
یادگیری ساختیافته عصبی (NSL) بر آموزش شبکههای عصبی عمیق با استفاده از سیگنالهای ساختاریافته (در صورت وجود) همراه با ورودیهای ویژگی تمرکز دارد. همانطور که بوئی و همکاران معرفی کردند. (WSDM'18) ، از این سیگنالهای ساختاریافته برای منظم کردن آموزش شبکه عصبی استفاده میشود، و مدل را مجبور میکند تا پیشبینیهای دقیق (با به حداقل رساندن تلفات نظارتشده) را بیاموزد، در عین حال شباهت ساختاری ورودی (با به حداقل رساندن تلفات همسایه) حفظ شود. ، شکل زیر را ببینید). این تکنیک عمومی است و میتواند در معماریهای عصبی دلخواه (مانند NNهای پیشخور، NNهای Convolutional و NNهای بازگشتی) اعمال شود.
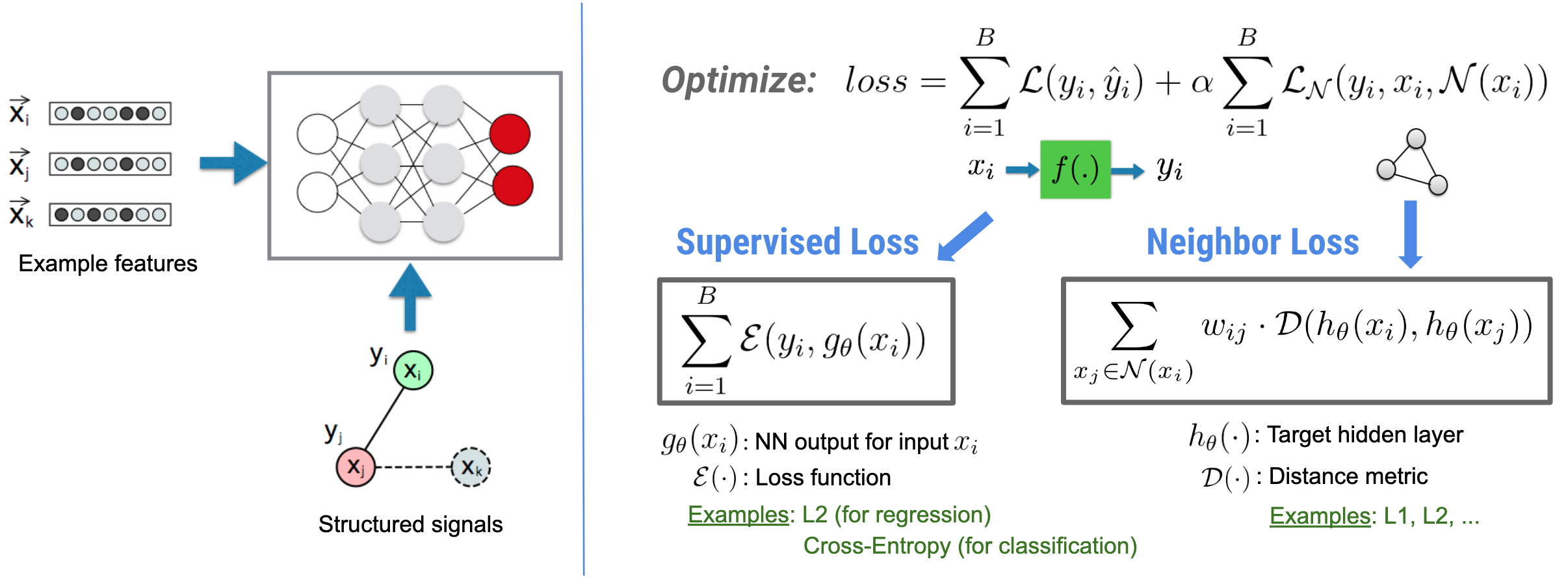
توجه داشته باشید که معادله از دست دادن همسایه تعمیمیافته انعطافپذیر است و میتواند شکلهای دیگری غیر از آنچه در بالا نشان داده شده باشد. برای مثال، ما همچنین میتوانیم\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) به عنوان ضرر همسایه انتخاب کنیم، که فاصله بین حقیقت زمین \(y_i\)و پیشبینی همسایه \(g_\theta(x_j)\)را محاسبه میکند. این معمولاً در یادگیری خصمانه استفاده می شود (Goodfellow et al., ICLR'15) . بنابراین، NSL به یادگیری نمودار عصبی تعمیم مییابد اگر همسایهها به طور صریح با یک نمودار نشان داده شوند، و اگر همسایهها به طور ضمنی توسط اغتشاش خصمانه القا شوند، به یادگیری مخالف تعمیم مییابد.
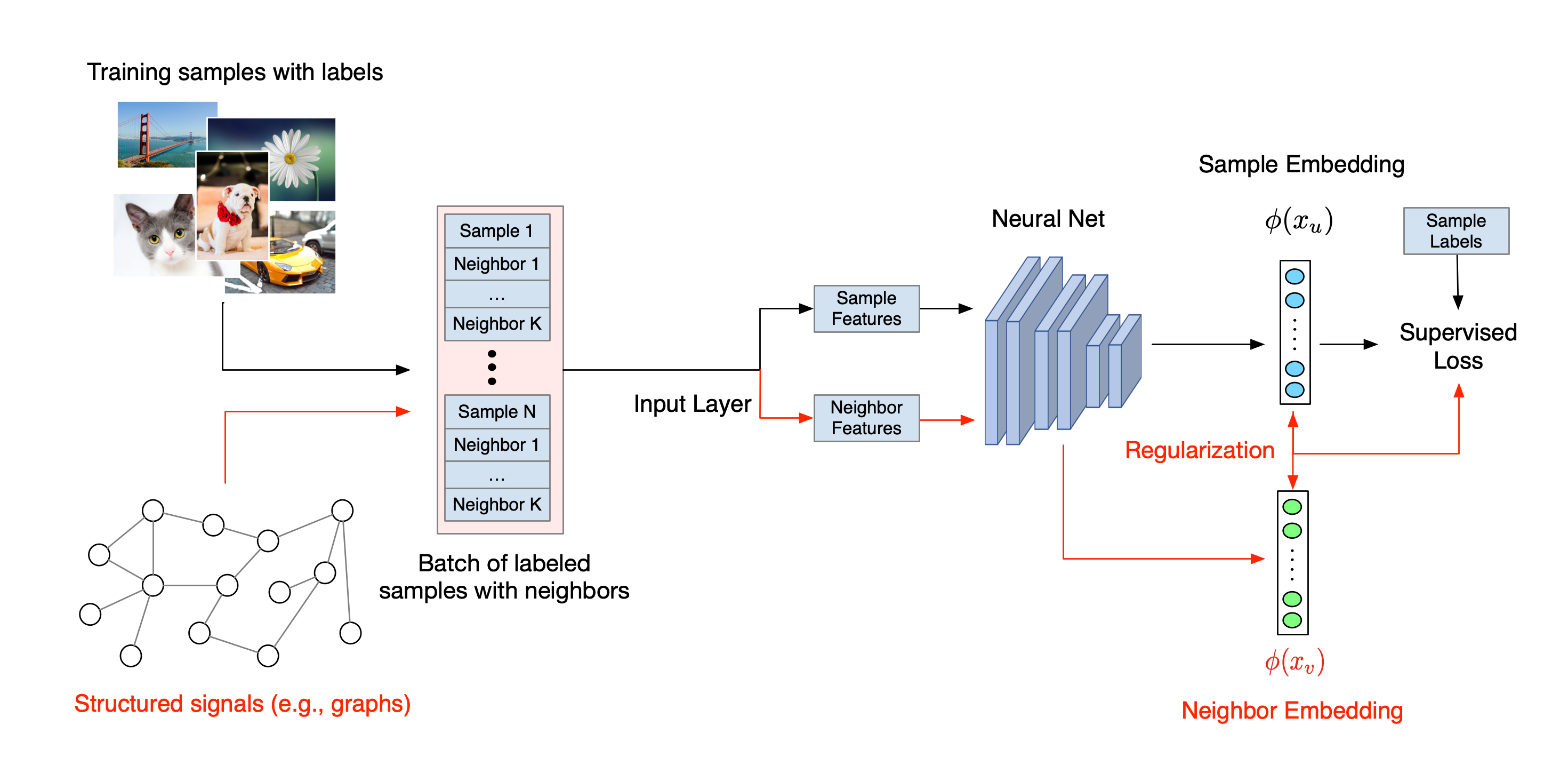
گردش کار کلی برای یادگیری ساختاریافته عصبی در زیر نشان داده شده است. فلشهای سیاه نشاندهنده گردش کار آموزشی معمولی و فلشهای قرمز نشاندهنده گردش کار جدید است که توسط NSL برای استفاده از سیگنالهای ساختاریافته معرفی شده است. ابتدا، نمونههای آموزشی برای گنجاندن سیگنالهای ساختیافته تکمیل میشوند. هنگامی که سیگنال های ساخت یافته به طور صریح ارائه نمی شوند، می توان آنها را ساخت یا القا کرد (این مورد برای یادگیری متخاصم کاربرد دارد). سپس، نمونههای آموزشی تقویتشده (شامل نمونههای اصلی و همسایههای متناظر آنها) برای محاسبه تعبیههای آنها به شبکه عصبی تغذیه میشوند. فاصله بین جاسازی یک نمونه و جاسازی همسایه آن محاسبه و به عنوان ضرر همسایه استفاده می شود که به عنوان یک اصطلاح منظم در نظر گرفته می شود و به ضرر نهایی اضافه می شود. برای نظمدهی صریح مبتنی بر همسایه، ما معمولاً از دست دادن همسایه را به عنوان فاصله بین جاسازی نمونه و جاسازی همسایه محاسبه میکنیم. با این حال، هر لایه از شبکه عصبی ممکن است برای محاسبه از دست دادن همسایه استفاده شود. از سوی دیگر، برای منظمسازی مبتنی بر همسایه القایی (تضاد)، از دست دادن همسایه را به عنوان فاصله بین پیشبینی خروجی همسایه خصمانه القایی و برچسب حقیقت زمین محاسبه میکنیم.
چرا از NSL استفاده کنیم؟
NSL مزایای زیر را به همراه دارد:
- دقت بالاتر : سیگنال(های) ساختار یافته در بین نمونه ها می تواند اطلاعاتی را ارائه دهد که همیشه در ورودی های ویژگی موجود نیست. بنابراین، نشان داده شده است که رویکرد آموزشی مشترک (هم با سیگنالها و هم ویژگیهای ساختاریافته) از بسیاری از روشهای موجود (که فقط به آموزش با ویژگیها متکی هستند) در طیف گستردهای از وظایف، مانند طبقهبندی اسناد و طبقهبندی هدف معنایی، بهتر عمل میکند ( Bui et al. .، WSDM'18 & Kipf و همکاران، ICLR'17 ).
- استحکام : نشان داده شده است که مدلهایی که با نمونههای متخاصم آموزش داده شدهاند در برابر اغتشاشات متخاصم که برای گمراهکردن پیشبینی یا طبقهبندی یک مدل طراحی شدهاند، مقاوم هستند ( Godfellow و همکاران، ICLR'15 & Miyato و همکاران، ICLR'16 ). هنگامی که تعداد نمونه های آموزشی کم است، آموزش با مثال های متضاد نیز به بهبود دقت مدل کمک می کند ( سیپراس و همکاران، ICLR'19 ).
- دادههای برچسبدار کمتر مورد نیاز : NSL شبکههای عصبی را قادر میسازد تا از دادههای برچسبدار و بدون برچسب استفاده کنند، که الگوی یادگیری را به یادگیری نیمهنظارتی گسترش میدهد. به طور خاص، NSL به شبکه اجازه میدهد تا با استفاده از دادههای برچسبگذاریشده مانند تنظیمات نظارتشده آموزش ببیند و در عین حال شبکه را به یادگیری نمایشهای پنهان مشابه برای «نمونههای همسایه» که ممکن است دارای برچسب باشند یا نداشته باشند سوق میدهد. این تکنیک نوید بزرگی را برای بهبود دقت مدل در زمانی که مقدار دادههای برچسبگذاری شده نسبتاً کم است، نشان داده است ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
آموزش های گام به گام
برای به دست آوردن تجربه عملی با یادگیری ساختاریافته عصبی، ما آموزش هایی داریم که سناریوهای مختلفی را پوشش می دهد که در آن سیگنال های ساختار یافته ممکن است به صراحت داده شوند، ساخته شوند یا القا شوند. اینجا چندتایی هستند:
تنظیم نمودار برای طبقه بندی اسناد با استفاده از نمودارهای طبیعی . در این آموزش، استفاده از منظمسازی گراف را برای طبقهبندی اسنادی که یک نمودار طبیعی (ارگانیک) تشکیل میدهند، بررسی میکنیم.
منظمسازی نمودار برای طبقهبندی احساسات با استفاده از نمودارهای سنتز شده . در این آموزش، ما استفاده از منظمسازی گراف را برای طبقهبندی احساسات مرور فیلم با ساخت (ترکیب) سیگنالهای ساختاریافته نشان میدهیم.
یادگیری خصمانه برای طبقه بندی تصاویر در این آموزش، استفاده از یادگیری خصمانه (جایی که سیگنال های ساختاریافته القا می شوند) برای طبقه بندی تصاویر حاوی ارقام عددی را بررسی می کنیم.
نمونهها و آموزشهای بیشتر را میتوانید در فهرست نمونههای مخزن GitHub ما پیدا کنید.