
O uso de unidades de processamento gráfico (GPUs) para executar seus modelos de aprendizado de máquina (ML) pode melhorar drasticamente o desempenho de seu modelo e a experiência do usuário de seus aplicativos habilitados para ML. Em dispositivos iOS, você pode habilitar o uso de execução acelerada por GPU de seus modelos usando um delegado . Os delegados atuam como drivers de hardware para o TensorFlow Lite, permitindo que você execute o código do seu modelo em processadores GPU.
Esta página descreve como habilitar a aceleração de GPU para modelos do TensorFlow Lite em aplicativos iOS. Para obter mais informações sobre como usar o delegado de GPU para o TensorFlow Lite, incluindo práticas recomendadas e técnicas avançadas, consulte a página de delegados de GPU .
Usar GPU com API de intérprete
A API do TensorFlow Lite Interpreter fornece um conjunto de APIs de uso geral para criar aplicativos de aprendizado de máquina. As instruções a seguir orientam você na adição de suporte a GPU a um aplicativo iOS. Este guia pressupõe que você já tenha um aplicativo iOS que possa executar com êxito um modelo de ML com o TensorFlow Lite.
Modifique o Podfile para incluir suporte a GPU
A partir da versão 2.3.0 do TensorFlow Lite, o delegado da GPU é excluído do pod para reduzir o tamanho do binário. Você pode incluí-los especificando uma subespecificação para o pod TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
OU
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Você também pode usar TensorFlowLiteObjC ou TensorFlowLiteC se quiser usar o Objective-C, que está disponível para as versões 2.4.0 e superiores, ou a API C.
Inicialize e use o delegado da GPU
Você pode usar o delegado da GPU com a API do TensorFlow Lite Interpreter com várias linguagens de programação. Swift e Objective-C são recomendados, mas você também pode usar C++ e C. O uso de C é necessário se você estiver usando uma versão do TensorFlow Lite anterior à 2.4. Os exemplos de código a seguir descrevem como usar o delegado com cada um desses idiomas.
Rápido
import TensorFlowLite
// Load model ...
// Initialize TensorFlow Lite interpreter with the GPU delegate.
let delegate = MetalDelegate()
if let interpreter = try Interpreter(modelPath: modelPath,
delegates: [delegate]) {
// Run inference ...
}
Objetivo-C
// Import module when using CocoaPods with module support
@import TFLTensorFlowLite;
// Or import following headers manually
#import "tensorflow/lite/objc/apis/TFLMetalDelegate.h"
#import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h"
// Initialize GPU delegate
TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init];
// Initialize interpreter with model path and GPU delegate
TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init];
NSError* error = nil;
TFLInterpreter* interpreter = [[TFLInterpreter alloc]
initWithModelPath:modelPath
options:options
delegates:@[ metalDelegate ]
error:&error];
if (error != nil) { /* Error handling... */ }
if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ }
if (error != nil) { /* Error handling... */ }
// Run inference ...
C++
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
tflite::ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// Clean up.
TFLGpuDelegateDelete(delegate);
C (antes de 2.4.0)
#include "tensorflow/lite/c/c_api.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
// Initialize model
TfLiteModel* model = TfLiteModelCreateFromFile(model_path);
// Initialize interpreter with GPU delegate
TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate();
TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config
TfLiteInterpreterOptionsAddDelegate(options, metal_delegate);
TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options);
TfLiteInterpreterOptionsDelete(options);
TfLiteInterpreterAllocateTensors(interpreter);
NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)];
NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)];
TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0);
const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0);
// Run inference
TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length);
TfLiteInterpreterInvoke(interpreter);
TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length);
// Clean up
TfLiteInterpreterDelete(interpreter);
TFLGpuDelegateDelete(metal_delegate);
TfLiteModelDelete(model);
Notas de uso da linguagem da API da GPU
- As versões do TensorFlow Lite anteriores à 2.4.0 só podem usar a API C para Objective-C.
- A API C++ só está disponível quando você usa bazel ou cria o TensorFlow Lite por conta própria. A API C++ não pode ser usada com CocoaPods.
- Ao usar o TensorFlow Lite com o delegado da GPU com C++, obtenha o delegado da GPU por meio da função
TFLGpuDelegateCreate()e passe-o paraInterpreter::ModifyGraphWithDelegate(), em vez de chamarInterpreter::AllocateTensors().
Crie e teste com o modo de lançamento
Mude para uma versão de versão com as configurações apropriadas do acelerador da API Metal para obter melhor desempenho e para testes finais. Esta seção explica como habilitar uma versão de compilação e definir a configuração para a aceleração do Metal.
Para mudar para uma compilação de lançamento:
- Edite as configurações de compilação selecionando Produto > Esquema > Editar esquema... e, em seguida, selecionando Executar .
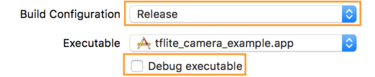
- Na guia Informações , altere Build Configuration para Release e desmarque Debug executável .
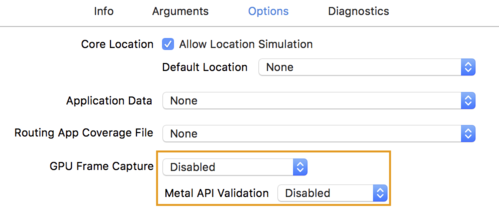
- Clique na guia Options e altere GPU Frame Capture para Disabled e Metal API Validation para Disabled .
- Certifique-se de selecionar compilações somente de versão na arquitetura de 64 bits. Em Project navigator > tflite_camera_example > PROJECT > your_project_name > Build Settings defina Build Active Architecture Only > Release para Yes .

Suporte avançado de GPU
Esta seção abrange os usos avançados do delegado de GPU para iOS, incluindo opções de delegado, buffers de entrada e saída e uso de modelos quantizados.
Opções de delegado para iOS
O construtor para delegado de GPU aceita uma struct de opções na API Swift , API Objective-C e API C . Passar nullptr (API C) ou nada (Objective-C e API Swift) para o inicializador define as opções padrão (explicadas no exemplo de Uso Básico acima).
Rápido
// THIS:
var options = MetalDelegate.Options()
options.isPrecisionLossAllowed = false
options.waitType = .passive
options.isQuantizationEnabled = true
let delegate = MetalDelegate(options: options)
// IS THE SAME AS THIS:
let delegate = MetalDelegate()
Objetivo-C
// THIS:
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.precisionLossAllowed = false;
options.waitType = TFLMetalDelegateThreadWaitTypePassive;
options.quantizationEnabled = true;
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options];
// IS THE SAME AS THIS:
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS:
const TFLGpuDelegateOptions options = {
.allow_precision_loss = false,
.wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive,
.enable_quantization = true,
};
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
// IS THE SAME AS THIS:
TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Buffers de entrada/saída usando a API C++
A computação na GPU requer que os dados estejam disponíveis para a GPU. Esse requisito geralmente significa que você deve executar uma cópia de memória. Você deve evitar que seus dados cruzem o limite de memória da CPU/GPU, se possível, pois isso pode levar uma quantidade significativa de tempo. Normalmente, esse cruzamento é inevitável, mas em alguns casos especiais, um ou outro pode ser omitido.
Se a entrada da rede for uma imagem já carregada na memória da GPU (por exemplo, uma textura da GPU contendo o feed da câmera), ela pode permanecer na memória da GPU sem nunca entrar na memória da CPU. Da mesma forma, se a saída da rede estiver na forma de uma imagem renderizável, como uma operação de transferência de estilo de imagem , você poderá exibir diretamente o resultado na tela.
Para obter o melhor desempenho, o TensorFlow Lite possibilita que os usuários leiam e gravem diretamente no buffer de hardware do TensorFlow e ignorem as cópias de memória evitáveis.
Supondo que a entrada da imagem esteja na memória da GPU, você deve primeiro convertê-la em um objeto MTLBuffer para Metal. Você pode associar um TfLiteTensor a um MTLBuffer preparado pelo usuário com a função TFLGpuDelegateBindMetalBufferToTensor() . Observe que esta função deve ser chamada após Interpreter::ModifyGraphWithDelegate() . Além disso, a saída de inferência é, por padrão, copiada da memória da GPU para a memória da CPU. Você pode desativar esse comportamento chamando Interpreter::SetAllowBufferHandleOutput(true) durante a inicialização.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h"
// ...
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->inputs()[0], user_provided_input_buffer)) {
return false;
}
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->outputs()[0], user_provided_output_buffer)) {
return false;
}
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return false;
Depois que o comportamento padrão é desativado, copiar a saída de inferência da memória da GPU para a memória da CPU requer uma chamada explícita para Interpreter::EnsureTensorDataIsReadable() para cada tensor de saída. Essa abordagem também funciona para modelos quantizados, mas você ainda precisa usar um buffer de tamanho float32 com float32 data , porque o buffer está vinculado ao buffer desquantizado interno.
Modelos quantizados
As bibliotecas delegadas da GPU do iOS suportam modelos quantizados por padrão . Você não precisa fazer nenhuma alteração no código para usar modelos quantizados com o delegado da GPU. A seção a seguir explica como desabilitar o suporte quantizado para fins de teste ou experimentais.
Desativar suporte a modelos quantizados
O código a seguir mostra como desabilitar o suporte para modelos quantizados.
Rápido
var options = MetalDelegate.Options()
options.isQuantizationEnabled = false
let delegate = MetalDelegate(options: options)
Objetivo-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault();
options.enable_quantization = false;
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Para obter mais informações sobre a execução de modelos quantizados com aceleração de GPU, consulte Visão geral do delegado de GPU .