
प्रशिक्षण के बाद परिमाणीकरण एक रूपांतरण तकनीक है जो मॉडल सटीकता में थोड़ी गिरावट के साथ सीपीयू और हार्डवेयर त्वरक विलंबता में सुधार करते हुए मॉडल आकार को कम कर सकती है। जब आप TensorFlow Lite कनवर्टर का उपयोग करके इसे TensorFlow Lite प्रारूप में परिवर्तित करते हैं, तो आप पहले से प्रशिक्षित फ्लोट TensorFlow मॉडल को परिमाणित कर सकते हैं।
अनुकूलन के तरीके
चुनने के लिए प्रशिक्षण के बाद परिमाणीकरण के कई विकल्प मौजूद हैं। यहां विकल्पों और उनके द्वारा प्रदान किए जाने वाले लाभों की एक सारांश तालिका दी गई है:
| तकनीक | फ़ायदे | हार्डवेयर |
|---|---|---|
| गतिशील रेंज परिमाणीकरण | 4x छोटा, 2x-3x स्पीडअप | CPU |
| पूर्ण पूर्णांक परिमाणीकरण | 4x छोटा, 3x+ स्पीडअप | सीपीयू, एज टीपीयू, माइक्रोकंट्रोलर |
| फ़्लोट16 परिमाणीकरण | 2x छोटा, GPU त्वरण | सीपीयू, जीपीयू |
निम्नलिखित निर्णय वृक्ष यह निर्धारित करने में मदद कर सकता है कि आपके उपयोग के मामले में प्रशिक्षण के बाद कौन सी परिमाणीकरण विधि सर्वोत्तम है:
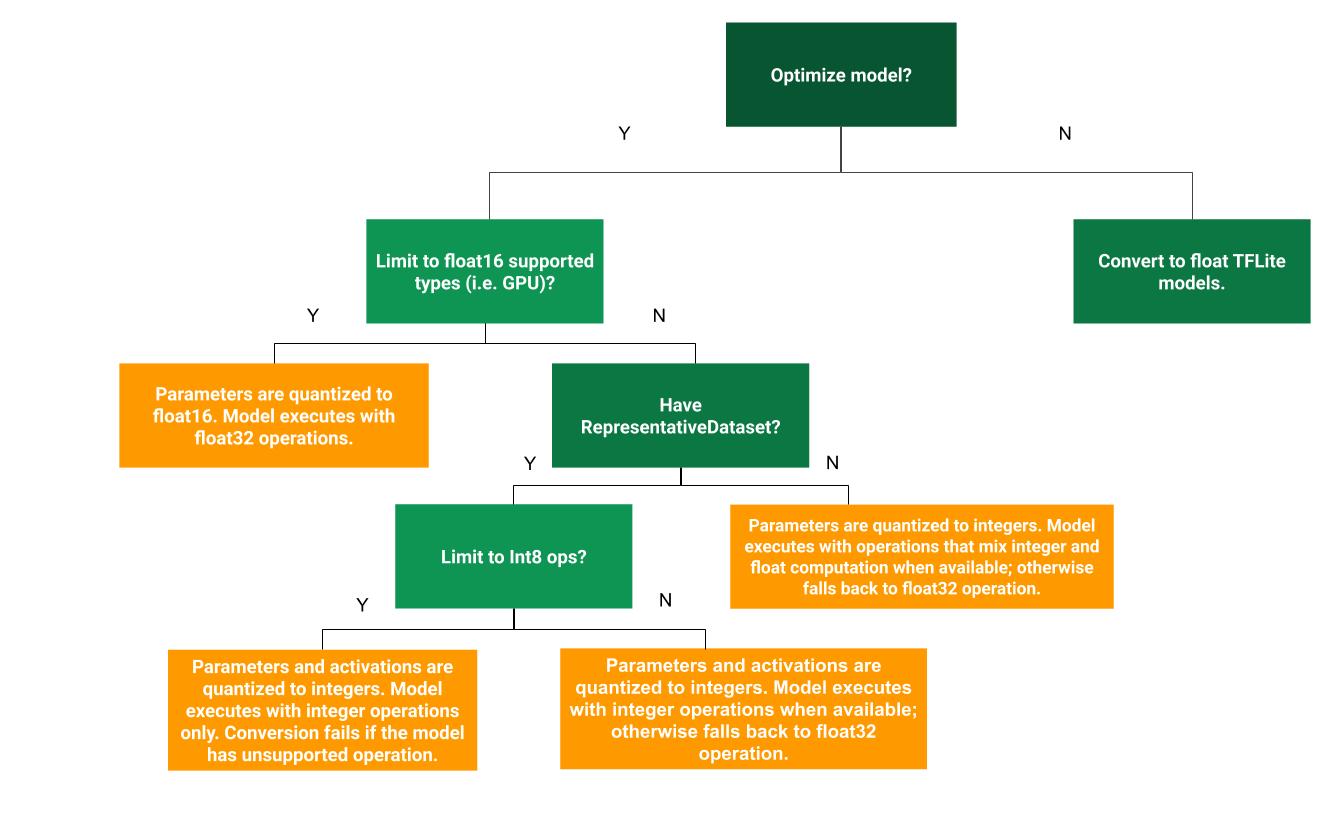
गतिशील रेंज परिमाणीकरण
डायनामिक रेंज क्वांटाइजेशन एक अनुशंसित शुरुआती बिंदु है क्योंकि यह आपको अंशांकन के लिए एक प्रतिनिधि डेटासेट प्रदान किए बिना कम मेमोरी उपयोग और तेज गणना प्रदान करता है। इस प्रकार का परिमाणीकरण, रूपांतरण समय पर फ़्लोटिंग पॉइंट से पूर्णांक तक केवल वज़न को सांख्यिकीय रूप से परिमाणित करता है, जो 8-बिट परिशुद्धता प्रदान करता है:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
अनुमान के दौरान विलंबता को और कम करने के लिए, "डायनामिक-रेंज" ऑपरेटर गतिशील रूप से 8-बिट्स की सीमा के आधार पर सक्रियणों की मात्रा निर्धारित करते हैं और 8-बिट भार और सक्रियणों के साथ गणना करते हैं। यह अनुकूलन पूरी तरह से निश्चित-बिंदु अनुमान के करीब विलंबता प्रदान करता है। हालाँकि, आउटपुट अभी भी फ़्लोटिंग पॉइंट का उपयोग करके संग्रहीत किए जाते हैं इसलिए डायनेमिक-रेंज ऑप्स की बढ़ी हुई गति पूर्ण निश्चित-पॉइंट गणना से कम है।
पूर्ण पूर्णांक परिमाणीकरण
यह सुनिश्चित करके कि सभी मॉडल गणित पूर्णांक परिमाणित हैं, आप विलंबता में और सुधार, चरम मेमोरी उपयोग में कमी और पूर्णांक केवल हार्डवेयर उपकरणों या त्वरक के साथ संगतता प्राप्त कर सकते हैं।
पूर्ण पूर्णांक परिमाणीकरण के लिए, आपको मॉडल में सभी फ़्लोटिंग-पॉइंट टेंसरों की सीमा, यानी (न्यूनतम, अधिकतम) को कैलिब्रेट या अनुमान लगाने की आवश्यकता है। भार और पूर्वाग्रह जैसे स्थिर टेंसरों के विपरीत, परिवर्तनीय टेंसर जैसे मॉडल इनपुट, सक्रियण (मध्यवर्ती परतों के आउटपुट) और मॉडल आउटपुट को तब तक कैलिब्रेट नहीं किया जा सकता जब तक कि हम कुछ अनुमान चक्र नहीं चलाते। परिणामस्वरूप, कनवर्टर को उन्हें कैलिब्रेट करने के लिए एक प्रतिनिधि डेटासेट की आवश्यकता होती है। यह डेटासेट प्रशिक्षण या सत्यापन डेटा का एक छोटा उपसमूह (लगभग ~100-500 नमूने) हो सकता है। नीचे representative_dataset() फ़ंक्शन देखें।
TensorFlow 2.7 संस्करण से, आप निम्नलिखित उदाहरण के रूप में हस्ताक्षर के माध्यम से प्रतिनिधि डेटासेट निर्दिष्ट कर सकते हैं:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
यदि दिए गए TensorFlow मॉडल में एक से अधिक हस्ताक्षर हैं, तो आप हस्ताक्षर कुंजी निर्दिष्ट करके एकाधिक डेटासेट निर्दिष्ट कर सकते हैं:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
आप इनपुट टेंसर सूची प्रदान करके प्रतिनिधि डेटासेट उत्पन्न कर सकते हैं:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 संस्करण के बाद से, हम इनपुट टेंसर सूची-आधारित दृष्टिकोण पर हस्ताक्षर-आधारित दृष्टिकोण का उपयोग करने की सलाह देते हैं क्योंकि इनपुट टेंसर ऑर्डर को आसानी से फ़्लिप किया जा सकता है।
परीक्षण उद्देश्यों के लिए, आप निम्नानुसार एक डमी डेटासेट का उपयोग कर सकते हैं:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
फ़्लोट फ़ॉलबैक के साथ पूर्णांक (डिफ़ॉल्ट फ़्लोट इनपुट/आउटपुट का उपयोग करके)
किसी मॉडल को पूरी तरह से पूर्णांकित करने के लिए, लेकिन फ़्लोट ऑपरेटरों का उपयोग तब करें जब उनके पास पूर्णांक कार्यान्वयन न हो (यह सुनिश्चित करने के लिए कि रूपांतरण सुचारू रूप से हो), निम्नलिखित चरणों का उपयोग करें:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
केवल पूर्णांक
केवल पूर्णांक मॉडल बनाना माइक्रोकंट्रोलर्स और कोरल एज टीपीयू के लिए टेन्सरफ्लो लाइट का एक सामान्य उपयोग मामला है।
इसके अतिरिक्त, केवल पूर्णांक उपकरणों (जैसे 8-बिट माइक्रोकंट्रोलर) और त्वरक (जैसे कोरल एज टीपीयू) के साथ संगतता सुनिश्चित करने के लिए, आप निम्न चरणों का उपयोग करके इनपुट और आउटपुट सहित सभी ऑप्स के लिए पूर्ण पूर्णांक परिमाणीकरण लागू कर सकते हैं:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
फ़्लोट16 परिमाणीकरण
आप 16-बिट फ़्लोटिंग पॉइंट नंबरों के लिए आईईईई मानक, फ़्लोटिंग 16 के वज़न को परिमाणित करके फ़्लोटिंग पॉइंट मॉडल के आकार को कम कर सकते हैं। वज़न के फ्लोट16 परिमाणीकरण को सक्षम करने के लिए, निम्नलिखित चरणों का उपयोग करें:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
फ्लोट16 परिमाणीकरण के लाभ इस प्रकार हैं:
- यह मॉडल के आकार को आधे तक कम कर देता है (क्योंकि सभी वजन उनके मूल आकार के आधे हो जाते हैं)।
- इससे सटीकता में न्यूनतम हानि होती है।
- यह कुछ प्रतिनिधियों (उदाहरण के लिए GPU प्रतिनिधि) का समर्थन करता है जो सीधे फ्लोट16 डेटा पर काम कर सकता है, जिसके परिणामस्वरूप फ्लोट32 गणनाओं की तुलना में तेज़ निष्पादन होता है।
फ्लोट16 परिमाणीकरण के नुकसान इस प्रकार हैं:
- यह विलंबता को उतना कम नहीं करता जितना निश्चित बिंदु गणित के परिमाणीकरण को कम करता है।
- डिफ़ॉल्ट रूप से, एक फ्लोट16 परिमाणित मॉडल सीपीयू पर चलने पर वजन मानों को फ्लोट32 में "डिक्वांटाइज" कर देगा। (ध्यान दें कि GPU प्रतिनिधि इस डिक्वांटाइज़ेशन को निष्पादित नहीं करेगा, क्योंकि यह फ्लोट16 डेटा पर काम कर सकता है।)
केवल पूर्णांक: 8-बिट भार के साथ 16-बिट सक्रियण (प्रयोगात्मक)
यह एक प्रायोगिक परिमाणीकरण योजना है। यह "केवल पूर्णांक" योजना के समान है, लेकिन सक्रियता को उनकी सीमा के आधार पर 16-बिट्स में परिमाणित किया जाता है, वजन को 8-बिट पूर्णांक में परिमाणित किया जाता है और पूर्वाग्रह को 64-बिट पूर्णांक में परिमाणित किया जाता है। इसे आगे 16x8 परिमाणीकरण के रूप में जाना जाता है।
इस परिमाणीकरण का मुख्य लाभ यह है कि यह सटीकता में काफी सुधार कर सकता है, लेकिन केवल मॉडल आकार को थोड़ा बढ़ा सकता है।
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
यदि मॉडल में कुछ ऑपरेटरों के लिए 16x8 परिमाणीकरण समर्थित नहीं है, तो मॉडल को अभी भी परिमाणित किया जा सकता है, लेकिन असमर्थित ऑपरेटरों को फ़्लोट में रखा जाता है। इसकी अनुमति देने के लिए निम्नलिखित विकल्प को target_spec में जोड़ा जाना चाहिए।
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
उपयोग के मामलों के उदाहरण जहां इस परिमाणीकरण योजना द्वारा प्रदान की गई सटीकता में सुधार शामिल हैं:
- सुपर-रिज़ॉल्यूशन,
- ऑडियो सिग्नल प्रोसेसिंग जैसे शोर रद्द करना और बीमफॉर्मिंग,
- छवि डी-नोइज़िंग,
- एक ही छवि से एचडीआर पुनर्निर्माण।
इस परिमाणीकरण का नुकसान यह है:
- अनुकूलित कर्नेल कार्यान्वयन की कमी के कारण वर्तमान में अनुमान 8-बिट पूर्ण पूर्णांक से काफी धीमा है।
- वर्तमान में यह मौजूदा हार्डवेयर त्वरित TFLite प्रतिनिधियों के साथ असंगत है।
इस परिमाणीकरण मोड के लिए एक ट्यूटोरियल यहां पाया जा सकता है।
मॉडल सटीकता
चूंकि प्रशिक्षण के बाद वजन की मात्रा निर्धारित की जाती है, इसलिए सटीकता में कमी हो सकती है, खासकर छोटे नेटवर्क के लिए। TensorFlow हब पर विशिष्ट नेटवर्क के लिए पूर्व-प्रशिक्षित पूर्णतः परिमाणित मॉडल प्रदान किए जाते हैं। यह सत्यापित करने के लिए कि सटीकता में कोई भी गिरावट स्वीकार्य सीमा के भीतर है, परिमाणित मॉडल की सटीकता की जांच करना महत्वपूर्ण है। TensorFlow Lite मॉडल सटीकता का मूल्यांकन करने के लिए उपकरण हैं।
वैकल्पिक रूप से, यदि सटीकता में गिरावट बहुत अधिक है, तो परिमाणीकरण जागरूक प्रशिक्षण का उपयोग करने पर विचार करें। हालाँकि, ऐसा करने के लिए नकली परिमाणीकरण नोड्स को जोड़ने के लिए मॉडल प्रशिक्षण के दौरान संशोधन की आवश्यकता होती है, जबकि इस पृष्ठ पर प्रशिक्षण के बाद परिमाणीकरण तकनीक मौजूदा पूर्व-प्रशिक्षित मॉडल का उपयोग करती है।
परिमाणित टेंसरों के लिए प्रतिनिधित्व
8-बिट परिमाणीकरण निम्न सूत्र का उपयोग करके फ़्लोटिंग पॉइंट मानों का अनुमान लगाता है।
\[real\_value = (int8\_value - zero\_point) \times scale\]
प्रतिनिधित्व के दो मुख्य भाग हैं:
प्रति-अक्ष (उर्फ प्रति-चैनल) या प्रति-टेंसर भार को 0 के बराबर शून्य-बिंदु के साथ [-127, 127] सीमा में int8 दो के पूरक मूल्यों द्वारा दर्शाया जाता है।
प्रति-टेंसर सक्रियण/इनपुट को सीमा [-128, 127] में int8 दो के पूरक मानों द्वारा दर्शाया जाता है, सीमा में शून्य-बिंदु के साथ [-128, 127]।
हमारी परिमाणीकरण योजना के विस्तृत दृश्य के लिए, कृपया हमारा परिमाणीकरण विवरण देखें। हार्डवेयर विक्रेता जो TensorFlow Lite के प्रतिनिधि इंटरफ़ेस में प्लग इन करना चाहते हैं, उन्हें वहां वर्णित परिमाणीकरण योजना को लागू करने के लिए प्रोत्साहित किया जाता है।