
| | |  Ver fuente en GitHub Ver fuente en GitHub | | |
Descripción general
Este clasifica portátiles de películas críticas como positivas o negativas utilizando el texto de la revisión. Este es un ejemplo de clasificación binaria, un importante y ampliamente aplicable tipo de problema de aprendizaje automático.
Demostraremos el uso de la regularización de gráficos en este cuaderno construyendo un gráfico a partir de la entrada dada. La receta general para construir un modelo de gráfico regularizado utilizando el marco de aprendizaje estructurado neuronal (NSL) cuando la entrada no contiene un gráfico explícito es la siguiente:
- Cree incrustaciones para cada muestra de texto en la entrada. Esto se puede hacer utilizando modelos pre-formados como word2vec , giratorio , BERT etc.
- Construya un gráfico basado en estas incrustaciones usando una métrica de similitud como la distancia 'L2', la distancia 'coseno', etc. Los nodos en el gráfico corresponden a muestras y los bordes en el gráfico corresponden a similitudes entre pares de muestras.
- Genere datos de entrenamiento a partir del gráfico sintetizado y las funciones de muestra anteriores. Los datos de entrenamiento resultantes contendrán características vecinas además de las características originales del nodo.
- Cree una red neuronal como modelo base utilizando la API secuencial, funcional o de subclase de Keras.
- Envuelva el modelo base con la clase contenedora GraphRegularization, que es proporcionada por el marco NSL, para crear un nuevo modelo gráfico de Keras. Este nuevo modelo incluirá un gráfico de pérdida de regularización como término de regularización en su objetivo de entrenamiento.
- Entrenar y evaluar el modelo gráfico de Keras.
Requisitos
- Instale el paquete Neural Structured Learning.
- Instale tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Dependencias e importaciones
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Conjunto de datos de IMDB
El conjunto de datos IMDB contiene el texto de 50.000 reseñas de películas de la Internet Movie Database . Estos se dividen en 25,000 revisiones para capacitación y 25,000 revisiones para pruebas. Las prácticas y pruebas conjuntos están equilibrados, lo que significa que contienen el mismo número de críticas positivas y negativas.
En este tutorial, usaremos una versión preprocesada del conjunto de datos IMDB.
Descargar el conjunto de datos de IMDB preprocesado
El conjunto de datos de IMDB viene empaquetado con TensorFlow. Ya ha sido preprocesado de tal manera que las reseñas (secuencias de palabras) se han convertido en secuencias de números enteros, donde cada número entero representa una palabra específica en un diccionario.
El siguiente código descarga el conjunto de datos de IMDB (o usa una copia en caché si ya se ha descargado):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
El argumento num_words=10000 mantiene los mejores 10.000 palabras que aparecen con más frecuencia en los datos de entrenamiento. Las palabras raras se descartan para mantener el tamaño del vocabulario manejable.
Explore los datos
Dediquemos un momento a comprender el formato de los datos. El conjunto de datos viene preprocesado: cada ejemplo es una matriz de números enteros que representan las palabras de la reseña de la película. Cada etiqueta es un valor entero de 0 o 1, donde 0 es una revisión negativa y 1 es una revisión positiva.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
El texto de las reseñas se ha convertido a números enteros, donde cada número entero representa una palabra específica en un diccionario. Así es como se ve la primera revisión:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Las reseñas de películas pueden tener diferentes duraciones. El siguiente código muestra la cantidad de palabras en la primera y segunda revisión. Dado que las entradas a una red neuronal deben tener la misma longitud, necesitaremos resolver esto más adelante.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Convierte los números enteros de nuevo en palabras
Puede resultar útil saber cómo convertir números enteros al texto correspondiente. Aquí, crearemos una función auxiliar para consultar un objeto de diccionario que contiene el mapeo de enteros a cadenas:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Ahora podemos usar el decode_review función para mostrar el texto de la primera revisión:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Construcción gráfica
La construcción de gráficos implica crear incrustaciones para muestras de texto y luego usar una función de similitud para comparar las incrustaciones.
Antes de continuar, primero creamos un directorio para almacenar los artefactos creados por este tutorial.
mkdir -p /tmp/imdb
Crear incrustaciones de muestra
Vamos a utilizar incrustaciones giratorios pretrained para crear inclusiones en el tf.train.Example formato para cada muestra en la entrada. Vamos a almacenar las inclusiones resultantes en el TFRecord formato junto con una característica adicional que representa el ID de cada muestra. Esto es importante y nos permitirá hacer coincidir las incrustaciones de muestra con los nodos correspondientes en el gráfico más adelante.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Construye una gráfica
Ahora que tenemos las incrustaciones de muestra, las usaremos para construir un gráfico de similitud, es decir, los nodos en este gráfico corresponderán a las muestras y los bordes en este gráfico corresponderán a la similitud entre pares de nodos.
El aprendizaje estructurado neuronal proporciona una biblioteca de creación de gráficos para crear un gráfico basado en incrustaciones de muestra. Utiliza similitud del coseno como la medida de similitud para comparar las incrustaciones y bordes de construcción entre ellos. También nos permite especificar un umbral de similitud, que se puede utilizar para descartar bordes diferentes del gráfico final. En este ejemplo, usando 0,99 como umbral de similitud y 12345 como semilla aleatoria, terminamos con un gráfico que tiene 429,415 bordes bidireccionales. Aquí estamos usando el apoyo del constructor gráfico de la localidad sensible hash (LSH) para acelerar la construcción de gráficos. Para más detalles sobre el uso de apoyo LSH del constructor gráfico, consulte la build_graph_from_config documentación de la API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Cada borde bidireccional está representado por dos bordes dirigidos en el archivo TSV de salida, de modo que ese archivo contiene 429,415 * 2 = 858,830 líneas en total:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Características de muestra
Creamos características de la muestra para nuestro problema con el tf.train.Example formato y ellos persisten en el TFRecord formato. Cada muestra incluirá las siguientes tres características:
- id: El ID de nodo de la muestra.
- palabras: Una lista de Int64 que contiene los ID de palabras.
- etiqueta: A singleton Int64 la identificación de la clase objetivo de la revisión.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Aumente los datos de entrenamiento con vecinos del gráfico
Dado que tenemos las características de muestra y el gráfico sintetizado, podemos generar los datos de entrenamiento aumentados para el aprendizaje estructurado neuronal. El marco NSL proporciona una biblioteca para combinar el gráfico y las características de muestra para producir los datos de entrenamiento finales para la regularización del gráfico. Los datos de entrenamiento resultantes incluirán características de muestra originales, así como características de sus vecinos correspondientes.
En este tutorial, consideramos los bordes no dirigidos y usamos un máximo de 3 vecinos por muestra para aumentar los datos de entrenamiento con los vecinos del gráfico.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Modelo base
Ahora estamos listos para construir un modelo base sin regularización de gráficos. Para construir este modelo, podemos usar incrustaciones que se usaron para construir el gráfico, o podemos aprender nuevas incrustaciones junto con la tarea de clasificación. Para el propósito de este cuaderno, haremos lo último.
Variables globales
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Hiperparámetros
Vamos a utilizar una instancia de HParams a inclue diversos hiperparámetros y constantes utilizadas para la formación y evaluación. A continuación, describimos brevemente cada uno de ellos:
num_classes: Hay 2 clases - positivo y negativo.
max_seq_length: Este es el número máximo de palabras consideradas de cada reseña de la película en este ejemplo.
vocab_size: Este es el tamaño del vocabulario considerado para este ejemplo.
distance_type: Esta es la distancia métrica utilizada para regularizar la muestra con sus vecinos.
graph_regularization_multiplier: Esto controla el peso relativo de la expresión gráfica de regularización en la función general de pérdida.
num_neighbors: El número de vecinos usados para la regularización gráfico. Este valor tiene que ser menor o igual a la
max_nbrsargumento utilizado anteriormente cuando se invocansl.tools.pack_nbrs.num_fc_units: El número de unidades en la capa completamente conectada de la red neuronal.
train_epochs: El número de épocas de formación.
El tamaño del lote utilizado para la formación y evaluación: batch_size.
eval_steps: El número de lotes a proceso antes considerando la evaluación es completa. Si se establece en
None, se evalúan todas las instancias en el conjunto de prueba.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Prepara los datos
Las revisiones, las matrices de números enteros, deben convertirse en tensores antes de introducirse en la red neuronal. Esta conversión se puede realizar de dos formas:
Convertir las matrices en vectores de
0s y1s indican ocurrencia palabra, similar a un uno en caliente de codificación. Por ejemplo, la secuencia[3, 5]se convertiría en un10000vector dimensional que es todo ceros excepto para los índices3y5, que son queridos. A continuación, hacer de esta la primera capa en nuestra red, unaDensecapa que puede manejar datos de punto flotante vector. Este enfoque requiere mucha memoria, sin embargo, requiere unnum_words * num_reviewsmatriz de tamaño.Alternativamente, podemos almohadilla de las matrices de manera que todos ellos tienen la misma longitud, a continuación, crear un tensor número entero de forma
max_length * num_reviews. Podemos usar una capa de incrustación capaz de manejar esta forma como la primera capa en nuestra red.
En este tutorial, usaremos el segundo enfoque.
Desde las críticas de películas deben tener la misma longitud, vamos a utilizar el pad_sequence función definida a continuación para estandarizar las longitudes.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Construye el modelo
Una red neuronal se crea apilando capas; esto requiere dos decisiones arquitectónicas principales:
- ¿Cuántas capas usar en el modelo?
- ¿Cuántas unidades ocultas a utilizar para cada capa?
En este ejemplo, los datos de entrada consisten en una matriz de índices de palabras. Las etiquetas para predecir son 0 o 1.
Usaremos un LSTM bidireccional como nuestro modelo base en este tutorial.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Las capas se apilan secuencialmente de manera efectiva para construir el clasificador:
- La primera capa es una
Inputcapa que lleva el vocabulario entero-codificado. - La siguiente capa es una
Embeddingcapa, que toma el vocabulario y la apariencia número entero codificado el vector de inclusión para cada palabra-index. Estos vectores se aprenden a medida que se entrena el modelo. Los vectores agregan una dimensión a la matriz de salida. Las dimensiones resultantes son:(batch, sequence, embedding). - A continuación, una capa LSTM bidireccional devuelve un vector de salida de longitud fija para cada ejemplo.
- Este vector de salida de longitud fija se canaliza a través de un plenamente conectado (
Densecapa) con 64 unidades ocultas. - La última capa está densamente conectada con un solo nodo de salida. Uso de la
sigmoidfunción de activación, este valor es un flotador entre 0 y 1, representando una probabilidad, o nivel de confianza.
Unidades ocultas
El modelo anterior tiene dos capas intermedias o "ocultos", entre la entrada y la salida, y con exclusión de la Embedding capa. El número de salidas (unidades, nodos o neuronas) es la dimensión del espacio de representación de la capa. En otras palabras, la cantidad de libertad que se le permite a la red cuando aprende una representación interna.
Si un modelo tiene más unidades ocultas (un espacio de representación de mayor dimensión) y / o más capas, entonces la red puede aprender representaciones más complejas. Sin embargo, hace que la red sea más costosa desde el punto de vista computacional y puede conducir al aprendizaje de patrones no deseados, patrones que mejoran el rendimiento en los datos de entrenamiento pero no en los datos de prueba. Esto se llama sobreajuste.
Función de pérdida y optimizador
Un modelo necesita una función de pérdida y un optimizador para el entrenamiento. Dado que este es un problema de clasificación binaria y el modelo de salidas una probabilidad (una capa de una sola unidad con una activación sigmoide), usaremos el binary_crossentropy función de pérdida.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Crea un conjunto de validación
Al entrenar, queremos verificar la precisión del modelo en datos que no ha visto antes. Crear un conjunto de validación estableciendo además una fracción de los datos de entrenamiento originales. (¿Por qué no usar el conjunto de pruebas ahora? Nuestro objetivo es desarrollar y ajustar nuestro modelo utilizando solo los datos de entrenamiento, luego usar los datos de prueba solo una vez para evaluar nuestra precisión).
En este tutorial, tomamos aproximadamente el 10% de las muestras de entrenamiento inicial (10% de 25000) como datos etiquetados para entrenamiento y el resto como datos de validación. Dado que la división inicial de tren / prueba fue 50/50 (25000 muestras cada una), la división efectiva de tren / validación / prueba que tenemos ahora es 5/45/50.
Tenga en cuenta que 'train_dataset' ya se ha agrupado y barajado.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Entrena el modelo
Entrene el modelo en mini lotes. Durante el entrenamiento, supervise la pérdida y la precisión del modelo en el conjunto de validación:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Evaluar el modelo
Ahora, veamos cómo funciona el modelo. Se devolverán dos valores. Pérdida (un número que representa nuestro error, los valores más bajos son mejores) y precisión.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Cree un gráfico de precisión / pérdida a lo largo del tiempo
model.fit() devuelve una History objeto que contiene un diccionario con todo lo que pasó durante el entrenamiento:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Hay cuatro entradas: una para cada métrica supervisada durante el entrenamiento y la validación. Podemos utilizarlos para trazar la pérdida de entrenamiento y validación para comparar, así como la precisión de entrenamiento y validación:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
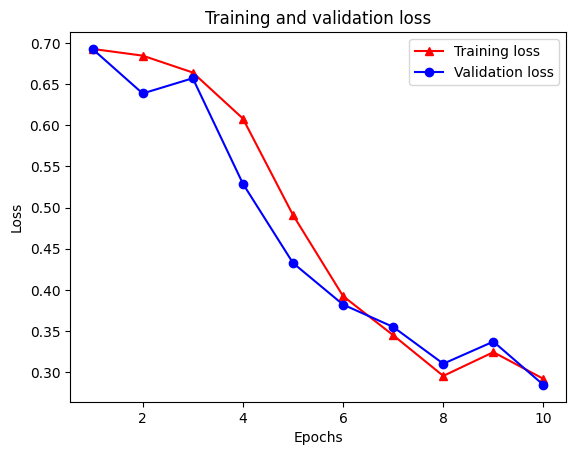
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
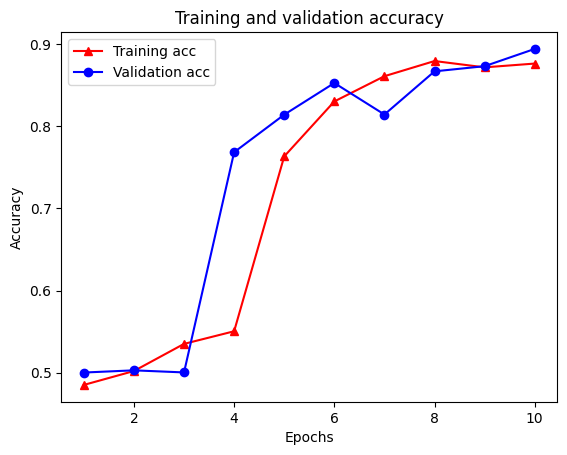
Tenga en cuenta la pérdida de entrenamiento disminuye con cada época y la exactitud de formación aumenta con cada época. Esto se espera cuando se usa una optimización de descenso de gradiente; debe minimizar la cantidad deseada en cada iteración.
Regularización de grafos
Ahora estamos listos para probar la regularización de gráficos utilizando el modelo base que construimos anteriormente. Vamos a utilizar el GraphRegularization clase de contenedor proporcionado por el marco de aprendizaje Neural estructurado para envolver el modelo base (bi-LSTM) para incluir regularización gráfico. El resto de los pasos para entrenar y evaluar el modelo de gráfico regularizado son similares a los del modelo base.
Crear modelo de gráfico regularizado
Para evaluar el beneficio incremental de la regularización de gráficos, crearemos una nueva instancia de modelo base. Esto se debe a que model ya se ha entrenado durante unas pocas iteraciones, y la reutilización de este modelo entrenado para crear un modelo gráfico-regularizado no será una comparación justa de model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Entrena el modelo
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Evaluar el modelo
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Cree un gráfico de precisión / pérdida a lo largo del tiempo
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
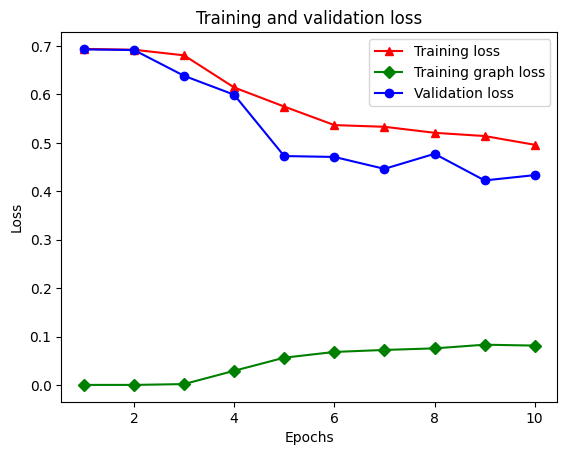
Hay cinco entradas en total en el diccionario: pérdida de entrenamiento, precisión de entrenamiento, pérdida de gráfico de entrenamiento, pérdida de validación y precisión de validación. Podemos trazarlos todos juntos para compararlos. Tenga en cuenta que la pérdida del gráfico solo se calcula durante el entrenamiento.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
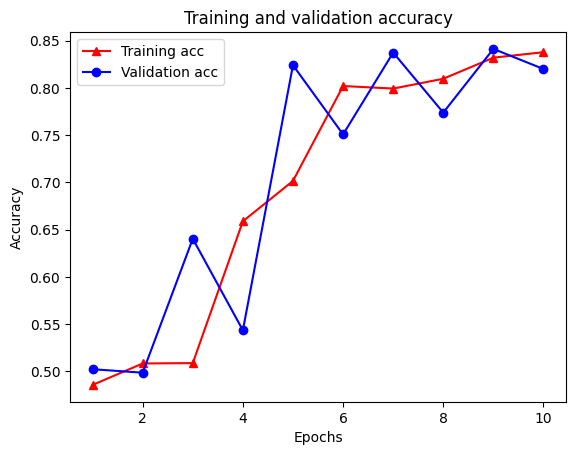
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
El poder del aprendizaje semi-supervisado
El aprendizaje semi-supervisado y, más específicamente, la regularización de gráficos en el contexto de este tutorial, puede ser realmente poderoso cuando la cantidad de datos de entrenamiento es pequeña. La falta de datos de entrenamiento se compensa aprovechando la similitud entre las muestras de entrenamiento, lo que no es posible en el aprendizaje supervisado tradicional.
Definimos relación de supervisión como la relación entre la formación de muestras con el número total de muestras que incluye entrenamiento, validación y muestras de ensayo. En este cuaderno, hemos utilizado un índice de supervisión de 0.05 (es decir, 5% de los datos etiquetados) para entrenar tanto el modelo base como el modelo regularizado por gráficos. Ilustramos el impacto del índice de supervisión en la precisión del modelo en la celda a continuación.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
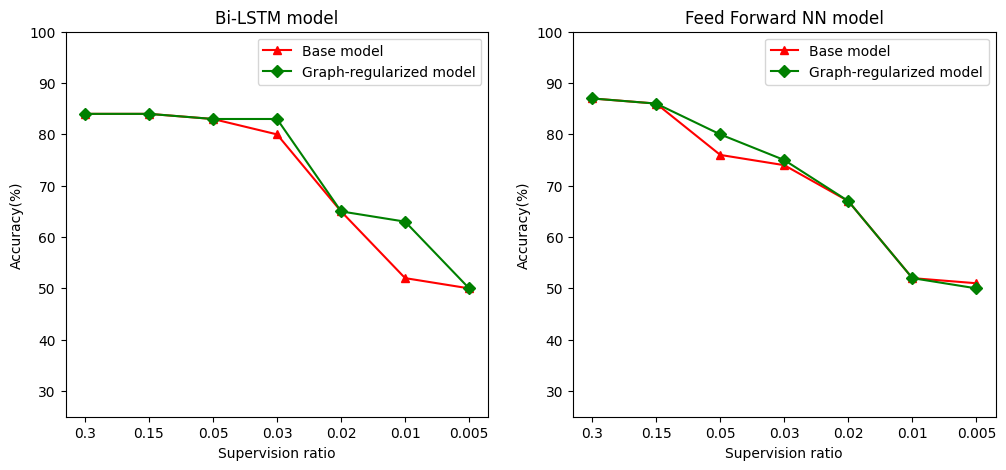
Se puede observar que a medida que disminuye la relación de superivisión, también disminuye la precisión del modelo. Esto es cierto tanto para el modelo base como para el modelo regularizado por gráficos, independientemente de la arquitectura del modelo utilizada. Sin embargo, observe que el modelo de gráfico regularizado funciona mejor que el modelo base para ambas arquitecturas. En particular, para el modelo Bi-LSTM, cuando la relación de supervisión es 0,01, la exactitud del modelo gráfico-regularizado es de ~ 20% mayor que la del modelo base. Esto se debe principalmente al aprendizaje semi-supervisado para el modelo de gráfico regularizado, donde la similitud estructural entre las muestras de entrenamiento se usa además de las muestras de entrenamiento en sí.
Conclusión
Hemos demostrado el uso de la regularización de gráficos utilizando el marco de aprendizaje estructurado neuronal (NSL) incluso cuando la entrada no contiene un gráfico explícito. Consideramos la tarea de clasificación de sentimientos de las reseñas de películas de IMDB para lo cual sintetizamos un gráfico de similitud basado en incrustaciones de reseñas. Alentamos a los usuarios a experimentar más variando los hiperparámetros, la cantidad de supervisión y utilizando diferentes arquitecturas de modelos.