lite/objc/apis/TFLMetalDelegate.h"
#import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h"
// Initialize GPU delegate
TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init];
// Initialize interpreter with model path and GPU delegate
TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init];
NSError* error = nil;
TFLInterpreter* interpreter = [[TFLInterpreter alloc]
initWithModelPath:modelPath
options:options
delegates:@[ metalDelegate ]
error:&error];
if (error != nil) { /* Error handling... */ }
if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ }
if (error != nil) { /* Error handling... */ }
// Run inference ...
C++
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
tflite::ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// Clean up.
TFLGpuDelegateDelete(delegate);
C (לפני 2.4.0)
#include "tensorflow/lite/c/c_api.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
// Initialize model
TfLiteModel* model = TfLiteModelCreateFromFile(model_path);
// Initialize interpreter with GPU delegate
TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate();
TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config
TfLiteInterpreterOptionsAddDelegate(options, metal_delegate);
TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options);
TfLiteInterpreterOptionsDelete(options);
TfLiteInterpreterAllocateTensors(interpreter);
NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)];
NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)];
TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0);
const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0);
// Run inference
TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length);
TfLiteInterpreterInvoke(interpreter);
TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length);
// Clean up
TfLiteInterpreterDelete(interpreter);
TFLGpuDelegateDelete(metal_delegate);
TfLiteModelDelete(model);
הערות לשימוש בשפת API של GPU
- גרסאות TensorFlow Lite לפני 2.4.0 יכולות להשתמש רק ב-C API עבור Objective-C.
- ה-API של C++ זמין רק כאשר אתה משתמש ב-bazel או בונה את TensorFlow Lite בעצמך. לא ניתן להשתמש ב-C++ API עם CocoaPods.
- בעת שימוש ב-TensorFlow Lite עם נציג ה-GPU עם C++, קבל את נציג ה-GPU דרך הפונקציה
TFLGpuDelegateCreate()ולאחר מכן העביר אותו ל-Interpreter::ModifyGraphWithDelegate(), במקום לקרוא ל-Interpreter::AllocateTensors().
בנה ובדוק עם מצב שחרור
שנה לגרסת גרסה עם הגדרות מאיץ מתכת API המתאימות כדי לקבל ביצועים טובים יותר ולבדיקה סופית. סעיף זה מסביר כיצד להפעיל הגדרה של בנייה והגדרה של גרסה עבור האצת מתכת.
כדי לשנות למבנה מהדורה:
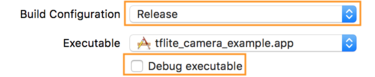
- ערוך את הגדרות הבנייה על ידי בחירה במוצר > תכנית > ערוך תכנית... ולאחר מכן בחירה בהפעלה .
- בכרטיסייה מידע , שנה את תצורת Build ל- Release ובטל את הסימון של Debug executable .
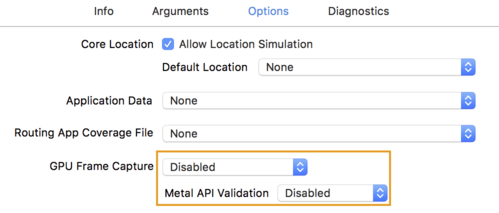
- לחץ על הכרטיסייה אפשרויות ושנה לכידת מסגרות GPU ל- Disabled ו- Metal API Validation ל- Disabled .
- הקפד לבחור ב-Release-Only builds על ארכיטקטורת 64-bit. תחת נווט הפרויקט > tflite_camera_example > PROJECT > your_project_name > הגדרות בנייה הגדר Build Active Architecture בלבד > שחרור ל -כן .

תמיכה מתקדמת ב-GPU
סעיף זה מכסה שימושים מתקדמים ב-GPU Delegate עבור iOS, כולל אפשרויות נציג, מאגרי קלט ופלט ושימוש במודלים כמותיים.
אפשרויות האצלה עבור iOS
הבנאי עבור נציג GPU מקבל struct של אפשרויות ב- Swift API , Objective-C API ו- C API . העברת nullptr (C API) או כלום (Objective-C ו-Swift API) לאתחל מגדיר את אפשרויות ברירת המחדל (אשר מוסברות בדוגמה של שימוש בסיסי למעלה).
מָהִיר
// THIS:
var options = MetalDelegate.Options()
options.isPrecisionLossAllowed = false
options.waitType = .passive
options.isQuantizationEnabled = true
let delegate = MetalDelegate(options: options)
// IS THE SAME AS THIS:
let delegate = MetalDelegate()
Objective-C
// THIS:
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.precisionLossAllowed = false;
options.waitType = TFLMetalDelegateThreadWaitTypePassive;
options.quantizationEnabled = true;
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options];
// IS THE SAME AS THIS:
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
ג
// THIS:
const TFLGpuDelegateOptions options = {
.allow_precision_loss = false,
.wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive,
.enable_quantization = true,
};
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
// IS THE SAME AS THIS:
TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
מאגרי קלט/פלט באמצעות C++ API
חישוב ב-GPU דורש שהנתונים יהיו זמינים ל-GPU. דרישה זו פירושה לעתים קרובות שעליך לבצע העתקת זיכרון. עליך להימנע מכך שהנתונים שלך יחצו את גבול זיכרון ה-CPU/GPU במידת האפשר, מכיוון שהדבר עלול לקחת פרק זמן משמעותי. בדרך כלל, חצייה כזו היא בלתי נמנעת, אך במקרים מיוחדים מסוימים ניתן לוותר על זה או אחר.
אם הקלט של הרשת הוא תמונה שכבר נטענה בזיכרון ה-GPU (לדוגמה, מרקם GPU המכיל את הזנת המצלמה) היא יכולה להישאר בזיכרון ה-GPU מבלי להיכנס לעולם לזיכרון המעבד. באופן דומה, אם הפלט של הרשת הוא בצורה של תמונה הניתנת לעיבוד, כגון פעולת העברת סגנון תמונה , ניתן להציג ישירות את התוצאה על המסך.
כדי להשיג את הביצועים הטובים ביותר, TensorFlow Lite מאפשר למשתמשים לקרוא ולכתוב ישירות ממאגר החומרה של TensorFlow ולעקוף עותקי זיכרון שניתן להימנע מהם.
בהנחה שקלט התמונה נמצא בזיכרון GPU, תחילה עליך להמיר אותו לאובייקט MTLBuffer עבור Metal. אתה יכול לשייך TfLiteTensor ל- MTLBuffer שהוכן על ידי המשתמש עם הפונקציה TFLGpuDelegateBindMetalBufferToTensor() . שימו לב שפונקציה זו חייבת להיקרא לאחר Interpreter::ModifyGraphWithDelegate() . בנוסף, פלט ההסקה מועתק, כברירת מחדל, מזיכרון GPU לזיכרון CPU. אתה יכול לבטל התנהגות זו על ידי קריאה ל- Interpreter::SetAllowBufferHandleOutput(true) במהלך האתחול.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h"
// ...
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->inputs()[0], user_provided_input_buffer)) {
return false;
}
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->outputs()[0], user_provided_output_buffer)) {
return false;
}
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return false;
לאחר כיבוי התנהגות ברירת המחדל, העתקת פלט ההסקה מזיכרון ה-GPU לזיכרון המעבד דורשת קריאה מפורשת ל- Interpreter::EnsureTensorDataIsReadable() עבור כל טנסור פלט. גישה זו עובדת גם עבור מודלים מכוונטיים, אך עדיין עליך להשתמש במאגר בגודל float32 עם נתוני float32 , מכיוון שהמאגר קשור למאגר הפנימי שה-de-quantized.
דגמים כמותיים
ספריות הנציגים של iOS GPU תומכות בדגמים כמותיים כברירת מחדל . אינך צריך לבצע שינויים כלשהם בקוד כדי להשתמש במודלים כמותיים עם נציג ה-GPU. הסעיף הבא מסביר כיצד להשבית תמיכה כמותית למטרות בדיקה או ניסוי.
השבת את התמיכה במודלים כמותיים
הקוד הבא מראה כיצד להשבית תמיכה עבור מודלים כמותיים.
מָהִיר
var options = MetalDelegate.Options()
options.isQuantizationEnabled = false
let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.quantizationEnabled = false;
ג
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault();
options.enable_quantization = false;
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
למידע נוסף על הפעלת דגמים קוונטיים עם האצת GPU, ראה סקירת נציגי GPU .