
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Na featurization tutorial incorporamos várias características em nossos modelos, mas os modelos consistir em apenas uma camada de incorporação. Podemos adicionar camadas mais densas aos nossos modelos para aumentar seu poder expressivo.
Em geral, os modelos mais profundos são capazes de aprender padrões mais complexos do que os modelos mais superficiais. Por exemplo, o nosso modelo de usuário incorpora IDs de usuário e marcas de tempo para as preferências do usuário modelo em um ponto no tempo. Um modelo superficial (digamos, uma única camada de incorporação) pode ser capaz de aprender apenas as relações mais simples entre esses recursos e filmes: um determinado filme é mais popular na época de seu lançamento e um determinado usuário geralmente prefere filmes de terror a comédias. Para capturar relacionamentos mais complexos, como as preferências do usuário que evoluem ao longo do tempo, podemos precisar de um modelo mais profundo com várias camadas densas empilhadas.
Obviamente, os modelos complexos também têm suas desvantagens. O primeiro é o custo computacional, pois modelos maiores requerem mais memória e mais computação para se adequar e servir. O segundo é o requisito de mais dados: em geral, mais dados de treinamento são necessários para aproveitar os modelos mais profundos. Com mais parâmetros, os modelos profundos podem se ajustar demais ou simplesmente memorizar os exemplos de treinamento em vez de aprender uma função que pode generalizar. Finalmente, treinar modelos mais profundos pode ser mais difícil e mais cuidado deve ser tomado na escolha de configurações como regularização e taxa de aprendizagem.
Encontrar uma boa arquitetura de um sistema de recomendação no mundo real é uma arte complexa, exigindo boa intuição e cuidadoso ajuste hiperparâmetro . Por exemplo, fatores como profundidade e largura do modelo, função de ativação, taxa de aprendizado e otimizador podem mudar radicalmente o desempenho do modelo. As opções de modelagem são ainda mais complicadas pelo fato de que boas métricas de avaliação offline podem não corresponder a um bom desempenho online e que a escolha do que otimizar é frequentemente mais crítica do que a escolha do próprio modelo.
No entanto, o esforço investido na construção e no ajuste fino de modelos maiores geralmente compensa. Neste tutorial, ilustraremos como construir modelos de recuperação profunda usando os Recomendadores do TensorFlow. Faremos isso construindo modelos progressivamente mais complexos para ver como isso afeta o desempenho do modelo.
Preliminares
Primeiro importamos os pacotes necessários.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
Neste tutorial, vamos utilizar os modelos do tutorial featurization para gerar embeddings. Portanto, usaremos apenas os recursos de id do usuário, carimbo de data / hora e título do filme.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Também fazemos algumas tarefas domésticas para preparar vocabulários de recursos.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
Definição de modelo
Modelo de consulta
Começamos com o modelo definido pelo utilizador no tutorial featurization como a primeira camada do nosso modelo, a tarefa de conversão de exemplos de entrada em bruto em incorporações de recursos.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
Definir modelos mais profundos exigirá que empilhemos camadas de modo sobre essa primeira entrada. Uma pilha progressivamente mais estreita de camadas, separada por uma função de ativação, é um padrão comum:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
Uma vez que o poder expressivo dos modelos lineares profundos não é maior do que o dos modelos lineares superficiais, usamos as ativações ReLU para todas, exceto a última camada oculta. A camada oculta final não usa nenhuma função de ativação: usar uma função de ativação limitaria o espaço de saída dos embeddings finais e poderia impactar negativamente o desempenho do modelo. Por exemplo, se ReLUs forem usados na camada de projeção, todos os componentes na incorporação de saída não serão negativos.
Vamos tentar algo semelhante aqui. Para facilitar a experimentação com diferentes profundidades, vamos definir um modelo cuja profundidade (e largura) é definida por um conjunto de parâmetros do construtor.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
O layer_sizes parâmetro nos dá a profundidade e largura do modelo. Podemos variar para experimentar modelos mais superficiais ou mais profundos.
Modelo candidato
Podemos adotar a mesma abordagem para o modelo do filme. Mais uma vez, começamos com o MovieModel do featurization tutorial:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
E expanda-o com camadas ocultas:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
Modelo combinado
Com ambos QueryModel e CandidateModel definido, podemos montar um modelo combinado e implementar a nossa perda e métricas lógica. Para tornar as coisas simples, vamos impor que a estrutura do modelo seja a mesma em todos os modelos de consulta e candidatos.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
Treinando o modelo
Prepare os dados
Primeiro dividimos os dados em um conjunto de treinamento e um conjunto de teste.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
Modelo raso
Estamos prontos para experimentar nosso primeiro modelo raso!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
Isso nos dá uma precisão dos 100 melhores de cerca de 0,27. Podemos usar isso como um ponto de referência para avaliar modelos mais profundos.
Modelo mais profundo
Que tal um modelo mais profundo com duas camadas?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
A precisão aqui é 0,29, um pouco melhor do que o modelo raso.
Podemos traçar as curvas de precisão de validação para ilustrar isso:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
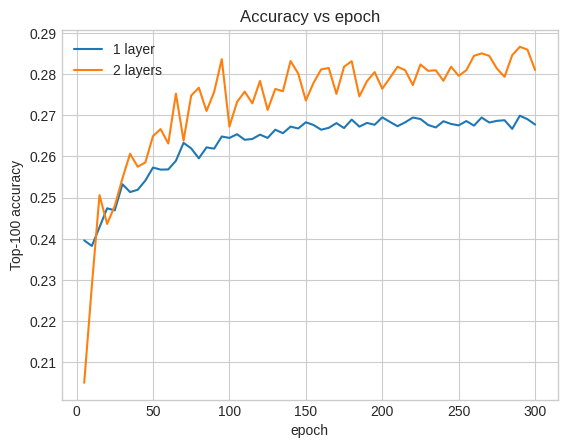
Mesmo no início do treinamento, o modelo maior tem uma liderança clara e estável sobre o modelo raso, sugerindo que adicionar profundidade ajuda o modelo a capturar relacionamentos mais matizados nos dados.
No entanto, modelos ainda mais profundos não são necessariamente melhores. O modelo a seguir estende a profundidade para três camadas:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
Na verdade, não vemos melhorias em relação ao modelo raso:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
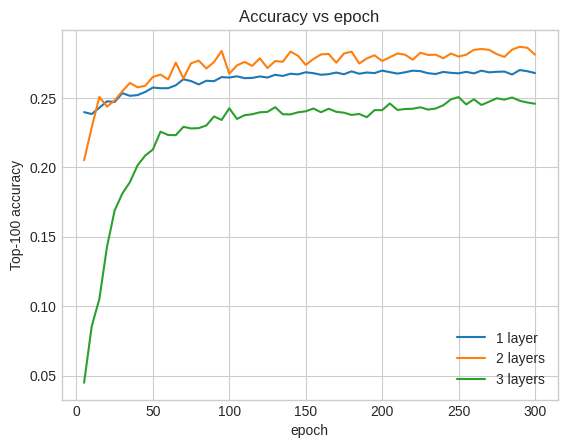
Esta é uma boa ilustração do fato de que modelos maiores e mais profundos, embora capazes de desempenho superior, geralmente requerem um ajuste muito cuidadoso. Por exemplo, ao longo deste tutorial, usamos uma única taxa de aprendizagem fixa. As escolhas alternativas podem dar resultados muito diferentes e vale a pena explorar.
Com o ajuste apropriado e dados suficientes, o esforço investido na construção de modelos maiores e mais profundos vale a pena em muitos casos: modelos maiores podem levar a melhorias substanciais na precisão da previsão.
Próximos passos
Neste tutorial, expandimos nosso modelo de recuperação com camadas densas e funções de ativação. Para ver como criar um modelo que pode realizar não apenas tarefas de recuperação, mas também tarefas de classificação, dê uma olhada no tutorial multitask .