
ابزارهای معیار
ابزارهای معیار TensorFlow Lite در حال حاضر آمار را برای معیارهای عملکرد مهم زیر اندازه گیری و محاسبه می کنند:
- زمان اولیه سازی
- زمان استنتاج حالت گرم کردن
- زمان استنتاج حالت پایدار
- استفاده از حافظه در زمان اولیه سازی
- مصرف کلی حافظه
ابزارهای بنچمارک بهعنوان برنامههای محک برای اندروید و iOS و بهعنوان باینری خط فرمان بومی در دسترس هستند و همه آنها منطق اندازهگیری عملکرد اصلی یکسانی دارند. توجه داشته باشید که گزینه های موجود و فرمت های خروجی به دلیل تفاوت در محیط زمان اجرا کمی متفاوت است.
برنامه بنچمارک اندروید
دو گزینه برای استفاده از ابزار بنچمارک در اندروید وجود دارد. یکی یک باینری بنچمارک بومی و دیگری یک برنامه بنچمارک اندرویدی است که معیار بهتری از عملکرد مدل در برنامه است. در هر صورت، اعداد از ابزار محک هنوز کمی با زمانی که استنتاج با مدل در برنامه واقعی اجرا میشود، متفاوت خواهد بود.
این برنامه بنچمارک اندروید رابط کاربری ندارد. با استفاده از دستور adb آن را نصب و اجرا کنید و با استفاده از دستور adb logcat نتایج را بازیابی کنید.
برنامه را دانلود یا بسازید
با استفاده از لینک های زیر، برنامه های بنچمارک پیش ساخته اندروید شبانه را دانلود کنید:
در مورد برنامه های بنچمارک اندروید که از عملیات TF از طریق Flex delegate پشتیبانی می کنند، از پیوندهای زیر استفاده کنید:
همچنین می توانید با دنبال کردن این دستورالعمل ها برنامه را از منبع بسازید.
معیار تهیه کنید
قبل از اجرای برنامه بنچمارک، برنامه را نصب کنید و فایل مدل را به صورت زیر به دستگاه فشار دهید:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
اجرای معیار
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph یک پارامتر مورد نیاز است.
-
graph:string
مسیر فایل مدل TFLite.
می توانید پارامترهای اختیاری بیشتری را برای اجرای معیار تعیین کنید.
-
num_threads:int(پیشفرض=1)
تعداد رشته هایی که برای اجرای مفسر TFLite استفاده می شود. -
use_gpu:bool(پیشفرض=نادرست)
از نماینده GPU استفاده کنید. -
use_nnapi:bool(پیش فرض=نادرست)
از نماینده NNAPI استفاده کنید. -
use_xnnpack:bool(پیشفرض=false)
از نماینده XNNPACK استفاده کنید. -
use_hexagon:bool(پیش فرض =false)
از نماینده Hexagon استفاده کنید.
بسته به دستگاهی که استفاده می کنید، برخی از این گزینه ها ممکن است در دسترس نباشند یا تاثیری نداشته باشند. برای پارامترهای عملکرد بیشتر که میتوانید با برنامه معیار اجرا کنید، به پارامترها مراجعه کنید.
نتایج را با استفاده از دستور logcat مشاهده کنید:
adb logcat | grep "Inference timings"
نتایج معیار به شرح زیر گزارش شده است:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
باینری معیار بومی
ابزار محک نیز به عنوان یک benchmark_model باینری بومی ارائه شده است. می توانید این ابزار را از خط فرمان پوسته در لینوکس، مک، دستگاه های جاسازی شده و دستگاه های اندرویدی اجرا کنید.
باینری را دانلود یا بسازید
با دنبال کردن لینکهای زیر، باینریهای خط فرمان بومی از پیش ساخته شده شبانه را دانلود کنید:
در مورد باینری های از پیش ساخته شده شبانه که از عملیات TF از طریق Flex delegate پشتیبانی می کنند، از پیوندهای زیر استفاده کنید:
برای محک زدن با نماینده Hexagon TensorFlow Lite ، فایلهای libhexagon_interface.so مورد نیاز را نیز از قبل ساختهایم (برای جزئیات بیشتر درباره این فایل اینجا را ببینید). لطفا پس از دانلود فایل پلتفرم مربوطه از لینک های زیر، نام فایل را به libhexagon_interface.so تغییر دهید.
همچنین می توانید باینری بنچمارک بومی را از منبع روی رایانه خود بسازید.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
برای ساخت با زنجیره ابزار Android NDK، ابتدا باید محیط ساخت را با دنبال کردن این راهنما تنظیم کنید یا از تصویر داکر همانطور که در این راهنما توضیح داده شده است استفاده کنید.
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
اجرای معیار
برای اجرای معیارها بر روی رایانه خود، باینری را از پوسته اجرا کنید.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
شما می توانید از همان مجموعه پارامترهایی که در بالا ذکر شد با باینری خط فرمان بومی استفاده کنید.
عملیات مدل سازی پروفایل
باینری مدل بنچمارک همچنین به شما امکان می دهد تا عملیات مدل را نمایه کنید و زمان اجرای هر اپراتور را دریافت کنید. برای انجام این کار، در حین فراخوانی، پرچم --enable_op_profiling=true به benchmark_model منتقل کنید. جزئیات در اینجا توضیح داده شده است.
باینری معیار بومی برای چندین گزینه عملکرد در یک اجرا
یک باینری راحت و ساده C++ نیز برای محک زدن چندین گزینه عملکرد در یک اجرا ارائه شده است. این باینری بر اساس ابزار محک ذکر شده ساخته شده است که تنها می تواند یک گزینه عملکرد واحد را در یک زمان محک بزند. آنها فرآیند ساخت/نصب/اجرا کردن یکسانی را به اشتراک می گذارند، اما نام هدف BUILD این باینری benchmark_model_performance_options است و برخی پارامترهای اضافی را می طلبد. یک پارامتر مهم برای این باینری این است:
perf_options_list : string (پیشفرض='همه')
فهرستی از گزینههای عملکرد TFLite که با کاما از هم جدا شدهاند تا محک بزنید.
شما می توانید باینری های از پیش ساخته شده شبانه برای این ابزار به شرح زیر دریافت کنید:
اپلیکیشن بنچمارک iOS
برای اجرای معیارها در دستگاه iOS، باید برنامه را از منبع بسازید. فایل مدل TensorFlow Lite را در پوشه benchmark_data درخت منبع قرار دهید و فایل benchmark_params.json را تغییر دهید. این فایلها در برنامه بستهبندی میشوند و برنامه دادهها را از دایرکتوری میخواند. برای دستورالعمل های دقیق به برنامه معیار iOS مراجعه کنید.
معیارهای عملکرد برای مدل های شناخته شده
این بخش معیارهای عملکرد TensorFlow Lite را هنگام اجرای مدلهای شناخته شده در برخی از دستگاههای Android و iOS فهرست میکند.
معیارهای عملکرد اندروید
این اعداد معیار عملکرد با دودویی معیار بومی تولید شدهاند.
برای بنچمارکهای اندروید، CPU Affinity قرار است از هستههای بزرگ در دستگاه برای کاهش واریانس استفاده کند ( جزئیات را ببینید).
فرض میکند که مدلها دانلود شده و در دایرکتوری /data/local/tmp/tflite_models از حالت فشرده خارج شدهاند. باینری بنچمارک با استفاده از این دستورالعمل ها ساخته می شود و فرض می شود که در فهرست /data/local/tmp قرار دارد.
برای اجرای معیار:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
برای اجرا با nnapi delegate، --use_nnapi=true را تنظیم کنید. برای اجرا با نماینده GPU، --use_gpu=true تنظیم کنید.
مقادیر عملکرد زیر در اندروید 10 اندازه گیری می شود.
| نام مدل | دستگاه | CPU، 4 رشته | پردازنده گرافیکی | NNAPI |
|---|---|---|---|---|
| Mobilenet_1.0_224 (float) | پیکسل 3 | 23.9 میلیثانیه | 6.45 میلیثانیه | 13.8 میلیثانیه |
| پیکسل 4 | 14.0 میلی ثانیه | 9.0 میلی ثانیه | 14.8 میلیثانیه | |
| Mobilenet_1.0_224 (مقدار) | پیکسل 3 | 13.4 میلیثانیه | --- | 6.0 میلی ثانیه |
| پیکسل 4 | 5.0 میلی ثانیه | --- | 3.2 میلی ثانیه | |
| موبایل NASNet | پیکسل 3 | 56 میلیثانیه | --- | 102 میلیثانیه |
| پیکسل 4 | 34.5 میلیثانیه | --- | 99.0 میلیثانیه | |
| SqueezeNet | پیکسل 3 | 35.8 میلیثانیه | 9.5 میلیثانیه | 18.5 میلیثانیه |
| پیکسل 4 | 23.9 میلیثانیه | 11.1 میلی ثانیه | 19.0 میلی ثانیه | |
| Inception_ResNet_V2 | پیکسل 3 | 422 میلیثانیه | 99.8 میلیثانیه | 201 میلیثانیه |
| پیکسل 4 | 272.6 میلیثانیه | 87.2 میلیثانیه | 171.1 میلیثانیه | |
| Inception_V4 | پیکسل 3 | 486 میلیثانیه | 93 میلیثانیه | 292 میلیثانیه |
| پیکسل 4 | 324.1 میلیثانیه | 97.6 میلیثانیه | 186.9 میلیثانیه |
معیارهای عملکرد iOS
این اعداد معیار عملکرد با برنامه معیار iOS تولید شدند.
برای اجرای بنچمارکهای iOS، برنامه محک اصلاح شد تا مدل مناسب را شامل شود و benchmark_params.json برای تنظیم num_threads روی 2 تغییر یافت. برای استفاده از نماینده GPU، "use_gpu" : "1" و "gpu_wait_type" : "aggressive" بودند. همچنین به benchmark_params.json اضافه شد.
| نام مدل | دستگاه | CPU، 2 رشته | پردازنده گرافیکی |
|---|---|---|---|
| Mobilenet_1.0_224 (float) | آیفون XS | 14.8 میلیثانیه | 3.4 میلیثانیه |
| Mobilenet_1.0_224 (مقدار) | آیفون XS | 11 میلی ثانیه | --- |
| موبایل NASNet | آیفون XS | 30.4 میلیثانیه | --- |
| SqueezeNet | آیفون XS | 21.1 میلیثانیه | 15.5 میلیثانیه |
| Inception_ResNet_V2 | آیفون XS | 261.1 میلیثانیه | 45.7 میلیثانیه |
| Inception_V4 | آیفون XS | 309 میلیثانیه | 54.4 میلیثانیه |
موارد داخلی TensorFlow Lite را ردیابی کنید
موارد داخلی TensorFlow Lite را در اندروید ردیابی کنید
رویدادهای داخلی از مفسر TensorFlow Lite یک برنامه Android را می توان با ابزارهای ردیابی Android ضبط کرد. آنها همان رویدادها با Android Trace API هستند، بنابراین رویدادهای ضبطشده از کد جاوا/کاتلین همراه با رویدادهای داخلی TensorFlow Lite دیده میشوند.
چند نمونه از رویدادها عبارتند از:
- فراخوانی اپراتور
- اصلاح نمودار توسط نماینده
- تخصیص تانسور
در میان گزینه های مختلف برای گرفتن ردیابی، این راهنما نمایه CPU Android Studio و برنامه System Tracing را پوشش می دهد. برای سایر گزینه ها به ابزار خط فرمان Perfetto یا ابزار خط فرمان Systrace مراجعه کنید.
افزودن رویدادهای ردیابی در کد جاوا
این یک قطعه کد از برنامه نمونه طبقه بندی تصاویر است. مفسر TensorFlow Lite در بخش recognizeImage/runInference اجرا میشود. این مرحله اختیاری است، اما برای کمک به اطلاع از محل برقراری تماس استنتاج مفید است.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
ردیابی TensorFlow Lite را فعال کنید
برای فعال کردن ردیابی TensorFlow Lite، قبل از شروع برنامه اندروید، ویژگی سیستم Android را debug.tflite.trace روی 1 تنظیم کنید.
adb shell setprop debug.tflite.trace 1
اگر این ویژگی زمانی تنظیم شده باشد که مفسر TensorFlow Lite مقداردهی شود، رویدادهای کلیدی (مثلاً فراخوانی اپراتور) از مفسر ردیابی خواهند شد.
بعد از اینکه همه ردیابی ها را گرفتید، ردیابی را با تنظیم مقدار ویژگی روی 0 غیرفعال کنید.
adb shell setprop debug.tflite.trace 0
نمایه CPU Android Studio
با دنبال کردن مراحل زیر با نمایه CPU Android Studio ردیابی کنید:
Run > Profile 'app' را از منوهای بالا انتخاب کنید.
وقتی پنجره Profiler ظاهر شد، روی هر نقطه از جدول زمانی CPU کلیک کنید.
از میان حالتهای پروفایل CPU، «ردیابی تماسهای سیستم» را انتخاب کنید.
دکمه "ضبط" را فشار دهید.
دکمه "توقف" را فشار دهید.
نتیجه ردیابی را بررسی کنید.
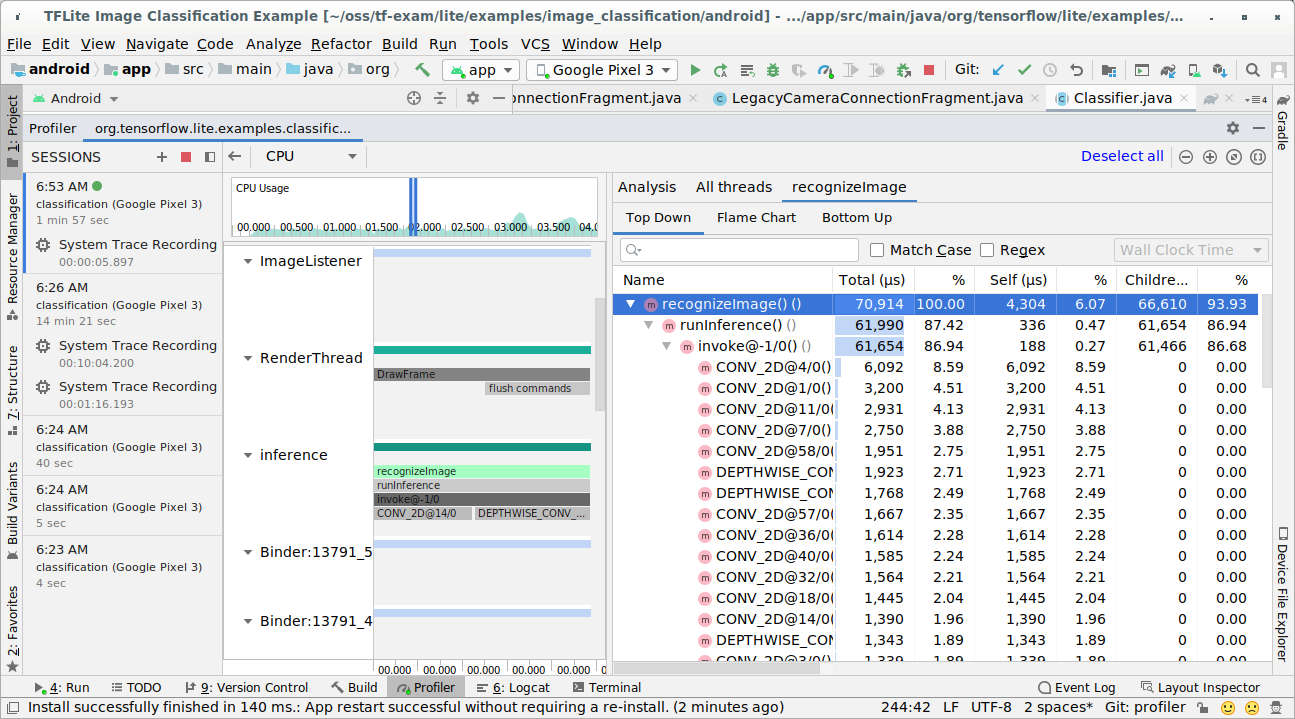
در این مثال، میتوانید سلسلهمراتب رویدادها را در یک رشته و آمار مربوط به زمان هر اپراتور را مشاهده کنید و همچنین جریان دادههای کل برنامه را در بین رشتهها مشاهده کنید.
برنامه ردیابی سیستم
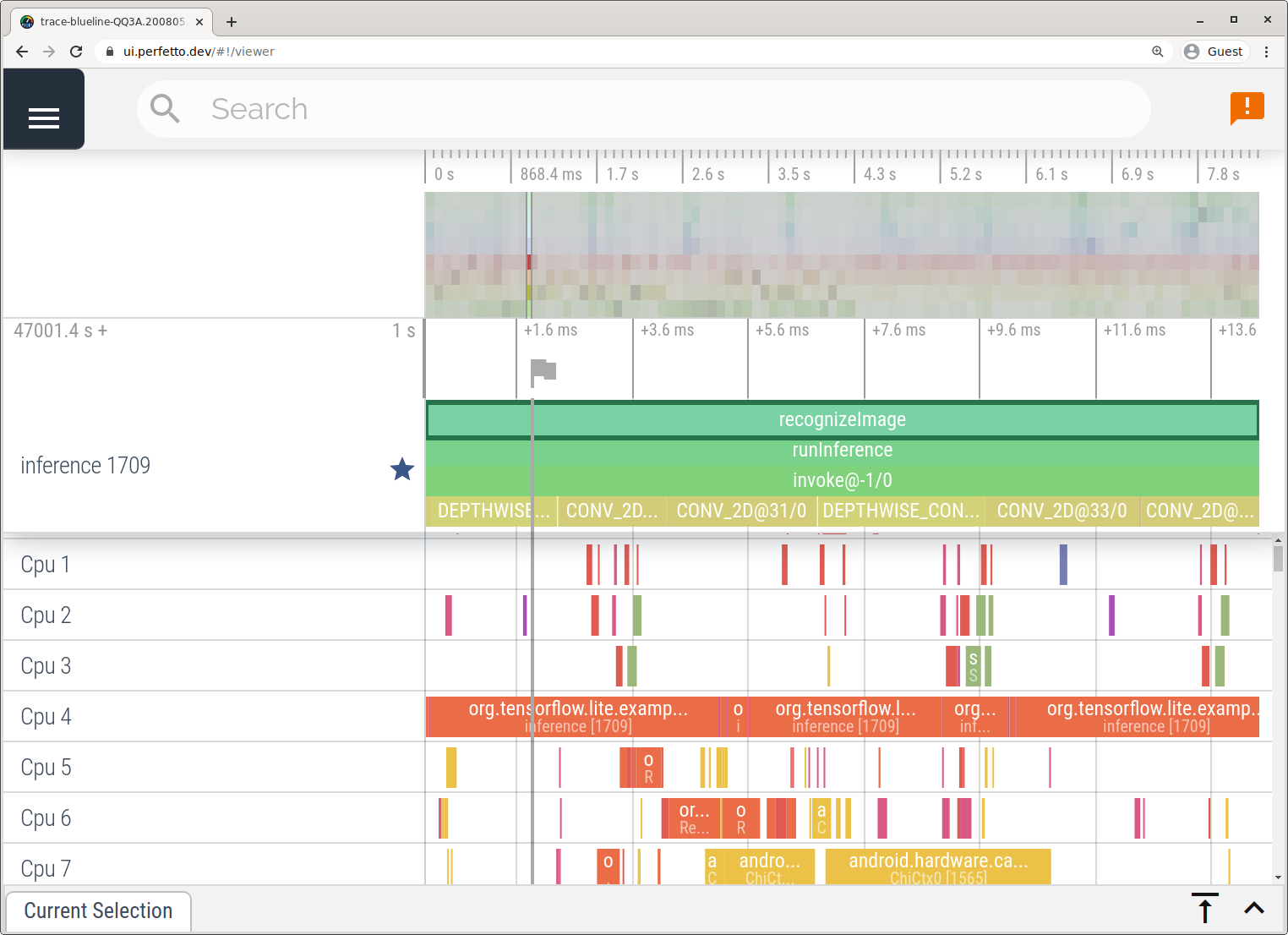
با دنبال کردن مراحلی که در برنامه System Tracing توضیح داده شده است، بدون Android Studio از ردیابی عکس بگیرید.
در این مثال، همان رویدادهای TFLite بسته به نسخه دستگاه Android ضبط و در قالب Perfetto یا Systrace ذخیره شدند. فایل های ردیابی گرفته شده را می توان در Perfetto UI باز کرد.
موارد داخلی TensorFlow Lite را در iOS ردیابی کنید
رویدادهای داخلی از مفسر TensorFlow Lite یک برنامه iOS را می توان با ابزار Instruments همراه با Xcode ضبط کرد. آنها رویدادهای نشانگر iOS هستند، بنابراین رویدادهای ضبط شده از کد Swift/Objective-C همراه با رویدادهای داخلی TensorFlow Lite دیده می شوند.
چند نمونه از رویدادها عبارتند از:
- فراخوانی اپراتور
- اصلاح نمودار توسط نماینده
- تخصیص تانسور
ردیابی TensorFlow Lite را فعال کنید
متغیر محیطی debug.tflite.trace با دنبال کردن مراحل زیر تنظیم کنید:
Product > Scheme > Edit Scheme... را از منوهای بالای Xcode انتخاب کنید.
روی "نمایه" در قسمت سمت چپ کلیک کنید.
کادر انتخاب «استفاده از آرگومانهای عمل اجرا و متغیرهای محیطی» را بردارید.
debug.tflite.traceرا در بخش «متغیرهای محیطی» اضافه کنید.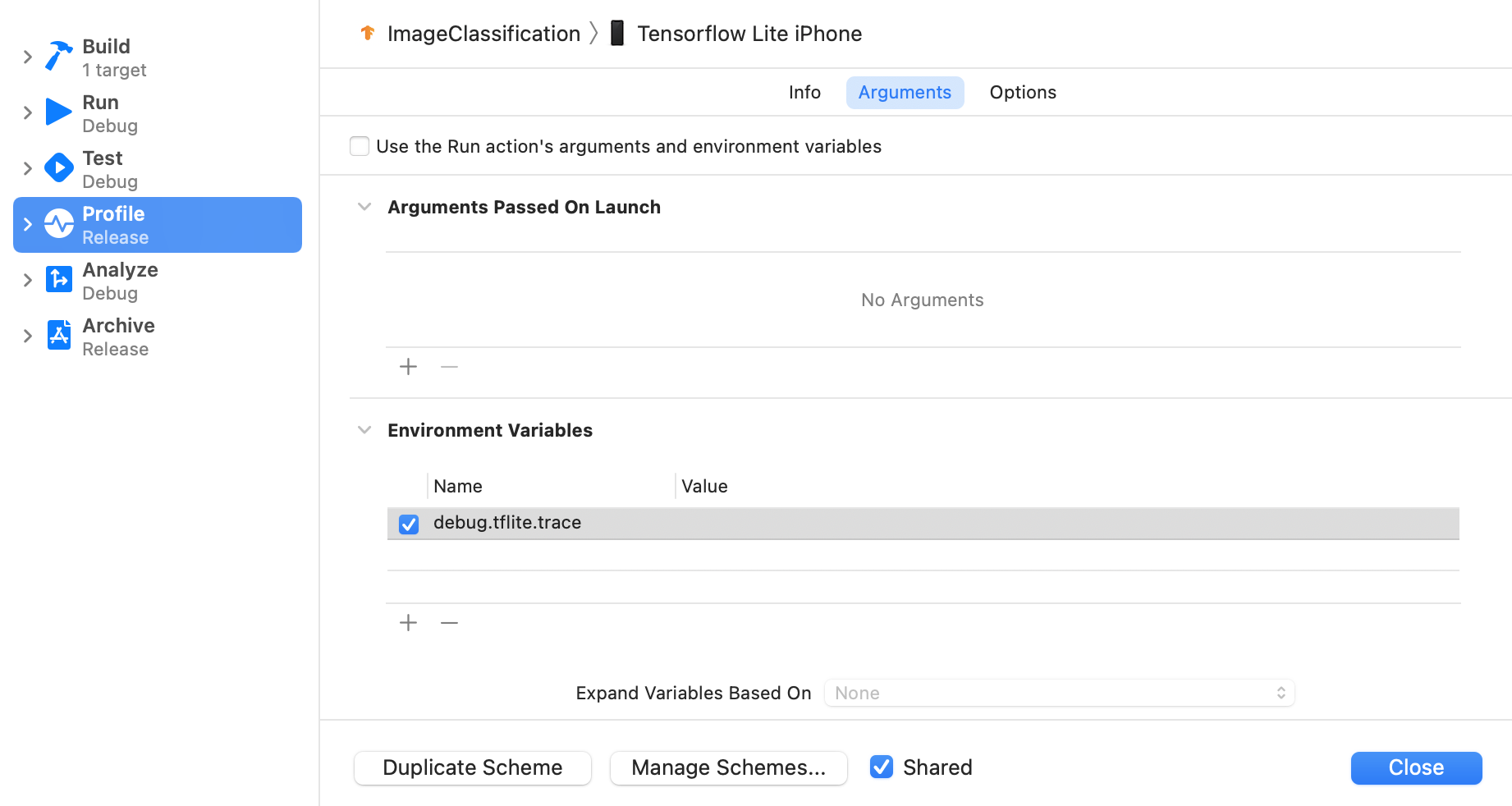
اگر میخواهید رویدادهای TensorFlow Lite را هنگام پروفایل کردن برنامه iOS حذف کنید، با حذف متغیر محیط، ردیابی را غیرفعال کنید.
ابزار XCode
با دنبال کردن مراحل زیر، ردیابی را ضبط کنید:
محصول > نمایه را از منوهای بالای Xcode انتخاب کنید.
هنگام راهاندازی ابزار Instruments، روی Logging در بین الگوهای پروفایل کلیک کنید.
دکمه "شروع" را فشار دهید.
دکمه "توقف" را فشار دهید.
برای گسترش موارد زیر سیستم OS Logging روی 'os_signpost' کلیک کنید.
روی «org.tensorflow.lite» زیرسیستم OS Logging کلیک کنید.
نتیجه ردیابی را بررسی کنید.
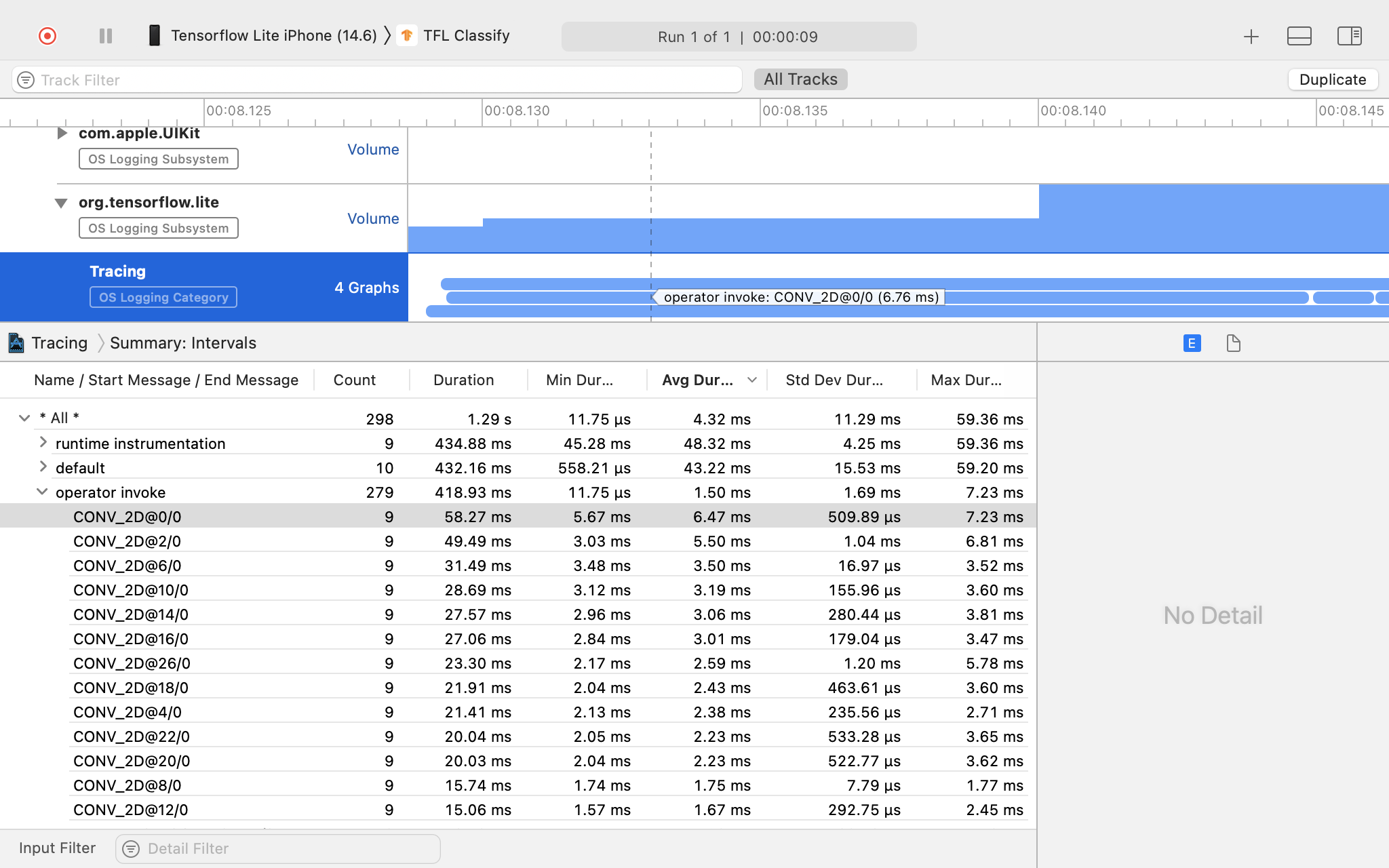
در این مثال می توانید سلسله مراتب رویدادها و آمار را برای هر زمان اپراتور مشاهده کنید.
با استفاده از داده های ردیابی
دادههای ردیابی به شما امکان میدهد گلوگاههای عملکرد را شناسایی کنید.
در اینجا چند نمونه از بینشهایی وجود دارد که میتوانید از نمایهساز و راهحلهای بالقوه برای بهبود عملکرد دریافت کنید:
- اگر تعداد هستههای CPU موجود کمتر از تعداد رشتههای استنتاج باشد، سربار زمانبندی CPU میتواند به عملکرد پایینتر منجر شود. برای جلوگیری از همپوشانی با استنتاج مدل خود یا تغییر دادن تعداد رشته های مفسر، می توانید سایر کارهای فشرده CPU را در برنامه خود برنامه ریزی مجدد کنید.
- اگر اپراتورها به طور کامل تفویض نشده باشند، برخی از بخشهای نمودار مدل به جای شتابدهنده سختافزاری مورد انتظار، بر روی CPU اجرا میشوند. می توانید اپراتورهای پشتیبانی نشده را با عملگرهای پشتیبانی شده مشابه جایگزین کنید.