
एज उपकरणों में अक्सर सीमित मेमोरी या कम्प्यूटेशनल शक्ति होती है। मॉडलों पर विभिन्न अनुकूलन लागू किए जा सकते हैं ताकि उन्हें इन बाधाओं के भीतर चलाया जा सके। इसके अलावा, कुछ अनुकूलन त्वरित अनुमान के लिए विशेष हार्डवेयर के उपयोग की अनुमति देते हैं।
TensorFlow Lite और TensorFlow मॉडल ऑप्टिमाइज़ेशन टूलकिट अनुकूलन अनुमान की जटिलता को कम करने के लिए उपकरण प्रदान करते हैं।
यह अनुशंसा की जाती है कि आप अपनी एप्लिकेशन विकास प्रक्रिया के दौरान मॉडल अनुकूलन पर विचार करें। यह दस्तावेज़ एज हार्डवेयर पर तैनाती के लिए टेन्सरफ़्लो मॉडल को अनुकूलित करने के लिए कुछ सर्वोत्तम प्रथाओं की रूपरेखा देता है।
मॉडलों को अनुकूलित क्यों किया जाना चाहिए
ऐसे कई मुख्य तरीके हैं जिनसे मॉडल अनुकूलन अनुप्रयोग विकास में मदद कर सकता है।
आकार में कमी
किसी मॉडल के आकार को कम करने के लिए अनुकूलन के कुछ रूपों का उपयोग किया जा सकता है। छोटे मॉडलों के निम्नलिखित लाभ हैं:
- छोटा भंडारण आकार: छोटे मॉडल आपके उपयोगकर्ताओं के उपकरणों पर कम भंडारण स्थान घेरते हैं। उदाहरण के लिए, छोटे मॉडल का उपयोग करने वाला एंड्रॉइड ऐप उपयोगकर्ता के मोबाइल डिवाइस पर कम संग्रहण स्थान लेगा।
- छोटा डाउनलोड आकार: छोटे मॉडलों को उपयोगकर्ताओं के उपकरणों पर डाउनलोड करने के लिए कम समय और बैंडविड्थ की आवश्यकता होती है।
- कम मेमोरी उपयोग: छोटे मॉडल चलाने पर कम रैम का उपयोग करते हैं, जो आपके एप्लिकेशन के अन्य हिस्सों के उपयोग के लिए मेमोरी को खाली कर देता है, और बेहतर प्रदर्शन और स्थिरता में तब्दील हो सकता है।
इन सभी मामलों में परिमाणीकरण एक मॉडल के आकार को कम कर सकता है, संभवतः कुछ सटीकता की कीमत पर। प्रूनिंग और क्लस्टरिंग किसी मॉडल को अधिक आसानी से संपीड़ित करके डाउनलोड के लिए उसके आकार को कम कर सकती है।
विलंबता में कमी
विलंबता किसी दिए गए मॉडल के साथ एकल अनुमान को चलाने में लगने वाले समय की मात्रा है। अनुकूलन के कुछ रूप किसी मॉडल का उपयोग करके अनुमान चलाने के लिए आवश्यक गणना की मात्रा को कम कर सकते हैं, जिसके परिणामस्वरूप विलंबता कम हो सकती है। विलंबता का असर बिजली की खपत पर भी पड़ सकता है।
वर्तमान में, परिमाणीकरण का उपयोग अनुमान के दौरान होने वाली गणनाओं को सरल बनाकर विलंबता को कम करने के लिए किया जा सकता है, संभवतः कुछ सटीकता की कीमत पर।
त्वरक अनुकूलता
कुछ हार्डवेयर त्वरक, जैसे कि एज टीपीयू , उन मॉडलों के साथ बहुत तेजी से अनुमान लगा सकते हैं जिन्हें सही ढंग से अनुकूलित किया गया है।
आम तौर पर, इस प्रकार के उपकरणों के लिए मॉडलों को एक विशिष्ट तरीके से परिमाणित करने की आवश्यकता होती है। प्रत्येक हार्डवेयर एक्सेलेरेटर की आवश्यकताओं के बारे में अधिक जानने के लिए उसका दस्तावेज़ देखें।
व्यापार नापसंद
अनुकूलन के परिणामस्वरूप संभावित रूप से मॉडल सटीकता में परिवर्तन हो सकता है, जिस पर एप्लिकेशन विकास प्रक्रिया के दौरान विचार किया जाना चाहिए।
सटीकता में परिवर्तन व्यक्तिगत मॉडल के अनुकूलित होने पर निर्भर करता है, और समय से पहले भविष्यवाणी करना मुश्किल होता है। आम तौर पर, जो मॉडल आकार या विलंबता के लिए अनुकूलित होते हैं वे थोड़ी मात्रा में सटीकता खो देंगे। आपके एप्लिकेशन के आधार पर, यह आपके उपयोगकर्ताओं के अनुभव को प्रभावित कर भी सकता है और नहीं भी। दुर्लभ मामलों में, अनुकूलन प्रक्रिया के परिणामस्वरूप कुछ मॉडल कुछ सटीकता प्राप्त कर सकते हैं।
अनुकूलन के प्रकार
TensorFlow Lite वर्तमान में परिमाणीकरण, छंटाई और क्लस्टरिंग के माध्यम से अनुकूलन का समर्थन करता है।
ये TensorFlow मॉडल ऑप्टिमाइज़ेशन टूलकिट का हिस्सा हैं, जो मॉडल ऑप्टिमाइज़ेशन तकनीकों के लिए संसाधन प्रदान करता है जो TensorFlow Lite के साथ संगत हैं।
परिमाणीकरण
क्वांटाइजेशन एक मॉडल के मापदंडों का प्रतिनिधित्व करने के लिए उपयोग की जाने वाली संख्याओं की सटीकता को कम करके काम करता है, जो डिफ़ॉल्ट रूप से 32-बिट फ़्लोटिंग पॉइंट नंबर होते हैं। इसके परिणामस्वरूप मॉडल का आकार छोटा हो जाता है और गणना तेज हो जाती है।
TensorFlow Lite में निम्न प्रकार के परिमाणीकरण उपलब्ध हैं:
| तकनीक | डेटा आवश्यकताएँ | आकार में कमी | शुद्धता | समर्थित हार्डवेयर |
|---|---|---|---|---|
| प्रशिक्षण के बाद फ़्लोट16 परिमाणीकरण | कोई डेटा नहीं | 50 तक% | नगण्य सटीकता हानि | सीपीयू, जीपीयू |
| प्रशिक्षण के बाद गतिशील रेंज परिमाणीकरण | कोई डेटा नहीं | 75% तक | सबसे छोटी सटीकता हानि | सीपीयू, जीपीयू (एंड्रॉइड) |
| प्रशिक्षण के बाद पूर्णांक परिमाणीकरण | बिना लेबल वाला प्रतिनिधि नमूना | 75% तक | छोटी सटीकता हानि | सीपीयू, जीपीयू (एंड्रॉइड), एजटीपीयू, हेक्सागोन डीएसपी |
| परिमाणीकरण-जागरूक प्रशिक्षण | लेबल किया गया प्रशिक्षण डेटा | 75% तक | सबसे छोटी सटीकता हानि | सीपीयू, जीपीयू (एंड्रॉइड), एजटीपीयू, हेक्सागोन डीएसपी |
निम्नलिखित निर्णय वृक्ष आपको अपेक्षित मॉडल आकार और सटीकता के आधार पर उन परिमाणीकरण योजनाओं का चयन करने में मदद करता है जिन्हें आप अपने मॉडल के लिए उपयोग करना चाहते हैं।
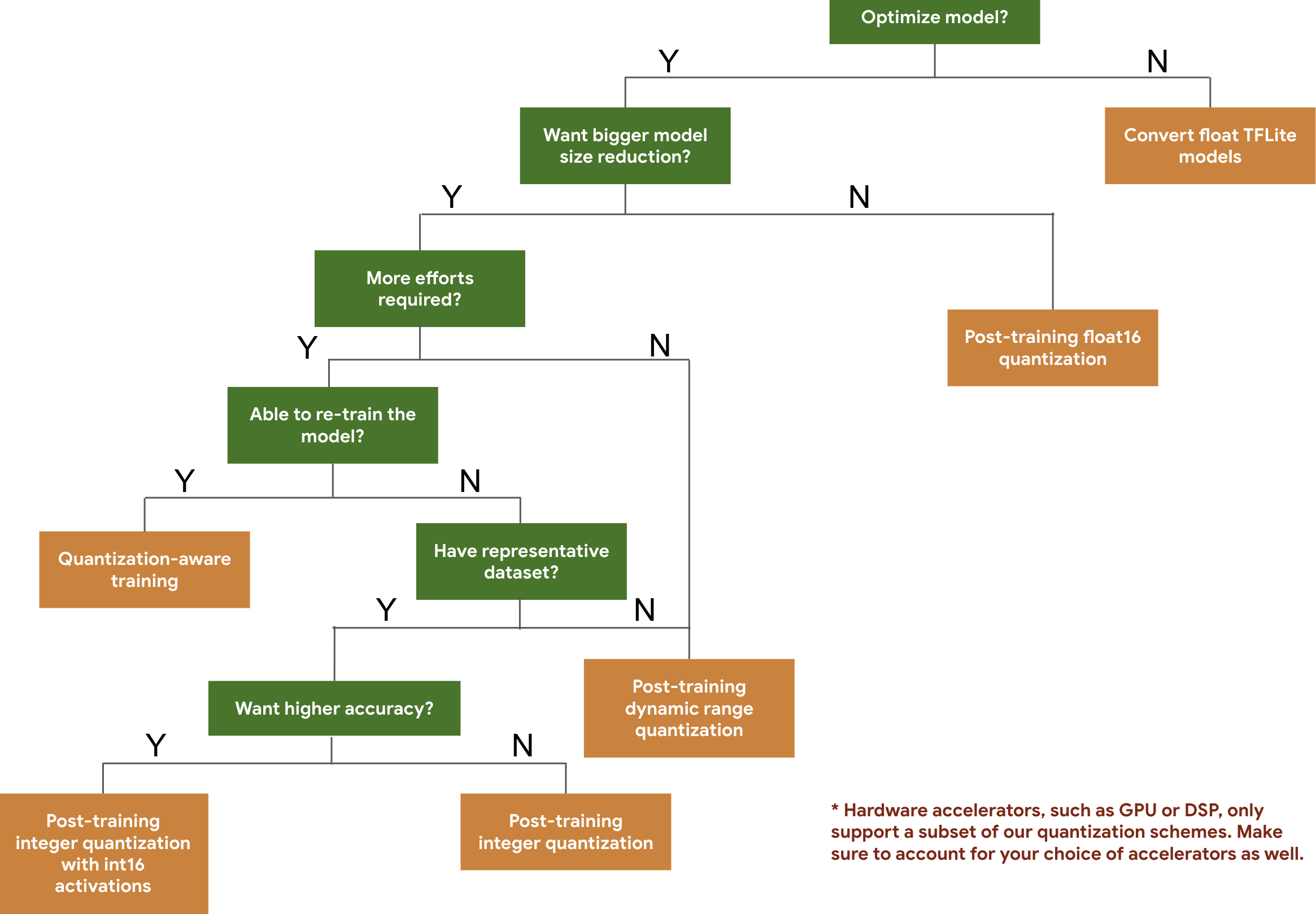
कुछ मॉडलों पर प्रशिक्षण के बाद परिमाणीकरण और परिमाणीकरण-जागरूक प्रशिक्षण के लिए विलंबता और सटीकता परिणाम नीचे दिए गए हैं। सभी विलंबता संख्याओं को एक बड़े कोर सीपीयू का उपयोग करके Pixel 2 उपकरणों पर मापा जाता है। जैसे-जैसे टूलकिट में सुधार होगा, वैसे-वैसे यहां संख्याएं भी बढ़ेंगी:
| नमूना | टॉप-1 सटीकता (मूल) | टॉप-1 सटीकता (प्रशिक्षण के बाद मात्राबद्ध) | टॉप-1 सटीकता (क्वांटाइज़ेशन अवेयर ट्रेनिंग) | विलंबता (मूल) (एमएस) | विलंबता (प्रशिक्षण के बाद मात्राबद्ध) (एमएस) | विलंबता (परिमाणीकरण जागरूक प्रशिक्षण) (एमएस) | आकार (मूल) (एमबी) | आकार (अनुकूलित) (एमबी) |
|---|---|---|---|---|---|---|---|---|
| मोबाइलनेट-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| मोबाइलनेट-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| आरंभ_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| रेसनेट_v2_101 | 0.770 | 0.768 | एन/ए | 3973 | 2868 | एन/ए | 178.3 | 44.9 |
Int16 सक्रियण और int8 भार के साथ पूर्ण पूर्णांक परिमाणीकरण
Int16 सक्रियणों के साथ परिमाणीकरण एक पूर्ण पूर्णांक परिमाणीकरण योजना है जिसमें int16 में सक्रियण और int8 में भार है। यह मोड समान मॉडल आकार को ध्यान में रखते हुए int8 में सक्रियण और भार दोनों के साथ पूर्ण पूर्णांक परिमाणीकरण योजना की तुलना में परिमाणित मॉडल की सटीकता में सुधार कर सकता है। इसकी अनुशंसा तब की जाती है जब सक्रियण परिमाणीकरण के प्रति संवेदनशील होते हैं।
ध्यान दें: वर्तमान में इस परिमाणीकरण योजना के लिए TFLite में केवल गैर-अनुकूलित संदर्भ कर्नेल कार्यान्वयन उपलब्ध हैं, इसलिए डिफ़ॉल्ट रूप से int8 कर्नेल की तुलना में प्रदर्शन धीमा होगा। इस मोड का पूरा लाभ वर्तमान में विशेष हार्डवेयर, या कस्टम सॉफ़्टवेयर के माध्यम से प्राप्त किया जा सकता है।
नीचे कुछ मॉडलों के लिए सटीकता परिणाम दिए गए हैं जो इस मोड से लाभान्वित होते हैं। नमूना सटीकता मीट्रिक प्रकार सटीकता (फ्लोट32 सक्रियण) सटीकता (int8 सक्रियण) सटीकता (int16 सक्रियण) Wav2letter WER 6.7% 7.7% 7.2% डीपस्पीच 0.5.1 (अनियंत्रित) प्रमाणपत्र 6.13% 43.67% 6.52% योलोV3 एमएपी(आईओयू=0.5) 0.577 0.563 0.574 मोबाइलनेटV1 टॉप-1 सटीकता 0.7062 0.694 0.6936 मोबाइलनेटV2 टॉप-1 सटीकता 0.718 0.7126 0.7137 मोबाइलबर्ट F1(सटीक मिलान) 88.81(81.23) 2.08(0) 88.73(81.15)
छंटाई
प्रूनिंग एक मॉडल के भीतर उन मापदंडों को हटाकर काम करती है जिनका उसकी भविष्यवाणियों पर केवल मामूली प्रभाव पड़ता है। काटे गए मॉडल डिस्क पर समान आकार के होते हैं, और उनकी रनटाइम विलंबता समान होती है, लेकिन उन्हें अधिक प्रभावी ढंग से संपीड़ित किया जा सकता है। यह मॉडल डाउनलोड आकार को कम करने के लिए प्रूनिंग को एक उपयोगी तकनीक बनाता है।
भविष्य में, TensorFlow Lite काँटे गए मॉडलों के लिए विलंबता में कमी प्रदान करेगा।
क्लस्टरिंग
क्लस्टरिंग एक मॉडल में प्रत्येक परत के वजन को क्लस्टर की पूर्वनिर्धारित संख्या में समूहित करके काम करती है, फिर प्रत्येक व्यक्तिगत क्लस्टर से संबंधित वजन के लिए सेंट्रोइड मान साझा करती है। इससे किसी मॉडल में अद्वितीय वजन मानों की संख्या कम हो जाती है, जिससे इसकी जटिलता कम हो जाती है।
परिणामस्वरूप, क्लस्टर्ड मॉडल को अधिक प्रभावी ढंग से संपीड़ित किया जा सकता है, जिससे प्रूनिंग के समान तैनाती लाभ मिलते हैं।
विकास कार्यप्रवाह
शुरुआती बिंदु के रूप में, जांचें कि होस्ट किए गए मॉडल आपके एप्लिकेशन के लिए काम कर सकते हैं या नहीं। यदि नहीं, तो हम अनुशंसा करते हैं कि उपयोगकर्ता प्रशिक्षण के बाद परिमाणीकरण उपकरण से शुरुआत करें क्योंकि यह व्यापक रूप से लागू है और इसके लिए प्रशिक्षण डेटा की आवश्यकता नहीं है।
ऐसे मामलों के लिए जहां सटीकता और विलंबता लक्ष्य पूरे नहीं होते हैं, या हार्डवेयर त्वरक समर्थन महत्वपूर्ण है, परिमाणीकरण-जागरूक प्रशिक्षण बेहतर विकल्प है। TensorFlow मॉडल ऑप्टिमाइज़ेशन टूलकिट के अंतर्गत अतिरिक्त अनुकूलन तकनीकें देखें।
यदि आप अपने मॉडल के आकार को और कम करना चाहते हैं, तो आप अपने मॉडलों को परिमाणित करने से पहले प्रूनिंग और/या क्लस्टरिंग का प्रयास कर सकते हैं।