
public enum _Raw-
Declaration
public enum _Raw.A -
Declaration
public enum _Raw.DataFormat -
Declaration
public enum _Raw.DataFormat1 -
Declaration
public enum _Raw.DataFormat5 -
Declaration
public enum _Raw.DensityUnit -
Declaration
public enum _Raw.Direction -
Declaration
public enum _Raw.Errors -
Declaration
public enum _Raw.FinalOp -
Declaration
public enum _Raw.Format -
Declaration
public enum _Raw.InputMode -
Declaration
public enum _Raw.InputQuantMode -
Declaration
public enum _Raw.LossType -
Declaration
public enum _Raw.MergeOp -
Declaration
public enum _Raw.Method -
Declaration
public enum _Raw.Method4 -
Declaration
public enum _Raw.Mode -
Declaration
public enum _Raw.Mode6 -
Declaration
public enum _Raw.OutputEncoding -
Declaration
public enum _Raw.Padding -
Declaration
public enum _Raw.Padding2 -
Declaration
public enum _Raw.Reduction -
Declaration
public enum _Raw.ReductionType -
Declaration
public enum _Raw.RnnMode -
Declaration
public enum _Raw.RoundMode -
Declaration
public enum _Raw.RoundMode7 -
Declaration
public enum _Raw.SplitType -
Declaration
public enum _Raw.SplitType2 -
Declaration
public enum _Raw.Unit -
Declaration
public static func a() -> Tensor<Float> -
Raise a exception to abort the process when called.
If exit_without_error is true, the process will exit normally, otherwise it will exit with a SIGABORT signal.
Returns nothing but an exception.
- Attr error_msg: A string which is the message associated with the exception.
Declaration
public static func abort( errorMsg: String, exitWithoutError: Bool = false ) -
Computes the absolute value of a tensor.
Given a tensor
x, this operation returns a tensor containing the absolute value of each element inx. For example, if x is an input element and y is an output element, this operation computes \(y = |x|\).Declaration
public static func abs<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Returns the element-wise sum of a list of tensors.
tf.accumulate_n_v2performs the same operation astf.add_n, but does not wait for all of its inputs to be ready before beginning to sum. This can save memory if inputs are ready at different times, since minimum temporary storage is proportional to the output size rather than the inputs size.Unlike the original
accumulate_n,accumulate_n_v2is differentiable.Returns a
Tensorof same shape and type as the elements ofinputs.Attr shape: Shape of elements of
inputs.
Declaration
public static func accumulateNV2<T: TensorFlowNumeric>( inputs: [Tensor<T>], shape: TensorShape? ) -> Tensor<T>Parameters
inputsA list of
Tensorobjects, each with same shape and type. -
Computes acos of x element-wise.
Declaration
public static func acos<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes inverse hyperbolic cosine of x element-wise.
Given an input tensor, the function computes inverse hyperbolic cosine of every element. Input range is
[1, inf]. It returnsnanif the input lies outside the range.x = tf.constant([-2, -0.5, 1, 1.2, 200, 10000, float("inf")]) tf.math.acosh(x) ==> [nan nan 0. 0.62236255 5.9914584 9.903487 inf]Declaration
public static func acosh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Returns x + y element-wise.
NOTE:
Addsupports broadcasting.AddNdoes not. More about broadcasting hereDeclaration
public static func add<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns x + y element-wise.
NOTE:
Addsupports broadcasting.AddNdoes not. More about broadcasting hereDeclaration
public static func add( _ x: StringTensor, _ y: StringTensor ) -> StringTensor -
Add an
N-minibatchSparseTensorto aSparseTensorsMap, returnNhandles.A
SparseTensorof rankRis represented by three tensors:sparse_indices,sparse_values, andsparse_shape, wheresparse_indices.shape[1] == sparse_shape.shape[0] == RAn
N-minibatch ofSparseTensorobjects is represented as aSparseTensorhaving a firstsparse_indicescolumn taking values between[0, N), where the minibatch sizeN == sparse_shape[0].The input
SparseTensormust have rankRgreater than 1, and the first dimension is treated as the minibatch dimension. Elements of theSparseTensormust be sorted in increasing order of this first dimension. The storedSparseTensorobjects pointed to by each row of the outputsparse_handleswill have rankR-1.The
SparseTensorvalues can then be read out as part of a minibatch by passing the given keys as vector elements toTakeManySparseFromTensorsMap. To ensure the correctSparseTensorsMapis accessed, ensure that the samecontainerandshared_nameare passed to that Op. If noshared_nameis provided here, instead use the name of the Operation created by callingAddManySparseToTensorsMapas theshared_namepassed toTakeManySparseFromTensorsMap. Ensure the Operations are colocated.Attrs:
- container: The container name for the
SparseTensorsMapcreated by this op. - shared_name: The shared name for the
SparseTensorsMapcreated by this op. If blank, the new Operation’s unique name is used.
- container: The container name for the
Output sparse_handles: 1-D. The handles of the
SparseTensornow stored in theSparseTensorsMap. Shape:[N].
Declaration
public static func addManySparseToTensorsMap<T: TensorFlowScalar>( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64>, container: String, sharedName: String ) -> Tensor<Int64>Parameters
sparse_indices2-D. The
indicesof the minibatchSparseTensor.sparse_indices[:, 0]must be ordered values in[0, N).sparse_values1-D. The
valuesof the minibatchSparseTensor.sparse_shape1-D. The
shapeof the minibatchSparseTensor. The minibatch sizeN == sparse_shape[0]. -
Add all input tensors element wise.
Inputs must be of same size and shape.
x = [9, 7, 10] tf.math.add_n(x) ==> 26Declaration
public static func addN<T: TensorFlowNumeric>( inputs: [Tensor<T>] ) -> Tensor<T> -
Add a
SparseTensorto aSparseTensorsMapreturn its handle.A
SparseTensoris represented by three tensors:sparse_indices,sparse_values, andsparse_shape.This operator takes the given
SparseTensorand adds it to a container object (aSparseTensorsMap). A unique key within this container is generated in the form of anint64, and this is the value that is returned.The
SparseTensorcan then be read out as part of a minibatch by passing the key as a vector element toTakeManySparseFromTensorsMap. To ensure the correctSparseTensorsMapis accessed, ensure that the samecontainerandshared_nameare passed to that Op. If noshared_nameis provided here, instead use the name of the Operation created by callingAddSparseToTensorsMapas theshared_namepassed toTakeManySparseFromTensorsMap. Ensure the Operations are colocated.Attrs:
- container: The container name for the
SparseTensorsMapcreated by this op. - shared_name: The shared name for the
SparseTensorsMapcreated by this op. If blank, the new Operation’s unique name is used.
- container: The container name for the
Output sparse_handle: 0-D. The handle of the
SparseTensornow stored in theSparseTensorsMap.
Declaration
public static func addSparseToTensorsMap<T: TensorFlowScalar>( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64>, container: String, sharedName: String ) -> Tensor<Int64>Parameters
sparse_indices2-D. The
indicesof theSparseTensor.sparse_values1-D. The
valuesof theSparseTensor.sparse_shape1-D. The
shapeof theSparseTensor. -
Returns x + y element-wise.
NOTE:
Addsupports broadcasting.AddNdoes not. More about broadcasting hereDeclaration
public static func addV2<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Adjust the contrast of one or more images.
imagesis a tensor of at least 3 dimensions. The last 3 dimensions are interpreted as[height, width, channels]. The other dimensions only represent a collection of images, such as[batch, height, width, channels].Contrast is adjusted independently for each channel of each image.
For each channel, the Op first computes the mean of the image pixels in the channel and then adjusts each component of each pixel to
(x - mean) * contrast_factor + mean.Output output: The contrast-adjusted image or images.
Declaration
public static func adjustContrastv2<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T>, contrastFactor: Tensor<Float> ) -> Tensor<T>Parameters
imagesImages to adjust. At least 3-D.
contrast_factorA float multiplier for adjusting contrast.
-
Adjust the hue of one or more images.
imagesis a tensor of at least 3 dimensions. The last dimension is interpretted as channels, and must be three.The input image is considered in the RGB colorspace. Conceptually, the RGB colors are first mapped into HSV. A delta is then applied all the hue values, and then remapped back to RGB colorspace.
Output output: The hue-adjusted image or images.
Declaration
public static func adjustHue<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T>, delta: Tensor<Float> ) -> Tensor<T>Parameters
imagesImages to adjust. At least 3-D.
deltaA float delta to add to the hue.
-
Adjust the saturation of one or more images.
imagesis a tensor of at least 3 dimensions. The last dimension is interpretted as channels, and must be three.The input image is considered in the RGB colorspace. Conceptually, the RGB colors are first mapped into HSV. A scale is then applied all the saturation values, and then remapped back to RGB colorspace.
Output output: The hue-adjusted image or images.
Declaration
public static func adjustSaturation<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T>, scale: Tensor<Float> ) -> Tensor<T>Parameters
imagesImages to adjust. At least 3-D.
scaleA float scale to add to the saturation.
-
Computes the “logical and” of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func all<Tidx: TensorFlowIndex>( _ input: Tensor<Bool>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<Bool>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to produce.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
An Op to exchange data across TPU replicas.
On each replica, the input is split into
split_countblocks alongsplit_dimensionand send to the other replicas given group_assignment. After receivingsplit_count- 1 blocks from other replicas, we concatenate the blocks alongconcat_dimensionas the output.For example, suppose there are 2 TPU replicas: replica 0 receives input:
[[A, B]]replica 1 receives input:[[C, D]]group_assignment=
[[0, 1]]concat_dimension=0 split_dimension=1 split_count=2replica 0’s output:
[[A], [C]]replica 1’s output:[[B], [D]]Attrs:
- T: The type of elements to be exchanged.
- concat_dimension: The dimension number to concatenate.
- split_dimension: The dimension number to split.
- split_count: The number of splits, this number must equal to the sub-group size(group_assignment.get_shape()[1])
Output output: The exchanged result.
Declaration
public static func allToAll<T: TensorFlowScalar>( _ input: Tensor<T>, groupAssignment: Tensor<Int32>, concatDimension: Int64, splitDimension: Int64, splitCount: Int64 ) -> Tensor<T>Parameters
inputThe local input to the sum.
group_assignmentAn int32 tensor with shape [num_groups, num_replicas_per_group].
group_assignment[i]represents the replica ids in the ith subgroup. -
Returns the argument of a complex number.
Given a tensor
inputof complex numbers, this operation returns a tensor of typefloatthat is the argument of each element ininput. All elements ininputmust be complex numbers of the form \(a + bj\), where a is the real part and b is the imaginary part.The argument returned by this operation is of the form \(atan2(b, a)\).
For example:
# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.angle(input) ==> [2.0132, 1.056]@compatibility(numpy) Equivalent to np.angle. @end_compatibility
Declaration
public static func angle< T: TensorFlowScalar, Tout: FloatingPoint & TensorFlowScalar >( _ input: Tensor<T> ) -> Tensor<Tout> -
A container for an iterator resource.
- Output handle: A handle to the iterator that can be passed to a “MakeIterator” or “IteratorGetNext” op. In contrast to Iterator, AnonymousIterator prevents resource sharing by name, and does not keep a reference to the resource container.
Declaration
public static func anonymousIterator( outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandle -
A container for an iterator resource.
- Outputs:
- handle: A handle to the iterator that can be passed to a “MakeIterator” or “IteratorGetNext” op. In contrast to Iterator, AnonymousIterator prevents resource sharing by name, and does not keep a reference to the resource container.
- deleter: A variant deleter that should be passed into the op that deletes the iterator.
Declaration
public static func anonymousIteratorV2( outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> (handle: ResourceHandle, deleter: VariantHandle) - Outputs:
-
Declaration
public static func anonymousMemoryCache() -> (handle: ResourceHandle, deleter: VariantHandle) -
A container for a multi device iterator resource.
- Outputs:
- handle: A handle to a multi device iterator that can be passed to a “MultiDeviceIteratorGetNextFromShard” op. In contrast to MultiDeviceIterator, AnonymousIterator prevents resource sharing by name, and does not keep a reference to the resource container.
- deleter: A variant deleter that should be passed into the op that deletes the iterator.
Declaration
public static func anonymousMultiDeviceIterator( devices: [String], outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> (handle: ResourceHandle, deleter: VariantHandle) - Outputs:
-
Declaration
public static func anonymousRandomSeedGenerator( seed: Tensor<Int64>, seed2: Tensor<Int64> ) -> (handle: ResourceHandle, deleter: VariantHandle) -
Computes the “logical or” of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func any<Tidx: TensorFlowIndex>( _ input: Tensor<Bool>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<Bool>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Returns the truth value of abs(x-y) < tolerance element-wise.
Declaration
public static func approximateEqual<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T>, tolerance: Double = 1e-05 ) -> Tensor<Bool> -
Returns the index with the largest value across dimensions of a tensor.
Note that in case of ties the identity of the return value is not guaranteed.
Usage:
import tensorflow as tf a = [1, 10, 26.9, 2.8, 166.32, 62.3] b = tf.math.argmax(input = a) c = tf.keras.backend.eval(b) # c = 4 # here a[4] = 166.32 which is the largest element of a across axis 0Declaration
public static func argMax< T: TensorFlowNumeric, Tidx: TensorFlowIndex, OutputType: TensorFlowIndex >( _ input: Tensor<T>, dimension: Tensor<Tidx> ) -> Tensor<OutputType>Parameters
dimensionint32 or int64, must be in the range
[-rank(input), rank(input)). Describes which dimension of the input Tensor to reduce across. For vectors, use dimension = 0. -
Returns the index with the smallest value across dimensions of a tensor.
Note that in case of ties the identity of the return value is not guaranteed.
Usage:
import tensorflow as tf a = [1, 10, 26.9, 2.8, 166.32, 62.3] b = tf.math.argmin(input = a) c = tf.keras.backend.eval(b) # c = 0 # here a[0] = 1 which is the smallest element of a across axis 0Declaration
public static func argMin< T: TensorFlowNumeric, Tidx: TensorFlowIndex, OutputType: TensorFlowIndex >( _ input: Tensor<T>, dimension: Tensor<Tidx> ) -> Tensor<OutputType>Parameters
dimensionint32 or int64, must be in the range
[-rank(input), rank(input)). Describes which dimension of the input Tensor to reduce across. For vectors, use dimension = 0. -
Converts each entry in the given tensor to strings.
Supports many numeric types and boolean.
For Unicode, see the https://www.tensorflow.org/tutorials/representation/unicode tutorial.
- Attrs:
- precision: The post-decimal precision to use for floating point numbers. Only used if precision > -1.
- scientific: Use scientific notation for floating point numbers.
- shortest: Use shortest representation (either scientific or standard) for floating point numbers.
- width: Pad pre-decimal numbers to this width. Applies to both floating point and integer numbers. Only used if width > -1.
- fill: The value to pad if width > -1. If empty, pads with spaces. Another typical value is ‘0’. String cannot be longer than 1 character.
Declaration
public static func asString<T: TensorFlowScalar>( _ input: Tensor<T>, precision: Int64 = -1, scientific: Bool = false, shortest: Bool = false, width: Int64 = -1, fill: String ) -> StringTensor - Attrs:
-
Computes the trignometric inverse sine of x element-wise.
The
tf.math.asinoperation returns the inverse oftf.math.sin, such that ify = tf.math.sin(x)then,x = tf.math.asin(y).Note: The output of
tf.math.asinwill lie within the invertible range of sine, i.e [-pi/2, pi/2].For example:
# Note: [1.047, 0.785] ~= [(pi/3), (pi/4)] x = tf.constant([1.047, 0.785]) y = tf.math.sin(x) # [0.8659266, 0.7068252] tf.math.asin(y) # [1.047, 0.785] = xDeclaration
public static func asin<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes inverse hyperbolic sine of x element-wise.
Given an input tensor, this function computes inverse hyperbolic sine for every element in the tensor. Both input and output has a range of
[-inf, inf].x = tf.constant([-float("inf"), -2, -0.5, 1, 1.2, 200, 10000, float("inf")]) tf.math.asinh(x) ==> [-inf -1.4436355 -0.4812118 0.8813736 1.0159732 5.991471 9.903487 inf]Declaration
public static func asinh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Asserts that the given condition is true.
If
conditionevaluates to false, print the list of tensors indata.summarizedetermines how many entries of the tensors to print.Attr summarize: Print this many entries of each tensor.
Declaration
public static func assert<T: TensorArrayProtocol>( condition: Tensor<Bool>, data: T, summarize: Int64 = 3 )Parameters
conditionThe condition to evaluate.
dataThe tensors to print out when condition is false.
-
A transformation that asserts which transformations happen next.
This transformation checks whether the camel-case names (i.e. “FlatMap”, not “flat_map”) of the transformations following this transformation match the list of names in the
transformationsargument. If there is a mismatch, the transformation raises an exception.The check occurs when iterating over the contents of the dataset, which means that the check happens after any static optimizations are applied to the dataset graph.
Declaration
public static func assertNextDataset( inputDataset: VariantHandle, transformations: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
AssertNextDatasetpasses through the outputs of its input dataset.transformationsA
tf.stringvectortf.Tensoridentifying the transformations that are expected to happen next. -
Adds a value to the current value of a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to see the incremented value or a subsequent newer one.
Attr dtype: the dtype of the value.
Declaration
public static func assignAddVariableOp<Dtype: TensorFlowScalar>( resource: ResourceHandle, value: Tensor<Dtype> )Parameters
resourcehandle to the resource in which to store the variable.
valuethe value by which the variable will be incremented.
-
Subtracts a value from the current value of a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to see the decremented value or a subsequent newer one.
Attr dtype: the dtype of the value.
Declaration
public static func assignSubVariableOp<Dtype: TensorFlowScalar>( resource: ResourceHandle, value: Tensor<Dtype> )Parameters
resourcehandle to the resource in which to store the variable.
valuethe value by which the variable will be incremented.
-
Assigns a new value to a variable.
Any ReadVariableOp with a control dependency on this op is guaranteed to return this value or a subsequent newer value of the variable.
Attr dtype: the dtype of the value.
Declaration
public static func assignVariableOp<Dtype: TensorFlowScalar>( resource: ResourceHandle, value: Tensor<Dtype> )Parameters
resourcehandle to the resource in which to store the variable.
valuethe value to set the new tensor to use.
-
Computes the trignometric inverse tangent of x element-wise.
The
tf.math.atanoperation returns the inverse oftf.math.tan, such that ify = tf.math.tan(x)then,x = tf.math.atan(y).Note: The output of
tf.math.atanwill lie within the invertible range of tan, i.e (-pi/2, pi/2).For example:
# Note: [1.047, 0.785] ~= [(pi/3), (pi/4)] x = tf.constant([1.047, 0.785]) y = tf.math.tan(x) # [1.731261, 0.99920404] tf.math.atan(y) # [1.047, 0.785] = xDeclaration
public static func atan<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes arctangent of
y/xelement-wise, respecting signs of the arguments.This is the angle ( \theta \in [-\pi, \pi] ) such that [ x = r \cos(\theta) ] and [ y = r \sin(\theta) ] where (r = \sqrt(x^2 + y^2) ).
Declaration
public static func atan2<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Computes inverse hyperbolic tangent of x element-wise.
Given an input tensor, this function computes inverse hyperbolic tangent for every element in the tensor. Input range is
[-1,1]and output range is[-inf, inf]. If input is-1, output will be-infand if the input is1, output will beinf. Values outside the range will havenanas output.x = tf.constant([-float("inf"), -1, -0.5, 1, 0, 0.5, 10, float("inf")]) tf.math.atanh(x) ==> [nan -inf -0.54930615 inf 0. 0.54930615 nan nan]Declaration
public static func atanh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Declaration
public static func attr( _ a: Int64 ) -
Declaration
public static func attrBool( _ a: Bool ) -
Declaration
public static func attrBoolList( _ a: [Bool] ) -
Declaration
public static func attrDefault( _ a: String = "banana" ) -
Declaration
public static func attrEmptyListDefault( _ a: [Double] ) -
Declaration
public static func attrEnum( _ a: A ) -
Declaration
public static func attrEnumList( _ a: [String] ) -
Declaration
public static func attrFloat( _ a: Double ) -
Declaration
public static func attrListDefault( _ a: [Int32] = [5, 15] ) -
Declaration
public static func attrListMin( _ a: [Int32] ) -
Declaration
public static func attrListTypeDefault<T: TensorFlowScalar>( _ a: [Tensor<T>], _ b: [Tensor<T>] ) -
Declaration
public static func attrMin( _ a: Int64 ) -
Declaration
public static func attrPartialShape( _ a: TensorShape? ) -
Declaration
public static func attrPartialShapeList( _ a: [TensorShape?] ) -
Declaration
public static func attrShape( _ a: TensorShape? ) -
Declaration
public static func attrShapeList( _ a: [TensorShape?] ) -
Declaration
public static func attrTypeDefault<T: TensorFlowScalar>( _ a: Tensor<T> ) -
audioMicrofrontend(audio:sampleRate:windowSize:windowStep:numChannels:upperBandLimit:lowerBandLimit:smoothingBits:evenSmoothing:oddSmoothing:minSignalRemaining:enablePcan:pcanStrength:pcanOffset:gainBits:enableLog:scaleShift:leftContext:rightContext:frameStride:zeroPadding:outScale:)
Audio Microfrontend Op.
This Op converts a sequence of audio data into one or more feature vectors containing filterbanks of the input. The conversion process uses a lightweight library to perform:
- A slicing window function
- Short-time FFTs
- Filterbank calculations
- Noise reduction
- PCAN Auto Gain Control
- Logarithmic scaling
Arguments audio: 1D Tensor, int16 audio data in temporal ordering. sample_rate: Integer, the sample rate of the audio in Hz. window_size: Integer, length of desired time frames in ms. window_step: Integer, length of step size for the next frame in ms. num_channels: Integer, the number of filterbank channels to use. upper_band_limit: Float, the highest frequency included in the filterbanks. lower_band_limit: Float, the lowest frequency included in the filterbanks. smoothing_bits: Int, scale up signal by 2^(smoothing_bits) before reduction. even_smoothing: Float, smoothing coefficient for even-numbered channels. odd_smoothing: Float, smoothing coefficient for odd-numbered channels. min_signal_remaining: Float, fraction of signal to preserve in smoothing. enable_pcan: Bool, enable PCAN auto gain control. pcan_strength: Float, gain normalization exponent. pcan_offset: Float, positive value added in the normalization denominator. gain_bits: Int, number of fractional bits in the gain. enable_log: Bool, enable logarithmic scaling of filterbanks. scale_shift: Integer, scale filterbanks by 2^(scale_shift). left_context: Integer, number of preceding frames to attach to each frame. right_context: Integer, number of preceding frames to attach to each frame. frame_stride: Integer, M frames to skip over, where output[n] = frame[n*M]. zero_padding: Bool, if left/right context is out-of-bounds, attach frame of zeroes. Otherwise, frame[0] or frame[size-1] will be copied. out_scale: Integer, divide all filterbanks by this number. out_type: DType, type of the output Tensor, defaults to UINT16.
Returns filterbanks: 2D Tensor, each row is a time frame, each column is a channel.
Declaration
public static func audioMicrofrontend<OutType: TensorFlowNumeric>( audio: Tensor<Int16>, sampleRate: Int64 = 16000, windowSize: Int64 = 25, windowStep: Int64 = 10, numChannels: Int64 = 32, upperBandLimit: Double = 7500, lowerBandLimit: Double = 125, smoothingBits: Int64 = 10, evenSmoothing: Double = 0.025, oddSmoothing: Double = 0.06, minSignalRemaining: Double = 0.05, enablePcan: Bool = false, pcanStrength: Double = 0.95, pcanOffset: Double = 80, gainBits: Int64 = 21, enableLog: Bool = true, scaleShift: Int64 = 6, leftContext: Int64 = 0, rightContext: Int64 = 0, frameStride: Int64 = 1, zeroPadding: Bool = false, outScale: Int64 = 1 ) -> Tensor<OutType> -
Produces a visualization of audio data over time.
Spectrograms are a standard way of representing audio information as a series of slices of frequency information, one slice for each window of time. By joining these together into a sequence, they form a distinctive fingerprint of the sound over time.
This op expects to receive audio data as an input, stored as floats in the range -1 to 1, together with a window width in samples, and a stride specifying how far to move the window between slices. From this it generates a three dimensional output. The first dimension is for the channels in the input, so a stereo audio input would have two here for example. The second dimension is time, with successive frequency slices. The third dimension has an amplitude value for each frequency during that time slice.
This means the layout when converted and saved as an image is rotated 90 degrees clockwise from a typical spectrogram. Time is descending down the Y axis, and the frequency decreases from left to right.
Each value in the result represents the square root of the sum of the real and imaginary parts of an FFT on the current window of samples. In this way, the lowest dimension represents the power of each frequency in the current window, and adjacent windows are concatenated in the next dimension.
To get a more intuitive and visual look at what this operation does, you can run tensorflow/examples/wav_to_spectrogram to read in an audio file and save out the resulting spectrogram as a PNG image.
Attrs:
- window_size: How wide the input window is in samples. For the highest efficiency this should be a power of two, but other values are accepted.
- stride: How widely apart the center of adjacent sample windows should be.
- magnitude_squared: Whether to return the squared magnitude or just the magnitude. Using squared magnitude can avoid extra calculations.
Output spectrogram: 3D representation of the audio frequencies as an image.
Declaration
Parameters
inputFloat representation of audio data.
-
Outputs a
Summaryprotocol buffer with audio.The summary has up to
max_outputssummary values containing audio. The audio is built fromtensorwhich must be 3-D with shape[batch_size, frames, channels]or 2-D with shape[batch_size, frames]. The values are assumed to be in the range of[-1.0, 1.0]with a sample rate ofsample_rate.The
tagargument is a scalarTensorof typestring. It is used to build thetagof the summary values:- If
max_outputsis 1, the summary value tag is ‘tag/audio’. If
max_outputsis greater than 1, the summary value tags are generated sequentially as ‘tag/audio/0’, ‘tag/audio/1’, etc.Attrs:
- sample_rate: The sample rate of the signal in hertz.
- max_outputs: Max number of batch elements to generate audio for.
Output summary: Scalar. Serialized
Summaryprotocol buffer.
Declaration
public static func audioSummary( tag: StringTensor, _ tensor: Tensor<Float>, sampleRate: Double, maxOutputs: Int64 = 3 ) -> StringTensorParameters
tagScalar. Used to build the
tagattribute of the summary values.tensor2-D of shape
[batch_size, frames]. - If
-
Outputs a
Summaryprotocol buffer with audio.The summary has up to
max_outputssummary values containing audio. The audio is built fromtensorwhich must be 3-D with shape[batch_size, frames, channels]or 2-D with shape[batch_size, frames]. The values are assumed to be in the range of[-1.0, 1.0]with a sample rate ofsample_rate.The
tagargument is a scalarTensorof typestring. It is used to build thetagof the summary values:- If
max_outputsis 1, the summary value tag is ‘tag/audio’. If
max_outputsis greater than 1, the summary value tags are generated sequentially as ‘tag/audio/0’, ‘tag/audio/1’, etc.Attr max_outputs: Max number of batch elements to generate audio for.
Output summary: Scalar. Serialized
Summaryprotocol buffer.
Declaration
public static func audioSummaryV2( tag: StringTensor, _ tensor: Tensor<Float>, sampleRate: Tensor<Float>, maxOutputs: Int64 = 3 ) -> StringTensorParameters
tagScalar. Used to build the
tagattribute of the summary values.tensor2-D of shape
[batch_size, frames].sample_rateThe sample rate of the signal in hertz.
- If
-
Creates a dataset that shards the input dataset.
Creates a dataset that shards the input dataset by num_workers, returning a sharded dataset for the index-th worker. This attempts to automatically shard a dataset by examining the Dataset graph and inserting a shard op before the inputs to a reader Dataset (e.g. CSVDataset, TFRecordDataset).
This dataset will throw a NotFound error if we cannot shard the dataset automatically.
Declaration
public static func autoShardDataset( inputDataset: VariantHandle, numWorkers: Tensor<Int64>, index: Tensor<Int64>, autoShardPolicy: Int64 = 0, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
num_workersA scalar representing the number of workers to distribute this dataset across.
indexA scalar representing the index of the current worker out of num_workers.
-
Performs average pooling on the input.
Each entry in
outputis the mean of the corresponding sizeksizewindow invalue.Attrs:
- ksize: The size of the sliding window for each dimension of
value. - strides: The stride of the sliding window for each dimension of
value. - padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
- ksize: The size of the sliding window for each dimension of
Output output: The average pooled output tensor.
Declaration
public static func avgPool<T: FloatingPoint & TensorFlowScalar>( value: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
value4-D with shape
[batch, height, width, channels]. -
Performs 3D average pooling on the input.
Attrs:
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
ksize[0] = ksize[4] = 1. - strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
Output output: The average pooled output tensor.
Declaration
public static func avgPool3D<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc ) -> Tensor<T>Parameters
inputShape
[batch, depth, rows, cols, channels]tensor to pool over. -
Computes gradients of average pooling function.
Attrs:
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
ksize[0] = ksize[4] = 1. - strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
Output output: The backprop for input.
Declaration
public static func avgPool3DGrad<T: FloatingPoint & TensorFlowScalar>( origInputShape: Tensor<Int32>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc ) -> Tensor<T>Parameters
orig_input_shapeThe original input dimensions.
gradOutput backprop of shape
[batch, depth, rows, cols, channels]. -
Computes gradients of the average pooling function.
Attrs:
- ksize: The size of the sliding window for each dimension of the input.
- strides: The stride of the sliding window for each dimension of the input.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: 4-D. Gradients w.r.t. the input of
avg_pool.
Declaration
public static func avgPoolGrad<T: FloatingPoint & TensorFlowScalar>( origInputShape: Tensor<Int32>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
orig_input_shape1-D. Shape of the original input to
avg_pool.grad4-D with shape
[batch, height, width, channels]. Gradients w.r.t. the output ofavg_pool. -
Declaration
public static func b() -> Tensor<Float> -
batch(inTensors:numBatchThreads:maxBatchSize:maxEnqueuedBatches:batchTimeoutMicros:allowedBatchSizes:gradTimeoutMicros:container:sharedName:batchingQueue:)
Batches all input tensors nondeterministically.
When many instances of this Op are being run concurrently with the same container/shared_name in the same device, some will output zero-shaped Tensors and others will output Tensors of size up to max_batch_size.
All Tensors in in_tensors are batched together (so, for example, labels and features should be batched with a single instance of this operation.
Each invocation of batch emits an
idscalar which will be used to identify this particular invocation when doing unbatch or its gradient.Each op which emits a non-empty batch will also emit a non-empty batch_index Tensor, which, is a [K, 3] matrix where each row contains the invocation’s id, start, and length of elements of each set of Tensors present in batched_tensors.
Batched tensors are concatenated along the first dimension, and all tensors in in_tensors must have the first dimension of the same size.
in_tensors: The tensors to be batched. num_batch_threads: Number of scheduling threads for processing batches of work. Determines the number of batches processed in parallel. max_batch_size: Batch sizes will never be bigger than this. batch_timeout_micros: Maximum number of microseconds to wait before outputting an incomplete batch. allowed_batch_sizes: Optional list of allowed batch sizes. If left empty, does nothing. Otherwise, supplies a list of batch sizes, causing the op to pad batches up to one of those sizes. The entries must increase monotonically, and the final entry must equal max_batch_size. grad_timeout_micros: The timeout to use for the gradient. See Unbatch. batched_tensors: Either empty tensors or a batch of concatenated Tensors. batch_index: If out_tensors is non-empty, has information to invert it. container: Controls the scope of sharing of this batch. id: always contains a scalar with a unique ID for this invocation of Batch. shared_name: Concurrently running instances of batch in the same device with the same container and shared_name will batch their elements together. If left empty, the op name will be used as the shared name. T: the types of tensors to be batched.
Declaration
public static func batch<T: TensorArrayProtocol>( inTensors: T, numBatchThreads: Int64, maxBatchSize: Int64, maxEnqueuedBatches: Int64 = 10, batchTimeoutMicros: Int64, allowedBatchSizes: [Int32], gradTimeoutMicros: Int64, container: String, sharedName: String, batchingQueue: String ) -> (batchedTensors: T, batchIndex: Tensor<Int64>, id: Tensor<Int64>) -
Declaration
public static func batchCholesky<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchCholeskyGrad<T: FloatingPoint & TensorFlowScalar>( l: Tensor<T>, grad: Tensor<T> ) -> Tensor<T> -
Creates a dataset that batches
batch_sizeelements frominput_dataset.Declaration
public static func batchDataset( inputDataset: VariantHandle, batchSize: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
batch_sizeA scalar representing the number of elements to accumulate in a batch.
-
Creates a dataset that batches
batch_sizeelements frominput_dataset.Declaration
public static func batchDatasetV2( inputDataset: VariantHandle, batchSize: Tensor<Int64>, dropRemainder: Tensor<Bool>, parallelCopy: Bool = false, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
batch_sizeA scalar representing the number of elements to accumulate in a batch.
drop_remainderA scalar representing whether the last batch should be dropped in case its size is smaller than desired.
-
batchFunction(inTensors:capturedTensors:f:numBatchThreads:maxBatchSize:batchTimeoutMicros:maxEnqueuedBatches:allowedBatchSizes:container:sharedName:batchingQueue:)
Batches all the inputs tensors to the computation done by the function.
So, for example, in the following code
# This input will be captured. y = tf.placeholder_with_default(1.0, shape=[]) @tf.Defun(tf.float32) def computation(a): return tf.matmul(a, a) + y b = gen_batch_ops.batch_function( f=computation in_tensors=[a], captured_tensors=computation.captured_inputs, Tout=[o.type for o in computation.definition.signature.output_arg], num_batch_threads=1, max_batch_size=10, batch_timeout_micros=100000, # 100ms allowed_batch_sizes=[3, 10], batching_queue="") If more than one session.run call is simultaneously trying to compute `b` the values of `a` will be gathered, non-deterministically concatenated along the first axis, and only one thread will run the computation. Assumes that all arguments of the function are Tensors which will be batched along their first dimension. Arguments that are captured, are not batched. The session.run call which does the concatenation, will use the values of the captured tensors available to it. Therefore, typical uses of captured tensors should involve values which remain unchanged across session.run calls. Inference is a good example of this. SparseTensor is not supported. The return value of the decorated function must be a Tensor or a list/tuple of Tensors. - Parameters: - in_tensors: The tensors to be batched. - captured_tensors: The tensors which are captured in the function, and don't need to be batched. - Attrs: - num_batch_threads: Number of scheduling threads for processing batches of work. Determines the number of batches processed in parallel. - max_batch_size: Batch sizes will never be bigger than this. - batch_timeout_micros: Maximum number of microseconds to wait before outputting an incomplete batch. - max_enqueued_batches: Maximum number of batches enqueued. Default: 10. - allowed_batch_sizes: Optional list of allowed batch sizes. If left empty, does nothing. Otherwise, supplies a list of batch sizes, causing the op to pad batches up to one of those sizes. The entries must increase monotonically, and the final entry must equal max_batch_size. - container: Controls the scope of sharing of this batch. - shared_name: Concurrently running instances of batch in the same device with the same container and shared_name will batch their elements together. If left empty, the op name will be used as the shared name. - Tin: the types of tensors to be batched. - Tcaptured: the types of the captured tensors. - Tout: the types of the output tensors. - Output out_tensors: The output tensors.Declaration
public static func batchFunction< FIn: TensorGroup, FOut: TensorGroup, Tin: TensorArrayProtocol, Tcaptured: TensorArrayProtocol, Tout: TensorGroup >( inTensors: Tin, capturedTensors: Tcaptured, f: (FIn) -> FOut, numBatchThreads: Int64, maxBatchSize: Int64, batchTimeoutMicros: Int64, maxEnqueuedBatches: Int64 = 10, allowedBatchSizes: [Int32], container: String, sharedName: String, batchingQueue: String ) -> Tout -
Multiplies slices of two tensors in batches.
Multiplies all slices of
Tensorxandy(each slice can be viewed as an element of a batch), and arranges the individual results in a single output tensor of the same batch size. Each of the individual slices can optionally be adjointed (to adjoint a matrix means to transpose and conjugate it) before multiplication by setting theadj_xoradj_yflag toTrue, which are by defaultFalse.The input tensors
xandyare 2-D or higher with shape[..., r_x, c_x]and[..., r_y, c_y].The output tensor is 2-D or higher with shape
[..., r_o, c_o], where:r_o = c_x if adj_x else r_x c_o = r_y if adj_y else c_yIt is computed as:
output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :])Attrs:
- adj_x: If
True, adjoint the slices ofx. Defaults toFalse. - adj_y: If
True, adjoint the slices ofy. Defaults toFalse.
- adj_x: If
Output output: 3-D or higher with shape
[..., r_o, c_o]
Declaration
public static func batchMatMul<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T>, adjX: Bool = false, adjY: Bool = false ) -> Tensor<T>Parameters
x2-D or higher with shape
[..., r_x, c_x].y2-D or higher with shape
[..., r_y, c_y]. -
Multiplies slices of two tensors in batches.
Multiplies all slices of
Tensorxandy(each slice can be viewed as an element of a batch), and arranges the individual results in a single output tensor of the same batch size. Each of the individual slices can optionally be adjointed (to adjoint a matrix means to transpose and conjugate it) before multiplication by setting theadj_xoradj_yflag toTrue, which are by defaultFalse.The input tensors
xandyare 2-D or higher with shape[..., r_x, c_x]and[..., r_y, c_y].The output tensor is 2-D or higher with shape
[..., r_o, c_o], where:r_o = c_x if adj_x else r_x c_o = r_y if adj_y else c_yIt is computed as:
output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :])NOTE:
BatchMatMulV2supports broadcasting in the batch dimensions. More about broadcasting here.Attrs:
- adj_x: If
True, adjoint the slices ofx. Defaults toFalse. - adj_y: If
True, adjoint the slices ofy. Defaults toFalse.
- adj_x: If
Output output: 3-D or higher with shape
[..., r_o, c_o]
Declaration
public static func batchMatMulV2<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T>, adjX: Bool = false, adjY: Bool = false ) -> Tensor<T>Parameters
x2-D or higher with shape
[..., r_x, c_x].y2-D or higher with shape
[..., r_y, c_y]. -
Declaration
public static func batchMatrixBandPart<T: TensorFlowScalar>( _ input: Tensor<T>, numLower: Tensor<Int64>, numUpper: Tensor<Int64> ) -> Tensor<T> -
Declaration
public static func batchMatrixDeterminant<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchMatrixDiag<T: TensorFlowScalar>( diagonal: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchMatrixDiagPart<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchMatrixInverse<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, adjoint: Bool = false ) -> Tensor<T> -
Declaration
public static func batchMatrixSetDiag<T: TensorFlowScalar>( _ input: Tensor<T>, diagonal: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchMatrixSolve<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, adjoint: Bool = false ) -> Tensor<T> -
Declaration
public static func batchMatrixSolveLs<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, l2Regularizer: Tensor<Double>, fast: Bool = true ) -> Tensor<T> -
Declaration
public static func batchMatrixTriangularSolve<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, lower: Bool = true, adjoint: Bool = false ) -> Tensor<T> -
Batch normalization.
This op is deprecated. Prefer
tf.nn.batch_normalization.Attrs:
- variance_epsilon: A small float number to avoid dividing by 0.
- scale_after_normalization: A bool indicating whether the resulted tensor needs to be multiplied with gamma.
Declaration
Parameters
tA 4D input Tensor.
mA 1D mean Tensor with size matching the last dimension of t. This is the first output from tf.nn.moments, or a saved moving average thereof.
vA 1D variance Tensor with size matching the last dimension of t. This is the second output from tf.nn.moments, or a saved moving average thereof.
betaA 1D beta Tensor with size matching the last dimension of t. An offset to be added to the normalized tensor.
gammaA 1D gamma Tensor with size matching the last dimension of t. If “scale_after_normalization” is true, this tensor will be multiplied with the normalized tensor.
-
Gradients for batch normalization.
This op is deprecated. See
tf.nn.batch_normalization.Attrs:
- variance_epsilon: A small float number to avoid dividing by 0.
- scale_after_normalization: A bool indicating whether the resulted tensor needs to be multiplied with gamma.
Outputs:
- dx: 4D backprop tensor for input.
- dm: 1D backprop tensor for mean.
- dv: 1D backprop tensor for variance.
- db: 1D backprop tensor for beta.
- dg: 1D backprop tensor for gamma.
Declaration
Parameters
tA 4D input Tensor.
mA 1D mean Tensor with size matching the last dimension of t. This is the first output from tf.nn.moments, or a saved moving average thereof.
vA 1D variance Tensor with size matching the last dimension of t. This is the second output from tf.nn.moments, or a saved moving average thereof.
gammaA 1D gamma Tensor with size matching the last dimension of t. If “scale_after_normalization” is true, this Tensor will be multiplied with the normalized Tensor.
backprop4D backprop Tensor.
-
Declaration
public static func batchSelfAdjointEig<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Declaration
public static func batchSelfAdjointEigV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, computeV: Bool = true ) -> (e: Tensor<T>, v: Tensor<T>) -
Declaration
public static func batchSvd<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, computeUv: Bool = true, fullMatrices: Bool = false ) -> (s: Tensor<T>, u: Tensor<T>, v: Tensor<T>) -
BatchToSpace for 4-D tensors of type T.
This is a legacy version of the more general BatchToSpaceND.
Rearranges (permutes) data from batch into blocks of spatial data, followed by cropping. This is the reverse transformation of SpaceToBatch. More specifically, this op outputs a copy of the input tensor where values from the
batchdimension are moved in spatial blocks to theheightandwidthdimensions, followed by cropping along theheightandwidthdimensions.Output output: 4-D with shape
[batch, height, width, depth], where:height = height_pad - crop_top - crop_bottom width = width_pad - crop_left - crop_rightThe attr
block_sizemust be greater than one. It indicates the block size.Some examples:
(1) For the following input of shape
[4, 1, 1, 1]and block_size of 2:[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]The output tensor has shape
[1, 2, 2, 1]and value:x = [[[[1], [2]], [[3], [4]]]](2) For the following input of shape
[4, 1, 1, 3]and block_size of 2:[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]]The output tensor has shape
[1, 2, 2, 3]and value:x = [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]](3) For the following input of shape
[4, 2, 2, 1]and block_size of 2:x = [[[[1], [3]], [[9], [11]]], [[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]The output tensor has shape
[1, 4, 4, 1]and value:x = [[[[1], [2], [3], [4]], [[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]](4) For the following input of shape
[8, 1, 2, 1]and block_size of 2:x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]], [[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]The output tensor has shape
[2, 2, 4, 1]and value:x = [[[[1], [3]], [[5], [7]]], [[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]]
Declaration
public static func batchToSpace< T: TensorFlowScalar, Tidx: TensorFlowIndex >( _ input: Tensor<T>, crops: Tensor<Tidx>, blockSize: Int64 ) -> Tensor<T>Parameters
input4-D tensor with shape
[batch*block_size*block_size, height_pad/block_size, width_pad/block_size, depth]. Note that the batch size of the input tensor must be divisible byblock_size * block_size.crops2-D tensor of non-negative integers with shape
[2, 2]. It specifies how many elements to crop from the intermediate result across the spatial dimensions as follows:crops = [[crop_top, crop_bottom], [crop_left, crop_right]] -
BatchToSpace for N-D tensors of type T.
This operation reshapes the “batch” dimension 0 into
M + 1dimensions of shapeblock_shape + [batch], interleaves these blocks back into the grid defined by the spatial dimensions[1, ..., M], to obtain a result with the same rank as the input. The spatial dimensions of this intermediate result are then optionally cropped according tocropsto produce the output. This is the reverse of SpaceToBatch. See below for a precise description.Declaration
public static func batchToSpaceND< T: TensorFlowScalar, TblockShape: TensorFlowIndex, Tcrops: TensorFlowIndex >( _ input: Tensor<T>, blockShape: Tensor<TblockShape>, crops: Tensor<Tcrops> ) -> Tensor<T>Parameters
inputN-D with shape
input_shape = [batch] + spatial_shape + remaining_shape, where spatial_shape has M dimensions.block_shape1-D with shape
[M], all values must be >= 1.crops2-D with shape
[M, 2], all values must be >= 0.crops[i] = [crop_start, crop_end]specifies the amount to crop from input dimensioni + 1, which corresponds to spatial dimensioni. It is required thatcrop_start[i] + crop_end[i] <= block_shape[i] * input_shape[i + 1].This operation is equivalent to the following steps:
-
Computes the Bessel i0e function of
xelement-wise.Exponentially scaled modified Bessel function of order 0 defined as
bessel_i0e(x) = exp(-abs(x)) bessel_i0(x).This function is faster and numerically stabler than
bessel_i0(x).Declaration
public static func besselI0e<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the Bessel i1e function of
xelement-wise.Exponentially scaled modified Bessel function of order 0 defined as
bessel_i1e(x) = exp(-abs(x)) bessel_i1(x).This function is faster and numerically stabler than
bessel_i1(x).Declaration
public static func besselI1e<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Compute the regularized incomplete beta integral \(I_x(a, b)\).
The regularized incomplete beta integral is defined as:
\(I_x(a, b) = \frac{B(x; a, b)}{B(a, b)}\)
where
\(B(x; a, b) = \int_0^x t^{a-1} (1 - t)^{b-1} dt\)
is the incomplete beta function and \(B(a, b)\) is the complete beta function.
Declaration
public static func betainc<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ b: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Adds
biastovalue.This is a special case of
tf.addwherebiasis restricted to be 1-D. Broadcasting is supported, sovaluemay have any number of dimensions.Attr data_format: Specify the data format of the input and output data. With the default format “NHWC”, the bias tensor will be added to the last dimension of the value tensor. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width]. The tensor will be added to “in_channels”, the third-to-the-last dimension.
Output output: Broadcasted sum of
valueandbias.
Declaration
public static func biasAdd<T: TensorFlowNumeric>( value: Tensor<T>, bias: Tensor<T>, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
valueAny number of dimensions.
bias1-D with size the last dimension of
value. -
The backward operation for “BiasAdd” on the “bias” tensor.
It accumulates all the values from out_backprop into the feature dimension. For NHWC data format, the feature dimension is the last. For NCHW data format, the feature dimension is the third-to-last.
Attr data_format: Specify the data format of the input and output data. With the default format “NHWC”, the bias tensor will be added to the last dimension of the value tensor. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width]. The tensor will be added to “in_channels”, the third-to-the-last dimension.
Output output: 1-D with size the feature dimension of
out_backprop.
Declaration
public static func biasAddGrad<T: TensorFlowNumeric>( outBackprop: Tensor<T>, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
out_backpropAny number of dimensions.
-
Adds
biastovalue.This is a deprecated version of BiasAdd and will be soon removed.
This is a special case of
tf.addwherebiasis restricted to be 1-D. Broadcasting is supported, sovaluemay have any number of dimensions.Output output: Broadcasted sum of
valueandbias.
Declaration
public static func biasAddV1<T: TensorFlowNumeric>( value: Tensor<T>, bias: Tensor<T> ) -> Tensor<T>Parameters
valueAny number of dimensions.
bias1-D with size the last dimension of
value. -
Declaration
public static func binary<T: TensorFlowScalar>( _ a: Tensor<T>, _ b: Tensor<T> ) -> Tensor<T> -
Counts the number of occurrences of each value in an integer array.
Outputs a vector with length
sizeand the same dtype asweights. Ifweightsare empty, then indexistores the number of times the valueiis counted inarr. Ifweightsare non-empty, then indexistores the sum of the value inweightsat each index where the corresponding value inarrisi.Values in
arroutside of the range [0, size) are ignored.Output bins: 1D
Tensorwith length equal tosize. The counts or summed weights for each value in the range [0, size).
Declaration
public static func bincount<T: TensorFlowNumeric>( arr: Tensor<Int32>, size: Tensor<Int32>, weights: Tensor<T> ) -> Tensor<T> -
Bitcasts a tensor from one type to another without copying data.
Given a tensor
input, this operation returns a tensor that has the same buffer data asinputwith datatypetype.If the input datatype
Tis larger than the output datatypetypethen the shape changes from […] to […, sizeof(T)/sizeof(type)].If
Tis smaller thantype, the operator requires that the rightmost dimension be equal to sizeof(type)/sizeof(T). The shape then goes from […, sizeof(type)/sizeof(T)] to […].tf.bitcast() and tf.cast() work differently when real dtype is casted as a complex dtype (e.g. tf.complex64 or tf.complex128) as tf.cast() make imaginary part 0 while tf.bitcast() gives module error. For example,
Example 1:
a = [1., 2., 3.] equality_bitcast = tf.bitcast(a, tf.complex128) Traceback (most recent call last): … InvalidArgumentError: Cannot bitcast from 1 to 18 [Op:Bitcast] equality_cast = tf.cast(a, tf.complex128) print(equality_cast) tf.Tensor([1.+0.j 2.+0.j 3.+0.j], shape=(3,), dtype=complex128)
Example 2:
tf.bitcast(tf.constant(0xffffffff, dtype=tf.uint32), tf.uint8)
Example 3:
x = [1., 2., 3.] y = [0., 2., 3.] equality= tf.equal(x,y) equality_cast = tf.cast(equality,tf.float32) equality_bitcast = tf.bitcast(equality_cast,tf.uint8) print(equality) tf.Tensor([False True True], shape=(3,), dtype=bool) print(equality_cast) tf.Tensor([0. 1. 1.], shape=(3,), dtype=float32) print(equality_bitcast) tf.Tensor( [[ 0 0 0 0] [ 0 0 128 63] [ 0 0 128 63]], shape=(3, 4), dtype=uint8)
NOTE: Bitcast is implemented as a low-level cast, so machines with different endian orderings will give different results.
Declaration
public static func bitcast< T: TensorFlowNumeric, Type: TensorFlowNumeric >( _ input: Tensor<T> ) -> Tensor<Type> -
Elementwise computes the bitwise AND of
xandy.The result will have those bits set, that are set in both
xandy. The computation is performed on the underlying representations ofxandy.For example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8, tf.uint16, tf.uint32, tf.uint64] for dtype in dtype_list: lhs = tf.constant([0, 5, 3, 14], dtype=dtype) rhs = tf.constant([5, 0, 7, 11], dtype=dtype) exp = tf.constant([0, 0, 3, 10], dtype=tf.float32) res = bitwise_ops.bitwise_and(lhs, rhs) tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUEDeclaration
public static func bitwiseAnd<T: TensorFlowInteger>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Elementwise computes the bitwise OR of
xandy.The result will have those bits set, that are set in
x,yor both. The computation is performed on the underlying representations ofxandy.For example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8, tf.uint16, tf.uint32, tf.uint64] for dtype in dtype_list: lhs = tf.constant([0, 5, 3, 14], dtype=dtype) rhs = tf.constant([5, 0, 7, 11], dtype=dtype) exp = tf.constant([5, 5, 7, 15], dtype=tf.float32) res = bitwise_ops.bitwise_or(lhs, rhs) tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUEDeclaration
public static func bitwiseOr<T: TensorFlowInteger>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Elementwise computes the bitwise XOR of
xandy.The result will have those bits set, that are different in
xandy. The computation is performed on the underlying representations ofxandy.For example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8, tf.uint16, tf.uint32, tf.uint64] for dtype in dtype_list: lhs = tf.constant([0, 5, 3, 14], dtype=dtype) rhs = tf.constant([5, 0, 7, 11], dtype=dtype) exp = tf.constant([5, 5, 4, 5], dtype=tf.float32) res = bitwise_ops.bitwise_xor(lhs, rhs) tf.assert_equal(tf.cast(res, tf.float32), exp) # TRUEDeclaration
public static func bitwiseXor<T: TensorFlowInteger>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Computes the LSTM cell forward propagation for all the time steps.
This is equivalent to applying LSTMBlockCell in a loop, like so:
for x1 in unpack(x): i1, cs1, f1, o1, ci1, co1, h1 = LSTMBlock( x1, cs_prev, h_prev, w, wci, wcf, wco, b) cs_prev = cs1 h_prev = h1 i.append(i1) cs.append(cs1) f.append(f1) o.append(o1) ci.append(ci1) co.append(co1) h.append(h1) return pack(i), pack(cs), pack(f), pack(o), pack(ci), pack(ch), pack(h)Attrs:
- forget_bias: The forget gate bias.
- cell_clip: Value to clip the ‘cs’ value to.
- use_peephole: Whether to use peephole weights.
Outputs:
- i: The input gate over the whole time sequence.
- cs: The cell state before the tanh over the whole time sequence.
- f: The forget gate over the whole time sequence.
- o: The output gate over the whole time sequence.
- ci: The cell input over the whole time sequence.
- co: The cell after the tanh over the whole time sequence.
- h: The output h vector over the whole time sequence.
Declaration
public static func blockLSTM<T: FloatingPoint & TensorFlowScalar>( seqLenMax: Tensor<Int64>, _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, forgetBias: Double = 1, cellClip: Double = 3, usePeephole: Bool = false ) -> ( i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, h: Tensor<T> )Parameters
seq_len_maxMaximum time length actually used by this input. Outputs are padded with zeros beyond this length.
xThe sequence input to the LSTM, shape (timelen, batch_size, num_inputs).
cs_prevValue of the initial cell state.
h_prevInitial output of cell (to be used for peephole).
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
-
Computes the LSTM cell backward propagation for the entire time sequence.
This implementation is to be used in conjunction of LSTMBlock.
Attr use_peephole: Whether to use peephole weights.
Outputs:
- x_grad: The gradient of x to be back-propped.
- cs_prev_grad: The gradient of cs_prev to be back-propped.
- h_prev_grad: The gradient of h_prev to be back-propped.
- w_grad: The gradient for w to be back-propped.
- wci_grad: The gradient for wci to be back-propped.
- wcf_grad: The gradient for wcf to be back-propped.
- wco_grad: The gradient for wco to be back-propped.
- b_grad: The gradient for w to be back-propped.
Declaration
public static func blockLSTMGrad<T: FloatingPoint & TensorFlowScalar>( seqLenMax: Tensor<Int64>, _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, h: Tensor<T>, csGrad: Tensor<T>, hGrad: Tensor<T>, usePeephole: Bool ) -> ( xGrad: Tensor<T>, csPrevGrad: Tensor<T>, hPrevGrad: Tensor<T>, wGrad: Tensor<T>, wciGrad: Tensor<T>, wcfGrad: Tensor<T>, wcoGrad: Tensor<T>, bGrad: Tensor<T> )Parameters
seq_len_maxMaximum time length actually used by this input. Outputs are padded with zeros beyond this length.
xThe sequence input to the LSTM, shape (timelen, batch_size, num_inputs).
cs_prevValue of the initial cell state.
h_prevInitial output of cell (to be used for peephole).
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
iThe input gate over the whole time sequence.
csThe cell state before the tanh over the whole time sequence.
fThe forget gate over the whole time sequence.
oThe output gate over the whole time sequence.
ciThe cell input over the whole time sequence.
coThe cell after the tanh over the whole time sequence.
hThe output h vector over the whole time sequence.
cs_gradThe current gradient of cs.
h_gradThe gradient of h vector.
-
blockLSTMGradV2(seqLenMax:_:csPrev:hPrev:w:wci:wcf:wco:_:i:cs:f:o:ci:co:h:csGrad:hGrad:usePeephole:)
Computes the LSTM cell backward propagation for the entire time sequence.
This implementation is to be used in conjunction of BlockLSTMV2.
Attr use_peephole: Whether to use peephole weights.
Outputs:
- x_grad: The gradient of x to be back-propped.
- cs_prev_grad: The gradient of cs_prev to be back-propped.
- h_prev_grad: The gradient of h_prev to be back-propped.
- w_grad: The gradient for w to be back-propped.
- wci_grad: The gradient for wci to be back-propped.
- wcf_grad: The gradient for wcf to be back-propped.
- wco_grad: The gradient for wco to be back-propped.
- b_grad: The gradient for w to be back-propped.
Declaration
public static func blockLSTMGradV2<T: FloatingPoint & TensorFlowScalar>( seqLenMax: Tensor<Int64>, _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, h: Tensor<T>, csGrad: Tensor<T>, hGrad: Tensor<T>, usePeephole: Bool ) -> ( xGrad: Tensor<T>, csPrevGrad: Tensor<T>, hPrevGrad: Tensor<T>, wGrad: Tensor<T>, wciGrad: Tensor<T>, wcfGrad: Tensor<T>, wcoGrad: Tensor<T>, bGrad: Tensor<T> )Parameters
seq_len_maxMaximum time length actually used by this input. Outputs are padded with zeros beyond this length.
xThe sequence input to the LSTM, shape (timelen, batch_size, num_inputs).
cs_prevValue of the initial cell state.
h_prevInitial output of cell (to be used for peephole).
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
iThe input gate over the whole time sequence.
csThe cell state before the tanh over the whole time sequence.
fThe forget gate over the whole time sequence.
oThe output gate over the whole time sequence.
ciThe cell input over the whole time sequence.
coThe cell after the tanh over the whole time sequence.
hThe output h vector over the whole time sequence.
cs_gradThe current gradient of cs.
h_gradThe gradient of h vector.
-
Computes the LSTM cell forward propagation for all the time steps.
This is equivalent to applying LSTMBlockCell in a loop, like so:
for x1 in unpack(x): i1, cs1, f1, o1, ci1, co1, h1 = LSTMBlock( x1, cs_prev, h_prev, w, wci, wcf, wco, b) cs_prev = cs1 h_prev = h1 i.append(i1) cs.append(cs1) f.append(f1) o.append(o1) ci.append(ci1) co.append(co1) h.append(h1) return pack(i), pack(cs), pack(f), pack(o), pack(ci), pack(ch), pack(h) Note that unlike LSTMBlockCell (and BlockLSTM) which uses ICFO gate layout, this op uses IFCO. So in order for the following snippet to be equivalent all gate-related outputs should be reordered.Attrs:
- cell_clip: Value to clip the ‘cs’ value to.
- use_peephole: Whether to use peephole weights.
Outputs:
- i: The input gate over the whole time sequence.
- cs: The cell state before the tanh over the whole time sequence.
- f: The forget gate over the whole time sequence.
- o: The output gate over the whole time sequence.
- ci: The cell input over the whole time sequence.
- co: The cell after the tanh over the whole time sequence.
- h: The output h vector over the whole time sequence.
Declaration
public static func blockLSTMV2<T: FloatingPoint & TensorFlowScalar>( seqLenMax: Tensor<Int64>, _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, cellClip: Double = 0, usePeephole: Bool = false ) -> ( i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, h: Tensor<T> )Parameters
seq_len_maxMaximum time length actually used by this input. Outputs are padded with zeros beyond this length.
xThe sequence input to the LSTM, shape (timelen, batch_size, num_inputs).
cs_prevValue of the initial cell state.
h_prevInitial output of cell (to be used for peephole).
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
-
Aggregates the summary of accumulated stats for the batch.
The summary stats contains gradients and hessians accumulated for each node, feature dimension id and bucket.
Attrs:
- max_splits: int; the maximum number of splits possible in the whole tree.
- num_buckets: int; equals to the maximum possible value of bucketized feature.
Output stats_summary: output Rank 4 Tensor (shape=[splits, feature_dimension, buckets, logits_dimension + hessian_dimension]) containing accumulated stats for each node, feature dimension and bucket.
Declaration
Parameters
node_idsint32; Rank 1 Tensor containing node ids for each example, shape [batch_size].
gradientsfloat32; Rank 2 Tensor (shape=[batch_size, logits_dimension]) with gradients for each example.
hessiansfloat32; Rank 2 Tensor (shape=[batch_size, hessian_dimension]) with hessians for each example.
featureint32; Rank 2 feature Tensors (shape=[batch_size, feature_dimension]).
-
Bucketize each feature based on bucket boundaries.
An op that returns a list of float tensors, where each tensor represents the bucketized values for a single feature.
Attr num_features: inferred int; number of features.
Output buckets: int; List of Rank 1 Tensors each containing the bucketized values for a single feature.
Declaration
Parameters
float_valuesfloat; List of Rank 1 Tensor each containing float values for a single feature.
bucket_boundariesfloat; List of Rank 1 Tensors each containing the bucket boundaries for a single feature.
-
boostedTreesCalculateBestFeatureSplit(nodeIdRange:statsSummary:l1:l2:treeComplexity:minNodeWeight:logitsDimension:splitType:)
Calculates gains for each feature and returns the best possible split information for the feature.
The split information is the best threshold (bucket id), gains and left/right node contributions per node for each feature.
It is possible that not all nodes can be split on each feature. Hence, the list of possible nodes can differ between the features. Therefore, we return
node_ids_listfor each feature, containing the list of nodes that this feature can be used to split.In this manner, the output is the best split per features and per node, so that it needs to be combined later to produce the best split for each node (among all possible features).
The output shapes are compatible in a way that the first dimension of all tensors are the same and equal to the number of possible split nodes for each feature.
Attrs:
- logits_dimension: The dimension of logit, i.e., number of classes.
- split_type: A string indicating if this Op should perform inequality split or equality split.
Outputs:
- node_ids: A Rank 1 tensors indicating possible split node ids for each feature. The length of the list is num_features, but each tensor has different size as each feature provides different possible nodes. See above for details like shapes and sizes.
- gains: A Rank 1 tensors indicating the best gains for each feature to split for certain nodes. See above for details like shapes and sizes.
- feature_dimensions: A Rank 1 tensors indicating the best feature dimension for each feature to split for certain nodes if the feature is multi-dimension. See above for details like shapes and sizes.
- thresholds: A Rank 1 tensors indicating the bucket id to compare with (as a threshold) for split in each node. See above for details like shapes and sizes.
- left_node_contribs: A Rank 2 tensors indicating the contribution of the left nodes when branching from parent nodes (given by the tensor element in the output node_ids_list) to the left direction by the given threshold for each feature. This value will be used to make the left node value by adding to the parent node value. Second dimension size is 1 for 1-dimensional logits, but would be larger for multi-class problems. See above for details like shapes and sizes.
- right_node_contribs: A Rank 2 tensors, with the same shape/conditions as left_node_contribs_list, but just that the value is for the right node.
- split_with_default_directions: A Rank 1 tensors indicating the which direction to go if data is missing. See above for details like shapes and sizes. Inequality with default left returns 0, inequality with default right returns 1, equality with default right returns 2.
Declaration
public static func boostedTreesCalculateBestFeatureSplit( nodeIdRange: Tensor<Int32>, statsSummary: Tensor<Float>, l1: Tensor<Float>, l2: Tensor<Float>, treeComplexity: Tensor<Float>, minNodeWeight: Tensor<Float>, logitsDimension: Int64, splitType: SplitType = .inequality ) -> ( nodeIds: Tensor<Int32>, gains: Tensor<Float>, featureDimensions: Tensor<Int32>, thresholds: Tensor<Int32>, leftNodeContribs: Tensor<Float>, rightNodeContribs: Tensor<Float>, splitWithDefaultDirections: StringTensor )Parameters
node_id_rangeA Rank 1 tensor (shape=[2]) to specify the range [first, last) of node ids to process within
stats_summary_list. The nodes are iterated between the two nodes specified by the tensor, as likefor node_id in range(node_id_range[0], node_id_range[1])(Note that the last index node_id_range[1] is exclusive).stats_summaryA Rank 4 tensor (#shape=[max_splits, feature_dims, bucket, stats_dims]) for accumulated stats summary (gradient/hessian) per node, per dimension, per buckets for each feature. The first dimension of the tensor is the maximum number of splits, and thus not all elements of it will be used, but only the indexes specified by node_ids will be used.
l1l1 regularization factor on leaf weights, per instance based.
l2l2 regularization factor on leaf weights, per instance based.
tree_complexityadjustment to the gain, per leaf based.
min_node_weightmininum avg of hessians in a node before required for the node to be considered for splitting.
-
boostedTreesCalculateBestGainsPerFeature(nodeIdRange:statsSummaryList:l1:l2:treeComplexity:minNodeWeight:maxSplits:)
Calculates gains for each feature and returns the best possible split information for the feature.
The split information is the best threshold (bucket id), gains and left/right node contributions per node for each feature.
It is possible that not all nodes can be split on each feature. Hence, the list of possible nodes can differ between the features. Therefore, we return
node_ids_listfor each feature, containing the list of nodes that this feature can be used to split.In this manner, the output is the best split per features and per node, so that it needs to be combined later to produce the best split for each node (among all possible features).
The length of output lists are all of the same length,
num_features. The output shapes are compatible in a way that the first dimension of all tensors of all lists are the same and equal to the number of possible split nodes for each feature.Attrs:
- max_splits: the number of nodes that can be split in the whole tree. Used as a dimension of output tensors.
- num_features: inferred from the size of
stats_summary_list; the number of total features.
Outputs:
- node_ids_list: An output list of Rank 1 tensors indicating possible split node ids for each feature. The length of the list is num_features, but each tensor has different size as each feature provides different possible nodes. See above for details like shapes and sizes.
- gains_list: An output list of Rank 1 tensors indicating the best gains for each feature to split for certain nodes. See above for details like shapes and sizes.
- thresholds_list: An output list of Rank 1 tensors indicating the bucket id to compare with (as a threshold) for split in each node. See above for details like shapes and sizes.
- left_node_contribs_list: A list of Rank 2 tensors indicating the contribution of the left nodes when branching from parent nodes (given by the tensor element in the output node_ids_list) to the left direction by the given threshold for each feature. This value will be used to make the left node value by adding to the parent node value. Second dimension size is 1 for 1-dimensional logits, but would be larger for multi-class problems. See above for details like shapes and sizes.
- right_node_contribs_list: A list of Rank 2 tensors, with the same shape/conditions as left_node_contribs_list, but just that the value is for the right node.
Declaration
public static func boostedTreesCalculateBestGainsPerFeature( nodeIdRange: Tensor<Int32>, statsSummaryList: [Tensor<Float>], l1: Tensor<Float>, l2: Tensor<Float>, treeComplexity: Tensor<Float>, minNodeWeight: Tensor<Float>, maxSplits: Int64 ) -> ( nodeIdsList: [Tensor<Int32>], gainsList: [Tensor<Float>], thresholdsList: [Tensor<Int32>], leftNodeContribsList: [Tensor<Float>], rightNodeContribsList: [Tensor<Float>] )Parameters
node_id_rangeA Rank 1 tensor (shape=[2]) to specify the range [first, last) of node ids to process within
stats_summary_list. The nodes are iterated between the two nodes specified by the tensor, as likefor node_id in range(node_id_range[0], node_id_range[1])(Note that the last index node_id_range[1] is exclusive).stats_summary_listA list of Rank 3 tensor (#shape=[max_splits, bucket, 2]) for accumulated stats summary (gradient/hessian) per node per buckets for each feature. The first dimension of the tensor is the maximum number of splits, and thus not all elements of it will be used, but only the indexes specified by node_ids will be used.
l1l1 regularization factor on leaf weights, per instance based.
l2l2 regularization factor on leaf weights, per instance based.
tree_complexityadjustment to the gain, per leaf based.
min_node_weightmininum avg of hessians in a node before required for the node to be considered for splitting.
-
Calculates the prior from the training data (the bias) and fills in the first node with the logits’ prior. Returns a boolean indicating whether to continue centering.
Output continue_centering: Bool, whether to continue bias centering.
Declaration
Parameters
tree_ensemble_handleHandle to the tree ensemble.
mean_gradientsA tensor with shape=[logits_dimension] with mean of gradients for a first node.
mean_hessiansA tensor with shape=[logits_dimension] mean of hessians for a first node.
l1l1 regularization factor on leaf weights, per instance based.
l2l2 regularization factor on leaf weights, per instance based.
-
Creates a tree ensemble model and returns a handle to it.
Declaration
public static func boostedTreesCreateEnsemble( treeEnsembleHandle: ResourceHandle, stampToken: Tensor<Int64>, treeEnsembleSerialized: StringTensor )Parameters
tree_ensemble_handleHandle to the tree ensemble resource to be created.
stamp_tokenToken to use as the initial value of the resource stamp.
tree_ensemble_serializedSerialized proto of the tree ensemble.
-
boostedTreesCreateQuantileStreamResource(quantileStreamResourceHandle:epsilon:numStreams:maxElements:)
Create the Resource for Quantile Streams.
Attr max_elements: int; The maximum number of data points that can be fed to the stream.
Declaration
public static func boostedTreesCreateQuantileStreamResource( quantileStreamResourceHandle: ResourceHandle, epsilon: Tensor<Float>, numStreams: Tensor<Int64>, maxElements: Int64 = 1_099_511_627_776 )Parameters
quantile_stream_resource_handleresource; Handle to quantile stream resource.
epsilonfloat; The required approximation error of the stream resource.
num_streamsint; The number of streams managed by the resource that shares the same epsilon.
-
Deserializes a serialized tree ensemble config and replaces current tree
ensemble.
Declaration
public static func boostedTreesDeserializeEnsemble( treeEnsembleHandle: ResourceHandle, stampToken: Tensor<Int64>, treeEnsembleSerialized: StringTensor )Parameters
tree_ensemble_handleHandle to the tree ensemble.
stamp_tokenToken to use as the new value of the resource stamp.
tree_ensemble_serializedSerialized proto of the ensemble.
-
Creates a handle to a BoostedTreesEnsembleResource
Declaration
public static func boostedTreesEnsembleResourceHandleOp( container: String, sharedName: String ) -> ResourceHandle -
Debugging/model interpretability outputs for each example.
It traverses all the trees and computes debug metrics for individual examples, such as getting split feature ids and logits after each split along the decision path used to compute directional feature contributions.
Attrs:
- num_bucketized_features: Inferred.
- logits_dimension: scalar, dimension of the logits, to be used for constructing the protos in examples_debug_outputs_serialized.
Output examples_debug_outputs_serialized: Output rank 1 Tensor containing a proto serialized as a string for each example.
Declaration
public static func boostedTreesExampleDebugOutputs( treeEnsembleHandle: ResourceHandle, bucketizedFeatures: [Tensor<Int32>], logitsDimension: Int64 ) -> StringTensorParameters
bucketized_featuresA list of rank 1 Tensors containing bucket id for each feature.
-
Flush the quantile summaries from each quantile stream resource.
An op that outputs a list of quantile summaries of a quantile stream resource. Each summary Tensor is rank 2, containing summaries (value, weight, min_rank, max_rank) for a single feature.
Declaration
public static func boostedTreesFlushQuantileSummaries( quantileStreamResourceHandle: ResourceHandle, numFeatures: Int64 ) -> [Tensor<Float>]Parameters
quantile_stream_resource_handleresource handle referring to a QuantileStreamResource.
-
Retrieves the tree ensemble resource stamp token, number of trees and growing statistics.
Outputs:
- stamp_token: Stamp token of the tree ensemble resource.
- num_trees: The number of trees in the tree ensemble resource.
- num_finalized_trees: The number of trees that were finished successfully.
- num_attempted_layers: The number of layers we attempted to build (but not necessarily succeeded).
- last_layer_nodes_range: Rank size 2 tensor that contains start and end ids of the nodes in the latest layer.
Declaration
Parameters
tree_ensemble_handleHandle to the tree ensemble.
-
Makes the summary of quantiles for the batch.
An op that takes a list of tensors (one tensor per feature) and outputs the quantile summaries for each tensor.
Attr num_features: int; Inferred from the size of float_values. The number of float features.
Output summaries: float; List of Rank 2 Tensors each containing the quantile summary (value, weight, min_rank, max_rank) of a single feature.
Declaration
Parameters
float_valuesfloat; List of Rank 1 Tensors each containing values for a single feature.
example_weightsfloat; Rank 1 Tensor with weights per instance.
epsilonfloat; The required maximum approximation error.
-
boostedTreesMakeStatsSummary(nodeIds:gradients:hessians:bucketizedFeaturesList:maxSplits:numBuckets:)
Makes the summary of accumulated stats for the batch.
The summary stats contains gradients and hessians accumulated into the corresponding node and bucket for each example.
Attrs:
- max_splits: int; the maximum number of splits possible in the whole tree.
- num_buckets: int; equals to the maximum possible value of bucketized feature.
- num_features: int; inferred from the size of bucketized_features_list; the number of features.
Output stats_summary: output Rank 4 Tensor (shape=[#features, #splits, #buckets, 2]) containing accumulated stats put into the corresponding node and bucket. The first index of 4th dimension refers to gradients, and the second to hessians.
Declaration
Parameters
node_idsint32 Rank 1 Tensor containing node ids, which each example falls into for the requested layer.
gradientsfloat32; Rank 2 Tensor (shape=[#examples, 1]) for gradients.
hessiansfloat32; Rank 2 Tensor (shape=[#examples, 1]) for hessians.
bucketized_features_listint32 list of Rank 1 Tensors, each containing the bucketized feature (for each feature column).
-
Runs multiple additive regression ensemble predictors on input instances and
computes the logits. It is designed to be used during prediction. It traverses all the trees and calculates the final score for each instance.
Attrs:
- num_bucketized_features: Inferred.
- logits_dimension: scalar, dimension of the logits, to be used for partial logits shape.
Output logits: Output rank 2 Tensor containing logits for each example.
Declaration
public static func boostedTreesPredict( treeEnsembleHandle: ResourceHandle, bucketizedFeatures: [Tensor<Int32>], logitsDimension: Int64 ) -> Tensor<Float>Parameters
bucketized_featuresA list of rank 1 Tensors containing bucket id for each feature.
-
Add the quantile summaries to each quantile stream resource.
An op that adds a list of quantile summaries to a quantile stream resource. Each summary Tensor is rank 2, containing summaries (value, weight, min_rank, max_rank) for a single feature.
Declaration
public static func boostedTreesQuantileStreamResourceAddSummaries( quantileStreamResourceHandle: ResourceHandle, summaries: [Tensor<Float>] )Parameters
quantile_stream_resource_handleresource handle referring to a QuantileStreamResource.
summariesstring; List of Rank 2 Tensor each containing the summaries for a single feature.
-
Deserialize bucket boundaries and ready flag into current QuantileAccumulator.
An op that deserializes bucket boundaries and are boundaries ready flag into current QuantileAccumulator.
Attr num_streams: inferred int; number of features to get bucket boundaries for.
Declaration
public static func boostedTreesQuantileStreamResourceDeserialize( quantileStreamResourceHandle: ResourceHandle, bucketBoundaries: [Tensor<Float>] )Parameters
quantile_stream_resource_handleresource handle referring to a QuantileStreamResource.
bucket_boundariesfloat; List of Rank 1 Tensors each containing the bucket boundaries for a feature.
-
Flush the summaries for a quantile stream resource.
An op that flushes the summaries for a quantile stream resource.
Attr generate_quantiles: bool; If True, the output will be the num_quantiles for each stream where the ith entry is the ith quantile of the input with an approximation error of epsilon. Duplicate values may be present. If False, the output will be the points in the histogram that we got which roughly translates to 1/epsilon boundaries and without any duplicates. Default to False.
Declaration
public static func boostedTreesQuantileStreamResourceFlush( quantileStreamResourceHandle: ResourceHandle, numBuckets: Tensor<Int64>, generateQuantiles: Bool = false )Parameters
quantile_stream_resource_handleresource handle referring to a QuantileStreamResource.
num_bucketsint; approximate number of buckets unless using generate_quantiles.
-
Generate the bucket boundaries for each feature based on accumulated summaries.
An op that returns a list of float tensors for a quantile stream resource. Each tensor is Rank 1 containing bucket boundaries for a single feature.
Attr num_features: inferred int; number of features to get bucket boundaries for.
Output bucket_boundaries: float; List of Rank 1 Tensors each containing the bucket boundaries for a feature.
Declaration
public static func boostedTreesQuantileStreamResourceGetBucketBoundaries( quantileStreamResourceHandle: ResourceHandle, numFeatures: Int64 ) -> [Tensor<Float>]Parameters
quantile_stream_resource_handleresource handle referring to a QuantileStreamResource.
-
Creates a handle to a BoostedTreesQuantileStreamResource.
Declaration
public static func boostedTreesQuantileStreamResourceHandleOp( container: String, sharedName: String ) -> ResourceHandle -
Serializes the tree ensemble to a proto.
Outputs:
- stamp_token: Stamp token of the tree ensemble resource.
- tree_ensemble_serialized: Serialized proto of the ensemble.
Declaration
public static func boostedTreesSerializeEnsemble( treeEnsembleHandle: ResourceHandle ) -> (stampToken: Tensor<Int64>, treeEnsembleSerialized: StringTensor)Parameters
tree_ensemble_handleHandle to the tree ensemble.
-
boostedTreesSparseAggregateStats(nodeIds:gradients:hessians:featureIndices:featureValues:featureShape:maxSplits:numBuckets:)
Aggregates the summary of accumulated stats for the batch.
The summary stats contains gradients and hessians accumulated for each node, bucket and dimension id.
Attrs:
- max_splits: int; the maximum number of splits possible in the whole tree.
- num_buckets: int; equals to the maximum possible value of bucketized feature + 1.
Outputs:
- stats_summary_indices: int32; Rank 2 indices of summary sparse Tensors (shape=[number of non zero statistics, 4]) The second axis can only be 4 including node id, feature dimension, bucket id, and statistics_dimension. statistics_dimension = logits_dimension + hessian_dimension.
- stats_summary_values: output Rank 1 Tensor (shape=[number of non zero statistics])
- stats_summary_shape: output Rank 1 Tensor (shape=[4]) The tensor has following 4 values: [max_splits, feature_dimension, num_buckets, statistics_dimension], where statistics_dimension = gradient_dimension + hessian_dimension. gradient_dimension is the same as label_dimension, i.e., the output space. hessian_dimension can be the same as logits dimension when diagonal hessian is used, or label_dimension^2 when full hessian is used.
Declaration
public static func boostedTreesSparseAggregateStats( nodeIds: Tensor<Int32>, gradients: Tensor<Float>, hessians: Tensor<Float>, featureIndices: Tensor<Int32>, featureValues: Tensor<Int32>, featureShape: Tensor<Int32>, maxSplits: Int64, numBuckets: Int64 ) -> ( statsSummaryIndices: Tensor<Int32>, statsSummaryValues: Tensor<Float>, statsSummaryShape: Tensor<Int32> )Parameters
node_idsint32; Rank 1 Tensor containing node ids for each example, shape [batch_size].
gradientsfloat32; Rank 2 Tensor (shape=[batch_size, logits_dimension]) with gradients for each example.
hessiansfloat32; Rank 2 Tensor (shape=[batch_size, hessian_dimension]) with hessians for each example.
feature_indicesint32; Rank 2 indices of feature sparse Tensors (shape=[number of sparse entries, 2]). Number of sparse entries across all instances from the batch. The first value is the index of the instance, the second is dimension of the feature. The second axis can only have 2 values, i.e., the input dense version of Tensor can only be matrix.
feature_valuesint32; Rank 1 values of feature sparse Tensors (shape=[number of sparse entries]). Number of sparse entries across all instances from the batch. The first value is the index of the instance, the second is dimension of the feature.
feature_shapeint32; Rank 1 dense shape of feature sparse Tensors (shape=[2]). The first axis can only have 2 values, [batch_size, feature_dimension].
-
boostedTreesSparseCalculateBestFeatureSplit(nodeIdRange:statsSummaryIndices:statsSummaryValues:statsSummaryShape:l1:l2:treeComplexity:minNodeWeight:logitsDimension:splitType:)
Calculates gains for each feature and returns the best possible split information for the feature.
The split information is the best threshold (bucket id), gains and left/right node contributions per node for each feature.
It is possible that not all nodes can be split on each feature. Hence, the list of possible nodes can differ between the features. Therefore, we return
node_ids_listfor each feature, containing the list of nodes that this feature can be used to split.In this manner, the output is the best split per features and per node, so that it needs to be combined later to produce the best split for each node (among all possible features).
The output shapes are compatible in a way that the first dimension of all tensors are the same and equal to the number of possible split nodes for each feature.
Attrs:
- logits_dimension: The dimension of logit, i.e., number of classes.
- split_type: A string indicating if this Op should perform inequality split or equality split.
Outputs:
- node_ids: A Rank 1 tensor indicating possible node ids that can be split.
- gains: A Rank 1 tensor indicating the best gains to split each node.
- feature_dimensions: A Rank 1 tensor indicating the best feature dimension for each feature to split for each node.
- thresholds: A Rank 1 tensor indicating the bucket id to compare with (as a threshold) for split in each node.
- left_node_contribs: A Rank 2 tensor indicating the contribution of the left nodes when branching from parent nodes to the left direction by the given threshold for each feature. This value will be used to make the left node value by adding to the parent node value. Second dimension size is logits dimension.
- right_node_contribs: A Rank 2 tensor, with the same shape/conditions as left_node_contribs_list, but just that the value is for the right node.
- split_with_default_directions: A Rank 1 tensor indicating which direction to go if data is missing. Inequality with default left returns 0, inequality with default right returns 1, equality with default right returns 2.
Declaration
public static func boostedTreesSparseCalculateBestFeatureSplit( nodeIdRange: Tensor<Int32>, statsSummaryIndices: Tensor<Int32>, statsSummaryValues: Tensor<Float>, statsSummaryShape: Tensor<Int32>, l1: Tensor<Float>, l2: Tensor<Float>, treeComplexity: Tensor<Float>, minNodeWeight: Tensor<Float>, logitsDimension: Int64, splitType: SplitType2 = .inequality ) -> ( nodeIds: Tensor<Int32>, gains: Tensor<Float>, featureDimensions: Tensor<Int32>, thresholds: Tensor<Int32>, leftNodeContribs: Tensor<Float>, rightNodeContribs: Tensor<Float>, splitWithDefaultDirections: StringTensor )Parameters
node_id_rangeA Rank 1 tensor (shape=[2]) to specify the range [first, last) of node ids to process within
stats_summary_list. The nodes are iterated between the two nodes specified by the tensor, as likefor node_id in range(node_id_range[0], node_id_range[1])(Note that the last index node_id_range[1] is exclusive).stats_summary_indicesA Rank 2 int64 tensor of dense shape N, 4 for accumulated stats summary (gradient/hessian) per node per bucket for each feature. The second dimension contains node id, feature dimension, bucket id, and stats dim. stats dim is the sum of logits dimension and hessian dimension, hessian dimension can either be logits dimension if diagonal hessian is used, or logits dimension^2 if full hessian is used.
stats_summary_valuesA Rank 1 float tensor of dense shape N, which supplies the values for each element in summary_indices.
stats_summary_shapeA Rank 1 float tensor of dense shape [4], which specifies the dense shape of the sparse tensor, which is [num tree nodes, feature dimensions, num buckets, stats dim].
l1l1 regularization factor on leaf weights, per instance based.
l2l2 regularization factor on leaf weights, per instance based.
tree_complexityadjustment to the gain, per leaf based.
min_node_weightmininum avg of hessians in a node before required for the node to be considered for splitting.
-
boostedTreesTrainingPredict(treeEnsembleHandle:cachedTreeIds:cachedNodeIds:bucketizedFeatures:logitsDimension:)
Runs multiple additive regression ensemble predictors on input instances and
computes the update to cached logits. It is designed to be used during training. It traverses the trees starting from cached tree id and cached node id and calculates the updates to be pushed to the cache.
Attrs:
- num_bucketized_features: Inferred.
- logits_dimension: scalar, dimension of the logits, to be used for partial logits shape.
Outputs:
- partial_logits: Rank 2 Tensor containing logits update (with respect to cached values stored) for each example.
- tree_ids: Rank 1 Tensor containing new tree ids for each example.
- node_ids: Rank 1 Tensor containing new node ids in the new tree_ids.
Declaration
Parameters
cached_tree_idsRank 1 Tensor containing cached tree ids which is the starting tree of prediction.
cached_node_idsRank 1 Tensor containing cached node id which is the starting node of prediction.
bucketized_featuresA list of rank 1 Tensors containing bucket id for each feature.
-
boostedTreesUpdateEnsemble(treeEnsembleHandle:featureIds:nodeIds:gains:thresholds:leftNodeContribs:rightNodeContribs:maxDepth:learningRate:pruningMode:)
Updates the tree ensemble by either adding a layer to the last tree being grown
or by starting a new tree.
Attrs:
- pruning_mode: 0-No pruning, 1-Pre-pruning, 2-Post-pruning.
- num_features: Number of features that have best splits returned. INFERRED.
Declaration
public static func boostedTreesUpdateEnsemble( treeEnsembleHandle: ResourceHandle, featureIds: Tensor<Int32>, nodeIds: [Tensor<Int32>], gains: [Tensor<Float>], thresholds: [Tensor<Int32>], leftNodeContribs: [Tensor<Float>], rightNodeContribs: [Tensor<Float>], maxDepth: Tensor<Int32>, learningRate: Tensor<Float>, pruningMode: Int64 )Parameters
tree_ensemble_handleHandle to the ensemble variable.
feature_idsRank 1 tensor with ids for each feature. This is the real id of the feature that will be used in the split.
node_idsList of rank 1 tensors representing the nodes for which this feature has a split.
gainsList of rank 1 tensors representing the gains for each of the feature’s split.
thresholdsList of rank 1 tensors representing the thesholds for each of the feature’s split.
left_node_contribsList of rank 2 tensors with left leaf contribs for each of the feature’s splits. Will be added to the previous node values to constitute the values of the left nodes.
right_node_contribsList of rank 2 tensors with right leaf contribs for each of the feature’s splits. Will be added to the previous node values to constitute the values of the right nodes.
max_depthMax depth of the tree to build.
learning_rateshrinkage const for each new tree.
-
boostedTreesUpdateEnsembleV2(treeEnsembleHandle:featureIds:dimensionIds:nodeIds:gains:thresholds:leftNodeContribs:rightNodeContribs:splitTypes:maxDepth:learningRate:pruningMode:logitsDimension:)
Updates the tree ensemble by adding a layer to the last tree being grown
or by starting a new tree.
Attrs:
- num_features: Number of features that have best splits returned. INFERRED.
- logits_dimension: scalar, dimension of the logits
Declaration
public static func boostedTreesUpdateEnsembleV2( treeEnsembleHandle: ResourceHandle, featureIds: Tensor<Int32>, dimensionIds: [Tensor<Int32>], nodeIds: [Tensor<Int32>], gains: [Tensor<Float>], thresholds: [Tensor<Int32>], leftNodeContribs: [Tensor<Float>], rightNodeContribs: [Tensor<Float>], splitTypes: [StringTensor], maxDepth: Tensor<Int32>, learningRate: Tensor<Float>, pruningMode: Tensor<Int32>, logitsDimension: Int64 = 1 )Parameters
tree_ensemble_handleHandle to the ensemble variable.
feature_idsRank 1 tensor with ids for each feature. This is the real id of the feature that will be used in the split.
dimension_idsList of rank 1 tensors representing the dimension in each feature.
node_idsList of rank 1 tensors representing the nodes for which this feature has a split.
gainsList of rank 1 tensors representing the gains for each of the feature’s split.
thresholdsList of rank 1 tensors representing the thesholds for each of the feature’s split.
left_node_contribsList of rank 2 tensors with left leaf contribs for each of the feature’s splits. Will be added to the previous node values to constitute the values of the left nodes.
right_node_contribsList of rank 2 tensors with right leaf contribs for each of the feature’s splits. Will be added to the previous node values to constitute the values of the right nodes.
split_typesList of rank 1 tensors representing the split type for each feature.
max_depthMax depth of the tree to build.
learning_rateshrinkage const for each new tree.
pruning_mode0-No pruning, 1-Pre-pruning, 2-Post-pruning.
-
Return the shape of s0 op s1 with broadcast.
Given
s0ands1, tensors that represent shapes, computer0, the broadcasted shape.s0,s1andr0are all integer vectors.Declaration
public static func broadcastArgs<T: TensorFlowIndex>( s0: Tensor<T>, s1: Tensor<T> ) -> Tensor<T> -
Return the reduction indices for computing gradients of s0 op s1 with broadcast.
This is typically used by gradient computations for a broadcasting operation.
Declaration
public static func broadcastGradientArgs<T: TensorFlowIndex>( s0: Tensor<T>, s1: Tensor<T> ) -> (r0: Tensor<T>, r1: Tensor<T>) -
Broadcast an array for a compatible shape.
Broadcasting is the process of making arrays to have compatible shapes for arithmetic operations. Two shapes are compatible if for each dimension pair they are either equal or one of them is one. When trying to broadcast a Tensor to a shape, it starts with the trailing dimensions, and works its way forward.
For example,
x = tf.constant([1, 2, 3]) y = tf.broadcast_to(x, [3, 3]) print(y) tf.Tensor( [[1 2 3] [1 2 3] [1 2 3]], shape=(3, 3), dtype=int32)
In the above example, the input Tensor with the shape of
[1, 3]is broadcasted to output Tensor with shape of[3, 3].Output output: A Tensor.
Declaration
public static func broadcastTo< T: TensorFlowScalar, Tidx: TensorFlowIndex >( _ input: Tensor<T>, shape: Tensor<Tidx> ) -> Tensor<T>Parameters
inputA Tensor to broadcast.
shapeAn 1-D
intTensor. The shape of the desired output. -
Bucketizes ‘input’ based on ‘boundaries’.
For example, if the inputs are boundaries = [0, 10, 100] input = [[-5, 10000] [150, 10] [5, 100]]
then the output will be output = [[0, 3] [3, 2] [1, 3]]
Attr boundaries: A sorted list of floats gives the boundary of the buckets.
Output output: Same shape with ‘input’, each value of input replaced with bucket index.
@compatibility(numpy) Equivalent to np.digitize. @end_compatibility
Declaration
public static func bucketize<T: TensorFlowNumeric>( _ input: Tensor<T>, boundaries: [Double] ) -> Tensor<Int32>Parameters
inputAny shape of Tensor contains with int or float type.
-
Records the bytes size of each element of
input_datasetin a StatsAggregator.Declaration
public static func bytesProducedStatsDataset( inputDataset: VariantHandle, tag: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Reads out the CSR components at batch
index.This op is meant only for debugging / testing, and its interface is not expected to be stable.
Outputs:
- row_ptrs: An array containing CSR matrix row pointers.
- col_inds: An array containing CSR matrix column indices.
- values: An array containing CSR matrix nonzero values.
Declaration
public static func cSRSparseMatrixComponents<Type: FloatingPoint & TensorFlowScalar>( csrSparseMatrix: VariantHandle, index: Tensor<Int32> ) -> (rowPtrs: Tensor<Int32>, colInds: Tensor<Int32>, values: Tensor<Type>)Parameters
csr_sparse_matrixA batched CSRSparseMatrix.
indexThe index in
csr_sparse_matrix‘s batch. -
Convert a (possibly batched) CSRSparseMatrix to dense.
Output dense_output: A dense tensor.
Declaration
public static func cSRSparseMatrixToDense<Type: FloatingPoint & TensorFlowScalar>( sparseInput: VariantHandle ) -> Tensor<Type>Parameters
sparse_inputA batched CSRSparseMatrix.
-
Converts a (possibly batched) CSRSparesMatrix to a SparseTensor.
Outputs:
- indices: SparseTensor indices.
- values: SparseTensor values.
- dense_shape: SparseTensor dense shape.
Declaration
public static func cSRSparseMatrixToSparseTensor<Type: FloatingPoint & TensorFlowScalar>( sparseMatrix: VariantHandle ) -> (indices: Tensor<Int64>, values: Tensor<Type>, denseShape: Tensor<Int64>)Parameters
sparse_matrixA (possibly batched) CSRSparseMatrix.
-
cSVDataset(filenames:compressionType:bufferSize:header:fieldDelim:useQuoteDelim:naValue:selectCols:recordDefaults:outputShapes:)
Declaration
public static func cSVDataset<OutputTypes: TensorArrayProtocol>( filenames: StringTensor, compressionType: StringTensor, bufferSize: Tensor<Int64>, header: Tensor<Bool>, fieldDelim: StringTensor, useQuoteDelim: Tensor<Bool>, naValue: StringTensor, selectCols: Tensor<Int64>, recordDefaults: OutputTypes, outputShapes: [TensorShape?] ) -> VariantHandle -
Performs beam search decoding on the logits given in input.
A note about the attribute merge_repeated: For the beam search decoder, this means that if consecutive entries in a beam are the same, only the first of these is emitted. That is, when the top path is “A B B B B”, “A B” is returned if merge_repeated = True but “A B B B B” is returned if merge_repeated = False.
Attrs:
- beam_width: A scalar >= 0 (beam search beam width).
- top_paths: A scalar >= 0, <= beam_width (controls output size).
- merge_repeated: If true, merge repeated classes in output.
Outputs:
- decoded_indices: A list (length: top_paths) of indices matrices. Matrix j,
size
(total_decoded_outputs[j] x 2), has indices of aSparseTensor<int64, 2>. The rows store: [batch, time]. - decoded_values: A list (length: top_paths) of values vectors. Vector j,
size
(length total_decoded_outputs[j]), has the values of aSparseTensor<int64, 2>. The vector stores the decoded classes for beam j. - decoded_shape: A list (length: top_paths) of shape vector. Vector j,
size
(2), stores the shape of the decodedSparseTensor[j]. Its values are:[batch_size, max_decoded_length[j]]. - log_probability: A matrix, shaped:
(batch_size x top_paths). The sequence log-probabilities.
- decoded_indices: A list (length: top_paths) of indices matrices. Matrix j,
size
Declaration
public static func cTCBeamSearchDecoder<T: FloatingPoint & TensorFlowScalar>( inputs: Tensor<T>, sequenceLength: Tensor<Int32>, beamWidth: Int64, topPaths: Int64, mergeRepeated: Bool = true ) -> ( decodedIndices: [Tensor<Int64>], decodedValues: [Tensor<Int64>], decodedShape: [Tensor<Int64>], logProbability: Tensor<T> )Parameters
inputs3-D, shape:
(max_time x batch_size x num_classes), the logits.sequence_lengthA vector containing sequence lengths, size
(batch). -
Performs greedy decoding on the logits given in inputs.
A note about the attribute merge_repeated: if enabled, when consecutive logits’ maximum indices are the same, only the first of these is emitted. Labeling the blank ‘*’, the sequence “A B B * B B” becomes “A B B” if merge_repeated = True and “A B B B B” if merge_repeated = False.
Regardless of the value of merge_repeated, if the maximum index of a given time and batch corresponds to the blank, index
(num_classes - 1), no new element is emitted.Attr merge_repeated: If True, merge repeated classes in output.
Outputs:
- decoded_indices: Indices matrix, size
(total_decoded_outputs x 2), of aSparseTensor<int64, 2>. The rows store: [batch, time]. - decoded_values: Values vector, size:
(total_decoded_outputs), of aSparseTensor<int64, 2>. The vector stores the decoded classes. - decoded_shape: Shape vector, size
(2), of the decoded SparseTensor. Values are:[batch_size, max_decoded_length]. - log_probability: Matrix, size
(batch_size x 1), containing sequence log-probabilities.
- decoded_indices: Indices matrix, size
Declaration
Parameters
inputs3-D, shape:
(max_time x batch_size x num_classes), the logits.sequence_lengthA vector containing sequence lengths, size
(batch_size). -
cTCLoss(inputs:labelsIndices:labelsValues:sequenceLength:preprocessCollapseRepeated:ctcMergeRepeated:ignoreLongerOutputsThanInputs:)
Calculates the CTC Loss (log probability) for each batch entry. Also calculates
the gradient. This class performs the softmax operation for you, so inputs should be e.g. linear projections of outputs by an LSTM.
Attrs:
- preprocess_collapse_repeated: Scalar, if true then repeated labels are collapsed prior to the CTC calculation.
- ctc_merge_repeated: Scalar. If set to false, during CTC calculation repeated non-blank labels will not be merged and are interpreted as individual labels. This is a simplified version of CTC.
- ignore_longer_outputs_than_inputs: Scalar. If set to true, during CTC calculation, items that have longer output sequences than input sequences are skipped: they don’t contribute to the loss term and have zero-gradient.
Outputs:
- loss: A vector (batch) containing log-probabilities.
- gradient: The gradient of
loss. 3-D, shape:(max_time x batch_size x num_classes).
Declaration
public static func cTCLoss<T: FloatingPoint & TensorFlowScalar>( inputs: Tensor<T>, labelsIndices: Tensor<Int64>, labelsValues: Tensor<Int32>, sequenceLength: Tensor<Int32>, preprocessCollapseRepeated: Bool = false, ctcMergeRepeated: Bool = true, ignoreLongerOutputsThanInputs: Bool = false ) -> (loss: Tensor<T>, gradient: Tensor<T>)Parameters
inputs3-D, shape:
(max_time x batch_size x num_classes), the logits.labels_indicesThe indices of a
SparseTensor<int32, 2>.labels_indices(i, :) == [b, t]meanslabels_values(i)stores the id for(batch b, time t).labels_valuesThe values (labels) associated with the given batch and time.
sequence_lengthA vector containing sequence lengths (batch).
-
Creates a dataset that caches elements from
input_dataset.A CacheDataset will iterate over the input_dataset, and store tensors. If the cache already exists, the cache will be used. If the cache is inappropriate (e.g. cannot be opened, contains tensors of the wrong shape / size), an error will the returned when used.
Declaration
public static func cacheDataset( inputDataset: VariantHandle, filename: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
filenameA path on the filesystem where we should cache the dataset. Note: this will be a directory.
-
Declaration
public static func cacheDatasetV2( inputDataset: VariantHandle, filename: StringTensor, cache: ResourceHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Cast x of type SrcT to y of DstT.
Declaration
public static func cast< Srct: TensorFlowScalar, Dstt: TensorFlowScalar >( _ x: Tensor<Srct>, truncate: Bool = false ) -> Tensor<Dstt> -
Returns element-wise smallest integer not less than x.
Declaration
public static func ceil<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Checks a tensor for NaN and Inf values.
When run, reports an
InvalidArgumenterror iftensorhas any values that are not a number (NaN) or infinity (Inf). Otherwise, passestensoras-is.- Attr message: Prefix of the error message.
Declaration
public static func checkNumerics<T: FloatingPoint & TensorFlowScalar>( _ tensor: Tensor<T>, message: String ) -> Tensor<T> -
Computes the Cholesky decomposition of one or more square matrices.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices.The input has to be symmetric and positive definite. Only the lower-triangular part of the input will be used for this operation. The upper-triangular part will not be read.
The output is a tensor of the same shape as the input containing the Cholesky decompositions for all input submatrices
[..., :, :].Note: The gradient computation on GPU is faster for large matrices but not for large batch dimensions when the submatrices are small. In this case it might be faster to use the CPU.
Output output: Shape is
[..., M, M].
Declaration
public static func cholesky<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Computes the reverse mode backpropagated gradient of the Cholesky algorithm.
For an explanation see “Differentiation of the Cholesky algorithm” by Iain Murray http://arxiv.org/abs/1602.07527.
Output output: Symmetrized version of df/dA . Shape is
[..., M, M]
Declaration
public static func choleskyGrad<T: FloatingPoint & TensorFlowScalar>( l: Tensor<T>, grad: Tensor<T> ) -> Tensor<T>Parameters
lOutput of batch Cholesky algorithm l = cholesky(A). Shape is
[..., M, M]. Algorithm depends only on lower triangular part of the innermost matrices of this tensor.graddf/dl where f is some scalar function. Shape is
[..., M, M]. Algorithm depends only on lower triangular part of the innermost matrices of this tensor. -
Declaration
public static func chooseFastestDataset( inputDatasets: [VariantHandle], numExperiments: Int64, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Clips tensor values to a specified min and max.
Given a tensor
t, this operation returns a tensor of the same type and shape astwith its values clipped toclip_value_minandclip_value_max. Any values less thanclip_value_minare set toclip_value_min. Any values greater thanclip_value_maxare set toclip_value_max.Output output: A clipped
Tensorwith the same shape as input ‘t’.
Declaration
public static func clipByValue<T: TensorFlowNumeric>( t: Tensor<T>, clipValueMin: Tensor<T>, clipValueMax: Tensor<T> ) -> Tensor<T> -
Declaration
public static func closeSummaryWriter( writer: ResourceHandle ) -
Receives a tensor value broadcast from another device.
Declaration
public static func collectiveBcastRecv<T: TensorFlowNumeric>( groupSize: Int64, groupKey: Int64, instanceKey: Int64, shape: TensorShape?, communicationHint: String = "auto" ) -> Tensor<T> -
Broadcasts a tensor value to one or more other devices.
Declaration
public static func collectiveBcastSend<T: TensorFlowNumeric>( _ input: Tensor<T>, groupSize: Int64, groupKey: Int64, instanceKey: Int64, shape: TensorShape?, communicationHint: String = "auto" ) -> Tensor<T> -
Mutually accumulates multiple tensors of identical type and shape.
Declaration
public static func collectiveGather<T: TensorFlowNumeric>( _ input: Tensor<T>, groupSize: Int64, groupKey: Int64, instanceKey: Int64, shape: TensorShape?, communicationHint: String = "auto" ) -> Tensor<T> -
An Op to permute tensors across replicated TPU instances.
Each instance supplies its own input.
For example, suppose there are 4 TPU instances:
[A, B, C, D]. Passing source_target_pairs=[[0,1],[1,2],[2,3],[3,0]]gets the outputs:[D, A, B, C].Attr T: The type of elements to be exchanged.
Output output: The permuted input.
Declaration
public static func collectivePermute<T: TensorFlowNumeric>( _ input: Tensor<T>, sourceTargetPairs: Tensor<Int32> ) -> Tensor<T>Parameters
inputThe local input to be permuted. Currently only supports float and bfloat16.
source_target_pairsA tensor with shape [num_pairs, 2].
-
collectiveReduce(_:groupSize:groupKey:instanceKey:mergeOp:finalOp:subdivOffsets:waitFor:communicationHint:)
Mutually reduces multiple tensors of identical type and shape.
Declaration
public static func collectiveReduce<T: TensorFlowNumeric>( _ input: Tensor<T>, groupSize: Int64, groupKey: Int64, instanceKey: Int64, mergeOp: MergeOp, finalOp: FinalOp, subdivOffsets: [Int32], waitFor: [Int32], communicationHint: String = "auto" ) -> Tensor<T> -
combinedNonMaxSuppression(boxes:scores:maxOutputSizePerClass:maxTotalSize:iouThreshold:scoreThreshold:padPerClass:clipBoxes:)
Greedily selects a subset of bounding boxes in descending order of score,
This operation performs non_max_suppression on the inputs per batch, across all classes. Prunes away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system. Also note that this algorithm is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is the final boxes, scores and classes tensor returned after performing non_max_suppression.
Attrs:
- pad_per_class: If false, the output nmsed boxes, scores and classes
are padded/clipped to
max_total_size. If true, the output nmsed boxes, scores and classes are padded to be of lengthmax_size_per_class*num_classes, unless it exceedsmax_total_sizein which case it is clipped tomax_total_size. Defaults to false. - clip_boxes: If true, assume the box coordinates are between [0, 1] and clip the output boxes if they fall beyond [0, 1]. If false, do not do clipping and output the box coordinates as it is.
- pad_per_class: If false, the output nmsed boxes, scores and classes
are padded/clipped to
Outputs:
- nmsed_boxes: A [batch_size, max_detections, 4] float32 tensor containing the non-max suppressed boxes.
- nmsed_scores: A [batch_size, max_detections] float32 tensor containing the scores for the boxes.
- nmsed_classes: A [batch_size, max_detections] float32 tensor containing the classes for the boxes.
- valid_detections: A [batch_size] int32 tensor indicating the number of valid detections per batch item. Only the top num_detections[i] entries in nms_boxes[i], nms_scores[i] and nms_class[i] are valid. The rest of the entries are zero paddings.
Declaration
public static func combinedNonMaxSuppression( boxes: Tensor<Float>, scores: Tensor<Float>, maxOutputSizePerClass: Tensor<Int32>, maxTotalSize: Tensor<Int32>, iouThreshold: Tensor<Float>, scoreThreshold: Tensor<Float>, padPerClass: Bool = false, clipBoxes: Bool = true ) -> ( nmsedBoxes: Tensor<Float>, nmsedScores: Tensor<Float>, nmsedClasses: Tensor<Float>, validDetections: Tensor<Int32> )Parameters
boxesA 4-D float tensor of shape
[batch_size, num_boxes, q, 4]. Ifqis 1 then same boxes are used for all classes otherwise, ifqis equal to number of classes, class-specific boxes are used.scoresA 3-D float tensor of shape
[batch_size, num_boxes, num_classes]representing a single score corresponding to each box (each row of boxes).max_output_size_per_classA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression per class
max_total_sizeA scalar representing maximum number of boxes retained over all classes.
iou_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too much with respect to IOU.
score_thresholdA 0-D float tensor representing the threshold for deciding when to remove boxes based on score.
-
Compare values of
inputtothresholdand pack resulting bits into auint8.Each comparison returns a boolean
true(ifinput_value > threshold) or andfalseotherwise.This operation is useful for Locality-Sensitive-Hashing (LSH) and other algorithms that use hashing approximations of cosine and
L2distances; codes can be generated from an input via:codebook_size = 50 codebook_bits = codebook_size * 32 codebook = tf.get_variable('codebook', [x.shape[-1].value, codebook_bits], dtype=x.dtype, initializer=tf.orthogonal_initializer()) codes = compare_and_threshold(tf.matmul(x, codebook), threshold=0.) codes = tf.bitcast(codes, tf.int32) # go from uint8 to int32 # now codes has shape x.shape[:-1] + [codebook_size]NOTE: Currently, the innermost dimension of the tensor must be divisible by 8.
Given an
inputshaped[s0, s1, ..., s_n], the output is auint8tensor shaped[s0, s1, ..., s_n / 8].Attr T: The type of the input and threshold.
Output output: The bitpacked comparisons.
Declaration
public static func compareAndBitpack<T: TensorFlowScalar>( _ input: Tensor<T>, threshold: Tensor<T> ) -> Tensor<UInt8>Parameters
inputValues to compare against
thresholdand bitpack.thresholdThreshold to compare against.
-
Converts two real numbers to a complex number.
Given a tensor
realrepresenting the real part of a complex number, and a tensorimagrepresenting the imaginary part of a complex number, this operation returns complex numbers elementwise of the form \(a + bj\), where a represents therealpart and b represents theimagpart.The input tensors
realandimagmust have the same shape.For example:
# tensor 'real' is [2.25, 3.25] # tensor `imag` is [4.75, 5.75] tf.complex(real, imag) ==> [[2.25 + 4.75j], [3.25 + 5.75j]]Declaration
public static func complex< T: FloatingPoint & TensorFlowScalar, Tout: TensorFlowScalar >( real: Tensor<T>, imag: Tensor<T> ) -> Tensor<Tout> -
Computes the complex absolute value of a tensor.
Given a tensor
xof complex numbers, this operation returns a tensor of typefloatordoublethat is the absolute value of each element inx. All elements inxmust be complex numbers of the form \(a + bj\). The absolute value is computed as \( \sqrt{a^2 + b^2}\).Declaration
public static func complexAbs< T: TensorFlowScalar, Tout: FloatingPoint & TensorFlowScalar >( _ x: Tensor<T> ) -> Tensor<Tout> -
Declaration
public static func complexStruct<TC: TensorGroup>( nA: Int64, nB: Int64 ) -> (a: [Tensor<Int32>], b: [Tensor<Int64>], c: TC) -
Computes the ids of the positions in sampled_candidates that match true_labels.
When doing log-odds NCE, the result of this op should be passed through a SparseToDense op, then added to the logits of the sampled candidates. This has the effect of ‘removing’ the sampled labels that match the true labels by making the classifier sure that they are sampled labels.
Attrs:
- num_true: Number of true labels per context.
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- indices: A vector of indices corresponding to rows of true_candidates.
- ids: A vector of IDs of positions in sampled_candidates that match a true_label for the row with the corresponding index in indices.
- weights: A vector of the same length as indices and ids, in which each element is -FLOAT_MAX.
Declaration
Parameters
true_classesThe true_classes output of UnpackSparseLabels.
sampled_candidatesThe sampled_candidates output of CandidateSampler.
-
Concatenates tensors along one dimension.
Output output: A
Tensorwith the concatenation of values stacked along theconcat_dimdimension. This tensor’s shape matches that ofvaluesexcept inconcat_dimwhere it has the sum of the sizes.
Declaration
public static func concat<T: TensorFlowScalar>( concatDim: Tensor<Int32>, _ values: [Tensor<T>] ) -> Tensor<T>Parameters
concat_dim0-D. The dimension along which to concatenate. Must be in the range [0, rank(values)).
valuesThe
NTensors to concatenate. Their ranks and types must match, and their sizes must match in all dimensions exceptconcat_dim. -
Computes offsets of concat inputs within its output.
For example:
# 'x' is [2, 2, 7] # 'y' is [2, 3, 7] # 'z' is [2, 5, 7] concat_offset(2, [x, y, z]) => [0, 0, 0], [0, 2, 0], [0, 5, 0]This is typically used by gradient computations for a concat operation.
Output offset: The
Nint32 vectors representing the starting offset of input tensors within the concatenated output.
Declaration
Parameters
concat_dimThe dimension along which to concatenate.
shapeThe
Nint32 vectors representing shape of tensors being concatenated. -
Concatenates tensors along one dimension.
Output output: A
Tensorwith the concatenation of values stacked along theconcat_dimdimension. This tensor’s shape matches that ofvaluesexcept inconcat_dimwhere it has the sum of the sizes.
Declaration
public static func concatV2< T: TensorFlowScalar, Tidx: TensorFlowIndex >( _ values: [Tensor<T>], axis: Tensor<Tidx> ) -> Tensor<T>Parameters
valuesList of
NTensors to concatenate. Their ranks and types must match, and their sizes must match in all dimensions exceptconcat_dim.axis0-D. The dimension along which to concatenate. Must be in the range [-rank(values), rank(values)).
-
Creates a dataset that concatenates
input_datasetwithanother_dataset.Declaration
public static func concatenateDataset( inputDataset: VariantHandle, anotherDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
configureDistributedTPU(embeddingConfig:tpuEmbeddingConfig:isGlobalInit:enableWholeMeshCompilations:compilationFailureClosesChips:)
Sets up the centralized structures for a distributed TPU system.
Attrs:
- embedding_config: Reserved. Do not use.
- tpu_embedding_config: Serialized tensorflow.tpu.TPUEmbeddingConfiguration that describes the embedding lookups of the program.
- is_global_init: Reserved. Do not use.
Output topology: A serialized tensorflow.tpu.TopologyProto that describes the TPU topology.
Declaration
public static func configureDistributedTPU( embeddingConfig: String, tpuEmbeddingConfig: String, isGlobalInit: Bool = false, enableWholeMeshCompilations: Bool = false, compilationFailureClosesChips: Bool = true ) -> StringTensor -
Sets up TPUEmbedding in a distributed TPU system.
- Attr config: Serialized tensorflow.tpu.TPUEmbeddingConfiguration that describes the embedding lookups of the program.
Declaration
public static func configureTPUEmbedding( config: String ) -
Returns the complex conjugate of a complex number.
Given a tensor
inputof complex numbers, this operation returns a tensor of complex numbers that are the complex conjugate of each element ininput. The complex numbers ininputmust be of the form \(a + bj\), where a is the real part and b is the imaginary part.The complex conjugate returned by this operation is of the form \(a - bj\).
For example:
# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.conj(input) ==> [-2.25 - 4.75j, 3.25 - 5.75j]Declaration
public static func conj<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Shuffle dimensions of x according to a permutation and conjugate the result.
The output
yhas the same rank asx. The shapes ofxandysatisfy:y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]y[i,j,k,...,s,t,u] == conj(x[perm[i], perm[j], perm[k],...,perm[s], perm[t], perm[u]])Declaration
public static func conjugateTranspose< T: TensorFlowScalar, Tperm: TensorFlowIndex >( _ x: Tensor<T>, perm: Tensor<Tperm> ) -> Tensor<T> -
Declaration
public static func constructionFails() -
This op consumes a lock created by
MutexLock.This op exists to consume a tensor created by
MutexLock(other than direct control dependencies). It should be the only that consumes the tensor, and will raise an error if it is not. Its only purpose is to keep the mutex lock tensor alive until it is consumed by this op.NOTE: This operation must run on the same device as its input. This may be enforced via the
colocate_withmechanism.Declaration
public static func consumeMutexLock( mutexLock: VariantHandle )Parameters
mutex_lockA tensor returned by
MutexLock. -
Does nothing. Serves as a control trigger for scheduling.
Only useful as a placeholder for control edges.
Declaration
public static func controlTrigger() -
Computes a 2-D convolution given 4-D
inputandfiltertensors.Given an input tensor of shape
[batch, in_height, in_width, in_channels]and a filter / kernel tensor of shape[filter_height, filter_width, in_channels, out_channels], this op performs the following:- Flattens the filter to a 2-D matrix with shape
[filter_height * filter_width * in_channels, output_channels]. - Extracts image patches from the input tensor to form a virtual
tensor of shape
[batch, out_height, out_width, filter_height * filter_width * in_channels]. - For each patch, right-multiplies the filter matrix and the image patch vector.
In detail, with the default NHWC format,
output[b, i, j, k] = sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] * filter[di, dj, q, k]Must have
strides[0] = strides[3] = 1. For the most common case of the same horizontal and vertices strides,strides = [1, stride, stride, 1].Attrs:
- strides: 1-D tensor of length 4. The stride of the sliding window for each
dimension of
input. The dimension order is determined by the value ofdata_format, see below for details. - padding: The type of padding algorithm to use.
- explicit_paddings: If
paddingis"EXPLICIT", the list of explicit padding amounts. For the ith dimension, the amount of padding inserted before and after the dimension isexplicit_paddings[2 * i]andexplicit_paddings[2 * i + 1], respectively. Ifpaddingis not"EXPLICIT",explicit_paddingsmust be empty. - data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, height, width, channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, channels, height, width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
- strides: 1-D tensor of length 4. The stride of the sliding window for each
dimension of
Output output: A 4-D tensor. The dimension order is determined by the value of
data_format, see below for details.
Declaration
public static func conv2D<T: TensorFlowNumeric>( _ input: Tensor<T>, filter: Tensor<T>, strides: [Int32], useCudnnOnGpu: Bool = true, padding: Padding2, explicitPaddings: [Int32], dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T>Parameters
inputA 4-D tensor. The dimension order is interpreted according to the value of
data_format, see below for details.filterA 4-D tensor of shape
[filter_height, filter_width, in_channels, out_channels] - Flattens the filter to a 2-D matrix with shape
-
conv2DBackpropFilter(_:filterSizes:outBackprop:strides:useCudnnOnGpu:padding:explicitPaddings:dataFormat:dilations:)
Computes the gradients of convolution with respect to the filter.
Attrs:
- strides: The stride of the sliding window for each dimension of the input of the convolution. Must be in the same order as the dimension specified with format.
- padding: The type of padding algorithm to use.
- explicit_paddings: If
paddingis"EXPLICIT", the list of explicit padding amounts. For the ith dimension, the amount of padding inserted before and after the dimension isexplicit_paddings[2 * i]andexplicit_paddings[2 * i + 1], respectively. Ifpaddingis not"EXPLICIT",explicit_paddingsmust be empty. - data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
Output output: 4-D with shape
[filter_height, filter_width, in_channels, out_channels]. Gradient w.r.t. thefilterinput of the convolution.
Declaration
public static func conv2DBackpropFilter<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, filterSizes: Tensor<Int32>, outBackprop: Tensor<T>, strides: [Int32], useCudnnOnGpu: Bool = true, padding: Padding2, explicitPaddings: [Int32], dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T>Parameters
input4-D with shape
[batch, in_height, in_width, in_channels].filter_sizesAn integer vector representing the tensor shape of
filter, wherefilteris a 4-D[filter_height, filter_width, in_channels, out_channels]tensor.out_backprop4-D with shape
[batch, out_height, out_width, out_channels]. Gradients w.r.t. the output of the convolution. -
conv2DBackpropInput(inputSizes:filter:outBackprop:strides:useCudnnOnGpu:padding:explicitPaddings:dataFormat:dilations:)
Computes the gradients of convolution with respect to the input.
Attrs:
- strides: The stride of the sliding window for each dimension of the input of the convolution. Must be in the same order as the dimension specified with format.
- padding: The type of padding algorithm to use.
- explicit_paddings: If
paddingis"EXPLICIT", the list of explicit padding amounts. For the ith dimension, the amount of padding inserted before and after the dimension isexplicit_paddings[2 * i]andexplicit_paddings[2 * i + 1], respectively. Ifpaddingis not"EXPLICIT",explicit_paddingsmust be empty. - data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
Output output: 4-D with shape
[batch, in_height, in_width, in_channels]. Gradient w.r.t. the input of the convolution.
Declaration
public static func conv2DBackpropInput<T: TensorFlowNumeric>( inputSizes: Tensor<Int32>, filter: Tensor<T>, outBackprop: Tensor<T>, strides: [Int32], useCudnnOnGpu: Bool = true, padding: Padding2, explicitPaddings: [Int32], dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T>Parameters
input_sizesAn integer vector representing the shape of
input, whereinputis a 4-D[batch, height, width, channels]tensor.filter4-D with shape
[filter_height, filter_width, in_channels, out_channels].out_backprop4-D with shape
[batch, out_height, out_width, out_channels]. Gradients w.r.t. the output of the convolution. -
Computes a 3-D convolution given 5-D
inputandfiltertensors.In signal processing, cross-correlation is a measure of similarity of two waveforms as a function of a time-lag applied to one of them. This is also known as a sliding dot product or sliding inner-product.
Our Conv3D implements a form of cross-correlation.
Attrs:
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- dilations: 1-D tensor of length 5. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
Declaration
public static func conv3D<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, filter: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc, dilations: [Int32] = [1, 1, 1, 1, 1] ) -> Tensor<T>Parameters
inputShape
[batch, in_depth, in_height, in_width, in_channels].filterShape
[filter_depth, filter_height, filter_width, in_channels, out_channels].in_channelsmust match betweeninputandfilter. -
Computes the gradients of 3-D convolution with respect to the filter.
Attrs:
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
Declaration
Parameters
inputShape
[batch, depth, rows, cols, in_channels].filterShape
[depth, rows, cols, in_channels, out_channels].in_channelsmust match betweeninputandfilter.out_backpropBackprop signal of shape
[batch, out_depth, out_rows, out_cols, out_channels]. -
Computes the gradients of 3-D convolution with respect to the filter.
Attrs:
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- dilations: 1-D tensor of length 5. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
Declaration
public static func conv3DBackpropFilterV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, filterSizes: Tensor<Int32>, outBackprop: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc, dilations: [Int32] = [1, 1, 1, 1, 1] ) -> Tensor<T>Parameters
inputShape
[batch, depth, rows, cols, in_channels].filter_sizesAn integer vector representing the tensor shape of
filter, wherefilteris a 5-D[filter_depth, filter_height, filter_width, in_channels, out_channels]tensor.out_backpropBackprop signal of shape
[batch, out_depth, out_rows, out_cols, out_channels]. -
Computes the gradients of 3-D convolution with respect to the input.
Attrs:
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
Declaration
Parameters
inputShape
[batch, depth, rows, cols, in_channels].filterShape
[depth, rows, cols, in_channels, out_channels].in_channelsmust match betweeninputandfilter.out_backpropBackprop signal of shape
[batch, out_depth, out_rows, out_cols, out_channels]. -
Computes the gradients of 3-D convolution with respect to the input.
Attrs:
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- dilations: 1-D tensor of length 5. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
- strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
Declaration
public static func conv3DBackpropInputV2< T: FloatingPoint & TensorFlowScalar, Tshape: TensorFlowIndex >( inputSizes: Tensor<Tshape>, filter: Tensor<T>, outBackprop: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc, dilations: [Int32] = [1, 1, 1, 1, 1] ) -> Tensor<T>Parameters
input_sizesAn integer vector representing the tensor shape of
input, whereinputis a 5-D[batch, depth, rows, cols, in_channels]tensor.filterShape
[depth, rows, cols, in_channels, out_channels].in_channelsmust match betweeninputandfilter.out_backpropBackprop signal of shape
[batch, out_depth, out_rows, out_cols, out_channels]. -
Copy a tensor from CPU-to-CPU or GPU-to-GPU.
Performs CPU-to-CPU or GPU-to-GPU deep-copying of tensor, depending on the device on which the tensor is allocated. N.B.: If the all downstream attached debug ops are disabled given the current gRPC gating status, the output will simply forward the input tensor without deep-copying. See the documentation of Debug* ops for more details.
Unlike the CopyHost Op, this op does not have HostMemory constraint on its input or output.
Attrs:
- tensor_name: The name of the input tensor.
- debug_ops_spec: A list of debug op spec (op, url, gated_grpc) for attached debug
ops. Each element of the list has the format
; ; , wherein gated_grpc is boolean represented as 0/1. E.g., “DebugIdentity;grpc://foo:3333;1”, “DebugIdentity;file:///tmp/tfdbg_1;0”.
Declaration
public static func copy<T: TensorFlowScalar>( _ input: Tensor<T>, tensorName: String, debugOpsSpec: [String] ) -> Tensor<T>Parameters
inputInput tensor.
-
Copy a tensor to host.
Performs CPU-to-CPU deep-copying of tensor. N.B.: If the all downstream attached debug ops are disabled given the current gRPC gating status, the output will simply forward the input tensor without deep-copying. See the documentation of Debug* ops for more details.
Unlike the Copy Op, this op has HostMemory constraint on its input or output.
Attrs:
- tensor_name: The name of the input tensor.
- debug_ops_spec: A list of debug op spec (op, url, gated_grpc) for attached debug
ops. Each element of the list has the format
; ; , wherein gated_grpc is boolean represented as 0/1. E.g., “DebugIdentity;grpc://foo:3333;1”, “DebugIdentity;file:///tmp/tfdbg_1;0”.
Declaration
public static func copyHost<T: TensorFlowScalar>( _ input: Tensor<T>, tensorName: String, debugOpsSpec: [String] ) -> Tensor<T>Parameters
inputInput tensor.
-
Declaration
public static func copyOp<T: TensorFlowScalar>( _ a: Tensor<T> ) -> Tensor<T> -
Computes cos of x element-wise.
Given an input tensor, this function computes cosine of every element in the tensor. Input range is
(-inf, inf)and output range is[-1,1]. If input lies outside the boundary,nanis returned.x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10000, float("inf")]) tf.math.cos(x) ==> [nan -0.91113025 0.87758255 0.5403023 0.36235774 0.48718765 -0.95215535 nan]Declaration
public static func cos<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes hyperbolic cosine of x element-wise.
Given an input tensor, this function computes hyperbolic cosine of every element in the tensor. Input range is
[-inf, inf]and output range is[1, inf].x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 2, 10, float("inf")]) tf.math.cosh(x) ==> [inf 4.0515420e+03 1.1276259e+00 1.5430807e+00 1.8106556e+00 3.7621956e+00 1.1013233e+04 inf]Declaration
public static func cosh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Declaration
public static func createSummaryDbWriter( writer: ResourceHandle, dbUri: StringTensor, experimentName: StringTensor, runName: StringTensor, userName: StringTensor ) -
Declaration
public static func createSummaryFileWriter( writer: ResourceHandle, logdir: StringTensor, maxQueue: Tensor<Int32>, flushMillis: Tensor<Int32>, filenameSuffix: StringTensor ) -
Extracts crops from the input image tensor and resizes them.
Extracts crops from the input image tensor and resizes them using bilinear sampling or nearest neighbor sampling (possibly with aspect ratio change) to a common output size specified by
crop_size. This is more general than thecrop_to_bounding_boxop which extracts a fixed size slice from the input image and does not allow resizing or aspect ratio change.Returns a tensor with
cropsfrom the inputimageat positions defined at the bounding box locations inboxes. The cropped boxes are all resized (with bilinear or nearest neighbor interpolation) to a fixedsize = [crop_height, crop_width]. The result is a 4-D tensor[num_boxes, crop_height, crop_width, depth]. The resizing is corner aligned. In particular, ifboxes = [[0, 0, 1, 1]], the method will give identical results to usingtf.image.resize_bilinear()ortf.image.resize_nearest_neighbor()(depends on themethodargument) withalign_corners=True.Attrs:
- method: A string specifying the sampling method for resizing. It can be either
"bilinear"or"nearest"and default to"bilinear". Currently two sampling methods are supported: Bilinear and Nearest Neighbor. - extrapolation_value: Value used for extrapolation, when applicable.
- method: A string specifying the sampling method for resizing. It can be either
Output crops: A 4-D tensor of shape
[num_boxes, crop_height, crop_width, depth].
Declaration
Parameters
imageA 4-D tensor of shape
[batch, image_height, image_width, depth]. Bothimage_heightandimage_widthneed to be positive.boxesA 2-D tensor of shape
[num_boxes, 4]. Thei-th row of the tensor specifies the coordinates of a box in thebox_ind[i]image and is specified in normalized coordinates[y1, x1, y2, x2]. A normalized coordinate value ofyis mapped to the image coordinate aty * (image_height - 1), so as the[0, 1]interval of normalized image height is mapped to[0, image_height - 1]in image height coordinates. We do allowy1>y2, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the[0, 1]range are allowed, in which case we useextrapolation_valueto extrapolate the input image values.box_indA 1-D tensor of shape
[num_boxes]with int32 values in[0, batch). The value ofbox_ind[i]specifies the image that thei-th box refers to.crop_sizeA 1-D tensor of 2 elements,
size = [crop_height, crop_width]. All cropped image patches are resized to this size. The aspect ratio of the image content is not preserved. Bothcrop_heightandcrop_widthneed to be positive. -
Computes the gradient of the crop_and_resize op wrt the input boxes tensor.
Attr method: A string specifying the interpolation method. Only ‘bilinear’ is supported for now.
Output output: A 2-D tensor of shape
[num_boxes, 4].
Declaration
Parameters
gradsA 4-D tensor of shape
[num_boxes, crop_height, crop_width, depth].imageA 4-D tensor of shape
[batch, image_height, image_width, depth]. Bothimage_heightandimage_widthneed to be positive.boxesA 2-D tensor of shape
[num_boxes, 4]. Thei-th row of the tensor specifies the coordinates of a box in thebox_ind[i]image and is specified in normalized coordinates[y1, x1, y2, x2]. A normalized coordinate value ofyis mapped to the image coordinate aty * (image_height - 1), so as the[0, 1]interval of normalized image height is mapped to[0, image_height - 1] in image height coordinates. We do allow y1 > y2, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the[0, 1]range are allowed, in which case we useextrapolation_value` to extrapolate the input image values.box_indA 1-D tensor of shape
[num_boxes]with int32 values in[0, batch). The value ofbox_ind[i]specifies the image that thei-th box refers to. -
Computes the gradient of the crop_and_resize op wrt the input image tensor.
Attr method: A string specifying the interpolation method. Only ‘bilinear’ is supported for now.
Output output: A 4-D tensor of shape
[batch, image_height, image_width, depth].
Declaration
Parameters
gradsA 4-D tensor of shape
[num_boxes, crop_height, crop_width, depth].boxesA 2-D tensor of shape
[num_boxes, 4]. Thei-th row of the tensor specifies the coordinates of a box in thebox_ind[i]image and is specified in normalized coordinates[y1, x1, y2, x2]. A normalized coordinate value ofyis mapped to the image coordinate aty * (image_height - 1), so as the[0, 1]interval of normalized image height is mapped to[0, image_height - 1] in image height coordinates. We do allow y1 > y2, in which case the sampled crop is an up-down flipped version of the original image. The width dimension is treated similarly. Normalized coordinates outside the[0, 1]range are allowed, in which case we useextrapolation_value` to extrapolate the input image values.box_indA 1-D tensor of shape
[num_boxes]with int32 values in[0, batch). The value ofbox_ind[i]specifies the image that thei-th box refers to.image_sizeA 1-D tensor with value
[batch, image_height, image_width, depth]containing the original image size. Bothimage_heightandimage_widthneed to be positive. -
Compute the pairwise cross product.
aandbmust be the same shape; they can either be simple 3-element vectors, or any shape where the innermost dimension is 3. In the latter case, each pair of corresponding 3-element vectors is cross-multiplied independently.Output product: Pairwise cross product of the vectors in
aandb.
Declaration
public static func cross<T: TensorFlowNumeric>( _ a: Tensor<T>, _ b: Tensor<T> ) -> Tensor<T>Parameters
aA tensor containing 3-element vectors.
bAnother tensor, of same type and shape as
a. -
An Op to sum inputs across replicated TPU instances.
Each instance supplies its own input.
For example, suppose there are 8 TPU instances:
[A, B, C, D, E, F, G, H]. Passing group_assignment=[[0,2,4,6],[1,3,5,7]]setsA, C, E, Gas group 0, andB, D, F, Has group 1. Thus we get the outputs:[A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H, A+C+E+G, B+D+F+H].Attr T: The type of elements to be summed.
Output output: The sum of all the distributed inputs.
Declaration
public static func crossReplicaSum<T: TensorFlowNumeric>( _ input: Tensor<T>, groupAssignment: Tensor<Int32> ) -> Tensor<T>Parameters
inputThe local input to the sum.
group_assignmentAn int32 tensor with shape [num_groups, num_replicas_per_group].
group_assignment[i]represents the replica ids in the ith subgroup. -
A RNN backed by cuDNN.
Computes the RNN from the input and initial states, with respect to the params buffer.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: A 3-D tensor with the shape of [seq_length, batch_size, input_size]. input_h: A 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore output: A 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. is_training: Indicates whether this operation is used for inferenece or training. reserve_space: An opaque tensor that can be used in backprop calculation. It is only produced if is_training is false.
Declaration
public static func cudnnRNN<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, isTraining: Bool = true ) -> (output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, reserveSpace: Tensor<T>) -
cudnnRNNBackprop(_:inputH:inputC:params:output:outputH:outputC:outputBackprop:outputHBackprop:outputCBackprop:reserveSpace:rnnMode:inputMode:direction:dropout:seed:seed2:)
Backprop step of CudnnRNN.
Compute the backprop of both data and weights in a RNN.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: A 3-D tensor with the shape of [seq_length, batch_size, input_size]. input_h: A 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore output: A 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. output_backprop: A 3-D tensor with the same shape as output in the forward pass. output_h_backprop: A 3-D tensor with the same shape as output_h in the forward pass. output_c_backprop: A 3-D tensor with the same shape as output_c in the forward pass. reserve_space: The same reserve_space produced in for forward operation. input_backprop: The backprop to input in the forward pass. Has the same shape as input. input_h_backprop: The backprop to input_h in the forward pass. Has the same shape as input_h. input_c_backprop: The backprop to input_c in the forward pass. Has the same shape as input_c. params_backprop: The backprop to the params buffer in the forward pass. Has the same shape as params.
Declaration
public static func cudnnRNNBackprop<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, outputBackprop: Tensor<T>, outputHBackprop: Tensor<T>, outputCBackprop: Tensor<T>, reserveSpace: Tensor<T>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0 ) -> ( inputBackprop: Tensor<T>, inputHBackprop: Tensor<T>, inputCBackprop: Tensor<T>, paramsBackprop: Tensor<T> ) -
cudnnRNNBackpropV2(_:inputH:inputC:params:output:outputH:outputC:outputBackprop:outputHBackprop:outputCBackprop:reserveSpace:hostReserved:rnnMode:inputMode:direction:dropout:seed:seed2:)
Backprop step of CudnnRNN.
Compute the backprop of both data and weights in a RNN. Takes an extra “host_reserved” inupt than CudnnRNNBackprop, which is used to determine RNN cudnnRNNAlgo_t and cudnnMathType_t.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicates whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: A 3-D tensor with the shape of [seq_length, batch_size, input_size]. input_h: A 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore output: A 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. output_backprop: A 3-D tensor with the same shape as output in the forward pass. output_h_backprop: A 3-D tensor with the same shape as output_h in the forward pass. output_c_backprop: A 3-D tensor with the same shape as output_c in the forward pass. reserve_space: The same reserve_space produced in the forward operation. host_reserved: The same host_reserved produced in the forward operation. input_backprop: The backprop to input in the forward pass. Has the same shape as input. input_h_backprop: The backprop to input_h in the forward pass. Has the same shape as input_h. input_c_backprop: The backprop to input_c in the forward pass. Has the same shape as input_c. params_backprop: The backprop to the params buffer in the forward pass. Has the same shape as params.
Declaration
public static func cudnnRNNBackpropV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, outputBackprop: Tensor<T>, outputHBackprop: Tensor<T>, outputCBackprop: Tensor<T>, reserveSpace: Tensor<T>, hostReserved: Tensor<Int8>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0 ) -> ( inputBackprop: Tensor<T>, inputHBackprop: Tensor<T>, inputCBackprop: Tensor<T>, paramsBackprop: Tensor<T> ) -
cudnnRNNBackpropV3(_:inputH:inputC:params:sequenceLengths:output:outputH:outputC:outputBackprop:outputHBackprop:outputCBackprop:reserveSpace:hostReserved:rnnMode:inputMode:direction:dropout:seed:seed2:numProj:timeMajor:)
Backprop step of CudnnRNNV3.
Compute the backprop of both data and weights in a RNN. Takes an extra “sequence_lengths” input than CudnnRNNBackprop.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicates whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: If time_major is true, this is a 3-D tensor with the shape of [seq_length, batch_size, input_size]. If time_major is false, the shape is [batch_size, seq_length, input_size]. input_h: If time_major is true, this is a 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. If time_major is false, the shape is [batch_size, num_layer * dir, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore sequence_lengths: a vector of lengths of each input sequence. output: If time_major is true, this is a 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. If time_major is false, the shape is [batch_size, seq_length, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. output_backprop: A 3-D tensor with the same shape as output in the forward pass. output_h_backprop: A 3-D tensor with the same shape as output_h in the forward pass. output_c_backprop: A 3-D tensor with the same shape as output_c in the forward pass. time_major: Indicates whether the input/output format is time major or batch major. reserve_space: The same reserve_space produced in the forward operation. input_backprop: The backprop to input in the forward pass. Has the same shape as input. input_h_backprop: The backprop to input_h in the forward pass. Has the same shape as input_h. input_c_backprop: The backprop to input_c in the forward pass. Has the same shape as input_c. params_backprop: The backprop to the params buffer in the forward pass. Has the same shape as params.
Declaration
public static func cudnnRNNBackpropV3<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, sequenceLengths: Tensor<Int32>, output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, outputBackprop: Tensor<T>, outputHBackprop: Tensor<T>, outputCBackprop: Tensor<T>, reserveSpace: Tensor<T>, hostReserved: Tensor<Int8>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, numProj: Int64 = 0, timeMajor: Bool = true ) -> ( inputBackprop: Tensor<T>, inputHBackprop: Tensor<T>, inputCBackprop: Tensor<T>, paramsBackprop: Tensor<T> ) -
cudnnRNNCanonicalToParams(numLayers:numUnits:inputSize:weights:biases:rnnMode:inputMode:direction:dropout:seed:seed2:)
Converts CudnnRNN params from canonical form to usable form.
Writes a set of weights into the opaque params buffer so they can be used in upcoming training or inferences.
Note that the params buffer may not be compatible across different GPUs. So any save and restoration should be converted to and from the canonical weights and biases.
num_layers: Specifies the number of layers in the RNN model. num_units: Specifies the size of the hidden state. input_size: Specifies the size of the input state. weights: the canonical form of weights that can be used for saving and restoration. They are more likely to be compatible across different generations. biases: the canonical form of biases that can be used for saving and restoration. They are more likely to be compatible across different generations. num_params: number of parameter sets for all layers. Each layer may contain multiple parameter sets, with each set consisting of a weight matrix and a bias vector. rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and The actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. dir = (direction == bidirectional) ? 2 : 1 dropout: dropout probability. When set to 0., dropout is disabled. seed: the 1st part of a seed to initialize dropout. seed2: the 2nd part of a seed to initialize dropout.
Declaration
public static func cudnnRNNCanonicalToParams<T: FloatingPoint & TensorFlowScalar>( numLayers: Tensor<Int32>, numUnits: Tensor<Int32>, inputSize: Tensor<Int32>, weights: [Tensor<T>], biases: [Tensor<T>], rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<T> -
cudnnRNNCanonicalToParamsV2(numLayers:numUnits:inputSize:weights:biases:rnnMode:inputMode:direction:dropout:seed:seed2:numProj:)
Converts CudnnRNN params from canonical form to usable form. It supports the projection in LSTM.
Writes a set of weights into the opaque params buffer so they can be used in upcoming training or inferences.
Note that the params buffer may not be compatible across different GPUs. So any save and restoration should be converted to and from the canonical weights and biases.
num_layers: Specifies the number of layers in the RNN model. num_units: Specifies the size of the hidden state. input_size: Specifies the size of the input state. weights: the canonical form of weights that can be used for saving and restoration. They are more likely to be compatible across different generations. biases: the canonical form of biases that can be used for saving and restoration. They are more likely to be compatible across different generations. num_params_weigths: number of weight parameter matrix for all layers. num_params_biases: number of bias parameter vector for all layers. rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and The actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. dir = (direction == bidirectional) ? 2 : 1 dropout: dropout probability. When set to 0., dropout is disabled. seed: the 1st part of a seed to initialize dropout. seed2: the 2nd part of a seed to initialize dropout. num_proj: The output dimensionality for the projection matrices. If None or 0, no projection is performed.
Declaration
public static func cudnnRNNCanonicalToParamsV2<T: FloatingPoint & TensorFlowScalar>( numLayers: Tensor<Int32>, numUnits: Tensor<Int32>, inputSize: Tensor<Int32>, weights: [Tensor<T>], biases: [Tensor<T>], rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, numProj: Int64 = 0 ) -> Tensor<T> -
cudnnRNNParamsSize(numLayers:numUnits:inputSize:t:rnnMode:inputMode:direction:dropout:seed:seed2:numProj:)
Computes size of weights that can be used by a Cudnn RNN model.
Return the params size that can be used by the Cudnn RNN model. Subsequent weight allocation and initialization should use this size.
num_layers: Specifies the number of layers in the RNN model. num_units: Specifies the size of the hidden state. input_size: Specifies the size of the input state. rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and The actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. dir = (direction == bidirectional) ? 2 : 1 dropout: dropout probability. When set to 0., dropout is disabled. seed: the 1st part of a seed to initialize dropout. seed2: the 2nd part of a seed to initialize dropout. params_size: The size of the params buffer that should be allocated and initialized for this RNN model. Note that this params buffer may not be compatible across GPUs. Please use CudnnRNNParamsWeights and CudnnRNNParamsBiases to save and restore them in a way that is compatible across different runs.
Declaration
public static func cudnnRNNParamsSize<S: TensorFlowIndex>( numLayers: Tensor<Int32>, numUnits: Tensor<Int32>, inputSize: Tensor<Int32>, t: TensorDataType, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, numProj: Int64 = 0 ) -> Tensor<S> -
cudnnRNNParamsToCanonical(numLayers:numUnits:inputSize:params:numParams:rnnMode:inputMode:direction:dropout:seed:seed2:)
Retrieves CudnnRNN params in canonical form.
Retrieves a set of weights from the opaque params buffer that can be saved and restored in a way compatible with future runs.
Note that the params buffer may not be compatible across different GPUs. So any save and restoration should be converted to and from the canonical weights and biases.
num_layers: Specifies the number of layers in the RNN model. num_units: Specifies the size of the hidden state. input_size: Specifies the size of the input state. num_params: number of parameter sets for all layers. Each layer may contain multiple parameter sets, with each set consisting of a weight matrix and a bias vector. weights: the canonical form of weights that can be used for saving and restoration. They are more likely to be compatible across different generations. biases: the canonical form of biases that can be used for saving and restoration. They are more likely to be compatible across different generations. rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and The actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. dir = (direction == bidirectional) ? 2 : 1 dropout: dropout probability. When set to 0., dropout is disabled. seed: the 1st part of a seed to initialize dropout. seed2: the 2nd part of a seed to initialize dropout.
Declaration
public static func cudnnRNNParamsToCanonical<T: FloatingPoint & TensorFlowScalar>( numLayers: Tensor<Int32>, numUnits: Tensor<Int32>, inputSize: Tensor<Int32>, params: Tensor<T>, numParams: Int64, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0 ) -> (weights: [Tensor<T>], biases: [Tensor<T>]) -
cudnnRNNParamsToCanonicalV2(numLayers:numUnits:inputSize:params:numParamsWeights:numParamsBiases:rnnMode:inputMode:direction:dropout:seed:seed2:numProj:)
Retrieves CudnnRNN params in canonical form. It supports the projection in LSTM.
Retrieves a set of weights from the opaque params buffer that can be saved and restored in a way compatible with future runs.
Note that the params buffer may not be compatible across different GPUs. So any save and restoration should be converted to and from the canonical weights and biases.
num_layers: Specifies the number of layers in the RNN model. num_units: Specifies the size of the hidden state. input_size: Specifies the size of the input state. num_params_weigths: number of weight parameter matrix for all layers. num_params_biases: number of bias parameter vector for all layers. weights: the canonical form of weights that can be used for saving and restoration. They are more likely to be compatible across different generations. biases: the canonical form of biases that can be used for saving and restoration. They are more likely to be compatible across different generations. rnn_mode: Indicates the type of the RNN model. input_mode: Indicate whether there is a linear projection between the input and The actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. dir = (direction == bidirectional) ? 2 : 1 dropout: dropout probability. When set to 0., dropout is disabled. seed: the 1st part of a seed to initialize dropout. seed2: the 2nd part of a seed to initialize dropout. num_proj: The output dimensionality for the projection matrices. If None or 0, no projection is performed.
Declaration
public static func cudnnRNNParamsToCanonicalV2<T: FloatingPoint & TensorFlowScalar>( numLayers: Tensor<Int32>, numUnits: Tensor<Int32>, inputSize: Tensor<Int32>, params: Tensor<T>, numParamsWeights: Int64, numParamsBiases: Int64, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, numProj: Int64 = 0 ) -> (weights: [Tensor<T>], biases: [Tensor<T>]) -
A RNN backed by cuDNN.
Computes the RNN from the input and initial states, with respect to the params buffer. Produces one extra output “host_reserved” than CudnnRNN.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicates whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: A 3-D tensor with the shape of [seq_length, batch_size, input_size]. input_h: A 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore output: A 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. is_training: Indicates whether this operation is used for inferenece or training. reserve_space: An opaque tensor that can be used in backprop calculation. It is only produced if is_training is true. host_reserved: An opaque tensor that can be used in backprop calculation. It is only produced if is_training is true. It is output on host memory rather than device memory.
Declaration
public static func cudnnRNNV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, isTraining: Bool = true ) -> ( output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, reserveSpace: Tensor<T>, hostReserved: Tensor<Int8> ) -
cudnnRNNV3(_:inputH:inputC:params:sequenceLengths:rnnMode:inputMode:direction:dropout:seed:seed2:numProj:isTraining:timeMajor:)
A RNN backed by cuDNN.
Computes the RNN from the input and initial states, with respect to the params buffer. Accepts one extra input “sequence_lengths” than CudnnRNN.
rnn_mode: Indicates the type of the RNN model. input_mode: Indicates whether there is a linear projection between the input and the actual computation before the first layer. ‘skip_input’ is only allowed when input_size == num_units; ‘auto_select’ implies ‘skip_input’ when input_size == num_units; otherwise, it implies ‘linear_input’. direction: Indicates whether a bidirectional model will be used. Should be “unidirectional” or “bidirectional”. dropout: Dropout probability. When set to 0., dropout is disabled. seed: The 1st part of a seed to initialize dropout. seed2: The 2nd part of a seed to initialize dropout. input: If time_major is true, this is a 3-D tensor with the shape of [seq_length, batch_size, input_size]. If time_major is false, the shape is [batch_size, seq_length, input_size]. input_h: If time_major is true, this is a 3-D tensor with the shape of [num_layer * dir, batch_size, num_units]. If time_major is false, the shape is [batch_size, num_layer * dir, num_units]. input_c: For LSTM, a 3-D tensor with the shape of [num_layer * dir, batch, num_units]. For other models, it is ignored. params: A 1-D tensor that contains the weights and biases in an opaque layout. The size must be created through CudnnRNNParamsSize, and initialized separately. Note that they might not be compatible across different generations. So it is a good idea to save and restore sequence_lengths: a vector of lengths of each input sequence. output: If time_major is true, this is a 3-D tensor with the shape of [seq_length, batch_size, dir * num_units]. If time_major is false, the shape is [batch_size, seq_length, dir * num_units]. output_h: The same shape has input_h. output_c: The same shape as input_c for LSTM. An empty tensor for other models. is_training: Indicates whether this operation is used for inferenece or training. time_major: Indicates whether the input/output format is time major or batch major. reserve_space: An opaque tensor that can be used in backprop calculation. It is only produced if is_training is true.
Declaration
public static func cudnnRNNV3<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputH: Tensor<T>, inputC: Tensor<T>, params: Tensor<T>, sequenceLengths: Tensor<Int32>, rnnMode: RnnMode = .lstm, inputMode: InputMode = .linearInput, direction: Direction = .unidirectional, dropout: Double = 0, seed: Int64 = 0, seed2: Int64 = 0, numProj: Int64 = 0, isTraining: Bool = true, timeMajor: Bool = true ) -> ( output: Tensor<T>, outputH: Tensor<T>, outputC: Tensor<T>, reserveSpace: Tensor<T>, hostReserved: Tensor<Int8> ) -
Compute the cumulative product of the tensor
xalongaxis.By default, this op performs an inclusive cumprod, which means that the first element of the input is identical to the first element of the output:
tf.cumprod([a, b, c]) # => [a, a * b, a * b * c]By setting the
exclusivekwarg toTrue, an exclusive cumprod is performed instead:tf.cumprod([a, b, c], exclusive=True) # => [1, a, a * b]By setting the
reversekwarg toTrue, the cumprod is performed in the opposite direction:tf.cumprod([a, b, c], reverse=True) # => [a * b * c, b * c, c]This is more efficient than using separate
tf.reverseops.The
reverseandexclusivekwargs can also be combined:tf.cumprod([a, b, c], exclusive=True, reverse=True) # => [b * c, c, 1]Attrs:
- exclusive: If
True, perform exclusive cumprod. - reverse: A
bool(default: False).
- exclusive: If
Declaration
public static func cumprod< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ x: Tensor<T>, axis: Tensor<Tidx>, exclusive: Bool = false, reverse: Bool = false ) -> Tensor<T> -
Compute the cumulative sum of the tensor
xalongaxis.By default, this op performs an inclusive cumsum, which means that the first element of the input is identical to the first element of the output:
tf.cumsum([a, b, c]) # => [a, a + b, a + b + c]By setting the
exclusivekwarg toTrue, an exclusive cumsum is performed instead:tf.cumsum([a, b, c], exclusive=True) # => [0, a, a + b]By setting the
reversekwarg toTrue, the cumsum is performed in the opposite direction:tf.cumsum([a, b, c], reverse=True) # => [a + b + c, b + c, c]This is more efficient than using separate
tf.reverseops.The
reverseandexclusivekwargs can also be combined:tf.cumsum([a, b, c], exclusive=True, reverse=True) # => [b + c, c, 0]Attrs:
- exclusive: If
True, perform exclusive cumsum. - reverse: A
bool(default: False).
- exclusive: If
Declaration
public static func cumsum< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ x: Tensor<T>, axis: Tensor<Tidx>, exclusive: Bool = false, reverse: Bool = false ) -> Tensor<T> -
Compute the cumulative product of the tensor
xalongaxis.By default, this op performs an inclusive cumulative log-sum-exp, which means that the first element of the input is identical to the first element of the output:
tf.math.cumulative_logsumexp([a, b, c]) # => [a, log(exp(a) + exp(b)), log(exp(a) + exp(b) + exp(c))]By setting the
exclusivekwarg toTrue, an exclusive cumulative log-sum-exp is performed instead:tf.cumulative_logsumexp([a, b, c], exclusive=True) # => [-inf, a, log(exp(a) * exp(b))]Note that the neutral element of the log-sum-exp operation is
-inf, however, for performance reasons, the minimal value representable by the floating point type is used instead.By setting the
reversekwarg toTrue, the cumulative log-sum-exp is performed in the opposite direction.Attrs:
- exclusive: If
True, perform exclusive cumulative log-sum-exp. - reverse: A
bool(default: False).
- exclusive: If
Declaration
public static func cumulativeLogsumexp< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( _ x: Tensor<T>, axis: Tensor<Tidx>, exclusive: Bool = false, reverse: Bool = false ) -> Tensor<T> -
Returns the dimension index in the destination data format given the one in
the source data format.
Attrs:
- src_format: source data format.
- dst_format: destination data format.
Output y: A Tensor with each element as a dimension index in destination data format.
Declaration
public static func dataFormatDimMap<T: TensorFlowIndex>( _ x: Tensor<T>, srcFormat: String = "NHWC", dstFormat: String = "NCHW" ) -> Tensor<T>Parameters
xA Tensor with each element as a dimension index in source data format. Must be in the range [-4, 4).
-
Returns the permuted vector/tensor in the destination data format given the
one in the source data format.
Attrs:
- src_format: source data format.
- dst_format: destination data format.
Output y: Vector of size 4 or Tensor of shape (4, 2) in destination data format.
Declaration
public static func dataFormatVecPermute<T: TensorFlowIndex>( _ x: Tensor<T>, srcFormat: String = "NHWC", dstFormat: String = "NCHW" ) -> Tensor<T>Parameters
xVector of size 4 or Tensor of shape (4, 2) in source data format.
-
Returns the cardinality of
input_dataset.Returns the cardinality of
input_dataset.Output cardinality: The cardinality of
input_dataset. Named constants are used to represent infinite and unknown cardinality.
Declaration
public static func datasetCardinality( inputDataset: VariantHandle ) -> Tensor<Int64>Parameters
input_datasetA variant tensor representing the dataset to return cardinality for.
-
Creates a dataset from the given
graph_def.Creates a dataset from the provided
graph_def.Output handle: A variant tensor representing the dataset.
Declaration
public static func datasetFromGraph( graphDef: StringTensor ) -> VariantHandleParameters
graph_defThe graph representation of the dataset (as serialized GraphDef).
-
Returns a serialized GraphDef representing
input_dataset.Returns a graph representation for
input_dataset.Output graph: The graph representation of the dataset (as serialized GraphDef).
Declaration
public static func datasetToGraph( inputDataset: VariantHandle, statefulWhitelist: [String], allowStateful: Bool = false, stripDeviceAssignment: Bool = false ) -> StringTensorParameters
input_datasetA variant tensor representing the dataset to return the graph representation for.
-
Returns a serialized GraphDef representing
input_dataset.Returns a graph representation for
input_dataset.Output graph: The graph representation of the dataset (as serialized GraphDef).
Declaration
public static func datasetToGraphV2( inputDataset: VariantHandle, externalStatePolicy: Int64 = 0, stripDeviceAssignment: Bool = false ) -> StringTensorParameters
input_datasetA variant tensor representing the dataset to return the graph representation for.
-
Outputs the single element from the given dataset.
Output components: The components of the single element of
input.
Declaration
public static func datasetToSingleElement<OutputTypes: TensorGroup>( dataset: VariantHandle, outputShapes: [TensorShape?] ) -> OutputTypesParameters
datasetA handle to a dataset that contains a single element.
-
Writes the given dataset to the given file using the TFRecord format.
Declaration
public static func datasetToTFRecord( inputDataset: VariantHandle, filename: StringTensor, compressionType: StringTensor )Parameters
input_datasetA variant tensor representing the dataset to write.
filenameA scalar string tensor representing the filename to use.
compression_typeA scalar string tensor containing either (i) the empty string (no compression), (ii) “ZLIB”, or (iii) “GZIP”.
-
Identity op for gradient debugging.
This op is hidden from public in Python. It is used by TensorFlow Debugger to register gradient tensors for gradient debugging. This op operates on non-reference-type tensors.
Declaration
public static func debugGradientIdentity<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Provides an identity mapping of the non-Ref type input tensor for debugging.
Provides an identity mapping of the non-Ref type input tensor for debugging.
Attrs:
- device_name: Name of the device on which the tensor resides.
- tensor_name: Name of the input tensor.
- debug_urls: List of URLs to debug targets, e.g., file:///foo/tfdbg_dump, grpc:://localhost:11011
- gated_grpc: Whether this op will be gated. If any of the debug_urls of this debug node is of the grpc:// scheme, when the value of this attribute is set to True, the data will not actually be sent via the grpc stream unless this debug op has been enabled at the debug_url. If all of the debug_urls of this debug node are of the grpc:// scheme and the debug op is enabled at none of them, the output will be an empty Tensor.
Declaration
public static func debugIdentity<T: TensorFlowScalar>( _ input: Tensor<T>, deviceName: String, tensorName: String, debugUrls: [String], gatedGrpc: Bool = false ) -> Tensor<T>Parameters
inputInput tensor, non-Reference type
-
Debug Identity V2 Op.
Provides an identity mapping from input to output, while writing the content of the input tensor by calling DebugEventsWriter.
The semantics of the input tensor depends on tensor_debug_mode. In typical usage, the input tensor comes directly from the user computation only when graph_debug_mode is FULL_TENSOR (see protobuf/debug_event.proto for a list of all the possible values of graph_debug_mode). For the other debug modes, the input tensor should be produced by an additional op or subgraph that computes summary information about one or more tensors.
Attrs:
- tfdbg_context_id: A tfdbg-generated ID for the context that the op belongs to, e.g., a concrete compiled tf.function.
- op_name: Optional. Name of the op that the debug op is concerned with. Used only for single-tensor trace.
- output_slot: Optional. Output slot index of the tensor that the debug op is concerned with. Used only for single-tensor trace.
- tensor_debug_mode: TensorDebugMode enum value. See debug_event.proto for details.
- debug_urls: List of URLs to debug targets, e.g., file:///foo/tfdbg_dump.
Declaration
public static func debugIdentityV2<T: TensorFlowScalar>( _ input: Tensor<T>, tfdbgContextId: String, opName: String, outputSlot: Int64 = -1, tensorDebugMode: Int64 = -1, debugUrls: [String] ) -> Tensor<T>Parameters
inputInput tensor, non-Reference type
-
Debug NaN Value Counter Op.
Counts number of NaNs in the input tensor, for debugging.
Attrs:
- tensor_name: Name of the input tensor.
- debug_urls: List of URLs to debug targets, e.g., file:///foo/tfdbg_dump, grpc:://localhost:11011.
- gated_grpc: Whether this op will be gated. If any of the debug_urls of this debug node is of the grpc:// scheme, when the value of this attribute is set to True, the data will not actually be sent via the grpc stream unless this debug op has been enabled at the debug_url. If all of the debug_urls of this debug node are of the grpc:// scheme and the debug op is enabled at none of them, the output will be an empty Tensor.
Declaration
public static func debugNanCount<T: TensorFlowScalar>( _ input: Tensor<T>, deviceName: String, tensorName: String, debugUrls: [String], gatedGrpc: Bool = false ) -> Tensor<Int64>Parameters
inputInput tensor, non-Reference type.
-
debugNumericSummary(_:deviceName:tensorName:debugUrls:lowerBound:upperBound:muteIfHealthy:gatedGrpc:)
Debug Numeric Summary Op.
Provide a basic summary of numeric value types, range and distribution.
output: A double tensor of shape [14 + nDimensions], where nDimensions is the the number of dimensions of the tensor’s shape. The elements of output are: [0]: is initialized (1.0) or not (0.0). [1]: total number of elements [2]: NaN element count [3]: generalized -inf count: elements <= lower_bound. lower_bound is -inf by default. [4]: negative element count (excluding -inf), if lower_bound is the default -inf. Otherwise, this is the count of elements > lower_bound and < 0. [5]: zero element count [6]: positive element count (excluding +inf), if upper_bound is the default -inf. Otherwise, this is the count of elements < upper_bound and > 0. [7]: generalized +inf count, elements >= upper_bound. upper_bound is +inf by default. Output elements [1:8] are all zero, if the tensor is uninitialized. [8]: minimum of all non-inf and non-NaN elements. If uninitialized or no such element exists: +inf. [9]: maximum of all non-inf and non-NaN elements. If uninitialized or no such element exists: -inf. [10]: mean of all non-inf and non-NaN elements. If uninitialized or no such element exists: NaN. [11]: variance of all non-inf and non-NaN elements. If uninitialized or no such element exists: NaN. [12]: Data type of the tensor encoded as an enum integer. See the DataType proto for more details. [13]: Number of dimensions of the tensor (ndims). [14+]: Sizes of the dimensions.
Attrs:
- tensor_name: Name of the input tensor.
- debug_urls: List of URLs to debug targets, e.g., file:///foo/tfdbg_dump, grpc:://localhost:11011.
- lower_bound: (float) The lower bound <= which values will be included in the generalized -inf count. Default: -inf.
- upper_bound: (float) The upper bound >= which values will be included in the generalized +inf count. Default: +inf.
- mute_if_healthy: (bool) Do not send data to the debug URLs unless at least one of elements [2], [3] and 7 is non-zero.
- gated_grpc: Whether this op will be gated. If any of the debug_urls of this debug node is of the grpc:// scheme, when the value of this attribute is set to True, the data will not actually be sent via the grpc stream unless this debug op has been enabled at the debug_url. If all of the debug_urls of this debug node are of the grpc:// scheme and the debug op is enabled at none of them, the output will be an empty Tensor.
Declaration
public static func debugNumericSummary<T: TensorFlowScalar>( _ input: Tensor<T>, deviceName: String, tensorName: String, debugUrls: [String], lowerBound: Double = -Double.infinity, upperBound: Double = Double.infinity, muteIfHealthy: Bool = false, gatedGrpc: Bool = false ) -> Tensor<Double>Parameters
inputInput tensor, non-Reference type.
-
Attrs:
tensor_debug_mode: Tensor debug mode: the mode in which the input tensor is summarized by the op. See the TensorDebugMode enum in tensorflow/core/protobuf/debug_event.proto for details.
Supported values: 2 (CURT_HEALTH): Output a float32/64 tensor of shape [2]. The 1st element is the tensor_id, if provided, and -1 otherwise. The 2nd element is a bit which is set to 1 if the input tensor has an infinity or nan value, or zero otherwise.
3 (CONCISE_HEALTH): Ouput a float32/64 tensor of shape [5]. The 1st element is the tensor_id, if provided, and -1 otherwise. The remaining four slots are the total number of elements, -infs, +infs, and nans in the input tensor respectively.
4 (FULL_HEALTH): Output a float32/64 tensor of shape [11]. The 1st element is the tensor_id, if provided, and -1 otherwise. The 2nd element is the device_id, if provided, and -1 otherwise. The 3rd element holds the datatype value of the input tensor as according to the enumerated type in tensorflow/core/framework/types.proto. The remaining elements hold the total number of elements, -infs, +infs, nans, negative finite numbers, zeros, and positive finite numbers in the input tensor respectively.
5 (SHAPE): Output a float32/64 tensor of shape [10]. The 1st element is the tensor_id, if provided, and -1 otherwise. The 2nd element holds the datatype value of the input tensor as according to the enumerated type in tensorflow/core/framework/types.proto. The 3rd element holds the rank of the tensor. The 4th element holds the number of elements within the tensor. Finally the remaining 6 elements hold the shape of the tensor. If the rank of the tensor is lower than 6, the shape is right padded with zeros. If the rank is greater than 6, the head of the shape is truncated.
6 (FULL_NUMERICS): Output a float32/64 tensor of shape [22]. The 1st element is the tensor_id, if provided, and -1 otherwise. The 2nd element is the device_id, if provided, and -1 otherwise. The 3rd element holds the datatype value of the input tensor as according to the enumerated type in tensorflow/core/framework/types.proto. The 4th element holds the rank of the tensor. The 5th to 11th elements hold the shape of the tensor. If the rank of the tensor is lower than 6, the shape is right padded with zeros. If the rank is greater than 6, the head of the shape is truncated. The 12th to 18th elements hold the number of elements, -infs, +infs, nans, denormal floats, negative finite numbers, zeros, and positive finite numbers in the input tensor respectively. The final four elements hold the min value, max value, mean, and variance of the input tensor.
8 (REDUCE_INF_NAN_THREE_SLOTS): Output a float32/64 tensor of shape [3]. The 1st element is -inf if any elements of the input tensor is -inf, or zero otherwise. The 2nd element is +inf if any elements of the input tensor is +inf, or zero otherwise. The 3rd element is nan if any element of the input tensor is nan, or zero otherwise.
tensor_id: Optional. An integer identifier for the tensor being summarized by this op.
Declaration
public static func debugNumericSummaryV2<T: TensorFlowScalar>( _ input: Tensor<T>, tensorDebugMode: Int64 = -1, tensorId: Int64 = -1 ) -> Tensor<Float>Parameters
inputInput tensor, to be summarized by the op.
-
decodeAndCropJpeg(contents:cropWindow:channels:ratio:fancyUpscaling:tryRecoverTruncated:acceptableFraction:dctMethod:)
Decode and Crop a JPEG-encoded image to a uint8 tensor.
The attr
channelsindicates the desired number of color channels for the decoded image.Accepted values are:
- 0: Use the number of channels in the JPEG-encoded image.
- 1: output a grayscale image.
- 3: output an RGB image.
If needed, the JPEG-encoded image is transformed to match the requested number of color channels.
The attr
ratioallows downscaling the image by an integer factor during decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than downscaling the image later.It is equivalent to a combination of decode and crop, but much faster by only decoding partial jpeg image.
Attrs:
- channels: Number of color channels for the decoded image.
- ratio: Downscaling ratio.
- fancy_upscaling: If true use a slower but nicer upscaling of the chroma planes (yuv420/422 only).
- try_recover_truncated: If true try to recover an image from truncated input.
- acceptable_fraction: The minimum required fraction of lines before a truncated input is accepted.
- dct_method: string specifying a hint about the algorithm used for decompression. Defaults to “” which maps to a system-specific default. Currently valid values are [“INTEGER_FAST”, “INTEGER_ACCURATE”]. The hint may be ignored (e.g., the internal jpeg library changes to a version that does not have that specific option.)
Output image: 3-D with shape
[height, width, channels]..
Declaration
public static func decodeAndCropJpeg( contents: StringTensor, cropWindow: Tensor<Int32>, channels: Int64 = 0, ratio: Int64 = 1, fancyUpscaling: Bool = true, tryRecoverTruncated: Bool = false, acceptableFraction: Double = 1, dctMethod: String ) -> Tensor<UInt8>Parameters
contents0-D. The JPEG-encoded image.
crop_window1-D. The crop window: [crop_y, crop_x, crop_height, crop_width].
-
Decode web-safe base64-encoded strings.
Input may or may not have padding at the end. See EncodeBase64 for padding. Web-safe means that input must use - and _ instead of + and /.
Output output: Decoded strings.
Declaration
public static func decodeBase64( _ input: StringTensor ) -> StringTensorParameters
inputBase64 strings to decode.
-
Decode the first frame of a BMP-encoded image to a uint8 tensor.
The attr
channelsindicates the desired number of color channels for the decoded image.Accepted values are:
- 0: Use the number of channels in the BMP-encoded image.
- 3: output an RGB image.
4: output an RGBA image.
Output image: 3-D with shape
[height, width, channels]. RGB order
Declaration
public static func decodeBmp( contents: StringTensor, channels: Int64 = 0 ) -> Tensor<UInt8>Parameters
contents0-D. The BMP-encoded image.
-
Convert CSV records to tensors. Each column maps to one tensor.
RFC 4180 format is expected for the CSV records. (https://tools.ietf.org/html/rfc4180) Note that we allow leading and trailing spaces with int or float field.
Attrs:
- field_delim: char delimiter to separate fields in a record.
- use_quote_delim: If false, treats double quotation marks as regular characters inside of the string fields (ignoring RFC 4180, Section 2, Bullet 5).
- na_value: Additional string to recognize as NA/NaN.
Output output: Each tensor will have the same shape as records.
Declaration
public static func decodeCSV<OutType: TensorArrayProtocol>( records: StringTensor, recordDefaults: OutType, fieldDelim: String = ",", useQuoteDelim: Bool = true, naValue: String, selectCols: [Int32] ) -> OutTypeParameters
recordsEach string is a record/row in the csv and all records should have the same format.
record_defaultsOne tensor per column of the input record, with either a scalar default value for that column or an empty vector if the column is required.
-
Decompress strings.
This op decompresses each element of the
bytesinputTensor, which is assumed to be compressed using the givencompression_type.The
outputis a stringTensorof the same shape asbytes, each element containing the decompressed data from the corresponding element inbytes.Attr compression_type: A scalar containing either (i) the empty string (no compression), (ii) “ZLIB”, or (iii) “GZIP”.
Output output: A Tensor with the same shape as input
bytes, uncompressed from bytes.
Declaration
public static func decodeCompressed( bytes: StringTensor, compressionType: String ) -> StringTensorParameters
bytesA Tensor of string which is compressed.
-
Decode the frame(s) of a GIF-encoded image to a uint8 tensor.
GIF images with frame or transparency compression are not supported. On Linux and MacOS systems, convert animated GIFs from compressed to uncompressed by running:
convert $src.gif -coalesce $dst.gifThis op also supports decoding JPEGs and PNGs, though it is cleaner to use
tf.image.decode_image.Output image: 4-D with shape
[num_frames, height, width, 3]. RGB channel order.
Declaration
public static func decodeGif( contents: StringTensor ) -> Tensor<UInt8>Parameters
contents0-D. The GIF-encoded image.
-
Convert JSON-encoded Example records to binary protocol buffer strings.
This op translates a tensor containing Example records, encoded using the standard JSON mapping, into a tensor containing the same records encoded as binary protocol buffers. The resulting tensor can then be fed to any of the other Example-parsing ops.
Output binary_examples: Each string is a binary Example protocol buffer corresponding to the respective element of
json_examples.
Declaration
public static func decodeJSONExample( jsonExamples: StringTensor ) -> StringTensorParameters
json_examplesEach string is a JSON object serialized according to the JSON mapping of the Example proto.
-
decodeJpeg(contents:channels:ratio:fancyUpscaling:tryRecoverTruncated:acceptableFraction:dctMethod:)
Decode a JPEG-encoded image to a uint8 tensor.
The attr
channelsindicates the desired number of color channels for the decoded image.Accepted values are:
- 0: Use the number of channels in the JPEG-encoded image.
- 1: output a grayscale image.
- 3: output an RGB image.
If needed, the JPEG-encoded image is transformed to match the requested number of color channels.
The attr
ratioallows downscaling the image by an integer factor during decoding. Allowed values are: 1, 2, 4, and 8. This is much faster than downscaling the image later.This op also supports decoding PNGs and non-animated GIFs since the interface is the same, though it is cleaner to use
tf.image.decode_image.Attrs:
- channels: Number of color channels for the decoded image.
- ratio: Downscaling ratio.
- fancy_upscaling: If true use a slower but nicer upscaling of the chroma planes (yuv420/422 only).
- try_recover_truncated: If true try to recover an image from truncated input.
- acceptable_fraction: The minimum required fraction of lines before a truncated input is accepted.
- dct_method: string specifying a hint about the algorithm used for decompression. Defaults to “” which maps to a system-specific default. Currently valid values are [“INTEGER_FAST”, “INTEGER_ACCURATE”]. The hint may be ignored (e.g., the internal jpeg library changes to a version that does not have that specific option.)
Output image: 3-D with shape
[height, width, channels]..
Declaration
public static func decodeJpeg( contents: StringTensor, channels: Int64 = 0, ratio: Int64 = 1, fancyUpscaling: Bool = true, tryRecoverTruncated: Bool = false, acceptableFraction: Double = 1, dctMethod: String ) -> Tensor<UInt8>Parameters
contents0-D. The JPEG-encoded image.
-
Reinterpret the bytes of a string as a vector of numbers.
Attr little_endian: Whether the input
input_bytesis in little-endian order. Ignored forout_typevalues that are stored in a single byte, likeuint8Output output: A Tensor with one more dimension than the input
bytes. The added dimension will have size equal to the length of the elements ofbytesdivided by the number of bytes to representout_type.
Declaration
public static func decodePaddedRaw<OutType: TensorFlowNumeric>( inputBytes: StringTensor, fixedLength: Tensor<Int32>, littleEndian: Bool = true ) -> Tensor<OutType>Parameters
input_bytesTensor of string to be decoded.
fixed_lengthLength in bytes for each element of the decoded output. Must be a multiple of the size of the output type.
-
Decode a PNG-encoded image to a uint8 or uint16 tensor.
The attr
channelsindicates the desired number of color channels for the decoded image.Accepted values are:
- 0: Use the number of channels in the PNG-encoded image.
- 1: output a grayscale image.
- 3: output an RGB image.
- 4: output an RGBA image.
If needed, the PNG-encoded image is transformed to match the requested number of color channels.
This op also supports decoding JPEGs and non-animated GIFs since the interface is the same, though it is cleaner to use
tf.image.decode_image.Attr channels: Number of color channels for the decoded image.
Output image: 3-D with shape
[height, width, channels].
Declaration
public static func decodePng<Dtype: UnsignedInteger & TensorFlowScalar>( contents: StringTensor, channels: Int64 = 0 ) -> Tensor<Dtype>Parameters
contents0-D. The PNG-encoded image.
-
The op extracts fields from a serialized protocol buffers message into tensors.
The
decode_protoop extracts fields from a serialized protocol buffers message into tensors. The fields infield_namesare decoded and converted to the correspondingoutput_typesif possible.A
message_typename must be provided to give context for the field names. The actual message descriptor can be looked up either in the linked-in descriptor pool or a filename provided by the caller using thedescriptor_sourceattribute.Each output tensor is a dense tensor. This means that it is padded to hold the largest number of repeated elements seen in the input minibatch. (The shape is also padded by one to prevent zero-sized dimensions). The actual repeat counts for each example in the minibatch can be found in the
sizesoutput. In many cases the output ofdecode_protois fed immediately into tf.squeeze if missing values are not a concern. When using tf.squeeze, always pass the squeeze dimension explicitly to avoid surprises.For the most part, the mapping between Proto field types and TensorFlow dtypes is straightforward. However, there are a few special cases:
A proto field that contains a submessage or group can only be converted to
DT_STRING(the serialized submessage). This is to reduce the complexity of the API. The resulting string can be used as input to another instance of the decode_proto op.TensorFlow lacks support for unsigned integers. The ops represent uint64 types as a
DT_INT64with the same twos-complement bit pattern (the obvious way). Unsigned int32 values can be represented exactly by specifying typeDT_INT64, or using twos-complement if the caller specifiesDT_INT32in theoutput_typesattribute.
Both binary and text proto serializations are supported, and can be chosen using the
formatattribute.The
descriptor_sourceattribute selects the source of protocol descriptors to consult when looking upmessage_type. This may be:An empty string or “local://”, in which case protocol descriptors are created for C++ (not Python) proto definitions linked to the binary.
A file, in which case protocol descriptors are created from the file, which is expected to contain a
FileDescriptorSetserialized as a string. NOTE: You can build adescriptor_sourcefile using the--descriptor_set_outand--include_importsoptions to the protocol compilerprotoc.A “bytes://
”, in which protocol descriptors are created from <bytes>, which is expected to be aFileDescriptorSetserialized as a string.Attrs:
- message_type: Name of the proto message type to decode.
- field_names: List of strings containing proto field names. An extension field can be decoded by using its full name, e.g. EXT_PACKAGE.EXT_FIELD_NAME.
- output_types: List of TF types to use for the respective field in field_names.
- descriptor_source: Either the special value
local://or a path to a file containing a serializedFileDescriptorSet. - message_format: Either
binaryortext. - sanitize: Whether to sanitize the result or not.
Outputs:
- sizes: Tensor of int32 with shape
[batch_shape, len(field_names)]. Each entry is the number of values found for the corresponding field. Optional fields may have 0 or 1 values. - values: List of tensors containing values for the corresponding field.
values[i]has datatypeoutput_types[i]and shape[batch_shape, max(sizes[...,i])].
- sizes: Tensor of int32 with shape
Declaration
public static func decodeProtoV2<OutputTypes: TensorGroup>( bytes: StringTensor, messageType: String, fieldNames: [String], descriptorSource: String = "local://", messageFormat: String = "binary", sanitize: Bool = false ) -> (sizes: Tensor<Int32>, values: OutputTypes)Parameters
bytesTensor of serialized protos with shape
batch_shape. -
Reinterpret the bytes of a string as a vector of numbers.
Attr little_endian: Whether the input
bytesare in little-endian order. Ignored forout_typevalues that are stored in a single byte likeuint8.Output output: A Tensor with one more dimension than the input
bytes. The added dimension will have size equal to the length of the elements ofbytesdivided by the number of bytes to representout_type.
Declaration
public static func decodeRaw<OutType: TensorFlowScalar>( bytes: StringTensor, littleEndian: Bool = true ) -> Tensor<OutType>Parameters
bytesAll the elements must have the same length.
-
Decode a 16-bit PCM WAV file to a float tensor.
The -32768 to 32767 signed 16-bit values will be scaled to -1.0 to 1.0 in float.
When desired_channels is set, if the input contains fewer channels than this then the last channel will be duplicated to give the requested number, else if the input has more channels than requested then the additional channels will be ignored.
If desired_samples is set, then the audio will be cropped or padded with zeroes to the requested length.
The first output contains a Tensor with the content of the audio samples. The lowest dimension will be the number of channels, and the second will be the number of samples. For example, a ten-sample-long stereo WAV file should give an output shape of [10, 2].
Attrs:
- desired_channels: Number of sample channels wanted.
- desired_samples: Length of audio requested.
Outputs:
- audio: 2-D with shape
[length, channels]. - sample_rate: Scalar holding the sample rate found in the WAV header.
- audio: 2-D with shape
Declaration
public static func decodeWav( contents: StringTensor, desiredChannels: Int64 = -1, desiredSamples: Int64 = -1 ) -> (audio: Tensor<Float>, sampleRate: Tensor<Int32>)Parameters
contentsThe WAV-encoded audio, usually from a file.
-
Makes a copy of
x.Output y: y: A
Tensorof typeT. A copy ofx. Guaranteed thatyis not an alias ofx.
Declaration
public static func deepCopy<T: TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T>Parameters
xThe source tensor of type
T. -
A container for an iterator resource.
Declaration
public static func deleteIterator( handle: ResourceHandle, deleter: VariantHandle )Parameters
handleA handle to the iterator to delete.
deleterA variant deleter.
-
Declaration
public static func deleteMemoryCache( handle: ResourceHandle, deleter: VariantHandle ) -
A container for an iterator resource.
Declaration
public static func deleteMultiDeviceIterator( multiDeviceIterator: ResourceHandle, iterators: [ResourceHandle], deleter: VariantHandle )Parameters
multi_device_iteratorA handle to the multi device iterator to delete.
iteratorsA list of iterator handles (unused). This is added so that automatic control dependencies get added during function tracing that ensure this op runs after all the dependent iterators are deleted.
deleterA variant deleter.
-
Declaration
public static func deleteRandomSeedGenerator( handle: ResourceHandle, deleter: VariantHandle ) -
Delete the tensor specified by its handle in the session.
Declaration
public static func deleteSessionTensor( handle: StringTensor )Parameters
handleThe handle for a tensor stored in the session state.
-
Converts a dense tensor to a (possibly batched) CSRSparseMatrix.
Output sparse_output: A (possibly batched) CSRSparseMatrix.
Declaration
public static func denseToCSRSparseMatrix<T: FloatingPoint & TensorFlowScalar>( denseInput: Tensor<T>, indices: Tensor<Int64> ) -> VariantHandleParameters
dense_inputA Dense tensor.
indicesIndices of nonzero elements.
-
Applies set operation along last dimension of 2
Tensorinputs.See SetOperationOp::SetOperationFromContext for values of
set_operation.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
-
Applies set operation along last dimension of 2
Tensorinputs.See SetOperationOp::SetOperationFromContext for values of
set_operation.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
public static func denseToDenseSetOperation( set1: StringTensor, set2: StringTensor, setOperation: String, validateIndices: Bool = true ) -> (resultIndices: Tensor<Int64>, resultValues: StringTensor, resultShape: Tensor<Int64>) -
Creates a dataset that batches input elements into a SparseTensor.
Declaration
public static func denseToSparseBatchDataset( inputDataset: VariantHandle, batchSize: Tensor<Int64>, rowShape: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA handle to an input dataset. Must have a single component.
batch_sizeA scalar representing the number of elements to accumulate in a batch.
row_shapeA vector representing the dense shape of each row in the produced SparseTensor. The shape may be partially specified, using
-1to indicate that a particular dimension should use the maximum size of all batch elements. -
Applies set operation along last dimension of
TensorandSparseTensor.See SetOperationOp::SetOperationFromContext for values of
set_operation.Input
set2is aSparseTensorrepresented byset2_indices,set2_values, andset2_shape. Forset2rankedn, 1stn-1dimensions must be the same asset1. Dimensionncontains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofset2indices.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
public static func denseToSparseSetOperation<T: TensorFlowInteger>( set1: Tensor<T>, set2Indices: Tensor<Int64>, set2Values: Tensor<T>, set2Shape: Tensor<Int64>, setOperation: String, validateIndices: Bool = true ) -> (resultIndices: Tensor<Int64>, resultValues: Tensor<T>, resultShape: Tensor<Int64>)Parameters
set1Tensorwith rankn. 1stn-1dimensions must be the same asset2. Dimensionncontains values in a set, duplicates are allowed but ignored.set2_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set2_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set2_shape1D
Tensor, shape of aSparseTensor.set2_shape[0...n-1]must be the same as the 1stn-1dimensions ofset1,result_shape[n]is the max set size acrossn-1dimensions. -
Applies set operation along last dimension of
TensorandSparseTensor.See SetOperationOp::SetOperationFromContext for values of
set_operation.Input
set2is aSparseTensorrepresented byset2_indices,set2_values, andset2_shape. Forset2rankedn, 1stn-1dimensions must be the same asset1. Dimensionncontains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofset2indices.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
public static func denseToSparseSetOperation( set1: StringTensor, set2Indices: Tensor<Int64>, set2Values: StringTensor, set2Shape: Tensor<Int64>, setOperation: String, validateIndices: Bool = true ) -> (resultIndices: Tensor<Int64>, resultValues: StringTensor, resultShape: Tensor<Int64>)Parameters
set1Tensorwith rankn. 1stn-1dimensions must be the same asset2. Dimensionncontains values in a set, duplicates are allowed but ignored.set2_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set2_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set2_shape1D
Tensor, shape of aSparseTensor.set2_shape[0...n-1]must be the same as the 1stn-1dimensions ofset1,result_shape[n]is the max set size acrossn-1dimensions. -
DepthToSpace for tensors of type T.
Rearranges data from depth into blocks of spatial data. This is the reverse transformation of SpaceToDepth. More specifically, this op outputs a copy of the input tensor where values from the
depthdimension are moved in spatial blocks to theheightandwidthdimensions. The attrblock_sizeindicates the input block size and how the data is moved.- Chunks of data of size
block_size * block_sizefrom depth are rearranged into non-overlapping blocks of sizeblock_size x block_size - The width the output tensor is
input_depth * block_size, whereas the height isinput_height * block_size. - The Y, X coordinates within each block of the output image are determined by the high order component of the input channel index.
- The depth of the input tensor must be divisible by
block_size * block_size.
The
data_formatattr specifies the layout of the input and output tensors with the following options: “NHWC”:[ batch, height, width, channels ]“NCHW”:[ batch, channels, height, width ]“NCHW_VECT_C”:qint8 [ batch, channels / 4, height, width, 4 ]It is useful to consider the operation as transforming a 6-D Tensor. e.g. for data_format = NHWC, Each element in the input tensor can be specified via 6 coordinates, ordered by decreasing memory layout significance as: n,iY,iX,bY,bX,oC (where n=batch index, iX, iY means X or Y coordinates within the input image, bX, bY means coordinates within the output block, oC means output channels). The output would be the input transposed to the following layout: n,iY,bY,iX,bX,oC
This operation is useful for resizing the activations between convolutions (but keeping all data), e.g. instead of pooling. It is also useful for training purely convolutional models.
For example, given an input of shape
[1, 1, 1, 4], data_format = “NHWC” and block_size = 2:x = [[[[1, 2, 3, 4]]]]This operation will output a tensor of shape
[1, 2, 2, 1]:[[[[1], [2]], [[3], [4]]]]Here, the input has a batch of 1 and each batch element has shape
[1, 1, 4], the corresponding output will have 2x2 elements and will have a depth of 1 channel (1 =4 / (block_size * block_size)). The output element shape is[2, 2, 1].For an input tensor with larger depth, here of shape
[1, 1, 1, 12], e.g.x = [[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]]This operation, for block size of 2, will return the following tensor of shape
[1, 2, 2, 3][[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]]Similarly, for the following input of shape
[1 2 2 4], and a block size of 2:x = [[[[1, 2, 3, 4], [5, 6, 7, 8]], [[9, 10, 11, 12], [13, 14, 15, 16]]]]the operator will return the following tensor of shape
[1 4 4 1]:x = [[[ [1], [2], [5], [6]], [ [3], [4], [7], [8]], [ [9], [10], [13], [14]], [ [11], [12], [15], [16]]]]- Attr block_size: The size of the spatial block, same as in Space2Depth.
Declaration
public static func depthToSpace<T: TensorFlowScalar>( _ input: Tensor<T>, blockSize: Int64, dataFormat: DataFormat5 = .nhwc ) -> Tensor<T> - Chunks of data of size
-
Computes a 2-D depthwise convolution given 4-D
inputandfiltertensors.Given an input tensor of shape
[batch, in_height, in_width, in_channels]and a filter / kernel tensor of shape[filter_height, filter_width, in_channels, channel_multiplier], containingin_channelsconvolutional filters of depth 1,depthwise_conv2dapplies a different filter to each input channel (expanding from 1 channel tochannel_multiplierchannels for each), then concatenates the results together. Thus, the output hasin_channels * channel_multiplierchannels.for k in 0..in_channels-1 for q in 0..channel_multiplier-1 output[b, i, j, k * channel_multiplier + q] = sum_{di, dj} input[b, strides[1] * i + di, strides[2] * j + dj, k] * filter[di, dj, k, q]Must have
strides[0] = strides[3] = 1. For the most common case of the same horizontal and vertices strides,strides = [1, stride, stride, 1].- Attrs:
- strides: 1-D of length 4. The stride of the sliding window for each dimension
of
input. - padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, height, width, channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, channels, height, width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
- strides: 1-D of length 4. The stride of the sliding window for each dimension
of
Declaration
public static func depthwiseConv2dNative<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, filter: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T> - Attrs:
-
depthwiseConv2dNativeBackpropFilter(_:filterSizes:outBackprop:strides:padding:dataFormat:dilations:)
Computes the gradients of depthwise convolution with respect to the filter.
Attrs:
- strides: The stride of the sliding window for each dimension of the input of the convolution.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, height, width, channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, channels, height, width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
Output output: 4-D with shape
[filter_height, filter_width, in_channels, out_channels]. Gradient w.r.t. thefilterinput of the convolution.
Declaration
public static func depthwiseConv2dNativeBackpropFilter<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, filterSizes: Tensor<Int32>, outBackprop: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T>Parameters
input4-D with shape based on
data_format. For example, ifdata_formatis ‘NHWC’ theninputis a 4-D[batch, in_height, in_width, in_channels]tensor.filter_sizesAn integer vector representing the tensor shape of
filter, wherefilteris a 4-D[filter_height, filter_width, in_channels, depthwise_multiplier]tensor.out_backprop4-D with shape based on
data_format. For example, ifdata_formatis ‘NHWC’ then out_backprop shape is[batch, out_height, out_width, out_channels]. Gradients w.r.t. the output of the convolution. -
depthwiseConv2dNativeBackpropInput(inputSizes:filter:outBackprop:strides:padding:dataFormat:dilations:)
Computes the gradients of depthwise convolution with respect to the input.
Attrs:
- strides: The stride of the sliding window for each dimension of the input of the convolution.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, height, width, channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, channels, height, width].
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
Output output: 4-D with shape according to
data_format. For example, ifdata_formatis ‘NHWC’, output shape is[batch, in_height, in_width, in_channels]. Gradient w.r.t. the input of the convolution.
Declaration
public static func depthwiseConv2dNativeBackpropInput<T: FloatingPoint & TensorFlowScalar>( inputSizes: Tensor<Int32>, filter: Tensor<T>, outBackprop: Tensor<T>, strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc, dilations: [Int32] = [1, 1, 1, 1] ) -> Tensor<T>Parameters
input_sizesAn integer vector representing the shape of
input, based ondata_format. For example, ifdata_formatis ‘NHWC’ theninputis a 4-D[batch, height, width, channels]tensor.filter4-D with shape
[filter_height, filter_width, in_channels, depthwise_multiplier].out_backprop4-D with shape based on
data_format. For example, ifdata_formatis ‘NHWC’ then out_backprop shape is[batch, out_height, out_width, out_channels]. Gradients w.r.t. the output of the convolution. -
Declaration
Parameters
min_rangeThe minimum scalar value possibly produced for the input.
max_rangeThe maximum scalar value possibly produced for the input.
-
Converts the given variant tensor to an iterator and stores it in the given resource.
Declaration
public static func deserializeIterator( resourceHandle: ResourceHandle, serialized: VariantHandle )Parameters
resource_handleA handle to an iterator resource.
serializedA variant tensor storing the state of the iterator contained in the resource.
-
Deserialize and concatenate
SparseTensorsfrom a serialized minibatch.The input
serialized_sparsemust be a string matrix of shape[N x 3]whereNis the minibatch size and the rows correspond to packed outputs ofSerializeSparse. The ranks of the originalSparseTensorobjects must all match. When the finalSparseTensoris created, it has rank one higher than the ranks of the incomingSparseTensorobjects (they have been concatenated along a new row dimension).The output
SparseTensorobject’s shape values for all dimensions but the first are the max across the inputSparseTensorobjects’ shape values for the corresponding dimensions. Its first shape value isN, the minibatch size.The input
SparseTensorobjects’ indices are assumed ordered in standard lexicographic order. If this is not the case, after this step runSparseReorderto restore index ordering.For example, if the serialized input is a
[2 x 3]matrix representing two originalSparseTensorobjects:index = [ 0] [10] [20] values = [1, 2, 3] shape = [50]and
index = [ 2] [10] values = [4, 5] shape = [30]then the final deserialized
SparseTensorwill be:index = [0 0] [0 10] [0 20] [1 2] [1 10] values = [1, 2, 3, 4, 5] shape = [2 50]Attr dtype: The
dtypeof the serializedSparseTensorobjects.
Declaration
public static func deserializeManySparse<Dtype: TensorFlowScalar>( serializedSparse: StringTensor ) -> (sparseIndices: Tensor<Int64>, sparseValues: Tensor<Dtype>, sparseShape: Tensor<Int64>)Parameters
serialized_sparse2-D, The
NserializedSparseTensorobjects. Must have 3 columns. -
Deserialize
SparseTensorobjects.The input
serialized_sparsemust have the shape[?, ?, ..., ?, 3]where the last dimension stores serializedSparseTensorobjects and the other N dimensions (N >= 0) correspond to a batch. The ranks of the originalSparseTensorobjects must all match. When the finalSparseTensoris created, its rank is the rank of the incomingSparseTensorobjects plus N; the sparse tensors have been concatenated along new dimensions, one for each batch.The output
SparseTensorobject’s shape values for the original dimensions are the max across the inputSparseTensorobjects’ shape values for the corresponding dimensions. The new dimensions match the size of the batch.The input
SparseTensorobjects’ indices are assumed ordered in standard lexicographic order. If this is not the case, after this step runSparseReorderto restore index ordering.For example, if the serialized input is a
[2 x 3]matrix representing two originalSparseTensorobjects:index = [ 0] [10] [20] values = [1, 2, 3] shape = [50]and
index = [ 2] [10] values = [4, 5] shape = [30]then the final deserialized
SparseTensorwill be:index = [0 0] [0 10] [0 20] [1 2] [1 10] values = [1, 2, 3, 4, 5] shape = [2 50]Attr dtype: The
dtypeof the serializedSparseTensorobjects.
Declaration
public static func deserializeSparse< Dtype: TensorFlowScalar, Tserialized: TensorFlowScalar >( serializedSparse: Tensor<Tserialized> ) -> (sparseIndices: Tensor<Int64>, sparseValues: Tensor<Dtype>, sparseShape: Tensor<Int64>)Parameters
serialized_sparseThe serialized
SparseTensorobjects. The last dimension must have 3 columns. -
Deserialize
SparseTensorobjects.The input
serialized_sparsemust have the shape[?, ?, ..., ?, 3]where the last dimension stores serializedSparseTensorobjects and the other N dimensions (N >= 0) correspond to a batch. The ranks of the originalSparseTensorobjects must all match. When the finalSparseTensoris created, its rank is the rank of the incomingSparseTensorobjects plus N; the sparse tensors have been concatenated along new dimensions, one for each batch.The output
SparseTensorobject’s shape values for the original dimensions are the max across the inputSparseTensorobjects’ shape values for the corresponding dimensions. The new dimensions match the size of the batch.The input
SparseTensorobjects’ indices are assumed ordered in standard lexicographic order. If this is not the case, after this step runSparseReorderto restore index ordering.For example, if the serialized input is a
[2 x 3]matrix representing two originalSparseTensorobjects:index = [ 0] [10] [20] values = [1, 2, 3] shape = [50]and
index = [ 2] [10] values = [4, 5] shape = [30]then the final deserialized
SparseTensorwill be:index = [0 0] [0 10] [0 20] [1 2] [1 10] values = [1, 2, 3, 4, 5] shape = [2 50]Attr dtype: The
dtypeof the serializedSparseTensorobjects.
Declaration
public static func deserializeSparse<Dtype: TensorFlowScalar>( serializedSparse: StringTensor ) -> (sparseIndices: Tensor<Int64>, sparseValues: Tensor<Dtype>, sparseShape: Tensor<Int64>)Parameters
serialized_sparseThe serialized
SparseTensorobjects. The last dimension must have 3 columns. -
Deletes the resource specified by the handle.
All subsequent operations using the resource will result in a NotFound error status.
Attr ignore_lookup_error: whether to ignore the error when the resource doesn’t exist.
Declaration
public static func destroyResourceOp( resource: ResourceHandle, ignoreLookupError: Bool = true )Parameters
resourcehandle to the resource to delete.
-
Declaration
public static func devicePlacementOp() -> StringTensor -
Returns a diagonal tensor with a given diagonal values.
Given a
diagonal, this operation returns a tensor with thediagonaland everything else padded with zeros. The diagonal is computed as follows:Assume
diagonalhas dimensions [D1,…, Dk], then the output is a tensor of rank 2k with dimensions [D1,…, Dk, D1,…, Dk] where:output[i1,..., ik, i1,..., ik] = diagonal[i1, ..., ik]and 0 everywhere else.For example:
# 'diagonal' is [1, 2, 3, 4] tf.diag(diagonal) ==> [[1, 0, 0, 0] [0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]]Declaration
public static func diag<T: TensorFlowNumeric>( diagonal: Tensor<T> ) -> Tensor<T>Parameters
diagonalRank k tensor where k is at most 1.
-
Returns the diagonal part of the tensor.
This operation returns a tensor with the
diagonalpart of theinput. Thediagonalpart is computed as follows:Assume
inputhas dimensions[D1,..., Dk, D1,..., Dk], then the output is a tensor of rankkwith dimensions[D1,..., Dk]where:diagonal[i1,..., ik] = input[i1, ..., ik, i1,..., ik].For example:
# 'input' is [[1, 0, 0, 0] [0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]] tf.diag_part(input) ==> [1, 2, 3, 4]Output diagonal: The extracted diagonal.
Declaration
public static func diagPart<T: TensorFlowNumeric>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputRank k tensor where k is even and not zero.
-
Computes Psi, the derivative of Lgamma (the log of the absolute value of
Gamma(x)), element-wise.Declaration
public static func digamma<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the grayscale dilation of 4-D
inputand 3-Dfiltertensors.The
inputtensor has shape[batch, in_height, in_width, depth]and thefiltertensor has shape[filter_height, filter_width, depth], i.e., each input channel is processed independently of the others with its own structuring function. Theoutputtensor has shape[batch, out_height, out_width, depth]. The spatial dimensions of the output tensor depend on thepaddingalgorithm. We currently only support the default “NHWC”data_format.In detail, the grayscale morphological 2-D dilation is the max-sum correlation (for consistency with
conv2d, we use unmirrored filters):output[b, y, x, c] = max_{dy, dx} input[b, strides[1] * y + rates[1] * dy, strides[2] * x + rates[2] * dx, c] + filter[dy, dx, c]Max-pooling is a special case when the filter has size equal to the pooling kernel size and contains all zeros.
Note on duality: The dilation of
inputby thefilteris equal to the negation of the erosion of-inputby the reflectedfilter.Attrs:
- strides: The stride of the sliding window for each dimension of the input
tensor. Must be:
[1, stride_height, stride_width, 1]. - rates: The input stride for atrous morphological dilation. Must be:
[1, rate_height, rate_width, 1]. - padding: The type of padding algorithm to use.
- strides: The stride of the sliding window for each dimension of the input
tensor. Must be:
Output output: 4-D with shape
[batch, out_height, out_width, depth].
Declaration
public static func dilation2D<T: TensorFlowNumeric>( _ input: Tensor<T>, filter: Tensor<T>, strides: [Int32], rates: [Int32], padding: Padding ) -> Tensor<T>Parameters
input4-D with shape
[batch, in_height, in_width, depth].filter3-D with shape
[filter_height, filter_width, depth]. -
Computes the gradient of morphological 2-D dilation with respect to the filter.
Attrs:
- strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be:
[1, stride_height, stride_width, 1]. - rates: 1-D of length 4. The input stride for atrous morphological dilation.
Must be:
[1, rate_height, rate_width, 1]. - padding: The type of padding algorithm to use.
- strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be:
Output filter_backprop: 3-D with shape
[filter_height, filter_width, depth].
Declaration
Parameters
input4-D with shape
[batch, in_height, in_width, depth].filter3-D with shape
[filter_height, filter_width, depth].out_backprop4-D with shape
[batch, out_height, out_width, depth]. -
Computes the gradient of morphological 2-D dilation with respect to the input.
Attrs:
- strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be:
[1, stride_height, stride_width, 1]. - rates: 1-D of length 4. The input stride for atrous morphological dilation.
Must be:
[1, rate_height, rate_width, 1]. - padding: The type of padding algorithm to use.
- strides: 1-D of length 4. The stride of the sliding window for each dimension of
the input tensor. Must be:
Output in_backprop: 4-D with shape
[batch, in_height, in_width, depth].
Declaration
Parameters
input4-D with shape
[batch, in_height, in_width, depth].filter3-D with shape
[filter_height, filter_width, depth].out_backprop4-D with shape
[batch, out_height, out_width, depth]. -
A substitute for
InterleaveDataseton a fixed list ofNdatasets.Declaration
public static func directedInterleaveDataset( selectorInputDataset: VariantHandle, dataInputDatasets: [VariantHandle], outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
selector_input_datasetA dataset of scalar
DT_INT64elements that determines which of theNdata inputs should produce the next output element.data_input_datasetsNdatasets with the same type that will be interleaved according to the values ofselector_input_dataset. -
Returns x / y element-wise.
NOTE:
Divsupports broadcasting. More about broadcasting hereDeclaration
public static func div<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns 0 if the denominator is zero.
NOTE:
DivNoNansupports broadcasting. More about broadcasting hereDeclaration
public static func divNoNan<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Draw bounding boxes on a batch of images.
Outputs a copy of
imagesbut draws on top of the pixels zero or more bounding boxes specified by the locations inboxes. The coordinates of the each bounding box inboxesare encoded as[y_min, x_min, y_max, x_max]. The bounding box coordinates are floats in[0.0, 1.0]relative to the width and height of the underlying image.For example, if an image is 100 x 200 pixels (height x width) and the bounding box is
[0.1, 0.2, 0.5, 0.9], the upper-left and bottom-right coordinates of the bounding box will be(40, 10)to(180, 50)(in (x,y) coordinates).Parts of the bounding box may fall outside the image.
Output output: 4-D with the same shape as
images. The batch of input images with bounding boxes drawn on the images.
Declaration
public static func drawBoundingBoxes<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T>, boxes: Tensor<Float> ) -> Tensor<T>Parameters
images4-D with shape
[batch, height, width, depth]. A batch of images.boxes3-D with shape
[batch, num_bounding_boxes, 4]containing bounding boxes. -
Draw bounding boxes on a batch of images.
Outputs a copy of
imagesbut draws on top of the pixels zero or more bounding boxes specified by the locations inboxes. The coordinates of the each bounding box inboxesare encoded as[y_min, x_min, y_max, x_max]. The bounding box coordinates are floats in[0.0, 1.0]relative to the width and height of the underlying image.For example, if an image is 100 x 200 pixels (height x width) and the bounding box is
[0.1, 0.2, 0.5, 0.9], the upper-left and bottom-right coordinates of the bounding box will be(40, 10)to(100, 50)(in (x,y) coordinates).Parts of the bounding box may fall outside the image.
Output output: 4-D with the same shape as
images. The batch of input images with bounding boxes drawn on the images.
Declaration
public static func drawBoundingBoxesV2<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T>, boxes: Tensor<Float>, colors: Tensor<Float> ) -> Tensor<T>Parameters
images4-D with shape
[batch, height, width, depth]. A batch of images.boxes3-D with shape
[batch, num_bounding_boxes, 4]containing bounding boxes.colors2-D. A list of RGBA colors to cycle through for the boxes.
-
Partitions
dataintonum_partitionstensors using indices frompartitions.For each index tuple
jsof sizepartitions.ndim, the slicedata[js, ...]becomes part ofoutputs[partitions[js]]. The slices withpartitions[js] = iare placed inoutputs[i]in lexicographic order ofjs, and the first dimension ofoutputs[i]is the number of entries inpartitionsequal toi. In detail,outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:] outputs[i] = pack([data[js, ...] for js if partitions[js] == i])data.shapemust start withpartitions.shape.For example:
# Scalar partitions. partitions = 1 num_partitions = 2 data = [10, 20] outputs[0] = [] # Empty with shape [0, 2] outputs[1] = [[10, 20]] # Vector partitions. partitions = [0, 0, 1, 1, 0] num_partitions = 2 data = [10, 20, 30, 40, 50] outputs[0] = [10, 20, 50] outputs[1] = [30, 40]See
dynamic_stitchfor an example on how to merge partitions back.
Attr num_partitions: The number of partitions to output.
Declaration
public static func dynamicPartition<T: TensorFlowScalar>( data: Tensor<T>, partitions: Tensor<Int32>, numPartitions: Int64 ) -> [Tensor<T>]Parameters
partitionsAny shape. Indices in the range
[0, num_partitions). -
Interleave the values from the
datatensors into a single tensor.Builds a merged tensor such that
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]For example, if each
indices[m]is scalar or vector, we have# Scalar indices: merged[indices[m], ...] = data[m][...] # Vector indices: merged[indices[m][i], ...] = data[m][i, ...]Each
data[i].shapemust start with the correspondingindices[i].shape, and the rest ofdata[i].shapemust be constant w.r.t.i. That is, we must havedata[i].shape = indices[i].shape + constant. In terms of thisconstant, the output shape ismerged.shape = [max(indices)] + constantValues are merged in order, so if an index appears in both
indices[m][i]andindices[n][j]for(m,i) < (n,j)the slicedata[n][j]will appear in the merged result. If you do not need this guarantee, ParallelDynamicStitch might perform better on some devices.For example:
indices[0] = 6 indices[1] = [4, 1] indices[2] = [[5, 2], [0, 3]] data[0] = [61, 62] data[1] = [[41, 42], [11, 12]] data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]] merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42], [51, 52], [61, 62]]This method can be used to merge partitions created by
dynamic_partitionas illustrated on the following example:# Apply function (increments x_i) on elements for which a certain condition # apply (x_i != -1 in this example). x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4]) condition_mask=tf.not_equal(x,tf.constant(-1.)) partitioned_data = tf.dynamic_partition( x, tf.cast(condition_mask, tf.int32) , 2) partitioned_data[1] = partitioned_data[1] + 1.0 condition_indices = tf.dynamic_partition( tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2) x = tf.dynamic_stitch(condition_indices, partitioned_data) # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain # unchanged.
Declaration
public static func dynamicStitch<T: TensorFlowScalar>( indices: [Tensor<Int32>], data: [Tensor<T>] ) -> Tensor<T> -
Eagerly executes a python function to compute func(input)->output. The
semantics of the input, output, and attributes are the same as those for PyFunc.
Declaration
public static func eagerPyFunc< Tin: TensorArrayProtocol, Tout: TensorGroup >( _ input: Tin, token: String, isAsync: Bool = false ) -> Tout -
editDistance(hypothesisIndices:hypothesisValues:hypothesisShape:truthIndices:truthValues:truthShape:normalize:)
Computes the (possibly normalized) Levenshtein Edit Distance.
The inputs are variable-length sequences provided by SparseTensors (hypothesis_indices, hypothesis_values, hypothesis_shape) and (truth_indices, truth_values, truth_shape).
The inputs are:
Attr normalize: boolean (if true, edit distances are normalized by length of truth).
The output is:
Output output: A dense float tensor with rank R - 1.
For the example input:
// hypothesis represents a 2x1 matrix with variable-length values: // (0,0) = ["a"] // (1,0) = ["b"] hypothesis_indices = [[0, 0, 0], [1, 0, 0]] hypothesis_values = ["a", "b"] hypothesis_shape = [2, 1, 1] // truth represents a 2x2 matrix with variable-length values: // (0,0) = [] // (0,1) = ["a"] // (1,0) = ["b", "c"] // (1,1) = ["a"] truth_indices = [[0, 1, 0], [1, 0, 0], [1, 0, 1], [1, 1, 0]] truth_values = ["a", "b", "c", "a"] truth_shape = [2, 2, 2] normalize = trueThe output will be:
// output is a 2x2 matrix with edit distances normalized by truth lengths. output = [[inf, 1.0], // (0,0): no truth, (0,1): no hypothesis [0.5, 1.0]] // (1,0): addition, (1,1): no hypothesis
Declaration
Parameters
hypothesis_indicesThe indices of the hypothesis list SparseTensor. This is an N x R int64 matrix.
hypothesis_valuesThe values of the hypothesis list SparseTensor. This is an N-length vector.
hypothesis_shapeThe shape of the hypothesis list SparseTensor. This is an R-length vector.
truth_indicesThe indices of the truth list SparseTensor. This is an M x R int64 matrix.
truth_valuesThe values of the truth list SparseTensor. This is an M-length vector.
truth_shapetruth indices, vector.
-
Computes the eigen decomposition of one or more square matrices.
Computes the eigenvalues and (optionally) right eigenvectors of each inner matrix in
inputsuch thatinput[..., :, :] = v[..., :, :] * diag(e[..., :]). The eigenvalues are sorted in non-decreasing order.# a is a tensor. # e is a tensor of eigenvalues. # v is a tensor of eigenvectors. e, v = eig(a) e = eig(a, compute_v=False)Attr compute_v: If
Truethen eigenvectors will be computed and returned inv. Otherwise, only the eigenvalues will be computed.Outputs:
- e: Eigenvalues. Shape is
[N]. - v: Eigenvectors. Shape is
[N, N].
- e: Eigenvalues. Shape is
Declaration
public static func eig< T: FloatingPoint & TensorFlowScalar, Tout: TensorFlowScalar >( _ input: Tensor<T>, computeV: Bool = true ) -> (e: Tensor<Tout>, v: Tensor<Tout>)Parameters
inputTensorinput of shape[N, N]. -
Tensor contraction according to Einstein summation convention.
Implements generalized Tensor contraction and reduction. Each input Tensor must have a corresponding input subscript appearing in the comma-separated left-hand side of the equation. The right-hand side of the equation consists of the output subscript. The input subscripts and the output subscript should consist of zero or more named axis labels and at most one ellipsis (
...).The named axis labels may be any single character other than those having special meaning, namely
,.->. The behavior of this Op is undefined if it receives an ill-formatted equation; since the validation is done at graph-building time, we omit format validation checks at runtime.Note: This Op is not intended to be called by the user; instead users should call
tf.einsumdirectly. It is a hidden Op used bytf.einsum.Operations are applied to the input(s) according to the following rules:
(a) Generalized Diagonals: For input dimensions corresponding to axis labels appearing more than once in the same input subscript, we take the generalized (
k-dimensional) diagonal. For example, in the equationiii->iwith input shape[3, 3, 3], the generalized diagonal would consist of3elements at indices(0, 0, 0),(1, 1, 1)and(2, 2, 2)to create a Tensor of shape[3].(b) Reduction: Axes corresponding to labels appearing only in one input subscript but not in the output subscript are summed over prior to Tensor contraction. For example, in the equation
ab,bc->b, the axis labelsaandcare the reduction axis labels.© Batch Dimensions: Axes corresponding to labels appearing in each of the input subscripts and also in the output subscript make up the batch dimensions in Tensor contraction. Unnamed axis labels corresponding to ellipsis (
...) also correspond to batch dimensions. For example, for the equation denoting batch matrix multiplication,bij,bjk->bik, the axis labelbcorresponds to a batch dimension.(d) Contraction: In case of binary einsum, axes corresponding to labels appearing in two different inputs (and not in the output) are contracted against each other. Considering the batch matrix multiplication equation again (
bij,bjk->bik), the contracted axis label isj.(e) Expand Diagonal: If the output subscripts contain repeated (explicit) axis labels, the opposite operation of (a) is applied. For example, in the equation
i->iii, and input shape[3], the output of shape[3, 3, 3]are all zeros, except for the (generalized) diagonal which is populated with values from the input. Note: This operation is not supported bynp.einsumortf.einsum; it is provided to enable computing the symbolic gradient oftf.einsum.The output subscripts must contain only labels appearing in at least one of the input subscripts. Furthermore, all dimensions mapping to the same axis label must be equal.
Any of the input and output subscripts may contain at most a single ellipsis (
...). These ellipsis are mapped against dimensions not corresponding to any named axis label. If two inputs contain ellipsis, then they are broadcasted according to standard NumPy broadcasting rules.The broadcasted dimensions are placed in the corresponding location of the ellipsis in the output subscript. If the broadcasted dimensions are non-empty and the output subscripts do not contain ellipsis, then an InvalidArgument error is raised.
@compatibility(numpy) Similar to
numpy.einsum.Comparison with
numpy.einsum:- This Op only supports unary and binary forms of
numpy.einsum. - This Op does not support implicit form. (i.e. equations without
->). This Op also supports repeated indices in the output subscript, which is not supported by
numpy.einsum. @end_compatibility- Attr equation: String describing the Einstein Summation operation; in the format of np.einsum.
- Output output: Output Tensor with shape depending upon
equation.
Declaration
public static func einsum<T: TensorFlowScalar>( inputs: [Tensor<T>], equation: String ) -> Tensor<T>Parameters
inputsList of 1 or 2 Tensors.
- This Op only supports unary and binary forms of
-
Computes exponential linear:
exp(features) - 1if < 0,featuresotherwise.See Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
Declaration
public static func elu<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T> ) -> Tensor<T> -
Computes gradients for the exponential linear (Elu) operation.
Output backprops: The gradients:
gradients * (outputs + 1)if outputs < 0,gradientsotherwise.
Declaration
public static func eluGrad<T: FloatingPoint & TensorFlowScalar>( gradients: Tensor<T>, outputs: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding Elu operation.
outputsThe outputs of the corresponding Elu operation.
-
Creates a tensor with the given shape.
This operation creates a tensor of
shapeanddtype.Attr init: If True, initialize the returned tensor with the default value of dtype. Otherwise, the implementation is free not to initializethe tensor’s content.
Output output: A
Tensorof typeT.
Declaration
public static func empty<Dtype: TensorFlowScalar>( shape: Tensor<Int32>, init_: Bool = false ) -> Tensor<Dtype>Parameters
shape1-D. Represents the shape of the output tensor.
-
Creates and returns an empty tensor list.
All list elements must be tensors of dtype element_dtype and shape compatible with element_shape.
handle: an empty tensor list. element_dtype: the type of elements in the list. element_shape: a shape compatible with that of elements in the list.
Declaration
public static func emptyTensorList<ShapeType: TensorFlowIndex>( elementShape: Tensor<ShapeType>, maxNumElements: Tensor<Int32>, elementDtype: TensorDataType ) -> VariantHandle -
Encode strings into web-safe base64 format.
Refer to the following article for more information on base64 format: en.wikipedia.org/wiki/Base64. Base64 strings may have padding with ‘=’ at the end so that the encoded has length multiple of 4. See Padding section of the link above.
Web-safe means that the encoder uses - and _ instead of + and /.
Attr pad: Bool whether padding is applied at the ends.
Output output: Input strings encoded in base64.
Declaration
public static func encodeBase64( _ input: StringTensor, pad: Bool = false ) -> StringTensorParameters
inputStrings to be encoded.
-
encodeJpeg(image:format:quality:progressive:optimizeSize:chromaDownsampling:densityUnit:xDensity:yDensity:xmpMetadata:)
JPEG-encode an image.
imageis a 3-D uint8 Tensor of shape[height, width, channels].The attr
formatcan be used to override the color format of the encoded output. Values can be:'': Use a default format based on the number of channels in the image.grayscale: Output a grayscale JPEG image. Thechannelsdimension ofimagemust be 1.rgb: Output an RGB JPEG image. Thechannelsdimension ofimagemust be 3.
If
formatis not specified or is the empty string, a default format is picked in function of the number of channels inimage:- 1: Output a grayscale image.
3: Output an RGB image.
Attrs:
- format: Per pixel image format.
- quality: Quality of the compression from 0 to 100 (higher is better and slower).
- progressive: If True, create a JPEG that loads progressively (coarse to fine).
- optimize_size: If True, spend CPU/RAM to reduce size with no quality change.
- chroma_downsampling: See http://en.wikipedia.org/wiki/Chroma_subsampling.
- density_unit: Unit used to specify
x_densityandy_density: pixels per inch ('in') or centimeter ('cm'). - x_density: Horizontal pixels per density unit.
- y_density: Vertical pixels per density unit.
- xmp_metadata: If not empty, embed this XMP metadata in the image header.
Output contents: 0-D. JPEG-encoded image.
Declaration
public static func encodeJpeg( image: Tensor<UInt8>, format: Format, quality: Int64 = 95, progressive: Bool = false, optimizeSize: Bool = false, chromaDownsampling: Bool = true, densityUnit: DensityUnit = .in_, xDensity: Int64 = 300, yDensity: Int64 = 300, xmpMetadata: String ) -> StringTensorParameters
image3-D with shape
[height, width, channels]. -
JPEG encode input image with provided compression quality.
imageis a 3-D uint8 Tensor of shape[height, width, channels].qualityis an int32 jpeg compression quality value between 0 and 100.Output contents: 0-D. JPEG-encoded image.
Declaration
public static func encodeJpegVariableQuality( images: Tensor<UInt8>, quality: Tensor<Int32> ) -> StringTensorParameters
imagesImages to adjust. At least 3-D.
qualityAn int quality to encode to.
-
PNG-encode an image.
imageis a 3-D uint8 or uint16 Tensor of shape[height, width, channels]wherechannelsis:- 1: for grayscale.
- 2: for grayscale + alpha.
- 3: for RGB.
- 4: for RGBA.
The ZLIB compression level,
compression, can be -1 for the PNG-encoder default or a value from 0 to 9. 9 is the highest compression level, generating the smallest output, but is slower.Attr compression: Compression level.
Output contents: 0-D. PNG-encoded image.
Declaration
public static func encodePng<T: UnsignedInteger & TensorFlowScalar>( image: Tensor<T>, compression: Int64 = -1 ) -> StringTensorParameters
image3-D with shape
[height, width, channels]. -
The op serializes protobuf messages provided in the input tensors.
The types of the tensors in
valuesmust match the schema for the fields specified infield_names. All the tensors invaluesmust have a common shape prefix, batch_shape.The
sizestensor specifies repeat counts for each field. The repeat count (last dimension) of a each tensor invaluesmust be greater than or equal to corresponding repeat count insizes.A
message_typename must be provided to give context for the field names. The actual message descriptor can be looked up either in the linked-in descriptor pool or a filename provided by the caller using thedescriptor_sourceattribute.For the most part, the mapping between Proto field types and TensorFlow dtypes is straightforward. However, there are a few special cases:
A proto field that contains a submessage or group can only be converted to
DT_STRING(the serialized submessage). This is to reduce the complexity of the API. The resulting string can be used as input to another instance of the decode_proto op.TensorFlow lacks support for unsigned integers. The ops represent uint64 types as a
DT_INT64with the same twos-complement bit pattern (the obvious way). Unsigned int32 values can be represented exactly by specifying typeDT_INT64, or using twos-complement if the caller specifiesDT_INT32in theoutput_typesattribute.
The
descriptor_sourceattribute selects the source of protocol descriptors to consult when looking upmessage_type. This may be:An empty string or “local://”, in which case protocol descriptors are created for C++ (not Python) proto definitions linked to the binary.
A file, in which case protocol descriptors are created from the file, which is expected to contain a
FileDescriptorSetserialized as a string. NOTE: You can build adescriptor_sourcefile using the--descriptor_set_outand--include_importsoptions to the protocol compilerprotoc.A “bytes://
”, in which protocol descriptors are created from <bytes>, which is expected to be aFileDescriptorSetserialized as a string.Attrs:
- field_names: List of strings containing proto field names.
- message_type: Name of the proto message type to decode.
- Tinput_types: The input types.
Output bytes: Tensor of serialized protos with shape
batch_shape.
Declaration
public static func encodeProto<TinputTypes: TensorArrayProtocol>( sizes: Tensor<Int32>, _ values: TinputTypes, fieldNames: [String], messageType: String, descriptorSource: String = "local://" ) -> StringTensorParameters
sizesTensor of int32 with shape
[batch_shape, len(field_names)].valuesList of tensors containing values for the corresponding field.
-
Encode audio data using the WAV file format.
This operation will generate a string suitable to be saved out to create a .wav audio file. It will be encoded in the 16-bit PCM format. It takes in float values in the range -1.0f to 1.0f, and any outside that value will be clamped to that range.
audiois a 2-D float Tensor of shape[length, channels].sample_rateis a scalar Tensor holding the rate to use (e.g. 44100).Output contents: 0-D. WAV-encoded file contents.
Declaration
public static func encodeWav( audio: Tensor<Float>, sampleRate: Tensor<Int32> ) -> StringTensorParameters
audio2-D with shape
[length, channels].sample_rateScalar containing the sample frequency.
-
An op that enqueues a list of input batch tensors to TPUEmbedding.
Attr device_ordinal: The TPU device to use. Should be >= 0 and less than the number of TPU cores in the task on which the node is placed.
Declaration
public static func enqueueTPUEmbeddingIntegerBatch( batch: [Tensor<Int32>], modeOverride: StringTensor, deviceOrdinal: Int64 = -1 )Parameters
batchA list of 1D tensors, one for each embedding table, containing the indices into the tables.
mode_overrideA string input that overrides the mode specified in the TPUEmbeddingConfiguration. Supported values are {‘unspecified’, ‘inference’, ‘training’, ‘backward_pass_only’}. When set to ‘unspecified’, the mode set in TPUEmbeddingConfiguration is used, otherwise mode_override is used.
-
enqueueTPUEmbeddingSparseBatch(sampleIndices:embeddingIndices:aggregationWeights:modeOverride:deviceOrdinal:combiners:)
An op that enqueues TPUEmbedding input indices from a SparseTensor.
This Op eases the porting of code that uses embedding_lookup_sparse(), although some Python preprocessing of the SparseTensor arguments to embedding_lookup_sparse() is required to produce the arguments to this Op, since only a single EnqueueTPUEmbeddingSparseBatch Op is allowed per training step.
The tensors at corresponding positions in the three input lists must have the same shape, i.e. rank 1 with dim_size() equal to the total number of lookups into the table described by the corresponding table_id.
Attrs:
- device_ordinal: The TPU device to use. Should be >= 0 and less than the number of TPU cores in the task on which the node is placed.
- combiners: A list of string scalars, one for each embedding table that specify how to normalize the embedding activations after weighted summation. Supported combiners are ‘mean’, ‘sum’, or ‘sqrtn’. It is invalid to have the sum of the weights be 0 for ‘mean’ or the sum of the squared weights be 0 for ‘sqrtn’. If combiners isn’t passed, the default is to use ‘sum’ for all tables.
Declaration
public static func enqueueTPUEmbeddingSparseBatch< T1: TensorFlowIndex, T2: TensorFlowIndex, T3: FloatingPoint & TensorFlowScalar >( sampleIndices: [Tensor<T1>], embeddingIndices: [Tensor<T2>], aggregationWeights: [Tensor<T3>], modeOverride: StringTensor, deviceOrdinal: Int64 = -1, combiners: [String] )Parameters
sample_indicesA list of rank 1 Tensors specifying the training example and feature to which the corresponding embedding_indices and aggregation_weights values belong. sample_indices[i] must equal b * nf + f, where nf is the number of features from the corresponding table, f is in [0, nf), and b is in [0, batch size).
embedding_indicesA list of rank 1 Tensors, indices into the embedding tables.
aggregation_weightsA list of rank 1 Tensors containing per sample – i.e. per (training example, feature) – aggregation weights.
mode_overrideA string input that overrides the mode specified in the TPUEmbeddingConfiguration. Supported values are {‘unspecified’, ‘inference’, ‘training’, ‘backward_pass_only’}. When set to ‘unspecified’, the mode set in TPUEmbeddingConfiguration is used, otherwise mode_override is used.
-
enqueueTPUEmbeddingSparseTensorBatch(sampleIndices:embeddingIndices:aggregationWeights:modeOverride:deviceOrdinal:combiners:tableIds:maxSequenceLengths:)
Eases the porting of code that uses tf.nn.embedding_lookup_sparse().
sample_indices[i], embedding_indices[i] and aggregation_weights[i] correspond to the ith feature. table_ids[i] indicates which embedding table to look up ith feature.
The tensors at corresponding positions in the three input lists (sample_indices, embedding_indices and aggregation_weights) must have the same shape, i.e. rank 1 with dim_size() equal to the total number of lookups into the table described by the corresponding feature.
Attrs:
- device_ordinal: The TPU device to use. Should be >= 0 and less than the number of TPU cores in the task on which the node is placed.
- combiners: A list of string scalars, one for each embedding table that specify how to normalize the embedding activations after weighted summation. Supported combiners are ‘mean’, ‘sum’, or ‘sqrtn’. It is invalid to have the sum of the weights be 0 for ‘mean’ or the sum of the squared weights be 0 for ‘sqrtn’. If combiners isn’t passed, the default is to use ‘sum’ for all tables.
- table_ids: A list of integers specifying the identifier of the embedding table (offset of TableDescriptor in the TPUEmbeddingConfiguration) to lookup the corresponding input. The ith input is looked up using table_ids[i]. The size of the table_ids list must be equal to that of sample_indices, embedding_indices and aggregation_weights.
Declaration
public static func enqueueTPUEmbeddingSparseTensorBatch< T1: TensorFlowIndex, T2: TensorFlowIndex, T3: FloatingPoint & TensorFlowScalar >( sampleIndices: [Tensor<T1>], embeddingIndices: [Tensor<T2>], aggregationWeights: [Tensor<T3>], modeOverride: StringTensor, deviceOrdinal: Int64 = -1, combiners: [String], tableIds: [Int32], maxSequenceLengths: [Int32] )Parameters
sample_indicesA list of rank 1 Tensors specifying the training example to which the corresponding embedding_indices and aggregation_weights values belong. It corresponds to sp_ids.indices[:,0] in embedding_lookup_sparse().
embedding_indicesA list of rank 1 Tensors, indices into the embedding tables. It corresponds to sp_ids.values in embedding_lookup_sparse().
aggregation_weightsA list of rank 1 Tensors containing per training example aggregation weights. It corresponds to sp_weights.values in embedding_lookup_sparse().
mode_overrideA string input that overrides the mode specified in the TPUEmbeddingConfiguration. Supported values are {‘unspecified’, ‘inference’, ‘training’, ‘backward_pass_only’}. When set to ‘unspecified’, the mode set in TPUEmbeddingConfiguration is used, otherwise mode_override is used.
-
Ensures that the tensor’s shape matches the expected shape.
Raises an error if the input tensor’s shape does not match the specified shape. Returns the input tensor otherwise.
Attr shape: The expected (possibly partially specified) shape of the input tensor.
Output output: A tensor with the same shape and contents as the input tensor or value.
Declaration
public static func ensureShape<T: TensorFlowScalar>( _ input: Tensor<T>, shape: TensorShape? ) -> Tensor<T>Parameters
inputA tensor, whose shape is to be validated.
-
Creates or finds a child frame, and makes
dataavailable to the child frame.This op is used together with
Exitto create loops in the graph. The uniqueframe_nameis used by theExecutorto identify frames. Ifis_constantis true,outputis a constant in the child frame; otherwise it may be changed in the child frame. At mostparallel_iterationsiterations are run in parallel in the child frame.Attrs:
- frame_name: The name of the child frame.
- is_constant: If true, the output is constant within the child frame.
- parallel_iterations: The number of iterations allowed to run in parallel.
Output output: The same tensor as
data.
Declaration
public static func enter<T: TensorFlowScalar>( data: Tensor<T>, frameName: String, isConstant: Bool = false, parallelIterations: Int64 = 10 ) -> Tensor<T>Parameters
dataThe tensor to be made available to the child frame.
-
Returns the truth value of (x == y) element-wise.
NOTE:
Equalsupports broadcasting. More about broadcasting herex = tf.constant([2, 4]) y = tf.constant(2) tf.math.equal(x, y) ==> array([True, False]) x = tf.constant([2, 4]) y = tf.constant([2, 4]) tf.math.equal(x, y) ==> array([True, True])Declaration
public static func equal<T: TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T>, incompatibleShapeError: Bool = true ) -> Tensor<Bool> -
Returns the truth value of (x == y) element-wise.
NOTE:
Equalsupports broadcasting. More about broadcasting herex = tf.constant([2, 4]) y = tf.constant(2) tf.math.equal(x, y) ==> array([True, False]) x = tf.constant([2, 4]) y = tf.constant([2, 4]) tf.math.equal(x, y) ==> array([True, True])Declaration
public static func equal( _ x: StringTensor, _ y: StringTensor, incompatibleShapeError: Bool = true ) -> Tensor<Bool> -
Computes the Gauss error function of
xelement-wise.Declaration
public static func erf<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the complementary error function of
xelement-wise.Declaration
public static func erfc<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Declaration
public static func erfinv<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the euclidean norm of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func euclideanNorm< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Exits the current frame to its parent frame.
Exit makes its input
dataavailable to the parent frame.Output output: The same tensor as
data.
Declaration
public static func exit<T: TensorFlowScalar>( data: Tensor<T> ) -> Tensor<T>Parameters
dataThe tensor to be made available to the parent frame.
-
Computes exponential of x element-wise. \(y = e^x\).
This function computes the exponential of every element in the input tensor. i.e.
exp(x)ore^(x), wherexis the input tensor.edenotes Euler’s number and is approximately equal to 2.718281. Output is positive for any real input.x = tf.constant(2.0) tf.math.exp(x) ==> 7.389056 x = tf.constant([2.0, 8.0]) tf.math.exp(x) ==> array([7.389056, 2980.958], dtype=float32)For complex numbers, the exponential value is calculated as follows:
e^(x+iy) = e^x * e^iy = e^x * (cos y + i sin y)Let’s consider complex number 1+1j as an example. e^1 * (cos 1 + i sin 1) = 2.7182818284590 * (0.54030230586+0.8414709848j)
x = tf.constant(1 + 1j) tf.math.exp(x) ==> 1.4686939399158851+2.2873552871788423jDeclaration
public static func exp<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Inserts a dimension of 1 into a tensor’s shape.
Given a tensor
input, this operation inserts a dimension of 1 at the dimension indexaxisofinput‘s shape. The dimension indexaxisstarts at zero; if you specify a negative number foraxisit is counted backward from the end.This operation is useful if you want to add a batch dimension to a single element. For example, if you have a single image of shape
[height, width, channels], you can make it a batch of 1 image withexpand_dims(image, 0), which will make the shape[1, height, width, channels].Other examples:
# 't' is a tensor of shape [2] shape(expand_dims(t, 0)) ==> [1, 2] shape(expand_dims(t, 1)) ==> [2, 1] shape(expand_dims(t, -1)) ==> [2, 1] # 't2' is a tensor of shape [2, 3, 5] shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5] shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5] shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1]This operation requires that:
-1-input.dims() <= dim <= input.dims()This operation is related to
squeeze(), which removes dimensions of size 1.Output output: Contains the same data as
input, but its shape has an additional dimension of size 1 added.
Declaration
public static func expandDims< T: TensorFlowScalar, Tdim: TensorFlowIndex >( _ input: Tensor<T>, dim: Tensor<Tdim> ) -> Tensor<T>Parameters
dim0-D (scalar). Specifies the dimension index at which to expand the shape of
input. Must be in the range[-rank(input) - 1, rank(input)]. -
Declaration
public static func experimentalAssertNextDataset( inputDataset: VariantHandle, transformations: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
experimentalAutoShardDataset(inputDataset:numWorkers:index:autoShardPolicy:outputTypes:outputShapes:)
Creates a dataset that shards the input dataset.
Creates a dataset that shards the input dataset by num_workers, returning a sharded dataset for the index-th worker. This attempts to automatically shard a dataset by examining the Dataset graph and inserting a shard op before the inputs to a reader Dataset (e.g. CSVDataset, TFRecordDataset).
This dataset will throw a NotFound error if we cannot shard the dataset automatically.
Declaration
public static func experimentalAutoShardDataset( inputDataset: VariantHandle, numWorkers: Tensor<Int64>, index: Tensor<Int64>, autoShardPolicy: Int64 = 0, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
num_workersA scalar representing the number of workers to distribute this dataset across.
indexA scalar representing the index of the current worker out of num_workers.
-
Records the bytes size of each element of
input_datasetin a StatsAggregator.Declaration
public static func experimentalBytesProducedStatsDataset( inputDataset: VariantHandle, tag: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
experimentalCSVDataset(filenames:compressionType:bufferSize:header:fieldDelim:useQuoteDelim:naValue:selectCols:recordDefaults:outputShapes:)
Declaration
public static func experimentalCSVDataset<OutputTypes: TensorArrayProtocol>( filenames: StringTensor, compressionType: StringTensor, bufferSize: Tensor<Int64>, header: Tensor<Bool>, fieldDelim: StringTensor, useQuoteDelim: Tensor<Bool>, naValue: StringTensor, selectCols: Tensor<Int64>, recordDefaults: OutputTypes, outputShapes: [TensorShape?] ) -> VariantHandle -
Declaration
public static func experimentalChooseFastestDataset( inputDatasets: [VariantHandle], numExperiments: Int64, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Returns the cardinality of
input_dataset.Returns the cardinality of
input_dataset.Output cardinality: The cardinality of
input_dataset. Named constants are used to represent infinite and unknown cardinality.
Declaration
public static func experimentalDatasetCardinality( inputDataset: VariantHandle ) -> Tensor<Int64>Parameters
input_datasetA variant tensor representing the dataset to return cardinality for.
-
Writes the given dataset to the given file using the TFRecord format.
Declaration
public static func experimentalDatasetToTFRecord( inputDataset: VariantHandle, filename: StringTensor, compressionType: StringTensor )Parameters
input_datasetA variant tensor representing the dataset to write.
filenameA scalar string tensor representing the filename to use.
compression_typeA scalar string tensor containing either (i) the empty string (no compression), (ii) “ZLIB”, or (iii) “GZIP”.
-
Creates a dataset that batches input elements into a SparseTensor.
Declaration
public static func experimentalDenseToSparseBatchDataset( inputDataset: VariantHandle, batchSize: Tensor<Int64>, rowShape: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA handle to an input dataset. Must have a single component.
batch_sizeA scalar representing the number of elements to accumulate in a batch.
row_shapeA vector representing the dense shape of each row in the produced SparseTensor. The shape may be partially specified, using
-1to indicate that a particular dimension should use the maximum size of all batch elements. -
experimentalDirectedInterleaveDataset(selectorInputDataset:dataInputDatasets:outputTypes:outputShapes:)
A substitute for
InterleaveDataseton a fixed list ofNdatasets.Declaration
public static func experimentalDirectedInterleaveDataset( selectorInputDataset: VariantHandle, dataInputDatasets: [VariantHandle], outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
selector_input_datasetA dataset of scalar
DT_INT64elements that determines which of theNdata inputs should produce the next output element.data_input_datasetsNdatasets with the same type that will be interleaved according to the values ofselector_input_dataset. -
experimentalGroupByReducerDataset(inputDataset:keyFuncOtherArguments:initFuncOtherArguments:reduceFuncOtherArguments:finalizeFuncOtherArguments:keyFunc:initFunc:reduceFunc:finalizeFunc:outputTypes:outputShapes:)
Creates a dataset that computes a group-by on
input_dataset.Creates a dataset that computes a group-by on
input_dataset.Attrs:
- key_func: A function mapping an element of
input_dataset, concatenated withkey_func_other_argumentsto a scalar value of type DT_INT64. - init_func: A function mapping a key of type DT_INT64, concatenated with
init_func_other_argumentsto the initial reducer state. - reduce_func: A function mapping the current reducer state and an element of
input_dataset, concatenated withreduce_func_other_argumentsto a new reducer state. - finalize_func: A function mapping the final reducer state to an output element.
- key_func: A function mapping an element of
Declaration
public static func experimentalGroupByReducerDataset< KeyfuncIn: TensorGroup, KeyfuncOut: TensorGroup, InitfuncIn: TensorGroup, InitfuncOut: TensorGroup, ReducefuncIn: TensorGroup, ReducefuncOut: TensorGroup, FinalizefuncIn: TensorGroup, FinalizefuncOut: TensorGroup, TkeyFuncOtherArguments: TensorArrayProtocol, TinitFuncOtherArguments: TensorArrayProtocol, TreduceFuncOtherArguments: TensorArrayProtocol, TfinalizeFuncOtherArguments: TensorArrayProtocol >( inputDataset: VariantHandle, keyFuncOtherArguments: TkeyFuncOtherArguments, initFuncOtherArguments: TinitFuncOtherArguments, reduceFuncOtherArguments: TreduceFuncOtherArguments, finalizeFuncOtherArguments: TfinalizeFuncOtherArguments, keyFunc: (KeyfuncIn) -> KeyfuncOut, initFunc: (InitfuncIn) -> InitfuncOut, reduceFunc: (ReducefuncIn) -> ReducefuncOut, finalizeFunc: (FinalizefuncIn) -> FinalizefuncOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
key_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
key_func.init_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
init_func.reduce_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
reduce_func.finalize_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
finalize_func. -
experimentalGroupByWindowDataset(inputDataset:keyFuncOtherArguments:reduceFuncOtherArguments:windowSizeFuncOtherArguments:keyFunc:reduceFunc:windowSizeFunc:outputTypes:outputShapes:)
Creates a dataset that computes a windowed group-by on
input_dataset.// TODO(mrry): Support non-int64 keys.
- Attr key_func: A function mapping an element of
input_dataset, concatenated withkey_func_other_argumentsto a scalar value of type DT_INT64.
Declaration
public static func experimentalGroupByWindowDataset< KeyfuncIn: TensorGroup, KeyfuncOut: TensorGroup, ReducefuncIn: TensorGroup, ReducefuncOut: TensorGroup, WindowsizefuncIn: TensorGroup, WindowsizefuncOut: TensorGroup, TkeyFuncOtherArguments: TensorArrayProtocol, TreduceFuncOtherArguments: TensorArrayProtocol, TwindowSizeFuncOtherArguments: TensorArrayProtocol >( inputDataset: VariantHandle, keyFuncOtherArguments: TkeyFuncOtherArguments, reduceFuncOtherArguments: TreduceFuncOtherArguments, windowSizeFuncOtherArguments: TwindowSizeFuncOtherArguments, keyFunc: (KeyfuncIn) -> KeyfuncOut, reduceFunc: (ReducefuncIn) -> ReducefuncOut, windowSizeFunc: (WindowsizefuncIn) -> WindowsizefuncOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle - Attr key_func: A function mapping an element of
-
Creates a dataset that contains the elements of
input_datasetignoring errors.Declaration
public static func experimentalIgnoreErrorsDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Returns the name of the device on which
resourcehas been placed.Declaration
public static func experimentalIteratorGetDevice( resource: ResourceHandle ) -> StringTensor -
Declaration
public static func experimentalLMDBDataset( filenames: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Records the latency of producing
input_datasetelements in a StatsAggregator.Declaration
public static func experimentalLatencyStatsDataset( inputDataset: VariantHandle, tag: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
experimentalMapAndBatchDataset(inputDataset:otherArguments:batchSize:numParallelCalls:dropRemainder:f:outputTypes:outputShapes:preserveCardinality:)
Creates a dataset that fuses mapping with batching.
Creates a dataset that applies
fto the outputs ofinput_datasetand then batchesbatch_sizeof them.Unlike a “MapDataset”, which applies
fsequentially, this dataset invokes up tobatch_size * num_parallel_batchescopies offin parallel.Attr f: A function to apply to the outputs of
input_dataset.
Declaration
public static func experimentalMapAndBatchDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, batchSize: Tensor<Int64>, numParallelCalls: Tensor<Int64>, dropRemainder: Tensor<Bool>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], preserveCardinality: Bool = false ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
other_argumentsA list of tensors, typically values that were captured when building a closure for
f.batch_sizeA scalar representing the number of elements to accumulate in a batch. It determines the number of concurrent invocations of
fthat process elements frominput_datasetin parallel.num_parallel_callsA scalar representing the maximum number of parallel invocations of the
map_fnfunction. Applying themap_fnon consecutive input elements in parallel has the potential to improve input pipeline throughput.drop_remainderA scalar representing whether the last batch should be dropped in case its size is smaller than desired.
-
experimentalMapDataset(inputDataset:otherArguments:f:outputTypes:outputShapes:useInterOpParallelism:preserveCardinality:)
Creates a dataset that applies
fto the outputs ofinput_dataset.Declaration
public static func experimentalMapDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], useInterOpParallelism: Bool = true, preserveCardinality: Bool = false ) -> VariantHandle -
Declaration
public static func experimentalMatchingFilesDataset( patterns: StringTensor ) -> VariantHandle -
experimentalMaxIntraOpParallelismDataset(inputDataset:maxIntraOpParallelism:outputTypes:outputShapes:)
Creates a dataset that overrides the maximum intra-op parallelism.
Declaration
public static func experimentalMaxIntraOpParallelismDataset( inputDataset: VariantHandle, maxIntraOpParallelism: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
max_intra_op_parallelismIdentifies the maximum intra-op parallelism to use.
-
Declaration
public static func experimentalNonSerializableDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
experimentalParallelInterleaveDataset(inputDataset:otherArguments:cycleLength:blockLength:sloppy:bufferOutputElements:prefetchInputElements:f:outputTypes:outputShapes:)
Creates a dataset that applies
fto the outputs ofinput_dataset.The resulting dataset is similar to the
InterleaveDataset, with the exception that if retrieving the next value from a dataset would cause the requester to block, it will skip that input dataset. This dataset is especially useful when loading data from a variable-latency datastores (e.g. HDFS, GCS), as it allows the training step to proceed so long as some data is available.!! WARNING !! This dataset is not deterministic!
- Attr f: A function mapping elements of
input_dataset, concatenated withother_arguments, to a Dataset variant that contains elements matchingoutput_typesandoutput_shapes.
Declaration
public static func experimentalParallelInterleaveDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, cycleLength: Tensor<Int64>, blockLength: Tensor<Int64>, sloppy: Tensor<Bool>, bufferOutputElements: Tensor<Int64>, prefetchInputElements: Tensor<Int64>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle - Attr f: A function mapping elements of
-
experimentalParseExampleDataset(inputDataset:numParallelCalls:denseDefaults:sparseKeys:denseKeys:sparseTypes:denseShapes:outputTypes:outputShapes:sloppy:)
Transforms
input_datasetcontainingExampleprotos as vectors of DT_STRING into a dataset ofTensororSparseTensorobjects representing the parsed features.Attrs:
- sparse_keys: A list of string keys in the examples features.
The results for these keys will be returned as
SparseTensorobjects. - dense_keys: A list of Ndense string Tensors (scalars). The keys expected in the Examples features associated with dense values.
- sparse_types: A list of
DTypesof the same length assparse_keys. Onlytf.float32(FloatList),tf.int64(Int64List), andtf.string(BytesList) are supported. - Tdense: A list of DTypes of the same length as
dense_keys. Onlytf.float32(FloatList),tf.int64(Int64List), andtf.string(BytesList) are supported. - dense_shapes: List of tuples with the same length as
dense_keys. The shape of the data for each dense feature referenced bydense_keys. Required for any input tensors identified bydense_keys. Must be either fully defined, or may contain an unknown first dimension. An unknown first dimension means the feature is treated as having a variable number of blocks, and the output shape along this dimension is considered unknown at graph build time. Padding is applied for minibatch elements smaller than the maximum number of blocks for the given feature along this dimension. - output_types: The type list for the return values.
- output_shapes: The list of shapes being produced.
- sparse_keys: A list of string keys in the examples features.
The results for these keys will be returned as
Declaration
public static func experimentalParseExampleDataset<Tdense: TensorArrayProtocol>( inputDataset: VariantHandle, numParallelCalls: Tensor<Int64>, denseDefaults: Tdense, sparseKeys: [String], denseKeys: [String], sparseTypes: [TensorDataType], denseShapes: [TensorShape?], outputTypes: [TensorDataType], outputShapes: [TensorShape?], sloppy: Bool = false ) -> VariantHandleParameters
dense_defaultsA dict mapping string keys to
Tensors. The keys of the dict must match the dense_keys of the feature. -
Creates a dataset that uses a custom thread pool to compute
input_dataset.Declaration
public static func experimentalPrivateThreadPoolDataset( inputDataset: VariantHandle, numThreads: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
num_threadsIdentifies the number of threads to use for the private threadpool.
-
Creates a Dataset that returns pseudorandom numbers.
Declaration
public static func experimentalRandomDataset( seed: Tensor<Int64>, seed2: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
seedA scalar seed for the random number generator. If either seed or seed2 is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
seed2A second scalar seed to avoid seed collision.
-
Creates a dataset that changes the batch size.
Creates a dataset that changes the batch size of the dataset to current batch size // num_replicas.
Declaration
public static func experimentalRebatchDataset( inputDataset: VariantHandle, numReplicas: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?], useFallback: Bool = true ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
num_replicasA scalar representing the number of replicas to distribute this batch across. As a result of this transformation the current batch size would end up being divided by this parameter.
-
experimentalScanDataset(inputDataset:initialState:otherArguments:f:outputTypes:outputShapes:preserveCardinality:)
Creates a dataset successively reduces
fover the elements ofinput_dataset.Declaration
public static func experimentalScanDataset< FIn: TensorGroup, FOut: TensorGroup, Tstate: TensorArrayProtocol, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, initialState: Tstate, otherArguments: Targuments, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], preserveCardinality: Bool = false ) -> VariantHandle -
experimentalSetStatsAggregatorDataset(inputDataset:statsAggregator:tag:counterPrefix:outputTypes:outputShapes:)
Declaration
public static func experimentalSetStatsAggregatorDataset( inputDataset: VariantHandle, statsAggregator: ResourceHandle, tag: StringTensor, counterPrefix: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Declaration
public static func experimentalSleepDataset( inputDataset: VariantHandle, sleepMicroseconds: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
experimentalSlidingWindowDataset(inputDataset:windowSize:windowShift:windowStride:outputTypes:outputShapes:)
Creates a dataset that passes a sliding window over
input_dataset.Declaration
public static func experimentalSlidingWindowDataset( inputDataset: VariantHandle, windowSize: Tensor<Int64>, windowShift: Tensor<Int64>, windowStride: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
window_sizeA scalar representing the number of elements in the sliding window.
window_shiftA scalar representing the steps moving the sliding window forward in one iteration. It must be positive.
window_strideA scalar representing the stride of the input elements of the sliding window. It must be positive.
-
Creates a dataset that executes a SQL query and emits rows of the result set.
Declaration
public static func experimentalSqlDataset( driverName: StringTensor, dataSourceName: StringTensor, query: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
driver_nameThe database type. Currently, the only supported type is ‘sqlite’.
data_source_nameA connection string to connect to the database.
queryA SQL query to execute.
-
Creates a statistics manager resource.
Declaration
public static func experimentalStatsAggregatorHandle( container: String, sharedName: String ) -> ResourceHandle -
Produces a summary of any statistics recorded by the given statistics manager.
Declaration
public static func experimentalStatsAggregatorSummary( iterator: ResourceHandle ) -> StringTensor -
Creates a dataset that stops iteration when predicate` is false.
The
predicatefunction must return a scalar boolean and accept the following arguments:- One tensor for each component of an element of
input_dataset. One tensor for each value in
other_arguments.Attr predicate: A function returning a scalar boolean.
Declaration
public static func experimentalTakeWhileDataset< PredicateIn: TensorGroup, PredicateOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, predicate: (PredicateIn) -> PredicateOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
other_argumentsA list of tensors, typically values that were captured when building a closure for
predicate. - One tensor for each component of an element of
-
Creates a dataset that uses a custom thread pool to compute
input_dataset.Declaration
public static func experimentalThreadPoolDataset( inputDataset: VariantHandle, threadPool: ResourceHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
thread_poolA resource produced by the ThreadPoolHandle op.
-
Creates a dataset that uses a custom thread pool to compute
input_dataset.Attrs:
- num_threads: The number of threads in the thread pool.
- max_intra_op_parallelism: The maximum degree of parallelism to use within operations that execute on this threadpool.
- display_name: A human-readable name for the threads that may be visible in some visualizations. threadpool.
Output handle: A resource that can be consumed by one or more ExperimentalThreadPoolDataset ops.
Declaration
public static func experimentalThreadPoolHandle( numThreads: Int64, maxIntraOpParallelism: Int64 = 1, displayName: String, container: String, sharedName: String ) -> ResourceHandle -
A dataset that splits the elements of its input into multiple elements.
Declaration
public static func experimentalUnbatchDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Creates a dataset that contains the unique elements of
input_dataset.Declaration
public static func experimentalUniqueDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Computes
exp(x) - 1element-wise.i.e.
exp(x) - 1ore^(x) - 1, wherexis the input tensor.edenotes Euler’s number and is approximately equal to 2.718281.x = tf.constant(2.0) tf.math.expm1(x) ==> 6.389056 x = tf.constant([2.0, 8.0]) tf.math.expm1(x) ==> array([6.389056, 2979.958], dtype=float32) x = tf.constant(1 + 1j) tf.math.expm1(x) ==> (0.46869393991588515+2.2873552871788423j)Declaration
public static func expm1<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Extracts a glimpse from the input tensor.
Returns a set of windows called glimpses extracted at location
offsetsfrom the input tensor. If the windows only partially overlaps the inputs, the non overlapping areas will be filled with random noise.The result is a 4-D tensor of shape
[batch_size, glimpse_height, glimpse_width, channels]. The channels and batch dimensions are the same as that of the input tensor. The height and width of the output windows are specified in thesizeparameter.The argument
normalizedandcenteredcontrols how the windows are built:- If the coordinates are normalized but not centered, 0.0 and 1.0 correspond to the minimum and maximum of each height and width dimension.
- If the coordinates are both normalized and centered, they range from -1.0 to 1.0. The coordinates (-1.0, -1.0) correspond to the upper left corner, the lower right corner is located at (1.0, 1.0) and the center is at (0, 0).
If the coordinates are not normalized they are interpreted as numbers of pixels.
Attrs:
- centered: indicates if the offset coordinates are centered relative to the image, in which case the (0, 0) offset is relative to the center of the input images. If false, the (0,0) offset corresponds to the upper left corner of the input images.
- normalized: indicates if the offset coordinates are normalized.
- uniform_noise: indicates if the noise should be generated using a uniform distribution or a Gaussian distribution.
- noise: indicates if the noise should
uniform,gaussian, orzero. The default isuniformwhich means the the noise type will be decided byuniform_noise.
Output glimpse: A tensor representing the glimpses
[batch_size, glimpse_height, glimpse_width, channels].
Declaration
Parameters
inputA 4-D float tensor of shape
[batch_size, height, width, channels].sizeA 1-D tensor of 2 elements containing the size of the glimpses to extract. The glimpse height must be specified first, following by the glimpse width.
offsetsA 2-D integer tensor of shape
[batch_size, 2]containing the y, x locations of the center of each window. -
Extract
patchesfromimagesand put them in the “depth” output dimension.Attrs:
- ksizes: The size of the sliding window for each dimension of
images. - strides: How far the centers of two consecutive patches are in
the images. Must be:
[1, stride_rows, stride_cols, 1]. - rates: Must be:
[1, rate_rows, rate_cols, 1]. This is the input stride, specifying how far two consecutive patch samples are in the input. Equivalent to extracting patches withpatch_sizes_eff = patch_sizes + (patch_sizes - 1) * (rates - 1), followed by subsampling them spatially by a factor ofrates. This is equivalent toratein dilated (a.k.a. Atrous) convolutions. - padding: The type of padding algorithm to use.
- ksizes: The size of the sliding window for each dimension of
Output patches: 4-D Tensor with shape
[batch, out_rows, out_cols, ksize_rows * ksize_cols * depth]containing image patches with sizeksize_rows x ksize_cols x depthvectorized in the “depth” dimension. Noteout_rowsandout_colsare the dimensions of the output patches.
Declaration
public static func extractImagePatches<T: TensorFlowNumeric>( images: Tensor<T>, ksizes: [Int32], strides: [Int32], rates: [Int32], padding: Padding ) -> Tensor<T>Parameters
images4-D Tensor with shape
[batch, in_rows, in_cols, depth]. -
Extract the shape information of a JPEG-encoded image.
This op only parses the image header, so it is much faster than DecodeJpeg.
Attr output_type: (Optional) The output type of the operation (int32 or int64). Defaults to int32.
Output image_shape: 1-D. The image shape with format [height, width, channels].
Declaration
public static func extractJpegShape<OutputType: TensorFlowIndex>( contents: StringTensor ) -> Tensor<OutputType>Parameters
contents0-D. The JPEG-encoded image.
-
Extract
patchesfrominputand put them in the “depth” output dimension. 3D extension ofextract_image_patches.Attrs:
- ksizes: The size of the sliding window for each dimension of
input. - strides: 1-D of length 5. How far the centers of two consecutive patches are in
input. Must be:[1, stride_planes, stride_rows, stride_cols, 1]. padding: The type of padding algorithm to use.
We specify the size-related attributes as:
ksizes = [1, ksize_planes, ksize_rows, ksize_cols, 1] strides = [1, stride_planes, strides_rows, strides_cols, 1]
- ksizes: The size of the sliding window for each dimension of
Output patches: 5-D Tensor with shape
[batch, out_planes, out_rows, out_cols, ksize_planes * ksize_rows * ksize_cols * depth]containing patches with sizeksize_planes x ksize_rows x ksize_cols x depthvectorized in the “depth” dimension. Noteout_planes,out_rowsandout_colsare the dimensions of the output patches.
Declaration
public static func extractVolumePatches<T: TensorFlowNumeric>( _ input: Tensor<T>, ksizes: [Int32], strides: [Int32], padding: Padding ) -> Tensor<T>Parameters
input5-D Tensor with shape
[batch, in_planes, in_rows, in_cols, depth]. -
Fast Fourier transform.
Computes the 1-dimensional discrete Fourier transform over the inner-most dimension of
input.Output output: A complex tensor of the same shape as
input. The inner-most dimension ofinputis replaced with its 1D Fourier transform.@compatibility(numpy) Equivalent to np.fft.fft @end_compatibility
Declaration
public static func fFT<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
2D fast Fourier transform.
Computes the 2-dimensional discrete Fourier transform over the inner-most 2 dimensions of
input.Output output: A complex tensor of the same shape as
input. The inner-most 2 dimensions ofinputare replaced with their 2D Fourier transform.@compatibility(numpy) Equivalent to np.fft.fft2 @end_compatibility
Declaration
public static func fFT2D<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
3D fast Fourier transform.
Computes the 3-dimensional discrete Fourier transform over the inner-most 3 dimensions of
input.Output output: A complex tensor of the same shape as
input. The inner-most 3 dimensions ofinputare replaced with their 3D Fourier transform.@compatibility(numpy) Equivalent to np.fft.fftn with 3 dimensions. @end_compatibility
Declaration
public static func fFT3D<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
A queue that produces elements in first-in first-out order.
Attrs:
- component_types: The type of each component in a value.
- shapes: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time.
- capacity: The upper bound on the number of elements in this queue. Negative numbers mean no limit.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this queue will be shared under the given name across multiple sessions.
Output handle: The handle to the queue.
Declaration
public static func fIFOQueueV2( componentTypes: [TensorDataType], shapes: [TensorShape?], capacity: Int64 = -1, container: String, sharedName: String ) -> ResourceHandle -
Output a fact about factorials.
Declaration
public static func fact() -> StringTensor -
This op is used as a placeholder in If branch functions. It doesn’t provide a valid output when run, so must either be removed (e.g. replaced with a function input) or guaranteed not to be used (e.g. if mirroring an intermediate output needed for the gradient computation of the other branch).
Attrs:
- dtype: The type of the output.
- shape: The purported shape of the output. This is only used for shape inference; the output will not necessarily have this shape. Can be a partial shape.
Output output: \“Fake\” output value. This should not be consumed by another op.
Declaration
public static func fakeParam<Dtype: TensorFlowScalar>( shape: TensorShape? ) -> Tensor<Dtype> -
Fake-quantize the ‘inputs’ tensor, type float to ‘outputs’ tensor of same type.
Attributes
[min; max]define the clamping range for theinputsdata.inputsvalues are quantized into the quantization range ([0; 2^num_bits - 1]whennarrow_rangeis false and[1; 2^num_bits - 1]when it is true) and then de-quantized and output as floats in[min; max]interval.num_bitsis the bitwidth of the quantization; between 2 and 16, inclusive.Before quantization,
minandmaxvalues are adjusted with the following logic. It is suggested to havemin <= 0 <= max. If0is not in the range of values, the behavior can be unexpected: If0 < min < max:min_adj = 0andmax_adj = max - min. Ifmin < max < 0:min_adj = min - maxandmax_adj = 0. Ifmin <= 0 <= max:scale = (max - min) / (2^num_bits - 1),min_adj = scale * round(min / scale)andmax_adj = max + min_adj - min.Quantization is called fake since the output is still in floating point.
-
Compute gradients for a FakeQuantWithMinMaxArgs operation.
Output backprops: Backpropagated gradients below the FakeQuantWithMinMaxArgs operation:
gradients * (inputs >= min && inputs <= max).
Declaration
Parameters
gradientsBackpropagated gradients above the FakeQuantWithMinMaxArgs operation.
inputsValues passed as inputs to the FakeQuantWithMinMaxArgs operation.
-
Fake-quantize the ‘inputs’ tensor of type float via global float scalars
minand
maxto ‘outputs’ tensor of same shape asinputs.[min; max]define the clamping range for theinputsdata.inputsvalues are quantized into the quantization range ([0; 2^num_bits - 1]whennarrow_rangeis false and[1; 2^num_bits - 1]when it is true) and then de-quantized and output as floats in[min; max]interval.num_bitsis the bitwidth of the quantization; between 2 and 16, inclusive.Before quantization,
minandmaxvalues are adjusted with the following logic. It is suggested to havemin <= 0 <= max. If0is not in the range of values, the behavior can be unexpected: If0 < min < max:min_adj = 0andmax_adj = max - min. Ifmin < max < 0:min_adj = min - maxandmax_adj = 0. Ifmin <= 0 <= max:scale = (max - min) / (2^num_bits - 1),min_adj = scale * round(min / scale)andmax_adj = max + min_adj - min.This operation has a gradient and thus allows for training
minandmaxvalues. -
Compute gradients for a FakeQuantWithMinMaxVars operation.
Attrs:
- num_bits: The bitwidth of the quantization; between 2 and 8, inclusive.
- narrow_range: Whether to quantize into 2^num_bits - 1 distinct values.
Outputs:
- backprops_wrt_input: Backpropagated gradients w.r.t. inputs:
gradients * (inputs >= min && inputs <= max). - backprop_wrt_min: Backpropagated gradients w.r.t. min parameter:
sum(gradients * (inputs < min)). - backprop_wrt_max: Backpropagated gradients w.r.t. max parameter:
sum(gradients * (inputs > max)).
- backprops_wrt_input: Backpropagated gradients w.r.t. inputs:
Declaration
Parameters
gradientsBackpropagated gradients above the FakeQuantWithMinMaxVars operation.
inputsValues passed as inputs to the FakeQuantWithMinMaxVars operation. min, max: Quantization interval, scalar floats.
-
Fake-quantize the ‘inputs’ tensor of type float and one of the shapes:
[d],[b, d][b, h, w, d]via per-channel floatsminandmaxof shape[d]to ‘outputs’ tensor of same shape asinputs.[min; max]define the clamping range for theinputsdata.inputsvalues are quantized into the quantization range ([0; 2^num_bits - 1]whennarrow_rangeis false and[1; 2^num_bits - 1]when it is true) and then de-quantized and output as floats in[min; max]interval.num_bitsis the bitwidth of the quantization; between 2 and 16, inclusive.Before quantization,
minandmaxvalues are adjusted with the following logic. It is suggested to havemin <= 0 <= max. If0is not in the range of values, the behavior can be unexpected: If0 < min < max:min_adj = 0andmax_adj = max - min. Ifmin < max < 0:min_adj = min - maxandmax_adj = 0. Ifmin <= 0 <= max:scale = (max - min) / (2^num_bits - 1),min_adj = scale * round(min / scale)andmax_adj = max + min_adj - min.This operation has a gradient and thus allows for training
minandmaxvalues. -
Compute gradients for a FakeQuantWithMinMaxVarsPerChannel operation.
Attrs:
- num_bits: The bitwidth of the quantization; between 2 and 16, inclusive.
- narrow_range: Whether to quantize into 2^num_bits - 1 distinct values.
Outputs:
- backprops_wrt_input: Backpropagated gradients w.r.t. inputs, shape same as
inputs:gradients * (inputs >= min && inputs <= max). - backprop_wrt_min: Backpropagated gradients w.r.t. min parameter, shape
[d]:sum_per_d(gradients * (inputs < min)). - backprop_wrt_max: Backpropagated gradients w.r.t. max parameter, shape
[d]:sum_per_d(gradients * (inputs > max)).
- backprops_wrt_input: Backpropagated gradients w.r.t. inputs, shape same as
Declaration
public static func fakeQuantWithMinMaxVarsPerChannelGradient( gradients: Tensor<Float>, inputs: Tensor<Float>, min: Tensor<Float>, max: Tensor<Float>, numBits: Int64 = 8, narrowRange: Bool = false ) -> ( backpropsWrtInput: Tensor<Float>, backpropWrtMin: Tensor<Float>, backpropWrtMax: Tensor<Float> )Parameters
gradientsBackpropagated gradients above the FakeQuantWithMinMaxVars operation, shape one of:
[d],[b, d],[b, h, w, d].inputsValues passed as inputs to the FakeQuantWithMinMaxVars operation, shape same as
gradients. min, max: Quantization interval, floats of shape[d]. -
Creates a tensor filled with a scalar value.
This operation creates a tensor of shape
dimsand fills it withvalue.For example:
# Output tensor has shape [2, 3]. fill([2, 3], 9) ==> [[9, 9, 9] [9, 9, 9]]tf.filldiffers fromtf.constantin a few ways:tf.fillonly supports scalar contents, whereastf.constantsupports Tensor values.tf.fillcreates an Op in the computation graph that constructs the actual Tensor value at runtime. This is in contrast totf.constantwhich embeds the entire Tensor into the graph with aConstnode.Because
tf.fillevaluates at graph runtime, it supports dynamic shapes based on other runtime Tensors, unliketf.constant.
Declaration
public static func fill< T: TensorFlowScalar, IndexType: TensorFlowIndex >( dims: Tensor<IndexType>, value: Tensor<T> ) -> Tensor<T>Parameters
dims1-D. Represents the shape of the output tensor.
value0-D (scalar). Value to fill the returned tensor.
@compatibility(numpy) Equivalent to np.full @end_compatibility
-
Creates a dataset containing elements of first component of
input_datasethaving true in the last component.Declaration
public static func filterByLastComponentDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Creates a dataset containing elements of
input_datasetmatchingpredicate.The
predicatefunction must return a scalar boolean and accept the following arguments:- One tensor for each component of an element of
input_dataset. One tensor for each value in
other_arguments.Attr predicate: A function returning a scalar boolean.
Declaration
public static func filterDataset< PredicateIn: TensorGroup, PredicateOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, predicate: (PredicateIn) -> PredicateOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
other_argumentsA list of tensors, typically values that were captured when building a closure for
predicate. - One tensor for each component of an element of
-
Generates fingerprint values.
Generates fingerprint values of
data.Fingerprint op considers the first dimension of
dataas the batch dimension, andoutput[i]contains the fingerprint value generated from contents indata[i, ...]for alli.Fingerprint op writes fingerprint values as byte arrays. For example, the default method
farmhash64generates a 64-bit fingerprint value at a time. This 8-byte value is written out as anuint8array of size 8, in little-endian order.For example, suppose that
datahas data typeDT_INT32and shape (2, 3, 4), and that the fingerprint method isfarmhash64. In this case, the output shape is (2, 8), where 2 is the batch dimension size ofdata, and 8 is the size of each fingerprint value in bytes.output[0, :]is generated from 12 integers indata[0, :, :]and similarlyoutput[1, :]is generated from other 12 integers indata[1, :, :].Note that this op fingerprints the raw underlying buffer, and it does not fingerprint Tensor’s metadata such as data type and/or shape. For example, the fingerprint values are invariant under reshapes and bitcasts as long as the batch dimension remain the same:
Fingerprint(data) == Fingerprint(Reshape(data, ...)) Fingerprint(data) == Fingerprint(Bitcast(data, ...))For string data, one should expect
Fingerprint(data) != Fingerprint(ReduceJoin(data))in general.Attr T: This can be a POD-type or string type.
Output fingerprint: A two-dimensional
Tensorof typetf.uint8. The first dimension equals todata‘s first dimension, and the second dimension size depends on the fingerprint algorithm.
Declaration
public static func fingerprint<T: TensorFlowScalar>( data: Tensor<T>, method: StringTensor ) -> Tensor<UInt8>Parameters
dataMust have rank 1 or higher.
methodFingerprint method used by this op. Currently available method is
farmhash::fingerprint64. -
Creates a dataset that emits the records from one or more binary files.
Declaration
public static func fixedLengthRecordDataset( filenames: StringTensor, headerBytes: Tensor<Int64>, recordBytes: Tensor<Int64>, footerBytes: Tensor<Int64>, bufferSize: Tensor<Int64> ) -> VariantHandleParameters
filenamesA scalar or a vector containing the name(s) of the file(s) to be read.
header_bytesA scalar representing the number of bytes to skip at the beginning of a file.
record_bytesA scalar representing the number of bytes in each record.
footer_bytesA scalar representing the number of bytes to skip at the end of a file.
buffer_sizeA scalar representing the number of bytes to buffer. Must be > 0.
-
fixedLengthRecordDatasetV2(filenames:headerBytes:recordBytes:footerBytes:bufferSize:compressionType:)
Declaration
public static func fixedLengthRecordDatasetV2( filenames: StringTensor, headerBytes: Tensor<Int64>, recordBytes: Tensor<Int64>, footerBytes: Tensor<Int64>, bufferSize: Tensor<Int64>, compressionType: StringTensor ) -> VariantHandle -
fixedLengthRecordReaderV2(headerBytes:recordBytes:footerBytes:hopBytes:container:sharedName:encoding:)
A Reader that outputs fixed-length records from a file.
Attrs:
- header_bytes: Number of bytes in the header, defaults to 0.
- record_bytes: Number of bytes in the record.
- footer_bytes: Number of bytes in the footer, defaults to 0.
- hop_bytes: Number of bytes to hop before each read. Default of 0 means using record_bytes.
- container: If non-empty, this reader is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
- encoding: The type of encoding for the file. Currently ZLIB and GZIP are supported. Defaults to none.
Output reader_handle: The handle to reference the Reader.
Declaration
public static func fixedLengthRecordReaderV2( headerBytes: Int64 = 0, recordBytes: Int64, footerBytes: Int64 = 0, hopBytes: Int64 = 0, container: String, sharedName: String, encoding: String ) -> ResourceHandle -
fixedUnigramCandidateSampler(trueClasses:numTrue:numSampled:unique:rangeMax:vocabFile:distortion:numReservedIds:numShards:shard:unigrams:seed:seed2:)
Generates labels for candidate sampling with a learned unigram distribution.
A unigram sampler could use a fixed unigram distribution read from a file or passed in as an in-memory array instead of building up the distribution from data on the fly. There is also an option to skew the distribution by applying a distortion power to the weights.
The vocabulary file should be in CSV-like format, with the last field being the weight associated with the word.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to randomly sample.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- range_max: The sampler will sample integers from the interval [0, range_max).
- vocab_file: Each valid line in this file (which should have a CSV-like format) corresponds to a valid word ID. IDs are in sequential order, starting from num_reserved_ids. The last entry in each line is expected to be a value corresponding to the count or relative probability. Exactly one of vocab_file and unigrams needs to be passed to this op.
- distortion: The distortion is used to skew the unigram probability distribution. Each weight is first raised to the distortion’s power before adding to the internal unigram distribution. As a result, distortion = 1.0 gives regular unigram sampling (as defined by the vocab file), and distortion = 0.0 gives a uniform distribution.
- num_reserved_ids: Optionally some reserved IDs can be added in the range [0, …, num_reserved_ids) by the users. One use case is that a special unknown word token is used as ID 0. These IDs will have a sampling probability of 0.
- num_shards: A sampler can be used to sample from a subset of the original range in order to speed up the whole computation through parallelism. This parameter (together with ‘shard’) indicates the number of partitions that are being used in the overall computation.
- shard: A sampler can be used to sample from a subset of the original range in order to speed up the whole computation through parallelism. This parameter (together with ‘num_shards’) indicates the particular partition number of a sampler op, when partitioning is being used.
- unigrams: A list of unigram counts or probabilities, one per ID in sequential order. Exactly one of vocab_file and unigrams should be passed to this op.
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
public static func fixedUnigramCandidateSampler( trueClasses: Tensor<Int64>, numTrue: Int64, numSampled: Int64, unique: Bool, rangeMax: Int64, vocabFile: String, distortion: Double = 1, numReservedIds: Int64 = 0, numShards: Int64 = 1, shard: Int64 = 0, unigrams: [Double], seed: Int64 = 0, seed2: Int64 = 0 ) -> ( sampledCandidates: Tensor<Int64>, trueExpectedCount: Tensor<Float>, sampledExpectedCount: Tensor<Float> )Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
Creates a dataset that applies
fto the outputs ofinput_dataset.Unlike MapDataset, the
fin FlatMapDataset is expected to return a Dataset variant, and FlatMapDataset will flatten successive results into a single Dataset.- Attr f: A function mapping elements of
input_dataset, concatenated withother_arguments, to a Dataset variant that contains elements matchingoutput_typesandoutput_shapes.
Declaration
public static func flatMapDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle - Attr f: A function mapping elements of
-
Declaration
public static func floatInput( _ a: Tensor<Float> ) -
Declaration
public static func floatOutput() -> Tensor<Float> -
Declaration
public static func floatOutputStringOutput() -> (a: Tensor<Float>, b: StringTensor) -
Returns element-wise largest integer not greater than x.
Declaration
public static func floor<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Returns x // y element-wise.
NOTE:
FloorDivsupports broadcasting. More about broadcasting hereDeclaration
public static func floorDiv<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns element-wise remainder of division. When
x < 0xory < 0istrue, this follows Python semantics in that the result here is consistent with a flooring divide. E.g.
floor(x / y) * y + mod(x, y) = x.NOTE:
FloorModsupports broadcasting. More about broadcasting hereDeclaration
public static func floorMod<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Declaration
public static func flushSummaryWriter( writer: ResourceHandle ) -
Declaration
public static func foo2( _ a: Tensor<Float>, _ b: StringTensor, c: StringTensor ) -> (d: Tensor<Float>, e: Tensor<Int32>) -
Declaration
public static func foo3( _ a: Tensor<Float>, _ b: StringTensor, c: Tensor<Float> ) -> (d: Tensor<Float>, e: Tensor<Int32>) -
output = input; for i in range(start, limit, delta) output = body(i, output);Attrs:
- T: A list of dtypes.
- body: A function that takes a list of tensors (int32, T) and returns another list of tensors (T).
Output output: A list of output tensors whose types are T.
Declaration
public static func for_< T: TensorArrayProtocol, BodyIn: TensorGroup, BodyOut: TensorGroup >( start: Tensor<Int32>, limit: Tensor<Int32>, delta: Tensor<Int32>, _ input: T, body: (BodyIn) -> BodyOut ) -> TParameters
startThe lower bound. An int32
limitThe upper bound. An int32
deltaThe increment. An int32
inputA list of input tensors whose types are T.
-
Performs fractional average pooling on the input.
Fractional average pooling is similar to Fractional max pooling in the pooling region generation step. The only difference is that after pooling regions are generated, a mean operation is performed instead of a max operation in each pooling region.
Attrs:
- pooling_ratio: Pooling ratio for each dimension of
value, currently only supports row and col dimension and should be >= 1.0. For example, a valid pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements must be 1.0 because we don’t allow pooling on batch and channels dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions respectively. - pseudo_random: When set to True, generates the pooling sequence in a pseudorandom fashion, otherwise, in a random fashion. Check paper Benjamin Graham, Fractional Max-Pooling for difference between pseudorandom and random.
overlapping: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
index 0 1 2 3 4value 20 5 16 3 7If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [41/3, 26/3] for fractional avg pooling.
deterministic: When set to True, a fixed pooling region will be used when iterating over a FractionalAvgPool node in the computation graph. Mainly used in unit test to make FractionalAvgPool deterministic.
seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
seed2: An second seed to avoid seed collision.
- pooling_ratio: Pooling ratio for each dimension of
Outputs:
- output: output tensor after fractional avg pooling.
- row_pooling_sequence: row pooling sequence, needed to calculate gradient.
- col_pooling_sequence: column pooling sequence, needed to calculate gradient.
Declaration
public static func fractionalAvgPool<T: TensorFlowNumeric>( value: Tensor<T>, poolingRatio: [Double], pseudoRandom: Bool = false, overlapping: Bool = false, deterministic: Bool = false, seed: Int64 = 0, seed2: Int64 = 0 ) -> (output: Tensor<T>, rowPoolingSequence: Tensor<Int64>, colPoolingSequence: Tensor<Int64>)Parameters
value4-D with shape
[batch, height, width, channels]. -
fractionalAvgPoolGrad(origInputTensorShape:outBackprop:rowPoolingSequence:colPoolingSequence:overlapping:)
Computes gradient of the FractionalAvgPool function.
Unlike FractionalMaxPoolGrad, we don’t need to find arg_max for FractionalAvgPoolGrad, we just need to evenly back-propagate each element of out_backprop to those indices that form the same pooling cell. Therefore, we just need to know the shape of original input tensor, instead of the whole tensor.
Attr overlapping: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
index 0 1 2 3 4value 20 5 16 3 7If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [41/3, 26/3] for fractional avg pooling.
Output output: 4-D. Gradients w.r.t. the input of
fractional_avg_pool.
Declaration
Parameters
orig_input_tensor_shapeOriginal input tensor shape for
fractional_avg_poolout_backprop4-D with shape
[batch, height, width, channels]. Gradients w.r.t. the output offractional_avg_pool.row_pooling_sequencerow pooling sequence, form pooling region with col_pooling_sequence.
col_pooling_sequencecolumn pooling sequence, form pooling region with row_pooling sequence.
-
Performs fractional max pooling on the input.
Fractional max pooling is slightly different than regular max pooling. In regular max pooling, you downsize an input set by taking the maximum value of smaller N x N subsections of the set (often 2x2), and try to reduce the set by a factor of N, where N is an integer. Fractional max pooling, as you might expect from the word “fractional”, means that the overall reduction ratio N does not have to be an integer.
The sizes of the pooling regions are generated randomly but are fairly uniform. For example, let’s look at the height dimension, and the constraints on the list of rows that will be pool boundaries.
First we define the following:
- input_row_length : the number of rows from the input set
- output_row_length : which will be smaller than the input
- alpha = input_row_length / output_row_length : our reduction ratio
- K = floor(alpha)
- row_pooling_sequence : this is the result list of pool boundary rows
Then, row_pooling_sequence should satisfy:
- a[0] = 0 : the first value of the sequence is 0
- a[end] = input_row_length : the last value of the sequence is the size
- K <= (a[i+1] - a[i]) <= K+1 : all intervals are K or K+1 size
- length(row_pooling_sequence) = output_row_length+1
For more details on fractional max pooling, see this paper: Benjamin Graham, Fractional Max-Pooling
Attrs:
- pooling_ratio: Pooling ratio for each dimension of
value, currently only supports row and col dimension and should be >= 1.0. For example, a valid pooling ratio looks like [1.0, 1.44, 1.73, 1.0]. The first and last elements must be 1.0 because we don’t allow pooling on batch and channels dimensions. 1.44 and 1.73 are pooling ratio on height and width dimensions respectively. - pseudo_random: When set to True, generates the pooling sequence in a pseudorandom fashion, otherwise, in a random fashion. Check paper Benjamin Graham, Fractional Max-Pooling for difference between pseudorandom and random.
overlapping: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
index 0 1 2 3 4value 20 5 16 3 7If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [20, 16] for fractional max pooling.
deterministic: When set to True, a fixed pooling region will be used when iterating over a FractionalMaxPool node in the computation graph. Mainly used in unit test to make FractionalMaxPool deterministic.
seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
seed2: An second seed to avoid seed collision.
- pooling_ratio: Pooling ratio for each dimension of
Outputs:
- output: output tensor after fractional max pooling.
- row_pooling_sequence: row pooling sequence, needed to calculate gradient.
- col_pooling_sequence: column pooling sequence, needed to calculate gradient.
Declaration
public static func fractionalMaxPool<T: TensorFlowNumeric>( value: Tensor<T>, poolingRatio: [Double], pseudoRandom: Bool = false, overlapping: Bool = false, deterministic: Bool = false, seed: Int64 = 0, seed2: Int64 = 0 ) -> (output: Tensor<T>, rowPoolingSequence: Tensor<Int64>, colPoolingSequence: Tensor<Int64>)Parameters
value4-D with shape
[batch, height, width, channels]. -
fractionalMaxPoolGrad(origInput:origOutput:outBackprop:rowPoolingSequence:colPoolingSequence:overlapping:)
Computes gradient of the FractionalMaxPool function.
Attr overlapping: When set to True, it means when pooling, the values at the boundary of adjacent pooling cells are used by both cells. For example:
index 0 1 2 3 4value 20 5 16 3 7If the pooling sequence is [0, 2, 4], then 16, at index 2 will be used twice. The result would be [20, 16] for fractional max pooling.
Output output: 4-D. Gradients w.r.t. the input of
fractional_max_pool.
Declaration
Parameters
orig_inputOriginal input for
fractional_max_poolorig_outputOriginal output for
fractional_max_poolout_backprop4-D with shape
[batch, height, width, channels]. Gradients w.r.t. the output offractional_max_pool.row_pooling_sequencerow pooling sequence, form pooling region with col_pooling_sequence.
col_pooling_sequencecolumn pooling sequence, form pooling region with row_pooling sequence.
-
Declaration
public static func funcAttr< FIn: TensorGroup, FOut: TensorGroup >( f: (FIn) -> FOut ) -
Batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for x and y. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- y: A 4D Tensor for output data.
- batch_mean: A 1D Tensor for the computed batch mean, to be used by TensorFlow to compute the running mean.
- batch_variance: A 1D Tensor for the computed batch variance, to be used by TensorFlow to compute the running variance.
- reserve_space_1: A 1D Tensor for the computed batch mean, to be reused in the gradient computation.
- reserve_space_2: A 1D Tensor for the computed batch variance (inverted variance in the cuDNN case), to be reused in the gradient computation.
Declaration
public static func fusedBatchNorm<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, scale: Tensor<T>, offset: Tensor<T>, mean: Tensor<T>, variance: Tensor<T>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( y: Tensor<T>, batchMean: Tensor<T>, batchVariance: Tensor<T>, reserveSpace1: Tensor<T>, reserveSpace2: Tensor<T> )Parameters
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
offsetA 1D Tensor for offset, to shift to the normalized x.
meanA 1D Tensor for population mean. Used for inference only; must be empty for training.
varianceA 1D Tensor for population variance. Used for inference only; must be empty for training.
-
Gradient for batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for y_backprop, x, x_backprop. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- x_backprop: A 4D Tensor for the gradient with respect to x.
- scale_backprop: A 1D Tensor for the gradient with respect to scale.
- offset_backprop: A 1D Tensor for the gradient with respect to offset.
- reserve_space_3: Unused placeholder to match the mean input in FusedBatchNorm.
- reserve_space_4: Unused placeholder to match the variance input in FusedBatchNorm.
Declaration
public static func fusedBatchNormGrad<T: FloatingPoint & TensorFlowScalar>( yBackprop: Tensor<T>, _ x: Tensor<T>, scale: Tensor<T>, reserveSpace1: Tensor<T>, reserveSpace2: Tensor<T>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( xBackprop: Tensor<T>, scaleBackprop: Tensor<T>, offsetBackprop: Tensor<T>, reserveSpace3: Tensor<T>, reserveSpace4: Tensor<T> )Parameters
y_backpropA 4D Tensor for the gradient with respect to y.
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
reserve_space_1When is_training is True, a 1D Tensor for the computed batch mean to be reused in gradient computation. When is_training is False, a 1D Tensor for the population mean to be reused in both 1st and 2nd order gradient computation.
reserve_space_2When is_training is True, a 1D Tensor for the computed batch variance (inverted variance in the cuDNN case) to be reused in gradient computation. When is_training is False, a 1D Tensor for the population variance to be reused in both 1st and 2nd order gradient computation.
-
Gradient for batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- U: The data type for the scale, offset, mean, and variance.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for y_backprop, x, x_backprop. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- x_backprop: A 4D Tensor for the gradient with respect to x.
- scale_backprop: A 1D Tensor for the gradient with respect to scale.
- offset_backprop: A 1D Tensor for the gradient with respect to offset.
- reserve_space_3: Unused placeholder to match the mean input in FusedBatchNorm.
- reserve_space_4: Unused placeholder to match the variance input in FusedBatchNorm.
Declaration
public static func fusedBatchNormGradV2< T: FloatingPoint & TensorFlowScalar, U: FloatingPoint & TensorFlowScalar >( yBackprop: Tensor<T>, _ x: Tensor<T>, scale: Tensor<Float>, reserveSpace1: Tensor<U>, reserveSpace2: Tensor<U>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( xBackprop: Tensor<T>, scaleBackprop: Tensor<U>, offsetBackprop: Tensor<U>, reserveSpace3: Tensor<U>, reserveSpace4: Tensor<U> )Parameters
y_backpropA 4D Tensor for the gradient with respect to y.
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
reserve_space_1When is_training is True, a 1D Tensor for the computed batch mean to be reused in gradient computation. When is_training is False, a 1D Tensor for the population mean to be reused in both 1st and 2nd order gradient computation.
reserve_space_2When is_training is True, a 1D Tensor for the computed batch variance (inverted variance in the cuDNN case) to be reused in gradient computation. When is_training is False, a 1D Tensor for the population variance to be reused in both 1st and 2nd order gradient computation.
-
fusedBatchNormGradV3(yBackprop:_:scale:reserveSpace1:reserveSpace2:reserveSpace3:epsilon:dataFormat:isTraining:)
Gradient for batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- U: The data type for the scale, offset, mean, and variance.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for y_backprop, x, x_backprop. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- x_backprop: A 4D Tensor for the gradient with respect to x.
- scale_backprop: A 1D Tensor for the gradient with respect to scale.
- offset_backprop: A 1D Tensor for the gradient with respect to offset.
- reserve_space_4: Unused placeholder to match the mean input in FusedBatchNorm.
- reserve_space_5: Unused placeholder to match the variance input in FusedBatchNorm.
Declaration
public static func fusedBatchNormGradV3< T: FloatingPoint & TensorFlowScalar, U: FloatingPoint & TensorFlowScalar >( yBackprop: Tensor<T>, _ x: Tensor<T>, scale: Tensor<Float>, reserveSpace1: Tensor<U>, reserveSpace2: Tensor<U>, reserveSpace3: Tensor<U>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( xBackprop: Tensor<T>, scaleBackprop: Tensor<U>, offsetBackprop: Tensor<U>, reserveSpace4: Tensor<U>, reserveSpace5: Tensor<U> )Parameters
y_backpropA 4D Tensor for the gradient with respect to y.
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
reserve_space_1When is_training is True, a 1D Tensor for the computed batch mean to be reused in gradient computation. When is_training is False, a 1D Tensor for the population mean to be reused in both 1st and 2nd order gradient computation.
reserve_space_2When is_training is True, a 1D Tensor for the computed batch variance (inverted variance in the cuDNN case) to be reused in gradient computation. When is_training is False, a 1D Tensor for the population variance to be reused in both 1st and 2nd order gradient computation.
reserve_space_3When is_training is True, a 1D Tensor for some intermediate results to be reused in gradient computation. When is_training is False, a dummy empty Tensor will be created.
-
Batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- U: The data type for the scale, offset, mean, and variance.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for x and y. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- y: A 4D Tensor for output data.
- batch_mean: A 1D Tensor for the computed batch mean, to be used by TensorFlow to compute the running mean.
- batch_variance: A 1D Tensor for the computed batch variance, to be used by TensorFlow to compute the running variance.
- reserve_space_1: A 1D Tensor for the computed batch mean, to be reused in the gradient computation.
- reserve_space_2: A 1D Tensor for the computed batch variance (inverted variance in the cuDNN case), to be reused in the gradient computation.
Declaration
public static func fusedBatchNormV2< T: FloatingPoint & TensorFlowScalar, U: FloatingPoint & TensorFlowScalar >( _ x: Tensor<T>, scale: Tensor<U>, offset: Tensor<U>, mean: Tensor<U>, variance: Tensor<U>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( y: Tensor<T>, batchMean: Tensor<U>, batchVariance: Tensor<U>, reserveSpace1: Tensor<U>, reserveSpace2: Tensor<U> )Parameters
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
offsetA 1D Tensor for offset, to shift to the normalized x.
meanA 1D Tensor for population mean. Used for inference only; must be empty for training.
varianceA 1D Tensor for population variance. Used for inference only; must be empty for training.
-
Batch normalization.
Note that the size of 4D Tensors are defined by either “NHWC” or “NCHW”. The size of 1D Tensors matches the dimension C of the 4D Tensors.
Attrs:
- T: The data type for the elements of input and output Tensors.
- U: The data type for the scale, offset, mean, and variance.
- epsilon: A small float number added to the variance of x.
- data_format: The data format for x and y. Either “NHWC” (default) or “NCHW”.
- is_training: A bool value to indicate the operation is for training (default) or inference.
Outputs:
- y: A 4D Tensor for output data.
- batch_mean: A 1D Tensor for the computed batch mean, to be used by TensorFlow to compute the running mean.
- batch_variance: A 1D Tensor for the computed batch variance, to be used by TensorFlow to compute the running variance.
- reserve_space_1: A 1D Tensor for the computed batch mean, to be reused in the gradient computation.
- reserve_space_2: A 1D Tensor for the computed batch variance (inverted variance in the cuDNN case), to be reused in the gradient computation.
- reserve_space_3: A 1D Tensor for some intermediate results, to be reused in the gradient computation for better efficiency.
Declaration
public static func fusedBatchNormV3< T: FloatingPoint & TensorFlowScalar, U: FloatingPoint & TensorFlowScalar >( _ x: Tensor<T>, scale: Tensor<U>, offset: Tensor<U>, mean: Tensor<U>, variance: Tensor<U>, epsilon: Double = 0.0001, dataFormat: DataFormat = .nhwc, isTraining: Bool = true ) -> ( y: Tensor<T>, batchMean: Tensor<U>, batchVariance: Tensor<U>, reserveSpace1: Tensor<U>, reserveSpace2: Tensor<U>, reserveSpace3: Tensor<U> )Parameters
xA 4D Tensor for input data.
scaleA 1D Tensor for scaling factor, to scale the normalized x.
offsetA 1D Tensor for offset, to shift to the normalized x.
meanA 1D Tensor for population mean. Used for inference only; must be empty for training.
varianceA 1D Tensor for population variance. Used for inference only; must be empty for training.
-
Performs a padding as a preprocess during a convolution.
Similar to FusedResizeAndPadConv2d, this op allows for an optimized implementation where the spatial padding transformation stage is fused with the im2col lookup, but in this case without the bilinear filtering required for resizing. Fusing the padding prevents the need to write out the intermediate results as whole tensors, reducing memory pressure, and we can get some latency gains by merging the transformation calculations. The data_format attribute for Conv2D isn’t supported by this op, and ‘NHWC’ order is used instead. Internally this op uses a single per-graph scratch buffer, which means that it will block if multiple versions are being run in parallel. This is because this operator is primarily an optimization to minimize memory usage.
Attrs:
- strides: 1-D of length 4. The stride of the sliding window for each dimension
of
input. Must be in the same order as the dimension specified with format. - padding: The type of padding algorithm to use.
- strides: 1-D of length 4. The stride of the sliding window for each dimension
of
Declaration
Parameters
input4-D with shape
[batch, in_height, in_width, in_channels].paddingsA two-column matrix specifying the padding sizes. The number of rows must be the same as the rank of
input.filter4-D with shape
[filter_height, filter_width, in_channels, out_channels]. -
Performs a resize and padding as a preprocess during a convolution.
It’s often possible to do spatial transformations more efficiently as part of the packing stage of a convolution, so this op allows for an optimized implementation where these stages are fused together. This prevents the need to write out the intermediate results as whole tensors, reducing memory pressure, and we can get some latency gains by merging the transformation calculations. The data_format attribute for Conv2D isn’t supported by this op, and defaults to ‘NHWC’ order. Internally this op uses a single per-graph scratch buffer, which means that it will block if multiple versions are being run in parallel. This is because this operator is primarily an optimization to minimize memory usage.
Attrs:
- resize_align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
- strides: 1-D of length 4. The stride of the sliding window for each dimension
of
input. Must be in the same order as the dimension specified with format. - padding: The type of padding algorithm to use.
Declaration
Parameters
input4-D with shape
[batch, in_height, in_width, in_channels].sizeA 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images.paddingsA two-column matrix specifying the padding sizes. The number of rows must be the same as the rank of
input.filter4-D with shape
[filter_height, filter_width, in_channels, out_channels]. -
Computes the GRU cell forward propagation for 1 time step.
Args x: Input to the GRU cell. h_prev: State input from the previous GRU cell. w_ru: Weight matrix for the reset and update gate. w_c: Weight matrix for the cell connection gate. b_ru: Bias vector for the reset and update gate. b_c: Bias vector for the cell connection gate.
Returns r: Output of the reset gate. u: Output of the update gate. c: Output of the cell connection gate. h: Current state of the GRU cell.
Note on notation of the variables:
Concatenation of a and b is represented by a_b Element-wise dot product of a and b is represented by ab Element-wise dot product is represented by \circ Matrix multiplication is represented by *
Biases are initialized with :
b_ru- constant_initializer(1.0)b_c- constant_initializer(0.0)This kernel op implements the following mathematical equations:
x_h_prev = [x, h_prev] [r_bar u_bar] = x_h_prev * w_ru + b_ru r = sigmoid(r_bar) u = sigmoid(u_bar) h_prevr = h_prev \circ r x_h_prevr = [x h_prevr] c_bar = x_h_prevr * w_c + b_c c = tanh(c_bar) h = (1-u) \circ c + u \circ h_prev -
Computes the GRU cell back-propagation for 1 time step.
Args x: Input to the GRU cell. h_prev: State input from the previous GRU cell. w_ru: Weight matrix for the reset and update gate. w_c: Weight matrix for the cell connection gate. b_ru: Bias vector for the reset and update gate. b_c: Bias vector for the cell connection gate. r: Output of the reset gate. u: Output of the update gate. c: Output of the cell connection gate. d_h: Gradients of the h_new wrt to objective function.
Returns d_x: Gradients of the x wrt to objective function. d_h_prev: Gradients of the h wrt to objective function. d_c_bar Gradients of the c_bar wrt to objective function. d_r_bar_u_bar Gradients of the r_bar & u_bar wrt to objective function.
This kernel op implements the following mathematical equations:
Note on notation of the variables:
Concatenation of a and b is represented by a_b Element-wise dot product of a and b is represented by ab Element-wise dot product is represented by \circ Matrix multiplication is represented by *
Additional notes for clarity:
w_rucan be segmented into 4 different matrices.w_ru = [w_r_x w_u_x w_r_h_prev w_u_h_prev]Similarly,
w_ccan be segmented into 2 different matrices.w_c = [w_c_x w_c_h_prevr]Same goes for biases.
b_ru = [b_ru_x b_ru_h] b_c = [b_c_x b_c_h]Another note on notation:
d_x = d_x_component_1 + d_x_component_2 where d_x_component_1 = d_r_bar * w_r_x^T + d_u_bar * w_r_x^T and d_x_component_2 = d_c_bar * w_c_x^T d_h_prev = d_h_prev_component_1 + d_h_prevr \circ r + d_h \circ u where d_h_prev_componenet_1 = d_r_bar * w_r_h_prev^T + d_u_bar * w_r_h_prev^TMathematics behind the Gradients below:
d_c_bar = d_h \circ (1-u) \circ (1-c \circ c) d_u_bar = d_h \circ (h-c) \circ u \circ (1-u) d_r_bar_u_bar = [d_r_bar d_u_bar] [d_x_component_1 d_h_prev_component_1] = d_r_bar_u_bar * w_ru^T [d_x_component_2 d_h_prevr] = d_c_bar * w_c^T d_x = d_x_component_1 + d_x_component_2 d_h_prev = d_h_prev_component_1 + d_h_prevr \circ r + uBelow calculation is performed in the python wrapper for the Gradients (not in the gradient kernel.)
d_w_ru = x_h_prevr^T * d_c_bar d_w_c = x_h_prev^T * d_r_bar_u_bar d_b_ru = sum of d_r_bar_u_bar along axis = 0 d_b_c = sum of d_c_bar along axis = 0Declaration
public static func gRUBlockCellGrad<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, hPrev: Tensor<T>, wRu: Tensor<T>, wC: Tensor<T>, bRu: Tensor<T>, bC: Tensor<T>, r: Tensor<T>, u: Tensor<T>, c: Tensor<T>, dH: Tensor<T> ) -> (dX: Tensor<T>, dHPrev: Tensor<T>, dCBar: Tensor<T>, dRBarUBar: Tensor<T>) -
Gather slices from
paramsaccording toindices.indicesmust be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shapeindices.shape + params.shape[1:]where:# Scalar indices output[:, ..., :] = params[indices, :, ... :] # Vector indices output[i, :, ..., :] = params[indices[i], :, ... :] # Higher rank indices output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :]If
indicesis a permutation andlen(indices) == params.shape[0]then this operation will permuteparamsaccordingly.validate_indices: DEPRECATED. If this operation is assigned to CPU, values inindicesare always validated to be within range. If assigned to GPU, out-of-bound indices result in safe but unspecified behavior, which may include raising an error.
Declaration
public static func gather< Tparams: TensorFlowScalar, Tindices: TensorFlowIndex >( params: Tensor<Tparams>, indices: Tensor<Tindices>, validateIndices: Bool = true ) -> Tensor<Tparams> -
Gather slices from
paramsinto a Tensor with shape specified byindices.indicesis a K-dimensional integer tensor, best thought of as a (K-1)-dimensional tensor of indices intoparams, where each element defines a slice ofparams:output[\\(i_0, ..., i_{K-2}\\)] = params[indices[\\(i_0, ..., i_{K-2}\\)]]Whereas in
tf.gatherindicesdefines slices into theaxisdimension ofparams, intf.gather_nd,indicesdefines slices into the firstNdimensions ofparams, whereN = indices.shape[-1].The last dimension of
indicescan be at most the rank ofparams:indices.shape[-1] <= params.rankThe last dimension of
indicescorresponds to elements (ifindices.shape[-1] == params.rank) or slices (ifindices.shape[-1] < params.rank) along dimensionindices.shape[-1]ofparams. The output tensor has shapeindices.shape[:-1] + params.shape[indices.shape[-1]:]Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, a 0 is stored in the corresponding output value.
Some examples below.
Simple indexing into a matrix:
indices = [[0, 0], [1, 1]] params = [['a', 'b'], ['c', 'd']] output = ['a', 'd']Slice indexing into a matrix:
indices = [[1], [0]] params = [['a', 'b'], ['c', 'd']] output = [['c', 'd'], ['a', 'b']]Indexing into a 3-tensor:
indices = [[1]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = [[['a1', 'b1'], ['c1', 'd1']]] indices = [[0, 1], [1, 0]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = [['c0', 'd0'], ['a1', 'b1']] indices = [[0, 0, 1], [1, 0, 1]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = ['b0', 'b1']Batched indexing into a matrix:
indices = [[[0, 0]], [[0, 1]]] params = [['a', 'b'], ['c', 'd']] output = [['a'], ['b']]Batched slice indexing into a matrix:
indices = [[[1]], [[0]]] params = [['a', 'b'], ['c', 'd']] output = [[['c', 'd']], [['a', 'b']]]Batched indexing into a 3-tensor:
indices = [[[1]], [[0]]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = [[[['a1', 'b1'], ['c1', 'd1']]], [[['a0', 'b0'], ['c0', 'd0']]]] indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = [[['c0', 'd0'], ['a1', 'b1']], [['a0', 'b0'], ['c1', 'd1']]] indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]] params = [[['a0', 'b0'], ['c0', 'd0']], [['a1', 'b1'], ['c1', 'd1']]] output = [['b0', 'b1'], ['d0', 'c1']]See also
tf.gatherandtf.batch_gather.Output output: Values from
paramsgathered from indices given byindices, with shapeindices.shape[:-1] + params.shape[indices.shape[-1]:].
Declaration
public static func gatherNd< Tparams: TensorFlowScalar, Tindices: TensorFlowIndex >( params: Tensor<Tparams>, indices: Tensor<Tindices> ) -> Tensor<Tparams>Parameters
paramsThe tensor from which to gather values.
indicesIndex tensor.
-
Gather slices from
paramsaxisaxisaccording toindices.indicesmust be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shapeparams.shape[:axis] + indices.shape + params.shape[axis + 1:]where:# Scalar indices (output is rank(params) - 1). output[a_0, ..., a_n, b_0, ..., b_n] = params[a_0, ..., a_n, indices, b_0, ..., b_n] # Vector indices (output is rank(params)). output[a_0, ..., a_n, i, b_0, ..., b_n] = params[a_0, ..., a_n, indices[i], b_0, ..., b_n] # Higher rank indices (output is rank(params) + rank(indices) - 1). output[a_0, ..., a_n, i, ..., j, b_0, ... b_n] = params[a_0, ..., a_n, indices[i, ..., j], b_0, ..., b_n]
Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, a 0 is stored in the corresponding output value.
See also
tf.batch_gatherandtf.gather_nd.Output output: Values from
paramsgathered from indices given byindices, with shapeparams.shape[:axis] + indices.shape + params.shape[axis + 1:].
Declaration
public static func gatherV2< Tparams: TensorFlowScalar, Tindices: TensorFlowIndex, Taxis: TensorFlowIndex >( params: Tensor<Tparams>, indices: Tensor<Tindices>, axis: Tensor<Taxis>, batchDims: Int64 = 0 ) -> Tensor<Tparams>Parameters
paramsThe tensor from which to gather values. Must be at least rank
axis + 1.indicesIndex tensor. Must be in range
[0, params.shape[axis]).axisThe axis in
paramsto gatherindicesfrom. Defaults to the first dimension. Supports negative indexes. -
generateBoundingBoxProposals(scores:bboxDeltas:imageInfo:anchors:nmsThreshold:preNmsTopn:minSize:postNmsTopn:)
This op produces Region of Interests from given bounding boxes(bbox_deltas) encoded wrt anchors according to eq.2 in arXiv:1506.01497
The op selects top `pre_nms_topn` scoring boxes, decodes them with respect to anchors, applies non-maximal suppression on overlapping boxes with higher than `nms_threshold` intersection-over-union (iou) value, discarding boxes where shorter side is less than `min_size`. Inputs: `scores`: A 4D tensor of shape [Batch, Height, Width, Num Anchors] containing the scores per anchor at given postion `bbox_deltas`: is a tensor of shape [Batch, Height, Width, 4 x Num Anchors] boxes encoded to each anchor `anchors`: A 1D tensor of shape [4 x Num Anchors], representing the anchors. Outputs: `rois`: output RoIs, a 3D tensor of shape [Batch, post_nms_topn, 4], padded by 0 if less than post_nms_topn candidates found. `roi_probabilities`: probability scores of each roi in 'rois', a 2D tensor of shape [Batch,post_nms_topn], padded with 0 if needed, sorted by scores.Attr post_nms_topn: An integer. Maximum number of rois in the output.
Outputs:
- rois: A 3-D float tensor of shape
[num_images,post_nms_topn,4]representing the selected region of interest boxes. Sorted in descending order in scores. - roi_probabilities: A 2-D float tensor of shape
[num_images, post_nms_topn]representing the score of the region of interest box inroistensor at the same index.
- rois: A 3-D float tensor of shape
Declaration
public static func generateBoundingBoxProposals( scores: Tensor<Float>, bboxDeltas: Tensor<Float>, imageInfo: Tensor<Float>, anchors: Tensor<Float>, nmsThreshold: Tensor<Float>, preNmsTopn: Tensor<Int32>, minSize: Tensor<Float>, postNmsTopn: Int64 = 300 ) -> (rois: Tensor<Float>, roiProbabilities: Tensor<Float>)Parameters
scoresA 4-D float tensor of shape
[num_images, height, width, num_achors]containing scores of the boxes for given anchors, can be unsorted.bbox_deltasA 4-D float tensor of shape
[num_images, height, width, 4 x num_anchors]. encoding boxes with respec to each anchor. Coordinates are given in the form [dy, dx, dh, dw].image_infoA 2-D float tensor of shape
[num_images, 5]containing image information Height, Width, Scale.anchorsA 2-D float tensor of shape
[num_anchors, 4]describing the anchor boxes. Boxes are formatted in the form [y1, x1, y2, x2].nms_thresholdA scalar float tensor for non-maximal-suppression threshold.
pre_nms_topnA scalar int tensor for the number of top scoring boxes to be used as input.
min_sizeA scalar float tensor. Any box that has a smaller size than min_size will be discarded.
-
Given a path to new and old vocabulary files, returns a remapping Tensor of
length
num_new_vocab, whereremapping[i]contains the row number in the old vocabulary that corresponds to rowiin the new vocabulary (starting at linenew_vocab_offsetand up tonum_new_vocabentities), or-1if entryiin the new vocabulary is not in the old vocabulary. The old vocabulary is constrained to the firstold_vocab_sizeentries ifold_vocab_sizeis not the default value of -1.num_vocab_offsetenables use in the partitioned variable case, and should generally be set through examining partitioning info. The format of the files should be a text file, with each line containing a single entity within the vocabulary.For example, with
new_vocab_filea text file containing each of the following elements on a single line:[f0, f1, f2, f3], old_vocab_file = [f1, f0, f3],num_new_vocab = 3, new_vocab_offset = 1, the returned remapping would be[0, -1, 2].The op also returns a count of how many entries in the new vocabulary were present in the old vocabulary, which is used to calculate the number of values to initialize in a weight matrix remapping
This functionality can be used to remap both row vocabularies (typically, features) and column vocabularies (typically, classes) from TensorFlow checkpoints. Note that the partitioning logic relies on contiguous vocabularies corresponding to div-partitioned variables. Moreover, the underlying remapping uses an IndexTable (as opposed to an inexact CuckooTable), so client code should use the corresponding index_table_from_file() as the FeatureColumn framework does (as opposed to tf.feature_to_id(), which uses a CuckooTable).
Attrs:
- new_vocab_offset: How many entries into the new vocab file to start reading.
- num_new_vocab: Number of entries in the new vocab file to remap.
- old_vocab_size: Number of entries in the old vocab file to consider. If -1, use the entire old vocabulary.
Outputs:
- remapping: A Tensor of length num_new_vocab where the element at index i is equal to the old ID that maps to the new ID i. This element is -1 for any new ID that is not found in the old vocabulary.
- num_present: Number of new vocab entries found in old vocab.
Declaration
public static func generateVocabRemapping( newVocabFile: StringTensor, oldVocabFile: StringTensor, newVocabOffset: Int64, numNewVocab: Int64, oldVocabSize: Int64 = -1 ) -> (remapping: Tensor<Int64>, numPresent: Tensor<Int32>)Parameters
new_vocab_filePath to the new vocab file.
old_vocab_filePath to the old vocab file.
-
generatorDataset(initFuncOtherArgs:nextFuncOtherArgs:finalizeFuncOtherArgs:initFunc:nextFunc:finalizeFunc:outputTypes:outputShapes:)
Creates a dataset that invokes a function to generate elements.
Declaration
public static func generatorDataset< InitfuncIn: TensorGroup, InitfuncOut: TensorGroup, NextfuncIn: TensorGroup, NextfuncOut: TensorGroup, FinalizefuncIn: TensorGroup, FinalizefuncOut: TensorGroup, TinitFuncArgs: TensorArrayProtocol, TnextFuncArgs: TensorArrayProtocol, TfinalizeFuncArgs: TensorArrayProtocol >( initFuncOtherArgs: TinitFuncArgs, nextFuncOtherArgs: TnextFuncArgs, finalizeFuncOtherArgs: TfinalizeFuncArgs, initFunc: (InitfuncIn) -> InitfuncOut, nextFunc: (NextfuncIn) -> NextfuncOut, finalizeFunc: (FinalizefuncIn) -> FinalizefuncOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Store the input tensor in the state of the current session.
Output handle: The handle for the tensor stored in the session state, represented as a string.
Declaration
public static func getSessionHandle<T: TensorFlowScalar>( value: Tensor<T> ) -> StringTensorParameters
valueThe tensor to be stored.
-
Store the input tensor in the state of the current session.
Output handle: The handle for the tensor stored in the session state, represented as a ResourceHandle object.
Declaration
public static func getSessionHandleV2<T: TensorFlowScalar>( value: Tensor<T> ) -> ResourceHandleParameters
valueThe tensor to be stored.
-
Get the value of the tensor specified by its handle.
Attr dtype: The type of the output value.
Output value: The tensor for the given handle.
Declaration
public static func getSessionTensor<Dtype: TensorFlowScalar>( handle: StringTensor ) -> Tensor<Dtype>Parameters
handleThe handle for a tensor stored in the session state.
-
Declaration
public static func graphDefVersion() -> Tensor<Int32> -
Returns the truth value of (x > y) element-wise.
NOTE:
Greatersupports broadcasting. More about broadcasting hereExample:
x = tf.constant([5, 4, 6]) y = tf.constant([5, 2, 5]) tf.math.greater(x, y) ==> [False, True, True] x = tf.constant([5, 4, 6]) y = tf.constant([5]) tf.math.greater(x, y) ==> [False, False, True]Declaration
public static func greater<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<Bool> -
Returns the truth value of (x >= y) element-wise.
NOTE:
GreaterEqualsupports broadcasting. More about broadcasting hereExample:
x = tf.constant([5, 4, 6, 7]) y = tf.constant([5, 2, 5, 10]) tf.math.greater_equal(x, y) ==> [True, True, True, False] x = tf.constant([5, 4, 6, 7]) y = tf.constant([5]) tf.math.greater_equal(x, y) ==> [True, False, True, True]Declaration
public static func greaterEqual<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<Bool> -
groupByReducerDataset(inputDataset:keyFuncOtherArguments:initFuncOtherArguments:reduceFuncOtherArguments:finalizeFuncOtherArguments:keyFunc:initFunc:reduceFunc:finalizeFunc:outputTypes:outputShapes:)
Creates a dataset that computes a group-by on
input_dataset.Creates a dataset that computes a group-by on
input_dataset.Attrs:
- key_func: A function mapping an element of
input_dataset, concatenated withkey_func_other_argumentsto a scalar value of type DT_INT64. - init_func: A function mapping a key of type DT_INT64, concatenated with
init_func_other_argumentsto the initial reducer state. - reduce_func: A function mapping the current reducer state and an element of
input_dataset, concatenated withreduce_func_other_argumentsto a new reducer state. - finalize_func: A function mapping the final reducer state to an output element.
- key_func: A function mapping an element of
Declaration
public static func groupByReducerDataset< KeyfuncIn: TensorGroup, KeyfuncOut: TensorGroup, InitfuncIn: TensorGroup, InitfuncOut: TensorGroup, ReducefuncIn: TensorGroup, ReducefuncOut: TensorGroup, FinalizefuncIn: TensorGroup, FinalizefuncOut: TensorGroup, TkeyFuncOtherArguments: TensorArrayProtocol, TinitFuncOtherArguments: TensorArrayProtocol, TreduceFuncOtherArguments: TensorArrayProtocol, TfinalizeFuncOtherArguments: TensorArrayProtocol >( inputDataset: VariantHandle, keyFuncOtherArguments: TkeyFuncOtherArguments, initFuncOtherArguments: TinitFuncOtherArguments, reduceFuncOtherArguments: TreduceFuncOtherArguments, finalizeFuncOtherArguments: TfinalizeFuncOtherArguments, keyFunc: (KeyfuncIn) -> KeyfuncOut, initFunc: (InitfuncIn) -> InitfuncOut, reduceFunc: (ReducefuncIn) -> ReducefuncOut, finalizeFunc: (FinalizefuncIn) -> FinalizefuncOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
key_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
key_func.init_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
init_func.reduce_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
reduce_func.finalize_func_other_argumentsA list of tensors, typically values that were captured when building a closure for
finalize_func. -
groupByWindowDataset(inputDataset:keyFuncOtherArguments:reduceFuncOtherArguments:windowSizeFuncOtherArguments:keyFunc:reduceFunc:windowSizeFunc:outputTypes:outputShapes:)
Creates a dataset that computes a windowed group-by on
input_dataset.// TODO(mrry): Support non-int64 keys.
- Attr key_func: A function mapping an element of
input_dataset, concatenated withkey_func_other_argumentsto a scalar value of type DT_INT64.
Declaration
public static func groupByWindowDataset< KeyfuncIn: TensorGroup, KeyfuncOut: TensorGroup, ReducefuncIn: TensorGroup, ReducefuncOut: TensorGroup, WindowsizefuncIn: TensorGroup, WindowsizefuncOut: TensorGroup, TkeyFuncOtherArguments: TensorArrayProtocol, TreduceFuncOtherArguments: TensorArrayProtocol, TwindowSizeFuncOtherArguments: TensorArrayProtocol >( inputDataset: VariantHandle, keyFuncOtherArguments: TkeyFuncOtherArguments, reduceFuncOtherArguments: TreduceFuncOtherArguments, windowSizeFuncOtherArguments: TwindowSizeFuncOtherArguments, keyFunc: (KeyfuncIn) -> KeyfuncOut, reduceFunc: (ReducefuncIn) -> ReducefuncOut, windowSizeFunc: (WindowsizefuncIn) -> WindowsizefuncOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle - Attr key_func: A function mapping an element of
-
Gives a guarantee to the TF runtime that the input tensor is a constant.
The runtime is then free to make optimizations based on this.
Only accepts value typed tensors as inputs and rejects resource variable handles as input.
Returns the input tensor without modification.
Declaration
public static func guaranteeConst<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Convert one or more images from HSV to RGB.
Outputs a tensor of the same shape as the
imagestensor, containing the RGB value of the pixels. The output is only well defined if the value inimagesare in[0,1].See
rgb_to_hsvfor a description of the HSV encoding.Output output:
imagesconverted to RGB.
Declaration
public static func hSVToRGB<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T> ) -> Tensor<T>Parameters
images1-D or higher rank. HSV data to convert. Last dimension must be size 3.
-
Creates a non-initialized hash table.
This op creates a hash table, specifying the type of its keys and values. Before using the table you will have to initialize it. After initialization the table will be immutable.
Attrs:
- container: If non-empty, this table is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this table is shared under the given name across multiple sessions.
- use_node_name_sharing: If true and shared_name is empty, the table is shared using the node name.
- key_dtype: Type of the table keys.
- value_dtype: Type of the table values.
Output table_handle: Handle to a table.
Declaration
public static func hashTableV2( container: String, sharedName: String, useNodeNameSharing: Bool = false, keyDtype: TensorDataType, valueDtype: TensorDataType ) -> ResourceHandle -
Return histogram of values.
Given the tensor
values, this operation returns a rank 1 histogram counting the number of entries invaluesthat fall into every bin. The bins are equal width and determined by the argumentsvalue_rangeandnbins.# Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf) nbins = 5 value_range = [0.0, 5.0] new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15] with tf.get_default_session() as sess: hist = tf.histogram_fixed_width(new_values, value_range, nbins=5) variables.global_variables_initializer().run() sess.run(hist) => [2, 1, 1, 0, 2]Output out: A 1-D
Tensorholding histogram of values.
Declaration
public static func histogramFixedWidth< T: TensorFlowNumeric, Dtype: TensorFlowIndex >( _ values: Tensor<T>, valueRange: Tensor<T>, nbins: Tensor<Int32> ) -> Tensor<Dtype> -
Outputs a
Summaryprotocol buffer with a histogram.The generated
Summaryhas one summary value containing a histogram forvalues.This op reports an
InvalidArgumenterror if any value is not finite.Output summary: Scalar. Serialized
Summaryprotocol buffer.
Declaration
public static func histogramSummary<T: TensorFlowNumeric>( tag: StringTensor, _ values: Tensor<T> ) -> StringTensorParameters
tagScalar. Tag to use for the
Summary.Value.valuesAny shape. Values to use to build the histogram.
-
Inverse fast Fourier transform.
Computes the inverse 1-dimensional discrete Fourier transform over the inner-most dimension of
input.Output output: A complex tensor of the same shape as
input. The inner-most dimension ofinputis replaced with its inverse 1D Fourier transform.@compatibility(numpy) Equivalent to np.fft.ifft @end_compatibility
Declaration
public static func iFFT<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
Inverse 2D fast Fourier transform.
Computes the inverse 2-dimensional discrete Fourier transform over the inner-most 2 dimensions of
input.Output output: A complex tensor of the same shape as
input. The inner-most 2 dimensions ofinputare replaced with their inverse 2D Fourier transform.@compatibility(numpy) Equivalent to np.fft.ifft2 @end_compatibility
Declaration
public static func iFFT2D<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
Inverse 3D fast Fourier transform.
Computes the inverse 3-dimensional discrete Fourier transform over the inner-most 3 dimensions of
input.Output output: A complex tensor of the same shape as
input. The inner-most 3 dimensions ofinputare replaced with their inverse 3D Fourier transform.@compatibility(numpy) Equivalent to np.fft.ifftn with 3 dimensions. @end_compatibility
Declaration
public static func iFFT3D<Tcomplex: TensorFlowScalar>( _ input: Tensor<Tcomplex> ) -> Tensor<Tcomplex>Parameters
inputA complex tensor.
-
Inverse real-valued fast Fourier transform.
Computes the inverse 1-dimensional discrete Fourier transform of a real-valued signal over the inner-most dimension of
input.The inner-most dimension of
inputis assumed to be the result ofRFFT: thefft_length / 2 + 1unique components of the DFT of a real-valued signal. Iffft_lengthis not provided, it is computed from the size of the inner-most dimension ofinput(fft_length = 2 * (inner - 1)). If the FFT length used to computeinputis odd, it should be provided since it cannot be inferred properly.Along the axis
IRFFTis computed on, iffft_length / 2 + 1is smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A float32 tensor of the same rank as
input. The inner-most dimension ofinputis replaced with thefft_lengthsamples of its inverse 1D Fourier transform.@compatibility(numpy) Equivalent to np.fft.irfft @end_compatibility
Declaration
public static func iRFFT< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Tcomplex>, fftLength: Tensor<Int32> ) -> Tensor<Treal>Parameters
inputA complex tensor.
fft_lengthAn int32 tensor of shape [1]. The FFT length.
-
Inverse 2D real-valued fast Fourier transform.
Computes the inverse 2-dimensional discrete Fourier transform of a real-valued signal over the inner-most 2 dimensions of
input.The inner-most 2 dimensions of
inputare assumed to be the result ofRFFT2D: The inner-most dimension contains thefft_length / 2 + 1unique components of the DFT of a real-valued signal. Iffft_lengthis not provided, it is computed from the size of the inner-most 2 dimensions ofinput. If the FFT length used to computeinputis odd, it should be provided since it cannot be inferred properly.Along each axis
IRFFT2Dis computed on, iffft_length(orfft_length / 2 + 1for the inner-most dimension) is smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A float32 tensor of the same rank as
input. The inner-most 2 dimensions ofinputare replaced with thefft_lengthsamples of their inverse 2D Fourier transform.@compatibility(numpy) Equivalent to np.fft.irfft2 @end_compatibility
Declaration
public static func iRFFT2D< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Tcomplex>, fftLength: Tensor<Int32> ) -> Tensor<Treal>Parameters
inputA complex tensor.
fft_lengthAn int32 tensor of shape [2]. The FFT length for each dimension.
-
Inverse 3D real-valued fast Fourier transform.
Computes the inverse 3-dimensional discrete Fourier transform of a real-valued signal over the inner-most 3 dimensions of
input.The inner-most 3 dimensions of
inputare assumed to be the result ofRFFT3D: The inner-most dimension contains thefft_length / 2 + 1unique components of the DFT of a real-valued signal. Iffft_lengthis not provided, it is computed from the size of the inner-most 3 dimensions ofinput. If the FFT length used to computeinputis odd, it should be provided since it cannot be inferred properly.Along each axis
IRFFT3Dis computed on, iffft_length(orfft_length / 2 + 1for the inner-most dimension) is smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A float32 tensor of the same rank as
input. The inner-most 3 dimensions ofinputare replaced with thefft_lengthsamples of their inverse 3D real Fourier transform.@compatibility(numpy) Equivalent to np.irfftn with 3 dimensions. @end_compatibility
Declaration
public static func iRFFT3D< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Tcomplex>, fftLength: Tensor<Int32> ) -> Tensor<Treal>Parameters
inputA complex tensor.
fft_lengthAn int32 tensor of shape [3]. The FFT length for each dimension.
-
Return a tensor with the same shape and contents as the input tensor or value.
Declaration
public static func identity<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Returns a list of tensors with the same shapes and contents as the input
tensors.
This op can be used to override the gradient for complicated functions. For example, suppose y = f(x) and we wish to apply a custom function g for backprop such that dx = g(dy). In Python,
with tf.get_default_graph().gradient_override_map( {'IdentityN': 'OverrideGradientWithG'}): y, _ = identity_n([f(x), x]) @tf.RegisterGradient('OverrideGradientWithG') def ApplyG(op, dy, _): return [None, g(dy)] # Do not backprop to f(x).Declaration
public static func identityN<T: TensorArrayProtocol>( _ input: T ) -> T -
A Reader that outputs the queued work as both the key and value.
To use, enqueue strings in a Queue. ReaderRead will take the front work string and output (work, work).
Attrs:
- container: If non-empty, this reader is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
Output reader_handle: The handle to reference the Reader.
Declaration
public static func identityReaderV2( container: String, sharedName: String ) -> ResourceHandle -
output = cond ? then_branch(input) : else_branch(input)
Attrs:
- Tin: A list of input types.
- Tout: A list of output types.
- then_branch: A function that takes ‘inputs’ and returns a list of tensors, whose types are the same as what else_branch returns.
- else_branch: A function that takes ‘inputs’ and returns a list of tensors, whose types are the same as what then_branch returns.
Output output: A list of return values.
Declaration
public static func if_< Tcond: TensorFlowScalar, Tin: TensorArrayProtocol, Tout: TensorGroup, ThenbranchIn: TensorGroup, ThenbranchOut: TensorGroup, ElsebranchIn: TensorGroup, ElsebranchOut: TensorGroup >( cond: Tensor<Tcond>, _ input: Tin, thenBranch: (ThenbranchIn) -> ThenbranchOut, elseBranch: (ElsebranchIn) -> ElsebranchOut, outputShapes: [TensorShape?] ) -> ToutParameters
condA Tensor. If the tensor is a scalar of non-boolean type, the scalar is converted to a boolean according to the following rule: if the scalar is a numerical value, non-zero means
Trueand zero means False; if the scalar is a string, non-empty meansTrueand empty meansFalse. If the tensor is not a scalar, being empty means False and being non-empty means True.inputA list of input tensors.
-
Compute the lower regularized incomplete Gamma function
P(a, x).The lower regularized incomplete Gamma function is defined as:
\(P(a, x) = gamma(a, x) / Gamma(a) = 1 - Q(a, x)\)
where
\(gamma(a, x) = \int_{0}^{x} t^{a-1} exp(-t) dt\)
is the lower incomplete Gamma function.
Note, above
Q(a, x)(Igammac) is the upper regularized complete Gamma function.Declaration
public static func igamma<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient of
igamma(a, x)wrta.Declaration
public static func igammaGradA<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Compute the upper regularized incomplete Gamma function
Q(a, x).The upper regularized incomplete Gamma function is defined as:
\(Q(a, x) = Gamma(a, x) / Gamma(a) = 1 - P(a, x)\)
where
\(Gamma(a, x) = int_{x}^{\infty} t^{a-1} exp(-t) dt\)
is the upper incomplete Gama function.
Note, above
P(a, x)(Igamma) is the lower regularized complete Gamma function.Declaration
public static func igammac<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Creates a dataset that contains the elements of
input_datasetignoring errors.Declaration
public static func ignoreErrorsDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Returns the imaginary part of a complex number.
Given a tensor
inputof complex numbers, this operation returns a tensor of typefloatthat is the imaginary part of each element ininput. All elements ininputmust be complex numbers of the form \(a + bj\), where a is the real part and b is the imaginary part returned by this operation.For example:
# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.imag(input) ==> [4.75, 5.75]Declaration
public static func imag< T: TensorFlowScalar, Tout: FloatingPoint & TensorFlowScalar >( _ input: Tensor<T> ) -> Tensor<Tout> -
Returns immutable tensor from memory region.
The current implementation memmaps the tensor from a file.
- Attrs:
- dtype: Type of the returned tensor.
- shape: Shape of the returned tensor.
- memory_region_name: Name of readonly memory region used by the tensor, see NewReadOnlyMemoryRegionFromFile in tensorflow::Env.
Declaration
public static func immutableConst<Dtype: TensorFlowScalar>( shape: TensorShape?, memoryRegionName: String ) -> Tensor<Dtype> - Attrs:
-
Declaration
public static func importEvent( writer: ResourceHandle, event: StringTensor ) -
Declaration
public static func inPolymorphicTwice<T: TensorFlowScalar>( _ a: [Tensor<T>], _ b: [Tensor<T>] ) -
Says whether the targets are in the top
Kpredictions.This outputs a
batch_sizebool array, an entryout[i]istrueif the prediction for the target class is among the topkpredictions among all predictions for examplei. Note that the behavior ofInTopKdiffers from theTopKop in its handling of ties; if multiple classes have the same prediction value and straddle the top-kboundary, all of those classes are considered to be in the topk.More formally, let
\(predictions_i\) be the predictions for all classes for example
i, \(targets_i\) be the target class for examplei, \(out_i\) be the output for examplei,$$out_i = predictions_{i, targets_i} \in TopKIncludingTies(predictions_i)$$
Attr k: Number of top elements to look at for computing precision.
Output precision: Computed Precision at
kas abool Tensor.
Declaration
public static func inTopK<T: TensorFlowIndex>( predictions: Tensor<Float>, targets: Tensor<T>, k: Int64 ) -> Tensor<Bool>Parameters
predictionsA
batch_sizexclassestensor.targetsA
batch_sizevector of class ids. -
Says whether the targets are in the top
Kpredictions.This outputs a
batch_sizebool array, an entryout[i]istrueif the prediction for the target class is among the topkpredictions among all predictions for examplei. Note that the behavior ofInTopKdiffers from theTopKop in its handling of ties; if multiple classes have the same prediction value and straddle the top-kboundary, all of those classes are considered to be in the topk.More formally, let
\(predictions_i\) be the predictions for all classes for example
i, \(targets_i\) be the target class for examplei, \(out_i\) be the output for examplei,$$out_i = predictions_{i, targets_i} \in TopKIncludingTies(predictions_i)$$
Output precision: Computed precision at
kas abool Tensor.
Declaration
public static func inTopKV2<T: TensorFlowIndex>( predictions: Tensor<Float>, targets: Tensor<T>, k: Tensor<T> ) -> Tensor<Bool>Parameters
predictionsA
batch_sizexclassestensor.targetsA
batch_sizevector of class ids.kNumber of top elements to look at for computing precision.
-
A placeholder op for a value that will be fed into the computation.
Attrs:
- dtype: The type of elements in the tensor.
- shape: The shape of the tensor.
Output output: A tensor that will be provided using the infeed mechanism.
Declaration
public static func infeedDequeue<Dtype: TensorFlowScalar>( shape: TensorShape? ) -> Tensor<Dtype> -
Fetches multiple values from infeed as an XLA tuple.
Attrs:
- dtypes: The element types of each element in
outputs. - shapes: The shapes of each tensor in
outputs.
- dtypes: The element types of each element in
Output outputs: A list of tensors that will be provided using the infeed mechanism.
Declaration
public static func infeedDequeueTuple<Dtypes: TensorGroup>( shapes: [TensorShape?] ) -> Dtypes -
An op which feeds a single Tensor value into the computation.
Attrs:
- dtype: The type of elements in the tensor.
- shape: The shape of the tensor.
- layout: A vector holding the requested layout in minor-to-major sequence. If a layout attribute is passed, but its values are all -1, the layout will be computed by the infeed operation.
- device_ordinal: The TPU device to use. This should be -1 when the Op is running on a TPU device, and >= 0 when the Op is running on the CPU device.
Declaration
public static func infeedEnqueue<Dtype: TensorFlowScalar>( _ input: Tensor<Dtype>, shape: TensorShape?, layout: [Int32], deviceOrdinal: Int64 = -1 )Parameters
inputA tensor that will be provided using the infeed mechanism.
-
An op which enqueues prelinearized buffer into TPU infeed.
Attr device_ordinal: The TPU device to use. This should be -1 when the Op is running on a TPU device and = 0 when the Op is running on the CPU device.
Declaration
public static func infeedEnqueuePrelinearizedBuffer( _ input: VariantHandle, deviceOrdinal: Int64 = -1 )Parameters
inputA variant tensor representing linearized output.
-
Feeds multiple Tensor values into the computation as an XLA tuple.
Attrs:
- dtypes: The element types of each element in
inputs. - shapes: The shapes of each tensor in
inputs. - layouts: A vector holding the requested layout in minor-to-major sequence for all the tuple shapes, in the order the shapes appear in the “shapes” input. The layout elements for a sub-shape can be set to -1, in which case the corresponding layout will be computed by the infeed operation.
- device_ordinal: The TPU device to use. This should be -1 when the Op is running on a TPU device, and >= 0 when the Op is running on the CPU device.
- dtypes: The element types of each element in
Declaration
public static func infeedEnqueueTuple<Dtypes: TensorArrayProtocol>( inputs: Dtypes, shapes: [TensorShape?], layouts: [Int32], deviceOrdinal: Int64 = -1 )Parameters
inputsA list of tensors that will be provided using the infeed mechanism.
-
Initializes a table from a text file.
It inserts one key-value pair into the table for each line of the file. The key and value is extracted from the whole line content, elements from the split line based on
delimiteror the line number (starting from zero). Where to extract the key and value from a line is specified bykey_indexandvalue_index.- A value of -1 means use the line number(starting from zero), expects
int64. - A value of -2 means use the whole line content, expects
string. A value >= 0 means use the index (starting at zero) of the split line based on
delimiter.Attrs:
- key_index: Column index in a line to get the table
keyvalues from. - value_index: Column index that represents information of a line to get the table
valuevalues from. - vocab_size: Number of elements of the file, use -1 if unknown.
- delimiter: Delimiter to separate fields in a line.
- key_index: Column index in a line to get the table
Declaration
public static func initializeTableFromTextFileV2( tableHandle: ResourceHandle, filename: StringTensor, keyIndex: Int64, valueIndex: Int64, vocabSize: Int64 = -1, delimiter: String = "\t" )Parameters
table_handleHandle to a table which will be initialized.
filenameFilename of a vocabulary text file.
- A value of -1 means use the line number(starting from zero), expects
-
Table initializer that takes two tensors for keys and values respectively.
Declaration
public static func initializeTableV2< Tkey: TensorFlowScalar, Tval: TensorFlowScalar >( tableHandle: ResourceHandle, keys: Tensor<Tkey>, _ values: Tensor<Tval> )Parameters
table_handleHandle to a table which will be initialized.
keysKeys of type Tkey.
valuesValues of type Tval.
-
Adds v into specified rows of x. Computes y = x; y[i, :] += v; return y.Output y: A
Tensorof type T. An alias ofx. The content ofyis undefined if there are duplicates ini.
Declaration
public static func inplaceAdd<T: TensorFlowScalar>( _ x: Tensor<T>, i: Tensor<Int32>, v: Tensor<T> ) -> Tensor<T> -
Subtracts `v` into specified rows of `x`. Computes y = x; y[i, :] -= v; return y.Output y: A
Tensorof type T. An alias ofx. The content ofyis undefined if there are duplicates ini.
Declaration
public static func inplaceSub<T: TensorFlowScalar>( _ x: Tensor<T>, i: Tensor<Int32>, v: Tensor<T> ) -> Tensor<T> -
Updates specified rows with values in `v`. Computes `x[i, :] = v; return x`.Output y: A
Tensorof type T. An alias ofx. The content ofyis undefined if there are duplicates ini.
Declaration
public static func inplaceUpdate<T: TensorFlowScalar>( _ x: Tensor<T>, i: Tensor<Int32>, v: Tensor<T> ) -> Tensor<T> -
Declaration
public static func int64Output() -> Tensor<Int64> -
Declaration
public static func intAttr( foo: Int64 = 1 ) -> Tensor<Int64> -
Declaration
public static func intInput( _ a: Tensor<Int32> ) -
Declaration
public static func intOutput() -> Tensor<Int32> -
Creates a dataset that applies
fto the outputs ofinput_dataset.Unlike MapDataset, the
fin InterleaveDataset is expected to return a Dataset variant, and InterleaveDataset will flatten successive results into a single Dataset. Unlike FlatMapDataset, InterleaveDataset will interleave sequences of up toblock_lengthconsecutive elements fromcycle_lengthinput elements.- Attr f: A function mapping elements of
input_dataset, concatenated withother_arguments, to a Dataset variant that contains elements matchingoutput_typesandoutput_shapes.
Declaration
public static func interleaveDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, cycleLength: Tensor<Int64>, blockLength: Tensor<Int64>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle - Attr f: A function mapping elements of
-
Computes the reciprocal of x element-wise.
I.e., \(y = 1 / x\).
Declaration
public static func inv<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient for the inverse of
xwrt its input.Specifically,
grad = -dy * y*y, wherey = 1/x, anddyis the corresponding input gradient.Declaration
public static func invGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
Invert (flip) each bit of supported types; for example, type
uint8value 01010101 becomes 10101010.Flip each bit of supported types. For example, type
int8(decimal 2) binary 00000010 becomes (decimal -3) binary 11111101. This operation is performed on each element of the tensor argumentx.Example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops # flip 2 (00000010) to -3 (11111101) tf.assert_equal(-3, bitwise_ops.invert(2)) dtype_list = [dtypes.int8, dtypes.int16, dtypes.int32, dtypes.int64, dtypes.uint8, dtypes.uint16, dtypes.uint32, dtypes.uint64] inputs = [0, 5, 3, 14] for dtype in dtype_list: # Because of issues with negative numbers, let's test this indirectly. # 1. invert(a) and a = 0 # 2. invert(a) or a = invert(0) input_tensor = tf.constant([0, 5, 3, 14], dtype=dtype) not_a_and_a, not_a_or_a, not_0 = [bitwise_ops.bitwise_and( input_tensor, bitwise_ops.invert(input_tensor)), bitwise_ops.bitwise_or( input_tensor, bitwise_ops.invert(input_tensor)), bitwise_ops.invert( tf.constant(0, dtype=dtype))] expected = tf.constant([0, 0, 0, 0], dtype=tf.float32) tf.assert_equal(tf.cast(not_a_and_a, tf.float32), expected) expected = tf.cast([not_0] * 4, tf.float32) tf.assert_equal(tf.cast(not_a_or_a, tf.float32), expected) # For unsigned dtypes let's also check the result directly. if dtype.is_unsigned: inverted = bitwise_ops.invert(input_tensor) expected = tf.constant([dtype.max - x for x in inputs], dtype=tf.float32) tf.assert_equal(tf.cast(inverted, tf.float32), tf.cast(expected, tf.float32))Declaration
public static func invert<T: TensorFlowInteger>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the inverse permutation of a tensor.
This operation computes the inverse of an index permutation. It takes a 1-D integer tensor
x, which represents the indices of a zero-based array, and swaps each value with its index position. In other words, for an output tensoryand an input tensorx, this operation computes the following:y[x[i]] = i for i in [0, 1, ..., len(x) - 1]The values must include 0. There can be no duplicate values or negative values.
For example:
# tensor `x` is [3, 4, 0, 2, 1] invert_permutation(x) ==> [2, 4, 3, 0, 1]Output y: 1-D.
Declaration
public static func invertPermutation<T: TensorFlowIndex>( _ x: Tensor<T> ) -> Tensor<T>Parameters
x1-D.
-
Checks whether a tree ensemble has been initialized.
Output is_initialized: output boolean on whether it is initialized or not.
Declaration
public static func isBoostedTreesEnsembleInitialized( treeEnsembleHandle: ResourceHandle ) -> Tensor<Bool>Parameters
tree_ensemble_handleHandle to the tree ensemble resouce.
-
Checks whether a quantile stream has been initialized.
An Op that checks if quantile stream resource is initialized.
Output is_initialized: bool; True if the resource is initialized, False otherwise.
Declaration
public static func isBoostedTreesQuantileStreamResourceInitialized( quantileStreamResourceHandle: ResourceHandle ) -> Tensor<Bool>Parameters
quantile_stream_resource_handleresource; The reference to quantile stream resource handle.
-
Returns which elements of x are finite.
@compatibility(numpy) Equivalent to np.isfinite @end_compatibility
Example:
x = tf.constant([5.0, 4.8, 6.8, np.inf, np.nan]) tf.math.is_finite(x) ==> [True, True, True, False, False]Declaration
public static func isFinite<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<Bool> -
Returns which elements of x are Inf.
@compatibility(numpy) Equivalent to np.isinf @end_compatibility
Example:
x = tf.constant([5.0, np.inf, 6.8, np.inf]) tf.math.is_inf(x) ==> [False, True, False, True]Declaration
public static func isInf<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<Bool> -
Returns which elements of x are NaN.
@compatibility(numpy) Equivalent to np.isnan @end_compatibility
Example:
x = tf.constant([5.0, np.nan, 6.8, np.nan, np.inf]) tf.math.is_nan(x) ==> [False, True, False, True, False]Declaration
public static func isNan<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<Bool> -
A container for an iterator resource.
- Output handle: A handle to the iterator that can be passed to a “MakeIterator” or “IteratorGetNext” op.
Declaration
public static func iterator( sharedName: String, container: String, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandle -
Converts the given string representing a handle to an iterator to a resource.
Attrs:
- output_types: If specified, defines the type of each tuple component in an element produced by the resulting iterator.
- output_shapes: If specified, defines the shape of each tuple component in an element produced by the resulting iterator.
Output resource_handle: A handle to an iterator resource.
Declaration
public static func iteratorFromStringHandle( stringHandle: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandleParameters
string_handleA string representation of the given handle.
-
Declaration
public static func iteratorFromStringHandleV2( stringHandle: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandle -
Returns the name of the device on which
resourcehas been placed.Declaration
public static func iteratorGetDevice( resource: ResourceHandle ) -> StringTensor -
Gets the next output from the given iterator .
Declaration
public static func iteratorGetNext<OutputTypes: TensorGroup>( iterator: ResourceHandle, outputShapes: [TensorShape?] ) -> OutputTypes -
Gets the next output from the given iterator as an Optional variant.
Declaration
public static func iteratorGetNextAsOptional( iterator: ResourceHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Gets the next output from the given iterator.
This operation is a synchronous version IteratorGetNext. It should only be used in situations where the iterator does not block the calling thread, or where the calling thread is not a member of the thread pool used to execute parallel operations (e.g. in eager mode).
Declaration
public static func iteratorGetNextSync<OutputTypes: TensorGroup>( iterator: ResourceHandle, outputShapes: [TensorShape?] ) -> OutputTypes -
Converts the given
resource_handlerepresenting an iterator to a string.Output string_handle: A string representation of the given handle.
Declaration
public static func iteratorToStringHandle( resourceHandle: ResourceHandle ) -> StringTensorParameters
resource_handleA handle to an iterator resource.
-
Declaration
public static func iteratorV2( sharedName: String, container: String, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandle -
Returns the index of a data point that should be added to the seed set.
Entries in distances are assumed to be squared distances of candidate points to the already sampled centers in the seed set. The op constructs one Markov chain of the k-MC^2 algorithm and returns the index of one candidate point to be added as an additional cluster center.
Output index: Scalar with the index of the sampled point.
Declaration
Parameters
distancesVector with squared distances to the closest previously sampled cluster center for each candidate point.
seedScalar. Seed for initializing the random number generator.
-
Declaration
public static func kernelLabel() -> StringTensor -
Declaration
public static func kernelLabelRequired( _ input: Tensor<Int32> ) -> StringTensor -
Selects num_to_sample rows of input using the KMeans++ criterion.
Rows of points are assumed to be input points. One row is selected at random. Subsequent rows are sampled with probability proportional to the squared L2 distance from the nearest row selected thus far till num_to_sample rows have been sampled.
Output samples: Matrix of shape (num_to_sample, d). The sampled rows.
Declaration
Parameters
pointsMatrix of shape (n, d). Rows are assumed to be input points.
num_to_sampleScalar. The number of rows to sample. This value must not be larger than n.
seedScalar. Seed for initializing the random number generator.
num_retries_per_sampleScalar. For each row that is sampled, this parameter specifies the number of additional points to draw from the current distribution before selecting the best. If a negative value is specified, a heuristic is used to sample O(log(num_to_sample)) additional points.
-
L2 Loss.
Computes half the L2 norm of a tensor without the
sqrt:output = sum(t ** 2) / 2Output output: 0-D.
Declaration
public static func l2Loss<T: FloatingPoint & TensorFlowScalar>( t: Tensor<T> ) -> Tensor<T>Parameters
tTypically 2-D, but may have any dimensions.
-
Creates a dataset that emits the key-value pairs in one or more LMDB files.
The Lightning Memory-Mapped Database Manager, or LMDB, is an embedded binary key-value database. This dataset can read the contents of LMDB database files, the names of which generally have the
.mdbsuffix.Each output element consists of a key-value pair represented as a pair of scalar string
Tensors, where the firstTensorcontains the key and the secondTensorcontains the value.LMDB uses different file formats on big- and little-endian machines.
LMDBDatasetcan only read files in the format of the host machine.Declaration
public static func lMDBDataset( filenames: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
filenamesA scalar or a vector containing the name(s) of the binary file(s) to be read.
-
Local Response Normalization.
The 4-D
inputtensor is treated as a 3-D array of 1-D vectors (along the last dimension), and each vector is normalized independently. Within a given vector, each component is divided by the weighted, squared sum of inputs withindepth_radius. In detail,sqr_sum[a, b, c, d] = sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2) output = input / (bias + alpha * sqr_sum) ** betaFor details, see Krizhevsky et al., ImageNet classification with deep convolutional neural networks (NIPS 2012).
Attrs:
- depth_radius: 0-D. Half-width of the 1-D normalization window.
- bias: An offset (usually positive to avoid dividing by 0).
- alpha: A scale factor, usually positive.
- beta: An exponent.
Declaration
public static func lRN<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, depthRadius: Int64 = 5, bias: Double = 1, alpha: Double = 1, beta: Double = 0.5 ) -> Tensor<T>Parameters
input4-D.
-
Gradients for Local Response Normalization.
Attrs:
- depth_radius: A depth radius.
- bias: An offset (usually > 0 to avoid dividing by 0).
- alpha: A scale factor, usually positive.
- beta: An exponent.
Output output: The gradients for LRN.
Declaration
public static func lRNGrad<T: FloatingPoint & TensorFlowScalar>( inputGrads: Tensor<T>, inputImage: Tensor<T>, outputImage: Tensor<T>, depthRadius: Int64 = 5, bias: Double = 1, alpha: Double = 1, beta: Double = 0.5 ) -> Tensor<T>Parameters
input_grads4-D with shape
[batch, height, width, channels].input_image4-D with shape
[batch, height, width, channels].output_image4-D with shape
[batch, height, width, channels]. -
Computes the LSTM cell forward propagation for 1 time step.
This implementation uses 1 weight matrix and 1 bias vector, and there’s an optional peephole connection.
This kernel op implements the following mathematical equations:
xh = [x, h_prev] [i, f, ci, o] = xh * w + b f = f + forget_bias if not use_peephole: wci = wcf = wco = 0 i = sigmoid(cs_prev * wci + i) f = sigmoid(cs_prev * wcf + f) ci = tanh(ci) cs = ci .* i + cs_prev .* f cs = clip(cs, cell_clip) o = sigmoid(cs * wco + o) co = tanh(cs) h = co .* oAttrs:
- forget_bias: The forget gate bias.
- cell_clip: Value to clip the ‘cs’ value to.
- use_peephole: Whether to use peephole weights.
Outputs:
- i: The input gate.
- cs: The cell state before the tanh.
- f: The forget gate.
- o: The output gate.
- ci: The cell input.
- co: The cell after the tanh.
- h: The output h vector.
Declaration
public static func lSTMBlockCell<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, forgetBias: Double = 1, cellClip: Double = 3, usePeephole: Bool = false ) -> ( i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, h: Tensor<T> )Parameters
xThe input to the LSTM cell, shape (batch_size, num_inputs).
cs_prevValue of the cell state at previous time step.
h_prevOutput of the previous cell at previous time step.
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
-
Computes the LSTM cell backward propagation for 1 timestep.
This implementation is to be used in conjunction of LSTMBlockCell.
Attr use_peephole: Whether the cell uses peephole connections.
Outputs:
- cs_prev_grad: The gradient of cs to be back-propped.
- dicfo: The derivative wrt to [i, cs, f, o].
- wci_grad: The gradient for wci to be back-propped.
- wcf_grad: The gradient for wcf to be back-propped.
- wco_grad: The gradient for wco to be back-propped.
Declaration
public static func lSTMBlockCellGrad<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, csPrev: Tensor<T>, hPrev: Tensor<T>, w: Tensor<T>, wci: Tensor<T>, wcf: Tensor<T>, wco: Tensor<T>, _ b: Tensor<T>, i: Tensor<T>, cs: Tensor<T>, f: Tensor<T>, o: Tensor<T>, ci: Tensor<T>, co: Tensor<T>, csGrad: Tensor<T>, hGrad: Tensor<T>, usePeephole: Bool ) -> ( csPrevGrad: Tensor<T>, dicfo: Tensor<T>, wciGrad: Tensor<T>, wcfGrad: Tensor<T>, wcoGrad: Tensor<T> )Parameters
xThe input to the LSTM cell, shape (batch_size, num_inputs).
cs_prevThe previous cell state.
h_prevThe previous h state.
wThe weight matrix.
wciThe weight matrix for input gate peephole connection.
wcfThe weight matrix for forget gate peephole connection.
wcoThe weight matrix for output gate peephole connection.
bThe bias vector.
iThe input gate.
csThe cell state before the tanh.
fThe forget gate.
oThe output gate.
ciThe cell input.
coThe cell after the tanh.
cs_gradThe current gradient of cs.
h_gradThe gradient of h vector.
-
Records the latency of producing
input_datasetelements in a StatsAggregator.Declaration
public static func latencyStatsDataset( inputDataset: VariantHandle, tag: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Computes rectified linear:
max(features, features * alpha).Declaration
public static func leakyRelu<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T>, alpha: Double = 0.2 ) -> Tensor<T> -
Computes rectified linear gradients for a LeakyRelu operation.
Output backprops:
gradients * (features > 0) + alpha * gradients * (features <= 0).
Declaration
public static func leakyReluGrad<T: FloatingPoint & TensorFlowScalar>( gradients: Tensor<T>, features: Tensor<T>, alpha: Double = 0.2 ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding LeakyRelu operation.
featuresThe features passed as input to the corresponding LeakyRelu operation, OR the outputs of that operation (both work equivalently).
-
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to randomly sample.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- range_max: The sampler will sample integers from the interval [0, range_max).
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
Elementwise computes the bitwise left-shift of
xandy.If
yis negative, or greater than or equal to the width ofxin bits the result is implementation defined.Example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops import numpy as np dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64] for dtype in dtype_list: lhs = tf.constant([-1, -5, -3, -14], dtype=dtype) rhs = tf.constant([5, 0, 7, 11], dtype=dtype) left_shift_result = bitwise_ops.left_shift(lhs, rhs) print(left_shift_result) # This will print: # tf.Tensor([ -32 -5 -128 0], shape=(4,), dtype=int8) # tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int16) # tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int32) # tf.Tensor([ -32 -5 -384 -28672], shape=(4,), dtype=int64) lhs = np.array([-2, 64, 101, 32], dtype=np.int8) rhs = np.array([-1, -5, -3, -14], dtype=np.int8) bitwise_ops.left_shift(lhs, rhs) # <tf.Tensor: shape=(4,), dtype=int8, numpy=array([ -2, 64, 101, 32], dtype=int8)>Declaration
public static func leftShift<T: TensorFlowInteger>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns the truth value of (x < y) element-wise.
NOTE:
Lesssupports broadcasting. More about broadcasting hereExample:
x = tf.constant([5, 4, 6]) y = tf.constant([5]) tf.math.less(x, y) ==> [False, True, False] x = tf.constant([5, 4, 6]) y = tf.constant([5, 6, 7]) tf.math.less(x, y) ==> [False, True, True]Declaration
public static func less<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<Bool> -
Returns the truth value of (x <= y) element-wise.
NOTE:
LessEqualsupports broadcasting. More about broadcasting hereExample:
x = tf.constant([5, 4, 6]) y = tf.constant([5]) tf.math.less_equal(x, y) ==> [True, True, False] x = tf.constant([5, 4, 6]) y = tf.constant([5, 6, 6]) tf.math.less_equal(x, y) ==> [True, True, True]Declaration
public static func lessEqual<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<Bool> -
Computes the log of the absolute value of
Gamma(x)element-wise.For positive numbers, this function computes log((input - 1)!) for every element in the tensor.
lgamma(5) = log((5-1)!) = log(4!) = log(24) = 3.1780539Example:
x = tf.constant([0, 0.5, 1, 4.5, -4, -5.6]) tf.math.lgamma(x) ==> [inf, 0.5723649, 0., 2.4537368, inf, -4.6477685]Declaration
public static func lgamma<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Generates values in an interval.
A sequence of
numevenly-spaced values are generated beginning atstart. Ifnum > 1, the values in the sequence increase bystop - start / num - 1, so that the last one is exactlystop.For example:
tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]Output output: 1-D. The generated values.
Declaration
public static func linSpace< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( start: Tensor<T>, stop: Tensor<T>, num: Tensor<Tidx> ) -> Tensor<T>Parameters
start0-D tensor. First entry in the range.
stop0-D tensor. Last entry in the range.
num0-D tensor. Number of values to generate.
-
Computes the difference between two lists of numbers or strings.
Given a list
xand a listy, this operation returns a listoutthat represents all values that are inxbut not iny. The returned listoutis sorted in the same order that the numbers appear inx(duplicates are preserved). This operation also returns a listidxthat represents the position of eachoutelement inx. In other words:out[i] = x[idx[i]] for i in [0, 1, ..., len(out) - 1]For example, given this input:
x = [1, 2, 3, 4, 5, 6] y = [1, 3, 5]This operation would return:
out ==> [2, 4, 6] idx ==> [1, 3, 5]Outputs:
- out: 1-D. Values present in
xbut not iny. - idx: 1-D. Positions of
xvalues preserved inout.
- out: 1-D. Values present in
Declaration
public static func listDiff< T: TensorFlowScalar, OutIdx: TensorFlowIndex >( _ x: Tensor<T>, _ y: Tensor<T> ) -> (out: Tensor<T>, idx: Tensor<OutIdx>)Parameters
x1-D. Values to keep.
y1-D. Values to remove.
-
Declaration
public static func listInput<T: TensorFlowScalar>( _ a: [Tensor<T>] ) -
Declaration
public static func listOutput<T>() -> T where T : TensorGroup -
loadAndRemapMatrix(ckptPath:oldTensorName:rowRemapping:colRemapping:initializingValues:numRows:numCols:maxRowsInMemory:)
Loads a 2-D (matrix)
Tensorwith nameold_tensor_namefrom the checkpointat
ckpt_pathand potentially reorders its rows and columns using the specified remappings.Most users should use one of the wrapper initializers (such as
tf.contrib.framework.load_and_remap_matrix_initializer) instead of this function directly.The remappings are 1-D tensors with the following properties:
row_remappingmust have exactlynum_rowsentries. Rowiof the output matrix will be initialized from the row corresponding to indexrow_remapping[i]in the oldTensorfrom the checkpoint.col_remappingmust have either 0 entries (indicating that no column reordering is needed) ornum_colsentries. If specified, columnjof the output matrix will be initialized from the column corresponding to indexcol_remapping[j]in the oldTensorfrom the checkpoint.- A value of -1 in either of the remappings signifies a “missing” entry. In that
case, values from the
initializing_valuestensor will be used to fill that missing row or column. Ifrow_remappinghasrmissing entries andcol_remappinghascmissing entries, then the following condition must be true:
(r * num_cols) + (c * num_rows) - (r * c) == len(initializing_values)The remapping tensors can be generated using the GenerateVocabRemapping op.
As an example, with row_remapping = [1, 0, -1], col_remapping = [0, 2, -1], initializing_values = [0.5, -0.5, 0.25, -0.25, 42], and w(i, j) representing the value from row i, column j of the old tensor in the checkpoint, the output matrix will look like the following:
[[w(1, 0), w(1, 2), 0.5], [w(0, 0), w(0, 2), -0.5], [0.25, -0.25, 42]]
Attrs:
- num_rows: Number of rows (length of the 1st dimension) in the output matrix.
- num_cols: Number of columns (length of the 2nd dimension) in the output matrix.
- max_rows_in_memory: The maximum number of rows to load from the checkpoint at once. If less than or equal to 0, the entire matrix will be loaded into memory. Setting this arg trades increased disk reads for lower memory usage.
Output output_matrix: Output matrix containing existing values loaded from the checkpoint, and with any missing values filled in from initializing_values.
Declaration
public static func loadAndRemapMatrix( ckptPath: StringTensor, oldTensorName: StringTensor, rowRemapping: Tensor<Int64>, colRemapping: Tensor<Int64>, initializingValues: Tensor<Float>, numRows: Int64, numCols: Int64, maxRowsInMemory: Int64 = -1 ) -> Tensor<Float>Parameters
ckpt_pathPath to the TensorFlow checkpoint (version 2,
TensorBundle) from which the old matrixTensorwill be loaded.old_tensor_nameName of the 2-D
Tensorto load from checkpoint.row_remappingcol_remappinginitializing_valuesA float
Tensorcontaining values to fill in for cells in the output matrix that are not loaded from the checkpoint. Length must be exactly the same as the number of missing / new cells. -
loadTPUEmbeddingADAMParameters(parameters:momenta:velocities:tableId:tableName:numShards:shardId:config:)
Load ADAM embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the ADAM optimization algorithm.
momentaValue of momenta used in the ADAM optimization algorithm.
velocitiesValue of velocities used in the ADAM optimization algorithm.
-
loadTPUEmbeddingADAMParametersGradAccumDebug(parameters:momenta:velocities:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load ADAM embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the ADAM optimization algorithm.
momentaValue of momenta used in the ADAM optimization algorithm.
velocitiesValue of velocities used in the ADAM optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the ADAM optimization algorithm.
-
loadTPUEmbeddingAdadeltaParameters(parameters:accumulators:updates:tableId:tableName:numShards:shardId:config:)
Load Adadelta embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Adadelta optimization algorithm.
accumulatorsValue of accumulators used in the Adadelta optimization algorithm.
updatesValue of updates used in the Adadelta optimization algorithm.
-
loadTPUEmbeddingAdadeltaParametersGradAccumDebug(parameters:accumulators:updates:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load Adadelta parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Adadelta optimization algorithm.
accumulatorsValue of accumulators used in the Adadelta optimization algorithm.
updatesValue of updates used in the Adadelta optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the Adadelta optimization algorithm.
-
loadTPUEmbeddingAdagradParameters(parameters:accumulators:tableId:tableName:numShards:shardId:config:)
Load Adagrad embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Adagrad optimization algorithm.
accumulatorsValue of accumulators used in the Adagrad optimization algorithm.
-
loadTPUEmbeddingAdagradParametersGradAccumDebug(parameters:accumulators:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load Adagrad embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Adagrad optimization algorithm.
accumulatorsValue of accumulators used in the Adagrad optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the Adagrad optimization algorithm.
-
loadTPUEmbeddingCenteredRMSPropParameters(parameters:ms:mom:mg:tableId:tableName:numShards:shardId:config:)
Load centered RMSProp embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the centered RMSProp optimization algorithm.
msValue of ms used in the centered RMSProp optimization algorithm.
momValue of mom used in the centered RMSProp optimization algorithm.
mgValue of mg used in the centered RMSProp optimization algorithm.
-
loadTPUEmbeddingFTRLParameters(parameters:accumulators:linears:tableId:tableName:numShards:shardId:config:)
Load FTRL embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the FTRL optimization algorithm.
accumulatorsValue of accumulators used in the FTRL optimization algorithm.
linearsValue of linears used in the FTRL optimization algorithm.
-
loadTPUEmbeddingFTRLParametersGradAccumDebug(parameters:accumulators:linears:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load FTRL embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the FTRL optimization algorithm.
accumulatorsValue of accumulators used in the FTRL optimization algorithm.
linearsValue of linears used in the FTRL optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the FTRL optimization algorithm.
-
loadTPUEmbeddingMDLAdagradLightParameters(parameters:accumulators:weights:benefits:tableId:tableName:numShards:shardId:config:)
Load MDL Adagrad Light embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the MDL Adagrad Light optimization algorithm.
accumulatorsValue of accumulators used in the MDL Adagrad Light optimization algorithm.
weightsValue of weights used in the MDL Adagrad Light optimization algorithm.
benefitsValue of benefits used in the MDL Adagrad Light optimization algorithm.
-
Load Momentum embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Momentum optimization algorithm.
momentaValue of momenta used in the Momentum optimization algorithm.
-
loadTPUEmbeddingMomentumParametersGradAccumDebug(parameters:momenta:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load Momentum embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the Momentum optimization algorithm.
momentaValue of momenta used in the Momentum optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the Momentum optimization algorithm.
-
loadTPUEmbeddingProximalAdagradParameters(parameters:accumulators:tableId:tableName:numShards:shardId:config:)
Load proximal Adagrad embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the proximal Adagrad optimization algorithm.
accumulatorsValue of accumulators used in the proximal Adagrad optimization algorithm.
-
loadTPUEmbeddingProximalAdagradParametersGradAccumDebug(parameters:accumulators:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load proximal Adagrad embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the proximal Adagrad optimization algorithm.
accumulatorsValue of accumulators used in the proximal Adagrad optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the proximal Adagrad optimization algorithm.
-
Load RMSProp embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the RMSProp optimization algorithm.
msValue of ms used in the RMSProp optimization algorithm.
momValue of mom used in the RMSProp optimization algorithm.
-
loadTPUEmbeddingRMSPropParametersGradAccumDebug(parameters:ms:mom:gradientAccumulators:tableId:tableName:numShards:shardId:config:)
Load RMSProp embedding parameters with debug support.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
Parameters
parametersValue of parameters used in the RMSProp optimization algorithm.
msValue of ms used in the RMSProp optimization algorithm.
momValue of mom used in the RMSProp optimization algorithm.
gradient_accumulatorsValue of gradient_accumulators used in the RMSProp optimization algorithm.
-
loadTPUEmbeddingStochasticGradientDescentParameters(parameters:tableId:tableName:numShards:shardId:config:)
Load SGD embedding parameters.
An op that loads optimization parameters into HBM for embedding. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to install parameters that are loaded from a checkpoint before a training loop is executed.
Declaration
public static func loadTPUEmbeddingStochasticGradientDescentParameters( parameters: Tensor<Float>, tableId: Int64 = -1, tableName: String, numShards: Int64, shardId: Int64, config: String )Parameters
parametersValue of parameters used in the stochastic gradient descent optimization algorithm.
-
Computes natural logarithm of x element-wise.
I.e., \(y = \log_e x\).
Example:
x = tf.constant([0, 0.5, 1, 5]) tf.math.log(x) ==> [-inf, -0.6931472, 0. , 1.609438]Declaration
public static func log<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes natural logarithm of (1 + x) element-wise.
I.e., \(y = \log_e (1 + x)\).
Example:
x = tf.constant([0, 0.5, 1, 5]) tf.math.log1p(x) ==> [0., 0.4054651, 0.6931472, 1.7917595]Declaration
public static func log1p<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the sign and the log of the absolute value of the determinant of
one or more square matrices.
The input is a tensor of shape
[N, M, M]whose inner-most 2 dimensions form square matrices. The outputs are two tensors containing the signs and absolute values of the log determinants for all N input submatrices[..., :, :]such that the determinant = sign*exp(log_abs_determinant). The log_abs_determinant is computed as det(P)*sum(log(diag(LU))) where LU is the LU decomposition of the input and P is the corresponding permutation matrix.Outputs:
- sign: The signs of the log determinants of the inputs. Shape is
[N]. - log_abs_determinant: The logs of the absolute values of the determinants
of the N input matrices. Shape is
[N].
- sign: The signs of the log determinants of the inputs. Shape is
Declaration
public static func logMatrixDeterminant<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> (sign: Tensor<T>, logAbsDeterminant: Tensor<T>)Parameters
inputShape is
[N, M, M]. -
Computes log softmax activations.
For each batch
iand classjwe havelogsoftmax[i, j] = logits[i, j] - log(sum(exp(logits[i])))Output logsoftmax: Same shape as
logits.
Declaration
public static func logSoftmax<T: FloatingPoint & TensorFlowScalar>( logits: Tensor<T> ) -> Tensor<T>Parameters
logits2-D with shape
[batch_size, num_classes]. -
Generates labels for candidate sampling with a log-uniform distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to randomly sample.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- range_max: The sampler will sample integers from the interval [0, range_max).
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
Outputs all keys and values in the table.
Outputs:
- keys: Vector of all keys present in the table.
- values: Tensor of all values in the table. Indexed in parallel with
keys.
Declaration
public static func lookupTableExportV2< Tkeys: TensorFlowScalar, Tvalues: TensorFlowScalar >( tableHandle: ResourceHandle ) -> (keys: Tensor<Tkeys>, values: Tensor<Tvalues>)Parameters
table_handleHandle to the table.
-
Looks up keys in a table, outputs the corresponding values.
The tensor
keysmust of the same type as the keys of the table. The outputvaluesis of the type of the table values.The scalar
default_valueis the value output for keys not present in the table. It must also be of the same type as the table values.Output values: Same shape as
keys. Values found in the table, ordefault_valuesfor missing keys.
Declaration
public static func lookupTableFindV2< Tin: TensorFlowScalar, Tout: TensorFlowScalar >( tableHandle: ResourceHandle, keys: Tensor<Tin>, defaultValue: Tensor<Tout> ) -> Tensor<Tout>Parameters
table_handleHandle to the table.
keysAny shape. Keys to look up.
-
Replaces the contents of the table with the specified keys and values.
The tensor
keysmust be of the same type as the keys of the table. The tensorvaluesmust be of the type of the table values.Declaration
public static func lookupTableImportV2< Tin: TensorFlowScalar, Tout: TensorFlowScalar >( tableHandle: ResourceHandle, keys: Tensor<Tin>, _ values: Tensor<Tout> )Parameters
table_handleHandle to the table.
keysAny shape. Keys to look up.
valuesValues to associate with keys.
-
Updates the table to associates keys with values.
The tensor
keysmust be of the same type as the keys of the table. The tensorvaluesmust be of the type of the table values.Declaration
public static func lookupTableInsertV2< Tin: TensorFlowScalar, Tout: TensorFlowScalar >( tableHandle: ResourceHandle, keys: Tensor<Tin>, _ values: Tensor<Tout> )Parameters
table_handleHandle to the table.
keysAny shape. Keys to look up.
valuesValues to associate with keys.
-
Removes keys and its associated values from a table.
The tensor
keysmust of the same type as the keys of the table. Keys not already in the table are silently ignored.Declaration
public static func lookupTableRemoveV2<Tin: TensorFlowScalar>( tableHandle: ResourceHandle, keys: Tensor<Tin> )Parameters
table_handleHandle to the table.
keysAny shape. Keys of the elements to remove.
-
Computes the number of elements in the given table.
Output size: Scalar that contains number of elements in the table.
Declaration
public static func lookupTableSizeV2( tableHandle: ResourceHandle ) -> Tensor<Int64>Parameters
table_handleHandle to the table.
-
Forwards the input to the output.
This operator represents the loop termination condition used by the “pivot” switches of a loop.
Output output: The same tensor as
input.
Parameters
inputA boolean scalar, representing the branch predicate of the Switch op.
-
Applies lower_bound(sorted_search_values, values) along each row.
Each set of rows with the same index in (sorted_inputs, values) is treated independently. The resulting row is the equivalent of calling
np.searchsorted(sorted_inputs, values, side='left').The result is not a global index to the entire
Tensor, but rather just the index in the last dimension.A 2-D example: sorted_sequence = [[0, 3, 9, 9, 10], [1, 2, 3, 4, 5]] values = [[2, 4, 9], [0, 2, 6]]
result = LowerBound(sorted_sequence, values)
result == [[1, 2, 2], [0, 1, 5]]
Output output: A
Tensorwith the same shape asvalues. It contains the first scalar index into the last dimension where values can be inserted without changing the ordered property.
Declaration
public static func lowerBound< T: TensorFlowScalar, OutType: TensorFlowIndex >( sortedInputs: Tensor<T>, _ values: Tensor<T> ) -> Tensor<OutType>Parameters
sorted_inputs2-D Tensor where each row is ordered.
values2-D Tensor with the same numbers of rows as
sorted_search_values. Contains the values that will be searched for insorted_search_values. -
Computes the LU decomposition of one or more square matrices.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices.The input has to be invertible.
The output consists of two tensors LU and P containing the LU decomposition of all input submatrices
[..., :, :]. LU encodes the lower triangular and upper triangular factors.For each input submatrix of shape
[M, M], L is a lower triangular matrix of shape[M, M]with unit diagonal whose entries correspond to the strictly lower triangular part of LU. U is a upper triangular matrix of shape[M, M]whose entries correspond to the upper triangular part, including the diagonal, of LU.P represents a permutation matrix encoded as a list of indices each between
0andM-1, inclusive. If P_mat denotes the permutation matrix corresponding to P, then the L, U and P satisfies P_mat * input = L * U.Outputs:
- lu: A tensor of shape
[..., M, M]whose strictly lower triangular part denotes the lower triangular factorLwith unit diagonal, and whose upper triangular part denotes the upper triangular factorU. - p: Permutation of the rows encoded as a list of indices in
0..M-1. Shape is[..., M]. @compatibility(scipy) Similar toscipy.linalg.lu, except the triangular factorsLandUare packed into a single tensor, the permutation is applied toinputinstead of the right hand side and the permutationPis returned as a list of indices instead of a permutation matrix. @end_compatibility
- lu: A tensor of shape
Declaration
public static func lu< T: FloatingPoint & TensorFlowScalar, OutputIdxType: TensorFlowIndex >( _ input: Tensor<T> ) -> (lu: Tensor<T>, p: Tensor<OutputIdxType>)Parameters
inputA tensor of shape
[..., M, M]whose inner-most 2 dimensions form matrices of size[M, M]. -
Makes a new iterator from the given
datasetand stores it initerator.This operation may be executed multiple times. Each execution will reset the iterator in
iteratorto the first element ofdataset.Declaration
public static func makeIterator( dataset: VariantHandle, iterator: ResourceHandle ) -
mapAndBatchDataset(inputDataset:otherArguments:batchSize:numParallelCalls:dropRemainder:f:outputTypes:outputShapes:preserveCardinality:)
Creates a dataset that fuses mapping with batching.
Creates a dataset that applies
fto the outputs ofinput_datasetand then batchesbatch_sizeof them.Unlike a “MapDataset”, which applies
fsequentially, this dataset invokes up tobatch_size * num_parallel_batchescopies offin parallel.Attr f: A function to apply to the outputs of
input_dataset.
Declaration
public static func mapAndBatchDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, batchSize: Tensor<Int64>, numParallelCalls: Tensor<Int64>, dropRemainder: Tensor<Bool>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], preserveCardinality: Bool = false ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
other_argumentsA list of tensors, typically values that were captured when building a closure for
f.batch_sizeA scalar representing the number of elements to accumulate in a batch. It determines the number of concurrent invocations of
fthat process elements frominput_datasetin parallel.num_parallel_callsA scalar representing the maximum number of parallel invocations of the
map_fnfunction. Applying themap_fnon consecutive input elements in parallel has the potential to improve input pipeline throughput.drop_remainderA scalar representing whether the last batch should be dropped in case its size is smaller than desired.
-
Op removes all elements in the underlying container.
Declaration
public static func mapClear( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -
mapDataset(inputDataset:otherArguments:f:outputTypes:outputShapes:useInterOpParallelism:preserveCardinality:)
Creates a dataset that applies
fto the outputs ofinput_dataset.Declaration
public static func mapDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], useInterOpParallelism: Bool = true, preserveCardinality: Bool = false ) -> VariantHandle -
Maps a function on the list of tensors unpacked from arguments on dimension 0. The function given by
fis assumed to be stateless, and is executed concurrently on all the slices; up to batch_size (i.e. the size of the 0th dimension of each argument) functions will be scheduled at once.The
max_intra_op_parallelismattr, which defaults to 1, can be used to limit the intra op parallelism. To limit inter-op parallelism, a user can set a private threadpool on the dataset usingtf.data.Options‘sThreadingOptions.Note that this op is not exposed to users directly, but is invoked in tf.data rewrites.
Attrs:
- Targuments: A list of types.
- Tcaptured: A list of types.
- output_types: A list of types.
- output_shapes: A list of shapes.
Output output: A list of output tensors whose types are
output_typesand whose dimensions 0 are the same as the dimensions 0 of the tensors inarguments, and whose remaining dimensions correspond to those inoutput_shapes.
Declaration
public static func mapDefun< Targuments: TensorArrayProtocol, Tcaptured: TensorArrayProtocol, OutputTypes: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( arguments: Targuments, capturedInputs: Tcaptured, outputShapes: [TensorShape?], f: (FIn) -> FOut, maxIntraOpParallelism: Int64 = 1 ) -> OutputTypesParameters
argumentsA list of tensors whose types are
Targuments, corresponding to the inputs the function should be mapped over.captured_inputsA list of tensors whose types are
Tcaptured, corresponding to the captured inputs of the defun. -
Op returns the number of incomplete elements in the underlying container.
Declaration
public static func mapIncompleteSize( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -> Tensor<Int32> -
Op peeks at the values at the specified key. If the
underlying container does not contain this key this op will block until it does.
Declaration
public static func mapPeek<Dtypes: TensorGroup>( key: Tensor<Int64>, indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Op returns the number of elements in the underlying container.
Declaration
public static func mapSize( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -> Tensor<Int32> -
Stage (key, values) in the underlying container which behaves like a hashtable.
Attrs:
- capacity: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: It is necessary to match this name to the matching Unstage Op.
Declaration
public static func mapStage<FakeDtypes: TensorArrayProtocol>( key: Tensor<Int64>, indices: Tensor<Int32>, _ values: FakeDtypes, capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String )Parameters
keyint64
valuesa list of tensors dtypes A list of data types that inserted values should adhere to.
-
Op removes and returns the values associated with the key
from the underlying container. If the underlying container does not contain this key, the op will block until it does.
Declaration
public static func mapUnstage<Dtypes: TensorGroup>( key: Tensor<Int64>, indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Op removes and returns a random (key, value)
from the underlying container. If the underlying container does not contain elements, the op will block until it does.
Declaration
public static func mapUnstageNoKey<Dtypes: TensorGroup>( indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> (key: Tensor<Int64>, values: Dtypes) -
Multiply the matrix “a” by the matrix “b”.
The inputs must be two-dimensional matrices and the inner dimension of “a” (after being transposed if transpose_a is true) must match the outer dimension of “b” (after being transposed if transposed_b is true).
Note: The default kernel implementation for MatMul on GPUs uses cublas.
- Attrs:
- transpose_a: If true, “a” is transposed before multiplication.
- transpose_b: If true, “b” is transposed before multiplication.
Declaration
public static func matMul<T: TensorFlowNumeric>( _ a: Tensor<T>, _ b: Tensor<T>, transposeA: Bool = false, transposeB: Bool = false ) -> Tensor<T> - Attrs:
-
Returns the set of files matching one or more glob patterns.
Note that this routine only supports wildcard characters in the basename portion of the pattern, not in the directory portion. Note also that the order of filenames returned is deterministic.
Output filenames: A vector of matching filenames.
Declaration
public static func matchingFiles( pattern: StringTensor ) -> StringTensorParameters
patternShell wildcard pattern(s). Scalar or vector of type string.
-
Declaration
public static func matchingFilesDataset( patterns: StringTensor ) -> VariantHandle -
Copy a tensor setting everything outside a central band in each innermost matrix
to zero.
The
bandpart is computed as follows: Assumeinputhaskdimensions[I, J, K, ..., M, N], then the output is a tensor with the same shape whereband[i, j, k, ..., m, n] = in_band(m, n) * input[i, j, k, ..., m, n].The indicator function
in_band(m, n) = (num_lower < 0 || (m-n) <= num_lower)) && (num_upper < 0 || (n-m) <= num_upper).For example:
# if 'input' is [[ 0, 1, 2, 3] [-1, 0, 1, 2] [-2, -1, 0, 1] [-3, -2, -1, 0]], tf.matrix_band_part(input, 1, -1) ==> [[ 0, 1, 2, 3] [-1, 0, 1, 2] [ 0, -1, 0, 1] [ 0, 0, -1, 0]], tf.matrix_band_part(input, 2, 1) ==> [[ 0, 1, 0, 0] [-1, 0, 1, 0] [-2, -1, 0, 1] [ 0, -2, -1, 0]]Useful special cases:
tf.matrix_band_part(input, 0, -1) ==> Upper triangular part. tf.matrix_band_part(input, -1, 0) ==> Lower triangular part. tf.matrix_band_part(input, 0, 0) ==> Diagonal.Output band: Rank
ktensor of the same shape as input. The extracted banded tensor.
Declaration
public static func matrixBandPart< T: TensorFlowScalar, Tindex: TensorFlowIndex >( _ input: Tensor<T>, numLower: Tensor<Tindex>, numUpper: Tensor<Tindex> ) -> Tensor<T>Parameters
inputRank
ktensor.num_lower0-D tensor. Number of subdiagonals to keep. If negative, keep entire lower triangle.
num_upper0-D tensor. Number of superdiagonals to keep. If negative, keep entire upper triangle.
-
Computes the determinant of one or more square matrices.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices. The output is a tensor containing the determinants for all input submatrices[..., :, :].Output output: Shape is
[...].
Declaration
public static func matrixDeterminant<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Returns a batched diagonal tensor with a given batched diagonal values.
Given a
diagonal, this operation returns a tensor with thediagonaland everything else padded with zeros. The diagonal is computed as follows:Assume
diagonalhaskdimensions[I, J, K, ..., N], then the output is a tensor of rankk+1with dimensions [I, J, K, …, N, N]` where:output[i, j, k, ..., m, n] = 1{m=n} * diagonal[i, j, k, ..., n].For example:
# 'diagonal' is [[1, 2, 3, 4], [5, 6, 7, 8]] and diagonal.shape = (2, 4) tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0] [0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]], [[5, 0, 0, 0] [0, 6, 0, 0] [0, 0, 7, 0] [0, 0, 0, 8]]] which has shape (2, 4, 4)Output output: Rank
k+1, withoutput.shape = diagonal.shape + [diagonal.shape[-1]].
Declaration
public static func matrixDiag<T: TensorFlowScalar>( diagonal: Tensor<T> ) -> Tensor<T>Parameters
diagonalRank
k, wherek >= 1. -
Returns the batched diagonal part of a batched tensor.
This operation returns a tensor with the
diagonalpart of the batchedinput. Thediagonalpart is computed as follows:Assume
inputhaskdimensions[I, J, K, ..., M, N], then the output is a tensor of rankk - 1with dimensions[I, J, K, ..., min(M, N)]where:diagonal[i, j, k, ..., n] = input[i, j, k, ..., n, n].The input must be at least a matrix.
For example:
# 'input' is [[[1, 0, 0, 0] [0, 2, 0, 0] [0, 0, 3, 0] [0, 0, 0, 4]], [[5, 0, 0, 0] [0, 6, 0, 0] [0, 0, 7, 0] [0, 0, 0, 8]]] and input.shape = (2, 4, 4) tf.matrix_diag_part(input) ==> [[1, 2, 3, 4], [5, 6, 7, 8]] which has shape (2, 4)Output diagonal: The extracted diagonal(s) having shape
diagonal.shape = input.shape[:-2] + [min(input.shape[-2:])].
Declaration
public static func matrixDiagPart<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputRank
ktensor wherek >= 2. -
Returns the batched diagonal part of a batched tensor.
Returns a tensor with the
k[0]-th tok[1]-th diagonals of the batchedinput.Assume
inputhasrdimensions[I, J, ..., L, M, N]. Letmax_diag_lenbe the maximum length among all diagonals to be extracted,max_diag_len = min(M + min(k[1], 0), N + min(-k[0], 0))Letnum_diagsbe the number of diagonals to extract,num_diags = k[1] - k[0] + 1.If
num_diags == 1, the output tensor is of rankr - 1with shape[I, J, ..., L, max_diag_len]and values:diagonal[i, j, ..., l, n] = input[i, j, ..., l, n+y, n+x] ; if 0 <= n+y < M and 0 <= n+x < N, padding_value ; otherwise.where
y = max(-k[1], 0),x = max(k[1], 0).Otherwise, the output tensor has rank
rwith dimensions[I, J, ..., L, num_diags, max_diag_len]with values:diagonal[i, j, ..., l, m, n] = input[i, j, ..., l, n+y, n+x] ; if 0 <= n+y < M and 0 <= n+x < N, padding_value ; otherwise.where
d = k[1] - m,y = max(-d, 0), andx = max(d, 0).The input must be at least a matrix.
For example:
input = np.array([[[1, 2, 3, 4], # Input shape: (2, 3, 4) [5, 6, 7, 8], [9, 8, 7, 6]], [[5, 4, 3, 2], [1, 2, 3, 4], [5, 6, 7, 8]]]) # A main diagonal from each batch. tf.matrix_diag_part(input) ==> [[1, 6, 7], # Output shape: (2, 3) [5, 2, 7]] # A superdiagonal from each batch. tf.matrix_diag_part(input, k = 1) ==> [[2, 7, 6], # Output shape: (2, 3) [4, 3, 8]] # A tridiagonal band from each batch. tf.matrix_diag_part(input, k = (-1, 1)) ==> [[[2, 7, 6], # Output shape: (2, 3, 3) [1, 6, 7], [5, 8, 0]], [[4, 3, 8], [5, 2, 7], [1, 6, 0]]] # Padding value = 9 tf.matrix_diag_part(input, k = (1, 3), padding_value = 9) ==> [[[4, 9, 9], # Output shape: (2, 3, 3) [3, 8, 9], [2, 7, 6]], [[2, 9, 9], [3, 4, 9], [4, 3, 8]]]Output diagonal: The extracted diagonal(s).
Declaration
public static func matrixDiagPartV2<T: TensorFlowScalar>( _ input: Tensor<T>, k: Tensor<Int32>, paddingValue: Tensor<T> ) -> Tensor<T>Parameters
inputRank
rtensor wherer >= 2.kDiagonal offset(s). Positive value means superdiagonal, 0 refers to the main diagonal, and negative value means subdiagonals.
kcan be a single integer (for a single diagonal) or a pair of integers specifying the low and high ends of a matrix band.k[0]must not be larger thank[1].padding_valueThe value to fill the area outside the specified diagonal band with. Default is 0.
-
Returns a batched diagonal tensor with given batched diagonal values.
Returns a tensor with the contents in
diagonalask[0]-th tok[1]-th diagonals of a matrix, with everything else padded withpadding.num_rowsandnum_colsspecify the dimension of the innermost matrix of the output. If both are not specified, the op assumes the innermost matrix is square and infers its size fromkand the innermost dimension ofdiagonal. If only one of them is specified, the op assumes the unspecified value is the smallest possible based on other criteria.Let
diagonalhaverdimensions[I, J, ..., L, M, N]. The output tensor has rankr+1with shape[I, J, ..., L, M, num_rows, num_cols]when only one diagonal is given (kis an integer ork[0] == k[1]). Otherwise, it has rankrwith shape[I, J, ..., L, num_rows, num_cols].The second innermost dimension of
diagonalhas double meaning. Whenkis scalar ork[0] == k[1],Mis part of the batch size [I, J, …, M], and the output tensor is:output[i, j, ..., l, m, n] = diagonal[i, j, ..., l, n-max(d_upper, 0)] ; if n - m == d_upper padding_value ; otherwiseOtherwise,
Mis treated as the number of diagonals for the matrix in the same batch (M = k[1]-k[0]+1), and the output tensor is:output[i, j, ..., l, m, n] = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] padding_value ; otherwisewhere
d = n - m,diag_index = k[1] - d, andindex_in_diag = n - max(d, 0).For example:
# The main diagonal. diagonal = np.array([[1, 2, 3, 4], # Input shape: (2, 4) [5, 6, 7, 8]]) tf.matrix_diag(diagonal) ==> [[[1, 0, 0, 0], # Output shape: (2, 4, 4) [0, 2, 0, 0], [0, 0, 3, 0], [0, 0, 0, 4]], [[5, 0, 0, 0], [0, 6, 0, 0], [0, 0, 7, 0], [0, 0, 0, 8]]] # A superdiagonal (per batch). diagonal = np.array([[1, 2, 3], # Input shape: (2, 3) [4, 5, 6]]) tf.matrix_diag(diagonal, k = 1) ==> [[[0, 1, 0, 0], # Output shape: (2, 4, 4) [0, 0, 2, 0], [0, 0, 0, 3], [0, 0, 0, 0]], [[0, 4, 0, 0], [0, 0, 5, 0], [0, 0, 0, 6], [0, 0, 0, 0]]] # A band of diagonals. diagonals = np.array([[[1, 2, 3], # Input shape: (2, 2, 3) [4, 5, 0]], [[6, 7, 9], [9, 1, 0]]]) tf.matrix_diag(diagonals, k = (-1, 0)) ==> [[[1, 0, 0], # Output shape: (2, 3, 3) [4, 2, 0], [0, 5, 3]], [[6, 0, 0], [9, 7, 0], [0, 1, 9]]] # Rectangular matrix. diagonal = np.array([1, 2]) # Input shape: (2) tf.matrix_diag(diagonal, k = -1, num_rows = 3, num_cols = 4) ==> [[0, 0, 0, 0], # Output shape: (3, 4) [1, 0, 0, 0], [0, 2, 0, 0]] # Rectangular matrix with inferred num_cols and padding_value = 9. tf.matrix_diag(diagonal, k = -1, num_rows = 3, padding_value = 9) ==> [[9, 9], # Output shape: (3, 2) [1, 9], [9, 2]]Output output: Has rank
r+1whenkis an integer ork[0] == k[1], rankrotherwise.
Declaration
Parameters
diagonalRank
r, wherer >= 1kDiagonal offset(s). Positive value means superdiagonal, 0 refers to the main diagonal, and negative value means subdiagonals.
kcan be a single integer (for a single diagonal) or a pair of integers specifying the low and high ends of a matrix band.k[0]must not be larger thank[1].num_rowsThe number of rows of the output matrix. If it is not provided, the op assumes the output matrix is a square matrix and infers the matrix size from k and the innermost dimension of
diagonal.num_colsThe number of columns of the output matrix. If it is not provided, the op assumes the output matrix is a square matrix and infers the matrix size from k and the innermost dimension of
diagonal.padding_valueThe number to fill the area outside the specified diagonal band with. Default is 0.
-
Deprecated, use python implementation tf.linalg.matrix_exponential.
Declaration
public static func matrixExponential<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Computes the inverse of one or more square invertible matrices or their
adjoints (conjugate transposes).
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices. The output is a tensor of the same shape as the input containing the inverse for all input submatrices[..., :, :].The op uses LU decomposition with partial pivoting to compute the inverses.
If a matrix is not invertible there is no guarantee what the op does. It may detect the condition and raise an exception or it may simply return a garbage result.
Output output: Shape is
[..., M, M].@compatibility(numpy) Equivalent to np.linalg.inv @end_compatibility
Declaration
public static func matrixInverse<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, adjoint: Bool = false ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Computes the matrix logarithm of one or more square matrices:
\(log(exp(A)) = A\)
This op is only defined for complex matrices. If A is positive-definite and real, then casting to a complex matrix, taking the logarithm and casting back to a real matrix will give the correct result.
This function computes the matrix logarithm using the Schur-Parlett algorithm. Details of the algorithm can be found in Section 11.6.2 of: Nicholas J. Higham, Functions of Matrices: Theory and Computation, SIAM 2008. ISBN 978-0-898716-46-7.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices. The output is a tensor of the same shape as the input containing the exponential for all input submatrices[..., :, :].Output output: Shape is
[..., M, M].@compatibility(scipy) Equivalent to scipy.linalg.logm @end_compatibility
Declaration
public static func matrixLogarithm<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Returns a batched matrix tensor with new batched diagonal values.
Given
inputanddiagonal, this operation returns a tensor with the same shape and values asinput, except for the main diagonal of the innermost matrices. These will be overwritten by the values indiagonal.The output is computed as follows:
Assume
inputhask+1dimensions[I, J, K, ..., M, N]anddiagonalhaskdimensions[I, J, K, ..., min(M, N)]. Then the output is a tensor of rankk+1with dimensions[I, J, K, ..., M, N]where:output[i, j, k, ..., m, n] = diagonal[i, j, k, ..., n]form == n.output[i, j, k, ..., m, n] = input[i, j, k, ..., m, n]form != n.- input: Rank
k+1, wherek >= 1. - diagonal: Rank
k, wherek >= 1. - Output output: Rank
k+1, withoutput.shape = input.shape.
- input: Rank
Declaration
public static func matrixSetDiag<T: TensorFlowScalar>( _ input: Tensor<T>, diagonal: Tensor<T> ) -> Tensor<T>Parameters
inputRank
k+1, wherek >= 1.diagonalRank
k, wherek >= 1. -
Returns a batched matrix tensor with new batched diagonal values.
Given
inputanddiagonal, this operation returns a tensor with the same shape and values asinput, except for the specified diagonals of the innermost matrices. These will be overwritten by the values indiagonal.inputhasr+1dimensions[I, J, ..., L, M, N]. Whenkis scalar ork[0] == k[1],diagonalhasrdimensions[I, J, ..., L, max_diag_len]. Otherwise, it hasr+1dimensions[I, J, ..., L, num_diags, max_diag_len].num_diagsis the number of diagonals,num_diags = k[1] - k[0] + 1.max_diag_lenis the longest diagonal in the range[k[0], k[1]],max_diag_len = min(M + min(k[1], 0), N + min(-k[0], 0))The output is a tensor of rank
k+1with dimensions[I, J, ..., L, M, N]. Ifkis scalar ork[0] == k[1]:output[i, j, ..., l, m, n] = diagonal[i, j, ..., l, n-max(k[1], 0)] ; if n - m == k[1] input[i, j, ..., l, m, n] ; otherwiseOtherwise,
output[i, j, ..., l, m, n] = diagonal[i, j, ..., l, diag_index, index_in_diag] ; if k[0] <= d <= k[1] input[i, j, ..., l, m, n] ; otherwisewhere
d = n - m,diag_index = k[1] - d, andindex_in_diag = n - max(d, 0).For example:
# The main diagonal. input = np.array([[[7, 7, 7, 7], # Input shape: (2, 3, 4) [7, 7, 7, 7], [7, 7, 7, 7]], [[7, 7, 7, 7], [7, 7, 7, 7], [7, 7, 7, 7]]]) diagonal = np.array([[1, 2, 3], # Diagonal shape: (2, 3) [4, 5, 6]]) tf.matrix_set_diag(diagonal) ==> [[[1, 7, 7, 7], # Output shape: (2, 3, 4) [7, 2, 7, 7], [7, 7, 3, 7]], [[4, 7, 7, 7], [7, 5, 7, 7], [7, 7, 6, 7]]] # A superdiagonal (per batch). tf.matrix_set_diag(diagonal, k = 1) ==> [[[7, 1, 7, 7], # Output shape: (2, 3, 4) [7, 7, 2, 7], [7, 7, 7, 3]], [[7, 4, 7, 7], [7, 7, 5, 7], [7, 7, 7, 6]]] # A band of diagonals. diagonals = np.array([[[1, 2, 3], # Diagonal shape: (2, 2, 3) [4, 5, 0]], [[6, 1, 2], [3, 4, 0]]]) tf.matrix_set_diag(diagonals, k = (-1, 0)) ==> [[[1, 7, 7, 7], # Output shape: (2, 3, 4) [4, 2, 7, 7], [0, 5, 3, 7]], [[6, 7, 7, 7], [3, 1, 7, 7], [7, 4, 2, 7]]]Output output: Rank
r+1, withoutput.shape = input.shape.
Declaration
public static func matrixSetDiagV2<T: TensorFlowScalar>( _ input: Tensor<T>, diagonal: Tensor<T>, k: Tensor<Int32> ) -> Tensor<T>Parameters
inputRank
r+1, wherer >= 1.diagonalRank
rwhenkis an integer ork[0] == k[1]. Otherwise, it has rankr+1.k >= 1.kDiagonal offset(s). Positive value means superdiagonal, 0 refers to the main diagonal, and negative value means subdiagonals.
kcan be a single integer (for a single diagonal) or a pair of integers specifying the low and high ends of a matrix band.k[0]must not be larger thank[1]. -
Solves systems of linear equations.
Matrixis a tensor of shape[..., M, M]whose inner-most 2 dimensions form square matrices.Rhsis a tensor of shape[..., M, K]. Theoutputis a tensor shape[..., M, K]. IfadjointisFalsethen each output matrix satisfiesmatrix[..., :, :] * output[..., :, :] = rhs[..., :, :]. IfadjointisTruethen each output matrix satisfiesadjoint(matrix[..., :, :]) * output[..., :, :] = rhs[..., :, :].Attr adjoint: Boolean indicating whether to solve with
matrixor its (block-wise) adjoint.Output output: Shape is
[..., M, K].
Declaration
public static func matrixSolve<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, adjoint: Bool = false ) -> Tensor<T>Parameters
matrixShape is
[..., M, M].rhsShape is
[..., M, K]. -
Solves one or more linear least-squares problems.
matrixis a tensor of shape[..., M, N]whose inner-most 2 dimensions form real or complex matrices of size[M, N].Rhsis a tensor of the same type asmatrixand shape[..., M, K]. The output is a tensor shape[..., N, K]where each output matrix solves each of the equationsmatrix[..., :, :]*output[..., :, :]=rhs[..., :, :]in the least squares sense.We use the following notation for (complex) matrix and right-hand sides in the batch:
matrix=\(A \in \mathbb{C}^{m \times n}\),rhs=\(B \in \mathbb{C}^{m \times k}\),output=\(X \in \mathbb{C}^{n \times k}\),l2_regularizer=\(\lambda \in \mathbb{R}\).If
fastisTrue, then the solution is computed by solving the normal equations using Cholesky decomposition. Specifically, if \(m \ge n\) then \(X = (A^H A + \lambda I)^{-1} A^H B\), which solves the least-squares problem \(X = \mathrm{argmin}{Z \in \Re^{n \times k} } ||A Z - B||_F^2 + \lambda ||Z||_F^2\). If \(m \lt n\) thenoutputis computed as \(X = A^H (A A^H + \lambda I)^{-1} B\), which (for \(\lambda = 0\)) is the minimum-norm solution to the under-determined linear system, i.e. \(X = \mathrm{argmin}{Z \in \mathbb{C}^{n \times k} } ||Z||F^2 \), subject to \(A Z = B\). Notice that the fast path is only numerically stable when \(A\) is numerically full rank and has a condition number \(\mathrm{cond}(A) \lt \frac{1}{\sqrt{\epsilon{mach} } }\) or \(\lambda\) is sufficiently large.If
fastisFalsean algorithm based on the numerically robust complete orthogonal decomposition is used. This computes the minimum-norm least-squares solution, even when \(A\) is rank deficient. This path is typically 6-7 times slower than the fast path. IffastisFalsethenl2_regularizeris ignored.Output output: Shape is
[..., N, K].
Declaration
public static func matrixSolveLs<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, l2Regularizer: Tensor<Double>, fast: Bool = true ) -> Tensor<T>Parameters
matrixShape is
[..., M, N].rhsShape is
[..., M, K].l2_regularizerScalar tensor.
@compatibility(numpy) Equivalent to np.linalg.lstsq @end_compatibility
-
Computes the matrix square root of one or more square matrices:
matmul(sqrtm(A), sqrtm(A)) = A
The input matrix should be invertible. If the input matrix is real, it should have no eigenvalues which are real and negative (pairs of complex conjugate eigenvalues are allowed).
The matrix square root is computed by first reducing the matrix to quasi-triangular form with the real Schur decomposition. The square root of the quasi-triangular matrix is then computed directly. Details of the algorithm can be found in: Nicholas J. Higham, “Computing real square roots of a real matrix”, Linear Algebra Appl., 1987.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices. The output is a tensor of the same shape as the input containing the matrix square root for all input submatrices[..., :, :].Output output: Shape is
[..., M, M].@compatibility(scipy) Equivalent to scipy.linalg.sqrtm @end_compatibility
Declaration
public static func matrixSquareRoot<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Solves systems of linear equations with upper or lower triangular matrices by backsubstitution.
matrixis a tensor of shape[..., M, M]whose inner-most 2 dimensions form square matrices. IflowerisTruethen the strictly upper triangular part of each inner-most matrix is assumed to be zero and not accessed. Ifloweris False then the strictly lower triangular part of each inner-most matrix is assumed to be zero and not accessed.rhsis a tensor of shape[..., M, K].The output is a tensor of shape
[..., M, K]. IfadjointisTruethen the innermost matrices inoutputsatisfy matrix equationsmatrix[..., :, :] * output[..., :, :] = rhs[..., :, :]. IfadjointisFalsethen the strictly then the innermost matrices inoutputsatisfy matrix equationsadjoint(matrix[..., i, k]) * output[..., k, j] = rhs[..., i, j].Example:
a = tf.constant([[3, 0, 0, 0], [2, 1, 0, 0], [1, 0, 1, 0], [1, 1, 1, 1]], dtype=tf.float32) b = tf.constant([[4], [2], [4], [2]], dtype=tf.float32) x = tf.linalg.triangular_solve(a, b, lower=True) x # <tf.Tensor: shape=(4, 1), dtype=float32, numpy= # array([[ 1.3333334 ], # [-0.66666675], # [ 2.6666665 ], # [-1.3333331 ]], dtype=float32)> # in python3 one can use `a@x` tf.matmul(a, x) # <tf.Tensor: shape=(4, 1), dtype=float32, numpy= # array([[4. ], # [2. ], # [4. ], # [1.9999999]], dtype=float32)>Attrs:
- lower: Boolean indicating whether the innermost matrices in
matrixare lower or upper triangular. adjoint: Boolean indicating whether to solve with
matrixor its (block-wise) adjoint.@compatibility(numpy) Equivalent to scipy.linalg.solve_triangular @end_compatibility
- lower: Boolean indicating whether the innermost matrices in
Output output: Shape is
[..., M, K].
Declaration
public static func matrixTriangularSolve<T: FloatingPoint & TensorFlowScalar>( matrix: Tensor<T>, rhs: Tensor<T>, lower: Bool = true, adjoint: Bool = false ) -> Tensor<T>Parameters
matrixShape is
[..., M, M].rhsShape is
[..., M, K]. -
Computes the maximum of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func max< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Creates a dataset that overrides the maximum intra-op parallelism.
Declaration
public static func maxIntraOpParallelismDataset( inputDataset: VariantHandle, maxIntraOpParallelism: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
max_intra_op_parallelismIdentifies the maximum intra-op parallelism to use.
-
Performs max pooling on the input.
Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: The max pooled output tensor.
Declaration
public static func maxPool<T: TensorFlowNumeric>( _ input: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat5 = .nhwc ) -> Tensor<T>Parameters
input4-D input to pool over.
-
Performs 3D max pooling on the input.
Attrs:
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
ksize[0] = ksize[4] = 1. - strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
Output output: The max pooled output tensor.
Declaration
public static func maxPool3D<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc ) -> Tensor<T>Parameters
inputShape
[batch, depth, rows, cols, channels]tensor to pool over. -
Computes gradients of max pooling function.
Attrs:
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
ksize[0] = ksize[4] = 1. - strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
Declaration
public static func maxPool3DGrad< T: FloatingPoint & TensorFlowScalar, Tinput: FloatingPoint & TensorFlowScalar >( origInput: Tensor<Tinput>, origOutput: Tensor<Tinput>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
gradOutput backprop of shape
[batch, depth, rows, cols, channels]. -
Computes second-order gradients of the maxpooling function.
Attrs:
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
ksize[0] = ksize[4] = 1. - strides: 1-D tensor of length 5. The stride of the sliding window for each
dimension of
input. Must havestrides[0] = strides[4] = 1. - padding: The type of padding algorithm to use.
- data_format: The data format of the input and output data. With the default format “NDHWC”, the data is stored in the order of: [batch, in_depth, in_height, in_width, in_channels]. Alternatively, the format could be “NCDHW”, the data storage order is: [batch, in_channels, in_depth, in_height, in_width].
- ksize: 1-D tensor of length 5. The size of the window for each dimension of
the input tensor. Must have
Output output: Gradients of gradients w.r.t. the input to
max_pool.
Declaration
public static func maxPool3DGradGrad<T: TensorFlowNumeric>( origInput: Tensor<T>, origOutput: Tensor<T>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat1 = .ndhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
gradOutput backprop of shape
[batch, depth, rows, cols, channels]. -
Computes gradients of the maxpooling function.
Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: Gradients w.r.t. the input to
max_pool.
Declaration
public static func maxPoolGrad<T: TensorFlowNumeric>( origInput: Tensor<T>, origOutput: Tensor<T>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
grad4-D. Gradients w.r.t. the output of
max_pool. -
Computes second-order gradients of the maxpooling function.
Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: Gradients of gradients w.r.t. the input to
max_pool.
Declaration
public static func maxPoolGradGrad<T: TensorFlowNumeric>( origInput: Tensor<T>, origOutput: Tensor<T>, grad: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
grad4-D. Gradients of gradients w.r.t. the input of
max_pool. -
Computes second-order gradients of the maxpooling function.
Attrs:
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: Gradients of gradients w.r.t. the input to
max_pool.
Declaration
public static func maxPoolGradGradV2<T: TensorFlowNumeric>( origInput: Tensor<T>, origOutput: Tensor<T>, grad: Tensor<T>, ksize: Tensor<Int32>, strides: Tensor<Int32>, padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
grad4-D. Gradients of gradients w.r.t. the input of
max_pool.ksizeThe size of the window for each dimension of the input tensor.
stridesThe stride of the sliding window for each dimension of the input tensor.
-
Computes second-order gradients of the maxpooling function.
Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- include_batch_in_index: Whether to include batch dimension in flattened index of
argmax.
Output output: Gradients of gradients w.r.t. the input of
max_pool.
Declaration
public static func maxPoolGradGradWithArgmax< Targmax: TensorFlowIndex, T: TensorFlowNumeric >( _ input: Tensor<T>, grad: Tensor<T>, argmax: Tensor<Targmax>, ksize: [Int32], strides: [Int32], padding: Padding, includeBatchInIndex: Bool = false ) -> Tensor<T>Parameters
inputThe original input.
grad4-D with shape
[batch, height, width, channels]. Gradients w.r.t. the input ofmax_pool.argmaxThe indices of the maximum values chosen for each output of
max_pool. -
Computes gradients of the maxpooling function.
Attrs:
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: Gradients w.r.t. the input to
max_pool.
Declaration
public static func maxPoolGradV2<T: TensorFlowNumeric>( origInput: Tensor<T>, origOutput: Tensor<T>, grad: Tensor<T>, ksize: Tensor<Int32>, strides: Tensor<Int32>, padding: Padding, dataFormat: DataFormat = .nhwc ) -> Tensor<T>Parameters
orig_inputThe original input tensor.
orig_outputThe original output tensor.
grad4-D. Gradients w.r.t. the output of
max_pool.ksizeThe size of the window for each dimension of the input tensor.
stridesThe stride of the sliding window for each dimension of the input tensor.
-
Computes gradients of the maxpooling function.
Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- include_batch_in_index: Whether to include batch dimension in flattened index of
argmax.
Output output: Gradients w.r.t. the input of
max_pool.
Declaration
public static func maxPoolGradWithArgmax< Targmax: TensorFlowIndex, T: TensorFlowNumeric >( _ input: Tensor<T>, grad: Tensor<T>, argmax: Tensor<Targmax>, ksize: [Int32], strides: [Int32], padding: Padding, includeBatchInIndex: Bool = false ) -> Tensor<T>Parameters
inputThe original input.
grad4-D with shape
[batch, height, width, channels]. Gradients w.r.t. the output ofmax_pool.argmaxThe indices of the maximum values chosen for each output of
max_pool. -
Performs max pooling on the input.
Attrs:
- padding: The type of padding algorithm to use.
- data_format: Specify the data format of the input and output data. With the default format “NHWC”, the data is stored in the order of: [batch, in_height, in_width, in_channels]. Alternatively, the format could be “NCHW”, the data storage order of: [batch, in_channels, in_height, in_width].
Output output: The max pooled output tensor.
Declaration
public static func maxPoolV2<T: TensorFlowNumeric>( _ input: Tensor<T>, ksize: Tensor<Int32>, strides: Tensor<Int32>, padding: Padding, dataFormat: DataFormat5 = .nhwc ) -> Tensor<T>Parameters
input4-D input to pool over.
ksizeThe size of the window for each dimension of the input tensor.
stridesThe stride of the sliding window for each dimension of the input tensor.
-
Performs max pooling on the input and outputs both max values and indices.
The indices in
argmaxare flattened, so that a maximum value at position[b, y, x, c]becomes flattened index:(y * width + x) * channels + cifinclude_batch_in_indexis False;((b * height + y) * width + x) * channels + cifinclude_batch_in_indexis True.The indices returned are always in
[0, height) x [0, width)before flattening, even if padding is involved and the mathematically correct answer is outside (either negative or too large). This is a bug, but fixing it is difficult to do in a safe backwards compatible way, especially due to flattening.Attrs:
- ksize: The size of the window for each dimension of the input tensor.
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- include_batch_in_index: Whether to include batch dimension in flattened index of
argmax.
Outputs:
- output: The max pooled output tensor.
- argmax: 4-D. The flattened indices of the max values chosen for each output.
Declaration
public static func maxPoolWithArgmax< Targmax: TensorFlowIndex, T: TensorFlowNumeric >( _ input: Tensor<T>, ksize: [Int32], strides: [Int32], padding: Padding, includeBatchInIndex: Bool = false ) -> (output: Tensor<T>, argmax: Tensor<Targmax>)Parameters
input4-D with shape
[batch, height, width, channels]. Input to pool over. -
Returns the max of x and y (i.e. x > y ? x : y) element-wise.
NOTE:
Maximumsupports broadcasting. More about broadcasting hereDeclaration
public static func maximum<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Computes the mean of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func mean< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Forwards the value of an available tensor from
inputstooutput.Mergewaits for at least one of the tensors ininputsto become available. It is usually combined withSwitchto implement branching.Mergeforwards the first tensor to become available tooutput, and setsvalue_indexto its index ininputs.Outputs:
- output: Will be set to the available input tensor.
- value_index: The index of the chosen input tensor in
inputs.
Declaration
public static func merge<T: TensorFlowScalar>( inputs: [Tensor<T>] ) -> (output: Tensor<T>, valueIndex: Tensor<Int32>)Parameters
inputsThe input tensors, exactly one of which will become available.
-
Merges summaries.
This op creates a
Summaryprotocol buffer that contains the union of all the values in the input summaries.When the Op is run, it reports an
InvalidArgumenterror if multiple values in the summaries to merge use the same tag.Output summary: Scalar. Serialized
Summaryprotocol buffer.
Declaration
public static func mergeSummary( inputs: [StringTensor] ) -> StringTensorParameters
inputsCan be of any shape. Each must contain serialized
Summaryprotocol buffers. -
V2 format specific: merges the metadata files of sharded checkpoints. The
result is one logical checkpoint, with one physical metadata file and renamed data files.
Intended for “grouping” multiple checkpoints in a sharded checkpoint setup.
If delete_old_dirs is true, attempts to delete recursively the dirname of each path in the input checkpoint_prefixes. This is useful when those paths are non user-facing temporary locations.
Attr delete_old_dirs: see above.
Declaration
public static func mergeV2Checkpoints( checkpointPrefixes: StringTensor, destinationPrefix: StringTensor, deleteOldDirs: Bool = true )Parameters
checkpoint_prefixesprefixes of V2 checkpoints to merge.
destination_prefixscalar. The desired final prefix. Allowed to be the same as one of the checkpoint_prefixes.
-
mfcc(spectrogram:sampleRate:upperFrequencyLimit:lowerFrequencyLimit:filterbankChannelCount:dctCoefficientCount:)
Transforms a spectrogram into a form that’s useful for speech recognition.
Mel Frequency Cepstral Coefficients are a way of representing audio data that’s been effective as an input feature for machine learning. They are created by taking the spectrum of a spectrogram (a ‘cepstrum’), and discarding some of the higher frequencies that are less significant to the human ear. They have a long history in the speech recognition world, and https://en.wikipedia.org/wiki/Mel-frequency_cepstrum is a good resource to learn more.
Attrs:
- upper_frequency_limit: The highest frequency to use when calculating the ceptstrum.
- lower_frequency_limit: The lowest frequency to use when calculating the ceptstrum.
- filterbank_channel_count: Resolution of the Mel bank used internally.
- dct_coefficient_count: How many output channels to produce per time slice.
Declaration
Parameters
spectrogramTypically produced by the Spectrogram op, with magnitude_squared set to true.
sample_rateHow many samples per second the source audio used.
-
Computes the minimum of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func min< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Returns the min of x and y (i.e. x < y ? x : y) element-wise.
NOTE:
Minimumsupports broadcasting. More about broadcasting hereDeclaration
public static func minimum<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Pads a tensor with mirrored values.
This operation pads a
inputwith mirrored values according to thepaddingsyou specify.paddingsis an integer tensor with shape[n, 2], where n is the rank ofinput. For each dimension D ofinput,paddings[D, 0]indicates how many values to add before the contents ofinputin that dimension, andpaddings[D, 1]indicates how many values to add after the contents ofinputin that dimension. Bothpaddings[D, 0]andpaddings[D, 1]must be no greater thaninput.dim_size(D)(orinput.dim_size(D) - 1) ifcopy_borderis true (if false, respectively).The padded size of each dimension D of the output is:
paddings(D, 0) + input.dim_size(D) + paddings(D, 1)For example:
# 't' is [[1, 2, 3], [4, 5, 6]]. # 'paddings' is [[1, 1]], [2, 2]]. # 'mode' is SYMMETRIC. # rank of 't' is 2. pad(t, paddings) ==> [[2, 1, 1, 2, 3, 3, 2] [2, 1, 1, 2, 3, 3, 2] [5, 4, 4, 5, 6, 6, 5] [5, 4, 4, 5, 6, 6, 5]]Attr mode: Either
REFLECTorSYMMETRIC. In reflect mode the padded regions do not include the borders, while in symmetric mode the padded regions do include the borders. For example, ifinputis[1, 2, 3]andpaddingsis[0, 2], then the output is[1, 2, 3, 2, 1]in reflect mode, and it is[1, 2, 3, 3, 2]in symmetric mode.Output output: The padded tensor.
Declaration
public static func mirrorPad< T: TensorFlowScalar, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, paddings: Tensor<Tpaddings>, mode: Mode6 ) -> Tensor<T>Parameters
inputThe input tensor to be padded.
paddingsA two-column matrix specifying the padding sizes. The number of rows must be the same as the rank of
input. -
Gradient op for
MirrorPadop. This op folds a mirror-padded tensor.This operation folds the padded areas of
inputbyMirrorPadaccording to thepaddingsyou specify.paddingsmust be the same aspaddingsargument given to the correspondingMirrorPadop.The folded size of each dimension D of the output is:
input.dim_size(D) - paddings(D, 0) - paddings(D, 1)For example:
# 't' is [[1, 2, 3], [4, 5, 6], [7, 8, 9]]. # 'paddings' is [[0, 1]], [0, 1]]. # 'mode' is SYMMETRIC. # rank of 't' is 2. pad(t, paddings) ==> [[ 1, 5] [11, 28]]Attr mode: The mode used in the
MirrorPadop.Output output: The folded tensor.
Declaration
public static func mirrorPadGrad< T: TensorFlowScalar, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, paddings: Tensor<Tpaddings>, mode: Mode6 ) -> Tensor<T>Parameters
inputThe input tensor to be folded.
paddingsA two-column matrix specifying the padding sizes. The number of rows must be the same as the rank of
input. -
Wraps an arbitrary MLIR computation expressed as a module with a main() function.
This operation does not have an associated kernel and is not intended to be executed in a regular TensorFlow session. Instead it is intended to be used for testing or for special case where a user intends to pass custom MLIR computation through a TensorFlow graph with the intent of having custom tooling processing it downstream (when targeting a different environment, like TensorFlow lite for example). The MLIR module is expected to have a main() function that will be used as an entry point. The inputs to the operations will be passed as argument to the main() function and the returned values of the main function mapped to the outputs. Example usage:
import tensorflow as tf from tensorflow.compiler.mlir.tensorflow.gen_mlir_passthrough_op import mlir_passthrough_op mlir_module = '''python func @main(%arg0 : tensor<10xf32>, %arg1 : tensor<10xf32>) -> tensor<10x10xf32> { %add = "magic.op"(%arg0, %arg1) : (tensor<10xf32>, tensor<10xf32>) -> tensor<10x10xf32> return %ret : tensor<10x10xf32> } ''' @tf.function def foo(x, y): return = mlir_passthrough_op([x, y], mlir_module, Toutputs=[tf.float32]) graph_def = foo.get_concrete_function(tf.TensorSpec([10], tf.float32), tf.TensorSpec([10], tf.float32)).graph.as_graph_def()Declaration
public static func mlirPassthroughOp< Tinputs: TensorArrayProtocol, Toutputs: TensorGroup >( inputs: Tinputs, mlirModule: String ) -> Toutputs -
Returns element-wise remainder of division. This emulates C semantics in that
the result here is consistent with a truncating divide. E.g.
tf.truncatediv(x, y) * y + truncate_mod(x, y) = x.NOTE:
Modsupports broadcasting. More about broadcasting hereDeclaration
public static func mod<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Identity transformation that models performance.
Identity transformation that models performance.
Declaration
public static func modelDataset( inputDataset: VariantHandle, algorithm: Int64 = 0, cpuBudget: Int64 = 0, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
-
Returns x * y element-wise.
NOTE:
Multiplysupports broadcasting. More about broadcasting hereDeclaration
public static func mul<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns x * y element-wise. Returns zero if y is zero, even if x if infinite or NaN.
NOTE:
MulNoNansupports broadcasting. More about broadcasting hereDeclaration
public static func mulNoNan<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Creates a MultiDeviceIterator resource.
Attrs:
- devices: A list of devices the iterator works across.
- shared_name: If non-empty, this resource will be shared under the given name across multiple sessions.
- container: If non-empty, this resource is placed in the given container. Otherwise, a default container is used.
- output_types: The type list for the return values.
- output_shapes: The list of shapes being produced.
Output handle: Handle to the resource created.
Declaration
public static func multiDeviceIterator( devices: [String], sharedName: String, container: String, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandle -
Generates a MultiDeviceIterator resource from its provided string handle.
Attrs:
- output_types: The type list for the return values.
- output_shapes: The list of shapes being produced.
Output multi_device_iterator: A MultiDeviceIterator resource.
Declaration
public static func multiDeviceIteratorFromStringHandle( stringHandle: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> ResourceHandleParameters
string_handleString representing the resource.
-
Gets next element for the provided shard number.
Attrs:
- output_types: The type list for the return values.
- output_shapes: The list of shapes being produced.
Output components: Result of the get_next on the dataset.
Declaration
public static func multiDeviceIteratorGetNextFromShard<OutputTypes: TensorGroup>( multiDeviceIterator: ResourceHandle, shardNum: Tensor<Int32>, incarnationId: Tensor<Int64>, outputShapes: [TensorShape?] ) -> OutputTypesParameters
multi_device_iteratorA MultiDeviceIterator resource.
shard_numInteger representing which shard to fetch data for.
incarnation_idWhich incarnation of the MultiDeviceIterator is running.
-
Initializes the multi device iterator with the given dataset.
Output incarnation_id: An int64 indicating which incarnation of the MultiDeviceIterator is running.
Declaration
public static func multiDeviceIteratorInit( dataset: VariantHandle, multiDeviceIterator: ResourceHandle, maxBufferSize: Tensor<Int64> ) -> Tensor<Int64>Parameters
datasetDataset to be iterated upon.
multi_device_iteratorA MultiDeviceIteratorResource.
max_buffer_sizeThe maximum size of the host side per device buffer to keep.
-
Produces a string handle for the given MultiDeviceIterator.
Output string_handle: A string representing the resource.
Declaration
public static func multiDeviceIteratorToStringHandle( multiDeviceIterator: ResourceHandle ) -> StringTensorParameters
multi_device_iteratorA MultiDeviceIterator resource.
-
Draws samples from a multinomial distribution.
Attrs:
- seed: If either seed or seed2 is set to be non-zero, the internal random number generator is seeded by the given seed. Otherwise, a random seed is used.
- seed2: A second seed to avoid seed collision.
Output output: 2-D Tensor with shape
[batch_size, num_samples]. Each slice[i, :]contains the drawn class labels with range[0, num_classes).
Declaration
public static func multinomial< T: TensorFlowNumeric, OutputDtype: TensorFlowIndex >( logits: Tensor<T>, numSamples: Tensor<Int32>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<OutputDtype>Parameters
logits2-D Tensor with shape
[batch_size, num_classes]. Each slice[i, :]represents the unnormalized log probabilities for all classes.num_samples0-D. Number of independent samples to draw for each row slice.
-
mutableDenseHashTableV2(emptyKey:deletedKey:container:sharedName:useNodeNameSharing:valueDtype:valueShape:initialNumBuckets:maxLoadFactor:)
Creates an empty hash table that uses tensors as the backing store.
It uses “open addressing” with quadratic reprobing to resolve collisions.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a scalar. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Attrs:
- container: If non-empty, this table is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this table is shared under the given name across multiple sessions.
- key_dtype: Type of the table keys.
- value_dtype: Type of the table values.
- value_shape: The shape of each value.
- initial_num_buckets: The initial number of hash table buckets. Must be a power to 2.
- max_load_factor: The maximum ratio between number of entries and number of buckets before growing the table. Must be between 0 and 1.
Output table_handle: Handle to a table.
Declaration
public static func mutableDenseHashTableV2<KeyDtype: TensorFlowScalar>( emptyKey: Tensor<KeyDtype>, deletedKey: Tensor<KeyDtype>, container: String, sharedName: String, useNodeNameSharing: Bool = false, valueDtype: TensorDataType, valueShape: TensorShape?, initialNumBuckets: Int64 = 131072, maxLoadFactor: Double = 0.8 ) -> ResourceHandleParameters
empty_keyThe key used to represent empty key buckets internally. Must not be used in insert or lookup operations.
-
mutableHashTableOfTensorsV2(container:sharedName:useNodeNameSharing:keyDtype:valueDtype:valueShape:)
Creates an empty hash table.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a vector. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Attrs:
- container: If non-empty, this table is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this table is shared under the given name across multiple sessions.
- key_dtype: Type of the table keys.
- value_dtype: Type of the table values.
Output table_handle: Handle to a table.
Declaration
public static func mutableHashTableOfTensorsV2( container: String, sharedName: String, useNodeNameSharing: Bool = false, keyDtype: TensorDataType, valueDtype: TensorDataType, valueShape: TensorShape? ) -> ResourceHandle -
Creates an empty hash table.
This op creates a mutable hash table, specifying the type of its keys and values. Each value must be a scalar. Data can be inserted into the table using the insert operations. It does not support the initialization operation.
Attrs:
- container: If non-empty, this table is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this table is shared under the given name across multiple sessions.
- use_node_name_sharing: If true and shared_name is empty, the table is shared using the node name.
- key_dtype: Type of the table keys.
- value_dtype: Type of the table values.
Output table_handle: Handle to a table.
Declaration
public static func mutableHashTableV2( container: String, sharedName: String, useNodeNameSharing: Bool = false, keyDtype: TensorDataType, valueDtype: TensorDataType ) -> ResourceHandle -
Locks a mutex resource. The output is the lock. So long as the lock tensor
is alive, any other request to use
MutexLockwith this mutex will wait.This is particularly useful for creating a critical section when used in conjunction with
MutexLockIdentity:mutex = mutex_v2( shared_name=handle_name, container=container, name=name) def execute_in_critical_section(fn, *args, **kwargs): lock = gen_resource_variable_ops.mutex_lock(mutex) with ops.control_dependencies([lock]): r = fn(*args, **kwargs) with ops.control_dependencies(nest.flatten(r)): with ops.colocate_with(mutex): ensure_lock_exists = mutex_lock_identity(lock) # Make sure that if any element of r is accessed, all of # them are executed together. r = nest.map_structure(tf.identity, r) with ops.control_dependencies([ensure_lock_exists]): return nest.map_structure(tf.identity, r)While
fnis running in the critical section, no other functions which wish to use this critical section may run.Often the use case is that two executions of the same graph, in parallel, wish to run
fn; and we wish to ensure that only one of them executes at a time. This is especially important iffnmodifies one or more variables at a time.It is also useful if two separate functions must share a resource, but we wish to ensure the usage is exclusive.
Output mutex_lock: A tensor that keeps a shared pointer to a lock on the mutex; when the Tensor is destroyed, the use count on the shared pointer is decreased by 1. When it reaches 0, the lock is released.
Declaration
public static func mutexLock( mutex: ResourceHandle ) -> VariantHandleParameters
mutexThe mutex resource to lock.
-
Creates a Mutex resource that can be locked by
MutexLock.Attrs:
- container: If non-empty, this variable is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this variable is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
Output resource: The mutex resource.
Declaration
public static func mutexV2( container: String, sharedName: String ) -> ResourceHandle -
Declaration
public static func nInPolymorphicTwice<T: TensorFlowScalar>( _ a: [Tensor<T>], _ b: [Tensor<T>] ) -
Declaration
public static func nInTwice( _ a: [Tensor<Int32>], _ b: [StringTensor] ) -
Declaration
public static func nInTwoTypeVariables< S: TensorFlowScalar, T: TensorFlowScalar >( _ a: [Tensor<S>], _ b: [Tensor<T>] ) -
Declaration
public static func nIntsIn( _ a: [Tensor<Int32>] ) -
Declaration
public static func nIntsOut( n: Int64 ) -> [Tensor<Int32>] -
Declaration
public static func nIntsOutDefault( n: Int64 = 3 ) -> [Tensor<Int32>] -
Declaration
public static func nPolymorphicIn<T: TensorFlowScalar>( _ a: [Tensor<T>] ) -
Declaration
public static func nPolymorphicOut<T: TensorFlowScalar>( n: Int64 ) -> [Tensor<T>] -
Declaration
public static func nPolymorphicOutDefault<T: TensorFlowScalar>( n: Int64 = 2 ) -> [Tensor<T>] -
Declaration
public static func nPolymorphicRestrictIn<T: TensorFlowScalar>( _ a: [Tensor<T>] ) -
Declaration
public static func nPolymorphicRestrictIn( _ a: [StringTensor] ) -
Declaration
public static func nPolymorphicRestrictOut<T: TensorFlowScalar>( n: Int64 ) -> [Tensor<T>] -
Declaration
public static func nPolymorphicRestrictOut( n: Int64 ) -> [StringTensor] -
Declaration
public static func namespaceTestStringOutput( _ input: Tensor<Float> ) -> (output1: Tensor<Float>, output2: StringTensor) -
Outputs a tensor containing the reduction across all input tensors.
Outputs a tensor containing the reduction across all input tensors passed to ops within the same `shared_name.
The graph should be constructed so if one op runs with shared_name value
c, thennum_devicesops will run with shared_name valuec. Failure to do so will cause the graph execution to fail to complete.input: the input to the reduction data: the value of the reduction across all
num_devicesdevices. reduction: the reduction operation to perform. num_devices: The number of devices participating in this reduction. shared_name: Identifier that shared between ops of the same reduction.Declaration
public static func ncclAllReduce<T: TensorFlowNumeric>( _ input: Tensor<T>, reduction: Reduction, numDevices: Int64, sharedName: String ) -> Tensor<T> -
Sends
inputto all devices that are connected to the output.Sends
inputto all devices that are connected to the output.The graph should be constructed so that all ops connected to the output have a valid device assignment, and the op itself is assigned one of these devices.
input: The input to the broadcast. output: The same as input. shape: The shape of the input tensor.
Declaration
public static func ncclBroadcast<T: TensorFlowNumeric>( _ input: Tensor<T>, shape: TensorShape? ) -> Tensor<T> -
Reduces
inputfromnum_devicesusingreductionto a single device.Reduces
inputfromnum_devicesusingreductionto a single device.The graph should be constructed so that all inputs have a valid device assignment, and the op itself is assigned one of these devices.
input: The input to the reduction. data: the value of the reduction across all
num_devicesdevices. reduction: the reduction operation to perform.Declaration
public static func ncclReduce<T: TensorFlowNumeric>( _ input: [Tensor<T>], reduction: Reduction ) -> Tensor<T> -
Declaration
public static func ndtri<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Selects the k nearest centers for each point.
Rows of points are assumed to be input points. Rows of centers are assumed to be the list of candidate centers. For each point, the k centers that have least L2 distance to it are computed.
Outputs:
- nearest_center_indices: Matrix of shape (n, min(m, k)). Each row contains the indices of the centers closest to the corresponding point, ordered by increasing distance.
- nearest_center_distances: Matrix of shape (n, min(m, k)). Each row contains the squared L2 distance to the corresponding center in nearest_center_indices.
Declaration
Parameters
pointsMatrix of shape (n, d). Rows are assumed to be input points.
centersMatrix of shape (m, d). Rows are assumed to be centers.
kNumber of nearest centers to return for each point. If k is larger than m, then only m centers are returned.
-
Computes numerical negative value element-wise.
I.e., \(y = -x\).
Declaration
public static func neg<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Returns the next representable value of
x1in the direction ofx2, element-wise.This operation returns the same result as the C++ std::nextafter function.
It can also return a subnormal number.
@compatibility(cpp) Equivalent to C++ std::nextafter function. @end_compatibility
Declaration
public static func nextAfter<T: FloatingPoint & TensorFlowScalar>( x1: Tensor<T>, x2: Tensor<T> ) -> Tensor<T> -
Makes its input available to the next iteration.
Output output: The same tensor as
data.
Declaration
public static func nextIteration<T: TensorFlowScalar>( data: Tensor<T> ) -> Tensor<T>Parameters
dataThe tensor to be made available to the next iteration.
-
Does nothing. Only useful as a placeholder for control edges.
Declaration
public static func noOp() -
Non-deterministically generates some integers.
This op may use some OS-provided source of non-determinism (e.g. an RNG), so each execution will give different results.
Attr dtype: The type of the output.
Output output: Non-deterministic integer values with specified shape.
Declaration
public static func nonDeterministicInts< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
-
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system. Note that this algorithm is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using the
tf.gather operation. For example: selected_indices = tf.image.non_max_suppression( boxes, scores, max_output_size, iou_threshold) selected_boxes = tf.gather(boxes, selected_indices)Attr iou_threshold: A float representing the threshold for deciding whether boxes overlap too much with respect to IOU.
Output selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size.
Declaration
Parameters
boxesA 2-D float tensor of shape
[num_boxes, 4].scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
-
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system. Note that this algorithm is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm.
The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using the
tf.gather operation. For example:selected_indices = tf.image.non_max_suppression_v2( boxes, scores, max_output_size, iou_threshold) selected_boxes = tf.gather(boxes, selected_indices)
Output selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size.
Declaration
public static func nonMaxSuppressionV2< T: FloatingPoint & TensorFlowScalar, TThreshold: FloatingPoint & TensorFlowScalar >( boxes: Tensor<T>, scores: Tensor<T>, maxOutputSize: Tensor<Int32>, iouThreshold: Tensor<TThreshold> ) -> Tensor<Int32>Parameters
boxesA 2-D float tensor of shape
[num_boxes, 4].scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
iou_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too much with respect to IOU.
-
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes with score less than
score_thresholdare removed. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system and more generally is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using thetf.gather operation. For example: selected_indices = tf.image.non_max_suppression_v2( boxes, scores, max_output_size, iou_threshold, score_threshold) selected_boxes = tf.gather(boxes, selected_indices)Output selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size.
Declaration
public static func nonMaxSuppressionV3< T: FloatingPoint & TensorFlowScalar, TThreshold: FloatingPoint & TensorFlowScalar >( boxes: Tensor<T>, scores: Tensor<T>, maxOutputSize: Tensor<Int32>, iouThreshold: Tensor<TThreshold>, scoreThreshold: Tensor<TThreshold> ) -> Tensor<Int32>Parameters
boxesA 2-D float tensor of shape
[num_boxes, 4].scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
iou_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too much with respect to IOU.
score_thresholdA 0-D float tensor representing the threshold for deciding when to remove boxes based on score.
-
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes with score less than
score_thresholdare removed. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system and more generally is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using thetf.gather operation. For example: selected_indices = tf.image.non_max_suppression_v2( boxes, scores, max_output_size, iou_threshold, score_threshold) selected_boxes = tf.gather(boxes, selected_indices)Attr pad_to_max_output_size: If true, the output
selected_indicesis padded to be of lengthmax_output_size. Defaults to false.Outputs:
- selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size. - valid_outputs: A 0-D integer tensor representing the number of valid elements in
selected_indices, with the valid elements appearing first.
- selected_indices: A 1-D integer tensor of shape
Declaration
public static func nonMaxSuppressionV4< T: FloatingPoint & TensorFlowScalar, TThreshold: FloatingPoint & TensorFlowScalar >( boxes: Tensor<T>, scores: Tensor<T>, maxOutputSize: Tensor<Int32>, iouThreshold: Tensor<TThreshold>, scoreThreshold: Tensor<TThreshold>, padToMaxOutputSize: Bool = false ) -> (selectedIndices: Tensor<Int32>, validOutputs: Tensor<Int32>)Parameters
boxesA 2-D float tensor of shape
[num_boxes, 4].scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
iou_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too much with respect to IOU.
score_thresholdA 0-D float tensor representing the threshold for deciding when to remove boxes based on score.
-
nonMaxSuppressionV5(boxes:scores:maxOutputSize:iouThreshold:scoreThreshold:softNmsSigma:padToMaxOutputSize:)
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high intersection-over-union (IOU) overlap with previously selected boxes. Bounding boxes with score less than
score_thresholdare removed. Bounding boxes are supplied as [y1, x1, y2, x2], where (y1, x1) and (y2, x2) are the coordinates of any diagonal pair of box corners and the coordinates can be provided as normalized (i.e., lying in the interval [0, 1]) or absolute. Note that this algorithm is agnostic to where the origin is in the coordinate system and more generally is invariant to orthogonal transformations and translations of the coordinate system; thus translating or reflections of the coordinate system result in the same boxes being selected by the algorithm. The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using thetf.gather operation. For example: selected_indices = tf.image.non_max_suppression_v2( boxes, scores, max_output_size, iou_threshold, score_threshold) selected_boxes = tf.gather(boxes, selected_indices) This op also supports a Soft-NMS (with Gaussian weighting) mode (c.f. Bodla et al, https://arxiv.org/abs/1704.04503) where boxes reduce the score of other overlapping boxes instead of directly causing them to be pruned. To enable this Soft-NMS mode, set thesoft_nms_sigmaparameter to be larger than 0.Attr pad_to_max_output_size: If true, the output
selected_indicesis padded to be of lengthmax_output_size. Defaults to false.Outputs:
- selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size. - selected_scores: A 1-D float tensor of shape
[M]representing the corresponding scores for each selected box, whereM <= max_output_size. Scores only differ from corresponding input scores when using Soft NMS (i.e. whensoft_nms_sigma>0) - valid_outputs: A 0-D integer tensor representing the number of valid elements in
selected_indices, with the valid elements appearing first.
- selected_indices: A 1-D integer tensor of shape
Declaration
public static func nonMaxSuppressionV5<T: FloatingPoint & TensorFlowScalar>( boxes: Tensor<T>, scores: Tensor<T>, maxOutputSize: Tensor<Int32>, iouThreshold: Tensor<T>, scoreThreshold: Tensor<T>, softNmsSigma: Tensor<T>, padToMaxOutputSize: Bool = false ) -> (selectedIndices: Tensor<Int32>, selectedScores: Tensor<T>, validOutputs: Tensor<Int32>)Parameters
boxesA 2-D float tensor of shape
[num_boxes, 4].scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
iou_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too much with respect to IOU.
score_thresholdA 0-D float tensor representing the threshold for deciding when to remove boxes based on score.
soft_nms_sigmaA 0-D float tensor representing the sigma parameter for Soft NMS; see Bodla et al (c.f. https://arxiv.org/abs/1704.04503). When
soft_nms_sigma=0.0(which is default), we fall back to standard (hard) NMS. -
Greedily selects a subset of bounding boxes in descending order of score,
pruning away boxes that have high overlaps with previously selected boxes. Bounding boxes with score less than
score_thresholdare removed. N-by-n overlap values are supplied as square matrix, which allows for defining a custom overlap criterium (eg. intersection over union, intersection over area, etc.).The output of this operation is a set of integers indexing into the input collection of bounding boxes representing the selected boxes. The bounding box coordinates corresponding to the selected indices can then be obtained using the
tf.gather operation. For example:selected_indices = tf.image.non_max_suppression_with_overlaps( overlaps, scores, max_output_size, overlap_threshold, score_threshold) selected_boxes = tf.gather(boxes, selected_indices)
Output selected_indices: A 1-D integer tensor of shape
[M]representing the selected indices from the boxes tensor, whereM <= max_output_size.
Declaration
Parameters
overlapsA 2-D float tensor of shape
[num_boxes, num_boxes]representing the n-by-n box overlap values.scoresA 1-D float tensor of shape
[num_boxes]representing a single score corresponding to each box (each row of boxes).max_output_sizeA scalar integer tensor representing the maximum number of boxes to be selected by non max suppression.
overlap_thresholdA 0-D float tensor representing the threshold for deciding whether boxes overlap too.
score_thresholdA 0-D float tensor representing the threshold for deciding when to remove boxes based on score.
-
Declaration
public static func nonSerializableDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Declaration
public static func none() -
Returns the truth value of (x != y) element-wise.
NOTE:
NotEqualsupports broadcasting. More about broadcasting hereDeclaration
public static func notEqual<T: TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T>, incompatibleShapeError: Bool = true ) -> Tensor<Bool> -
Returns the truth value of (x != y) element-wise.
NOTE:
NotEqualsupports broadcasting. More about broadcasting hereDeclaration
public static func notEqual( _ x: StringTensor, _ y: StringTensor, incompatibleShapeError: Bool = true ) -> Tensor<Bool> -
Finds values of the
n-th order statistic for the last dimension.If the input is a vector (rank-1), finds the entries which is the nth-smallest value in the vector and outputs their values as scalar tensor.
For matrices (resp. higher rank input), computes the entries which is the nth-smallest value in each row (resp. vector along the last dimension). Thus,
values.shape = input.shape[:-1]Attr reverse: When set to True, find the nth-largest value in the vector and vice versa.
Output values: The
n-th order statistic along each last dimensional slice.
Declaration
public static func nthElement<T: TensorFlowNumeric>( _ input: Tensor<T>, n: Tensor<Int32>, reverse: Bool = false ) -> Tensor<T>Parameters
input1-D or higher with last dimension at least
n+1.n0-D. Position of sorted vector to select along the last dimension (along each row for matrices). Valid range of n is
[0, input.shape[:-1]) -
Declaration
public static func old() -
Returns a one-hot tensor.
The locations represented by indices in
indicestake valueon_value, while all other locations take valueoff_value.If the input
indicesis rankN, the output will have rankN+1, The new axis is created at dimensionaxis(default: the new axis is appended at the end).If
indicesis a scalar the output shape will be a vector of lengthdepth.If
indicesis a vector of lengthfeatures, the output shape will be:features x depth if axis == -1 depth x features if axis == 0If
indicesis a matrix (batch) with shape[batch, features], the output shape will be:batch x features x depth if axis == -1 batch x depth x features if axis == 1 depth x batch x features if axis == 0Examples
Suppose that
indices = [0, 2, -1, 1] depth = 3 on_value = 5.0 off_value = 0.0 axis = -1Then output is
[4 x 3]:output = [5.0 0.0 0.0] // one_hot(0) [0.0 0.0 5.0] // one_hot(2) [0.0 0.0 0.0] // one_hot(-1) [0.0 5.0 0.0] // one_hot(1)Suppose that
indices = [0, 2, -1, 1] depth = 3 on_value = 0.0 off_value = 3.0 axis = 0Then output is
[3 x 4]:output = [0.0 3.0 3.0 3.0] [3.0 3.0 3.0 0.0] [3.0 3.0 3.0 3.0] [3.0 0.0 3.0 3.0] // ^ one_hot(0) // ^ one_hot(2) // ^ one_hot(-1) // ^ one_hot(1)Suppose that
indices = [[0, 2], [1, -1]] depth = 3 on_value = 1.0 off_value = 0.0 axis = -1Then output is
[2 x 2 x 3]:output = [ [1.0, 0.0, 0.0] // one_hot(0) [0.0, 0.0, 1.0] // one_hot(2) ][ [0.0, 1.0, 0.0] // one_hot(1) [0.0, 0.0, 0.0] // one_hot(-1) ]Attr axis: The axis to fill (default: -1, a new inner-most axis).
Output output: The one-hot tensor.
Declaration
public static func oneHot< T: TensorFlowScalar, Ti: TensorFlowInteger >( indices: Tensor<Ti>, depth: Tensor<Int32>, onValue: Tensor<T>, offValue: Tensor<T>, axis: Int64 = -1 ) -> Tensor<T>Parameters
indicesA tensor of indices.
depthA scalar defining the depth of the one hot dimension.
on_valueA scalar defining the value to fill in output when
indices[j] = i.off_valueA scalar defining the value to fill in output when
indices[j] != i. -
Makes a “one-shot” iterator that can be iterated only once.
A one-shot iterator bundles the logic for defining the dataset and the state of the iterator in a single op, which allows simple input pipelines to be defined without an additional initialization (“MakeIterator”) step.
One-shot iterators have the following limitations:
- They do not support parameterization: all logic for creating the underlying
dataset must be bundled in the
dataset_factoryfunction. - They are not resettable. Once a one-shot iterator reaches the end of its
underlying dataset, subsequent “IteratorGetNext” operations on that
iterator will always produce an
OutOfRangeerror.
For greater flexibility, use “Iterator” and “MakeIterator” to define an iterator using an arbitrary subgraph, which may capture tensors (including fed values) as parameters, and which may be reset multiple times by rerunning “MakeIterator”.
Attr dataset_factory: A function of type
() -> DT_VARIANT, where the returned DT_VARIANT is a dataset.Output handle: A handle to the iterator that can be passed to an “IteratorGetNext” op.
Declaration
public static func oneShotIterator< DatasetfactoryIn: TensorGroup, DatasetfactoryOut: TensorGroup >( datasetFactory: (DatasetfactoryIn) -> DatasetfactoryOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], container: String, sharedName: String ) -> ResourceHandle - They do not support parameterization: all logic for creating the underlying
dataset must be bundled in the
-
Returns a tensor of ones with the same shape and type as x.
Output y: a tensor of the same shape and type as x but filled with ones.
Declaration
public static func onesLike<T: TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T>Parameters
xa tensor of type T.
-
Declaration
public static func opWithDefaultAttr( defaultFloat: Double = 123 ) -> Tensor<Int32> -
Declaration
public static func opWithFutureDefaultAttr() -
Creates a dataset by applying optimizations to
input_dataset.Creates a dataset by applying optimizations to
input_dataset.Declaration
public static func optimizeDataset( inputDataset: VariantHandle, optimizations: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?], optimizationConfigs: [String] ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
optimizationsA
tf.stringvectortf.Tensoridentifying optimizations to use. -
Constructs an Optional variant from a tuple of tensors.
Declaration
public static func optionalFromValue<ToutputTypes: TensorArrayProtocol>( components: ToutputTypes ) -> VariantHandle -
Returns the value stored in an Optional variant or raises an error if none exists.
Declaration
public static func optionalGetValue<OutputTypes: TensorGroup>( optional: VariantHandle, outputShapes: [TensorShape?] ) -> OutputTypes -
Returns true if and only if the given Optional variant has a value.
Declaration
public static func optionalHasValue( optional: VariantHandle ) -> Tensor<Bool> -
Creates an Optional variant with no value.
Declaration
public static func optionalNone() -> VariantHandle -
Op removes all elements in the underlying container.
Declaration
public static func orderedMapClear( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -
Op returns the number of incomplete elements in the underlying container.
Declaration
public static func orderedMapIncompleteSize( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -> Tensor<Int32> -
Op peeks at the values at the specified key. If the
underlying container does not contain this key this op will block until it does. This Op is optimized for performance.
Declaration
public static func orderedMapPeek<Dtypes: TensorGroup>( key: Tensor<Int64>, indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Op returns the number of elements in the underlying container.
Declaration
public static func orderedMapSize( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -> Tensor<Int32> -
Stage (key, values) in the underlying container which behaves like a ordered
associative container. Elements are ordered by key.
Attrs:
- capacity: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: It is necessary to match this name to the matching Unstage Op.
Declaration
public static func orderedMapStage<FakeDtypes: TensorArrayProtocol>( key: Tensor<Int64>, indices: Tensor<Int32>, _ values: FakeDtypes, capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String )Parameters
keyint64
valuesa list of tensors dtypes A list of data types that inserted values should adhere to.
-
Op removes and returns the values associated with the key
from the underlying container. If the underlying container does not contain this key, the op will block until it does.
Declaration
public static func orderedMapUnstage<Dtypes: TensorGroup>( key: Tensor<Int64>, indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Op removes and returns the (key, value) element with the smallest
key from the underlying container. If the underlying container does not contain elements, the op will block until it does.
Declaration
public static func orderedMapUnstageNoKey<Dtypes: TensorGroup>( indices: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> (key: Tensor<Int64>, values: Dtypes) -
Declaration
public static func outT<T>() -> Tensor<T> where T : TensorFlowScalar -
Declaration
public static func outTypeList<T>() -> T where T : TensorGroup -
Declaration
public static func outTypeListRestrict<T>() -> T where T : TensorGroup -
Retrieves a single tensor from the computation outfeed.
This operation will block indefinitely until data is available.
Attrs:
- dtype: The type of elements in the tensor.
- shape: The shape of the tensor.
- device_ordinal: The TPU device to use. This should be -1 when the Op is running on a TPU device, and >= 0 when the Op is running on the CPU device.
Output output: A tensor that will be read from the device outfeed.
Declaration
public static func outfeedDequeue<Dtype: TensorFlowScalar>( shape: TensorShape?, deviceOrdinal: Int64 = -1 ) -> Tensor<Dtype> -
Retrieve multiple values from the computation outfeed.
This operation will block indefinitely until data is available. Output
icorresponds to XLA tuple elementi.Attrs:
- dtypes: The element types of each element in
outputs. - shapes: The shapes of each tensor in
outputs. - device_ordinal: The TPU device to use. This should be -1 when the Op is running on a TPU device, and >= 0 when the Op is running on the CPU device.
- dtypes: The element types of each element in
Output outputs: A list of tensors that will be read from the outfeed.
Declaration
public static func outfeedDequeueTuple<Dtypes: TensorGroup>( shapes: [TensorShape?], deviceOrdinal: Int64 = -1 ) -> Dtypes -
Enqueue a Tensor on the computation outfeed.
Declaration
public static func outfeedEnqueue<Dtype: TensorFlowScalar>( _ input: Tensor<Dtype> )Parameters
inputA tensor that will be inserted into the outfeed queue.
-
Enqueue multiple Tensor values on the computation outfeed.
Declaration
public static func outfeedEnqueueTuple<Dtypes: TensorArrayProtocol>( inputs: Dtypes )Parameters
inputsA list of tensors that will be inserted into the outfeed queue as an XLA tuple.
-
Packs a list of
Nrank-Rtensors into one rank-(R+1)tensor.Packs the
Ntensors invaluesinto a tensor with rank one higher than each tensor invalues, by packing them along theaxisdimension. Given a list of tensors of shape(A, B, C);if
axis == 0then theoutputtensor will have the shape(N, A, B, C). ifaxis == 1then theoutputtensor will have the shape(A, N, B, C). Etc.For example:
# 'x' is [1, 4] # 'y' is [2, 5] # 'z' is [3, 6] pack([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim. pack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]]This is the opposite of
unpack.Attr axis: Dimension along which to pack. Negative values wrap around, so the valid range is
[-(R+1), R+1).Output output: The packed tensor.
Declaration
public static func pack<T: TensorFlowScalar>( _ values: [Tensor<T>], axis: Int64 = 0 ) -> Tensor<T>Parameters
valuesMust be of same shape and type.
-
Pads a tensor with zeros.
This operation pads a
inputwith zeros according to thepaddingsyou specify.paddingsis an integer tensor with shape[Dn, 2], where n is the rank ofinput. For each dimension D ofinput,paddings[D, 0]indicates how many zeros to add before the contents ofinputin that dimension, andpaddings[D, 1]indicates how many zeros to add after the contents ofinputin that dimension.The padded size of each dimension D of the output is:
paddings(D, 0) + input.dim_size(D) + paddings(D, 1)For example:
# 't' is [[1, 1], [2, 2]] # 'paddings' is [[1, 1], [2, 2]] # rank of 't' is 2 pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0] [0, 0, 1, 1, 0, 0] [0, 0, 2, 2, 0, 0] [0, 0, 0, 0, 0, 0]]Declaration
public static func pad< T: TensorFlowScalar, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, paddings: Tensor<Tpaddings> ) -> Tensor<T> -
Pads a tensor.
This operation pads
inputaccording to thepaddingsandconstant_valuesyou specify.paddingsis an integer tensor with shape[Dn, 2], where n is the rank ofinput. For each dimension D ofinput,paddings[D, 0]indicates how many padding values to add before the contents ofinputin that dimension, andpaddings[D, 1]indicates how many padding values to add after the contents ofinputin that dimension.constant_valuesis a scalar tensor of the same type asinputthat indicates the value to use for paddinginput.The padded size of each dimension D of the output is:
paddings(D, 0) + input.dim_size(D) + paddings(D, 1)For example:
# 't' is [[1, 1], [2, 2]] # 'paddings' is [[1, 1], [2, 2]] # 'constant_values' is 0 # rank of 't' is 2 pad(t, paddings) ==> [[0, 0, 0, 0, 0, 0] [0, 0, 1, 1, 0, 0] [0, 0, 2, 2, 0, 0] [0, 0, 0, 0, 0, 0]]Declaration
public static func padV2< T: TensorFlowScalar, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, paddings: Tensor<Tpaddings>, constantValues: Tensor<T> ) -> Tensor<T> -
Creates a dataset that batches and pads
batch_sizeelements from the input.Declaration
public static func paddedBatchDataset<ToutputTypes: TensorArrayProtocol>( inputDataset: VariantHandle, batchSize: Tensor<Int64>, paddedShapes: [Tensor<Int64>], paddingValues: ToutputTypes, outputShapes: [TensorShape?] ) -> VariantHandleParameters
batch_sizeA scalar representing the number of elements to accumulate in a batch.
padded_shapesA list of int64 tensors representing the desired padded shapes of the corresponding output components. These shapes may be partially specified, using
-1to indicate that a particular dimension should be padded to the maximum size of all batch elements.padding_valuesA list of scalars containing the padding value to use for each of the outputs.
-
paddedBatchDatasetV2(inputDataset:batchSize:paddedShapes:paddingValues:dropRemainder:parallelCopy:outputShapes:)
Creates a dataset that batches and pads
batch_sizeelements from the input.Declaration
public static func paddedBatchDatasetV2<ToutputTypes: TensorArrayProtocol>( inputDataset: VariantHandle, batchSize: Tensor<Int64>, paddedShapes: [Tensor<Int64>], paddingValues: ToutputTypes, dropRemainder: Tensor<Bool>, parallelCopy: Bool = false, outputShapes: [TensorShape?] ) -> VariantHandleParameters
batch_sizeA scalar representing the number of elements to accumulate in a batch.
padded_shapesA list of int64 tensors representing the desired padded shapes of the corresponding output components. These shapes may be partially specified, using
-1to indicate that a particular dimension should be padded to the maximum size of all batch elements.padding_valuesA list of scalars containing the padding value to use for each of the outputs.
drop_remainderA scalar representing whether the last batch should be dropped in case its size is smaller than desired.
-
A queue that produces elements in first-in first-out order.
Variable-size shapes are allowed by setting the corresponding shape dimensions to 0 in the shape attr. In this case DequeueMany will pad up to the maximum size of any given element in the minibatch. See below for details.
Attrs:
- component_types: The type of each component in a value.
- shapes: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. Shapes of fixed rank but variable size are allowed by setting any shape dimension to -1. In this case, the inputs’ shape may vary along the given dimension, and DequeueMany will pad the given dimension with zeros up to the maximum shape of all elements in the given batch. If the length of this attr is 0, different queue elements may have different ranks and shapes, but only one element may be dequeued at a time.
- capacity: The upper bound on the number of elements in this queue. Negative numbers mean no limit.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this queue will be shared under the given name across multiple sessions.
Output handle: The handle to the queue.
Declaration
public static func paddingFIFOQueueV2( componentTypes: [TensorDataType], shapes: [TensorShape?], capacity: Int64 = -1, container: String, sharedName: String ) -> ResourceHandle -
Concatenates a list of
Ntensors along the first dimension.The input tensors are all required to have size 1 in the first dimension.
For example:
# 'x' is [[1, 4]] # 'y' is [[2, 5]] # 'z' is [[3, 6]] parallel_concat([x, y, z]) => [[1, 4], [2, 5], [3, 6]] # Pack along first dim.The difference between concat and parallel_concat is that concat requires all of the inputs be computed before the operation will begin but doesn’t require that the input shapes be known during graph construction. Parallel concat will copy pieces of the input into the output as they become available, in some situations this can provide a performance benefit.
Attr shape: the final shape of the result; should be equal to the shapes of any input but with the number of input values in the first dimension.
Output output: The concatenated tensor.
Declaration
public static func parallelConcat<T: TensorFlowScalar>( _ values: [Tensor<T>], shape: TensorShape? ) -> Tensor<T>Parameters
valuesTensors to be concatenated. All must have size 1 in the first dimension and same shape.
-
Interleave the values from the
datatensors into a single tensor.Builds a merged tensor such that
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]For example, if each
indices[m]is scalar or vector, we have# Scalar indices: merged[indices[m], ...] = data[m][...] # Vector indices: merged[indices[m][i], ...] = data[m][i, ...]Each
data[i].shapemust start with the correspondingindices[i].shape, and the rest ofdata[i].shapemust be constant w.r.t.i. That is, we must havedata[i].shape = indices[i].shape + constant. In terms of thisconstant, the output shape ismerged.shape = [max(indices)] + constantValues may be merged in parallel, so if an index appears in both
indices[m][i]andindices[n][j], the result may be invalid. This differs from the normal DynamicStitch operator that defines the behavior in that case.For example:
indices[0] = 6 indices[1] = [4, 1] indices[2] = [[5, 2], [0, 3]] data[0] = [61, 62] data[1] = [[41, 42], [11, 12]] data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]] merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42], [51, 52], [61, 62]]This method can be used to merge partitions created by
dynamic_partitionas illustrated on the following example:# Apply function (increments x_i) on elements for which a certain condition # apply (x_i != -1 in this example). x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4]) condition_mask=tf.not_equal(x,tf.constant(-1.)) partitioned_data = tf.dynamic_partition( x, tf.cast(condition_mask, tf.int32) , 2) partitioned_data[1] = partitioned_data[1] + 1.0 condition_indices = tf.dynamic_partition( tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2) x = tf.dynamic_stitch(condition_indices, partitioned_data) # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain # unchanged.
Declaration
public static func parallelDynamicStitch<T: TensorFlowScalar>( indices: [Tensor<Int32>], data: [Tensor<T>] ) -> Tensor<T> -
parallelInterleaveDataset(inputDataset:otherArguments:cycleLength:blockLength:sloppy:bufferOutputElements:prefetchInputElements:f:outputTypes:outputShapes:)
Creates a dataset that applies
fto the outputs ofinput_dataset.The resulting dataset is similar to the
InterleaveDataset, with the exception that if retrieving the next value from a dataset would cause the requester to block, it will skip that input dataset. This dataset is especially useful when loading data from a variable-latency datastores (e.g. HDFS, GCS), as it allows the training step to proceed so long as some data is available.!! WARNING !! If the
sloppyparameter is set toTrue, the operation of this dataset will not be deterministic!This dataset has been superseded by
ParallelInterleaveDatasetV2. New code should useParallelInterleaveDatasetV2.The Python API
tf.data.experimental.parallel_interleavecreates instances of this op.tf.data.experimental.parallel_interleaveis a deprecated API.Attrs:
- f: A function mapping elements of
input_dataset, concatenated withother_arguments, to a Dataset variant that contains elements matchingoutput_typesandoutput_shapes. - Targuments: Types of the elements of
other_arguments.
- f: A function mapping elements of
Declaration
public static func parallelInterleaveDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, cycleLength: Tensor<Int64>, blockLength: Tensor<Int64>, sloppy: Tensor<Bool>, bufferOutputElements: Tensor<Int64>, prefetchInputElements: Tensor<Int64>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetDataset that produces a stream of arguments for the function
f.other_argumentsAdditional arguments to pass to
fbeyond those produced byinput_dataset. Evaluated once when the dataset is instantiated.cycle_lengthNumber of datasets (each created by applying
fto the elements ofinput_dataset) among which theParallelInterleaveDatasetwill cycle in a round-robin fashion.block_lengthNumber of elements at a time to produce from each interleaved invocation of a dataset returned by
f.sloppyIf
True, return elements as they become available, even if that means returning these elements in a non-deterministic order. Sloppy operation may result in better performance in the presence of stragglers, but the dataset will still block if all of its open streams are blocked. IfFalse, always return elements in a deterministic order.buffer_output_elementsThe number of elements each iterator being interleaved should buffer (similar to the
.prefetch()transformation for each interleaved iterator).prefetch_input_elementsDetermines the number of iterators to prefetch, allowing buffers to warm up and data to be pre-fetched without blocking the main thread.
-
parallelInterleaveDatasetV2(inputDataset:otherArguments:cycleLength:blockLength:numParallelCalls:f:outputTypes:outputShapes:sloppy:)
Creates a dataset that applies
fto the outputs ofinput_dataset.The resulting dataset is similar to the
InterleaveDataset, except that the dataset will fetch records from the interleaved datasets in parallel.The
tf.dataPython API creates instances of this op fromDataset.interleave()when thenum_parallel_callsparameter of that method is set to any value other thanNone.By default, the output of this dataset will be deterministic, which may result in the dataset blocking if the next data item to be returned isn’t available. In order to avoid head-of-line blocking, one can set the
experimental_deterministicparameter oftf.data.OptionstoFalse, which can improve performance at the expense of non-determinism.Attrs:
- f: A function mapping elements of
input_dataset, concatenated withother_arguments, to a Dataset variant that contains elements matchingoutput_typesandoutput_shapes. - Targuments: Types of the elements of
other_arguments.
- f: A function mapping elements of
Declaration
public static func parallelInterleaveDatasetV2< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, cycleLength: Tensor<Int64>, blockLength: Tensor<Int64>, numParallelCalls: Tensor<Int64>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], sloppy: Bool = false ) -> VariantHandleParameters
input_datasetDataset that produces a stream of arguments for the function
f.other_argumentsAdditional arguments to pass to
fbeyond those produced byinput_dataset. Evaluated once when the dataset is instantiated.cycle_lengthNumber of datasets (each created by applying
fto the elements ofinput_dataset) among which theParallelInterleaveDatasetV2will cycle in a round-robin fashion.block_lengthNumber of elements at a time to produce from each interleaved invocation of a dataset returned by
f.num_parallel_callsDetermines the number of threads that should be used for fetching data from input datasets in parallel. The Python API
tf.data.experimental.AUTOTUNEconstant can be used to indicate that the level of parallelism should be autotuned. -
parallelMapDataset(inputDataset:otherArguments:numParallelCalls:f:outputTypes:outputShapes:useInterOpParallelism:sloppy:preserveCardinality:)
Creates a dataset that applies
fto the outputs ofinput_dataset.Unlike a “MapDataset”, which applies
fsequentially, this dataset invokes up tonum_parallel_callscopies offin parallel.Declaration
public static func parallelMapDataset< FIn: TensorGroup, FOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, numParallelCalls: Tensor<Int32>, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], useInterOpParallelism: Bool = true, sloppy: Bool = false, preserveCardinality: Bool = false ) -> VariantHandleParameters
num_parallel_callsThe number of concurrent invocations of
fthat process elements frominput_datasetin parallel. -
Outputs random values from a normal distribution. The parameters may each be a
scalar which applies to the entire output, or a vector of length shape[0] which stores the parameters for each batch.
Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- dtype: The type of the output.
- seed: If either
Output output: A matrix of shape num_batches x samples_per_batch, filled with random truncated normal values using the parameters for each row.
Declaration
public static func parameterizedTruncatedNormal< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex >( shape: Tensor<T>, means: Tensor<Dtype>, stdevs: Tensor<Dtype>, minvals: Tensor<Dtype>, maxvals: Tensor<Dtype>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor. Batches are indexed by the 0th dimension.
meansThe mean parameter of each batch.
stdevsThe standard deviation parameter of each batch. Must be greater than 0.
minvalsThe minimum cutoff. May be -infinity.
maxvalsThe maximum cutoff. May be +infinity, and must be more than the minval for each batch.
-
Transforms a vector of brain.Example protos (as strings) into typed tensors.
Attrs:
- sparse_types: A list of Nsparse types; the data types of data in each Feature given in sparse_keys. Currently the ParseExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- dense_shapes: A list of Ndense shapes; the shapes of data in each Feature given in dense_keys. The number of elements in the Feature corresponding to dense_key[j] must always equal dense_shapes[j].NumEntries(). If dense_shapes[j] == (D0, D1, …, DN) then the shape of output Tensor dense_values[j] will be (|serialized|, D0, D1, …, DN): The dense outputs are just the inputs row-stacked by batch. This works for dense_shapes[j] = (-1, D1, …, DN). In this case the shape of the output Tensor dense_values[j] will be (|serialized|, M, D1, .., DN), where M is the maximum number of blocks of elements of length D1 * …. * DN, across all minibatch entries in the input. Any minibatch entry with less than M blocks of elements of length D1 * … * DN will be padded with the corresponding default_value scalar element along the second dimension.
Declaration
public static func parseExample< SparseTypes: TensorGroup, Tdense: TensorArrayProtocol >( serialized: StringTensor, names: StringTensor, sparseKeys: [StringTensor], denseKeys: [StringTensor], denseDefaults: Tdense, denseShapes: [TensorShape?] ) -> ( sparseIndices: [Tensor<Int64>], sparseValues: SparseTypes, sparseShapes: [Tensor<Int64>], denseValues: Tdense )Parameters
serializedA vector containing a batch of binary serialized Example protos.
namesA vector containing the names of the serialized protos. May contain, for example, table key (descriptive) names for the corresponding serialized protos. These are purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty vector if no names are available. If non-empty, this vector must be the same length as “serialized”.
sparse_keysA list of Nsparse string Tensors (scalars). The keys expected in the Examples’ features associated with sparse values.
dense_keysA list of Ndense string Tensors (scalars). The keys expected in the Examples’ features associated with dense values.
dense_defaultsA list of Ndense Tensors (some may be empty). dense_defaults[j] provides default values when the example’s feature_map lacks dense_key[j]. If an empty Tensor is provided for dense_defaults[j], then the Feature dense_keys[j] is required. The input type is inferred from dense_defaults[j], even when it’s empty. If dense_defaults[j] is not empty, and dense_shapes[j] is fully defined, then the shape of dense_defaults[j] must match that of dense_shapes[j]. If dense_shapes[j] has an undefined major dimension (variable strides dense feature), dense_defaults[j] must contain a single element: the padding element.
-
parseExampleDataset(inputDataset:numParallelCalls:denseDefaults:sparseKeys:denseKeys:sparseTypes:denseShapes:outputTypes:outputShapes:sloppy:raggedKeys:raggedValueTypes:raggedSplitTypes:)
Transforms
input_datasetcontainingExampleprotos as vectors of DT_STRING into a dataset ofTensororSparseTensorobjects representing the parsed features.Attrs:
- sparse_keys: A list of string keys in the examples features.
The results for these keys will be returned as
SparseTensorobjects. - dense_keys: A list of Ndense string Tensors (scalars). The keys expected in the Examples features associated with dense values.
- sparse_types: A list of
DTypesof the same length assparse_keys. Onlytf.float32(FloatList),tf.int64(Int64List), andtf.string(BytesList) are supported. - Tdense: A list of DTypes of the same length as
dense_keys. Onlytf.float32(FloatList),tf.int64(Int64List), andtf.string(BytesList) are supported. - dense_shapes: List of tuples with the same length as
dense_keys. The shape of the data for each dense feature referenced bydense_keys. Required for any input tensors identified bydense_keys. Must be either fully defined, or may contain an unknown first dimension. An unknown first dimension means the feature is treated as having a variable number of blocks, and the output shape along this dimension is considered unknown at graph build time. Padding is applied for minibatch elements smaller than the maximum number of blocks for the given feature along this dimension. - output_types: The type list for the return values.
- output_shapes: The list of shapes being produced.
- sparse_keys: A list of string keys in the examples features.
The results for these keys will be returned as
Declaration
public static func parseExampleDataset<Tdense: TensorArrayProtocol>( inputDataset: VariantHandle, numParallelCalls: Tensor<Int64>, denseDefaults: Tdense, sparseKeys: [String], denseKeys: [String], sparseTypes: [TensorDataType], denseShapes: [TensorShape?], outputTypes: [TensorDataType], outputShapes: [TensorShape?], sloppy: Bool = false, raggedKeys: [String], raggedValueTypes: [TensorDataType], raggedSplitTypes: [TensorDataType] ) -> VariantHandleParameters
dense_defaultsA dict mapping string keys to
Tensors. The keys of the dict must match the dense_keys of the feature. -
parseExampleV2(serialized:names:sparseKeys:denseKeys:raggedKeys:denseDefaults:numSparse:denseShapes:)
Transforms a vector of tf.Example protos (as strings) into typed tensors.
Attrs:
- num_sparse: The number of sparse keys.
- sparse_types: A list of
num_sparsetypes; the data types of data in each Feature given in sparse_keys. Currently the ParseExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). - ragged_value_types: A list of
num_raggedtypes; the data types of data in each Feature given in ragged_keys (wherenum_ragged = sparse_keys.size()). Currently the ParseExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). - ragged_split_types: A list of
num_raggedtypes; the data types of row_splits in each Feature given in ragged_keys (wherenum_ragged = sparse_keys.size()). May be DT_INT32 or DT_INT64. - dense_shapes: A list of
num_denseshapes; the shapes of data in each Feature given in dense_keys (wherenum_dense = dense_keys.size()). The number of elements in the Feature corresponding to dense_key[j] must always equal dense_shapes[j].NumEntries(). If dense_shapes[j] == (D0, D1, …, DN) then the shape of output Tensor dense_values[j] will be (|serialized|, D0, D1, …, DN): The dense outputs are just the inputs row-stacked by batch. This works for dense_shapes[j] = (-1, D1, …, DN). In this case the shape of the output Tensor dense_values[j] will be (|serialized|, M, D1, .., DN), where M is the maximum number of blocks of elements of length D1 * …. * DN, across all minibatch entries in the input. Any minibatch entry with less than M blocks of elements of length D1 * … * DN will be padded with the corresponding default_value scalar element along the second dimension.
Declaration
public static func parseExampleV2< Tdense: TensorArrayProtocol, SparseTypes: TensorGroup, RaggedValueTypes: TensorGroup, RaggedSplitTypes: TensorGroup >( serialized: StringTensor, names: StringTensor, sparseKeys: StringTensor, denseKeys: StringTensor, raggedKeys: StringTensor, denseDefaults: Tdense, numSparse: Int64, denseShapes: [TensorShape?] ) -> ( sparseIndices: [Tensor<Int64>], sparseValues: SparseTypes, sparseShapes: [Tensor<Int64>], denseValues: Tdense, raggedValues: RaggedValueTypes, raggedRowSplits: RaggedSplitTypes )Parameters
serializedA scalar or vector containing binary serialized Example protos.
namesA tensor containing the names of the serialized protos. Corresponds 1:1 with the
serializedtensor. May contain, for example, table key (descriptive) names for the corresponding serialized protos. These are purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty vector if no names are available. If non-empty, this tensor must have the same shape as “serialized”.sparse_keysVector of strings. The keys expected in the Examples’ features associated with sparse values.
dense_keysVector of strings. The keys expected in the Examples’ features associated with dense values.
ragged_keysVector of strings. The keys expected in the Examples’ features associated with ragged values.
dense_defaultsA list of Tensors (some may be empty). Corresponds 1:1 with
dense_keys. dense_defaults[j] provides default values when the example’s feature_map lacks dense_key[j]. If an empty Tensor is provided for dense_defaults[j], then the Feature dense_keys[j] is required. The input type is inferred from dense_defaults[j], even when it’s empty. If dense_defaults[j] is not empty, and dense_shapes[j] is fully defined, then the shape of dense_defaults[j] must match that of dense_shapes[j]. If dense_shapes[j] has an undefined major dimension (variable strides dense feature), dense_defaults[j] must contain a single element: the padding element. -
parseSequenceExample(serialized:debugName:contextDenseDefaults:featureListDenseMissingAssumedEmpty:contextSparseKeys:contextDenseKeys:featureListSparseKeys:featureListDenseKeys:ncontextSparse:ncontextDense:nfeatureListSparse:nfeatureListDense:contextDenseShapes:featureListDenseShapes:)
Transforms a vector of brain.SequenceExample protos (as strings) into typed tensors.
Attrs:
- feature_list_dense_missing_assumed_empty: A vector listing the FeatureList keys which may be missing from the SequenceExamples. If the associated FeatureList is missing, it is treated as empty. By default, any FeatureList not listed in this vector must exist in the SequenceExamples.
- context_sparse_keys: A list of Ncontext_sparse string Tensors (scalars). The keys expected in the Examples’ features associated with context_sparse values.
- context_dense_keys: A list of Ncontext_dense string Tensors (scalars). The keys expected in the SequenceExamples’ context features associated with dense values.
- feature_list_sparse_keys: A list of Nfeature_list_sparse string Tensors (scalars). The keys expected in the FeatureLists associated with sparse values.
- feature_list_dense_keys: A list of Nfeature_list_dense string Tensors (scalars). The keys expected in the SequenceExamples’ feature_lists associated with lists of dense values.
- context_sparse_types: A list of Ncontext_sparse types; the data types of data in each context Feature given in context_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- context_dense_shapes: A list of Ncontext_dense shapes; the shapes of data in each context Feature given in context_dense_keys. The number of elements in the Feature corresponding to context_dense_key[j] must always equal context_dense_shapes[j].NumEntries(). The shape of context_dense_values[j] will match context_dense_shapes[j].
- feature_list_sparse_types: A list of Nfeature_list_sparse types; the data types of data in each FeatureList given in feature_list_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- feature_list_dense_shapes: A list of Nfeature_list_dense shapes; the shapes of data in each FeatureList given in feature_list_dense_keys. The shape of each Feature in the FeatureList corresponding to feature_list_dense_key[j] must always equal feature_list_dense_shapes[j].NumEntries().
Declaration
public static func parseSequenceExample< ContextSparseTypes: TensorGroup, TcontextDense: TensorArrayProtocol, FeatureListDenseTypes: TensorGroup, FeatureListSparseTypes: TensorGroup >( serialized: StringTensor, debugName: StringTensor, contextDenseDefaults: TcontextDense, featureListDenseMissingAssumedEmpty: [String], contextSparseKeys: [String], contextDenseKeys: [String], featureListSparseKeys: [String], featureListDenseKeys: [String], ncontextSparse: Int64 = 0, ncontextDense: Int64 = 0, nfeatureListSparse: Int64 = 0, nfeatureListDense: Int64 = 0, contextDenseShapes: [TensorShape?], featureListDenseShapes: [TensorShape?] ) -> ( contextSparseIndices: [Tensor<Int64>], contextSparseValues: ContextSparseTypes, contextSparseShapes: [Tensor<Int64>], contextDenseValues: TcontextDense, featureListSparseIndices: [Tensor<Int64>], featureListSparseValues: FeatureListSparseTypes, featureListSparseShapes: [Tensor<Int64>], featureListDenseValues: FeatureListDenseTypes, featureListDenseLengths: [Tensor<Int64>] )Parameters
serializedA vector containing binary serialized SequenceExample protos.
debug_nameA vector containing the names of the serialized protos. May contain, for example, table key (descriptive) name for the corresponding serialized proto. This is purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty vector if no name is available.
context_dense_defaultsA list of Ncontext_dense Tensors (some may be empty). context_dense_defaults[j] provides default values when the SequenceExample’s context map lacks context_dense_key[j]. If an empty Tensor is provided for context_dense_defaults[j], then the Feature context_dense_keys[j] is required. The input type is inferred from context_dense_defaults[j], even when it’s empty. If context_dense_defaults[j] is not empty, its shape must match context_dense_shapes[j].
-
parseSequenceExampleV2(serialized:debugName:contextSparseKeys:contextDenseKeys:contextRaggedKeys:featureListSparseKeys:featureListDenseKeys:featureListRaggedKeys:featureListDenseMissingAssumedEmpty:contextDenseDefaults:ncontextSparse:contextDenseShapes:nfeatureListSparse:nfeatureListDense:featureListDenseShapes:)
Transforms a vector of tf.io.SequenceExample protos (as strings) into typed tensors.
Attrs:
- context_sparse_types: A list of Ncontext_sparse types; the data types of data in each context Feature given in context_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- context_ragged_value_types: RaggedTensor.value dtypes for the ragged context features.
- context_ragged_split_types: RaggedTensor.row_split dtypes for the ragged context features.
- context_dense_shapes: A list of Ncontext_dense shapes; the shapes of data in each context Feature given in context_dense_keys. The number of elements in the Feature corresponding to context_dense_key[j] must always equal context_dense_shapes[j].NumEntries(). The shape of context_dense_values[j] will match context_dense_shapes[j].
- feature_list_sparse_types: A list of Nfeature_list_sparse types; the data types of data in each FeatureList given in feature_list_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- feature_list_ragged_value_types: RaggedTensor.value dtypes for the ragged FeatureList features.
- feature_list_ragged_split_types: RaggedTensor.row_split dtypes for the ragged FeatureList features.
- feature_list_dense_shapes: A list of Nfeature_list_dense shapes; the shapes of data in each FeatureList given in feature_list_dense_keys. The shape of each Feature in the FeatureList corresponding to feature_list_dense_key[j] must always equal feature_list_dense_shapes[j].NumEntries().
Declaration
public static func parseSequenceExampleV2< TcontextDense: TensorArrayProtocol, ContextSparseTypes: TensorGroup, ContextRaggedValueTypes: TensorGroup, ContextRaggedSplitTypes: TensorGroup, FeatureListDenseTypes: TensorGroup, FeatureListSparseTypes: TensorGroup, FeatureListRaggedValueTypes: TensorGroup, FeatureListRaggedSplitTypes: TensorGroup >( serialized: StringTensor, debugName: StringTensor, contextSparseKeys: StringTensor, contextDenseKeys: StringTensor, contextRaggedKeys: StringTensor, featureListSparseKeys: StringTensor, featureListDenseKeys: StringTensor, featureListRaggedKeys: StringTensor, featureListDenseMissingAssumedEmpty: Tensor<Bool>, contextDenseDefaults: TcontextDense, ncontextSparse: Int64 = 0, contextDenseShapes: [TensorShape?], nfeatureListSparse: Int64 = 0, nfeatureListDense: Int64 = 0, featureListDenseShapes: [TensorShape?] ) -> ( contextSparseIndices: [Tensor<Int64>], contextSparseValues: ContextSparseTypes, contextSparseShapes: [Tensor<Int64>], contextDenseValues: TcontextDense, contextRaggedValues: ContextRaggedValueTypes, contextRaggedRowSplits: ContextRaggedSplitTypes, featureListSparseIndices: [Tensor<Int64>], featureListSparseValues: FeatureListSparseTypes, featureListSparseShapes: [Tensor<Int64>], featureListDenseValues: FeatureListDenseTypes, featureListDenseLengths: [Tensor<Int64>], featureListRaggedValues: FeatureListRaggedValueTypes, featureListRaggedOuterSplits: FeatureListRaggedSplitTypes, featureListRaggedInnerSplits: FeatureListRaggedSplitTypes )Parameters
serializedA scalar or vector containing binary serialized SequenceExample protos.
debug_nameA scalar or vector containing the names of the serialized protos. May contain, for example, table key (descriptive) name for the corresponding serialized proto. This is purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty vector if no name is available.
context_sparse_keysThe keys expected in the Examples’ features associated with context_sparse values.
context_dense_keysThe keys expected in the SequenceExamples’ context features associated with dense values.
context_ragged_keysThe keys expected in the Examples’ features associated with context_ragged values.
feature_list_sparse_keysThe keys expected in the FeatureLists associated with sparse values.
feature_list_dense_keysThe keys expected in the SequenceExamples’ feature_lists associated with lists of dense values.
feature_list_ragged_keysThe keys expected in the FeatureLists associated with ragged values.
feature_list_dense_missing_assumed_emptyA vector corresponding 1:1 with featue_list_dense_keys, indicating which features may be missing from the SequenceExamples. If the associated FeatureList is missing, it is treated as empty.
context_dense_defaultsA list of Ncontext_dense Tensors (some may be empty). context_dense_defaults[j] provides default values when the SequenceExample’s context map lacks context_dense_key[j]. If an empty Tensor is provided for context_dense_defaults[j], then the Feature context_dense_keys[j] is required. The input type is inferred from context_dense_defaults[j], even when it’s empty. If context_dense_defaults[j] is not empty, its shape must match context_dense_shapes[j].
-
Transforms a tf.Example proto (as a string) into typed tensors.
Attrs:
- num_sparse: The number of sparse features to be parsed from the example. This
must match the lengths of
sparse_keysandsparse_types. - sparse_keys: A list of
num_sparsestrings. The keys expected in the Examples’ features associated with sparse values. - dense_keys: The keys expected in the Examples’ features associated with dense values.
- sparse_types: A list of
num_sparsetypes; the data types of data in each Feature given in sparse_keys. Currently the ParseSingleExample op supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). - Tdense: The data types of data in each Feature given in dense_keys.
The length of this list must match the length of
dense_keys. Currently the ParseSingleExample op supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList). - dense_shapes: The shapes of data in each Feature given in dense_keys.
The length of this list must match the length of
dense_keys. The number of elements in the Feature corresponding to dense_key[j] must always equal dense_shapes[j].NumEntries(). If dense_shapes[j] == (D0, D1, …, DN) then the shape of output Tensor dense_values[j] will be (D0, D1, …, DN): In the case dense_shapes[j] = (-1, D1, …, DN), the shape of the output Tensor dense_values[j] will be (M, D1, .., DN), where M is the number of blocks of elements of length D1 * …. * DN, in the input.
- num_sparse: The number of sparse features to be parsed from the example. This
must match the lengths of
Declaration
public static func parseSingleExample< SparseTypes: TensorGroup, Tdense: TensorArrayProtocol >( serialized: StringTensor, denseDefaults: Tdense, numSparse: Int64, sparseKeys: [String], denseKeys: [String], denseShapes: [TensorShape?] ) -> ( sparseIndices: [Tensor<Int64>], sparseValues: SparseTypes, sparseShapes: [Tensor<Int64>], denseValues: Tdense )Parameters
serializedA vector containing a batch of binary serialized Example protos.
dense_defaultsA list of Tensors (some may be empty), whose length matches the length of
dense_keys. dense_defaults[j] provides default values when the example’s feature_map lacks dense_key[j]. If an empty Tensor is provided for dense_defaults[j], then the Feature dense_keys[j] is required. The input type is inferred from dense_defaults[j], even when it’s empty. If dense_defaults[j] is not empty, and dense_shapes[j] is fully defined, then the shape of dense_defaults[j] must match that of dense_shapes[j]. If dense_shapes[j] has an undefined major dimension (variable strides dense feature), dense_defaults[j] must contain a single element: the padding element. -
parseSingleSequenceExample(serialized:featureListDenseMissingAssumedEmpty:contextSparseKeys:contextDenseKeys:featureListSparseKeys:featureListDenseKeys:contextDenseDefaults:debugName:contextDenseShapes:featureListDenseShapes:)
Transforms a scalar brain.SequenceExample proto (as strings) into typed tensors.
Attrs:
- context_sparse_types: A list of Ncontext_sparse types; the data types of data in each context Feature given in context_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- context_dense_shapes: A list of Ncontext_dense shapes; the shapes of data in each context Feature given in context_dense_keys. The number of elements in the Feature corresponding to context_dense_key[j] must always equal context_dense_shapes[j].NumEntries(). The shape of context_dense_values[j] will match context_dense_shapes[j].
- feature_list_sparse_types: A list of Nfeature_list_sparse types; the data types of data in each FeatureList given in feature_list_sparse_keys. Currently the ParseSingleSequenceExample supports DT_FLOAT (FloatList), DT_INT64 (Int64List), and DT_STRING (BytesList).
- feature_list_dense_shapes: A list of Nfeature_list_dense shapes; the shapes of data in each FeatureList given in feature_list_dense_keys. The shape of each Feature in the FeatureList corresponding to feature_list_dense_key[j] must always equal feature_list_dense_shapes[j].NumEntries().
Declaration
public static func parseSingleSequenceExample< ContextSparseTypes: TensorGroup, TcontextDense: TensorArrayProtocol, FeatureListDenseTypes: TensorGroup, FeatureListSparseTypes: TensorGroup >( serialized: StringTensor, featureListDenseMissingAssumedEmpty: StringTensor, contextSparseKeys: [StringTensor], contextDenseKeys: [StringTensor], featureListSparseKeys: [StringTensor], featureListDenseKeys: [StringTensor], contextDenseDefaults: TcontextDense, debugName: StringTensor, contextDenseShapes: [TensorShape?], featureListDenseShapes: [TensorShape?] ) -> ( contextSparseIndices: [Tensor<Int64>], contextSparseValues: ContextSparseTypes, contextSparseShapes: [Tensor<Int64>], contextDenseValues: TcontextDense, featureListSparseIndices: [Tensor<Int64>], featureListSparseValues: FeatureListSparseTypes, featureListSparseShapes: [Tensor<Int64>], featureListDenseValues: FeatureListDenseTypes )Parameters
serializedA scalar containing a binary serialized SequenceExample proto.
feature_list_dense_missing_assumed_emptyA vector listing the FeatureList keys which may be missing from the SequenceExample. If the associated FeatureList is missing, it is treated as empty. By default, any FeatureList not listed in this vector must exist in the SequenceExample.
context_sparse_keysA list of Ncontext_sparse string Tensors (scalars). The keys expected in the Examples’ features associated with context_sparse values.
context_dense_keysA list of Ncontext_dense string Tensors (scalars). The keys expected in the SequenceExamples’ context features associated with dense values.
feature_list_sparse_keysA list of Nfeature_list_sparse string Tensors (scalars). The keys expected in the FeatureLists associated with sparse values.
feature_list_dense_keysA list of Nfeature_list_dense string Tensors (scalars). The keys expected in the SequenceExamples’ feature_lists associated with lists of dense values.
context_dense_defaultsA list of Ncontext_dense Tensors (some may be empty). context_dense_defaults[j] provides default values when the SequenceExample’s context map lacks context_dense_key[j]. If an empty Tensor is provided for context_dense_defaults[j], then the Feature context_dense_keys[j] is required. The input type is inferred from context_dense_defaults[j], even when it’s empty. If context_dense_defaults[j] is not empty, its shape must match context_dense_shapes[j].
debug_nameA scalar containing the name of the serialized proto. May contain, for example, table key (descriptive) name for the corresponding serialized proto. This is purely useful for debugging purposes, and the presence of values here has no effect on the output. May also be an empty scalar if no name is available.
-
Transforms a serialized tensorflow.TensorProto proto into a Tensor.
Attr out_type: The type of the serialized tensor. The provided type must match the type of the serialized tensor and no implicit conversion will take place.
Output output: A Tensor of type
out_type.
Declaration
public static func parseTensor<OutType: TensorFlowScalar>( serialized: StringTensor ) -> Tensor<OutType>Parameters
serializedA scalar string containing a serialized TensorProto proto.
-
returns
f(inputs), wheref‘s body is placed and partitioned.Attrs:
- Tin: A list of input types.
- Tout: A list of output types.
- f: A function that takes 'args’, a list of tensors, and returns ‘output’, another list of tensors. Input and output types are specified by ‘Tin’ and ‘Tout’. The function body of f will be placed and partitioned across devices, setting this op apart from the regular Call op.
Output output: A list of return values.
Declaration
public static func partitionedCall< Tin: TensorArrayProtocol, Tout: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( args: Tin, f: (FIn) -> FOut, config: String, configProto: String, executorType: String ) -> ToutParameters
argsA list of input tensors.
-
A placeholder op for a value that will be fed into the computation.
N.B. This operation will fail with an error if it is executed. It is intended as a way to represent a value that will always be fed, and to provide attrs that enable the fed value to be checked at runtime.
Attrs:
- dtype: The type of elements in the tensor.
- shape: (Optional) The shape of the tensor. If the shape has 0 dimensions, the shape is unconstrained.
Output output: A placeholder tensor that must be replaced using the feed mechanism.
Declaration
public static func placeholder<Dtype: TensorFlowScalar>( shape: TensorShape? ) -> Tensor<Dtype> -
A placeholder op for a value that will be fed into the computation.
N.B. This operation will fail with an error if it is executed. It is intended as a way to represent a value that will always be fed, and to provide attrs that enable the fed value to be checked at runtime.
Attrs:
- dtype: The type of elements in the tensor.
- shape: The shape of the tensor. The shape can be any partially-specified shape. To be unconstrained, pass in a shape with unknown rank.
Output output: A placeholder tensor that must be replaced using the feed mechanism.
Declaration
public static func placeholderV2<Dtype: TensorFlowScalar>( shape: TensorShape? ) -> Tensor<Dtype> -
A placeholder op that passes through
inputwhen its output is not fed.Attrs:
- dtype: The type of elements in the tensor.
- shape: The (possibly partial) shape of the tensor.
Output output: A placeholder tensor that defaults to
inputif it is not fed.
Declaration
public static func placeholderWithDefault<Dtype: TensorFlowScalar>( _ input: Tensor<Dtype>, shape: TensorShape? ) -> Tensor<Dtype>Parameters
inputThe default value to produce when
outputis not fed. -
Compute the polygamma function \(\psi^{(n)}(x)\).
The polygamma function is defined as:
\(\psi^{(a)}(x) = \frac{d^a}{dx^a} \psi(x)\)
where \(\psi(x)\) is the digamma function. The polygamma function is defined only for non-negative integer orders \a.
Declaration
public static func polygamma<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ x: Tensor<T> ) -> Tensor<T> -
Declaration
public static func polymorphic<T: TensorFlowScalar>( _ a: Tensor<T> ) -> Tensor<T> -
Declaration
public static func polymorphicDefaultOut<T>() -> Tensor<T> where T : TensorFlowScalar -
Declaration
public static func polymorphicOut<T>() -> Tensor<T> where T : TensorFlowScalar -
Computes element-wise population count (a.k.a. popcount, bitsum, bitcount).
For each entry in
x, calculates the number of1(on) bits in the binary representation of that entry.NOTE: It is more efficient to first
tf.bitcastyour tensors intoint32orint64and perform the bitcount on the result, than to feed in 8- or 16-bit inputs and then aggregate the resulting counts.Declaration
public static func populationCount<T: TensorFlowInteger>( _ x: Tensor<T> ) -> Tensor<UInt8> -
Computes the power of one value to another.
Given a tensor
xand a tensory, this operation computes \(x^y\) for corresponding elements inxandy. For example:# tensor 'x' is [[2, 2]], [3, 3]] # tensor 'y' is [[8, 16], [2, 3]] tf.pow(x, y) ==> [[256, 65536], [9, 27]]Declaration
public static func pow<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Creates a dataset that asynchronously prefetches elements from
input_dataset.Declaration
public static func prefetchDataset( inputDataset: VariantHandle, bufferSize: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?], slackPeriod: Int64 = 0, legacyAutotune: Bool = true ) -> VariantHandleParameters
buffer_sizeThe maximum number of elements to buffer in an iterator over this dataset.
-
An op which linearizes one Tensor value to an opaque variant tensor.
Attrs:
- dtype: The type of elements in the tensor.
- shape: The shape of the tensor.
- layout: A vector holding the requested layout in minor-to-major sequence. If a layout attribute is passed but its values are all -1 the layout will be computed by the infeed operation.
Declaration
public static func prelinearize<Dtype: TensorFlowScalar>( _ input: Tensor<Dtype>, shape: TensorShape?, layout: [Int32] ) -> VariantHandleParameters
inputA tensor that will be linearized.
-
An op which linearizes multiple Tensor values to an opaque variant tensor.
Attrs:
- dtypes: The element types of each element in
inputs. - shapes: The shapes of each tensor in
inputs. - layouts: A vector holding the requested layout in minor-to-major sequence for all the tuple shapes in the order the shapes appear in the “shapes” input. The layout elements for a sub-shape can be set to -1 in which case the corresponding layout will be computed by the infeed operation.
- dtypes: The element types of each element in
Declaration
public static func prelinearizeTuple<Dtypes: TensorArrayProtocol>( inputs: Dtypes, shapes: [TensorShape?], layouts: [Int32] ) -> VariantHandleParameters
inputsA list of tensors that will be provided using the infeed mechanism.
-
An identity op that triggers an error if a gradient is requested.
When executed in a graph, this op outputs its input tensor as-is.
When building ops to compute gradients, the TensorFlow gradient system will return an error when trying to lookup the gradient of this op, because no gradient must ever be registered for this function. This op exists to prevent subtle bugs from silently returning unimplemented gradients in some corner cases.
Attr message: Will be printed in the error when anyone tries to differentiate this operation.
Output output: the same input tensor.
Declaration
public static func preventGradient<T: TensorFlowScalar>( _ input: Tensor<T>, message: String ) -> Tensor<T>Parameters
inputany tensor.
-
Prints a list of tensors.
Passes
inputthrough tooutputand printsdatawhen evaluating.Attrs:
- message: A string, prefix of the error message.
- first_n: Only log
first_nnumber of times. -1 disables logging. - summarize: Only print this many entries of each tensor.
Output output: = The unmodified
inputtensor
Declaration
public static func print< T: TensorFlowScalar, U: TensorArrayProtocol >( _ input: Tensor<T>, data: U, message: String, firstN: Int64 = -1, summarize: Int64 = 3 ) -> Tensor<T>Parameters
inputThe tensor passed to
outputdataA list of tensors to print out when op is evaluated.
-
Prints a string scalar.
Prints a string scalar to the desired output_stream.
Attr output_stream: A string specifying the output stream or logging level to print to.
Declaration
public static func printV2( _ input: StringTensor, outputStream: String = "stderr", end: String = "" )Parameters
inputThe string scalar to print.
-
A queue that produces elements sorted by the first component value.
Note that the PriorityQueue requires the first component of any element to be a scalar int64, in addition to the other elements declared by component_types. Therefore calls to Enqueue and EnqueueMany (resp. Dequeue and DequeueMany) on a PriorityQueue will all require (resp. output) one extra entry in their input (resp. output) lists.
Attrs:
- component_types: The type of each component in a value.
- shapes: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time.
- capacity: The upper bound on the number of elements in this queue. Negative numbers mean no limit.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this queue will be shared under the given name across multiple sessions.
Output handle: The handle to the queue.
Declaration
public static func priorityQueueV2( componentTypes: [TensorDataType], shapes: [TensorShape?], capacity: Int64 = -1, container: String, sharedName: String ) -> ResourceHandle -
Creates a dataset that uses a custom thread pool to compute
input_dataset.Declaration
public static func privateThreadPoolDataset( inputDataset: VariantHandle, numThreads: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
num_threadsIdentifies the number of threads to use for the private threadpool.
-
Computes the product of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func prod< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Invokes a python function to compute func(input)->output.
This operation is considered stateful. For a stateless version, see PyFuncStateless.
Attrs:
- token: A token representing a registered python function in this address space.
- Tin: Data types of the inputs to the op.
- Tout: Data types of the outputs from the op. The length of the list specifies the number of outputs.
Output output: The outputs from the Op.
Declaration
public static func pyFunc< Tin: TensorArrayProtocol, Tout: TensorGroup >( _ input: Tin, token: String ) -> ToutParameters
inputList of Tensors that will provide input to the Op.
-
A stateless version of PyFunc.
Declaration
public static func pyFuncStateless< Tin: TensorArrayProtocol, Tout: TensorGroup >( _ input: Tin, token: String ) -> Tout -
Computes the QR decompositions of one or more matrices.
Computes the QR decomposition of each inner matrix in
tensorsuch thattensor[..., :, :] = q[..., :, :] * r[..., :,:])# a is a tensor. # q is a tensor of orthonormal matrices. # r is a tensor of upper triangular matrices. q, r = qr(a) q_full, r_full = qr(a, full_matrices=True)Attr full_matrices: If true, compute full-sized
qandr. If false (the default), compute only the leadingPcolumns ofq.Outputs:
- q: Orthonormal basis for range of
a. Iffull_matricesisFalsethen shape is[..., M, P]; iffull_matricesisTruethen shape is[..., M, M]. - r: Triangular factor. If
full_matricesisFalsethen shape is[..., P, N]. Iffull_matricesisTruethen shape is[..., M, N].
- q: Orthonormal basis for range of
Declaration
public static func qr<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, fullMatrices: Bool = false ) -> (q: Tensor<T>, r: Tensor<T>)Parameters
inputA tensor of shape
[..., M, N]whose inner-most 2 dimensions form matrices of size[M, N]. LetPbe the minimum ofMandN. -
Use QuantizeAndDequantizeV2 instead.
Declaration
public static func quantizeAndDequantize<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, signedInput: Bool = true, numBits: Int64 = 8, rangeGiven: Bool = false, inputMin: Double = 0, inputMax: Double = 0 ) -> Tensor<T> -
quantizeAndDequantizeV2(_:inputMin:inputMax:signedInput:numBits:rangeGiven:roundMode:narrowRange:axis:)
Quantizes then dequantizes a tensor.
This op simulates the precision loss from the quantized forward pass by:
- Quantizing the tensor to fixed point numbers, which should match the target quantization method when it is used in inference.
- Dequantizing it back to floating point numbers for the following ops, most likely matmul.
There are different ways to quantize. This version uses only scaling, so 0.0 maps to 0.
From the specified ‘num_bits’ in the quantized output type, it determines minimum and maximum representable quantized values.
e.g.
- [-128, 127] for signed, num_bits = 8, or
- [0, 255] for unsigned, num_bits = 8.
If range_given == False, the initial input_min, input_max will be determined automatically as the minimum and maximum values in the input tensor, otherwise the specified values of input_min, input_max are used.
Note: If the input_min, input_max are specified, they do not need to equal the actual minimum and maximum values in the tensor. e.g. in some cases it may be beneficial to specify these values such that the low probability extremes of the input distribution are clipped.
This op determines the maximum scale_factor that would map the initial [input_min, input_max] range to a range that lies within the representable quantized range.
It determines the scale from one of input_min and input_max, then updates the other one to maximize the representable range.
e.g.
- if the output is signed, num_bits = 8, [input_min, input_max] = [-10.0, 5.0]: it would use a scale_factor of -128 / -10.0 = 12.8 In this case, it would update input_max to be 127 / 12.8 = 9.921875
- if the output is signed, num_bits = 8, [input_min, input_max] = [-10.0, 10.0]: it would use a scale_factor of 127 / 10.0 = 12.7 In this case, it would update input_min to be 128.0 / 12.7 = -10.07874
- if the output is unsigned, input_min is forced to be 0, and only the specified input_max is used.
After determining the scale_factor and updating the input range, it applies the following to each value in the ‘input’ tensor.
output = round(clamp(value, input_min, input_max) * scale_factor) / scale_factor.
The above round function rounds the value based on the given round_mode.
Attrs:
- signed_input: Whether the quantization is signed or unsigned. (actually this parameter should
have been called
signed_output) - num_bits: The bitwidth of the quantization.
- range_given: Whether the range is given or should be determined from the
inputtensor. round_mode: The ‘round_mode’ attribute controls which rounding tie-breaking algorithm is used when rounding float values to their quantized equivalents. The following rounding modes are currently supported:
- HALF_TO_EVEN: this is the default round_mode.
- HALF_UP: round towards positive. In this mode 7.5 rounds up to 8 and -7.5 rounds up to -7.
narrow_range: If True, then the absolute value of the quantized minimum value is the same as the quantized maximum value, instead of 1 greater. i.e. for 8 bit quantization, the minimum value is -127 instead of -128.
axis: If specified, this axis is treated as a channel or slice axis, and a separate quantization range is used for each channel or slice along this axis.
- signed_input: Whether the quantization is signed or unsigned. (actually this parameter should
have been called
Declaration
public static func quantizeAndDequantizeV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, inputMin: Tensor<T>, inputMax: Tensor<T>, signedInput: Bool = true, numBits: Int64 = 8, rangeGiven: Bool = false, roundMode: RoundMode = .halfToEven, narrowRange: Bool = false, axis: Int64 = -1 ) -> Tensor<T>Parameters
inputTensor to quantize and then dequantize.
input_minIf
range_given == True, this specifies the minimum input value that needs to be represented, otherwise it is determined from the min value of theinputtensor.input_maxIf
range_given == True, this specifies the maximum input value that needs to be represented, otherwise it is determined from the max value of theinputtensor. -
Quantizes then dequantizes a tensor.
This is almost identical to QuantizeAndDequantizeV2, except that num_bits is a tensor, so its value can change during training.
-
Convert the quantized ‘input’ tensor into a lower-precision ‘output’, using the
actual distribution of the values to maximize the usage of the lower bit depth and adjusting the output min and max ranges accordingly.
[input_min, input_max] are scalar floats that specify the range for the float interpretation of the ‘input’ data. For example, if input_min is -1.0f and input_max is 1.0f, and we are dealing with quint16 quantized data, then a 0 value in the 16-bit data should be interpreted as -1.0f, and a 65535 means 1.0f.
This operator tries to squeeze as much precision as possible into an output with a lower bit depth by calculating the actual min and max values found in the data. For example, maybe that quint16 input has no values lower than 16,384 and none higher than 49,152. That means only half the range is actually needed, all the float interpretations are between -0.5f and 0.5f, so if we want to compress the data into a quint8 output, we can use that range rather than the theoretical -1.0f to 1.0f that is suggested by the input min and max.
In practice, this is most useful for taking output from operations like QuantizedMatMul that can produce higher bit-depth outputs than their inputs and may have large potential output ranges, but in practice have a distribution of input values that only uses a small fraction of the possible range. By feeding that output into this operator, we can reduce it from 32 bits down to 8 with minimal loss of accuracy.
Attrs:
- Tinput: The type of the input.
- out_type: The type of the output. Should be a lower bit depth than Tinput.
Outputs:
- output_min: The float value that the minimum quantized output value represents.
- output_max: The float value that the maximum quantized output value represents.
Declaration
public static func quantizeDownAndShrinkRange< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, inputMin: Tensor<Float>, inputMax: Tensor<Float> ) -> (output: Tensor<OutType>, outputMin: Tensor<Float>, outputMax: Tensor<Float>)Parameters
input_minThe float value that the minimum quantized input value represents.
input_maxThe float value that the maximum quantized input value represents.
-
Quantize the ‘input’ tensor of type float to ‘output’ tensor of type ‘T’.
[min_range, max_range] are scalar floats that specify the range for the ‘input’ data. The ‘mode’ attribute controls exactly which calculations are used to convert the float values to their quantized equivalents. The ‘round_mode’ attribute controls which rounding tie-breaking algorithm is used when rounding float values to their quantized equivalents.
In ‘MIN_COMBINED’ mode, each value of the tensor will undergo the following:
out[i] = (in[i] - min_range) * range(T) / (max_range - min_range) if T == qint8: out[i] -= (range(T) + 1) / 2.0here
range(T) = numeric_limits<T>::max() - numeric_limits<T>::min()MIN_COMBINED Mode Example
Assume the input is type float and has a possible range of [0.0, 6.0] and the output type is quint8 ([0, 255]). The min_range and max_range values should be specified as 0.0 and 6.0. Quantizing from float to quint8 will multiply each value of the input by 255/6 and cast to quint8.
If the output type was qint8 ([-128, 127]), the operation will additionally subtract each value by 128 prior to casting, so that the range of values aligns with the range of qint8.
If the mode is ‘MIN_FIRST’, then this approach is used:
num_discrete_values = 1 << (# of bits in T) range_adjust = num_discrete_values / (num_discrete_values - 1) range = (range_max - range_min) * range_adjust range_scale = num_discrete_values / range quantized = round(input * range_scale) - round(range_min * range_scale) + numeric_limits<T>::min() quantized = max(quantized, numeric_limits<T>::min()) quantized = min(quantized, numeric_limits<T>::max())The biggest difference between this and MIN_COMBINED is that the minimum range is rounded first, before it’s subtracted from the rounded value. With MIN_COMBINED, a small bias is introduced where repeated iterations of quantizing and dequantizing will introduce a larger and larger error.
SCALED mode Example
SCALEDmode matches the quantization approach used inQuantizeAndDequantize{V2|V3}.If the mode is
SCALED, the quantization is performed by multiplying each input value by a scaling_factor. The scaling_factor is determined frommin_rangeandmax_rangeto be as large as possible such that the range frommin_rangetomax_rangeis representable within values of type T.const int min_T = std::numeric_limits<T>::min(); const int max_T = std::numeric_limits<T>::max(); const float max_float = std::numeric_limits<float>::max(); const float scale_factor_from_min_side = (min_T * min_range > 0) ? min_T / min_range : max_float; const float scale_factor_from_max_side = (max_T * max_range > 0) ? max_T / max_range : max_float; const float scale_factor = std::min(scale_factor_from_min_side, scale_factor_from_max_side);We next use the scale_factor to adjust min_range and max_range as follows:
min_range = min_T / scale_factor; max_range = max_T / scale_factor;e.g. if T = qint8, and initially min_range = -10, and max_range = 9, we would compare -128/-10.0 = 12.8 to 127/9.0 = 14.11, and set scaling_factor = 12.8 In this case, min_range would remain -10, but max_range would be adjusted to 127 / 12.8 = 9.921875
So we will quantize input values in the range (-10, 9.921875) to (-128, 127).
The input tensor can now be quantized by clipping values to the range
min_rangetomax_range, then multiplying by scale_factor as follows:result = round(min(max_range, max(min_range, input)) * scale_factor)The adjusted
min_rangeandmax_rangeare returned as outputs 2 and 3 of this operation. These outputs should be used as the range for any further calculations.narrow_range (bool) attribute
If true, we do not use the minimum quantized value. i.e. for int8 the quantized output, it would be restricted to the range -127..127 instead of the full -128..127 range. This is provided for compatibility with certain inference backends. (Only applies to SCALED mode)
axis (int) attribute
An optional
axisattribute can specify a dimension index of the input tensor, such that quantization ranges will be calculated and applied separately for each slice of the tensor along that dimension. This is useful for per-channel quantization.If axis is specified, min_range and max_range
if
axis=None, per-tensor quantization is performed as normal.ensure_minimum_range (float) attribute
Ensures the minimum quantization range is at least this value. The legacy default value for this is 0.01, but it is strongly suggested to set it to 0 for new uses.
Outputs:
- output: The quantized data produced from the float input.
- output_min: The final quantization range minimum, used to clip input values before scaling
and rounding them to quantized values.
If the
axisattribute is specified, this will be a 1-D tensor whose size matches theaxisdimension of the input and output tensors. - output_max: The final quantization range maximum, used to clip input values before scaling
and rounding them to quantized values.
If the
axisattribute is specified, this will be a 1-D tensor whose size matches theaxisdimension of the input and output tensors.
Declaration
public static func quantizeV2<T: TensorFlowScalar>( _ input: Tensor<Float>, minRange: Tensor<Float>, maxRange: Tensor<Float>, mode: Mode = .minCombined, roundMode: RoundMode7 = .halfAwayFromZero, narrowRange: Bool = false, axis: Int64 = -1, ensureMinimumRange: Double = 0.01 ) -> (output: Tensor<T>, outputMin: Tensor<Float>, outputMax: Tensor<Float>)Parameters
min_rangeThe minimum value of the quantization range. This value may be adjusted by the op depending on other parameters. The adjusted value is written to
output_min. If theaxisattribute is specified, this must be a 1-D tensor whose size matches theaxisdimension of the input and output tensors.max_rangeThe maximum value of the quantization range. This value may be adjusted by the op depending on other parameters. The adjusted value is written to
output_max. If theaxisattribute is specified, this must be a 1-D tensor whose size matches theaxisdimension of the input and output tensors. -
Returns x + y element-wise, working on quantized buffers.
Outputs:
- min_z: The float value that the lowest quantized output value represents.
max_z: The float value that the highest quantized output value represents.
NOTE:
QuantizedAddsupports limited forms of broadcasting. More about broadcasting here
Declaration
public static func quantizedAdd< T1: TensorFlowScalar, T2: TensorFlowScalar, Toutput: TensorFlowScalar >( _ x: Tensor<T1>, _ y: Tensor<T2>, minX: Tensor<Float>, maxX: Tensor<Float>, minY: Tensor<Float>, maxY: Tensor<Float> ) -> (z: Tensor<Toutput>, minZ: Tensor<Float>, maxZ: Tensor<Float>)Parameters
min_xThe float value that the lowest quantized
xvalue represents.max_xThe float value that the highest quantized
xvalue represents.min_yThe float value that the lowest quantized
yvalue represents.max_yThe float value that the highest quantized
yvalue represents. -
Produces the average pool of the input tensor for quantized types.
Attrs:
- ksize: The size of the window for each dimension of the input tensor. The length must be 4 to match the number of dimensions of the input.
- strides: The stride of the sliding window for each dimension of the input tensor. The length must be 4 to match the number of dimensions of the input.
- padding: The type of padding algorithm to use.
Outputs:
- min_output: The float value that the lowest quantized output value represents.
- max_output: The float value that the highest quantized output value represents.
Declaration
Parameters
input4-D with shape
[batch, height, width, channels].min_inputThe float value that the lowest quantized input value represents.
max_inputThe float value that the highest quantized input value represents.
-
quantizedBatchNormWithGlobalNormalization(t:tMin:tMax:m:mMin:mMax:v:vMin:vMax:beta:betaMin:betaMax:gamma:gammaMin:gammaMax:varianceEpsilon:scaleAfterNormalization:)
Quantized Batch normalization.
This op is deprecated and will be removed in the future. Prefer
tf.nn.batch_normalization.Attrs:
- variance_epsilon: A small float number to avoid dividing by 0.
- scale_after_normalization: A bool indicating whether the resulted tensor needs to be multiplied with gamma.
Declaration
public static func quantizedBatchNormWithGlobalNormalization< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( t: Tensor<Tinput>, tMin: Tensor<Float>, tMax: Tensor<Float>, m: Tensor<Tinput>, mMin: Tensor<Float>, mMax: Tensor<Float>, v: Tensor<Tinput>, vMin: Tensor<Float>, vMax: Tensor<Float>, beta: Tensor<Tinput>, betaMin: Tensor<Float>, betaMax: Tensor<Float>, gamma: Tensor<Tinput>, gammaMin: Tensor<Float>, gammaMax: Tensor<Float>, varianceEpsilon: Double, scaleAfterNormalization: Bool ) -> (result: Tensor<OutType>, resultMin: Tensor<Float>, resultMax: Tensor<Float>)Parameters
tA 4D input Tensor.
t_minThe value represented by the lowest quantized input.
t_maxThe value represented by the highest quantized input.
mA 1D mean Tensor with size matching the last dimension of t. This is the first output from tf.nn.moments, or a saved moving average thereof.
m_minThe value represented by the lowest quantized mean.
m_maxThe value represented by the highest quantized mean.
vA 1D variance Tensor with size matching the last dimension of t. This is the second output from tf.nn.moments, or a saved moving average thereof.
v_minThe value represented by the lowest quantized variance.
v_maxThe value represented by the highest quantized variance.
betaA 1D beta Tensor with size matching the last dimension of t. An offset to be added to the normalized tensor.
beta_minThe value represented by the lowest quantized offset.
beta_maxThe value represented by the highest quantized offset.
gammaA 1D gamma Tensor with size matching the last dimension of t. If “scale_after_normalization” is true, this tensor will be multiplied with the normalized tensor.
gamma_minThe value represented by the lowest quantized gamma.
gamma_maxThe value represented by the highest quantized gamma.
-
Adds Tensor ‘bias’ to Tensor ‘input’ for Quantized types.
Broadcasts the values of bias on dimensions 0..N-2 of ‘input’.
Outputs:
- min_out: The float value that the lowest quantized output value represents.
- max_out: The float value that the highest quantized output value represents.
Declaration
public static func quantizedBiasAdd< T1: TensorFlowScalar, T2: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<T1>, bias: Tensor<T2>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minBias: Tensor<Float>, maxBias: Tensor<Float> ) -> (output: Tensor<OutType>, minOut: Tensor<Float>, maxOut: Tensor<Float>)Parameters
biasA 1D bias Tensor with size matching the last dimension of ‘input’.
min_inputThe float value that the lowest quantized input value represents.
max_inputThe float value that the highest quantized input value represents.
min_biasThe float value that the lowest quantized bias value represents.
max_biasThe float value that the highest quantized bias value represents.
-
Concatenates quantized tensors along one dimension.
Outputs:
- output: A
Tensorwith the concatenation of values stacked along theconcat_dimdimension. This tensor’s shape matches that ofvaluesexcept inconcat_dimwhere it has the sum of the sizes. - output_min: The float value that the minimum quantized output value represents.
- output_max: The float value that the maximum quantized output value represents.
- output: A
Declaration
Parameters
concat_dim0-D. The dimension along which to concatenate. Must be in the range [0, rank(values)).
valuesThe
NTensors to concatenate. Their ranks and types must match, and their sizes must match in all dimensions exceptconcat_dim.input_minsThe minimum scalar values for each of the input tensors.
input_maxesThe maximum scalar values for each of the input tensors.
-
Computes a 2D convolution given quantized 4D input and filter tensors.
The inputs are quantized tensors where the lowest value represents the real number of the associated minimum, and the highest represents the maximum. This means that you can only interpret the quantized output in the same way, by taking the returned minimum and maximum values into account.
Attrs:
- strides: The stride of the sliding window for each dimension of the input tensor.
- padding: The type of padding algorithm to use.
- dilations: 1-D tensor of length 4. The dilation factor for each dimension of
input. If set to k > 1, there will be k-1 skipped cells between each filter element on that dimension. The dimension order is determined by the value ofdata_format, see above for details. Dilations in the batch and depth dimensions must be 1.
Outputs:
- min_output: The float value that the lowest quantized output value represents.
- max_output: The float value that the highest quantized output value represents.
Declaration
public static func quantizedConv2D< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
filterfilter’s input_depth dimension must match input’s depth dimensions.
min_inputThe float value that the lowest quantized input value represents.
max_inputThe float value that the highest quantized input value represents.
min_filterThe float value that the lowest quantized filter value represents.
max_filterThe float value that the highest quantized filter value represents.
-
quantizedConv2DAndRelu(_:filter:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DAndRelu< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DAndReluAndRequantize(_:filter:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DAndReluAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DAndRequantize(_:filter:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DPerChannel(_:filter:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:)
Computes QuantizedConv2D per channel.
Attrs:
- Tinput: The quantized type of input tensor that needs to be converted.
- Tfilter: The quantized type of filter tensor that needs to be converted.
- out_type: The quantized type of output tensor that needs to be converted.
- strides: list of stride values.
- dilations: list of dilation values.
Outputs:
- output: The output tensor.
- min_output: The minimum value of the final output tensor.
- max_output: The maximum value of the final output tensor.
Declaration
public static func quantizedConv2DPerChannel< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
inputThe original input tensor.
filterThe original filter tensor.
min_inputThe minimum value of the input tensor
max_inputThe maximum value of the input tensor.
min_filterThe minimum value of the filter tensor.
max_filterThe maximum value of the filter tensor.
-
quantizedConv2DWithBias(_:filter:bias:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBias< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Float>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasAndRelu(_:filter:bias:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasAndRelu< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Float>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasAndReluAndRequantize(_:filter:bias:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasAndReluAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Tbias>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasAndRequantize(_:filter:bias:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Tbias>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasSignedSumAndReluAndRequantize(_:filter:bias:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:summand:minSummand:maxSummand:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasSignedSumAndReluAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, Tsummand: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Tbias>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, summand: Tensor<Tsummand>, minSummand: Tensor<Float>, maxSummand: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasSumAndRelu(_:filter:bias:minInput:maxInput:minFilter:maxFilter:summand:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasSumAndRelu< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Float>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, summand: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
quantizedConv2DWithBiasSumAndReluAndRequantize(_:filter:bias:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:summand:minSummand:maxSummand:strides:padding:dilations:paddingList:)
Declaration
public static func quantizedConv2DWithBiasSumAndReluAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, Tsummand: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Tbias>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, summand: Tensor<Tsummand>, minSummand: Tensor<Float>, maxSummand: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1], paddingList: [Int32] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>) -
Computes quantized depthwise Conv2D.
Attrs:
- Tinput: The type of the input.
- Tfilter: The type of the filter.
- out_type: The type of the output.
- strides: List of stride values.
- dilations: List of dilation values.
Outputs:
- output: The output tensor.
- min_output: The float value that the minimum quantized output value represents.
- max_output: The float value that the maximum quantized output value represents.
Declaration
public static func quantizedDepthwiseConv2D< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
inputThe original input tensor.
filterThe original filter tensor.
min_inputThe float value that the minimum quantized input value represents.
max_inputThe float value that the maximum quantized input value represents.
min_filterThe float value that the minimum quantized filter value represents.
max_filterThe float value that the maximum quantized filter value represents.
-
quantizedDepthwiseConv2DWithBias(_:filter:bias:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:)
Computes quantized depthwise Conv2D with Bias.
Attrs:
- Tinput: The type of the input.
- Tfilter: The type of the filter.
- out_type: The type of the output.
- strides: List of stride values.
- dilations: List of dilation values.
Outputs:
- output: The output tensor.
- min_output: The float value that the minimum quantized output value represents.
- max_output: The float value that the maximum quantized output value represents.
Declaration
public static func quantizedDepthwiseConv2DWithBias< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Float>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
inputThe original input tensor.
filterThe original filter tensor.
biasThe original bias tensor.
min_inputThe float value that the minimum quantized input value represents.
max_inputThe float value that the maximum quantized input value represents.
min_filterThe float value that the minimum quantized filter value represents.
max_filterThe float value that the maximum quantized filter value represents.
-
quantizedDepthwiseConv2DWithBiasAndRelu(_:filter:bias:minInput:maxInput:minFilter:maxFilter:strides:padding:dilations:)
Computes quantized depthwise Conv2D with Bias and Relu.
Attrs:
- Tinput: The type of the input.
- Tfilter: The type of the filter.
- out_type: The type of the output.
- strides: List of stride values.
- dilations: List of dilation values.
Outputs:
- output: The output tensor.
- min_output: The float value that the minimum quantized output value represents.
- max_output: The float value that the maximum quantized output value represents.
Declaration
public static func quantizedDepthwiseConv2DWithBiasAndRelu< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Float>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
inputThe original input tensor.
filterThe original filter tensor.
biasThe original bias tensor.
min_inputThe float value that the minimum quantized input value represents.
max_inputThe float value that the maximum quantized input value represents.
min_filterThe float value that the minimum quantized filter value represents.
max_filterThe float value that the maximum quantized filter value represents.
-
quantizedDepthwiseConv2DWithBiasAndReluAndRequantize(_:filter:bias:minInput:maxInput:minFilter:maxFilter:minFreezedOutput:maxFreezedOutput:strides:padding:dilations:)
Computes quantized depthwise Conv2D with Bias, Relu and Requantize.
Attrs:
- Tinput: The type of the input.
- Tfilter: The type of the filter.
- Tbias: The type of the bias.
- out_type: The type of the output.
- strides: List of stride values.
- dilations: List of dilation values.
Outputs:
- output: The output tensor.
- min_output: The float value that the minimum quantized output value represents.
- max_output: The float value that the maximum quantized output value represents.
Declaration
public static func quantizedDepthwiseConv2DWithBiasAndReluAndRequantize< Tinput: TensorFlowScalar, Tfilter: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, filter: Tensor<Tfilter>, bias: Tensor<Tbias>, minInput: Tensor<Float>, maxInput: Tensor<Float>, minFilter: Tensor<Float>, maxFilter: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, strides: [Int32], padding: Padding, dilations: [Int32] = [1, 1, 1, 1] ) -> (output: Tensor<OutType>, minOutput: Tensor<Float>, maxOutput: Tensor<Float>)Parameters
inputThe original input tensor.
filterThe original filter tensor.
biasThe original bias tensor.
min_inputThe float value that the minimum quantized input value represents.
max_inputThe float value that the maximum quantized input value represents.
min_filterThe float value that the minimum quantized filter value represents.
max_filterThe float value that the maximum quantized filter value represents.
min_freezed_outputThe minimum float value of the output tensor.
max_freezed_outputThe maximum float value of the output tensor.
-
quantizedInstanceNorm(_:xMin:xMax:outputRangeGiven:givenYMin:givenYMax:varianceEpsilon:minSeparation:)
Quantized Instance normalization.
Attrs:
- output_range_given: If True,
given_y_minandgiven_y_minandgiven_y_maxare used as the output range. Otherwise, the implementation computes the output range. - given_y_min: Output in
y_minifoutput_range_givenis True. - given_y_max: Output in
y_maxifoutput_range_givenis True. - variance_epsilon: A small float number to avoid dividing by 0.
- min_separation: Minimum value of
y_max - y_min
- output_range_given: If True,
Outputs:
- y: A 4D Tensor.
- y_min: The value represented by the lowest quantized output.
- y_max: The value represented by the highest quantized output.
Declaration
public static func quantizedInstanceNorm<T: TensorFlowScalar>( _ x: Tensor<T>, xMin: Tensor<Float>, xMax: Tensor<Float>, outputRangeGiven: Bool = false, givenYMin: Double = 0, givenYMax: Double = 0, varianceEpsilon: Double = 1e-05, minSeparation: Double = 0.001 ) -> (y: Tensor<T>, yMin: Tensor<Float>, yMax: Tensor<Float>)Parameters
xA 4D input Tensor.
x_minThe value represented by the lowest quantized input.
x_maxThe value represented by the highest quantized input.
-
Perform a quantized matrix multiplication of
aby the matrixb.The inputs must be two-dimensional matrices and the inner dimension of
a(after being transposed iftranspose_ais non-zero) must match the outer dimension ofb(after being transposed iftransposed_bis non-zero).Attrs:
- transpose_a: If true,
ais transposed before multiplication. - transpose_b: If true,
bis transposed before multiplication. - Tactivation: The type of output produced by activation function following this operation.
- transpose_a: If true,
Outputs:
- min_out: The float value that the lowest quantized output value represents.
- max_out: The float value that the highest quantized output value represents.
Declaration
public static func quantizedMatMul< T1: TensorFlowScalar, T2: TensorFlowScalar, Toutput: TensorFlowScalar >( _ a: Tensor<T1>, _ b: Tensor<T2>, minA: Tensor<Float>, maxA: Tensor<Float>, minB: Tensor<Float>, maxB: Tensor<Float>, transposeA: Bool = false, transposeB: Bool = false, tactivation: TensorDataType ) -> (out: Tensor<Toutput>, minOut: Tensor<Float>, maxOut: Tensor<Float>)Parameters
aMust be a two-dimensional tensor.
bMust be a two-dimensional tensor.
min_aThe float value that the lowest quantized
avalue represents.max_aThe float value that the highest quantized
avalue represents.min_bThe float value that the lowest quantized
bvalue represents.max_bThe float value that the highest quantized
bvalue represents. -
Performs a quantized matrix multiplication of
aby the matrixbwith bias add.The inputs must be two-dimensional matrices and 1D bias vector. And the inner dimension of
a(after being transposed iftranspose_ais non-zero) must match the outer dimension ofb(after being transposed iftransposed_bis non-zero). Then do broadcast add operation with bias values on the matrix mulplication result. The bias size must match inner dimension ofb.Attrs:
- transpose_a: If true,
ais transposed before multiplication. - transpose_b: If true,
bis transposed before multiplication. - input_quant_mode: Input data quantization mode. Either MIN_FIRST(default) or SCALED.
- transpose_a: If true,
Outputs:
- min_out: The float value that the lowest quantized output value represents.
- max_out: The float value that the highest quantized output value represents.
Declaration
public static func quantizedMatMulWithBias< T1: TensorFlowScalar, T2: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, Toutput: TensorFlowScalar >( _ a: Tensor<T1>, _ b: Tensor<T2>, bias: Tensor<Tbias>, minA: Tensor<Float>, maxA: Tensor<Float>, minB: Tensor<Float>, maxB: Tensor<Float>, transposeA: Bool = false, transposeB: Bool = false, inputQuantMode: InputQuantMode = .minFirst ) -> (out: Tensor<Toutput>, minOut: Tensor<Float>, maxOut: Tensor<Float>)Parameters
aA matrix to be multiplied. Must be a two-dimensional tensor of type
quint8.bA matrix to be multiplied and must be a two-dimensional tensor of type
qint8.biasA 1D bias tensor with size matching inner dimension of
b(after being transposed iftransposed_bis non-zero).min_aThe float value that the lowest quantized
avalue represents.max_aThe float value that the highest quantized
avalue represents.min_bThe float value that the lowest quantized
bvalue represents.max_bThe float value that the highest quantized
bvalue represents. -
Perform a quantized matrix multiplication of
aby the matrixbwith bias add and relu fusion.The inputs must be two-dimensional matrices and 1D bias vector. And the inner dimension of
a(after being transposed iftranspose_ais non-zero) must match the outer dimension ofb(after being transposed iftransposed_bis non-zero). Then do broadcast add operation with bias values on the matrix mulplication result. The bias size must match inner dimension ofb. Then do relu activation to get non-negative result.Attrs:
- transpose_a: If true,
ais transposed before multiplication. - transpose_b: If true,
bis transposed before multiplication. - input_quant_mode: Input data quantization mode. Either MIN_FIRST(default) or SCALED.
- transpose_a: If true,
Outputs:
- min_out: The float value that the lowest quantized output value represents.
- max_out: The float value that the highest quantized output value represents.
Declaration
public static func quantizedMatMulWithBiasAndRelu< T1: TensorFlowScalar, T2: TensorFlowScalar, Toutput: TensorFlowScalar >( _ a: Tensor<T1>, _ b: Tensor<T2>, bias: Tensor<Float>, minA: Tensor<Float>, maxA: Tensor<Float>, minB: Tensor<Float>, maxB: Tensor<Float>, transposeA: Bool = false, transposeB: Bool = false, inputQuantMode: InputQuantMode = .minFirst ) -> (out: Tensor<Toutput>, minOut: Tensor<Float>, maxOut: Tensor<Float>)Parameters
aA matrix to be multiplied. Must be a two-dimensional tensor of type
quint8.bA matrix to be multiplied and must be a two-dimensional tensor of type
qint8.biasA 1D bias tensor with size matching with inner dimension of
b(after being transposed iftransposed_bis non-zero).min_aThe float value that the lowest quantized
avalue represents.max_aThe float value that the highest quantized
avalue represents.min_bThe float value that the lowest quantized
bvalue represents.max_bThe float value that the highest quantized
bvalue represents. -
quantizedMatMulWithBiasAndReluAndRequantize(_:_:bias:minA:maxA:minB:maxB:minFreezedOutput:maxFreezedOutput:transposeA:transposeB:inputQuantMode:)
Perform a quantized matrix multiplication of
aby the matrixbwith bias add and relu and requantize fusion.The inputs must be two-dimensional matrices and 1D bias vector. And the inner dimension of
a(after being transposed iftranspose_ais non-zero) must match the outer dimension ofb(after being transposed iftransposed_bis non-zero). Then do broadcast add operation with bias values on the matrix mulplication result. The bias size must match inner dimension ofb. Then do relu activation to get non-negative result. Then do requantize operation to get final uint8 result.Attrs:
- transpose_a: If true,
ais transposed before multiplication. - transpose_b: If true,
bis transposed before multiplication. - input_quant_mode: Input data quantization mode. Either MIN_FIRST(default) or SCALED.
- transpose_a: If true,
Outputs:
- min_out: The float value that the lowest quantized output value represents.
- max_out: The float value that the highest quantized output value represents.
Declaration
public static func quantizedMatMulWithBiasAndReluAndRequantize< T1: TensorFlowScalar, T2: TensorFlowScalar, Tbias: FloatingPoint & TensorFlowScalar, Toutput: TensorFlowScalar >( _ a: Tensor<T1>, _ b: Tensor<T2>, bias: Tensor<Tbias>, minA: Tensor<Float>, maxA: Tensor<Float>, minB: Tensor<Float>, maxB: Tensor<Float>, minFreezedOutput: Tensor<Float>, maxFreezedOutput: Tensor<Float>, transposeA: Bool = false, transposeB: Bool = false, inputQuantMode: InputQuantMode = .minFirst ) -> (out: Tensor<Toutput>, minOut: Tensor<Float>, maxOut: Tensor<Float>)Parameters
aA matrix to be multiplied. Must be a two-dimensional tensor of type
quint8.bA matrix to be multiplied and must be a two-dimensional tensor of type
qint8.biasA 1D bias tensor with size matching with inner dimension of
b(after being transposed iftransposed_bis non-zero).min_aThe float value that the lowest quantized
avalue represents.max_aThe float value that the highest quantized
avalue represents.min_bThe float value that the lowest quantized
bvalue represents.max_bThe float value that the highest quantized
bvalue represents.min_freezed_outputThe float value that the highest quantized output value after requantize.
-
Produces the max pool of the input tensor for quantized types.
Attrs:
- ksize: The size of the window for each dimension of the input tensor. The length must be 4 to match the number of dimensions of the input.
- strides: The stride of the sliding window for each dimension of the input tensor. The length must be 4 to match the number of dimensions of the input.
- padding: The type of padding algorithm to use.
Outputs:
- min_output: The float value that the lowest quantized output value represents.
- max_output: The float value that the highest quantized output value represents.
Declaration
Parameters
inputThe 4D (batch x rows x cols x depth) Tensor to MaxReduce over.
min_inputThe float value that the lowest quantized input value represents.
max_inputThe float value that the highest quantized input value represents.
-
Returns x * y element-wise, working on quantized buffers.
Outputs:
- min_z: The float value that the lowest quantized output value represents.
max_z: The float value that the highest quantized output value represents.
NOTE:
QuantizedMulsupports limited forms of broadcasting. More about broadcasting here
Declaration
public static func quantizedMul< T1: TensorFlowScalar, T2: TensorFlowScalar, Toutput: TensorFlowScalar >( _ x: Tensor<T1>, _ y: Tensor<T2>, minX: Tensor<Float>, maxX: Tensor<Float>, minY: Tensor<Float>, maxY: Tensor<Float> ) -> (z: Tensor<Toutput>, minZ: Tensor<Float>, maxZ: Tensor<Float>)Parameters
min_xThe float value that the lowest quantized
xvalue represents.max_xThe float value that the highest quantized
xvalue represents.min_yThe float value that the lowest quantized
yvalue represents.max_yThe float value that the highest quantized
yvalue represents. -
Computes Quantized Rectified Linear:
max(features, 0)Outputs:
- activations: Has the same output shape as “features”.
- min_activations: The float value that the lowest quantized value represents.
- max_activations: The float value that the highest quantized value represents.
Declaration
public static func quantizedRelu< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( features: Tensor<Tinput>, minFeatures: Tensor<Float>, maxFeatures: Tensor<Float> ) -> ( activations: Tensor<OutType>, minActivations: Tensor<Float>, maxActivations: Tensor<Float> )Parameters
min_featuresThe float value that the lowest quantized value represents.
max_featuresThe float value that the highest quantized value represents.
-
Computes Quantized Rectified Linear 6:
min(max(features, 0), 6)Outputs:
- activations: Has the same output shape as “features”.
- min_activations: The float value that the lowest quantized value represents.
- max_activations: The float value that the highest quantized value represents.
Declaration
public static func quantizedRelu6< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( features: Tensor<Tinput>, minFeatures: Tensor<Float>, maxFeatures: Tensor<Float> ) -> ( activations: Tensor<OutType>, minActivations: Tensor<Float>, maxActivations: Tensor<Float> )Parameters
min_featuresThe float value that the lowest quantized value represents.
max_featuresThe float value that the highest quantized value represents.
-
Computes Quantized Rectified Linear X:
min(max(features, 0), max_value)Outputs:
- activations: Has the same output shape as “features”.
- min_activations: The float value that the lowest quantized value represents.
- max_activations: The float value that the highest quantized value represents.
Declaration
public static func quantizedReluX< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( features: Tensor<Tinput>, maxValue: Tensor<Float>, minFeatures: Tensor<Float>, maxFeatures: Tensor<Float> ) -> ( activations: Tensor<OutType>, minActivations: Tensor<Float>, maxActivations: Tensor<Float> )Parameters
min_featuresThe float value that the lowest quantized value represents.
max_featuresThe float value that the highest quantized value represents.
-
Reshapes a quantized tensor as per the Reshape op.
- Parameters: - shape: Defines the shape of the output tensor. - input_min: The minimum value of the input. - input_max: The maximum value of the input. - Outputs: - output_min: This value is copied from input_min. - output_max: This value is copied from input_max.Declaration
public static func quantizedReshape< T: TensorFlowScalar, Tshape: TensorFlowIndex >( _ tensor: Tensor<T>, shape: Tensor<Tshape>, inputMin: Tensor<Float>, inputMax: Tensor<Float> ) -> (output: Tensor<T>, outputMin: Tensor<Float>, outputMax: Tensor<Float>) -
Resize quantized
imagestosizeusing quantized bilinear interpolation.Input images and output images must be quantized types.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
Output resized_images: 4-D with shape
[batch, new_height, new_width, channels].
Declaration
Parameters
images4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images. -
Closes the given queue.
This operation signals that no more elements will be enqueued in the given queue. Subsequent Enqueue(Many) operations will fail. Subsequent Dequeue(Many) operations will continue to succeed if sufficient elements remain in the queue. Subsequent Dequeue(Many) operations that would block will fail immediately.
Attr cancel_pending_enqueues: If true, all pending enqueue requests that are blocked on the given queue will be canceled.
Declaration
public static func queueCloseV2( handle: ResourceHandle, cancelPendingEnqueues: Bool = false )Parameters
handleThe handle to a queue.
-
Dequeues
ntuples of one or more tensors from the given queue.If the queue is closed and there are fewer than
nelements, then an OutOfRange error is returned.This operation concatenates queue-element component tensors along the 0th dimension to make a single component tensor. All of the components in the dequeued tuple will have size
nin the 0th dimension.This operation has
koutputs, wherekis the number of components in the tuples stored in the given queue, and outputiis the ith component of the dequeued tuple.N.B. If the queue is empty, this operation will block until
nelements have been dequeued (or ‘timeout_ms’ elapses, if specified).Attrs:
- component_types: The type of each component in a tuple.
- timeout_ms: If the queue has fewer than n elements, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet.
Output components: One or more tensors that were dequeued as a tuple.
Declaration
public static func queueDequeueManyV2<ComponentTypes: TensorGroup>( handle: ResourceHandle, n: Tensor<Int32>, timeoutMs: Int64 = -1 ) -> ComponentTypesParameters
handleThe handle to a queue.
nThe number of tuples to dequeue.
-
Dequeues
ntuples of one or more tensors from the given queue.This operation is not supported by all queues. If a queue does not support DequeueUpTo, then an Unimplemented error is returned.
If the queue is closed and there are more than 0 but less than
nelements remaining, then instead of returning an OutOfRange error like QueueDequeueMany, less thannelements are returned immediately. If the queue is closed and there are 0 elements left in the queue, then an OutOfRange error is returned just like in QueueDequeueMany. Otherwise the behavior is identical to QueueDequeueMany:This operation concatenates queue-element component tensors along the 0th dimension to make a single component tensor. All of the components in the dequeued tuple will have size n in the 0th dimension.
This operation has
koutputs, wherekis the number of components in the tuples stored in the given queue, and outputiis the ith component of the dequeued tuple.Attrs:
- component_types: The type of each component in a tuple.
- timeout_ms: If the queue has fewer than n elements, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet.
Output components: One or more tensors that were dequeued as a tuple.
Declaration
public static func queueDequeueUpToV2<ComponentTypes: TensorGroup>( handle: ResourceHandle, n: Tensor<Int32>, timeoutMs: Int64 = -1 ) -> ComponentTypesParameters
handleThe handle to a queue.
nThe number of tuples to dequeue.
-
Dequeues a tuple of one or more tensors from the given queue.
This operation has k outputs, where k is the number of components in the tuples stored in the given queue, and output i is the ith component of the dequeued tuple.
N.B. If the queue is empty, this operation will block until an element has been dequeued (or ‘timeout_ms’ elapses, if specified).
Attrs:
- component_types: The type of each component in a tuple.
- timeout_ms: If the queue is empty, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet.
Output components: One or more tensors that were dequeued as a tuple.
Declaration
public static func queueDequeueV2<ComponentTypes: TensorGroup>( handle: ResourceHandle, timeoutMs: Int64 = -1 ) -> ComponentTypesParameters
handleThe handle to a queue.
-
Enqueues zero or more tuples of one or more tensors in the given queue.
This operation slices each component tensor along the 0th dimension to make multiple queue elements. All of the tuple components must have the same size in the 0th dimension.
The components input has k elements, which correspond to the components of tuples stored in the given queue.
N.B. If the queue is full, this operation will block until the given elements have been enqueued (or ‘timeout_ms’ elapses, if specified).
Attr timeout_ms: If the queue is too full, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet.
Declaration
public static func queueEnqueueManyV2<Tcomponents: TensorArrayProtocol>( handle: ResourceHandle, components: Tcomponents, timeoutMs: Int64 = -1 )Parameters
handleThe handle to a queue.
componentsOne or more tensors from which the enqueued tensors should be taken.
-
Enqueues a tuple of one or more tensors in the given queue.
The components input has k elements, which correspond to the components of tuples stored in the given queue.
N.B. If the queue is full, this operation will block until the given element has been enqueued (or ‘timeout_ms’ elapses, if specified).
Attr timeout_ms: If the queue is full, this operation will block for up to timeout_ms milliseconds. Note: This option is not supported yet.
Declaration
public static func queueEnqueueV2<Tcomponents: TensorArrayProtocol>( handle: ResourceHandle, components: Tcomponents, timeoutMs: Int64 = -1 )Parameters
handleThe handle to a queue.
componentsOne or more tensors from which the enqueued tensors should be taken.
-
Returns true if queue is closed.
This operation returns true if the queue is closed and false if the queue is open.
Declaration
public static func queueIsClosedV2( handle: ResourceHandle ) -> Tensor<Bool>Parameters
handleThe handle to a queue.
-
Computes the number of elements in the given queue.
Output size: The number of elements in the given queue.
Declaration
public static func queueSizeV2( handle: ResourceHandle ) -> Tensor<Int32>Parameters
handleThe handle to a queue.
-
Real-valued fast Fourier transform.
Computes the 1-dimensional discrete Fourier transform of a real-valued signal over the inner-most dimension of
input.Since the DFT of a real signal is Hermitian-symmetric,
RFFTonly returns thefft_length / 2 + 1unique components of the FFT: the zero-frequency term, followed by thefft_length / 2positive-frequency terms.Along the axis
RFFTis computed on, iffft_lengthis smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A complex64 tensor of the same rank as
input. The inner-most dimension ofinputis replaced with thefft_length / 2 + 1unique frequency components of its 1D Fourier transform.@compatibility(numpy) Equivalent to np.fft.rfft @end_compatibility
Declaration
public static func rFFT< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Treal>, fftLength: Tensor<Int32> ) -> Tensor<Tcomplex>Parameters
inputA float32 tensor.
fft_lengthAn int32 tensor of shape [1]. The FFT length.
-
2D real-valued fast Fourier transform.
Computes the 2-dimensional discrete Fourier transform of a real-valued signal over the inner-most 2 dimensions of
input.Since the DFT of a real signal is Hermitian-symmetric,
RFFT2Donly returns thefft_length / 2 + 1unique components of the FFT for the inner-most dimension ofoutput: the zero-frequency term, followed by thefft_length / 2positive-frequency terms.Along each axis
RFFT2Dis computed on, iffft_lengthis smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A complex64 tensor of the same rank as
input. The inner-most 2 dimensions ofinputare replaced with their 2D Fourier transform. The inner-most dimension containsfft_length / 2 + 1unique frequency components.@compatibility(numpy) Equivalent to np.fft.rfft2 @end_compatibility
Declaration
public static func rFFT2D< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Treal>, fftLength: Tensor<Int32> ) -> Tensor<Tcomplex>Parameters
inputA float32 tensor.
fft_lengthAn int32 tensor of shape [2]. The FFT length for each dimension.
-
3D real-valued fast Fourier transform.
Computes the 3-dimensional discrete Fourier transform of a real-valued signal over the inner-most 3 dimensions of
input.Since the DFT of a real signal is Hermitian-symmetric,
RFFT3Donly returns thefft_length / 2 + 1unique components of the FFT for the inner-most dimension ofoutput: the zero-frequency term, followed by thefft_length / 2positive-frequency terms.Along each axis
RFFT3Dis computed on, iffft_lengthis smaller than the corresponding dimension ofinput, the dimension is cropped. If it is larger, the dimension is padded with zeros.Output output: A complex64 tensor of the same rank as
input. The inner-most 3 dimensions ofinputare replaced with the their 3D Fourier transform. The inner-most dimension containsfft_length / 2 + 1unique frequency components.@compatibility(numpy) Equivalent to np.fft.rfftn with 3 dimensions. @end_compatibility
Declaration
public static func rFFT3D< Treal: FloatingPoint & TensorFlowScalar, Tcomplex: TensorFlowScalar >( _ input: Tensor<Treal>, fftLength: Tensor<Int32> ) -> Tensor<Tcomplex>Parameters
inputA float32 tensor.
fft_lengthAn int32 tensor of shape [3]. The FFT length for each dimension.
-
Converts one or more images from RGB to HSV.
Outputs a tensor of the same shape as the
imagestensor, containing the HSV value of the pixels. The output is only well defined if the value inimagesare in[0,1].output[..., 0]contains hue,output[..., 1]contains saturation, andoutput[..., 2]contains value. All HSV values are in[0,1]. A hue of 0 corresponds to pure red, hue 1/3 is pure green, and 2/3 is pure blue.Output output:
imagesconverted to HSV.
Declaration
public static func rGBToHSV<T: FloatingPoint & TensorFlowScalar>( images: Tensor<T> ) -> Tensor<T>Parameters
images1-D or higher rank. RGB data to convert. Last dimension must be size 3.
-
Gather ragged slices from
paramsaxis0according toindices.Outputs a
RaggedTensoroutput composed fromoutput_dense_valuesandoutput_nested_splits, such that:output.shape = indices.shape + params.shape[1:] output.ragged_rank = indices.shape.ndims + params.ragged_rank output[i...j, d0...dn] = params[indices[i...j], d0...dn]where
params = ragged.from_nested_row_splits(params_dense_values, params_nested_splits)provides the values that should be gathered.indicesia a dense tensor with dtypeint32orint64, indicating which values should be gathered.output = ragged.from_nested_row_splits(output_dense_values, output_nested_splits)is the output tensor.
(Note: This c++ op is used to implement the higher-level python
tf.ragged.gatherop, which also supports ragged indices.)Attrs:
- PARAMS_RAGGED_RANK: The ragged rank of the
paramsRaggedTensor.params_nested_splitsshould contain this number ofrow_splitstensors. This value should equalparams.ragged_rank. - OUTPUT_RAGGED_RANK: The ragged rank of the output RaggedTensor.
output_nested_splitswill contain this number ofrow_splitstensors. This value should equalindices.shape.ndims + params.ragged_rank - 1.
- PARAMS_RAGGED_RANK: The ragged rank of the
Outputs:
- output_nested_splits: The
nested_row_splitstensors that define the row-partitioning for the returned RaggedTensor. - output_dense_values: The
flat_valuesfor the returned RaggedTensor.
- output_nested_splits: The
Declaration
public static func raggedGather< Tvalues: TensorFlowScalar, Tindices: TensorFlowIndex, Tsplits: TensorFlowIndex >( paramsNestedSplits: [Tensor<Tsplits>], paramsDenseValues: Tensor<Tvalues>, indices: Tensor<Tindices>, oUTPUTRAGGEDRANK: Int64 ) -> (outputNestedSplits: [Tensor<Tsplits>], outputDenseValues: Tensor<Tvalues>)Parameters
params_nested_splitsThe
nested_row_splitstensors that define the row-partitioning for theparamsRaggedTensor input.params_dense_valuesThe
flat_valuesfor theparamsRaggedTensor. There was a terminology change at the python level from dense_values to flat_values, so dense_values is the deprecated name.indicesIndices in the outermost dimension of
paramsof the values that should be gathered. -
Returns a
RaggedTensorcontaining the specified sequences of numbers.Returns a
RaggedTensorresultcomposed fromrt_dense_valuesandrt_nested_splits, such thatresult[i] = range(starts[i], limits[i], deltas[i]).(rt_nested_splits, rt_dense_values) = ragged_range( starts=[2, 5, 8], limits=[3, 5, 12], deltas=1) result = tf.ragged.from_row_splits(rt_dense_values, rt_nested_splits) print(result) <tf.RaggedTensor [[2], [], [8, 9, 10, 11]] >The input tensors
starts,limits, anddeltasmay be scalars or vectors. The vector inputs must all have the same size. Scalar inputs are broadcast to match the size of the vector inputs.Outputs:
- rt_nested_splits: The
row_splitsfor the returnedRaggedTensor. - rt_dense_values: The
flat_valuesfor the returnedRaggedTensor.
- rt_nested_splits: The
Declaration
public static func raggedRange< T: TensorFlowNumeric, Tsplits: TensorFlowIndex >( starts: Tensor<T>, limits: Tensor<T>, deltas: Tensor<T> ) -> (rtNestedSplits: Tensor<Tsplits>, rtDenseValues: Tensor<T>)Parameters
startsThe starts of each range.
limitsThe limits of each range.
deltasThe deltas of each range.
-
Decodes a
variantTensor into aRaggedTensor.Decodes the given
variantTensor and returns aRaggedTensor. The input could be a scalar, meaning it encodes a singleRaggedTensorwith ragged_rankoutput_ragged_rank. It could also have an arbitrary rank, in which case each element is decoded into aRaggedTensorwith ragged_rankinput_ragged_rankand these are then stacked according to the input shape to output a singleRaggedTensorwith ragged_rankoutput_ragged_rank. Eachvariantelement in the input Tensor is decoded by retrieving from the element a 1-DvariantTensor withinput_ragged_rank + 1Tensors, corresponding to the splits and values of the decodedRaggedTensor. Ifinput_ragged_rankis -1, then it is inferred asoutput_ragged_rank-rank(encoded_ragged). SeeRaggedTensorToVariantfor the corresponding encoding logic.Attrs:
- input_ragged_rank: The ragged rank of each encoded
RaggedTensorcomponent in the input. If set to -1, this is inferred asoutput_ragged_rank-rank(encoded_ragged) - output_ragged_rank: The expected ragged rank of the output
RaggedTensor. The following must hold:output_ragged_rank = rank(encoded_ragged) + input_ragged_rank.
- input_ragged_rank: The ragged rank of each encoded
Outputs:
- output_nested_splits: A list of one or more Tensors representing the splits of the output
RaggedTensor. - output_dense_values: A Tensor representing the values of the output
RaggedTensor.
- output_nested_splits: A list of one or more Tensors representing the splits of the output
Declaration
public static func raggedTensorFromVariant< Tvalues: TensorFlowScalar, Tsplits: TensorFlowIndex >( encodedRagged: VariantHandle, inputRaggedRank: Int64, outputRaggedRank: Int64 ) -> (outputNestedSplits: [Tensor<Tsplits>], outputDenseValues: Tensor<Tvalues>)Parameters
encoded_raggedA
variantTensor containing encodedRaggedTensors. -
Converts a
RaggedTensorinto aSparseTensorwith the same values.input=ragged.from_nested_row_splits(rt_dense_values, rt_nested_splits) output=SparseTensor(indices=sparse_indices, values=sparse_values, dense_shape=sparse_dense_shape)
Attr RAGGED_RANK: The ragged rank of the input RaggedTensor.
rt_nested_splitsshould contain this number of ragged-splits tensors. This value should equalinput.ragged_rank.Outputs:
- sparse_indices: The indices for the
SparseTensor. - sparse_values: The values of the
SparseTensor. - sparse_dense_shape:
sparse_dense_shapeis a tight bounding box of the inputRaggedTensor.
- sparse_indices: The indices for the
Declaration
public static func raggedTensorToSparse< T: TensorFlowScalar, Tsplits: TensorFlowIndex >( rtNestedSplits: [Tensor<Tsplits>], rtDenseValues: Tensor<T> ) -> (sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseDenseShape: Tensor<Int64>)Parameters
rt_nested_splitsThe
row_splitsfor theRaggedTensor.rt_dense_valuesThe
flat_valuesfor theRaggedTensor. -
Create a dense tensor from a ragged tensor, possibly altering its shape.
The
ragged_to_denseop creates a dense tensor from a list of row partition tensors, a value vector, and default values. If the shape is unspecified, the minimal shape required to contain all the elements in the ragged tensor (the natural shape) will be used. If some dimensions are left unspecified, then the size of the natural shape is used in that dimension.The default_value will be broadcast to the output shape. After that, the values from the ragged tensor overwrite the default values. Note that the default_value must have less dimensions than the value.
The row partition tensors are in the order of the dimensions. At present, the types can be:
- “ROW_SPLITS”: the row_splits tensor from the ragged tensor.
- “VALUE_ROWIDS”: the value_rowids tensor from the ragged tensor.
“FIRST_DIM_SIZE”: if value_rowids is used for the first dimension, then it is preceded by “FIRST_DIM_SIZE”.
Attr row_partition_types: The types of the row partition tensors. At present, these can be:
- “ROW_SPLITS”: the row_splits tensor from the ragged tensor.
- “VALUE_ROWIDS”: the value_rowids tensor from the ragged tensor.
- “FIRST_DIM_SIZE”: if value_rowids is used for the first dimension, then it is preceeded by “FIRST_DIM_SIZE”. The tensors are in the order of the dimensions.
Output result: The resulting dense tensor.
Declaration
public static func raggedTensorToTensor< T: TensorFlowScalar, Tindex: TensorFlowIndex, Tshape: TensorFlowIndex >( shape: Tensor<Tshape>, _ values: Tensor<T>, defaultValue: Tensor<T>, rowPartitionTensors: [Tensor<Tindex>], rowPartitionTypes: [String] ) -> Tensor<T>Parameters
shapeThe desired shape of the the output tensor. If left unspecified (empty), the minimal shape required to contain all the elements in the ragged tensor (the natural shape) will be used. If some dimensions are left unspecified, then the size of the natural shape is used in that dimension.
Note that dense dimensions cannot be modified by the shape argument. Trying to change the size of a dense dimension will cause the op to fail. Examples: natural shape: [4, 5, 6] shape: -1 output shape: [4, 5, 6]
natural shape: [4, 5, 6] shape: [3, -1, 2] output shape: [3, 5, 2]
natural shape: [4, 5, 6] shape: [3, 7, 2] output shape: [3, 7, 2]
valuesA 1D tensor representing the values of the ragged tensor.
default_valueThe default_value when the shape is larger than the ragged tensor. The default_value is broadcast until it is the shape of the output tensor, and then overwritten by values in the ragged tensor. The default value must be compatible with this broadcast operation, and must have fewer dimensions than the value tensor.
-
Encodes a
RaggedTensorinto avariantTensor.Encodes the given
RaggedTensorand returns avariantTensor. Ifbatched_inputis True, then inputRaggedTensoris unbatched along the zero-th dimension, each componentRaggedTensoris encoded into a scalarvariantTensor, and these are stacked to return a 1-DvariantTensor. Ifbatched_inputis False, then the inputRaggedTensoris encoded as is and a scalarvariantTensor is returned. ARaggedTensoris encoded by first creating a 1-DvariantTensor withragged_rank + 1elements, containing the splits and values Tensors of theRaggedTensor. Then the 1-DvariantTensor is wrapped in a scalarvariantTensor. SeeRaggedTensorFromVariantfor the corresponding decoding logic.Attr batched_input: A
booldenoting whether the input is a batchedRaggedTensor.Output encoded_ragged: A
variantTensor that containing encodedRaggedTensor.
Declaration
public static func raggedTensorToVariant< Tvalues: TensorFlowScalar, Tsplits: TensorFlowIndex >( rtNestedSplits: [Tensor<Tsplits>], rtDenseValues: Tensor<Tvalues>, batchedInput: Bool ) -> VariantHandleParameters
rt_nested_splitsA list of one or more Tensors representing the splits of the input
RaggedTensor.rt_dense_valuesA Tensor representing the values of the input
RaggedTensor. -
Randomly crop
image.sizeis a 1-D int64 tensor with 2 elements representing the crop height and width. The values must be non negative.This Op picks a random location in
imageand crops aheightbywidthrectangle from that location. The random location is picked so the cropped area will fit inside the original image.Attrs:
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Output output: 3-D of shape
[crop_height, crop_width, channels].
Declaration
public static func randomCrop<T: TensorFlowNumeric>( image: Tensor<T>, size: Tensor<Int64>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<T>Parameters
image3-D of shape
[height, width, channels].size1-D of length 2 containing:
crop_height,crop_width.. -
Creates a Dataset that returns pseudorandom numbers.
Creates a Dataset that returns a stream of uniformly distributed pseudorandom 64-bit signed integers.
In the TensorFlow Python API, you can instantiate this dataset via the class
tf.data.experimental.RandomDataset.Instances of this dataset are also created as a result of the
hoist_random_uniformstatic optimization. Whether this optimization is performed is determined by theexperimental_optimization.hoist_random_uniformoption oftf.data.Options.Declaration
public static func randomDataset( seed: Tensor<Int64>, seed2: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
seedA scalar seed for the random number generator. If either seed or seed2 is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
seed2A second scalar seed to avoid seed collision.
-
Outputs random values from the Gamma distribution(s) described by alpha.
This op uses the algorithm by Marsaglia et al. to acquire samples via transformation-rejection from pairs of uniform and normal random variables. See http://dl.acm.org/citation.cfm?id=358414
Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- seed: If either
Output output: A tensor with shape
shape + shape(alpha). Each slice[:, ..., :, i0, i1, ...iN]contains the samples drawn foralpha[i0, i1, ...iN]. The dtype of the output matches the dtype of alpha.
Declaration
public static func randomGamma< S: TensorFlowIndex, T: FloatingPoint & TensorFlowScalar >( shape: Tensor<S>, alpha: Tensor<T>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<T>Parameters
shape1-D integer tensor. Shape of independent samples to draw from each distribution described by the shape parameters given in alpha.
alphaA tensor in which each scalar is a “shape” parameter describing the associated gamma distribution.
-
Computes the derivative of a Gamma random sample w.r.t.
alpha.Declaration
public static func randomGammaGrad<T: FloatingPoint & TensorFlowScalar>( alpha: Tensor<T>, sample: Tensor<T> ) -> Tensor<T> -
Use RandomPoissonV2 instead.
Declaration
public static func randomPoisson< S: TensorFlowIndex, Dtype: FloatingPoint & TensorFlowScalar >( shape: Tensor<S>, rate: Tensor<Dtype>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype> -
Outputs random values from the Poisson distribution(s) described by rate.
This op uses two algorithms, depending on rate. If rate >= 10, then the algorithm by Hormann is used to acquire samples via transformation-rejection. See http://www.sciencedirect.com/science/article/pii/0167668793909974.
Otherwise, Knuth’s algorithm is used to acquire samples via multiplying uniform random variables. See Donald E. Knuth (1969). Seminumerical Algorithms. The Art of Computer Programming, Volume 2. Addison Wesley
Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- seed: If either
Output output: A tensor with shape
shape + shape(rate). Each slice[:, ..., :, i0, i1, ...iN]contains the samples drawn forrate[i0, i1, ...iN].
Declaration
public static func randomPoissonV2< S: TensorFlowIndex, R: TensorFlowNumeric, Dtype: TensorFlowNumeric >( shape: Tensor<S>, rate: Tensor<R>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype>Parameters
shape1-D integer tensor. Shape of independent samples to draw from each distribution described by the shape parameters given in rate.
rateA tensor in which each scalar is a “rate” parameter describing the associated poisson distribution.
-
Randomly shuffles a tensor along its first dimension.
The tensor is shuffled along dimension 0, such that each
value[j]is mapped to one and only oneoutput[i]. For example, a mapping that might occur for a 3x2 tensor is:[[1, 2], [[5, 6], [3, 4], ==> [1, 2], [5, 6]] [3, 4]]Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- seed: If either
Output output: A tensor of same shape and type as
value, shuffled along its first dimension.
Declaration
public static func randomShuffle<T: TensorFlowScalar>( value: Tensor<T>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<T>Parameters
valueThe tensor to be shuffled.
-
randomShuffleQueueV2(componentTypes:shapes:capacity:minAfterDequeue:seed:seed2:container:sharedName:)
A queue that randomizes the order of elements.
Attrs:
- component_types: The type of each component in a value.
- shapes: The shape of each component in a value. The length of this attr must be either 0 or the same as the length of component_types. If the length of this attr is 0, the shapes of queue elements are not constrained, and only one element may be dequeued at a time.
- capacity: The upper bound on the number of elements in this queue. Negative numbers mean no limit.
- min_after_dequeue: Dequeue will block unless there would be this many elements after the dequeue or the queue is closed. This ensures a minimum level of mixing of elements.
- seed: If either seed or seed2 is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.
- seed2: A second seed to avoid seed collision.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this queue will be shared under the given name across multiple sessions.
Output handle: The handle to the queue.
Declaration
public static func randomShuffleQueueV2( componentTypes: [TensorDataType], shapes: [TensorShape?], capacity: Int64 = -1, minAfterDequeue: Int64 = 0, seed: Int64 = 0, seed2: Int64 = 0, container: String, sharedName: String ) -> ResourceHandle -
Outputs random values from a normal distribution.
The generated values will have mean 0 and standard deviation 1.
Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- dtype: The type of the output.
- seed: If either
Output output: A tensor of the specified shape filled with random normal values.
Declaration
public static func randomStandardNormal< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex >( shape: Tensor<T>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
-
Outputs random values from a uniform distribution.
The generated values follow a uniform distribution in the range
[0, 1). The lower bound 0 is included in the range, while the upper bound 1 is excluded.Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- dtype: The type of the output.
- seed: If either
Output output: A tensor of the specified shape filled with uniform random values.
Declaration
public static func randomUniform< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex >( shape: Tensor<T>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
-
Outputs random integers from a uniform distribution.
The generated values are uniform integers in the range
[minval, maxval). The lower boundminvalis included in the range, while the upper boundmaxvalis excluded.The random integers are slightly biased unless
maxval - minvalis an exact power of two. The bias is small for values ofmaxval - minvalsignificantly smaller than the range of the output (either2^32or2^64).Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- seed: If either
Output output: A tensor of the specified shape filled with uniform random integers.
Declaration
public static func randomUniformInt< Tout: TensorFlowIndex, T: TensorFlowIndex >( shape: Tensor<T>, minval: Tensor<Tout>, maxval: Tensor<Tout>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Tout>Parameters
shapeThe shape of the output tensor.
minval0-D. Inclusive lower bound on the generated integers.
maxval0-D. Exclusive upper bound on the generated integers.
-
Creates a sequence of numbers.
This operation creates a sequence of numbers that begins at
startand extends by increments ofdeltaup to but not includinglimit.For example:
# 'start' is 3 # 'limit' is 18 # 'delta' is 3 tf.range(start, limit, delta) ==> [3, 6, 9, 12, 15]Output output: 1-D.
Declaration
public static func range<Tidx: TensorFlowNumeric>( start: Tensor<Tidx>, limit: Tensor<Tidx>, delta: Tensor<Tidx> ) -> Tensor<Tidx>Parameters
start0-D (scalar). First entry in the sequence.
limit0-D (scalar). Upper limit of sequence, exclusive.
delta0-D (scalar). Optional. Default is 1. Number that increments
start. -
Creates a dataset with a range of values. Corresponds to python’s xrange.
Declaration
public static func rangeDataset( start: Tensor<Int64>, stop: Tensor<Int64>, step: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
startcorresponds to start in python’s xrange().
stopcorresponds to stop in python’s xrange().
stepcorresponds to step in python’s xrange().
-
Returns the rank of a tensor.
This operation returns an integer representing the rank of
input.For example:
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] # shape of tensor 't' is [2, 2, 3] rank(t) ==> 3Note: The rank of a tensor is not the same as the rank of a matrix. The rank of a tensor is the number of indices required to uniquely select each element of the tensor. Rank is also known as “order”, “degree”, or “ndims.”
Declaration
public static func rank<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<Int32> -
Reads and outputs the entire contents of the input filename.
Declaration
public static func readFile( filename: StringTensor ) -> StringTensor -
Reads the value of a variable.
The tensor returned by this operation is immutable.
The value returned by this operation is guaranteed to be influenced by all the writes on which this operation depends directly or indirectly, and to not be influenced by any of the writes which depend directly or indirectly on this operation.
Attr dtype: the dtype of the value.
Declaration
public static func readVariableOp<Dtype: TensorFlowScalar>( resource: ResourceHandle ) -> Tensor<Dtype>Parameters
resourcehandle to the resource in which to store the variable.
-
Returns the number of records this Reader has produced.
This is the same as the number of ReaderRead executions that have succeeded.
Declaration
public static func readerNumRecordsProducedV2( readerHandle: ResourceHandle ) -> Tensor<Int64>Parameters
reader_handleHandle to a Reader.
-
Returns the number of work units this Reader has finished processing.
Declaration
public static func readerNumWorkUnitsCompletedV2( readerHandle: ResourceHandle ) -> Tensor<Int64>Parameters
reader_handleHandle to a Reader.
-
Returns up to
num_records(key, value) pairs produced by a Reader.Will dequeue from the input queue if necessary (e.g. when the Reader needs to start reading from a new file since it has finished with the previous file). It may return less than
num_recordseven before the last batch.Outputs:
- keys: A 1-D tensor.
- values: A 1-D tensor.
Declaration
public static func readerReadUpToV2( readerHandle: ResourceHandle, queueHandle: ResourceHandle, numRecords: Tensor<Int64> ) -> (keys: StringTensor, values: StringTensor)Parameters
reader_handleHandle to a
Reader.queue_handleHandle to a
Queue, with string work items.num_recordsnumber of records to read from
Reader. -
Returns the next record (key, value pair) produced by a Reader.
Will dequeue from the input queue if necessary (e.g. when the Reader needs to start reading from a new file since it has finished with the previous file).
Outputs:
- key: A scalar.
- value: A scalar.
Declaration
public static func readerReadV2( readerHandle: ResourceHandle, queueHandle: ResourceHandle ) -> (key: StringTensor, value: StringTensor)Parameters
reader_handleHandle to a Reader.
queue_handleHandle to a Queue, with string work items.
-
Restore a Reader to its initial clean state.
Declaration
public static func readerResetV2( readerHandle: ResourceHandle )Parameters
reader_handleHandle to a Reader.
-
Restore a reader to a previously saved state.
Not all Readers support being restored, so this can produce an Unimplemented error.
Declaration
public static func readerRestoreStateV2( readerHandle: ResourceHandle, state: StringTensor )Parameters
reader_handleHandle to a Reader.
stateResult of a ReaderSerializeState of a Reader with type matching reader_handle.
-
Produce a string tensor that encodes the state of a Reader.
Not all Readers support being serialized, so this can produce an Unimplemented error.
Declaration
public static func readerSerializeStateV2( readerHandle: ResourceHandle ) -> StringTensorParameters
reader_handleHandle to a Reader.
-
Returns the real part of a complex number.
Given a tensor
inputof complex numbers, this operation returns a tensor of typefloatthat is the real part of each element ininput. All elements ininputmust be complex numbers of the form \(a + bj\), where a is the real part returned by this operation and b is the imaginary part.For example:
# tensor 'input' is [-2.25 + 4.75j, 3.25 + 5.75j] tf.real(input) ==> [-2.25, 3.25]Declaration
public static func real< T: TensorFlowScalar, Tout: FloatingPoint & TensorFlowScalar >( _ input: Tensor<T> ) -> Tensor<Tout> -
Returns x / y element-wise for real types.
If
xandyare reals, this will return the floating-point division.NOTE:
Divsupports broadcasting. More about broadcasting hereDeclaration
public static func realDiv<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Creates a dataset that changes the batch size.
Creates a dataset that changes the batch size of the dataset to current batch size // num_workers.
Declaration
public static func rebatchDataset( inputDataset: VariantHandle, numReplicas: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?], useFallback: Bool = true ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
num_replicasA scalar representing the number of replicas to distribute this batch across. As a result of this transformation the current batch size would end up being divided by this parameter.
-
Computes the reciprocal of x element-wise.
I.e., \(y = 1 / x\).
Declaration
public static func reciprocal<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient for the inverse of
xwrt its input.Specifically,
grad = -dy * y*y, wherey = 1/x, anddyis the corresponding input gradient.Declaration
public static func reciprocalGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
recordInput(filePattern:fileRandomSeed:fileShuffleShiftRatio:fileBufferSize:fileParallelism:batchSize:compressionType:)
Emits randomized records.
Attrs:
- file_pattern: Glob pattern for the data files.
- file_random_seed: Random seeds used to produce randomized records.
- file_shuffle_shift_ratio: Shifts the list of files after the list is randomly shuffled.
- file_buffer_size: The randomization shuffling buffer.
- file_parallelism: How many sstables are opened and concurrently iterated over.
- batch_size: The batch size.
- compression_type: The type of compression for the file. Currently ZLIB and GZIP are supported. Defaults to none.
Output records: A tensor of shape [batch_size].
Declaration
public static func recordInput( filePattern: String, fileRandomSeed: Int64 = 301, fileShuffleShiftRatio: Double = 0, fileBufferSize: Int64 = 10000, fileParallelism: Int64 = 16, batchSize: Int64 = 32, compressionType: String ) -> StringTensor -
Receives the named tensor from send_device on recv_device.
Attrs:
- tensor_name: The name of the tensor to receive.
- send_device: The name of the device sending the tensor.
- send_device_incarnation: The current incarnation of send_device.
- recv_device: The name of the device receiving the tensor.
- client_terminated: If set to true, this indicates that the node was added to the graph as a result of a client-side feed or fetch of Tensor data, in which case the corresponding send or recv is expected to be managed locally by the caller.
Output tensor: The tensor to receive.
Declaration
public static func recv<TensorType: TensorFlowScalar>( tensorName: String, sendDevice: String, sendDeviceIncarnation: Int64, recvDevice: String, clientTerminated: Bool = false ) -> Tensor<TensorType> -
An op that receives embedding activations on the TPU.
The TPU system performs the embedding lookups and aggregations specified by the arguments to TPUEmbeddingEnqueue(Integer/Sparse/SparseTensor)Batch. The results of these aggregations are visible to the Tensorflow Graph as the outputs of a RecvTPUEmbeddingActivations op. This op returns a list containing one Tensor of activations per table specified in the model. There can be at most one RecvTPUEmbeddingActivations op in the TPU graph.
Attrs:
- num_outputs: The number of output activation tensors, equal to the number of embedding tables in the model.
- config: Serialized TPUEmbeddingConfiguration proto.
Output outputs: A TensorList of embedding activations containing one Tensor per embedding table in the model.
Declaration
public static func recvTPUEmbeddingActivations( numOutputs: Int64, config: String ) -> [Tensor<Float>] -
Reduces the input dataset to a singleton using a reduce function.
Attr f: A function that maps
(old_state, input_element)tonew_state. It must take two arguments and return a nested structures of tensors. The structure ofnew_statemust match the structure ofinitial_state.
Declaration
public static func reduceDataset< FIn: TensorGroup, FOut: TensorGroup, Tstate: TensorArrayProtocol, Targuments: TensorArrayProtocol, OutputTypes: TensorGroup >( inputDataset: VariantHandle, initialState: Tstate, otherArguments: Targuments, f: (FIn) -> FOut, outputShapes: [TensorShape?], useInterOpParallelism: Bool = true ) -> OutputTypesParameters
input_datasetA variant tensor representing the input dataset.
initial_stateA nested structure of tensors, representing the initial state of the transformation.
-
Joins a string Tensor across the given dimensions.
Computes the string join across dimensions in the given string Tensor of shape
[\\(d_0, d_1, ..., d_{n-1}\\)]. Returns a new Tensor created by joining the input strings with the given separator (default: empty string). Negative indices are counted backwards from the end, with-1being equivalent ton - 1. If indices are not specified, joins across all dimensions beginning fromn - 1through0.For example:
# tensor `a` is [["a", "b"], ["c", "d"]] tf.reduce_join(a, 0) ==> ["ac", "bd"] tf.reduce_join(a, 1) ==> ["ab", "cd"] tf.reduce_join(a, -2) = tf.reduce_join(a, 0) ==> ["ac", "bd"] tf.reduce_join(a, -1) = tf.reduce_join(a, 1) ==> ["ab", "cd"] tf.reduce_join(a, 0, keep_dims=True) ==> [["ac", "bd"]] tf.reduce_join(a, 1, keep_dims=True) ==> [["ab"], ["cd"]] tf.reduce_join(a, 0, separator=".") ==> ["a.c", "b.d"] tf.reduce_join(a, [0, 1]) ==> "acbd" tf.reduce_join(a, [1, 0]) ==> "abcd" tf.reduce_join(a, []) ==> [["a", "b"], ["c", "d"]] tf.reduce_join(a) = tf.reduce_join(a, [1, 0]) ==> "abcd"Attrs:
- keep_dims: If
True, retain reduced dimensions with length1. - separator: The separator to use when joining.
- keep_dims: If
Output output: Has shape equal to that of the input with reduced dimensions removed or set to
1depending onkeep_dims.
Declaration
public static func reduceJoin( inputs: StringTensor, reductionIndices: Tensor<Int32>, keepDims: Bool = false, separator: String ) -> StringTensorParameters
inputsThe input to be joined. All reduced indices must have non-zero size.
reduction_indicesThe dimensions to reduce over. Dimensions are reduced in the order specified. Omitting
reduction_indicesis equivalent to passing[n-1, n-2, ..., 0]. Negative indices from-nto-1are supported. -
Check if the input matches the regex pattern.
The input is a string tensor of any shape. The pattern is a scalar string tensor which is applied to every element of the input tensor. The boolean values (True or False) of the output tensor indicate if the input matches the regex pattern provided.
The pattern follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
Output output: A bool tensor with the same shape as
input.
Declaration
public static func regexFullMatch( _ input: StringTensor, pattern: StringTensor ) -> Tensor<Bool>Parameters
inputA string tensor of the text to be processed.
patternA scalar string tensor containing the regular expression to match the input.
-
Replaces matches of the
patternregular expression ininputwith the replacement string provided inrewrite.It follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
Attr replace_global: If True, the replacement is global (that is, all matches of the
patternregular expression in each input string are rewritten), otherwise therewritesubstitution is only made for the firstpatternmatch.Output output: The text after applying pattern match and rewrite substitution.
Declaration
public static func regexReplace( _ input: StringTensor, pattern: StringTensor, rewrite: StringTensor, replaceGlobal: Bool = true ) -> StringTensorParameters
inputThe text to be processed.
patternThe regular expression to be matched in the
inputstrings.rewriteThe rewrite string to be substituted for the
patternexpression where it is matched in theinputstrings. -
Computes rectified linear:
max(features, 0).See: https://en.wikipedia.org/wiki/Rectifier_(neural_networks) Example usage:
tf.nn.relu([-2., 0., -0., 3.]).numpy() array([ 0., 0., -0., 3.], dtype=float32)
Declaration
public static func relu<T: TensorFlowNumeric>( features: Tensor<T> ) -> Tensor<T> -
Computes rectified linear 6:
min(max(features, 0), 6).Declaration
public static func relu6<T: TensorFlowNumeric>( features: Tensor<T> ) -> Tensor<T> -
Computes rectified linear 6 gradients for a Relu6 operation.
Output backprops: The gradients:
gradients * (features > 0) * (features < 6).
Declaration
public static func relu6Grad<T: TensorFlowNumeric>( gradients: Tensor<T>, features: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding Relu6 operation.
featuresThe features passed as input to the corresponding Relu6 operation, or its output; using either one produces the same result.
-
Computes rectified linear gradients for a Relu operation.
Output backprops:
gradients * (features > 0).
Declaration
public static func reluGrad<T: TensorFlowNumeric>( gradients: Tensor<T>, features: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding Relu operation.
featuresThe features passed as input to the corresponding Relu operation, OR the outputs of that operation (both work equivalently).
-
Runs function
fon a remote device indicated bytarget.Attrs:
- Tin: The type list for the arguments.
- Tout: The type list for the return values.
- f: The function to run remotely.
Output output: A list of return values.
Declaration
public static func remoteCall< Tin: TensorArrayProtocol, Tout: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( target: StringTensor, args: Tin, f: (FIn) -> FOut ) -> ToutParameters
targetA fully specified device name where we want to run the function.
argsA list of arguments for the function.
-
Execute a sub graph on a remote processor.
The graph specifications(such as graph itself, input tensors and output names) are stored as a serialized protocol buffer of RemoteFusedGraphExecuteInfo as serialized_remote_fused_graph_execute_info. The specifications will be passed to a dedicated registered remote fused graph executor. The executor will send the graph specifications to a remote processor and execute that graph. The execution results will be passed to consumer nodes as outputs of this node.
Attr serialized_remote_fused_graph_execute_info: Serialized protocol buffer of RemoteFusedGraphExecuteInfo which contains graph specifications.
Output outputs: Arbitrary number of tensors with arbitrary data types
Declaration
public static func remoteFusedGraphExecute< Tinputs: TensorArrayProtocol, Toutputs: TensorGroup >( inputs: Tinputs, serializedRemoteFusedGraphExecuteInfo: String ) -> ToutputsParameters
inputsArbitrary number of tensors with arbitrary data types
-
Creates a dataset that emits the outputs of
input_datasetcounttimes.Declaration
public static func repeatDataset( inputDataset: VariantHandle, count: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
countA scalar representing the number of times that
input_datasetshould be repeated. A value of-1indicates that it should be repeated infinitely. -
Computes a range that covers the actual values present in a quantized tensor.
Given a quantized tensor described by
(input, input_min, input_max), outputs a range that covers the actual values present in that tensor. This op is typically used to produce therequested_output_minandrequested_output_maxforRequantize.Attr Tinput: The type of the input.
Outputs:
- output_min: The computed min output.
- output_max: the computed max output.
Declaration
Parameters
input_minThe float value that the minimum quantized input value represents.
input_maxThe float value that the maximum quantized input value represents.
-
Computes requantization range per channel.
Attrs:
- T: The quantized type of input tensor that needs to be converted.
- clip_value_max: The maximum value of the output that needs to be clipped. Example: set this to 6 for Relu6.
Outputs:
- output_min: The minimum value of the final output tensor
- output_max: The maximum value of the final output tensor.
Declaration
Parameters
inputThe original input tensor.
input_minThe minimum value of the input tensor
input_maxThe maximum value of the input tensor.
-
Converts the quantized
inputtensor into a lower-precisionoutput.Converts the quantized
inputtensor into a lower-precisionoutput, using the output range specified withrequested_output_minandrequested_output_max.[input_min, input_max]are scalar floats that specify the range for the float interpretation of theinputdata. For example, ifinput_minis -1.0f andinput_maxis 1.0f, and we are dealing withquint16quantized data, then a 0 value in the 16-bit data should be interpreted as -1.0f, and a 65535 means 1.0f.Attrs:
- Tinput: The type of the input.
- out_type: The type of the output. Should be a lower bit depth than Tinput.
Outputs:
- output_min: The requested_output_min value is copied into this output.
- output_max: The requested_output_max value is copied into this output.
Declaration
public static func requantize< Tinput: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<Tinput>, inputMin: Tensor<Float>, inputMax: Tensor<Float>, requestedOutputMin: Tensor<Float>, requestedOutputMax: Tensor<Float> ) -> (output: Tensor<OutType>, outputMin: Tensor<Float>, outputMax: Tensor<Float>)Parameters
input_minThe float value that the minimum quantized input value represents.
input_maxThe float value that the maximum quantized input value represents.
requested_output_minThe float value that the minimum quantized output value represents.
requested_output_maxThe float value that the maximum quantized output value represents.
-
Requantizes input with min and max values known per channel.
Attrs:
- T: The quantized type of input tensor that needs to be converted.
- out_type: The quantized type of output tensor that needs to be converted.
Outputs:
- output: Output tensor.
- output_min: The minimum value of the final output tensor
- output_max: The maximum value of the final output tensor.
Declaration
public static func requantizePerChannel< T: TensorFlowScalar, OutType: TensorFlowScalar >( _ input: Tensor<T>, inputMin: Tensor<Float>, inputMax: Tensor<Float>, requestedOutputMin: Tensor<Float>, requestedOutputMax: Tensor<Float> ) -> (output: Tensor<OutType>, outputMin: Tensor<Float>, outputMax: Tensor<Float>)Parameters
inputThe original input tensor.
input_minThe minimum value of the input tensor
input_maxThe maximum value of the input tensor.
requested_output_minThe minimum value of the output tensor requested.
requested_output_maxThe maximum value of the output tensor requested.
-
Declaration
public static func requiresOlderGraphVersion() -> Tensor<Int32> -
Declaration
public static func reservedAttr( range: Int64 ) -
Declaration
public static func reservedInput( _ input: Tensor<Int32> ) -
Reshapes a tensor.
Given
tensor, this operation returns a tensor that has the same values astensorwith shapeshape.If one component of 1-D tensor
shapeis the special value -1, the size of that dimension is computed so that the total size remains constant. In particular, ashapeof[-1]flattens into 1-D. At most one component ofshapemay be unknown.The
shapemust be 1-D and the operation returns a tensor with shapeshapefilled with the values oftensor. In this case, the number of elements implied byshapemust be the same as the number of elements intensor.It is an error if
shapeis not 1-D.For example:
# tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9] # tensor 't' has shape [9] reshape(t, [3, 3]) ==> [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # tensor 't' is [[[1, 1], [2, 2]], # [[3, 3], [4, 4]]] # tensor 't' has shape [2, 2, 2] reshape(t, [2, 4]) ==> [[1, 1, 2, 2], [3, 3, 4, 4]] # tensor 't' is [[[1, 1, 1], # [2, 2, 2]], # [[3, 3, 3], # [4, 4, 4]], # [[5, 5, 5], # [6, 6, 6]]] # tensor 't' has shape [3, 2, 3] # pass '[-1]' to flatten 't' reshape(t, [-1]) ==> [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6] # -1 can also be used to infer the shape # -1 is inferred to be 9: reshape(t, [2, -1]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], [4, 4, 4, 5, 5, 5, 6, 6, 6]] # -1 is inferred to be 2: reshape(t, [-1, 9]) ==> [[1, 1, 1, 2, 2, 2, 3, 3, 3], [4, 4, 4, 5, 5, 5, 6, 6, 6]] # -1 is inferred to be 3: reshape(t, [ 2, -1, 3]) ==> [[[1, 1, 1], [2, 2, 2], [3, 3, 3]], [[4, 4, 4], [5, 5, 5], [6, 6, 6]]] # tensor 't' is [7] # shape `[]` reshapes to a scalar reshape(t, []) ==> 7Declaration
public static func reshape< T: TensorFlowScalar, Tshape: TensorFlowIndex >( _ tensor: Tensor<T>, shape: Tensor<Tshape> ) -> Tensor<T>Parameters
shapeDefines the shape of the output tensor.
-
Resize
imagestosizeusing area interpolation.Input images can be of different types but output images are always float.
The range of pixel values for the output image might be slightly different from the range for the input image because of limited numerical precision. To guarantee an output range, for example
[0.0, 1.0], applytf.clip_by_valueto the output.Each output pixel is computed by first transforming the pixel’s footprint into the input tensor and then averaging the pixels that intersect the footprint. An input pixel’s contribution to the average is weighted by the fraction of its area that intersects the footprint. This is the same as OpenCV’s INTER_AREA.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
Output resized_images: 4-D with shape
[batch, new_height, new_width, channels].
Declaration
public static func resizeArea<T: TensorFlowNumeric>( images: Tensor<T>, size: Tensor<Int32>, alignCorners: Bool = false ) -> Tensor<Float>Parameters
images4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images. -
Resize
imagestosizeusing bicubic interpolation.Input images can be of different types but output images are always float.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
Output resized_images: 4-D with shape
[batch, new_height, new_width, channels].
Declaration
public static func resizeBicubic<T: TensorFlowNumeric>( images: Tensor<T>, size: Tensor<Int32>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<Float>Parameters
images4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images. -
Computes the gradient of bicubic interpolation.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and grad tensors are aligned. Defaults to false.
Output output: 4-D with shape
[batch, orig_height, orig_width, channels]. Gradients with respect to the input image. Input image must have been float or double.
Declaration
public static func resizeBicubicGrad<T: FloatingPoint & TensorFlowScalar>( grads: Tensor<Float>, originalImage: Tensor<T>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<T>Parameters
grads4-D with shape
[batch, height, width, channels].original_image4-D with shape
[batch, orig_height, orig_width, channels], The image tensor that was resized. -
Resize
imagestosizeusing bilinear interpolation.Input images can be of different types but output images are always float.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
Output resized_images: 4-D with shape
[batch, new_height, new_width, channels].
Declaration
public static func resizeBilinear<T: TensorFlowNumeric>( images: Tensor<T>, size: Tensor<Int32>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<Float>Parameters
images4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images. -
Computes the gradient of bilinear interpolation.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and grad tensors are aligned. Defaults to false.
Output output: 4-D with shape
[batch, orig_height, orig_width, channels]. Gradients with respect to the input image. Input image must have been float or double.
Declaration
public static func resizeBilinearGrad<T: FloatingPoint & TensorFlowScalar>( grads: Tensor<Float>, originalImage: Tensor<T>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<T>Parameters
grads4-D with shape
[batch, height, width, channels].original_image4-D with shape
[batch, orig_height, orig_width, channels], The image tensor that was resized. -
Resize
imagestosizeusing nearest neighbor interpolation.Attr align_corners: If true, the centers of the 4 corner pixels of the input and output tensors are aligned, preserving the values at the corner pixels. Defaults to false.
Output resized_images: 4-D with shape
[batch, new_height, new_width, channels].
Declaration
public static func resizeNearestNeighbor<T: TensorFlowNumeric>( images: Tensor<T>, size: Tensor<Int32>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<T>Parameters
images4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
new_height, new_width. The new size for the images. -
Computes the gradient of nearest neighbor interpolation.
Attr align_corners: If true, the centers of the 4 corner pixels of the input and grad tensors are aligned. Defaults to false.
Output output: 4-D with shape
[batch, orig_height, orig_width, channels]. Gradients with respect to the input image.
Declaration
public static func resizeNearestNeighborGrad<T: TensorFlowNumeric>( grads: Tensor<T>, size: Tensor<Int32>, alignCorners: Bool = false, halfPixelCenters: Bool = false ) -> Tensor<T>Parameters
grads4-D with shape
[batch, height, width, channels].size= A 1-D int32 Tensor of 2 elements:
orig_height, orig_width. The original input size. -
Applies a gradient to a given accumulator.
Does not add if local_step is lesser than the accumulator’s global_step.
Attr dtype: The data type of accumulated gradients. Needs to correspond to the type of the accumulator.
Declaration
public static func resourceAccumulatorApplyGradient<Dtype: TensorFlowNumeric>( handle: ResourceHandle, localStep: Tensor<Int64>, gradient: Tensor<Dtype> )Parameters
handleThe handle to a accumulator.
local_stepThe local_step value at which the gradient was computed.
gradientA tensor of the gradient to be accumulated.
-
Returns the number of gradients aggregated in the given accumulators.
Output num_accumulated: The number of gradients aggregated in the given accumulator.
Declaration
public static func resourceAccumulatorNumAccumulated( handle: ResourceHandle ) -> Tensor<Int32>Parameters
handleThe handle to an accumulator.
-
Updates the accumulator with a new value for global_step.
Logs warning if the accumulator’s value is already higher than new_global_step.
Declaration
public static func resourceAccumulatorSetGlobalStep( handle: ResourceHandle, newGlobalStep: Tensor<Int64> )Parameters
handleThe handle to an accumulator.
new_global_stepThe new global_step value to set.
-
Extracts the average gradient in the given ConditionalAccumulator.
The op blocks until sufficient (i.e., more than num_required) gradients have been accumulated. If the accumulator has already aggregated more than num_required gradients, it returns the average of the accumulated gradients. Also automatically increments the recorded global_step in the accumulator by 1, and resets the aggregate to 0.
Attr dtype: The data type of accumulated gradients. Needs to correspond to the type of the accumulator.
Output average: The average of the accumulated gradients.
Declaration
public static func resourceAccumulatorTakeGradient<Dtype: TensorFlowNumeric>( handle: ResourceHandle, numRequired: Tensor<Int32> ) -> Tensor<Dtype>Parameters
handleThe handle to an accumulator.
num_requiredNumber of gradients required before we return an aggregate.
-
Update ‘*var’ according to the AdaMax algorithm.
m_t <- beta1 * m_{t-1} + (1 - beta1) * g v_t <- max(beta2 * v_{t-1}, abs(g)) variable <- variable - learning_rate / (1 - beta1^t) * m_t / (v_t + epsilon)
Attr use_locking: If
True, updating of the var, m, and v tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdaMax<T: TensorFlowNumeric>( var_: ResourceHandle, m: ResourceHandle, v: ResourceHandle, beta1Power: Tensor<T>, lr: Tensor<T>, beta1: Tensor<T>, beta2: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mShould be from a Variable().
vShould be from a Variable().
beta1_powerMust be a scalar.
lrScaling factor. Must be a scalar.
beta1Momentum factor. Must be a scalar.
beta2Momentum factor. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
-
Update ‘*var’ according to the adadelta scheme.
accum = rho() * accum + (1 - rho()) * grad.square(); update = (update_accum + epsilon).sqrt() * (accum + epsilon()).rsqrt() * grad; update_accum = rho() * update_accum + (1 - rho()) * update.square(); var -= update;
Attr use_locking: If True, updating of the var, accum and update_accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdadelta<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, accumUpdate: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
accum_updateShould be from a Variable().
lrScaling factor. Must be a scalar.
rhoDecay factor. Must be a scalar.
epsilonConstant factor. Must be a scalar.
gradThe gradient.
-
Update ‘*var’ according to the adagrad scheme.
accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdagrad<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false, updateSlots: Bool = true )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrScaling factor. Must be a scalar.
gradThe gradient.
-
resourceApplyAdagradDA(var_:gradientAccumulator:gradientSquaredAccumulator:grad:lr:l1:l2:globalStep:useLocking:)
Update ‘*var’ according to the proximal adagrad scheme.
Attr use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdagradDA<T: TensorFlowNumeric>( var_: ResourceHandle, gradientAccumulator: ResourceHandle, gradientSquaredAccumulator: ResourceHandle, grad: Tensor<T>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, globalStep: Tensor<Int64>, useLocking: Bool = false )Parameters
varShould be from a Variable().
gradient_accumulatorShould be from a Variable().
gradient_squared_accumulatorShould be from a Variable().
gradThe gradient.
lrScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
global_stepTraining step number. Must be a scalar.
-
Update ‘*var’ according to the adagrad scheme.
accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdagradV2<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false, updateSlots: Bool = true )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrScaling factor. Must be a scalar.
epsilonConstant factor. Must be a scalar.
gradThe gradient.
-
resourceApplyAdam(var_:m:v:beta1Power:beta2Power:lr:beta1:beta2:epsilon:grad:useLocking:useNesterov:)
Update ‘*var’ according to the Adam algorithm.
$$\text{lr}t := \mathrm{learning_rate} * \sqrt{1 - \beta_2^t} / (1 - \beta_1^t)$$ $$m_t := \beta_1 * m{t-1} + (1 - \beta_1) * g$$ $$v_t := \beta_2 * v_{t-1} + (1 - \beta_2) * g * g$$ $$\text{variable} := \text{variable} - \text{lr}_t * m_t / (\sqrt{v_t} + \epsilon)$$
Attrs:
- use_locking: If
True, updating of the var, m, and v tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. - use_nesterov: If
True, uses the nesterov update.
- use_locking: If
Declaration
public static func resourceApplyAdam<T: TensorFlowNumeric>( var_: ResourceHandle, m: ResourceHandle, v: ResourceHandle, beta1Power: Tensor<T>, beta2Power: Tensor<T>, lr: Tensor<T>, beta1: Tensor<T>, beta2: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false, useNesterov: Bool = false )Parameters
varShould be from a Variable().
mShould be from a Variable().
vShould be from a Variable().
beta1_powerMust be a scalar.
beta2_powerMust be a scalar.
lrScaling factor. Must be a scalar.
beta1Momentum factor. Must be a scalar.
beta2Momentum factor. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
-
resourceApplyAdamWithAmsgrad(var_:m:v:vhat:beta1Power:beta2Power:lr:beta1:beta2:epsilon:grad:useLocking:)
Update ‘*var’ according to the Adam algorithm.
$$\text{lr}t := \mathrm{learning_rate} * \sqrt{1 - \beta_2^t} / (1 - \beta_1^t)$$ $$m_t := \beta_1 * m{t-1} + (1 - \beta_1) * g$$ $$v_t := \beta_2 * v_{t-1} + (1 - \beta_2) * g * g$$ $$\hat{v}t := max{\hat{v}{t-1}, v_t}$$ $$\text{variable} := \text{variable} - \text{lr}_t * m_t / (\sqrt{\hat{v}_t} + \epsilon)$$
Attr use_locking: If
True, updating of the var, m, and v tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAdamWithAmsgrad<T: TensorFlowNumeric>( var_: ResourceHandle, m: ResourceHandle, v: ResourceHandle, vhat: ResourceHandle, beta1Power: Tensor<T>, beta2Power: Tensor<T>, lr: Tensor<T>, beta1: Tensor<T>, beta2: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mShould be from a Variable().
vShould be from a Variable().
vhatShould be from a Variable().
beta1_powerMust be a scalar.
beta2_powerMust be a scalar.
lrScaling factor. Must be a scalar.
beta1Momentum factor. Must be a scalar.
beta2Momentum factor. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
-
Update ‘*var’ according to the AddSign update.
m_t <- beta1 * m_{t-1} + (1 - beta1) * g update <- (alpha + sign_decay * sign(g) *sign(m)) * g variable <- variable - lr_t * update
Attr use_locking: If
True, updating of the var and m tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyAddSign<T: TensorFlowNumeric>( var_: ResourceHandle, m: ResourceHandle, lr: Tensor<T>, alpha: Tensor<T>, signDecay: Tensor<T>, beta: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mShould be from a Variable().
lrScaling factor. Must be a scalar.
alphaMust be a scalar.
sign_decayMust be a scalar.
betaMust be a scalar.
gradThe gradient.
-
Update ‘*var’ according to the centered RMSProp algorithm.
The centered RMSProp algorithm uses an estimate of the centered second moment (i.e., the variance) for normalization, as opposed to regular RMSProp, which uses the (uncentered) second moment. This often helps with training, but is slightly more expensive in terms of computation and memory.
Note that in dense implementation of this algorithm, mg, ms, and mom will update even if the grad is zero, but in this sparse implementation, mg, ms, and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 mean_grad = decay * mean_grad + (1-decay) * gradient
Delta = learning_rate * gradient / sqrt(mean_square + epsilon - mean_grad ** 2)
mg <- rho * mg_{t-1} + (1-rho) * grad ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms - mg * mg + epsilon) var <- var - mom
Attr use_locking: If
True, updating of the var, mg, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyCenteredRMSProp<T: TensorFlowNumeric>( var_: ResourceHandle, mg: ResourceHandle, ms: ResourceHandle, mom: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, momentum: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mgShould be from a Variable().
msShould be from a Variable().
momShould be from a Variable().
lrScaling factor. Must be a scalar.
rhoDecay rate. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
-
Update ‘*var’ according to the Ftrl-proximal scheme.
accum_new = accum + grad * grad linear += grad - (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyFtrl<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, linear: ResourceHandle, grad: Tensor<T>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, lrPower: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
linearShould be from a Variable().
gradThe gradient.
lrScaling factor. Must be a scalar.
l1L1 regulariation. Must be a scalar.
l2L2 regulariation. Must be a scalar.
lr_powerScaling factor. Must be a scalar.
-
Update ‘*var’ according to the Ftrl-proximal scheme.
grad_with_shrinkage = grad + 2 * l2_shrinkage * var accum_new = accum + grad_with_shrinkage * grad_with_shrinkage linear += grad_with_shrinkage + (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyFtrlV2<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, linear: ResourceHandle, grad: Tensor<T>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, l2Shrinkage: Tensor<T>, lrPower: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
linearShould be from a Variable().
gradThe gradient.
lrScaling factor. Must be a scalar.
l1L1 regulariation. Must be a scalar.
l2L2 shrinkage regulariation. Must be a scalar.
lr_powerScaling factor. Must be a scalar.
-
Update ‘*var’ by subtracting ‘alpha’ * ‘delta’ from it.
Attr use_locking: If
True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyGradientDescent<T: TensorFlowNumeric>( var_: ResourceHandle, alpha: Tensor<T>, delta: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
alphaScaling factor. Must be a scalar.
deltaThe change.
-
Update ‘*var’ according to the momentum scheme.
Set use_nesterov = True if you want to use Nesterov momentum.
accum = accum * momentum - lr * grad var += accum
Attrs:
- use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. - use_nesterov: If
True, the tensor passed to compute grad will be var + momentum * accum, so in the end, the var you get is actually var + momentum * accum.
- use_locking: If
Declaration
public static func resourceApplyKerasMomentum<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, momentum: Tensor<T>, useLocking: Bool = false, useNesterov: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrScaling factor. Must be a scalar.
gradThe gradient.
momentumMomentum. Must be a scalar.
-
Update ‘*var’ according to the momentum scheme. Set use_nesterov = True if you
want to use Nesterov momentum.
accum = accum * momentum + grad var -= lr * accum
Attrs:
- use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. - use_nesterov: If
True, the tensor passed to compute grad will be var - lr * momentum * accum, so in the end, the var you get is actually var - lr * momentum * accum.
- use_locking: If
Declaration
public static func resourceApplyMomentum<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, momentum: Tensor<T>, useLocking: Bool = false, useNesterov: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrScaling factor. Must be a scalar.
gradThe gradient.
momentumMomentum. Must be a scalar.
-
Update ‘*var’ according to the AddSign update.
m_t <- beta1 * m_{t-1} + (1 - beta1) * g update <- exp(logbase * sign_decay * sign(g) * sign(m_t)) * g variable <- variable - lr_t * update
Attr use_locking: If
True, updating of the var and m tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyPowerSign<T: TensorFlowNumeric>( var_: ResourceHandle, m: ResourceHandle, lr: Tensor<T>, logbase: Tensor<T>, signDecay: Tensor<T>, beta: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mShould be from a Variable().
lrScaling factor. Must be a scalar.
logbaseMust be a scalar.
sign_decayMust be a scalar.
betaMust be a scalar.
gradThe gradient.
-
Update ‘*var’ and ‘*accum’ according to FOBOS with Adagrad learning rate.
accum += grad * grad prox_v = var - lr * grad * (1 / sqrt(accum)) var = sign(prox_v)/(1+lr*l2) * max{|prox_v|-lr*l1,0}
Attr use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyProximalAdagrad<T: TensorFlowNumeric>( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
gradThe gradient.
-
Update ‘*var’ as FOBOS algorithm with fixed learning rate.
prox_v = var - alpha * delta var = sign(prox_v)/(1+alpha*l2) * max{|prox_v|-alpha*l1,0}
Attr use_locking: If True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyProximalGradientDescent<T: TensorFlowNumeric>( var_: ResourceHandle, alpha: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, delta: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
alphaScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
deltaThe change.
-
Update ‘*var’ according to the RMSProp algorithm.
Note that in dense implementation of this algorithm, ms and mom will update even if the grad is zero, but in this sparse implementation, ms and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 Delta = learning_rate * gradient / sqrt(mean_square + epsilon)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Attr use_locking: If
True, updating of the var, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceApplyRMSProp<T: TensorFlowNumeric>( var_: ResourceHandle, ms: ResourceHandle, mom: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, momentum: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
msShould be from a Variable().
momShould be from a Variable().
lrScaling factor. Must be a scalar.
rhoDecay rate. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
-
A conditional accumulator for aggregating gradients.
The accumulator accepts gradients marked with local_step greater or equal to the most recent global_step known to the accumulator. The average can be extracted from the accumulator, provided sufficient gradients have been accumulated. Extracting the average automatically resets the aggregate to 0, and increments the global_step recorded by the accumulator. This is a resource version of ConditionalAccumulator that will work in TF2.0 with tf.cond version 2.
Attrs:
- dtype: The type of the value being accumulated.
- shape: The shape of the values, can be [], in which case shape is unknown.
- container: If non-empty, this accumulator is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this accumulator will be shared under the given name across multiple sessions.
Output handle: The handle to the accumulator.
Declaration
public static func resourceConditionalAccumulator( dtype: TensorDataType, shape: TensorShape?, container: String, sharedName: String, reductionType: ReductionType = .mean ) -> ResourceHandle -
Increments variable pointed to by ‘resource’ until it reaches ‘limit’.
Attr limit: If incrementing ref would bring it above limit, instead generates an ‘OutOfRange’ error.
Output output: A copy of the input before increment. If nothing else modifies the input, the values produced will all be distinct.
Declaration
public static func resourceCountUpTo<T: TensorFlowIndex>( resource: ResourceHandle, limit: Int64 ) -> Tensor<T>Parameters
resourceShould be from a scalar
Variablenode. -
Declaration
public static func resourceCreateOp( resource: ResourceHandle ) -
Gather slices from the variable pointed to by
resourceaccording toindices.indicesmust be an integer tensor of any dimension (usually 0-D or 1-D). Produces an output tensor with shapeindices.shape + params.shape[1:]where:# Scalar indices output[:, ..., :] = params[indices, :, ... :] # Vector indices output[i, :, ..., :] = params[indices[i], :, ... :] # Higher rank indices output[i, ..., j, :, ... :] = params[indices[i, ..., j], :, ..., :]Declaration
public static func resourceGather< Dtype: TensorFlowScalar, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, batchDims: Int64 = 0, validateIndices: Bool = true ) -> Tensor<Dtype> -
Declaration
public static func resourceGatherNd< Dtype: TensorFlowScalar, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices> ) -> Tensor<Dtype> -
Declaration
public static func resourceInitializedOp( resource: ResourceHandle ) -> Tensor<Bool> -
Adds sparse updates to the variable referenced by
resource.This operation computes
# Scalar indices ref[indices, ...] += updates[...] # Vector indices (for each i) ref[indices[i], ...] += updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions add.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterAdd< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Divides sparse updates into the variable referenced by
resource.This operation computes
# Scalar indices ref[indices, ...] /= updates[...] # Vector indices (for each i) ref[indices[i], ...] /= updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] /= updates[i, ..., j, ...]Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions multiply.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterDiv< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Reduces sparse updates into the variable referenced by
resourceusing themaxoperation.This operation computes
# Scalar indices ref[indices, ...] = max(ref[indices, ...], updates[...]) # Vector indices (for each i) ref[indices[i], ...] = max(ref[indices[i], ...], updates[i, ...]) # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] = max(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions are combined.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterMax< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Reduces sparse updates into the variable referenced by
resourceusing theminoperation.This operation computes
# Scalar indices ref[indices, ...] = min(ref[indices, ...], updates[...]) # Vector indices (for each i) ref[indices[i], ...] = min(ref[indices[i], ...], updates[i, ...]) # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] = min(ref[indices[i, ..., j], ...], updates[i, ..., j, ...])Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions are combined.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterMin< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Multiplies sparse updates into the variable referenced by
resource.This operation computes
# Scalar indices ref[indices, ...] *= updates[...] # Vector indices (for each i) ref[indices[i], ...] *= updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] *= updates[i, ..., j, ...]Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions multiply.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterMul< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Applies sparse addition to individual values or slices in a Variable.
refis aTensorwith rankPandindicesis aTensorof rankQ.indicesmust be integer tensor, containing indices intoref. It must be shape[d_0, ..., d_{Q-2}, K]where0 < K <= P.The innermost dimension of
indices(with lengthK) corresponds to indices into elements (ifK = P) or slices (ifK < P) along theKth dimension ofref.updatesisTensorof rankQ-1+P-Kwith shape:[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that addition would look like this:
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True) indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) add = tf.scatter_nd_add(ref, indices, updates) with tf.Session() as sess: print sess.run(add)The resulting update to ref would look like this:
[1, 13, 3, 14, 14, 6, 7, 20]See
tf.scatter_ndfor more details about how to make updates to slices.Attr use_locking: An optional bool. Defaults to True. If True, the assignment will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceScatterNdAdd< T: TensorFlowScalar, Tindices: TensorFlowIndex >( ref: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<T>, useLocking: Bool = true )Parameters
refA resource handle. Must be from a VarHandleOp.
indicesA Tensor. Must be one of the following types: int32, int64. A tensor of indices into ref.
updatesA Tensor. Must have the same type as ref. A tensor of values to add to ref.
-
Applies sparse subtraction to individual values or slices in a Variable.
refis aTensorwith rankPandindicesis aTensorof rankQ.indicesmust be integer tensor, containing indices intoref. It must be shape[d_0, ..., d_{Q-2}, K]where0 < K <= P.The innermost dimension of
indices(with lengthK) corresponds to indices into elements (ifK = P) or slices (ifK < P) along theKth dimension ofref.updatesisTensorof rankQ-1+P-Kwith shape:[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]]For example, say we want to subtract 4 scattered elements from a rank-1 tensor with 8 elements. In Python, that subtraction would look like this:
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8], use_resource=True) indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) sub = tf.scatter_nd_sub(ref, indices, updates) with tf.Session() as sess: print sess.run(sub)The resulting update to ref would look like this:
[1, -9, 3, -6, -4, 6, 7, -4]See
tf.scatter_ndfor more details about how to make updates to slices.Attr use_locking: An optional bool. Defaults to True. If True, the assignment will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceScatterNdSub< T: TensorFlowScalar, Tindices: TensorFlowIndex >( ref: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<T>, useLocking: Bool = true )Parameters
refA resource handle. Must be from a VarHandleOp.
indicesA Tensor. Must be one of the following types: int32, int64. A tensor of indices into ref.
updatesA Tensor. Must have the same type as ref. A tensor of values to add to ref.
-
Applies sparse
updatesto individual values or slices within a givenvariable according to
indices.refis aTensorwith rankPandindicesis aTensorof rankQ.indicesmust be integer tensor, containing indices intoref. It must be shape[d_0, ..., d_{Q-2}, K]where0 < K <= P.The innermost dimension of
indices(with lengthK) corresponds to indices into elements (ifK = P) or slices (ifK < P) along theKth dimension ofref.updatesisTensorof rankQ-1+P-Kwith shape:[d_0, ..., d_{Q-2}, ref.shape[K], ..., ref.shape[P-1]].For example, say we want to update 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that update would look like this:
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) indices = tf.constant([[4], [3], [1] ,[7]]) updates = tf.constant([9, 10, 11, 12]) update = tf.scatter_nd_update(ref, indices, updates) with tf.Session() as sess: print sess.run(update)The resulting update to ref would look like this:
[1, 11, 3, 10, 9, 6, 7, 12]See
tf.scatter_ndfor more details about how to make updates to slices.Attr use_locking: An optional bool. Defaults to True. If True, the assignment will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceScatterNdUpdate< T: TensorFlowScalar, Tindices: TensorFlowIndex >( ref: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<T>, useLocking: Bool = true )Parameters
refA resource handle. Must be from a VarHandleOp.
indicesA Tensor. Must be one of the following types: int32, int64. A tensor of indices into ref.
updatesA Tensor. Must have the same type as ref. A tensor of updated values to add to ref.
-
Subtracts sparse updates from the variable referenced by
resource.This operation computes
# Scalar indices ref[indices, ...] -= updates[...] # Vector indices (for each i) ref[indices[i], ...] -= updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] -= updates[i, ..., j, ...]Duplicate entries are handled correctly: if multiple
indicesreference the same location, their contributions add.Requires
updates.shape = indices.shape + ref.shape[1:]orupdates.shape = [].
Declaration
public static func resourceScatterSub< Dtype: TensorFlowNumeric, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
Assigns sparse updates to the variable referenced by
resource.This operation computes
# Scalar indices ref[indices, ...] = updates[...] # Vector indices (for each i) ref[indices[i], ...] = updates[i, ...] # High rank indices (for each i, ..., j) ref[indices[i, ..., j], ...] = updates[i, ..., j, ...]Declaration
public static func resourceScatterUpdate< Dtype: TensorFlowScalar, Tindices: TensorFlowIndex >( resource: ResourceHandle, indices: Tensor<Tindices>, updates: Tensor<Dtype> )Parameters
resourceShould be from a
Variablenode.indicesA tensor of indices into the first dimension of
ref.updatesA tensor of updated values to add to
ref. -
var: Should be from a Variable().
Attr use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyAdadelta< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, accumUpdate: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false )Parameters
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
rhoDecay factor. Must be a scalar.
epsilonConstant factor. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
-
Update relevant entries in ‘*var’ and ‘*accum’ according to the adagrad scheme.
That is for rows we have grad for, we update var and accum as follows: accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyAdagrad< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false, updateSlots: Bool = true )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
-
resourceSparseApplyAdagradDA(var_:gradientAccumulator:gradientSquaredAccumulator:grad:indices:lr:l1:l2:globalStep:useLocking:)
Update entries in ‘*var’ and ‘*accum’ according to the proximal adagrad scheme.
Attr use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyAdagradDA< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, gradientAccumulator: ResourceHandle, gradientSquaredAccumulator: ResourceHandle, grad: Tensor<T>, indices: Tensor<Tindices>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, globalStep: Tensor<Int64>, useLocking: Bool = false )Parameters
varShould be from a Variable().
gradient_accumulatorShould be from a Variable().
gradient_squared_accumulatorShould be from a Variable().
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
lrLearning rate. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
global_stepTraining step number. Must be a scalar.
-
Update relevant entries in ‘*var’ and ‘*accum’ according to the adagrad scheme.
That is for rows we have grad for, we update var and accum as follows: accum += grad * grad var -= lr * grad * (1 / sqrt(accum))
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyAdagradV2< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false, updateSlots: Bool = true )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
epsilonConstant factor. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
-
Update ‘*var’ according to the centered RMSProp algorithm.
The centered RMSProp algorithm uses an estimate of the centered second moment (i.e., the variance) for normalization, as opposed to regular RMSProp, which uses the (uncentered) second moment. This often helps with training, but is slightly more expensive in terms of computation and memory.
Note that in dense implementation of this algorithm, mg, ms, and mom will update even if the grad is zero, but in this sparse implementation, mg, ms, and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 mean_grad = decay * mean_grad + (1-decay) * gradient Delta = learning_rate * gradient / sqrt(mean_square + epsilon - mean_grad ** 2)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Attr use_locking: If
True, updating of the var, mg, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyCenteredRMSProp< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, mg: ResourceHandle, ms: ResourceHandle, mom: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, momentum: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false )Parameters
varShould be from a Variable().
mgShould be from a Variable().
msShould be from a Variable().
momShould be from a Variable().
lrScaling factor. Must be a scalar.
rhoDecay rate. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var, ms and mom.
-
Update relevant entries in ‘*var’ according to the Ftrl-proximal scheme.
That is for rows we have grad for, we update var, accum and linear as follows: accum_new = accum + grad * grad linear += grad - (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyFtrl< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, linear: ResourceHandle, grad: Tensor<T>, indices: Tensor<Tindices>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, lrPower: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
linearShould be from a Variable().
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
lrScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
lr_powerScaling factor. Must be a scalar.
-
Update relevant entries in ‘*var’ according to the Ftrl-proximal scheme.
That is for rows we have grad for, we update var, accum and linear as follows: grad_with_shrinkage = grad + 2 * l2_shrinkage * var accum_new = accum + grad_with_shrinkage * grad_with_shrinkage linear += grad_with_shrinkage + (accum_new^(-lr_power) - accum^(-lr_power)) / lr * var quadratic = 1.0 / (accum_new^(lr_power) * lr) + 2 * l2 var = (sign(linear) * l1 - linear) / quadratic if |linear| > l1 else 0.0 accum = accum_new
Attr use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyFtrlV2< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, linear: ResourceHandle, grad: Tensor<T>, indices: Tensor<Tindices>, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, l2Shrinkage: Tensor<T>, lrPower: Tensor<T>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
linearShould be from a Variable().
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
lrScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 shrinkage regulariation. Must be a scalar.
lr_powerScaling factor. Must be a scalar.
-
Update relevant entries in ‘*var’ and ‘*accum’ according to the momentum scheme.
Set use_nesterov = True if you want to use Nesterov momentum.
That is for rows we have grad for, we update var and accum as follows:
accum = accum * momentum - lr * grad var += accum
Attrs:
- use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. - use_nesterov: If
True, the tensor passed to compute grad will be var + momentum * accum, so in the end, the var you get is actually var + momentum * accum.
- use_locking: If
Declaration
public static func resourceSparseApplyKerasMomentum< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, momentum: Tensor<T>, useLocking: Bool = false, useNesterov: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
momentumMomentum. Must be a scalar.
-
Update relevant entries in ‘*var’ and ‘*accum’ according to the momentum scheme.
Set use_nesterov = True if you want to use Nesterov momentum.
That is for rows we have grad for, we update var and accum as follows:
accum = accum * momentum + grad var -= lr * accum
Attrs:
- use_locking: If
True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention. - use_nesterov: If
True, the tensor passed to compute grad will be var - lr * momentum * accum, so in the end, the var you get is actually var - lr * momentum * accum.
- use_locking: If
Declaration
public static func resourceSparseApplyMomentum< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, momentum: Tensor<T>, useLocking: Bool = false, useNesterov: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
momentumMomentum. Must be a scalar.
-
Sparse update entries in ‘*var’ and ‘*accum’ according to FOBOS algorithm.
That is for rows we have grad for, we update var and accum as follows: accum += grad * grad prox_v = var prox_v -= lr * grad * (1 / sqrt(accum)) var = sign(prox_v)/(1+lr*l2) * max{|prox_v|-lr*l1,0}
Attr use_locking: If True, updating of the var and accum tensors will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyProximalAdagrad< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, accum: ResourceHandle, lr: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false )Parameters
varShould be from a Variable().
accumShould be from a Variable().
lrLearning rate. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
-
Sparse update ‘*var’ as FOBOS algorithm with fixed learning rate.
That is for rows we have grad for, we update var as follows: prox_v = var - alpha * grad var = sign(prox_v)/(1+alpha*l2) * max{|prox_v|-alpha*l1,0}
Attr use_locking: If True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyProximalGradientDescent< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, alpha: Tensor<T>, l1: Tensor<T>, l2: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false )Parameters
varShould be from a Variable().
alphaScaling factor. Must be a scalar.
l1L1 regularization. Must be a scalar.
l2L2 regularization. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var and accum.
-
Update ‘*var’ according to the RMSProp algorithm.
Note that in dense implementation of this algorithm, ms and mom will update even if the grad is zero, but in this sparse implementation, ms and mom will not update in iterations during which the grad is zero.
mean_square = decay * mean_square + (1-decay) * gradient ** 2 Delta = learning_rate * gradient / sqrt(mean_square + epsilon)
ms <- rho * ms_{t-1} + (1-rho) * grad * grad mom <- momentum * mom_{t-1} + lr * grad / sqrt(ms + epsilon) var <- var - mom
Attr use_locking: If
True, updating of the var, ms, and mom tensors is protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.
Declaration
public static func resourceSparseApplyRMSProp< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( var_: ResourceHandle, ms: ResourceHandle, mom: ResourceHandle, lr: Tensor<T>, rho: Tensor<T>, momentum: Tensor<T>, epsilon: Tensor<T>, grad: Tensor<T>, indices: Tensor<Tindices>, useLocking: Bool = false )Parameters
varShould be from a Variable().
msShould be from a Variable().
momShould be from a Variable().
lrScaling factor. Must be a scalar.
rhoDecay rate. Must be a scalar.
epsilonRidge term. Must be a scalar.
gradThe gradient.
indicesA vector of indices into the first dimension of var, ms and mom.
-
resourceStridedSliceAssign(ref:begin:end:strides:value:beginMask:endMask:ellipsisMask:newAxisMask:shrinkAxisMask:)
Assign
valueto the sliced l-value reference ofref.The values of
valueare assigned to the positions in the variablerefthat are selected by the slice parameters. The slice parametersbegin,end,strides, etc. work exactly as inStridedSlice`.NOTE this op currently does not support broadcasting and so
value‘s shape must be exactly the shape produced by the slice ofref.Declaration
public static func resourceStridedSliceAssign< T: TensorFlowScalar, Index: TensorFlowIndex >( ref: ResourceHandle, begin: Tensor<Index>, end: Tensor<Index>, strides: Tensor<Index>, value: Tensor<T>, beginMask: Int64 = 0, endMask: Int64 = 0, ellipsisMask: Int64 = 0, newAxisMask: Int64 = 0, shrinkAxisMask: Int64 = 0 ) -
Declaration
public static func resourceUsingOp( resource: ResourceHandle ) -
Restores a tensor from checkpoint files.
Reads a tensor stored in one or several files. If there are several files (for instance because a tensor was saved as slices),
file_patternmay contain wildcard symbols (*and?) in the filename portion only, not in the directory portion.If a
file_patternmatches several files,preferred_shardcan be used to hint in which file the requested tensor is likely to be found. This op will first open the file at indexpreferred_shardin the list of matching files and try to restore tensors from that file. Only if some tensors or tensor slices are not found in that first file, then the Op opens all the files. Settingpreferred_shardto match the value passed as theshardinput of a matchingSaveOp may speed up Restore. This attribute only affects performance, not correctness. The default value -1 means files are processed in order.See also
RestoreSlice.Attrs:
- dt: The type of the tensor to be restored.
- preferred_shard: Index of file to open first if multiple files match
file_pattern.
Output tensor: The restored tensor.
Declaration
public static func restore<Dt: TensorFlowScalar>( filePattern: StringTensor, tensorName: StringTensor, preferredShard: Int64 = -1 ) -> Tensor<Dt>Parameters
file_patternMust have a single element. The pattern of the files from which we read the tensor.
tensor_nameMust have a single element. The name of the tensor to be restored.
-
Restores a tensor from checkpoint files.
This is like
Restoreexcept that restored tensor can be listed as filling only a slice of a larger tensor.shape_and_slicespecifies the shape of the larger tensor and the slice that the restored tensor covers.The
shape_and_sliceinput has the same format as the elements of theshapes_and_slicesinput of theSaveSlicesop.Attrs:
- dt: The type of the tensor to be restored.
- preferred_shard: Index of file to open first if multiple files match
file_pattern. See the documentation forRestore.
Output tensor: The restored tensor.
Declaration
public static func restoreSlice<Dt: TensorFlowScalar>( filePattern: StringTensor, tensorName: StringTensor, shapeAndSlice: StringTensor, preferredShard: Int64 = -1 ) -> Tensor<Dt>Parameters
file_patternMust have a single element. The pattern of the files from which we read the tensor.
tensor_nameMust have a single element. The name of the tensor to be restored.
shape_and_sliceScalar. The shapes and slice specifications to use when restoring a tensors.
-
Restores tensors from a V2 checkpoint.
For backward compatibility with the V1 format, this Op currently allows restoring from a V1 checkpoint as well:
- This Op first attempts to find the V2 index file pointed to by “prefix”, and if found proceed to read it as a V2 checkpoint;
- Otherwise the V1 read path is invoked. Relying on this behavior is not recommended, as the ability to fall back to read V1 might be deprecated and eventually removed.
By default, restores the named tensors in full. If the caller wishes to restore specific slices of stored tensors, “shape_and_slices” should be non-empty strings and correspondingly well-formed.
Callers must ensure all the named tensors are indeed stored in the checkpoint.
Attr dtypes: shape {N}. The list of expected dtype for the tensors. Must match those stored in the checkpoint.
Output tensors: shape {N}. The restored tensors, whose shapes are read from the checkpoint directly.
Declaration
public static func restoreV2<Dtypes: TensorGroup>( prefix: StringTensor, tensorNames: StringTensor, shapeAndSlices: StringTensor ) -> DtypesParameters
prefixMust have a single element. The prefix of a V2 checkpoint.
tensor_namesshape {N}. The names of the tensors to be restored.
shape_and_slicesshape {N}. The slice specs of the tensors to be restored. Empty strings indicate that they are non-partitioned tensors.
-
Declaration
public static func restrict<T: TensorFlowScalar>( _ a: Tensor<T> ) -> Tensor<T> -
Declaration
public static func restrict( _ a: StringTensor ) -> StringTensor -
Retrieve ADAM embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- momenta: Parameter momenta updated by the ADAM optimization algorithm.
- velocities: Parameter velocities updated by the ADAM optimization algorithm.
- Outputs:
-
Retrieve ADAM embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- momenta: Parameter momenta updated by the ADAM optimization algorithm.
- velocities: Parameter velocities updated by the ADAM optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the ADAM optimization algorithm.
- Outputs:
-
Retrieve Adadelta embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the Adadelta optimization algorithm.
- updates: Parameter updates updated by the Adadelta optimization algorithm.
- Outputs:
-
Retrieve Adadelta embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the Adadelta optimization algorithm.
- updates: Parameter updates updated by the Adadelta optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the Adadelta optimization algorithm.
- Outputs:
-
Retrieve Adagrad embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the Adagrad optimization algorithm.
- Outputs:
-
Retrieve Adagrad embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the Adagrad optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the Adagrad optimization algorithm.
- Outputs:
-
Retrieve centered RMSProp embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- ms: Parameter ms updated by the centered RMSProp optimization algorithm.
- mom: Parameter mom updated by the centered RMSProp optimization algorithm.
- mg: Parameter mg updated by the centered RMSProp optimization algorithm.
- Outputs:
-
Retrieve FTRL embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the FTRL optimization algorithm.
- linears: Parameter linears updated by the FTRL optimization algorithm.
- Outputs:
-
Retrieve FTRL embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the FTRL optimization algorithm.
- linears: Parameter linears updated by the FTRL optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the FTRL optimization algorithm.
- Outputs:
-
Retrieve MDL Adagrad Light embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the MDL Adagrad Light optimization algorithm.
- weights: Parameter weights updated by the MDL Adagrad Light optimization algorithm.
- benefits: Parameter benefits updated by the MDL Adagrad Light optimization algorithm.
- Outputs:
-
Retrieve Momentum embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- momenta: Parameter momenta updated by the Momentum optimization algorithm.
- Outputs:
-
Retrieve Momentum embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- momenta: Parameter momenta updated by the Momentum optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the Momentum optimization algorithm.
- Outputs:
-
Retrieve proximal Adagrad embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the proximal Adagrad optimization algorithm.
- Outputs:
-
retrieveTPUEmbeddingProximalAdagradParametersGradAccumDebug(tableId:tableName:numShards:shardId:config:)
Retrieve proximal Adagrad embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- accumulators: Parameter accumulators updated by the proximal Adagrad optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the proximal Adagrad optimization algorithm.
- Outputs:
-
Retrieve RMSProp embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- ms: Parameter ms updated by the RMSProp optimization algorithm.
- mom: Parameter mom updated by the RMSProp optimization algorithm.
- Outputs:
-
Retrieve RMSProp embedding parameters with debug support.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Outputs:
- ms: Parameter ms updated by the RMSProp optimization algorithm.
- mom: Parameter mom updated by the RMSProp optimization algorithm.
- gradient_accumulators: Parameter gradient_accumulators updated by the RMSProp optimization algorithm.
- Outputs:
-
retrieveTPUEmbeddingStochasticGradientDescentParameters(tableId:tableName:numShards:shardId:config:)
Retrieve SGD embedding parameters.
An op that retrieves optimization parameters from embedding to host memory. Must be preceded by a ConfigureTPUEmbeddingHost op that sets up the correct embedding table configuration. For example, this op is used to retrieve updated parameters before saving a checkpoint.
- Output parameters: Parameter parameters updated by the stochastic gradient descent optimization algorithm.
Declaration
public static func retrieveTPUEmbeddingStochasticGradientDescentParameters( tableId: Int64 = -1, tableName: String, numShards: Int64, shardId: Int64, config: String ) -> Tensor<Float> -
Reverses specific dimensions of a tensor.
Given a
tensor, and abooltensordimsrepresenting the dimensions oftensor, this operation reverses each dimension i oftensorwheredims[i]isTrue.tensorcan have up to 8 dimensions. The number of dimensions oftensormust equal the number of elements indims. In other words:rank(tensor) = size(dims)For example:
# tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4] # 'dims' is [False, False, False, True] reverse(t, dims) ==> [[[[ 3, 2, 1, 0], [ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]] # 'dims' is [False, True, False, False] reverse(t, dims) ==> [[[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]] # 'dims' is [False, False, True, False] reverse(t, dims) ==> [[[[8, 9, 10, 11], [4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]Output output: The same shape as
tensor.
Declaration
public static func reverse<T: TensorFlowScalar>( _ tensor: Tensor<T>, dims: Tensor<Bool> ) -> Tensor<T>Parameters
tensorUp to 8-D.
dims1-D. The dimensions to reverse.
-
Reverses specific dimensions of a tensor.
Given a
tensor, and abooltensordimsrepresenting the dimensions oftensor, this operation reverses each dimension i oftensorwheredims[i]isTrue.tensorcan have up to 8 dimensions. The number of dimensions oftensormust equal the number of elements indims. In other words:rank(tensor) = size(dims)For example:
# tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4] # 'dims' is [False, False, False, True] reverse(t, dims) ==> [[[[ 3, 2, 1, 0], [ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]] # 'dims' is [False, True, False, False] reverse(t, dims) ==> [[[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]] # 'dims' is [False, False, True, False] reverse(t, dims) ==> [[[[8, 9, 10, 11], [4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]Output output: The same shape as
tensor.
Declaration
public static func reverse( _ tensor: StringTensor, dims: Tensor<Bool> ) -> StringTensorParameters
tensorUp to 8-D.
dims1-D. The dimensions to reverse.
-
Reverses variable length slices.
This op first slices
inputalong the dimensionbatch_dim, and for each slicei, reverses the firstseq_lengths[i]elements along the dimensionseq_dim.The elements of
seq_lengthsmust obeyseq_lengths[i] <= input.dims[seq_dim], andseq_lengthsmust be a vector of lengthinput.dims[batch_dim].The output slice
ialong dimensionbatch_dimis then given by input slicei, with the firstseq_lengths[i]slices along dimensionseq_dimreversed.For example:
# Given this: batch_dim = 0 seq_dim = 1 input.dims = (4, 8, ...) seq_lengths = [7, 2, 3, 5] # then slices of input are reversed on seq_dim, but only up to seq_lengths: output[0, 0:7, :, ...] = input[0, 7:0:-1, :, ...] output[1, 0:2, :, ...] = input[1, 2:0:-1, :, ...] output[2, 0:3, :, ...] = input[2, 3:0:-1, :, ...] output[3, 0:5, :, ...] = input[3, 5:0:-1, :, ...] # while entries past seq_lens are copied through: output[0, 7:, :, ...] = input[0, 7:, :, ...] output[1, 2:, :, ...] = input[1, 2:, :, ...] output[2, 3:, :, ...] = input[2, 3:, :, ...] output[3, 2:, :, ...] = input[3, 2:, :, ...]In contrast, if:
# Given this: batch_dim = 2 seq_dim = 0 input.dims = (8, ?, 4, ...) seq_lengths = [7, 2, 3, 5] # then slices of input are reversed on seq_dim, but only up to seq_lengths: output[0:7, :, 0, :, ...] = input[7:0:-1, :, 0, :, ...] output[0:2, :, 1, :, ...] = input[2:0:-1, :, 1, :, ...] output[0:3, :, 2, :, ...] = input[3:0:-1, :, 2, :, ...] output[0:5, :, 3, :, ...] = input[5:0:-1, :, 3, :, ...] # while entries past seq_lens are copied through: output[7:, :, 0, :, ...] = input[7:, :, 0, :, ...] output[2:, :, 1, :, ...] = input[2:, :, 1, :, ...] output[3:, :, 2, :, ...] = input[3:, :, 2, :, ...] output[2:, :, 3, :, ...] = input[2:, :, 3, :, ...]Attrs:
- seq_dim: The dimension which is partially reversed.
- batch_dim: The dimension along which reversal is performed.
Output output: The partially reversed input. It has the same shape as
input.
Declaration
public static func reverseSequence< T: TensorFlowScalar, Tlen: TensorFlowIndex >( _ input: Tensor<T>, seqLengths: Tensor<Tlen>, seqDim: Int64, batchDim: Int64 = 0 ) -> Tensor<T>Parameters
inputThe input to reverse.
seq_lengths1-D with length
input.dims(batch_dim)andmax(seq_lengths) <= input.dims(seq_dim) -
Reverses specific dimensions of a tensor.
NOTE
tf.reversehas now changed behavior in preparation for 1.0.tf.reverse_v2is currently an alias that will be deprecated before TF 1.0.Given a
tensor, and aint32tensoraxisrepresenting the set of dimensions oftensorto reverse. This operation reverses each dimensionifor which there existsjs.t.axis[j] == i.tensorcan have up to 8 dimensions. The number of dimensions specified inaxismay be 0 or more entries. If an index is specified more than once, a InvalidArgument error is raised.For example:
# tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4] # 'dims' is [3] or 'dims' is [-1] reverse(t, dims) ==> [[[[ 3, 2, 1, 0], [ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]] # 'dims' is '[1]' (or 'dims' is '[-3]') reverse(t, dims) ==> [[[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]] # 'dims' is '[2]' (or 'dims' is '[-2]') reverse(t, dims) ==> [[[[8, 9, 10, 11], [4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]Output output: The same shape as
tensor.
Declaration
public static func reverseV2< Tidx: TensorFlowIndex, T: TensorFlowScalar >( _ tensor: Tensor<T>, axis: Tensor<Tidx> ) -> Tensor<T>Parameters
tensorUp to 8-D.
axis1-D. The indices of the dimensions to reverse. Must be in the range
[-rank(tensor), rank(tensor)). -
Reverses specific dimensions of a tensor.
NOTE
tf.reversehas now changed behavior in preparation for 1.0.tf.reverse_v2is currently an alias that will be deprecated before TF 1.0.Given a
tensor, and aint32tensoraxisrepresenting the set of dimensions oftensorto reverse. This operation reverses each dimensionifor which there existsjs.t.axis[j] == i.tensorcan have up to 8 dimensions. The number of dimensions specified inaxismay be 0 or more entries. If an index is specified more than once, a InvalidArgument error is raised.For example:
# tensor 't' is [[[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]]] # tensor 't' shape is [1, 2, 3, 4] # 'dims' is [3] or 'dims' is [-1] reverse(t, dims) ==> [[[[ 3, 2, 1, 0], [ 7, 6, 5, 4], [ 11, 10, 9, 8]], [[15, 14, 13, 12], [19, 18, 17, 16], [23, 22, 21, 20]]]] # 'dims' is '[1]' (or 'dims' is '[-3]') reverse(t, dims) ==> [[[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23] [[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]]] # 'dims' is '[2]' (or 'dims' is '[-2]') reverse(t, dims) ==> [[[[8, 9, 10, 11], [4, 5, 6, 7], [0, 1, 2, 3]] [[20, 21, 22, 23], [16, 17, 18, 19], [12, 13, 14, 15]]]]Output output: The same shape as
tensor.
Declaration
public static func reverseV2<Tidx: TensorFlowIndex>( _ tensor: StringTensor, axis: Tensor<Tidx> ) -> StringTensorParameters
tensorUp to 8-D.
axis1-D. The indices of the dimensions to reverse. Must be in the range
[-rank(tensor), rank(tensor)). -
Elementwise computes the bitwise right-shift of
xandy.Performs a logical shift for unsigned integer types, and an arithmetic shift for signed integer types.
If
yis negative, or greater than or equal to than the width ofxin bits the result is implementation defined.Example:
import tensorflow as tf from tensorflow.python.ops import bitwise_ops import numpy as np dtype_list = [tf.int8, tf.int16, tf.int32, tf.int64] for dtype in dtype_list: lhs = tf.constant([-1, -5, -3, -14], dtype=dtype) rhs = tf.constant([5, 0, 7, 11], dtype=dtype) right_shift_result = bitwise_ops.right_shift(lhs, rhs) print(right_shift_result) # This will print: # tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int8) # tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int16) # tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int32) # tf.Tensor([-1 -5 -1 -1], shape=(4,), dtype=int64) lhs = np.array([-2, 64, 101, 32], dtype=np.int8) rhs = np.array([-1, -5, -3, -14], dtype=np.int8) bitwise_ops.right_shift(lhs, rhs) # <tf.Tensor: shape=(4,), dtype=int8, numpy=array([ -2, 64, 101, 32], dtype=int8)>Declaration
public static func rightShift<T: TensorFlowInteger>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns element-wise integer closest to x.
If the result is midway between two representable values, the even representable is chosen. For example:
rint(-1.5) ==> -2.0 rint(0.5000001) ==> 1.0 rint([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0]) ==> [-2., -2., -0., 0., 2., 2., 2.]Declaration
public static func rint<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Advance the counter of a counter-based RNG.
The state of the RNG after
rng_skip(n)will be the same as that afterstateful_uniform([n])(or any other distribution). The actual increment added to the counter is an unspecified implementation detail.Declaration
public static func rngSkip( resource: ResourceHandle, algorithm: Tensor<Int64>, delta: Tensor<Int64> )Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
deltaThe amount of advancement.
-
Rolls the elements of a tensor along an axis.
The elements are shifted positively (towards larger indices) by the offset of
shiftalong the dimension ofaxis. Negativeshiftvalues will shift elements in the opposite direction. Elements that roll passed the last position will wrap around to the first and vice versa. Multiple shifts along multiple axes may be specified.For example:
# 't' is [0, 1, 2, 3, 4] roll(t, shift=2, axis=0) ==> [3, 4, 0, 1, 2] # shifting along multiple dimensions # 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]] roll(t, shift=[1, -2], axis=[0, 1]) ==> [[7, 8, 9, 5, 6], [2, 3, 4, 0, 1]] # shifting along the same axis multiple times # 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]] roll(t, shift=[2, -3], axis=[1, 1]) ==> [[1, 2, 3, 4, 0], [6, 7, 8, 9, 5]]Output output: Has the same shape and size as the input. The elements are shifted positively (towards larger indices) by the offsets of
shiftalong the dimensions ofaxis.
Declaration
public static func roll< T: TensorFlowScalar, Tshift: TensorFlowIndex, Taxis: TensorFlowIndex >( _ input: Tensor<T>, shift: Tensor<Tshift>, axis: Tensor<Taxis> ) -> Tensor<T>Parameters
shiftDimension must be 0-D or 1-D.
shift[i]specifies the number of places by which elements are shifted positively (towards larger indices) along the dimension specified byaxis[i]. Negative shifts will roll the elements in the opposite direction.axisDimension must be 0-D or 1-D.
axis[i]specifies the dimension that the shiftshift[i]should occur. If the same axis is referenced more than once, the total shift for that axis will be the sum of all the shifts that belong to that axis. -
Rounds the values of a tensor to the nearest integer, element-wise.
Rounds half to even. Also known as bankers rounding. If you want to round according to the current system rounding mode use std::cint.
Declaration
public static func round<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Perform batches of RPC requests.
This op asynchronously performs either a single RPC request, or a batch of requests. RPC requests are defined by three main parameters:
address(the host+port or BNS address of the request)method(the RPC method name for the request)request(the serialized proto string, or vector of strings, of the RPC request argument).
For example, if you have an RPC service running on port localhost:2345, and its interface is configured with the following proto declaration:
service MyService { rpc MyMethod(MyRequestProto) returns (MyResponseProto) { } };then call this op with arguments:
address = "localhost:2345" method = "MyService/MyMethod"The
requesttensor is a string tensor representing serializedMyRequestProtostrings; and the output string tensorresponsewill have the same shape and contain (upon successful completion) corresponding serializedMyResponseProtostrings.For example, to send a single, empty,
MyRequestProto, call this op withrequest = "". To send 5 parallel empty requests, call this op withrequest = ["", "", "", "", ""].More generally, one can create a batch of
MyRequestProtoserialized protos from regular batched tensors using theencode_protoop, and convert the responseMyResponseProtoserialized protos to batched tensors using thedecode_protoop.NOTE Working with serialized proto strings is faster than instantiating actual proto objects in memory, so no performance degradation is expected compared to writing custom kernels for this workflow.
If the connection fails or the remote worker returns an error status, the op reraises this exception locally.
See the
TryRpcop if you prefer to handle RPC failures manually in the graph.Attrs:
- protocol: RPC protocol to use. Empty string means use the default protocol. Options include ‘grpc’.
- fail_fast:
boolean. Iftrue(default), then failures to connect (i.e., the server does not immediately respond) cause an RPC failure. - timeout_in_ms:
int. If0(default), then the kernel will run the RPC request and only time out if the RPC deadline passes or the session times out. If this value is greater than0, then the op will raise an exception if the RPC takes longer thantimeout_in_ms.
Output response: Same shape as
request. Serialized proto strings: the rpc responses.
Declaration
public static func rpc( address: StringTensor, method: StringTensor, request: StringTensor, protocol_: String, failFast: Bool = true, timeoutInMs: Int64 = 0 ) -> StringTensorParameters
address0-Dor1-D. The address (i.e. host_name:port) of the RPC server. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withmethodandrequest.method0-Dor1-D. The method address on the RPC server. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withaddressandrequest.request0-Dor1-D. Serialized proto strings: the rpc request argument. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withaddressandmethod. -
Computes reciprocal of square root of x element-wise.
I.e., \(y = 1 / \sqrt{x}\).
Declaration
public static func rsqrt<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient for the rsqrt of
xwrt its input.Specifically,
grad = dy * -0.5 * y^3, wherey = rsqrt(x), anddyis the corresponding input gradient.Declaration
public static func rsqrtGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
sampleDistortedBoundingBox(imageSize:boundingBoxes:seed:seed2:minObjectCovered:aspectRatioRange:areaRange:maxAttempts:useImageIfNoBoundingBoxes:)
Generate a single randomly distorted bounding box for an image.
Bounding box annotations are often supplied in addition to ground-truth labels in image recognition or object localization tasks. A common technique for training such a system is to randomly distort an image while preserving its content, i.e. data augmentation. This Op outputs a randomly distorted localization of an object, i.e. bounding box, given an
image_size,bounding_boxesand a series of constraints.The output of this Op is a single bounding box that may be used to crop the original image. The output is returned as 3 tensors:
begin,sizeandbboxes. The first 2 tensors can be fed directly intotf.sliceto crop the image. The latter may be supplied totf.image.draw_bounding_boxesto visualize what the bounding box looks like.Bounding boxes are supplied and returned as
[y_min, x_min, y_max, x_max]. The bounding box coordinates are floats in[0.0, 1.0]relative to the width and height of the underlying image.For example,
# Generate a single distorted bounding box. begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box( tf.shape(image), bounding_boxes=bounding_boxes) # Draw the bounding box in an image summary. image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0), bbox_for_draw) tf.summary.image('images_with_box', image_with_box) # Employ the bounding box to distort the image. distorted_image = tf.slice(image, begin, size)Note that if no bounding box information is available, setting
use_image_if_no_bounding_boxes = truewill assume there is a single implicit bounding box covering the whole image. Ifuse_image_if_no_bounding_boxesis false and no bounding boxes are supplied, an error is raised.Attrs:
- seed: If either
seedorseed2are set to non-zero, the random number generator is seeded by the givenseed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- min_object_covered: The cropped area of the image must contain at least this fraction of any bounding box supplied. The value of this parameter should be non-negative. In the case of 0, the cropped area does not need to overlap any of the bounding boxes supplied.
- aspect_ratio_range: The cropped area of the image must have an aspect ratio = width / height within this range.
- area_range: The cropped area of the image must contain a fraction of the supplied image within this range.
- max_attempts: Number of attempts at generating a cropped region of the image
of the specified constraints. After
max_attemptsfailures, return the entire image. - use_image_if_no_bounding_boxes: Controls behavior if no bounding boxes supplied. If true, assume an implicit bounding box covering the whole input. If false, raise an error.
- seed: If either
Outputs:
- begin: 1-D, containing
[offset_height, offset_width, 0]. Provide as input totf.slice. - size: 1-D, containing
[target_height, target_width, -1]. Provide as input totf.slice. - bboxes: 3-D with shape
[1, 1, 4]containing the distorted bounding box. Provide as input totf.image.draw_bounding_boxes.
- begin: 1-D, containing
Declaration
public static func sampleDistortedBoundingBox<T: TensorFlowInteger>( imageSize: Tensor<T>, boundingBoxes: Tensor<Float>, seed: Int64 = 0, seed2: Int64 = 0, minObjectCovered: Double = 0.1, aspectRatioRange: [Double] = [0.75, 1.33], areaRange: [Double] = [0.05, 1], maxAttempts: Int64 = 100, useImageIfNoBoundingBoxes: Bool = false ) -> (begin: Tensor<T>, size: Tensor<T>, bboxes: Tensor<Float>)Parameters
image_size1-D, containing
[height, width, channels].bounding_boxes3-D with shape
[batch, N, 4]describing the N bounding boxes associated with the image. -
sampleDistortedBoundingBoxV2(imageSize:boundingBoxes:minObjectCovered:seed:seed2:aspectRatioRange:areaRange:maxAttempts:useImageIfNoBoundingBoxes:)
Generate a single randomly distorted bounding box for an image.
Bounding box annotations are often supplied in addition to ground-truth labels in image recognition or object localization tasks. A common technique for training such a system is to randomly distort an image while preserving its content, i.e. data augmentation. This Op outputs a randomly distorted localization of an object, i.e. bounding box, given an
image_size,bounding_boxesand a series of constraints.The output of this Op is a single bounding box that may be used to crop the original image. The output is returned as 3 tensors:
begin,sizeandbboxes. The first 2 tensors can be fed directly intotf.sliceto crop the image. The latter may be supplied totf.image.draw_bounding_boxesto visualize what the bounding box looks like.Bounding boxes are supplied and returned as
[y_min, x_min, y_max, x_max]. The bounding box coordinates are floats in[0.0, 1.0]relative to the width and height of the underlying image.For example,
# Generate a single distorted bounding box. begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box( tf.shape(image), bounding_boxes=bounding_boxes) # Draw the bounding box in an image summary. image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0), bbox_for_draw) tf.summary.image('images_with_box', image_with_box) # Employ the bounding box to distort the image. distorted_image = tf.slice(image, begin, size)Note that if no bounding box information is available, setting
use_image_if_no_bounding_boxes = truewill assume there is a single implicit bounding box covering the whole image. Ifuse_image_if_no_bounding_boxesis false and no bounding boxes are supplied, an error is raised.Attrs:
- seed: If either
seedorseed2are set to non-zero, the random number generator is seeded by the givenseed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- aspect_ratio_range: The cropped area of the image must have an aspect ratio = width / height within this range.
- area_range: The cropped area of the image must contain a fraction of the supplied image within this range.
- max_attempts: Number of attempts at generating a cropped region of the image
of the specified constraints. After
max_attemptsfailures, return the entire image. - use_image_if_no_bounding_boxes: Controls behavior if no bounding boxes supplied. If true, assume an implicit bounding box covering the whole input. If false, raise an error.
- seed: If either
Outputs:
- begin: 1-D, containing
[offset_height, offset_width, 0]. Provide as input totf.slice. - size: 1-D, containing
[target_height, target_width, -1]. Provide as input totf.slice. - bboxes: 3-D with shape
[1, 1, 4]containing the distorted bounding box. Provide as input totf.image.draw_bounding_boxes.
- begin: 1-D, containing
Declaration
public static func sampleDistortedBoundingBoxV2<T: TensorFlowInteger>( imageSize: Tensor<T>, boundingBoxes: Tensor<Float>, minObjectCovered: Tensor<Float>, seed: Int64 = 0, seed2: Int64 = 0, aspectRatioRange: [Double] = [0.75, 1.33], areaRange: [Double] = [0.05, 1], maxAttempts: Int64 = 100, useImageIfNoBoundingBoxes: Bool = false ) -> (begin: Tensor<T>, size: Tensor<T>, bboxes: Tensor<Float>)Parameters
image_size1-D, containing
[height, width, channels].bounding_boxes3-D with shape
[batch, N, 4]describing the N bounding boxes associated with the image.min_object_coveredThe cropped area of the image must contain at least this fraction of any bounding box supplied. The value of this parameter should be non-negative. In the case of 0, the cropped area does not need to overlap any of the bounding boxes supplied.
-
Creates a dataset that takes a Bernoulli sample of the contents of another dataset.
There is no transformation in the
tf.dataPython API for creating this dataset. Instead, it is created as a result of thefilter_with_random_uniform_fusionstatic optimization. Whether this optimization is performed is determined by theexperimental_optimization.filter_with_random_uniform_fusionoption oftf.data.Options.Declaration
public static func samplingDataset( inputDataset: VariantHandle, rate: Tensor<Float>, seed: Tensor<Int64>, seed2: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
rateA scalar representing the sample rate. Each element of
input_datasetis retained with this probability, independent of all other elements.seedA scalar representing seed of random number generator.
seed2A scalar representing seed2 of random number generator.
-
Saves the input tensors to disk.
The size of
tensor_namesmust match the number of tensors indata.data[i]is written tofilenamewith nametensor_names[i].See also
SaveSlices.Declaration
public static func save<T: TensorArrayProtocol>( filename: StringTensor, tensorNames: StringTensor, data: T )Parameters
filenameMust have a single element. The name of the file to which we write the tensor.
tensor_namesShape
[N]. The names of the tensors to be saved.dataNtensors to save. -
Saves input tensors slices to disk.
This is like
Saveexcept that tensors can be listed in the saved file as being a slice of a larger tensor.shapes_and_slicesspecifies the shape of the larger tensor and the slice that this tensor covers.shapes_and_slicesmust have as many elements astensor_names.Elements of the
shapes_and_slicesinput must either be:- The empty string, in which case the corresponding tensor is saved normally.
- A string of the form
dim0 dim1 ... dimN-1 slice-specwhere thedimIare the dimensions of the larger tensor andslice-specspecifies what part is covered by the tensor to save.
slice-specitself is a:-separated list:slice0:slice1:...:sliceN-1where eachsliceIis either:- The string
-meaning that the slice covers all indices of this dimension start,lengthwherestartandlengthare integers. In that case the slice coverslengthindices starting atstart.
See also
Save.Declaration
public static func saveSlices<T: TensorArrayProtocol>( filename: StringTensor, tensorNames: StringTensor, shapesAndSlices: StringTensor, data: T )Parameters
filenameMust have a single element. The name of the file to which we write the tensor.
tensor_namesShape
[N]. The names of the tensors to be saved.shapes_and_slicesShape
[N]. The shapes and slice specifications to use when saving the tensors.dataNtensors to save. -
Saves tensors in V2 checkpoint format.
By default, saves the named tensors in full. If the caller wishes to save specific slices of full tensors, “shape_and_slices” should be non-empty strings and correspondingly well-formed.
Declaration
public static func saveV2<Dtypes: TensorArrayProtocol>( prefix: StringTensor, tensorNames: StringTensor, shapeAndSlices: StringTensor, tensors: Dtypes )Parameters
prefixMust have a single element. The prefix of the V2 checkpoint to which we write the tensors.
tensor_namesshape {N}. The names of the tensors to be saved.
shape_and_slicesshape {N}. The slice specs of the tensors to be saved. Empty strings indicate that they are non-partitioned tensors.
tensorsNtensors to save. -
Outputs a
Summaryprotocol buffer with scalar values.The input
tagsandvaluesmust have the same shape. The generated summary has a summary value for each tag-value pair intagsandvalues.Output summary: Scalar. Serialized
Summaryprotocol buffer.
Declaration
public static func scalarSummary<T: TensorFlowNumeric>( tags: StringTensor, _ values: Tensor<T> ) -> StringTensorParameters
tagsTags for the summary.
valuesSame shape as `tags. Values for the summary.
-
scanDataset(inputDataset:initialState:otherArguments:f:outputTypes:outputShapes:preserveCardinality:useDefaultDevice:)
Creates a dataset successively reduces
fover the elements ofinput_dataset.Declaration
public static func scanDataset< FIn: TensorGroup, FOut: TensorGroup, Tstate: TensorArrayProtocol, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, initialState: Tstate, otherArguments: Targuments, f: (FIn) -> FOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?], preserveCardinality: Bool = false, useDefaultDevice: Bool = true ) -> VariantHandle -
Scatter
updatesinto a new tensor according toindices.Creates a new tensor by applying sparse
updatesto individual values or slices within a tensor (initially zero for numeric, empty for string) of the givenshapeaccording to indices. This operator is the inverse of thetf.gather_ndoperator which extracts values or slices from a given tensor.This operation is similar to tensor_scatter_add, except that the tensor is zero-initialized. Calling
tf.scatter_nd(indices, values, shape)is identical totensor_scatter_add(tf.zeros(shape, values.dtype), indices, values)If
indicescontains duplicates, then their updates are accumulated (summed).WARNING: The order in which updates are applied is nondeterministic, so the output will be nondeterministic if
indicescontains duplicates – because of some numerical approximation issues, numbers summed in different order may yield different results.indicesis an integer tensor containing indices into a new tensor of shapeshape. The last dimension ofindicescan be at most the rank ofshape:indices.shape[-1] <= shape.rankThe last dimension of
indicescorresponds to indices into elements (ifindices.shape[-1] = shape.rank) or slices (ifindices.shape[-1] < shape.rank) along dimensionindices.shape[-1]ofshape.updatesis a tensor with shapeindices.shape[:-1] + shape[indices.shape[-1]:]The simplest form of scatter is to insert individual elements in a tensor by index. For example, say we want to insert 4 scattered elements in a rank-1 tensor with 8 elements.

In Python, this scatter operation would look like this:
indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) shape = tf.constant([8]) scatter = tf.scatter_nd(indices, updates, shape) print(scatter)The resulting tensor would look like this:
[0, 11, 0, 10, 9, 0, 0, 12]We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter operation would look like this:
indices = tf.constant([[0], [2]]) updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]]]) shape = tf.constant([4, 4, 4]) scatter = tf.scatter_nd(indices, updates, shape) print(scatter)The resulting tensor would look like this:
[[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
Output output: A new tensor with the given shape and updates applied according to the indices.
Declaration
public static func scatterNd< T: TensorFlowScalar, Tindices: TensorFlowIndex >( indices: Tensor<Tindices>, updates: Tensor<T>, shape: Tensor<Tindices> ) -> Tensor<T>Parameters
indicesIndex tensor.
updatesUpdates to scatter into output.
shape1-D. The shape of the resulting tensor.
-
Applies sparse addition to
inputusing individual values or slicesfrom
updatesaccording to indicesindices. The updates are non-aliasing:inputis only modified in-place if no other operations will use it. Otherwise, a copy ofinputis made. This operation has a gradient with respect to bothinputandupdates.inputis aTensorwith rankPandindicesis aTensorof rankQ.indicesmust be integer tensor, containing indices intoinput. It must be shape \([d_0, …, d_{Q-2}, K]\) where0 < K <= P.The innermost dimension of
indices(with lengthK) corresponds to indices into elements (ifK = P) or(P-K)-dimensional slices (ifK < P) along theKth dimension ofinput.updatesisTensorof rankQ-1+P-Kwith shape:$$[d_0, …, d_{Q-2}, input.shape[K], …, input.shape[P-1]].$$
For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that addition would look like this:
input = tf.constant([1, 2, 3, 4, 5, 6, 7, 8]) indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) output = tf.scatter_nd_non_aliasing_add(input, indices, updates) with tf.Session() as sess: print(sess.run(output))The resulting value
outputwould look like this:[1, 13, 3, 14, 14, 6, 7, 20]See
tf.scatter_ndfor more details about how to make updates to slices.Output output: A
Tensorwith the same shape asinput, containing values ofinputupdated withupdates.
Declaration
public static func scatterNdNonAliasingAdd< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ input: Tensor<T>, indices: Tensor<Tindices>, updates: Tensor<T> ) -> Tensor<T>Parameters
inputA Tensor.
indicesA Tensor. Must be one of the following types:
int32,int64. A tensor of indices intoinput.updatesA Tensor. Must have the same type as ref. A tensor of updated values to add to
input. -
Computes fingerprints of the input strings.
Output output: a (N,2) shaped matrix where N is the number of elements in the input vector. Each row contains the low and high parts of the fingerprint.
Declaration
public static func sdcaFprint( _ input: StringTensor ) -> Tensor<Int64>Parameters
inputvector of strings to compute fingerprints on.
-
sdcaOptimizer(sparseExampleIndices:sparseFeatureIndices:sparseFeatureValues:denseFeatures:exampleWeights:exampleLabels:sparseIndices:sparseWeights:denseWeights:exampleStateData:lossType:adaptative:l1:l2:numLossPartitions:numInnerIterations:)
Distributed version of Stochastic Dual Coordinate Ascent (SDCA) optimizer for
linear models with L1 + L2 regularization. As global optimization objective is strongly-convex, the optimizer optimizes the dual objective at each step. The optimizer applies each update one example at a time. Examples are sampled uniformly, and the optimizer is learning rate free and enjoys linear convergence rate.
Proximal Stochastic Dual Coordinate Ascent.
Shai Shalev-Shwartz, Tong Zhang. 2012$$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
Adding vs. Averaging in Distributed Primal-Dual Optimization.
Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan, Peter Richtarik, Martin Takac. 2015Stochastic Dual Coordinate Ascent with Adaptive Probabilities.
Dominik Csiba, Zheng Qu, Peter Richtarik. 2015Attrs:
- loss_type: Type of the primal loss. Currently SdcaSolver supports logistic, squared and hinge losses.
- adaptative: Whether to use Adaptive SDCA for the inner loop.
- num_sparse_features: Number of sparse feature groups to train on.
- num_sparse_features_with_values: Number of sparse feature groups with values associated with it, otherwise implicitly treats values as 1.0.
- num_dense_features: Number of dense feature groups to train on.
- l1: Symmetric l1 regularization strength.
- l2: Symmetric l2 regularization strength.
- num_loss_partitions: Number of partitions of the global loss function.
- num_inner_iterations: Number of iterations per mini-batch.
Outputs:
- out_example_state_data: a list of vectors containing the updated example state data.
- out_delta_sparse_weights: a list of vectors where each value is the delta weights associated with a sparse feature group.
- out_delta_dense_weights: a list of vectors where the values are the delta weights associated with a dense feature group.
Declaration
public static func sdcaOptimizer( sparseExampleIndices: [Tensor<Int64>], sparseFeatureIndices: [Tensor<Int64>], sparseFeatureValues: [Tensor<Float>], denseFeatures: [Tensor<Float>], exampleWeights: Tensor<Float>, exampleLabels: Tensor<Float>, sparseIndices: [Tensor<Int64>], sparseWeights: [Tensor<Float>], denseWeights: [Tensor<Float>], exampleStateData: Tensor<Float>, lossType: LossType, adaptative: Bool = false, l1: Double, l2: Double, numLossPartitions: Int64, numInnerIterations: Int64 ) -> ( outExampleStateData: Tensor<Float>, outDeltaSparseWeights: [Tensor<Float>], outDeltaDenseWeights: [Tensor<Float>] )Parameters
sparse_example_indicesa list of vectors which contain example indices.
sparse_feature_indicesa list of vectors which contain feature indices.
sparse_feature_valuesa list of vectors which contains feature value associated with each feature group.
dense_featuresa list of matrices which contains the dense feature values.
example_weightsa vector which contains the weight associated with each example.
example_labelsa vector which contains the label/target associated with each example.
sparse_indicesa list of vectors where each value is the indices which has corresponding weights in sparse_weights. This field maybe omitted for the dense approach.
sparse_weightsa list of vectors where each value is the weight associated with a sparse feature group.
dense_weightsa list of vectors where the values are the weights associated with a dense feature group.
example_state_dataa list of vectors containing the example state data.
-
sdcaOptimizerV2(sparseExampleIndices:sparseFeatureIndices:sparseFeatureValues:denseFeatures:exampleWeights:exampleLabels:sparseIndices:sparseWeights:denseWeights:exampleStateData:lossType:adaptive:l1:l2:numLossPartitions:numInnerIterations:)
Distributed version of Stochastic Dual Coordinate Ascent (SDCA) optimizer for
linear models with L1 + L2 regularization. As global optimization objective is strongly-convex, the optimizer optimizes the dual objective at each step. The optimizer applies each update one example at a time. Examples are sampled uniformly, and the optimizer is learning rate free and enjoys linear convergence rate.
Proximal Stochastic Dual Coordinate Ascent.
Shai Shalev-Shwartz, Tong Zhang. 2012$$Loss Objective = \sum f_{i} (wx_{i}) + (l2 / 2) * |w|^2 + l1 * |w|$$
Adding vs. Averaging in Distributed Primal-Dual Optimization.
Chenxin Ma, Virginia Smith, Martin Jaggi, Michael I. Jordan, Peter Richtarik, Martin Takac. 2015Stochastic Dual Coordinate Ascent with Adaptive Probabilities.
Dominik Csiba, Zheng Qu, Peter Richtarik. 2015Attrs:
- loss_type: Type of the primal loss. Currently SdcaSolver supports logistic, squared and hinge losses.
- adaptive: Whether to use Adaptive SDCA for the inner loop.
- num_sparse_features: Number of sparse feature groups to train on.
- num_sparse_features_with_values: Number of sparse feature groups with values associated with it, otherwise implicitly treats values as 1.0.
- num_dense_features: Number of dense feature groups to train on.
- l1: Symmetric l1 regularization strength.
- l2: Symmetric l2 regularization strength.
- num_loss_partitions: Number of partitions of the global loss function.
- num_inner_iterations: Number of iterations per mini-batch.
Outputs:
- out_example_state_data: a list of vectors containing the updated example state data.
- out_delta_sparse_weights: a list of vectors where each value is the delta weights associated with a sparse feature group.
- out_delta_dense_weights: a list of vectors where the values are the delta weights associated with a dense feature group.
Declaration
public static func sdcaOptimizerV2( sparseExampleIndices: [Tensor<Int64>], sparseFeatureIndices: [Tensor<Int64>], sparseFeatureValues: [Tensor<Float>], denseFeatures: [Tensor<Float>], exampleWeights: Tensor<Float>, exampleLabels: Tensor<Float>, sparseIndices: [Tensor<Int64>], sparseWeights: [Tensor<Float>], denseWeights: [Tensor<Float>], exampleStateData: Tensor<Float>, lossType: LossType, adaptive: Bool = false, l1: Double, l2: Double, numLossPartitions: Int64, numInnerIterations: Int64 ) -> ( outExampleStateData: Tensor<Float>, outDeltaSparseWeights: [Tensor<Float>], outDeltaDenseWeights: [Tensor<Float>] )Parameters
sparse_example_indicesa list of vectors which contain example indices.
sparse_feature_indicesa list of vectors which contain feature indices.
sparse_feature_valuesa list of vectors which contains feature value associated with each feature group.
dense_featuresa list of matrices which contains the dense feature values.
example_weightsa vector which contains the weight associated with each example.
example_labelsa vector which contains the label/target associated with each example.
sparse_indicesa list of vectors where each value is the indices which has corresponding weights in sparse_weights. This field maybe omitted for the dense approach.
sparse_weightsa list of vectors where each value is the weight associated with a sparse feature group.
dense_weightsa list of vectors where the values are the weights associated with a dense feature group.
example_state_dataa list of vectors containing the example state data.
-
Computes the maximum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output_i = \max_j(data_j)\) where
maxis overjsuch thatsegment_ids[j] == i.If the max is empty for a given segment ID
i,output[i] = 0.
For example:
c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) tf.segment_max(c, tf.constant([0, 0, 1])) # ==> [[4, 3, 3, 4], # [5, 6, 7, 8]]Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func segmentMax< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices> ) -> Tensor<T>Parameters
segment_idsA 1-D tensor whose size is equal to the size of
data‘s first dimension. Values should be sorted and can be repeated. -
Computes the mean along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output_i = \frac{\sum_j data_j}{N}\) where
meanis overjsuch thatsegment_ids[j] == iandNis the total number of values summed.If the mean is empty for a given segment ID
i,output[i] = 0.
For example:
c = tf.constant([[1.0,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) tf.segment_mean(c, tf.constant([0, 0, 1])) # ==> [[2.5, 2.5, 2.5, 2.5], # [5, 6, 7, 8]]Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func segmentMean< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices> ) -> Tensor<T>Parameters
segment_idsA 1-D tensor whose size is equal to the size of
data‘s first dimension. Values should be sorted and can be repeated. -
Computes the minimum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output_i = \min_j(data_j)\) where
minis overjsuch thatsegment_ids[j] == i.If the min is empty for a given segment ID
i,output[i] = 0.
For example:
c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) tf.segment_min(c, tf.constant([0, 0, 1])) # ==> [[1, 2, 2, 1], # [5, 6, 7, 8]]Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func segmentMin< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices> ) -> Tensor<T>Parameters
segment_idsA 1-D tensor whose size is equal to the size of
data‘s first dimension. Values should be sorted and can be repeated. -
Computes the product along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output_i = \prod_j data_j\) where the product is over
jsuch thatsegment_ids[j] == i.If the product is empty for a given segment ID
i,output[i] = 1.
For example:
c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) tf.segment_prod(c, tf.constant([0, 0, 1])) # ==> [[4, 6, 6, 4], # [5, 6, 7, 8]]Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func segmentProd< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices> ) -> Tensor<T>Parameters
segment_idsA 1-D tensor whose size is equal to the size of
data‘s first dimension. Values should be sorted and can be repeated. -
Computes the sum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output_i = \sum_j data_j\) where sum is over
jsuch thatsegment_ids[j] == i.If the sum is empty for a given segment ID
i,output[i] = 0.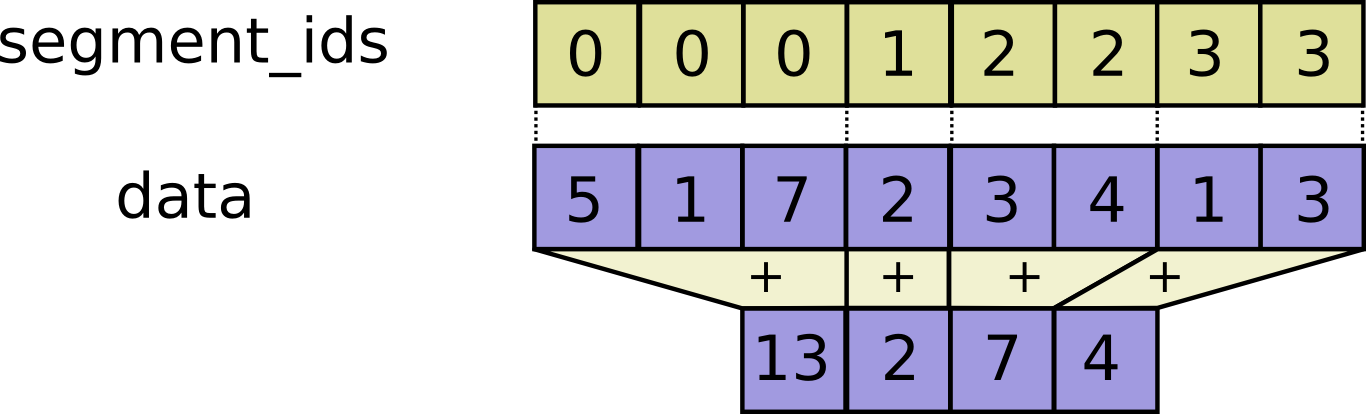
For example:
c = tf.constant([[1,2,3,4], [4, 3, 2, 1], [5,6,7,8]]) tf.segment_sum(c, tf.constant([0, 0, 1])) # ==> [[5, 5, 5, 5], # [5, 6, 7, 8]]Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func segmentSum< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices> ) -> Tensor<T>Parameters
segment_idsA 1-D tensor whose size is equal to the size of
data‘s first dimension. Values should be sorted and can be repeated. -
Selects elements from
xory, depending oncondition.The
x, andytensors must all have the same shape, and the output will also have that shape.The
conditiontensor must be a scalar ifxandyare scalars. Ifxandyare vectors or higher rank, thenconditionmust be either a scalar, a vector with size matching the first dimension ofx, or must have the same shape asx.The
conditiontensor acts as a mask that chooses, based on the value at each element, whether the corresponding element / row in the output should be taken fromx(if true) ory(if false).If
conditionis a vector andxandyare higher rank matrices, then it chooses which row (outer dimension) to copy fromxandy. Ifconditionhas the same shape asxandy, then it chooses which element to copy fromxandy.For example:
# 'condition' tensor is [[True, False] # [False, True]] # 't' is [[1, 2], # [3, 4]] # 'e' is [[5, 6], # [7, 8]] select(condition, t, e) # => [[1, 6], [7, 4]] # 'condition' tensor is [True, False] # 't' is [[1, 2], # [3, 4]] # 'e' is [[5, 6], # [7, 8]] select(condition, t, e) ==> [[1, 2], [7, 8]]Output output: = A
Tensorwith the same type and shape asxandy.
Declaration
public static func select<T: TensorFlowScalar>( condition: Tensor<Bool>, t: Tensor<T>, e: Tensor<T> ) -> Tensor<T> -
Declaration
public static func selectV2<T: TensorFlowScalar>( condition: Tensor<Bool>, t: Tensor<T>, e: Tensor<T> ) -> Tensor<T> -
Computes the Eigen Decomposition of a batch of square self-adjoint matrices.
The input is a tensor of shape
[..., M, M]whose inner-most 2 dimensions form square matrices, with the same constraints as the single matrix SelfAdjointEig.The result is a […, M+1, M] matrix with […, 0,:] containing the eigenvalues, and subsequent […,1:, :] containing the eigenvectors. The eigenvalues are sorted in non-decreasing order.
Output output: Shape is
[..., M+1, M].
Declaration
public static func selfAdjointEig<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputShape is
[..., M, M]. -
Computes the eigen decomposition of one or more square self-adjoint matrices.
Computes the eigenvalues and (optionally) eigenvectors of each inner matrix in
inputsuch thatinput[..., :, :] = v[..., :, :] * diag(e[..., :]). The eigenvalues are sorted in non-decreasing order.# a is a tensor. # e is a tensor of eigenvalues. # v is a tensor of eigenvectors. e, v = self_adjoint_eig(a) e = self_adjoint_eig(a, compute_v=False)Attr compute_v: If
Truethen eigenvectors will be computed and returned inv. Otherwise, only the eigenvalues will be computed.Outputs:
- e: Eigenvalues. Shape is
[N]. - v: Eigenvectors. Shape is
[N, N].
- e: Eigenvalues. Shape is
Declaration
public static func selfAdjointEigV2<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, computeV: Bool = true ) -> (e: Tensor<T>, v: Tensor<T>)Parameters
inputTensorinput of shape[N, N]. -
Computes scaled exponential linear:
scale * alpha * (exp(features) - 1)if < 0,
scale * featuresotherwise.To be used together with
initializer = tf.variance_scaling_initializer(factor=1.0, mode='FAN_IN'). For correct dropout, usetf.contrib.nn.alpha_dropout.Declaration
public static func selu<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T> ) -> Tensor<T> -
Computes gradients for the scaled exponential linear (Selu) operation.
Output backprops: The gradients:
gradients * (outputs + scale * alpha)if outputs < 0,scale * gradientsotherwise.
Declaration
public static func seluGrad<T: FloatingPoint & TensorFlowScalar>( gradients: Tensor<T>, outputs: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding Selu operation.
outputsThe outputs of the corresponding Selu operation.
-
Sends the named tensor from send_device to recv_device.
Attrs:
- tensor_name: The name of the tensor to send.
- send_device: The name of the device sending the tensor.
- send_device_incarnation: The current incarnation of send_device.
- recv_device: The name of the device receiving the tensor.
- client_terminated: If set to true, this indicates that the node was added to the graph as a result of a client-side feed or fetch of Tensor data, in which case the corresponding send or recv is expected to be managed locally by the caller.
Declaration
public static func send<T: TensorFlowScalar>( _ tensor: Tensor<T>, tensorName: String, sendDevice: String, sendDeviceIncarnation: Int64, recvDevice: String, clientTerminated: Bool = false )Parameters
tensorThe tensor to send.
-
Performs gradient updates of embedding tables.
Attr config: Serialized TPUEmbeddingConfiguration proto.
Declaration
Parameters
inputsA TensorList of gradients with which to update embedding tables. This argument has the same length and shapes as the return value of RecvTPUEmbeddingActivations, but contains gradients of the model’s loss with respect to the embedding activations. The embedding tables are updated from these gradients via the optimizer specified in the TPU embedding configuration given to tpu.initialize_system.
learning_ratesA TensorList of float32 scalars, one for each dynamic learning rate tag: see the comments in //third_party/tensorflow/core/protobuf/tpu/optimization_parameters.proto. Multiple tables can share the same dynamic learning rate tag as specified in the configuration. If the learning rates for all tables are constant, this list should be empty.
-
Converts the given
resource_handlerepresenting an iterator to a variant tensor.Output serialized: A variant tensor storing the state of the iterator contained in the resource.
Declaration
public static func serializeIterator( resourceHandle: ResourceHandle ) -> VariantHandleParameters
resource_handleA handle to an iterator resource.
-
Serialize an
N-minibatchSparseTensorinto an[N, 3]Tensorobject.The
SparseTensormust have rankRgreater than 1, and the first dimension is treated as the minibatch dimension. Elements of theSparseTensormust be sorted in increasing order of this first dimension. The serializedSparseTensorobjects going into each row ofserialized_sparsewill have rankR-1.The minibatch size
Nis extracted fromsparse_shape[0].Attr out_type: The
dtypeto use for serialization; the supported types arestring(default) andvariant.
Declaration
public static func serializeManySparse< T: TensorFlowScalar, OutType: TensorFlowScalar >( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64> ) -> Tensor<OutType>Parameters
sparse_indices2-D. The
indicesof the minibatchSparseTensor.sparse_values1-D. The
valuesof the minibatchSparseTensor.sparse_shape1-D. The
shapeof the minibatchSparseTensor. -
Serialize an
N-minibatchSparseTensorinto an[N, 3]Tensorobject.The
SparseTensormust have rankRgreater than 1, and the first dimension is treated as the minibatch dimension. Elements of theSparseTensormust be sorted in increasing order of this first dimension. The serializedSparseTensorobjects going into each row ofserialized_sparsewill have rankR-1.The minibatch size
Nis extracted fromsparse_shape[0].Attr out_type: The
dtypeto use for serialization; the supported types arestring(default) andvariant.
Declaration
public static func serializeManySparse<T: TensorFlowScalar>( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64> ) -> StringTensorParameters
sparse_indices2-D. The
indicesof the minibatchSparseTensor.sparse_values1-D. The
valuesof the minibatchSparseTensor.sparse_shape1-D. The
shapeof the minibatchSparseTensor. -
Serialize a
SparseTensorinto a[3]Tensorobject.Attr out_type: The
dtypeto use for serialization; the supported types arestring(default) andvariant.
Declaration
public static func serializeSparse< T: TensorFlowScalar, OutType: TensorFlowScalar >( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64> ) -> Tensor<OutType>Parameters
sparse_indices2-D. The
indicesof theSparseTensor.sparse_values1-D. The
valuesof theSparseTensor.sparse_shape1-D. The
shapeof theSparseTensor. -
Serialize a
SparseTensorinto a[3]Tensorobject.Attr out_type: The
dtypeto use for serialization; the supported types arestring(default) andvariant.
Declaration
public static func serializeSparse<T: TensorFlowScalar>( sparseIndices: Tensor<Int64>, sparseValues: Tensor<T>, sparseShape: Tensor<Int64> ) -> StringTensorParameters
sparse_indices2-D. The
indicesof theSparseTensor.sparse_values1-D. The
valuesof theSparseTensor.sparse_shape1-D. The
shapeof theSparseTensor. -
Transforms a Tensor into a serialized TensorProto proto.
Attr T: The type of the input tensor.
Output serialized: A serialized TensorProto proto of the input tensor.
Declaration
public static func serializeTensor<T: TensorFlowScalar>( _ tensor: Tensor<T> ) -> StringTensorParameters
tensorA Tensor of type
T. -
Number of unique elements along last dimension of input
set.Input
setis aSparseTensorrepresented byset_indices,set_values, andset_shape. The last dimension contains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofsetindices.Output size: For
setrankedn, this is aTensorwith rankn-1, and the same 1stn-1dimensions asset. Each value is the number of unique elements in the corresponding[0...n-1]dimension ofset.
Declaration
public static func setSize<T: TensorFlowInteger>( setIndices: Tensor<Int64>, setValues: Tensor<T>, setShape: Tensor<Int64>, validateIndices: Bool = true ) -> Tensor<Int32> -
Number of unique elements along last dimension of input
set.Input
setis aSparseTensorrepresented byset_indices,set_values, andset_shape. The last dimension contains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofsetindices.Output size: For
setrankedn, this is aTensorwith rankn-1, and the same 1stn-1dimensions asset. Each value is the number of unique elements in the corresponding[0...n-1]dimension ofset.
Declaration
public static func setSize( setIndices: Tensor<Int64>, setValues: StringTensor, setShape: Tensor<Int64>, validateIndices: Bool = true ) -> Tensor<Int32> -
Declaration
public static func setStatsAggregatorDataset( inputDataset: VariantHandle, statsAggregator: ResourceHandle, tag: StringTensor, counterPrefix: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Returns the shape of a tensor.
This operation returns a 1-D integer tensor representing the shape of
input.For example:
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] shape(t) ==> [2, 2, 3]Declaration
public static func shape< T: TensorFlowScalar, OutType: TensorFlowIndex >( _ input: Tensor<T> ) -> Tensor<OutType> -
Returns shape of tensors.
This operation returns N 1-D integer tensors representing shape of
input[i]s.Declaration
public static func shapeN< T: TensorFlowScalar, OutType: TensorFlowIndex >( _ input: [Tensor<T>] ) -> [Tensor<OutType>] -
Creates a
Datasetthat includes only 1/num_shardsof this dataset.Declaration
public static func shardDataset( inputDataset: VariantHandle, numShards: Tensor<Int64>, index: Tensor<Int64>, requireNonEmpty: Bool = false, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
num_shardsAn integer representing the number of shards operating in parallel.
indexAn integer representing the current worker index.
-
Generate a sharded filename. The filename is printf formatted as
%s-%05d-of-%05d, basename, shard, num_shards.
Declaration
public static func shardedFilename( basename: StringTensor, shard: Tensor<Int32>, numShards: Tensor<Int32> ) -> StringTensor -
Generate a glob pattern matching all sharded file names.
Declaration
public static func shardedFilespec( basename: StringTensor, numShards: Tensor<Int32> ) -> StringTensor -
Creates a dataset that shuffles and repeats elements from
input_datasetpseudorandomly.
Declaration
public static func shuffleAndRepeatDataset( inputDataset: VariantHandle, bufferSize: Tensor<Int64>, seed: Tensor<Int64>, seed2: Tensor<Int64>, count: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
buffer_sizeThe number of output elements to buffer in an iterator over this dataset. Compare with the
min_after_dequeueattr when creating aRandomShuffleQueue.seedA scalar seed for the random number generator. If either
seedorseed2is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.seed2A second scalar seed to avoid seed collision.
countA scalar representing the number of times the underlying dataset should be repeated. The default is
-1, which results in infinite repetition. -
Creates a dataset that shuffles elements from
input_datasetpseudorandomly.Attr reshuffle_each_iteration: If true, each iterator over this dataset will be given a different pseudorandomly generated seed, based on a sequence seeded by the
seedandseed2inputs. If false, each iterator will be given the same seed, and repeated iteration over this dataset will yield the exact same sequence of results.
Declaration
public static func shuffleDataset( inputDataset: VariantHandle, bufferSize: Tensor<Int64>, seed: Tensor<Int64>, seed2: Tensor<Int64>, reshuffleEachIteration: Bool = true, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
buffer_sizeThe number of output elements to buffer in an iterator over this dataset. Compare with the
min_after_dequeueattr when creating aRandomShuffleQueue.seedA scalar seed for the random number generator. If either
seedorseed2is set to be non-zero, the random number generator is seeded by the given seed. Otherwise, a random seed is used.seed2A second scalar seed to avoid seed collision.
-
Declaration
public static func shuffleDatasetV2( inputDataset: VariantHandle, bufferSize: Tensor<Int64>, seedGenerator: ResourceHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Shuts down a running distributed TPU system.
The op returns an error if no system is running.
Declaration
public static func shutdownDistributedTPU() -
Computes sigmoid of
xelement-wise.Specifically,
y = 1 / (1 + exp(-x)).Declaration
public static func sigmoid<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient of the sigmoid of
xwrt its input.Specifically,
grad = dy * y * (1 - y), wherey = sigmoid(x), anddyis the corresponding input gradient.Declaration
public static func sigmoidGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
Returns an element-wise indication of the sign of a number.
y = sign(x) = -1ifx < 0; 0 ifx == 0; 1 ifx > 0.For complex numbers,
y = sign(x) = x / |x|ifx != 0, otherwisey = 0.Example usage:
tf.math.sign([0., 2., -3.])
Declaration
public static func sign<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Declaration
public static func simpleStruct( nA: Int64 ) -> [Tensor<Int32>] -
Computes sine of x element-wise.
Given an input tensor, this function computes sine of every element in the tensor. Input range is
(-inf, inf)and output range is[-1,1].x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10, float("inf")]) tf.math.sin(x) ==> [nan -0.4121185 -0.47942555 0.84147096 0.9320391 -0.87329733 -0.54402107 nan]Declaration
public static func sin<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes hyperbolic sine of x element-wise.
Given an input tensor, this function computes hyperbolic sine of every element in the tensor. Input range is
[-inf,inf]and output range is[-inf,inf].x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 2, 10, float("inf")]) tf.math.sinh(x) ==> [-inf -4.0515420e+03 -5.2109528e-01 1.1752012e+00 1.5094614e+00 3.6268604e+00 1.1013232e+04 inf]Declaration
public static func sinh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Returns the size of a tensor.
This operation returns an integer representing the number of elements in
input.For example:
# 't' is [[[1, 1,, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]]] size(t) ==> 12Declaration
public static func size< T: TensorFlowScalar, OutType: TensorFlowIndex >( _ input: Tensor<T> ) -> Tensor<OutType> -
Creates a dataset that skips
countelements from theinput_dataset.Declaration
public static func skipDataset( inputDataset: VariantHandle, count: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
countA scalar representing the number of elements from the
input_datasetthat should be skipped. If count is -1, skips everything. -
Parses a text file and creates a batch of examples.
Attrs:
- filename: The corpus’s text file name.
- batch_size: The size of produced batch.
- window_size: The number of words to predict to the left and right of the target.
- min_count: The minimum number of word occurrences for it to be included in the vocabulary.
- subsample: Threshold for word occurrence. Words that appear with higher frequency will be randomly down-sampled. Set to 0 to disable.
Outputs:
- vocab_word: A vector of words in the corpus.
- vocab_freq: Frequencies of words. Sorted in the non-ascending order.
- words_per_epoch: Number of words per epoch in the data file.
- current_epoch: The current epoch number.
- total_words_processed: The total number of words processed so far.
- examples: A vector of word ids.
- labels: A vector of word ids.
Declaration
public static func skipgram( filename: String, batchSize: Int64, windowSize: Int64 = 5, minCount: Int64 = 5, subsample: Double = 0.001 ) -> ( vocabWord: StringTensor, vocabFreq: Tensor<Int32>, wordsPerEpoch: Tensor<Int64>, currentEpoch: Tensor<Int32>, totalWordsProcessed: Tensor<Int64>, examples: Tensor<Int32>, labels: Tensor<Int32> ) -
Declaration
public static func sleepDataset( inputDataset: VariantHandle, sleepMicroseconds: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Return a slice from ‘input’.
The output tensor is a tensor with dimensions described by ‘size’ whose values are extracted from ‘input’ starting at the offsets in ‘begin’.
Requirements: 0 <= begin[i] <= begin[i] + size[i] <= Di for i in [0, n)
Declaration
public static func slice< T: TensorFlowScalar, Index: TensorFlowIndex >( _ input: Tensor<T>, begin: Tensor<Index>, size: Tensor<Index> ) -> Tensor<T>Parameters
beginbegin[i] specifies the offset into the ‘i'th dimension of 'input’ to slice from.
sizesize[i] specifies the number of elements of the ‘i'th dimension of 'input’ to slice. If size[i] is -1, all remaining elements in dimension i are included in the slice (i.e. this is equivalent to setting size[i] = input.dim_size(i) - begin[i]).
-
Creates a dataset that passes a sliding window over
input_dataset.Declaration
public static func slidingWindowDataset( inputDataset: VariantHandle, windowSize: Tensor<Int64>, windowShift: Tensor<Int64>, windowStride: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
window_sizeA scalar representing the number of elements in the sliding window.
window_shiftA scalar representing the steps moving the sliding window forward in one iteration. It must be positive.
window_strideA scalar representing the stride of the input elements of the sliding window. It must be positive.
-
Returns a copy of the input tensor.
Declaration
public static func snapshot<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
snapshotDataset(inputDataset:path:outputTypes:outputShapes:compression:readerPathPrefix:writerPathPrefix:shardSizeBytes:pendingSnapshotExpirySeconds:numReaderThreads:readerBufferSize:numWriterThreads:writerBufferSize:shuffleOnRead:seed:seed2:)
Creates a dataset that will write to / read from a snapshot.
This dataset attempts to determine whether a valid snapshot exists at the
snapshot_path, and reads from the snapshot in lieu of usinginput_dataset. If not, it will run the preprocessing pipeline as usual, and write out a snapshot of the data processed for future use.Declaration
public static func snapshotDataset( inputDataset: VariantHandle, path: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?], compression: String, readerPathPrefix: String, writerPathPrefix: String, shardSizeBytes: Int64 = 10_737_418_240, pendingSnapshotExpirySeconds: Int64 = 86400, numReaderThreads: Int64 = 1, readerBufferSize: Int64 = 1, numWriterThreads: Int64 = 1, writerBufferSize: Int64 = 1, shuffleOnRead: Bool = false, seed: Int64 = 0, seed2: Int64 = 0 ) -> VariantHandleParameters
input_datasetA variant tensor representing the input dataset.
pathThe path we should write snapshots to / read snapshots from.
-
Computes softmax activations.
For each batch
iand classjwe have$$softmax[i, j] = exp(logits[i, j]) / sum_j(exp(logits[i, j]))$$Output softmax: Same shape as
logits.
Declaration
public static func softmax<T: FloatingPoint & TensorFlowScalar>( logits: Tensor<T> ) -> Tensor<T>Parameters
logits2-D with shape
[batch_size, num_classes]. -
Computes softmax cross entropy cost and gradients to backpropagate.
Inputs are the logits, not probabilities.
Outputs:
- loss: Per example loss (batch_size vector).
- backprop: backpropagated gradients (batch_size x num_classes matrix).
Declaration
public static func softmaxCrossEntropyWithLogits<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T>, labels: Tensor<T> ) -> (loss: Tensor<T>, backprop: Tensor<T>)Parameters
featuresbatch_size x num_classes matrix
labelsbatch_size x num_classes matrix The caller must ensure that each batch of labels represents a valid probability distribution.
-
Computes softplus:
log(exp(features) + 1).Declaration
public static func softplus<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T> ) -> Tensor<T> -
Computes softplus gradients for a softplus operation.
Output backprops: The gradients:
gradients / (1 + exp(-features)).
Declaration
public static func softplusGrad<T: FloatingPoint & TensorFlowScalar>( gradients: Tensor<T>, features: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding softplus operation.
featuresThe features passed as input to the corresponding softplus operation.
-
Computes softsign:
features / (abs(features) + 1).Declaration
public static func softsign<T: FloatingPoint & TensorFlowScalar>( features: Tensor<T> ) -> Tensor<T> -
Computes softsign gradients for a softsign operation.
Output backprops: The gradients:
gradients / (1 + abs(features)) ** 2.
Declaration
public static func softsignGrad<T: FloatingPoint & TensorFlowScalar>( gradients: Tensor<T>, features: Tensor<T> ) -> Tensor<T>Parameters
gradientsThe backpropagated gradients to the corresponding softsign operation.
featuresThe features passed as input to the corresponding softsign operation.
-
SpaceToBatch for 4-D tensors of type T.
This is a legacy version of the more general SpaceToBatchND.
Zero-pads and then rearranges (permutes) blocks of spatial data into batch. More specifically, this op outputs a copy of the input tensor where values from the
heightandwidthdimensions are moved to thebatchdimension. After the zero-padding, bothheightandwidthof the input must be divisible by the block size.Declaration
public static func spaceToBatch< T: TensorFlowScalar, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, paddings: Tensor<Tpaddings>, blockSize: Int64 ) -> Tensor<T>Parameters
input4-D with shape
[batch, height, width, depth].paddings2-D tensor of non-negative integers with shape
[2, 2]. It specifies the padding of the input with zeros across the spatial dimensions as follows:paddings = [[pad_top, pad_bottom], [pad_left, pad_right]]The effective spatial dimensions of the zero-padded input tensor will be:
height_pad = pad_top + height + pad_bottom width_pad = pad_left + width + pad_rightThe attr
block_sizemust be greater than one. It indicates the block size.- Non-overlapping blocks of size
block_size x block sizein the height and width dimensions are rearranged into the batch dimension at each location. - The batch of the output tensor is
batch * block_size * block_size. - Both height_pad and width_pad must be divisible by block_size.
The shape of the output will be:
[batch*block_size*block_size, height_pad/block_size, width_pad/block_size, depth]Some examples:
(1) For the following input of shape
[1, 2, 2, 1]and block_size of 2:x = [[[[1], [2]], [[3], [4]]]]The output tensor has shape
[4, 1, 1, 1]and value:[[[[1]]], [[[2]]], [[[3]]], [[[4]]]](2) For the following input of shape
[1, 2, 2, 3]and block_size of 2:x = [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]]The output tensor has shape
[4, 1, 1, 3]and value:[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]](3) For the following input of shape
[1, 4, 4, 1]and block_size of 2:x = [[[[1], [2], [3], [4]], [[5], [6], [7], [8]], [[9], [10], [11], [12]], [[13], [14], [15], [16]]]]The output tensor has shape
[4, 2, 2, 1]and value:x = [[[[1], [3]], [[9], [11]]], [[[2], [4]], [[10], [12]]], [[[5], [7]], [[13], [15]]], [[[6], [8]], [[14], [16]]]](4) For the following input of shape
[2, 2, 4, 1]and block_size of 2:x = [[[[1], [2], [3], [4]], [[5], [6], [7], [8]]], [[[9], [10], [11], [12]], [[13], [14], [15], [16]]]]The output tensor has shape
[8, 1, 2, 1]and value:x = [[[[1], [3]]], [[[9], [11]]], [[[2], [4]]], [[[10], [12]]], [[[5], [7]]], [[[13], [15]]], [[[6], [8]]], [[[14], [16]]]]Among others, this operation is useful for reducing atrous convolution into regular convolution.
- Non-overlapping blocks of size
-
SpaceToBatch for N-D tensors of type T.
This operation divides “spatial” dimensions
[1, ..., M]of the input into a grid of blocks of shapeblock_shape, and interleaves these blocks with the “batch” dimension (0) such that in the output, the spatial dimensions[1, ..., M]correspond to the position within the grid, and the batch dimension combines both the position within a spatial block and the original batch position. Prior to division into blocks, the spatial dimensions of the input are optionally zero padded according topaddings. See below for a precise description.Declaration
public static func spaceToBatchND< T: TensorFlowScalar, TblockShape: TensorFlowIndex, Tpaddings: TensorFlowIndex >( _ input: Tensor<T>, blockShape: Tensor<TblockShape>, paddings: Tensor<Tpaddings> ) -> Tensor<T>Parameters
inputN-D with shape
input_shape = [batch] + spatial_shape + remaining_shape, where spatial_shape hasMdimensions.block_shape1-D with shape
[M], all values must be >= 1.paddings2-D with shape
[M, 2], all values must be >= 0.paddings[i] = [pad_start, pad_end]specifies the padding for input dimensioni + 1, which corresponds to spatial dimensioni. It is required thatblock_shape[i]dividesinput_shape[i + 1] + pad_start + pad_end.This operation is equivalent to the following steps:
-
SpaceToDepth for tensors of type T.
Rearranges blocks of spatial data, into depth. More specifically, this op outputs a copy of the input tensor where values from the
heightandwidthdimensions are moved to thedepthdimension. The attrblock_sizeindicates the input block size.- Non-overlapping blocks of size
block_size x block sizeare rearranged into depth at each location. - The depth of the output tensor is
block_size * block_size * input_depth. - The Y, X coordinates within each block of the input become the high order component of the output channel index.
- The input tensor’s height and width must be divisible by block_size.
The
data_formatattr specifies the layout of the input and output tensors with the following options: “NHWC”:[ batch, height, width, channels ]“NCHW”:[ batch, channels, height, width ]“NCHW_VECT_C”:qint8 [ batch, channels / 4, height, width, 4 ]It is useful to consider the operation as transforming a 6-D Tensor. e.g. for data_format = NHWC, Each element in the input tensor can be specified via 6 coordinates, ordered by decreasing memory layout significance as: n,oY,bY,oX,bX,iC (where n=batch index, oX, oY means X or Y coordinates within the output image, bX, bY means coordinates within the input block, iC means input channels). The output would be a transpose to the following layout: n,oY,oX,bY,bX,iC
This operation is useful for resizing the activations between convolutions (but keeping all data), e.g. instead of pooling. It is also useful for training purely convolutional models.
For example, given an input of shape
[1, 2, 2, 1], data_format = “NHWC” and block_size = 2:x = [[[[1], [2]], [[3], [4]]]]This operation will output a tensor of shape
[1, 1, 1, 4]:[[[[1, 2, 3, 4]]]]Here, the input has a batch of 1 and each batch element has shape
[2, 2, 1], the corresponding output will have a single element (i.e. width and height are both 1) and will have a depth of 4 channels (1 * block_size * block_size). The output element shape is[1, 1, 4].For an input tensor with larger depth, here of shape
[1, 2, 2, 3], e.g.x = [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]]This operation, for block_size of 2, will return the following tensor of shape
[1, 1, 1, 12][[[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]]]Similarly, for the following input of shape
[1 4 4 1], and a block size of 2:x = [[[[1], [2], [5], [6]], [[3], [4], [7], [8]], [[9], [10], [13], [14]], [[11], [12], [15], [16]]]]the operator will return the following tensor of shape
[1 2 2 4]:x = [[[[1, 2, 3, 4], [5, 6, 7, 8]], [[9, 10, 11, 12], [13, 14, 15, 16]]]]- Attr block_size: The size of the spatial block.
Declaration
public static func spaceToDepth<T: TensorFlowScalar>( _ input: Tensor<T>, blockSize: Int64, dataFormat: DataFormat5 = .nhwc ) -> Tensor<T> - Non-overlapping blocks of size
-
Adds two
SparseTensorobjects to produce anotherSparseTensor.The input
SparseTensorobjects’ indices are assumed ordered in standard lexicographic order. If this is not the case, before this step runSparseReorderto restore index ordering.By default, if two values sum to zero at some index, the output
SparseTensorwould still include that particular location in its index, storing a zero in the corresponding value slot. To override this, callers can specifythresh, indicating that if the sum has a magnitude strictly smaller thanthresh, its corresponding value and index would then not be included. In particular,thresh == 0(default) means everything is kept and actual thresholding happens only for a positive value.In the following shapes,
nnzis the count after takingthreshinto account.Declaration
public static func sparseAdd< T: TensorFlowNumeric, Treal: TensorFlowNumeric >( aIndices: Tensor<Int64>, aValues: Tensor<T>, aShape: Tensor<Int64>, bIndices: Tensor<Int64>, bValues: Tensor<T>, bShape: Tensor<Int64>, thresh: Tensor<Treal> ) -> (sumIndices: Tensor<Int64>, sumValues: Tensor<T>, sumShape: Tensor<Int64>)Parameters
a_indices2-D. The
indicesof the firstSparseTensor, size[nnz, ndims]Matrix.a_values1-D. The
valuesof the firstSparseTensor, size[nnz]Vector.a_shape1-D. The
shapeof the firstSparseTensor, size[ndims]Vector.b_indices2-D. The
indicesof the secondSparseTensor, size[nnz, ndims]Matrix.b_values1-D. The
valuesof the secondSparseTensor, size[nnz]Vector.b_shape1-D. The
shapeof the secondSparseTensor, size[ndims]Vector.thresh0-D. The magnitude threshold that determines if an output value/index pair takes space.
-
The gradient operator for the SparseAdd op.
The SparseAdd op calculates A + B, where A, B, and the sum are all represented as
SparseTensorobjects. This op takes in the upstream gradient w.r.t. non-empty values of the sum, and outputs the gradients w.r.t. the non-empty values of A and B.Outputs:
- a_val_grad: 1-D with shape
[nnz(A)]. The gradient with respect to the non-empty values of A. - b_val_grad: 1-D with shape
[nnz(B)]. The gradient with respect to the non-empty values of B.
- a_val_grad: 1-D with shape
Declaration
Parameters
backprop_val_grad1-D with shape
[nnz(sum)]. The gradient with respect to the non-empty values of the sum.a_indices2-D. The
indicesof theSparseTensorA, size[nnz(A), ndims].b_indices2-D. The
indicesof theSparseTensorB, size[nnz(B), ndims].sum_indices2-D. The
indicesof the sumSparseTensor, size[nnz(sum), ndims]. -
Concatenates a list of
SparseTensoralong the specified dimension.Concatenation is with respect to the dense versions of these sparse tensors. It is assumed that each input is a
SparseTensorwhose elements are ordered along increasing dimension number.All inputs’ shapes must match, except for the concat dimension. The
indices,values, andshapeslists must have the same length.The output shape is identical to the inputs’, except along the concat dimension, where it is the sum of the inputs’ sizes along that dimension.
The output elements will be resorted to preserve the sort order along increasing dimension number.
This op runs in
O(M log M)time, whereMis the total number of non-empty values across all inputs. This is due to the need for an internal sort in order to concatenate efficiently across an arbitrary dimension.For example, if
concat_dim = 1and the inputs aresp_inputs[0]: shape = [2, 3] [0, 2]: "a" [1, 0]: "b" [1, 1]: "c" sp_inputs[1]: shape = [2, 4] [0, 1]: "d" [0, 2]: "e"then the output will be
shape = [2, 7] [0, 2]: "a" [0, 4]: "d" [0, 5]: "e" [1, 0]: "b" [1, 1]: "c"Graphically this is equivalent to doing
[ a] concat [ d e ] = [ a d e ] [b c ] [ ] [b c ]Attr concat_dim: Dimension to concatenate along. Must be in range [-rank, rank), where rank is the number of dimensions in each input
SparseTensor.Outputs:
- output_indices: 2-D. Indices of the concatenated
SparseTensor. - output_values: 1-D. Non-empty values of the concatenated
SparseTensor. - output_shape: 1-D. Shape of the concatenated
SparseTensor.
- output_indices: 2-D. Indices of the concatenated
Declaration
Parameters
indices2-D. Indices of each input
SparseTensor.values1-D. Non-empty values of each
SparseTensor.shapes1-D. Shapes of each
SparseTensor. -
Generates sparse cross from a list of sparse and dense tensors.
The op takes two lists, one of 2D
SparseTensorand one of 2DTensor, each representing features of one feature column. It outputs a 2DSparseTensorwith the batchwise crosses of these features.For example, if the inputs are
inputs[0]: SparseTensor with shape = [2, 2] [0, 0]: "a" [1, 0]: "b" [1, 1]: "c" inputs[1]: SparseTensor with shape = [2, 1] [0, 0]: "d" [1, 0]: "e" inputs[2]: Tensor [["f"], ["g"]]then the output will be
shape = [2, 2] [0, 0]: "a_X_d_X_f" [1, 0]: "b_X_e_X_g" [1, 1]: "c_X_e_X_g"if hashed_output=true then the output will be
shape = [2, 2] [0, 0]: FingerprintCat64( Fingerprint64("f"), FingerprintCat64( Fingerprint64("d"), Fingerprint64("a"))) [1, 0]: FingerprintCat64( Fingerprint64("g"), FingerprintCat64( Fingerprint64("e"), Fingerprint64("b"))) [1, 1]: FingerprintCat64( Fingerprint64("g"), FingerprintCat64( Fingerprint64("e"), Fingerprint64("c")))Attrs:
- hashed_output: If true, returns the hash of the cross instead of the string. This will allow us avoiding string manipulations.
- num_buckets: It is used if hashed_output is true. output = hashed_value%num_buckets if num_buckets > 0 else hashed_value.
- hash_key: Specify the hash_key that will be used by the
FingerprintCat64function to combine the crosses fingerprints.
Outputs:
- output_indices: 2-D. Indices of the concatenated
SparseTensor. - output_values: 1-D. Non-empty values of the concatenated or hashed
SparseTensor. - output_shape: 1-D. Shape of the concatenated
SparseTensor.
- output_indices: 2-D. Indices of the concatenated
Declaration
public static func sparseCross< SparseTypes: TensorArrayProtocol, DenseTypes: TensorArrayProtocol, OutType: TensorFlowIndex >( indices: [Tensor<Int64>], _ values: SparseTypes, shapes: [Tensor<Int64>], denseInputs: DenseTypes, hashedOutput: Bool, numBuckets: Int64, hashKey: Int64, internalType: TensorDataType ) -> (outputIndices: Tensor<Int64>, outputValues: Tensor<OutType>, outputShape: Tensor<Int64>)Parameters
indices2-D. Indices of each input
SparseTensor.values1-D. values of each
SparseTensor.shapes1-D. Shapes of each
SparseTensor.dense_inputs2-D. Columns represented by dense
Tensor. -
Generates sparse cross from a list of sparse and dense tensors.
The op takes two lists, one of 2D
SparseTensorand one of 2DTensor, each representing features of one feature column. It outputs a 2DSparseTensorwith the batchwise crosses of these features.For example, if the inputs are
inputs[0]: SparseTensor with shape = [2, 2] [0, 0]: "a" [1, 0]: "b" [1, 1]: "c" inputs[1]: SparseTensor with shape = [2, 1] [0, 0]: "d" [1, 0]: "e" inputs[2]: Tensor [["f"], ["g"]]then the output will be
shape = [2, 2] [0, 0]: "a_X_d_X_f" [1, 0]: "b_X_e_X_g" [1, 1]: "c_X_e_X_g"if hashed_output=true then the output will be
shape = [2, 2] [0, 0]: FingerprintCat64( Fingerprint64("f"), FingerprintCat64( Fingerprint64("d"), Fingerprint64("a"))) [1, 0]: FingerprintCat64( Fingerprint64("g"), FingerprintCat64( Fingerprint64("e"), Fingerprint64("b"))) [1, 1]: FingerprintCat64( Fingerprint64("g"), FingerprintCat64( Fingerprint64("e"), Fingerprint64("c")))Attrs:
- hashed_output: If true, returns the hash of the cross instead of the string. This will allow us avoiding string manipulations.
- num_buckets: It is used if hashed_output is true. output = hashed_value%num_buckets if num_buckets > 0 else hashed_value.
- hash_key: Specify the hash_key that will be used by the
FingerprintCat64function to combine the crosses fingerprints.
Outputs:
- output_indices: 2-D. Indices of the concatenated
SparseTensor. - output_values: 1-D. Non-empty values of the concatenated or hashed
SparseTensor. - output_shape: 1-D. Shape of the concatenated
SparseTensor.
- output_indices: 2-D. Indices of the concatenated
Declaration
public static func sparseCross< SparseTypes: TensorArrayProtocol, DenseTypes: TensorArrayProtocol >( indices: [Tensor<Int64>], _ values: SparseTypes, shapes: [Tensor<Int64>], denseInputs: DenseTypes, hashedOutput: Bool, numBuckets: Int64, hashKey: Int64, internalType: TensorDataType ) -> (outputIndices: Tensor<Int64>, outputValues: StringTensor, outputShape: Tensor<Int64>)Parameters
indices2-D. Indices of each input
SparseTensor.values1-D. values of each
SparseTensor.shapes1-D. Shapes of each
SparseTensor.dense_inputs2-D. Columns represented by dense
Tensor. -
Adds up a SparseTensor and a dense Tensor, using these special rules:
(1) Broadcasts the dense side to have the same shape as the sparse side, if eligible; (2) Then, only the dense values pointed to by the indices of the SparseTensor participate in the cwise addition.
By these rules, the result is a logical SparseTensor with exactly the same indices and shape, but possibly with different non-zero values. The output of this Op is the resultant non-zero values.
Output output: 1-D. The
Nvalues that are operated on.
Declaration
Parameters
sp_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.sp_values1-D.
Nnon-empty values corresponding tosp_indices.sp_shape1-D. Shape of the input SparseTensor.
denseR-D. The dense Tensor operand. -
Component-wise divides a SparseTensor by a dense Tensor.
Limitation: this Op only broadcasts the dense side to the sparse side, but not the other direction.
Output output: 1-D. The
Nvalues that are operated on.
Declaration
Parameters
sp_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.sp_values1-D.
Nnon-empty values corresponding tosp_indices.sp_shape1-D. Shape of the input SparseTensor.
denseR-D. The dense Tensor operand. -
Component-wise multiplies a SparseTensor by a dense Tensor.
The output locations corresponding to the implicitly zero elements in the sparse tensor will be zero (i.e., will not take up storage space), regardless of the contents of the dense tensor (even if it’s +/-INF and that INF*0 == NaN).
Limitation: this Op only broadcasts the dense side to the sparse side, but not the other direction.
Output output: 1-D. The
Nvalues that are operated on.
Declaration
Parameters
sp_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.sp_values1-D.
Nnon-empty values corresponding tosp_indices.sp_shape1-D. Shape of the input SparseTensor.
denseR-D. The dense Tensor operand. -
Fills empty rows in the input 2-D
SparseTensorwith a default value.The input
SparseTensoris represented via the tuple of inputs (indices,values,dense_shape). The outputSparseTensorhas the samedense_shapebut with indicesoutput_indicesand valuesoutput_values.This op inserts a single entry for every row that doesn’t have any values. The index is created as
[row, 0, ..., 0]and the inserted value isdefault_value.For example, suppose
sp_inputhas shape[5, 6]and non-empty values:[0, 1]: a [0, 3]: b [2, 0]: c [3, 1]: dRows 1 and 4 are empty, so the output will be of shape
[5, 6]with values:[0, 1]: a [0, 3]: b [1, 0]: default_value [2, 0]: c [3, 1]: d [4, 0]: default_valueThe output
SparseTensorwill be in row-major order and will have the same shape as the input.This op also returns an indicator vector shaped
[dense_shape[0]]such thatempty_row_indicator[i] = True iff row i was an empty row.And a reverse index map vector shaped
[indices.shape[0]]that is used during backpropagation,reverse_index_map[j] = out_j s.t. indices[j, :] == output_indices[out_j, :]Outputs:
- output_values: 1-D. the values of the filled sparse tensor.
- empty_row_indicator: 1-D. whether the dense row was missing in the input sparse tensor.
- reverse_index_map: 1-D. a map from the input indices to the output indices.
Declaration
Parameters
indices2-D. the indices of the sparse tensor.
values1-D. the values of the sparse tensor.
dense_shape1-D. the shape of the sparse tensor.
default_value0-D. default value to insert into location
[row, 0, ..., 0]for rows missing from the input sparse tensor. output indices: 2-D. the indices of the filled sparse tensor. -
The gradient of SparseFillEmptyRows.
Takes vectors reverse_index_map, shaped
[N], and grad_values, shaped[N_full], whereN_full >= Nand copies data into eitherd_valuesord_default_value. Hered_valuesis shaped[N]andd_default_valueis a scalar.d_values[j] = grad_values[reverse_index_map[j]] d_default_value = sum_{k : 0 .. N_full - 1} ( grad_values[k] * 1{k not in reverse_index_map})
Outputs:
- d_values: 1-D. The backprop into values.
- d_default_value: 0-D. The backprop into default_value.
Declaration
public static func sparseFillEmptyRowsGrad<T: TensorFlowScalar>( reverseIndexMap: Tensor<Int64>, gradValues: Tensor<T> ) -> (dValues: Tensor<T>, dDefaultValue: Tensor<T>)Parameters
reverse_index_map1-D. The reverse index map from SparseFillEmptyRows.
grad_values1-D. The gradients from backprop.
-
Multiply matrix “a” by matrix “b”.
The inputs must be two-dimensional matrices and the inner dimension of “a” must match the outer dimension of “b”. Both “a” and “b” must be
Tensors notSparseTensors. This op is optimized for the case where at least one of “a” or “b” is sparse, in the sense that they have a large proportion of zero values. The breakeven for using this versus a dense matrix multiply on one platform was 30% zero values in the sparse matrix.The gradient computation of this operation will only take advantage of sparsity in the input gradient when that gradient comes from a Relu.
Declaration
public static func sparseMatMul< Ta: FloatingPoint & TensorFlowScalar, Tb: FloatingPoint & TensorFlowScalar >( _ a: Tensor<Ta>, _ b: Tensor<Tb>, transposeA: Bool = false, transposeB: Bool = false, aIsSparse: Bool = false, bIsSparse: Bool = false ) -> Tensor<Float> -
Sparse addition of two CSR matrices, C = alpha * A + beta * B.
The gradients of SparseMatrixAdd outputs with respect to alpha and beta are not currently defined (TensorFlow will return zeros for these entries).
Output c: A CSRSparseMatrix.
Declaration
public static func sparseMatrixAdd<T: FloatingPoint & TensorFlowScalar>( _ a: VariantHandle, _ b: VariantHandle, alpha: Tensor<T>, beta: Tensor<T> ) -> VariantHandleParameters
aA CSRSparseMatrix.
bA CSRSparseMatrix.
alphaA constant scalar.
betaA constant scalar.
-
Matrix-multiplies a sparse matrix with a dense matrix.
Returns a dense matrix. For inputs A and B, where A is CSR and B is dense; this op returns a dense C;
If transpose_output is false, returns:
C = A . BIf transpose_output is
true, returns:C = transpose(A . B) = transpose(B) . transpose(A)where the transposition is performed along the two innermost (matrix) dimensions.
If conjugate_output is
true, returns:C = conjugate(A . B) = conjugate(A) . conjugate(B)If both conjugate_output and transpose_output are
true, returns:C = conjugate(transpose(A . B)) = conjugate(transpose(B)) . conjugate(transpose(A))Attrs:
- transpose_a: Indicates whether
ashould be transposed. - transpose_b: Indicates whether
bshould be transposed. - adjoint_a: Indicates whether
ashould be conjugate-transposed. - adjoint_b: Indicates whether
bshould be conjugate-transposed. - transpose_output: Transposes the product of
aandb. - conjugate_output: Conjugates the product of
aandb.
- transpose_a: Indicates whether
Output output: A dense output tensor.
Declaration
public static func sparseMatrixMatMul<T: TensorFlowScalar>( _ a: VariantHandle, _ b: Tensor<T>, transposeA: Bool = false, transposeB: Bool = false, adjointA: Bool = false, adjointB: Bool = false, transposeOutput: Bool = false, conjugateOutput: Bool = false ) -> Tensor<T>Parameters
aA CSRSparseMatrix.
bA dense tensor.
-
Element-wise multiplication of a sparse matrix with a dense tensor.
Returns a sparse matrix.
The dense tensor
bmay be either a scalar; otherwiseamust be a rank-3SparseMatrix; in this casebmust be shaped[batch_size, 1, 1]and the multiply operation broadcasts.NOTE even if
bis zero, the sparsity structure of the output does not change.Output output: A dense output tensor.
Declaration
public static func sparseMatrixMul<T: TensorFlowScalar>( _ a: VariantHandle, _ b: Tensor<T> ) -> VariantHandleParameters
aA CSRSparseMatrix.
bA dense tensor.
-
Returns the number of nonzeroes of
sparse_matrix.Output nnz: The number of nonzeroes of
sparse_matrix.
Declaration
public static func sparseMatrixNNZ( sparseMatrix: VariantHandle ) -> Tensor<Int32>Parameters
sparse_matrixA CSRSparseMatrix.
-
Computes the Approximate Minimum Degree (AMD) ordering of
input.Computes the Approximate Minimum Degree (AMD) ordering for a sparse matrix.
The returned permutation may be used to permute the rows and columns of the given sparse matrix. This typically results in permuted sparse matrix’s sparse Cholesky (or other decompositions) in having fewer zero fill-in compared to decomposition of the original matrix.
The input sparse matrix may have rank 2 or rank 3. The output Tensor, representing would then have rank 1 or 2 respectively, with the same batch shape as the input.
Each component of the input sparse matrix must represent a square symmetric matrix; only the lower triangular part of the matrix is read. The values of the sparse matrix does not affect the returned permutation, only the sparsity pattern of the sparse matrix is used. Hence, a single AMD ordering may be reused for the Cholesky decompositions of sparse matrices with the same sparsity pattern but with possibly different values.
Each batch component of the output permutation represents a permutation of
Nelements, where the input sparse matrix components each haveNrows. That is, the component contains each of the integers{0, .. N-1}exactly once. Theith element represents the row index that theith row maps to.Usage example:
from tensorflow.python.ops.linalg.sparse import sparse_csr_matrix_ops a_indices = np.array([[0, 0], [1, 1], [2, 1], [2, 2], [3, 3]]) a_values = np.array([1.0, 2.0, 1.0, 3.0, 4.0], np.float32) a_dense_shape = [4, 4] with tf.Session() as sess: # Define (COO format) SparseTensor over Numpy array. a_st = tf.SparseTensor(a_indices, a_values, a_dense_shape) # Convert SparseTensors to CSR SparseMatrix. a_sm = sparse_csr_matrix_ops.sparse_tensor_to_csr_sparse_matrix( a_st.indices, a_st.values, a_st.dense_shape) # Obtain the AMD Ordering for the CSR SparseMatrix. ordering_amd = sparse_csr_matrix_ops.sparse_matrix_ordering_amd(sparse_matrix) ordering_amd_value = sess.run(ordering_amd)ordering_amd_valuestores the AMD ordering:[1 2 3 0].input: A
CSRSparseMatrix.Output output: The Approximate Minimum Degree (AMD) ordering of
input.
Declaration
public static func sparseMatrixOrderingAMD( _ input: VariantHandle ) -> Tensor<Int32>Parameters
inputA
CSRSparseMatrix. -
Calculates the softmax of a CSRSparseMatrix.
Calculate the softmax of the innermost dimensions of a SparseMatrix.
Missing values are treated as
-inf(i.e., logits of zero probability); and the output has the same sparsity structure as the input (though missing values in the output may now be treated as having probability zero).Output softmax: A CSRSparseMatrix.
Declaration
public static func sparseMatrixSoftmax( logits: VariantHandle, type: TensorDataType ) -> VariantHandleParameters
logitsA CSRSparseMatrix.
-
Calculates the gradient of the SparseMatrixSoftmax op.
Output gradient: The output gradient.
Declaration
public static func sparseMatrixSoftmaxGrad( softmax: VariantHandle, gradSoftmax: VariantHandle, type: TensorDataType ) -> VariantHandleParameters
softmaxA CSRSparseMatrix.
grad_softmaxThe gradient of
softmax. -
Computes the sparse Cholesky decomposition of
input.Computes the Sparse Cholesky decomposition of a sparse matrix, with the given fill-in reducing permutation.
The input sparse matrix and the fill-in reducing permutation
permutationmust have compatible shapes. If the sparse matrix has rank 3; with the batch dimensionB, then thepermutationmust be of rank 2; with the same batch dimensionB. There is no support for broadcasting.Furthermore, each component vector of
permutationmust be of lengthN, containing each of the integers {0, 1, …, N - 1} exactly once, whereNis the number of rows of each component of the sparse matrix.Each component of the input sparse matrix must represent a symmetric positive definite (SPD) matrix; although only the lower triangular part of the matrix is read. If any individual component is not SPD, then an InvalidArgument error is thrown.
The returned sparse matrix has the same dense shape as the input sparse matrix. For each component
Aof the input sparse matrix, the corresponding output sparse matrix representsL, the lower triangular Cholesky factor satisfying the following identity:A = L * Ltwhere Lt denotes the transpose of L (or its conjugate transpose, if
typeiscomplex64orcomplex128).The
typeparameter denotes the type of the matrix elements. The supported types are:float32,float64,complex64andcomplex128.Usage example:
from tensorflow.python.ops.linalg.sparse import sparse_csr_matrix_ops a_indices = np.array([[0, 0], [1, 1], [2, 1], [2, 2], [3, 3]]) a_values = np.array([1.0, 2.0, 1.0, 3.0, 4.0], np.float32) a_dense_shape = [4, 4] with tf.Session() as sess: # Define (COO format) SparseTensor over Numpy array. a_st = tf.SparseTensor(a_indices, a_values, a_dense_shape) # Convert SparseTensors to CSR SparseMatrix. a_sm = sparse_csr_matrix_ops.sparse_tensor_to_csr_sparse_matrix( a_st.indices, a_st.values, a_st.dense_shape) # Obtain the Sparse Cholesky factor using AMD Ordering for reducing zero # fill-in (number of structural non-zeros in the sparse Cholesky factor). ordering_amd = sparse_csr_matrix_ops.sparse_matrix_ordering_amd(sparse_matrix) cholesky_sparse_matrices = ( sparse_csr_matrix_ops.sparse_matrix_sparse_cholesky( sparse_matrix, ordering_amd, type=tf.float32)) # Convert the CSRSparseMatrix Cholesky factor to a dense Tensor dense_cholesky = sparse_csr_matrix_ops.csr_sparse_matrix_to_dense( cholesky_sparse_matrices, tf.float32) # Evaluate the dense Tensor value. dense_cholesky_value = sess.run(dense_cholesky)dense_cholesky_valuestores the dense Cholesky factor:[[ 1. 0. 0. 0.] [ 0. 1.41 0. 0.] [ 0. 0.70 1.58 0.] [ 0. 0. 0. 2.]]input: A
CSRSparseMatrix. permutation: ATensor. type: The type ofinput.Output output: The sparse Cholesky decompsition of
input.
Declaration
public static func sparseMatrixSparseCholesky( _ input: VariantHandle, permutation: Tensor<Int32>, type: TensorDataType ) -> VariantHandleParameters
inputA
CSRSparseMatrix.permutationA fill-in reducing permutation matrix.
-
Sparse-matrix-multiplies two CSR matrices
aandb.Performs a matrix multiplication of a sparse matrix
awith a sparse matrixb; returns a sparse matrixa * b, unless eitheraorbis transposed or adjointed.Each matrix may be transposed or adjointed (conjugated and transposed) according to the Boolean parameters
transpose_a,adjoint_a,transpose_bandadjoint_b. At most one oftranspose_aoradjoint_amay be True. Similarly, at most one oftranspose_boradjoint_bmay be True.The inputs must have compatible shapes. That is, the inner dimension of
amust be equal to the outer dimension ofb. This requirement is adjusted according to whether eitheraorbis transposed or adjointed.The
typeparameter denotes the type of the matrix elements. Bothaandbmust have the same type. The supported types are:float32,float64,complex64andcomplex128.Both
aandbmust have the same rank. Broadcasting is not supported. If they have rank 3, each batch of 2D CSRSparseMatrices withinaandbmust have the same dense shape.The sparse matrix product may have numeric (non-structural) zeros. TODO(anudhyan): Consider adding a boolean attribute to control whether to prune zeros.
Usage example:
from tensorflow.python.ops.linalg.sparse import sparse_csr_matrix_ops a_indices = np.array([[0, 0], [2, 3], [2, 4], [3, 0]]) a_values = np.array([1.0, 5.0, -1.0, -2.0], np.float32) a_dense_shape = [4, 5] b_indices = np.array([[0, 0], [3, 0], [3, 1]]) b_values = np.array([2.0, 7.0, 8.0], np.float32) b_dense_shape = [5, 3] with tf.Session() as sess: # Define (COO format) Sparse Tensors over Numpy arrays a_st = tf.SparseTensor(a_indices, a_values, a_dense_shape) b_st = tf.SparseTensor(b_indices, b_values, b_dense_shape) # Convert SparseTensors to CSR SparseMatrix a_sm = sparse_csr_matrix_ops.sparse_tensor_to_csr_sparse_matrix( a_st.indices, a_st.values, a_st.dense_shape) b_sm = sparse_csr_matrix_ops.sparse_tensor_to_csr_sparse_matrix( b_st.indices, b_st.values, b_st.dense_shape) # Compute the CSR SparseMatrix matrix multiplication c_sm = sparse_csr_matrix_ops.sparse_matrix_sparse_mat_mul( a=a_sm, b=b_sm, type=tf.float32) # Convert the CSR SparseMatrix product to a dense Tensor c_sm_dense = sparse_csr_matrix_ops.csr_sparse_matrix_to_dense( c_sm, tf.float32) # Evaluate the dense Tensor value c_sm_dense_value = sess.run(c_sm_dense)c_sm_dense_valuestores the dense matrix product:[[ 2. 0. 0.] [ 0. 0. 0.] [ 35. 40. 0.] [ -4. 0. 0.]]a: A
CSRSparseMatrix. b: ACSRSparseMatrixwith the same type and rank asa. type: The type of bothaandb. transpose_a: If True,atransposed before multiplication. transpose_b: If True,btransposed before multiplication. adjoint_a: If True,aadjointed before multiplication. adjoint_b: If True,badjointed before multiplication.Attrs:
- transpose_a: Indicates whether
ashould be transposed. - transpose_b: Indicates whether
bshould be transposed. - adjoint_a: Indicates whether
ashould be conjugate-transposed. - adjoint_b: Indicates whether
bshould be conjugate-transposed.
- transpose_a: Indicates whether
Output c: A CSRSparseMatrix.
Declaration
public static func sparseMatrixSparseMatMul( _ a: VariantHandle, _ b: VariantHandle, type: TensorDataType, transposeA: Bool = false, transposeB: Bool = false, adjointA: Bool = false, adjointB: Bool = false ) -> VariantHandleParameters
aA CSRSparseMatrix.
bA CSRSparseMatrix.
-
Transposes the inner (matrix) dimensions of a CSRSparseMatrix.
Transposes the inner (matrix) dimensions of a SparseMatrix and optionally conjugates its values.
Attr conjugate: Indicates whether
inputshould be conjugated.Output output: A CSRSparseMatrix.
Declaration
public static func sparseMatrixTranspose( _ input: VariantHandle, conjugate: Bool = false, type: TensorDataType ) -> VariantHandleParameters
inputA CSRSparseMatrix.
-
Creates an all-zeros CSRSparseMatrix with shape
dense_shape.Output sparse_matrix: An empty CSR matrix with shape
dense_shape.
Declaration
public static func sparseMatrixZeros( denseShape: Tensor<Int64>, type: TensorDataType ) -> VariantHandleParameters
dense_shapeThe desired matrix shape.
-
Computes the max of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to
tf.reduce_max(). In particular, this Op also returns a denseTensorinstead of a sparse one.Reduces
sp_inputalong the dimensions given inreduction_axes. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inreduction_axes. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.If
reduction_axeshas no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output:
R-K-D. The reduced Tensor.
Declaration
Parameters
input_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.input_values1-D.
Nnon-empty values corresponding toinput_indices.input_shape1-D. Shape of the input SparseTensor.
reduction_axes1-D. Length-
Kvector containing the reduction axes. -
Computes the max of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to
tf.reduce_max(). In contrast to SparseReduceMax, this Op returns a SparseTensor.Reduces
sp_inputalong the dimensions given inreduction_axes. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inreduction_axes. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.If
reduction_axeshas no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.Attr keep_dims: If true, retain reduced dimensions with length 1.
Declaration
Parameters
input_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.input_values1-D.
Nnon-empty values corresponding toinput_indices.input_shape1-D. Shape of the input SparseTensor.
reduction_axes1-D. Length-
Kvector containing the reduction axes. -
Computes the sum of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to
tf.reduce_sum(). In particular, this Op also returns a denseTensorinstead of a sparse one.Reduces
sp_inputalong the dimensions given inreduction_axes. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inreduction_axes. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.If
reduction_axeshas no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output:
R-K-D. The reduced Tensor.
Declaration
Parameters
input_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.input_values1-D.
Nnon-empty values corresponding toinput_indices.input_shape1-D. Shape of the input SparseTensor.
reduction_axes1-D. Length-
Kvector containing the reduction axes. -
Computes the sum of elements across dimensions of a SparseTensor.
This Op takes a SparseTensor and is the sparse counterpart to
tf.reduce_sum(). In contrast to SparseReduceSum, this Op returns a SparseTensor.Reduces
sp_inputalong the dimensions given inreduction_axes. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inreduction_axes. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.If
reduction_axeshas no entries, all dimensions are reduced, and a tensor with a single element is returned. Additionally, the axes can be negative, which are interpreted according to the indexing rules in Python.Attr keep_dims: If true, retain reduced dimensions with length 1.
Declaration
Parameters
input_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.input_values1-D.
Nnon-empty values corresponding toinput_indices.input_shape1-D. Shape of the input SparseTensor.
reduction_axes1-D. Length-
Kvector containing the reduction axes. -
Reorders a SparseTensor into the canonical, row-major ordering.
Note that by convention, all sparse ops preserve the canonical ordering along increasing dimension number. The only time ordering can be violated is during manual manipulation of the indices and values vectors to add entries.
Reordering does not affect the shape of the SparseTensor.
If the tensor has rank
RandNnon-empty values,input_indiceshas shape[N, R], input_values has lengthN, and input_shape has lengthR.Outputs:
- output_indices: 2-D.
N x Rmatrix with the same indices as input_indices, but in canonical row-major ordering. - output_values: 1-D.
Nnon-empty values corresponding tooutput_indices.
- output_indices: 2-D.
Declaration
Parameters
input_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, possibly not in canonical ordering.input_values1-D.
Nnon-empty values corresponding toinput_indices.input_shape1-D. Shape of the input SparseTensor.
-
Reshapes a SparseTensor to represent values in a new dense shape.
This operation has the same semantics as reshape on the represented dense tensor. The
input_indicesare recomputed based on the requestednew_shape.If one component of
new_shapeis the special value -1, the size of that dimension is computed so that the total dense size remains constant. At most one component ofnew_shapecan be -1. The number of dense elements implied bynew_shapemust be the same as the number of dense elements originally implied byinput_shape.Reshaping does not affect the order of values in the SparseTensor.
If the input tensor has rank
R_inandNnon-empty values, andnew_shapehas lengthR_out, theninput_indiceshas shape[N, R_in],input_shapehas lengthR_in,output_indiceshas shape[N, R_out], andoutput_shapehas lengthR_out.Outputs:
- output_indices: 2-D.
N x R_outmatrix with the updated indices of non-empty values in the output SparseTensor. - output_shape: 1-D.
R_outvector with the full dense shape of the output SparseTensor. This is the same asnew_shapebut with any -1 dimensions filled in.
- output_indices: 2-D.
Declaration
Parameters
input_indices2-D.
N x R_inmatrix with the indices of non-empty values in a SparseTensor.input_shape1-D.
R_invector with the input SparseTensor’s dense shape.new_shape1-D.
R_outvector with the requested new dense shape. -
Computes the mean along sparse segments of a tensor.
See
tf.sparse.segment_sumfor usage examples.Like
SegmentMean, butsegment_idscan have rank less thandata‘s first dimension, selecting a subset of dimension 0, specified byindices.Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func sparseSegmentMean< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
-
Computes gradients for SparseSegmentMean.
Returns tensor “output” with same shape as grad, except for dimension 0 whose value is output_dim0.
Declaration
public static func sparseSegmentMeanGrad< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( grad: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32>, outputDim0: Tensor<Int32> ) -> Tensor<T>Parameters
gradgradient propagated to the SparseSegmentMean op.
indicesindices passed to the corresponding SparseSegmentMean op.
segment_idssegment_ids passed to the corresponding SparseSegmentMean op.
output_dim0dimension 0 of “data” passed to SparseSegmentMean op.
-
Computes the mean along sparse segments of a tensor.
Like
SparseSegmentMean, but allows missing ids insegment_ids. If an id is misisng, theoutputtensor at that position will be zeroed.Read the section on segmentation for an explanation of segments.
Output output: Has same shape as data, except for dimension 0 which has size
num_segments.
Declaration
public static func sparseSegmentMeanWithNumSegments< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
num_segmentsShould equal the number of distinct segment IDs.
-
Computes the sum along sparse segments of a tensor divided by the sqrt of N.
N is the size of the segment being reduced.
See
tf.sparse.segment_sumfor usage examples.Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func sparseSegmentSqrtN< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
-
Computes gradients for SparseSegmentSqrtN.
Returns tensor “output” with same shape as grad, except for dimension 0 whose value is output_dim0.
Declaration
public static func sparseSegmentSqrtNGrad< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex >( grad: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32>, outputDim0: Tensor<Int32> ) -> Tensor<T>Parameters
gradgradient propagated to the SparseSegmentSqrtN op.
indicesindices passed to the corresponding SparseSegmentSqrtN op.
segment_idssegment_ids passed to the corresponding SparseSegmentSqrtN op.
output_dim0dimension 0 of “data” passed to SparseSegmentSqrtN op.
-
Computes the sum along sparse segments of a tensor divided by the sqrt of N.
N is the size of the segment being reduced.
Like
SparseSegmentSqrtN, but allows missing ids insegment_ids. If an id is misisng, theoutputtensor at that position will be zeroed.Read the section on segmentation for an explanation of segments.
Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func sparseSegmentSqrtNWithNumSegments< T: FloatingPoint & TensorFlowScalar, Tidx: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
num_segmentsShould equal the number of distinct segment IDs.
-
Computes the sum along sparse segments of a tensor.
Read the section on segmentation for an explanation of segments.
Like
SegmentSum, butsegment_idscan have rank less thandata‘s first dimension, selecting a subset of dimension 0, specified byindices.For example:
c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]]) # Select two rows, one segment. tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 0])) # => [[0 0 0 0]] # Select two rows, two segment. tf.sparse_segment_sum(c, tf.constant([0, 1]), tf.constant([0, 1])) # => [[ 1 2 3 4] # [-1 -2 -3 -4]] # Select all rows, two segments. tf.sparse_segment_sum(c, tf.constant([0, 1, 2]), tf.constant([0, 0, 1])) # => [[0 0 0 0] # [5 6 7 8]] # Which is equivalent to: tf.segment_sum(c, tf.constant([0, 0, 1]))Output output: Has same shape as data, except for dimension 0 which has size
k, the number of segments.
Declaration
public static func sparseSegmentSum< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
-
Computes the sum along sparse segments of a tensor.
Like
SparseSegmentSum, but allows missing ids insegment_ids. If an id is misisng, theoutputtensor at that position will be zeroed.Read the section on segmentation for an explanation of segments.
For example:
c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]]) tf.sparse_segment_sum_with_num_segments( c, tf.constant([0, 1]), tf.constant([0, 0]), num_segments=3) # => [[0 0 0 0] # [0 0 0 0] # [0 0 0 0]] tf.sparse_segment_sum_with_num_segments(c, tf.constant([0, 1]), tf.constant([0, 2], num_segments=4)) # => [[ 1 2 3 4] # [ 0 0 0 0] # [-1 -2 -3 -4] # [ 0 0 0 0]]Output output: Has same shape as data, except for dimension 0 which has size
num_segments.
Declaration
public static func sparseSegmentSumWithNumSegments< T: TensorFlowNumeric, Tidx: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, indices: Tensor<Tidx>, segmentIds: Tensor<Int32>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
indicesA 1-D tensor. Has same rank as
segment_ids.segment_idsA 1-D tensor. Values should be sorted and can be repeated.
num_segmentsShould equal the number of distinct segment IDs.
-
Slice a
SparseTensorbased on thestartandsize.For example, if the input is
input_tensor = shape = [2, 7] [ a d e ] [b c ]Graphically the output tensors are:
sparse_slice([0, 0], [2, 4]) = shape = [2, 4] [ a ] [b c ] sparse_slice([0, 4], [2, 3]) = shape = [2, 3] [ d e ] [ ]Outputs:
- output_values: A list of 1-D tensors represents the values of the output sparse tensors.
- output_shape: A list of 1-D tensors represents the shape of the output sparse tensors.
Declaration
Parameters
indices2-D tensor represents the indices of the sparse tensor.
values1-D tensor represents the values of the sparse tensor.
shape1-D. tensor represents the shape of the sparse tensor.
start1-D. tensor represents the start of the slice.
size1-D. tensor represents the size of the slice. output indices: A list of 1-D tensors represents the indices of the output sparse tensors.
-
The gradient operator for the SparseSlice op.
This op takes in the upstream gradient w.r.t. non-empty values of the sliced
SparseTensor, and outputs the gradients w.r.t. the non-empty values of inputSparseTensor.Output val_grad: 1-D. The gradient with respect to the non-empty values of input
SparseTensor.
Declaration
Parameters
backprop_val_grad1-D. The gradient with respect to the non-empty values of the sliced
SparseTensor.input_indices2-D. The
indicesof the inputSparseTensor.input_start1-D. tensor represents the start of the slice.
output_indices2-D. The
indicesof the slicedSparseTensor. -
Applies softmax to a batched N-D
SparseTensor.The inputs represent an N-D SparseTensor with logical shape
[..., B, C](whereN >= 2), and with indices sorted in the canonical lexicographic order.This op is equivalent to applying the normal
tf.nn.softmax()to each innermost logical submatrix with shape[B, C], but with the catch that the implicitly zero elements do not participate. Specifically, the algorithm is equivalent to the following:(1) Applies
tf.nn.softmax()to a densified view of each innermost submatrix with shape[B, C], along the size-C dimension; (2) Masks out the original implicitly-zero locations; (3) Renormalizes the remaining elements.Hence, the
SparseTensorresult has exactly the same non-zero indices and shape.Output output: 1-D. The
NNZvalues for the resultSparseTensor.
Declaration
public static func sparseSoftmax<T: FloatingPoint & TensorFlowScalar>( spIndices: Tensor<Int64>, spValues: Tensor<T>, spShape: Tensor<Int64> ) -> Tensor<T>Parameters
sp_indices2-D.
NNZ x Rmatrix with the indices of non-empty values in a SparseTensor, in canonical ordering.sp_values1-D.
NNZnon-empty values corresponding tosp_indices.sp_shape1-D. Shape of the input SparseTensor.
-
Computes softmax cross entropy cost and gradients to backpropagate.
Unlike
SoftmaxCrossEntropyWithLogits, this operation does not accept a matrix of label probabilities, but rather a single label per row of features. This label is considered to have probability 1.0 for the given row.Inputs are the logits, not probabilities.
Outputs:
- loss: Per example loss (batch_size vector).
- backprop: backpropagated gradients (batch_size x num_classes matrix).
Declaration
public static func sparseSoftmaxCrossEntropyWithLogits< T: FloatingPoint & TensorFlowScalar, Tlabels: TensorFlowIndex >( features: Tensor<T>, labels: Tensor<Tlabels> ) -> (loss: Tensor<T>, backprop: Tensor<T>)Parameters
featuresbatch_size x num_classes matrix
labelsbatch_size vector with values in [0, num_classes). This is the label for the given minibatch entry.
-
Returns the element-wise max of two SparseTensors.
Assumes the two SparseTensors have the same shape, i.e., no broadcasting.
Outputs:
- output_indices: 2-D. The indices of the output SparseTensor.
- output_values: 1-D. The values of the output SparseTensor.
Declaration
Parameters
a_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, in the canonical lexicographic ordering.a_values1-D.
Nnon-empty values corresponding toa_indices.a_shape1-D. Shape of the input SparseTensor.
b_indicescounterpart to
a_indicesfor the other operand.b_valuescounterpart to
a_valuesfor the other operand; must be of the same dtype.b_shapecounterpart to
a_shapefor the other operand; the two shapes must be equal. -
Returns the element-wise min of two SparseTensors.
Assumes the two SparseTensors have the same shape, i.e., no broadcasting.
Outputs:
- output_indices: 2-D. The indices of the output SparseTensor.
- output_values: 1-D. The values of the output SparseTensor.
Declaration
Parameters
a_indices2-D.
N x Rmatrix with the indices of non-empty values in a SparseTensor, in the canonical lexicographic ordering.a_values1-D.
Nnon-empty values corresponding toa_indices.a_shape1-D. Shape of the input SparseTensor.
b_indicescounterpart to
a_indicesfor the other operand.b_valuescounterpart to
a_valuesfor the other operand; must be of the same dtype.b_shapecounterpart to
a_shapefor the other operand; the two shapes must be equal. -
Split a
SparseTensorintonum_splittensors along one dimension.If the
shape[split_dim]is not an integer multiple ofnum_split. Slices[0 : shape[split_dim] % num_split]gets one extra dimension. For example, ifsplit_dim = 1andnum_split = 2and the input isinput_tensor = shape = [2, 7] [ a d e ] [b c ]Graphically the output tensors are:
output_tensor[0] = shape = [2, 4] [ a ] [b c ] output_tensor[1] = shape = [2, 3] [ d e ] [ ]Attr num_split: The number of ways to split.
Outputs:
- output_values: A list of 1-D tensors represents the values of the output sparse tensors.
- output_shape: A list of 1-D tensors represents the shape of the output sparse tensors.
Declaration
Parameters
split_dim0-D. The dimension along which to split. Must be in the range
[0, rank(shape)).indices2-D tensor represents the indices of the sparse tensor.
values1-D tensor represents the values of the sparse tensor.
shape1-D. tensor represents the shape of the sparse tensor. output indices: A list of 1-D tensors represents the indices of the output sparse tensors.
-
Adds up a
SparseTensorand a denseTensor, producing a denseTensor.This Op does not require
a_indicesbe sorted in standard lexicographic order.Declaration
public static func sparseTensorDenseAdd< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( aIndices: Tensor<Tindices>, aValues: Tensor<T>, aShape: Tensor<Tindices>, _ b: Tensor<T> ) -> Tensor<T>Parameters
a_indices2-D. The
indicesof theSparseTensor, with shape[nnz, ndims].a_values1-D. The
valuesof theSparseTensor, with shape[nnz].a_shape1-D. The
shapeof theSparseTensor, with shape[ndims].bndims-D Tensor. With shapea_shape. -
Multiply SparseTensor (of rank 2) “A” by dense matrix “B”.
No validity checking is performed on the indices of A. However, the following input format is recommended for optimal behavior:
if adjoint_a == false: A should be sorted in lexicographically increasing order. Use SparseReorder if you’re not sure. if adjoint_a == true: A should be sorted in order of increasing dimension 1 (i.e., “column major” order instead of “row major” order).
Attrs:
- adjoint_a: Use the adjoint of A in the matrix multiply. If A is complex, this is transpose(conj(A)). Otherwise it’s transpose(A).
- adjoint_b: Use the adjoint of B in the matrix multiply. If B is complex, this is transpose(conj(B)). Otherwise it’s transpose(B).
Declaration
public static func sparseTensorDenseMatMul< T: TensorFlowScalar, Tindices: TensorFlowIndex >( aIndices: Tensor<Tindices>, aValues: Tensor<T>, aShape: Tensor<Int64>, _ b: Tensor<T>, adjointA: Bool = false, adjointB: Bool = false ) -> Tensor<T>Parameters
a_indices2-D. The
indicesof theSparseTensor, size[nnz, 2]Matrix.a_values1-D. The
valuesof theSparseTensor, size[nnz]Vector.a_shape1-D. The
shapeof theSparseTensor, size[2]Vector.b2-D. A dense Matrix.
-
Creates a dataset that splits a SparseTensor into elements row-wise.
Declaration
public static func sparseTensorSliceDataset<Tvalues: TensorFlowScalar>( indices: Tensor<Int64>, _ values: Tensor<Tvalues>, denseShape: Tensor<Int64> ) -> VariantHandle -
Converts a SparseTensor to a (possibly batched) CSRSparseMatrix.
Output sparse_matrix: A (possibly batched) CSRSparseMatrix.
Declaration
public static func sparseTensorToCSRSparseMatrix<T: FloatingPoint & TensorFlowScalar>( indices: Tensor<Int64>, _ values: Tensor<T>, denseShape: Tensor<Int64> ) -> VariantHandleParameters
indicesSparseTensor indices.
valuesSparseTensor values.
dense_shapeSparseTensor dense shape.
-
Converts a sparse representation into a dense tensor.
Builds an array
densewith shapeoutput_shapesuch that# If sparse_indices is scalar dense[i] = (i == sparse_indices ? sparse_values : default_value) # If sparse_indices is a vector, then for each i dense[sparse_indices[i]] = sparse_values[i] # If sparse_indices is an n by d matrix, then for each i in [0, n) dense[sparse_indices[i][0], ..., sparse_indices[i][d-1]] = sparse_values[i]All other values in
denseare set todefault_value. Ifsparse_valuesis a scalar, all sparse indices are set to this single value.Indices should be sorted in lexicographic order, and indices must not contain any repeats. If
validate_indicesis true, these properties are checked during execution.Attr validate_indices: If true, indices are checked to make sure they are sorted in lexicographic order and that there are no repeats.
Output dense: Dense output tensor of shape
output_shape.
Declaration
public static func sparseToDense< T: TensorFlowScalar, Tindices: TensorFlowIndex >( sparseIndices: Tensor<Tindices>, outputShape: Tensor<Tindices>, sparseValues: Tensor<T>, defaultValue: Tensor<T>, validateIndices: Bool = true ) -> Tensor<T>Parameters
sparse_indices0-D, 1-D, or 2-D.
sparse_indices[i]contains the complete index wheresparse_values[i]will be placed.output_shape1-D. Shape of the dense output tensor.
sparse_values1-D. Values corresponding to each row of
sparse_indices, or a scalar value to be used for all sparse indices.default_valueScalar value to set for indices not specified in
sparse_indices. -
sparseToSparseSetOperation(set1Indices:set1Values:set1Shape:set2Indices:set2Values:set2Shape:setOperation:validateIndices:)
Applies set operation along last dimension of 2
SparseTensorinputs.See SetOperationOp::SetOperationFromContext for values of
set_operation.If
validate_indicesisTrue,SparseToSparseSetOperationvalidates the order and range ofset1andset2indices.Input
set1is aSparseTensorrepresented byset1_indices,set1_values, andset1_shape. Forset1rankedn, 1stn-1dimensions must be the same asset2. Dimensionncontains values in a set, duplicates are allowed but ignored.Input
set2is aSparseTensorrepresented byset2_indices,set2_values, andset2_shape. Forset2rankedn, 1stn-1dimensions must be the same asset1. Dimensionncontains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofset1andset2indices.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
public static func sparseToSparseSetOperation<T: TensorFlowInteger>( set1Indices: Tensor<Int64>, set1Values: Tensor<T>, set1Shape: Tensor<Int64>, set2Indices: Tensor<Int64>, set2Values: Tensor<T>, set2Shape: Tensor<Int64>, setOperation: String, validateIndices: Bool = true ) -> (resultIndices: Tensor<Int64>, resultValues: Tensor<T>, resultShape: Tensor<Int64>)Parameters
set1_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set1_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set1_shape1D
Tensor, shape of aSparseTensor.set1_shape[0...n-1]must be the same asset2_shape[0...n-1],set1_shape[n]is the max set size across0...n-1dimensions.set2_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set2_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set2_shape1D
Tensor, shape of aSparseTensor.set2_shape[0...n-1]must be the same asset1_shape[0...n-1],set2_shape[n]is the max set size across0...n-1dimensions. -
sparseToSparseSetOperation(set1Indices:set1Values:set1Shape:set2Indices:set2Values:set2Shape:setOperation:validateIndices:)
Applies set operation along last dimension of 2
SparseTensorinputs.See SetOperationOp::SetOperationFromContext for values of
set_operation.If
validate_indicesisTrue,SparseToSparseSetOperationvalidates the order and range ofset1andset2indices.Input
set1is aSparseTensorrepresented byset1_indices,set1_values, andset1_shape. Forset1rankedn, 1stn-1dimensions must be the same asset2. Dimensionncontains values in a set, duplicates are allowed but ignored.Input
set2is aSparseTensorrepresented byset2_indices,set2_values, andset2_shape. Forset2rankedn, 1stn-1dimensions must be the same asset1. Dimensionncontains values in a set, duplicates are allowed but ignored.If
validate_indicesisTrue, this op validates the order and range ofset1andset2indices.Output
resultis aSparseTensorrepresented byresult_indices,result_values, andresult_shape. Forset1andset2rankedn, this has ranknand the same 1stn-1dimensions asset1andset2. Thenthdimension contains the result ofset_operationapplied to the corresponding[0...n-1]dimension ofset.Outputs:
- result_indices: 2D indices of a
SparseTensor. - result_values: 1D values of a
SparseTensor. - result_shape: 1D
Tensorshape of aSparseTensor.result_shape[0...n-1]is the same as the 1stn-1dimensions ofset1andset2,result_shape[n]is the max result set size across all0...n-1dimensions.
- result_indices: 2D indices of a
Declaration
public static func sparseToSparseSetOperation( set1Indices: Tensor<Int64>, set1Values: StringTensor, set1Shape: Tensor<Int64>, set2Indices: Tensor<Int64>, set2Values: StringTensor, set2Shape: Tensor<Int64>, setOperation: String, validateIndices: Bool = true ) -> (resultIndices: Tensor<Int64>, resultValues: StringTensor, resultShape: Tensor<Int64>)Parameters
set1_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set1_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set1_shape1D
Tensor, shape of aSparseTensor.set1_shape[0...n-1]must be the same asset2_shape[0...n-1],set1_shape[n]is the max set size across0...n-1dimensions.set2_indices2D
Tensor, indices of aSparseTensor. Must be in row-major order.set2_values1D
Tensor, values of aSparseTensor. Must be in row-major order.set2_shape1D
Tensor, shape of aSparseTensor.set2_shape[0...n-1]must be the same asset1_shape[0...n-1],set2_shape[n]is the max set size across0...n-1dimensions. -
Splits a tensor into
num_splittensors along one dimension.Attr num_split: The number of ways to split. Must evenly divide
value.shape[split_dim].Output output: They are identically shaped tensors, whose shape matches that of
valueexcept alongaxis, where their sizes arevalues.shape[split_dim] / num_split.
Declaration
public static func split<T: TensorFlowScalar>( splitDim: Tensor<Int32>, value: Tensor<T>, numSplit: Int64 ) -> [Tensor<T>]Parameters
split_dim0-D. The dimension along which to split. Must be in the range
[-rank(value), rank(value)).valueThe tensor to split.
-
Splits a tensor into
num_splittensors along one dimension.Output output: Tensors whose shape matches that of
valueexcept alongaxis, where their sizes aresize_splits[i].
Declaration
public static func splitV< T: TensorFlowScalar, Tlen: TensorFlowIndex >( value: Tensor<T>, sizeSplits: Tensor<Tlen>, splitDim: Tensor<Int32>, numSplit: Int64 ) -> [Tensor<T>]Parameters
valueThe tensor to split.
size_splitslist containing the sizes of each output tensor along the split dimension. Must sum to the dimension of value along split_dim. Can contain one -1 indicating that dimension is to be inferred.
split_dim0-D. The dimension along which to split. Must be in the range
[-rank(value), rank(value)). -
Creates a dataset that executes a SQL query and emits rows of the result set.
Declaration
public static func sqlDataset( driverName: StringTensor, dataSourceName: StringTensor, query: StringTensor, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
driver_nameThe database type. Currently, the only supported type is ‘sqlite’.
data_source_nameA connection string to connect to the database.
queryA SQL query to execute.
-
Computes square root of x element-wise.
I.e., \(y = \sqrt{x} = x^{½}\).
Declaration
public static func sqrt<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient for the sqrt of
xwrt its input.Specifically,
grad = dy * 0.5 / y, wherey = sqrt(x), anddyis the corresponding input gradient.Declaration
public static func sqrtGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
Computes square of x element-wise.
I.e., \(y = x * x = x^2\).
Declaration
public static func square<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Returns (x - y)(x - y) element-wise.
NOTE:
SquaredDifferencesupports broadcasting. More about broadcasting hereDeclaration
public static func squaredDifference<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Removes dimensions of size 1 from the shape of a tensor.
Given a tensor
input, this operation returns a tensor of the same type with all dimensions of size 1 removed. If you don’t want to remove all size 1 dimensions, you can remove specific size 1 dimensions by specifyingaxis.For example:
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1] shape(squeeze(t)) ==> [2, 3]Or, to remove specific size 1 dimensions:
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1] shape(squeeze(t, [2, 4])) ==> [1, 2, 3, 1]Attr squeeze_dims: If specified, only squeezes the dimensions listed. The dimension index starts at 0. It is an error to squeeze a dimension that is not 1. Must be in the range
[-rank(input), rank(input)).Output output: Contains the same data as
input, but has one or more dimensions of size 1 removed.
Declaration
public static func squeeze<T: TensorFlowScalar>( _ input: Tensor<T>, squeezeDims: [Int32] ) -> Tensor<T>Parameters
inputThe
inputto squeeze. -
Delete the stack from its resource container.
Declaration
public static func stackCloseV2( handle: ResourceHandle )Parameters
handleThe handle to a stack.
-
Pop the element at the top of the stack.
Attr elem_type: The type of the elem that is popped.
Output elem: The tensor that is popped from the top of the stack.
Declaration
public static func stackPopV2<ElemType: TensorFlowScalar>( handle: ResourceHandle ) -> Tensor<ElemType>Parameters
handleThe handle to a stack.
-
Push an element onto the stack.
Attr swap_memory: Swap
elemto CPU. Default to false.Output output: The same tensor as the input ‘elem’.
Declaration
public static func stackPushV2<T: TensorFlowScalar>( handle: ResourceHandle, elem: Tensor<T>, swapMemory: Bool = false ) -> Tensor<T>Parameters
handleThe handle to a stack.
elemThe tensor to be pushed onto the stack.
-
A stack that produces elements in first-in last-out order.
Attrs:
- elem_type: The type of the elements on the stack.
- stack_name: Overrides the name used for the temporary stack resource. Default value is the name of the ‘Stack’ op (which is guaranteed unique).
Output handle: The handle to the stack.
Declaration
public static func stackV2( maxSize: Tensor<Int32>, elemType: TensorDataType, stackName: String ) -> ResourceHandleParameters
max_sizeThe maximum size of the stack if non-negative. If negative, the stack size is unlimited.
-
Stage values similar to a lightweight Enqueue.
The basic functionality of this Op is similar to a queue with many fewer capabilities and options. This Op is optimized for performance.
Attrs:
- capacity: Maximum number of elements in the Staging Area. If > 0, inserts on the container will block when the capacity is reached.
- memory_limit: The maximum number of bytes allowed for Tensors in the Staging Area. If > 0, inserts will block until sufficient space is available.
- container: If non-empty, this queue is placed in the given container. Otherwise, a default container is used.
- shared_name: It is necessary to match this name to the matching Unstage Op.
Declaration
public static func stage<Dtypes: TensorArrayProtocol>( _ values: Dtypes, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String )Parameters
valuesa list of tensors dtypes A list of data types that inserted values should adhere to.
-
Op removes all elements in the underlying container.
Declaration
public static func stageClear( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -
Op peeks at the values at the specified index. If the
underlying container does not contain sufficient elements this op will block until it does. This Op is optimized for performance.
Declaration
public static func stagePeek<Dtypes: TensorGroup>( index: Tensor<Int32>, capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Op returns the number of elements in the underlying container.
Declaration
public static func stageSize( capacity: Int64 = 0, memoryLimit: Int64 = 0, dtypes: [TensorDataType], container: String, sharedName: String ) -> Tensor<Int32> -
returns
f(inputs), wheref‘s body is placed and partitioned.Attrs:
- Tin: A list of input types.
- Tout: A list of output types.
- f: A function that takes 'args’, a list of tensors, and returns ‘output’, another list of tensors. Input and output types are specified by ‘Tin’ and ‘Tout’. The function body of f will be placed and partitioned across devices, setting this op apart from the regular Call op. This op is stateful.
Output output: A list of return values.
Declaration
public static func statefulPartitionedCall< Tin: TensorArrayProtocol, Tout: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( args: Tin, f: (FIn) -> FOut, config: String, configProto: String, executorType: String ) -> ToutParameters
argsA list of input tensors.
-
Declaration
public static func statefulRandomBinomial< S: TensorFlowIndex, T: TensorFlowNumeric, Dtype: TensorFlowNumeric >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<S>, counts: Tensor<T>, probs: Tensor<T> ) -> Tensor<Dtype> -
Outputs random values from a normal distribution. This op is deprecated in favor of op ‘StatefulStandardNormalV2’
The generated values will have mean 0 and standard deviation 1.
Attr dtype: The type of the output.
Output output: A tensor of the specified shape filled with random normal values.
Declaration
public static func statefulStandardNormal< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
shapeThe shape of the output tensor.
-
Outputs random values from a normal distribution.
The generated values will have mean 0 and standard deviation 1.
Attr dtype: The type of the output.
Output output: A tensor of the specified shape filled with random normal values.
Declaration
public static func statefulStandardNormalV2< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
shapeThe shape of the output tensor.
-
Outputs random values from a truncated normal distribution.
The generated values follow a normal distribution with mean 0 and standard deviation 1, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statefulTruncatedNormal< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
shapeThe shape of the output tensor.
-
Outputs random values from a uniform distribution.
The generated values follow a uniform distribution in the range
[0, 1). The lower bound 0 is included in the range, while the upper bound 1 is excluded.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statefulUniform< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
shapeThe shape of the output tensor.
-
Outputs random integers from a uniform distribution.
The generated values are uniform integers covering the whole range of
dtype.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statefulUniformFullInt< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<ShapeDtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
shapeThe shape of the output tensor.
-
Outputs random integers from a uniform distribution.
The generated values are uniform integers in the range
[minval, maxval). The lower boundminvalis included in the range, while the upper boundmaxvalis excluded.The random integers are slightly biased unless
maxval - minvalis an exact power of two. The bias is small for values ofmaxval - minvalsignificantly smaller than the range of the output (either2^32or2^64).Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statefulUniformInt< Dtype: TensorFlowScalar, ShapeDtype: TensorFlowScalar >( resource: ResourceHandle, algorithm: Tensor<Int64>, shape: Tensor<ShapeDtype>, minval: Tensor<Dtype>, maxval: Tensor<Dtype> ) -> Tensor<Dtype>Parameters
resourceThe handle of the resource variable that stores the state of the RNG.
algorithmThe RNG algorithm.
shapeThe shape of the output tensor.
minvalMinimum value (inclusive, scalar).
maxvalMaximum value (exclusive, scalar).
-
output = cond ? then_branch(input) : else_branch(input)
Attrs:
- Tin: A list of input types.
- Tout: A list of output types.
- then_branch: A function that takes ‘inputs’ and returns a list of tensors, whose types are the same as what else_branch returns.
- else_branch: A function that takes ‘inputs’ and returns a list of tensors, whose types are the same as what then_branch returns.
Output output: A list of return values.
Declaration
public static func statelessIf< Tcond: TensorFlowScalar, Tin: TensorArrayProtocol, Tout: TensorGroup, ThenbranchIn: TensorGroup, ThenbranchOut: TensorGroup, ElsebranchIn: TensorGroup, ElsebranchOut: TensorGroup >( cond: Tensor<Tcond>, _ input: Tin, thenBranch: (ThenbranchIn) -> ThenbranchOut, elseBranch: (ElsebranchIn) -> ElsebranchOut, outputShapes: [TensorShape?] ) -> ToutParameters
condA Tensor. If the tensor is a scalar of non-boolean type, the scalar is converted to a boolean according to the following rule: if the scalar is a numerical value, non-zero means
Trueand zero means False; if the scalar is a string, non-empty meansTrueand empty meansFalse. If the tensor is not a scalar, being empty means False and being non-empty means True.This should only be used when the if then/else body functions do not have stateful ops.inputA list of input tensors.
-
Draws samples from a multinomial distribution.
Output output: 2-D Tensor with shape
[batch_size, num_samples]. Each slice[i, :]contains the drawn class labels with range[0, num_classes).
Declaration
public static func statelessMultinomial< T: TensorFlowNumeric, Tseed: TensorFlowIndex, OutputDtype: TensorFlowIndex >( logits: Tensor<T>, numSamples: Tensor<Int32>, seed: Tensor<Tseed> ) -> Tensor<OutputDtype>Parameters
logits2-D Tensor with shape
[batch_size, num_classes]. Each slice[i, :]represents the unnormalized log probabilities for all classes.num_samples0-D. Number of independent samples to draw for each row slice.
seed2 seeds (shape [2]).
-
Outputs deterministic pseudorandom values from a normal distribution.
The generated values will have mean 0 and standard deviation 1.
The outputs are a deterministic function of
shapeandseed.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statelessRandomNormal< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex, Tseed: TensorFlowIndex >( shape: Tensor<T>, seed: Tensor<Tseed> ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
seed2 seeds (shape [2]).
-
Outputs deterministic pseudorandom random values from a uniform distribution.
The generated values follow a uniform distribution in the range
[0, 1). The lower bound 0 is included in the range, while the upper bound 1 is excluded.The outputs are a deterministic function of
shapeandseed.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statelessRandomUniform< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex, Tseed: TensorFlowIndex >( shape: Tensor<T>, seed: Tensor<Tseed> ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
seed2 seeds (shape [2]).
-
Outputs deterministic pseudorandom random integers from a uniform distribution.
The generated values follow a uniform distribution in the range
[minval, maxval).The outputs are a deterministic function of
shape,seed,minval, andmaxval.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statelessRandomUniformInt< Dtype: TensorFlowIndex, T: TensorFlowIndex, Tseed: TensorFlowIndex >( shape: Tensor<T>, seed: Tensor<Tseed>, minval: Tensor<Dtype>, maxval: Tensor<Dtype> ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
seed2 seeds (shape [2]).
minvalMinimum value (inclusive, scalar).
maxvalMaximum value (exclusive, scalar).
-
Outputs deterministic pseudorandom values from a truncated normal distribution.
The generated values follow a normal distribution with mean 0 and standard deviation 1, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
The outputs are a deterministic function of
shapeandseed.Attr dtype: The type of the output.
Output output: Random values with specified shape.
Declaration
public static func statelessTruncatedNormal< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex, Tseed: TensorFlowIndex >( shape: Tensor<T>, seed: Tensor<Tseed> ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
seed2 seeds (shape [2]).
-
output = input; While (Cond(output)) { output = Body(output) }
Attrs:
- T: dtype in use.
cond: A function takes ‘input’ and returns a tensor. If the tensor is a scalar of non-boolean, the scalar is converted to a boolean according to the following rule: if the scalar is a numerical value, non-zero means True and zero means False; if the scalar is a string, non-empty means True and empty means False. If the tensor is not a scalar, non-emptiness means True and False otherwise.
This should only be used when the while condition and body functions do not have stateful ops.body: A function that takes a list of tensors and returns another list of tensors. Both lists have the same types as specified by T.
Output output: A list of output tensors whose types are T.
Declaration
public static func statelessWhile< T: TensorArrayProtocol, CondIn: TensorGroup, CondOut: TensorGroup, BodyIn: TensorGroup, BodyOut: TensorGroup >( _ input: T, cond: (CondIn) -> CondOut, body: (BodyIn) -> BodyOut, outputShapes: [TensorShape?], parallelIterations: Int64 = 10 ) -> TParameters
inputA list of input tensors whose types are T.
-
Check if the input matches the regex pattern.
The input is a string tensor of any shape. The pattern is the regular expression to be matched with every element of the input tensor. The boolean values (True or False) of the output tensor indicate if the input matches the regex pattern provided.
The pattern follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
Attr pattern: The regular expression to match the input.
Output output: A bool tensor with the same shape as
input.
Declaration
public static func staticRegexFullMatch( _ input: StringTensor, pattern: String ) -> Tensor<Bool>Parameters
inputA string tensor of the text to be processed.
-
Replaces the match of pattern in input with rewrite.
It follows the re2 syntax (https://github.com/google/re2/wiki/Syntax)
Attrs:
- pattern: The regular expression to match the input.
- rewrite: The rewrite to be applied to the matched expression.
- replace_global: If True, the replacement is global, otherwise the replacement is done only on the first match.
Output output: The text after applying pattern and rewrite.
Declaration
public static func staticRegexReplace( _ input: StringTensor, pattern: String, rewrite: String, replaceGlobal: Bool = true ) -> StringTensorParameters
inputThe text to be processed.
-
Creates a statistics manager resource.
Declaration
public static func statsAggregatorHandle( container: String, sharedName: String ) -> ResourceHandle -
Declaration
public static func statsAggregatorHandleV2( container: String, sharedName: String ) -> ResourceHandle -
Set a summary_writer_interface to record statistics using given stats_aggregator.
Declaration
public static func statsAggregatorSetSummaryWriter( statsAggregator: ResourceHandle, summary: ResourceHandle ) -
Produces a summary of any statistics recorded by the given statistics manager.
Declaration
public static func statsAggregatorSummary( iterator: ResourceHandle ) -> StringTensor -
Stops gradient computation.
When executed in a graph, this op outputs its input tensor as-is.
When building ops to compute gradients, this op prevents the contribution of its inputs to be taken into account. Normally, the gradient generator adds ops to a graph to compute the derivatives of a specified ‘loss’ by recursively finding out inputs that contributed to its computation. If you insert this op in the graph it inputs are masked from the gradient generator. They are not taken into account for computing gradients.
This is useful any time you want to compute a value with TensorFlow but need to pretend that the value was a constant. Some examples include:
- The EM algorithm where the M-step should not involve backpropagation through the output of the E-step.
- Contrastive divergence training of Boltzmann machines where, when differentiating the energy function, the training must not backpropagate through the graph that generated the samples from the model.
- Adversarial training, where no backprop should happen through the adversarial example generation process.
Declaration
public static func stopGradient<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Return a strided slice from
input.Note, most python users will want to use the Python
Tensor.__getitem__orVariable.__getitem__rather than this op directly.The goal of this op is to produce a new tensor with a subset of the elements from the
ndimensionalinputtensor. The subset is chosen using a sequence ofmsparse range specifications encoded into the arguments of this function. Note, in some casesmcould be equal ton, but this need not be the case. Each range specification entry can be one of the following:An ellipsis (…). Ellipses are used to imply zero or more dimensions of full-dimension selection and are produced using
ellipsis_mask. For example,foo[...]is the identity slice.A new axis. This is used to insert a new shape=1 dimension and is produced using
new_axis_mask. For example,foo[:, ...]wherefoois shape(3, 4)produces a(1, 3, 4)tensor.A range
begin:end:stride. This is used to specify how much to choose from a given dimension.stridecan be any integer but 0.beginis an integer which represents the index of the first value to select whileendrepresents the index of the last value to select. The number of values selected in each dimension isend - beginifstride > 0andbegin - endifstride < 0.beginandendcan be negative where-1is the last element,-2is the second to last.begin_maskcontrols whether to replace the explicitly givenbeginwith an implicit effective value of0ifstride > 0and-1ifstride < 0.end_maskis analogous but produces the number required to create the largest open interval. For example, given a shape(3,)tensorfoo[:], the effectivebeginandendare0and3. Do not assume this is equivalent tofoo[0:-1]which has an effectivebeginandendof0and2. Another example isfoo[-2::-1]which reverses the first dimension of a tensor while dropping the last two (in the original order elements). For examplefoo = [1,2,3,4]; foo[-2::-1]is[4,3].A single index. This is used to keep only elements that have a given index. For example (
foo[2, :]on a shape(5,6)tensor produces a shape(6,)tensor. This is encoded inbeginandendandshrink_axis_mask.
Each conceptual range specification is encoded in the op’s argument. This encoding is best understand by considering a non-trivial example. In particular,
foo[1, 2:4, None, ..., :-3:-1, :]will be encoded asbegin = [1, 2, x, x, 0, x] # x denotes don't care (usually 0) end = [2, 4, x, x, -3, x] strides = [1, 1, x, x, -1, 1] begin_mask = 1<<4 | 1 << 5 = 48 end_mask = 1<<5 = 32 ellipsis_mask = 1<<3 = 8 new_axis_mask = 1<<2 4 shrink_axis_mask = 1<<0In this case if
foo.shapeis (5, 5, 5, 5, 5, 5) the final shape of the slice becomes (2, 1, 5, 5, 2, 5). Let us walk step by step through each argument specification.The first argument in the example slice is turned into
begin = 1andend = begin + 1 = 2. To disambiguate from the original spec2:4we also set the appropriate bit inshrink_axis_mask.2:4is contributes 2, 4, 1 to begin, end, and stride. All masks have zero bits contributed.None is a synonym for
tf.newaxis. This means insert a dimension of size 1 dimension in the final shape. Dummy values are contributed to begin, end and stride, while the new_axis_mask bit is set....grab the full ranges from as many dimensions as needed to fully specify a slice for every dimension of the input shape.:-3:-1shows the use of negative indices. A negative indexiassociated with a dimension that has shapesis converted to a positive indexs + i. So-1becomess-1(i.e. the last element). This conversion is done internally so begin, end and strides receive x, -3, and -1. The appropriate begin_mask bit is set to indicate the start range is the full range (ignoring the x).:indicates that the entire contents of the corresponding dimension is selected. This is equivalent to::or0::1. begin, end, and strides receive 0, 0, and 1, respectively. The appropriate bits inbegin_maskandend_maskare also set.
Requirements:
0 != strides[i] for i in [0, m)ellipsis_mask must be a power of two (only one ellipsis)Attrs:
- begin_mask: a bitmask where a bit i being 1 means to ignore the begin
value and instead use the largest interval possible. At runtime
begin[i] will be replaced with
[0, n-1)ifstride[i] > 0or[-1, n-1]ifstride[i] < 0 - end_mask: analogous to
begin_mask - ellipsis_mask: a bitmask where bit
ibeing 1 means theith position is actually an ellipsis. One bit at most can be 1. Ifellipsis_mask == 0, then an implicit ellipsis mask of1 << (m+1)is provided. This means thatfoo[3:5] == foo[3:5, ...]. An ellipsis implicitly creates as many range specifications as necessary to fully specify the sliced range for every dimension. For example for a 4-dimensional tensorfoothe slicefoo[2, ..., 5:8]impliesfoo[2, :, :, 5:8]. - new_axis_mask: a bitmask where bit
ibeing 1 means theith specification creates a new shape 1 dimension. For examplefoo[:4, tf.newaxis, :2]would produce a shape(4, 1, 2)tensor. - shrink_axis_mask: a bitmask where bit
iimplies that theith specification should shrink the dimensionality. begin and end must imply a slice of size 1 in the dimension. For example in python one might dofoo[:, 3, :]which would result inshrink_axis_maskbeing 2.
- begin_mask: a bitmask where a bit i being 1 means to ignore the begin
value and instead use the largest interval possible. At runtime
begin[i] will be replaced with
Declaration
public static func stridedSlice< T: TensorFlowScalar, Index: TensorFlowIndex >( _ input: Tensor<T>, begin: Tensor<Index>, end: Tensor<Index>, strides: Tensor<Index>, beginMask: Int64 = 0, endMask: Int64 = 0, ellipsisMask: Int64 = 0, newAxisMask: Int64 = 0, shrinkAxisMask: Int64 = 0 ) -> Tensor<T>Parameters
beginbegin[k]specifies the offset into thekth range specification. The exact dimension this corresponds to will be determined by context. Out-of-bounds values will be silently clamped. If thekth bit ofbegin_maskthenbegin[k]is ignored and the full range of the appropriate dimension is used instead. Negative values causes indexing to start from the highest element e.g. Iffoo==[1,2,3]thenfoo[-1]==3.endend[i]is likebeginwith the exception thatend_maskis used to determine full ranges.stridesstrides[i]specifies the increment in theith specification after extracting a given element. Negative indices will reverse the original order. Out or range values are clamped to[0,dim[i]) if slice[i]>0or[-1,dim[i]-1] if slice[i] < 0 -
stridedSliceGrad(shape:begin:end:strides:dy:beginMask:endMask:ellipsisMask:newAxisMask:shrinkAxisMask:)
Returns the gradient of
StridedSlice.Since
StridedSlicecuts out pieces of itsinputwhich is sizeshape, its gradient will have the same shape (which is passed here asshape). The gradient will be zero in any element that the slice does not select.Arguments are the same as StridedSliceGrad with the exception that
dyis the input gradient to be propagated andshapeis the shape ofStridedSlice‘sinput.Declaration
public static func stridedSliceGrad< T: TensorFlowScalar, Index: TensorFlowIndex >( shape: Tensor<Index>, begin: Tensor<Index>, end: Tensor<Index>, strides: Tensor<Index>, dy: Tensor<T>, beginMask: Int64 = 0, endMask: Int64 = 0, ellipsisMask: Int64 = 0, newAxisMask: Int64 = 0, shrinkAxisMask: Int64 = 0 ) -> Tensor<T> -
Formats a string template using a list of tensors.
Formats a string template using a list of tensors, pretty-printing tensor summaries.
Attrs:
- template: A string, the template to format tensor summaries into.
- placeholder: A string, at each placeholder in the template a subsequent tensor summary will be inserted.
- summarize: When formatting the tensor summaries print the first and last summarize entries of each tensor dimension.
Output output: = The resulting string scalar.
Declaration
public static func stringFormat<T: TensorArrayProtocol>( inputs: T, template: String = "%s", placeholder: String = "%s", summarize: Int64 = 3 ) -> StringTensorParameters
inputsThe list of tensors to format into the placeholder string.
-
Joins the strings in the given list of string tensors into one tensor;
with the given separator (default is an empty separator).
Attr separator: string, an optional join separator.
Declaration
public static func stringJoin( inputs: [StringTensor], separator: String ) -> StringTensorParameters
inputsA list of string tensors. The tensors must all have the same shape, or be scalars. Scalars may be mixed in; these will be broadcast to the shape of non-scalar inputs.
-
String lengths of
input.Computes the length of each string given in the input tensor.
strings = tf.constant([‘Hello’,‘TensorFlow’, ‘\U0001F642’]) tf.strings.length(strings).numpy() # default counts bytes array([ 5, 10, 4], dtype=int32) tf.strings.length(strings, unit=“UTF8_CHAR”).numpy() array([ 5, 10, 1], dtype=int32)
Attr unit: The unit that is counted to compute string length. One of:
"BYTE"(for the number of bytes in each string) or"UTF8_CHAR"(for the number of UTF-8 encoded Unicode code points in each string). Results are undefined ifunit=UTF8_CHARand theinputstrings do not contain structurally valid UTF-8.Output output: Integer tensor that has the same shape as
input. The output contains the element-wise string lengths ofinput.
Declaration
public static func stringLength( _ input: StringTensor, unit: Unit = .byte ) -> Tensor<Int32>Parameters
inputThe strings for which to compute the length for each element.
-
Declaration
public static func stringListAttr( _ a: [String], _ b: String ) -
Converts each string in the input Tensor to lowercase.
Declaration
public static func stringLower( _ input: StringTensor, encoding: String ) -> StringTensor -
stringNGrams(data:dataSplits:separator:ngramWidths:leftPad:rightPad:padWidth:preserveShortSequences:)
Creates ngrams from ragged string data.
This op accepts a ragged tensor with 1 ragged dimension containing only strings and outputs a ragged tensor with 1 ragged dimension containing ngrams of that string, joined along the innermost axis.
Attrs:
- separator: The string to append between elements of the token. Use “” for no separator.
- ngram_widths: The sizes of the ngrams to create.
- left_pad: The string to use to pad the left side of the ngram sequence. Only used if pad_width != 0.
- right_pad: The string to use to pad the right side of the ngram sequence. Only used if pad_width != 0.
- pad_width: The number of padding elements to add to each side of each
sequence. Note that padding will never be greater than ‘ngram_widths’-1
regardless of this value. If
pad_width=-1, then addmax(ngram_widths)-1elements.
Outputs:
- ngrams: The values tensor of the output ngrams ragged tensor.
- ngrams_splits: The splits tensor of the output ngrams ragged tensor.
Declaration
public static func stringNGrams<Tsplits: TensorFlowIndex>( data: StringTensor, dataSplits: Tensor<Tsplits>, separator: String, ngramWidths: [Int32], leftPad: String, rightPad: String, padWidth: Int64, preserveShortSequences: Bool ) -> (ngrams: StringTensor, ngramsSplits: Tensor<Tsplits>)Parameters
dataThe values tensor of the ragged string tensor to make ngrams out of. Must be a 1D string tensor.
data_splitsThe splits tensor of the ragged string tensor to make ngrams out of.
-
Split elements of
inputbased ondelimiterinto aSparseTensor.Let N be the size of source (typically N will be the batch size). Split each element of
inputbased ondelimiterand return aSparseTensorcontaining the splitted tokens. Empty tokens are ignored.delimitercan be empty, or a string of split characters. Ifdelimiteris an empty string, each element ofinputis split into individual single-byte character strings, including splitting of UTF-8 multibyte sequences. Otherwise every character ofdelimiteris a potential split point.For example: N = 2, input[0] is ‘hello world’ and input[1] is ‘a b c’, then the output will be
indices = [0, 0; 0, 1; 1, 0; 1, 1; 1, 2] shape = [2, 3] values = [‘hello’, ‘world’, ‘a’, ‘b’, ‘c’]
Attr skip_empty: A
bool. IfTrue, skip the empty strings from the result.Outputs:
- indices: A dense matrix of int64 representing the indices of the sparse tensor.
- values: A vector of strings corresponding to the splited values.
- shape: a length-2 vector of int64 representing the shape of the sparse tensor, where the first value is N and the second value is the maximum number of tokens in a single input entry.
Declaration
public static func stringSplit( _ input: StringTensor, delimiter: StringTensor, skipEmpty: Bool = true ) -> (indices: Tensor<Int64>, values: StringTensor, shape: Tensor<Int64>)Parameters
input1-D. Strings to split.
delimiter0-D. Delimiter characters (bytes), or empty string.
-
Split elements of
sourcebased onsepinto aSparseTensor.Let N be the size of source (typically N will be the batch size). Split each element of
sourcebased onsepand return aSparseTensorcontaining the split tokens. Empty tokens are ignored.For example, N = 2, source[0] is ‘hello world’ and source[1] is ‘a b c’, then the output will be
st.indices = [0, 0; 0, 1; 1, 0; 1, 1; 1, 2] st.shape = [2, 3] st.values = ['hello', 'world', 'a', 'b', 'c']If
sepis given, consecutive delimiters are not grouped together and are deemed to delimit empty strings. For example, source of"1<>2<><>3"and sep of"<>"returns["1", "2", "", "3"]. Ifsepis None or an empty string, consecutive whitespace are regarded as a single separator, and the result will contain no empty strings at the startor end if the string has leading or trailing whitespace.Note that the above mentioned behavior matches python’s str.split.
Attr maxsplit: An
int. Ifmaxsplit > 0, limit of the split of the result.
Declaration
public static func stringSplitV2( _ input: StringTensor, sep: StringTensor, maxsplit: Int64 = -1 ) -> (indices: Tensor<Int64>, values: StringTensor, shape: Tensor<Int64>) -
Strip leading and trailing whitespaces from the Tensor.
Output output: A string
Tensorof the same shape as the input.
Declaration
public static func stringStrip( _ input: StringTensor ) -> StringTensorParameters
inputA string
Tensorof any shape. -
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process.
Note that the hash function may change from time to time. This functionality will be deprecated and it’s recommended to use
tf.string_to_hash_bucket_fast()ortf.string_to_hash_bucket_strong().Attr num_buckets: The number of buckets.
Output output: A Tensor of the same shape as the input
string_tensor.
Declaration
public static func stringToHashBucket( stringTensor: StringTensor, numBuckets: Int64 ) -> Tensor<Int64> -
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process and will never change. However, it is not suitable for cryptography. This function may be used when CPU time is scarce and inputs are trusted or unimportant. There is a risk of adversaries constructing inputs that all hash to the same bucket. To prevent this problem, use a strong hash function with
tf.string_to_hash_bucket_strong.Attr num_buckets: The number of buckets.
Output output: A Tensor of the same shape as the input
string_tensor.
Declaration
public static func stringToHashBucketFast( _ input: StringTensor, numBuckets: Int64 ) -> Tensor<Int64>Parameters
inputThe strings to assign a hash bucket.
-
Converts each string in the input Tensor to its hash mod by a number of buckets.
The hash function is deterministic on the content of the string within the process. The hash function is a keyed hash function, where attribute
keydefines the key of the hash function.keyis an array of 2 elements.A strong hash is important when inputs may be malicious, e.g. URLs with additional components. Adversaries could try to make their inputs hash to the same bucket for a denial-of-service attack or to skew the results. A strong hash can be used to make it difficult to find inputs with a skewed hash value distribution over buckets. This requires that the hash function is seeded by a high-entropy (random) “key” unknown to the adversary.
The additional robustness comes at a cost of roughly 4x higher compute time than
tf.string_to_hash_bucket_fast.Attrs:
- num_buckets: The number of buckets.
- key: The key used to seed the hash function, passed as a list of two uint64 elements.
Output output: A Tensor of the same shape as the input
string_tensor.
Declaration
public static func stringToHashBucketStrong( _ input: StringTensor, numBuckets: Int64, key: [Int32] ) -> Tensor<Int64>Parameters
inputThe strings to assign a hash bucket.
-
Converts each string in the input Tensor to the specified numeric type.
(Note that int32 overflow results in an error while float overflow results in a rounded value.)
Example:
strings = [“5.0”, “3.0”, “7.0”] tf.strings.to_number(strings)
Attr out_type: The numeric type to interpret each string in
string_tensoras.Output output: A Tensor of the same shape as the input
string_tensor.
Declaration
public static func stringToNumber<OutType: TensorFlowNumeric>( stringTensor: StringTensor ) -> Tensor<OutType> -
Converts each string in the input Tensor to uppercase.
Declaration
public static func stringUpper( _ input: StringTensor, encoding: String ) -> StringTensor -
Declaration
public static func stubResourceHandleOp( container: String, sharedName: String ) -> ResourceHandle -
Returns x - y element-wise.
NOTE:
Subtractsupports broadcasting. More about broadcasting hereDeclaration
public static func sub<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Return substrings from
Tensorof strings.For each string in the input
Tensor, creates a substring starting at indexposwith a total length oflen.If
lendefines a substring that would extend beyond the length of the input string, or iflenis negative, then as many characters as possible are used.A negative
posindicates distance within the string backwards from the end.If
posspecifies an index which is out of range for any of the input strings, then anInvalidArgumentErroris thrown.posandlenmust have the same shape, otherwise aValueErroris thrown on Op creation.NOTE:
Substrsupports broadcasting up to two dimensions. More about broadcasting here
Examples
Using scalar
posandlen:input = [b'Hello', b'World'] position = 1 length = 3 output = [b'ell', b'orl']Using
posandlenwith same shape asinput:input = [[b'ten', b'eleven', b'twelve'], [b'thirteen', b'fourteen', b'fifteen'], [b'sixteen', b'seventeen', b'eighteen']] position = [[1, 2, 3], [1, 2, 3], [1, 2, 3]] length = [[2, 3, 4], [4, 3, 2], [5, 5, 5]] output = [[b'en', b'eve', b'lve'], [b'hirt', b'urt', b'te'], [b'ixtee', b'vente', b'hteen']]Broadcasting
posandlenontoinput:input = [[b'ten', b'eleven', b'twelve'], [b'thirteen', b'fourteen', b'fifteen'], [b'sixteen', b'seventeen', b'eighteen'], [b'nineteen', b'twenty', b'twentyone']] position = [1, 2, 3] length = [1, 2, 3] output = [[b'e', b'ev', b'lve'], [b'h', b'ur', b'tee'], [b'i', b've', b'hte'], [b'i', b'en', b'nty']]Broadcasting
inputontoposandlen:input = b'thirteen' position = [1, 5, 7] length = [3, 2, 1] output = [b'hir', b'ee', b'n']Attr unit: The unit that is used to create the substring. One of:
"BYTE"(for defining position and length by bytes) or"UTF8_CHAR"(for the UTF-8 encoded Unicode code points). The default is"BYTE". Results are undefined ifunit=UTF8_CHARand theinputstrings do not contain structurally valid UTF-8.Output output: Tensor of substrings
Declaration
public static func substr<T: TensorFlowIndex>( _ input: StringTensor, pos: Tensor<T>, len: Tensor<T>, unit: Unit = .byte ) -> StringTensorParameters
inputTensor of strings
posScalar defining the position of first character in each substring
lenScalar defining the number of characters to include in each substring
-
Computes the sum of elements across dimensions of a tensor.
Reduces
inputalong the dimensions given inaxis. Unlesskeep_dimsis true, the rank of the tensor is reduced by 1 for each entry inaxis. Ifkeep_dimsis true, the reduced dimensions are retained with length 1.Attr keep_dims: If true, retain reduced dimensions with length 1.
Output output: The reduced tensor.
Declaration
public static func sum< T: TensorFlowNumeric, Tidx: TensorFlowIndex >( _ input: Tensor<T>, reductionIndices: Tensor<Tidx>, keepDims: Bool = false ) -> Tensor<T>Parameters
inputThe tensor to reduce.
reduction_indicesThe dimensions to reduce. Must be in the range
[-rank(input), rank(input)). -
Declaration
public static func summaryWriter( sharedName: String, container: String ) -> ResourceHandle -
Computes the singular value decompositions of one or more matrices.
Computes the SVD of each inner matrix in
inputsuch thatinput[..., :, :] = u[..., :, :] * diag(s[..., :, :]) * transpose(v[..., :, :])# a is a tensor containing a batch of matrices. # s is a tensor of singular values for each matrix. # u is the tensor containing the left singular vectors for each matrix. # v is the tensor containing the right singular vectors for each matrix. s, u, v = svd(a) s, _, _ = svd(a, compute_uv=False)Attrs:
- compute_uv: If true, left and right singular vectors will be
computed and returned in
uandv, respectively. If false,uandvare not set and should never referenced. - full_matrices: If true, compute full-sized
uandv. If false (the default), compute only the leadingPsingular vectors. Ignored ifcompute_uvisFalse.
- compute_uv: If true, left and right singular vectors will be
computed and returned in
Outputs:
- s: Singular values. Shape is
[..., P]. - u: Left singular vectors. If
full_matricesisFalsethen shape is[..., M, P]; iffull_matricesisTruethen shape is[..., M, M]. Undefined ifcompute_uvisFalse. - v: Left singular vectors. If
full_matricesisFalsethen shape is[..., N, P]. Iffull_matricesisTruethen shape is[..., N, N]. Undefined ifcompute_uvis false.
- s: Singular values. Shape is
Declaration
public static func svd<T: FloatingPoint & TensorFlowScalar>( _ input: Tensor<T>, computeUv: Bool = true, fullMatrices: Bool = false ) -> (s: Tensor<T>, u: Tensor<T>, v: Tensor<T>)Parameters
inputA tensor of shape
[..., M, N]whose inner-most 2 dimensions form matrices of size[M, N]. LetPbe the minimum ofMandN. -
Forwards
datato the output port determined bypred.If
predis true, thedatainput is forwarded tooutput_true. Otherwise, the data goes tooutput_false.See also
RefSwitchandMerge.Outputs:
- output_false: If
predis false, data will be forwarded to this output. - output_true: If
predis true, data will be forwarded to this output.
- output_false: If
Declaration
public static func switch_<T: TensorFlowScalar>( data: Tensor<T>, pred: Tensor<Bool> ) -> (outputFalse: Tensor<T>, outputTrue: Tensor<T>)Parameters
dataThe tensor to be forwarded to the appropriate output.
predA scalar that specifies which output port will receive data.
-
Computes the gradient function for function f via backpropagation.
Attrs:
- Tin: the type list for the input list.
- Tout: the type list for the input list.
f: The function we want to compute the gradient for.
The function ‘f’ must be a numerical function which takes N inputs and produces M outputs. Its gradient function ‘g’, which is computed by this SymbolicGradient op is a function taking N + M inputs and produces N outputs.
I.e. if we have (y1, y2, …, y_M) = f(x1, x2, …, x_N), then, g is (dL/dx1, dL/dx2, …, dL/dx_N) = g(x1, x2, …, x_N, dL/dy1, dL/dy2, …, dL/dy_M),
where L is a scalar-value function of (x1, x2, …, xN) (e.g., the loss function). dL/dx_i is the partial derivative of L with respect to x_i.
(Needs some math expert to say the comment above better.)
Output output: a list of output tensors of size N;
Declaration
public static func symbolicGradient< Tin: TensorArrayProtocol, Tout: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( _ input: Tin, f: (FIn) -> FOut ) -> ToutParameters
inputa list of input tensors of size N + M;
-
Creates a dataset that emits the records from one or more TFRecord files.
Declaration
public static func tFRecordDataset( filenames: StringTensor, compressionType: StringTensor, bufferSize: Tensor<Int64> ) -> VariantHandleParameters
filenamesA scalar or vector containing the name(s) of the file(s) to be read.
compression_typeA scalar containing either (i) the empty string (no compression), (ii) “ZLIB”, or (iii) “GZIP”.
buffer_sizeA scalar representing the number of bytes to buffer. A value of 0 means no buffering will be performed.
-
A Reader that outputs the records from a TensorFlow Records file.
Attrs:
- container: If non-empty, this reader is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
Output reader_handle: The handle to reference the Reader.
Declaration
public static func tFRecordReaderV2( container: String, sharedName: String, compressionType: String ) -> ResourceHandle -
Returns the result of a TPU compilation.
This operation returns the result of a TPU compilation as a serialized CompilationResultProto, which holds a status and an error message if an error occurred during compilation.
Declaration
public static func tPUCompilationResult() -> StringTensor -
An op enabling differentiation of TPU Embeddings.
This op simply returns its first input, which is assumed to have been sliced from the Tensors returned by TPUEmbeddingDequeueActivations. The presence of this op, and its first argument being a trainable Variable, enables automatic differentiation of graphs containing embeddings via the TPU Embedding Python libraries.
Attrs:
- table_id: The id of the table in the embedding layer configuration from which these activations were computed.
- lookup_id: Identifier of the set of embedding indices which produced these activations.
Declaration
Parameters
embedding_variableA trainable variable, enabling optimizers to find this op.
sliced_activationsThe embedding activations Tensor to return.
-
A TPU core selector Op.
This Op produces a set of TPU cores (for warm-up) or a single TPU core (for regular inference) to execute the TPU program on. The output is consumed by TPUPartitionedCall.
- Output device_ordinals: A vector 1 or more TPU cores.
Declaration
public static func tPUOrdinalSelector() -> Tensor<Int32> -
Calls a function placed on a specified TPU device.
Attrs:
- Tin: The types of the arguments to the function.
- Tout: The types of the outputs of the function.
- f: The function to call.
Output output: The output of the function call.
Declaration
public static func tPUPartitionedCall< Tin: TensorArrayProtocol, Tout: TensorGroup, FIn: TensorGroup, FOut: TensorGroup >( args: Tin, deviceOrdinal: Tensor<Int32>, f: (FIn) -> FOut, autotunerThresh: Int64 = 0 ) -> ToutParameters
argsThe arguments to the function.
device_ordinalThe TPU device ordinal to run the function on.
-
tPUReplicateMetadata(numReplicas:numCoresPerReplica:topology:useTpu:deviceAssignment:computationShape:hostComputeCore:paddingMap:stepMarkerLocation:allowSoftPlacement:)
Metadata indicating how the TPU computation should be replicated.
This operation holds the metadata common to operations of a
tpu.replicate()computation subgraph.- Attrs:
- num_replicas: Number of replicas of the computation
- num_cores_per_replica: Number of cores per replica. Used for model parallelism.
- topology: TopologyProto indicating the topology of the TPU pod slice.
- use_tpu: Whether to place the computation on the TPU.
- device_assignment: The assignment of devices for the computation.
- computation_shape: DEPRECATED. Use num_cores_per_replica instead.
Declaration
public static func tPUReplicateMetadata( numReplicas: Int64, numCoresPerReplica: Int64 = 1, topology: String, useTpu: Bool = true, deviceAssignment: [Int32], computationShape: [Int32], hostComputeCore: [String], paddingMap: [String], stepMarkerLocation: String = "STEP_MARK_AT_ENTRY", allowSoftPlacement: Bool = false ) - Attrs:
-
Connects N inputs to an N-way replicated TPU computation.
This operation holds a replicated input to a
tpu.replicate()computation subgraph. Each replicated input has the same shape and type alongside the output.For example:
%a = "tf.opA"() %b = "tf.opB"() %replicated_input = "tf.TPUReplicatedInput"(%a, %b) %computation = "tf.Computation"(%replicated_input)The above computation has a replicated input of two replicas.
Declaration
public static func tPUReplicatedInput<T: TensorFlowScalar>( inputs: [Tensor<T>], isMirroredVariable: Bool = false, index: Int64 = -1 ) -> Tensor<T> -
Connects N outputs from an N-way replicated TPU computation.
This operation holds a replicated output from a
tpu.replicate()computation subgraph. Each replicated output has the same shape and type alongside the input.For example:
%computation = "tf.Computation"() %replicated_output:2 = "tf.TPUReplicatedOutput"(%computation)The above computation has a replicated output of two replicas.
Declaration
public static func tPUReplicatedOutput<T: TensorFlowScalar>( _ input: Tensor<T>, numReplicas: Int64 ) -> [Tensor<T>] -
Creates a dataset that contains
countelements from theinput_dataset.Declaration
public static func takeDataset( inputDataset: VariantHandle, count: Tensor<Int64>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
countA scalar representing the number of elements from the
input_datasetthat should be taken. A value of-1indicates that all ofinput_datasetis taken. -
Read
SparseTensorsfrom aSparseTensorsMapand concatenate them.The input
sparse_handlesmust be anint64matrix of shape[N, 1]whereNis the minibatch size and the rows correspond to the output handles ofAddSparseToTensorsMaporAddManySparseToTensorsMap. The ranks of the originalSparseTensorobjects that went into the given input ops must all match. When the finalSparseTensoris created, it has rank one higher than the ranks of the incomingSparseTensorobjects (they have been concatenated along a new row dimension on the left).The output
SparseTensorobject’s shape values for all dimensions but the first are the max across the inputSparseTensorobjects’ shape values for the corresponding dimensions. Its first shape value isN, the minibatch size.The input
SparseTensorobjects’ indices are assumed ordered in standard lexicographic order. If this is not the case, after this step runSparseReorderto restore index ordering.For example, if the handles represent an input, which is a
[2, 3]matrix representing two originalSparseTensorobjects:index = [ 0] [10] [20] values = [1, 2, 3] shape = [50]and
index = [ 2] [10] values = [4, 5] shape = [30]then the final
SparseTensorwill be:index = [0 0] [0 10] [0 20] [1 2] [1 10] values = [1, 2, 3, 4, 5] shape = [2 50]Attrs:
- dtype: The
dtypeof theSparseTensorobjects stored in theSparseTensorsMap. - container: The container name for the
SparseTensorsMapread by this op. - shared_name: The shared name for the
SparseTensorsMapread by this op. It should not be blank; rather theshared_nameor unique Operation name of the Op that created the originalSparseTensorsMapshould be used.
- dtype: The
Outputs:
- sparse_indices: 2-D. The
indicesof the minibatchSparseTensor. - sparse_values: 1-D. The
valuesof the minibatchSparseTensor. - sparse_shape: 1-D. The
shapeof the minibatchSparseTensor.
- sparse_indices: 2-D. The
Declaration
public static func takeManySparseFromTensorsMap<Dtype: TensorFlowScalar>( sparseHandles: Tensor<Int64>, container: String, sharedName: String ) -> (sparseIndices: Tensor<Int64>, sparseValues: Tensor<Dtype>, sparseShape: Tensor<Int64>)Parameters
sparse_handles1-D, The
NserializedSparseTensorobjects. Shape:[N]. -
Creates a dataset that stops iteration when predicate` is false.
The
predicatefunction must return a scalar boolean and accept the following arguments:- One tensor for each component of an element of
input_dataset. One tensor for each value in
other_arguments.Attr predicate: A function returning a scalar boolean.
Declaration
public static func takeWhileDataset< PredicateIn: TensorGroup, PredicateOut: TensorGroup, Targuments: TensorArrayProtocol >( inputDataset: VariantHandle, otherArguments: Targuments, predicate: (PredicateIn) -> PredicateOut, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
other_argumentsA list of tensors, typically values that were captured when building a closure for
predicate. - One tensor for each component of an element of
-
Computes tan of x element-wise.
Given an input tensor, this function computes tangent of every element in the tensor. Input range is
(-inf, inf)and output range is(-inf, inf). If input lies outside the boundary,nanis returned.x = tf.constant([-float("inf"), -9, -0.5, 1, 1.2, 200, 10000, float("inf")]) tf.math.tan(x) ==> [nan 0.45231566 -0.5463025 1.5574077 2.572152 -1.7925274 0.32097113 nan]Declaration
public static func tan<T: TensorFlowNumeric>( _ x: Tensor<T> ) -> Tensor<T> -
Computes hyperbolic tangent of
xelement-wise.Given an input tensor, this function computes hyperbolic tangent of every element in the tensor. Input range is
[-inf, inf]and output range is[-1,1].x = tf.constant([-float("inf"), -5, -0.5, 1, 1.2, 2, 3, float("inf")]) tf.math.tanh(x) ==> [-1. -0.99990916 -0.46211717 0.7615942 0.8336547 0.9640276 0.9950547 1.]Declaration
public static func tanh<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T> -
Computes the gradient for the tanh of
xwrt its input.Specifically,
grad = dy * (1 - y*y), wherey = tanh(x), anddyis the corresponding input gradient.Declaration
public static func tanhGrad<T: FloatingPoint & TensorFlowScalar>( _ y: Tensor<T>, dy: Tensor<T> ) -> Tensor<T> -
Deprecated. Use TensorArrayCloseV3
Declaration
public static func tensorArrayCloseV2( handle: StringTensor ) -
Delete the TensorArray from its resource container.
This enables the user to close and release the resource in the middle of a step/run.
Declaration
public static func tensorArrayCloseV3( handle: ResourceHandle )Parameters
handleThe handle to a TensorArray (output of TensorArray or TensorArrayGrad).
-
Deprecated. Use TensorArrayConcatV3
Declaration
public static func tensorArrayConcatV2<Dtype: TensorFlowScalar>( handle: StringTensor, flowIn: Tensor<Float>, elementShapeExcept0: TensorShape? ) -> (value: Tensor<Dtype>, lengths: Tensor<Int64>) -
Concat the elements from the TensorArray into value
value.Takes
Telements of shapes(n0 x d0 x d1 x ...), (n1 x d0 x d1 x ...), ..., (n(T-1) x d0 x d1 x ...)and concatenates them into a Tensor of shape:
(n0 + n1 + ... + n(T-1) x d0 x d1 x ...)All elements must have the same shape (excepting the first dimension).
Attrs:
- dtype: The type of the elem that is returned.
- element_shape_except0: The expected shape of an element, if known, excluding the first dimension. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, concatenating zero-size TensorArrays is an error.
Outputs:
- value: All of the elements in the TensorArray, concatenated along the first axis.
- lengths: A vector of the row sizes of the original T elements in the
value output. In the example above, this would be the values:
(n1, n2, ..., n(T-1)).
Declaration
public static func tensorArrayConcatV3<Dtype: TensorFlowScalar>( handle: ResourceHandle, flowIn: Tensor<Float>, elementShapeExcept0: TensorShape? ) -> (value: Tensor<Dtype>, lengths: Tensor<Int64>)Parameters
handleThe handle to a TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArrayGatherV3
Declaration
public static func tensorArrayGatherV2<Dtype: TensorFlowScalar>( handle: StringTensor, indices: Tensor<Int32>, flowIn: Tensor<Float>, elementShape: TensorShape? ) -> Tensor<Dtype> -
Gather specific elements from the TensorArray into output
value.All elements selected by
indicesmust have the same shape.Attrs:
- dtype: The type of the elem that is returned.
- element_shape: The expected shape of an element, if known. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, gathering zero-size TensorArrays is an error.
Output value: All of the elements in the TensorArray, concatenated along a new axis (the new dimension 0).
Declaration
public static func tensorArrayGatherV3<Dtype: TensorFlowScalar>( handle: ResourceHandle, indices: Tensor<Int32>, flowIn: Tensor<Float>, elementShape: TensorShape? ) -> Tensor<Dtype>Parameters
handleThe handle to a TensorArray.
indicesThe locations in the TensorArray from which to read tensor elements.
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArrayGradV3
Declaration
public static func tensorArrayGradV2( handle: StringTensor, flowIn: Tensor<Float>, source: String ) -> StringTensor -
Creates a TensorArray for storing the gradients of values in the given handle.
If the given TensorArray gradient already exists, returns a reference to it.
Locks the size of the original TensorArray by disabling its dynamic size flag.
A note about the input flow_in:
The handle flow_in forces the execution of the gradient lookup to occur only after certain other operations have occurred. For example, when the forward TensorArray is dynamically sized, writes to this TensorArray may resize the object. The gradient TensorArray is statically sized based on the size of the forward TensorArray when this operation executes. Furthermore, the size of the forward TensorArray is frozen by this call. As a result, the flow is used to ensure that the call to generate the gradient TensorArray only happens after all writes are executed.
In the case of dynamically sized TensorArrays, gradient computation should only be performed on read operations that have themselves been chained via flow to occur only after all writes have executed. That way the final size of the forward TensorArray is known when this operation is called.
A note about the source attribute:
TensorArray gradient calls use an accumulator TensorArray object. If multiple gradients are calculated and run in the same session, the multiple gradient nodes may accidentally flow through the same accumulator TensorArray. This double counts and generally breaks the TensorArray gradient flow.
The solution is to identify which gradient call this particular TensorArray gradient is being called in. This is performed by identifying a unique string (e.g. “gradients”, “gradients_1”, …) from the input gradient Tensor’s name. This string is used as a suffix when creating the TensorArray gradient object here (the attribute
source).The attribute
sourceis added as a suffix to the forward TensorArray’s name when performing the creation / lookup, so that each separate gradient calculation gets its own TensorArray accumulator.Attr source: The gradient source string, used to decide which gradient TensorArray to return.
Declaration
public static func tensorArrayGradV3( handle: ResourceHandle, flowIn: Tensor<Float>, source: String ) -> (gradHandle: ResourceHandle, flowOut: Tensor<Float>)Parameters
handleThe handle to the forward TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Creates a TensorArray for storing multiple gradients of values in the given handle.
Similar to TensorArrayGradV3. However it creates an accumulator with an expanded shape compared to the input TensorArray whose gradient is being computed. This enables multiple gradients for the same TensorArray to be calculated using the same accumulator.
Attr source: The gradient source string, used to decide which gradient TensorArray to return.
Declaration
public static func tensorArrayGradWithShape( handle: ResourceHandle, flowIn: Tensor<Float>, shapeToPrepend: Tensor<Int32>, source: String ) -> (gradHandle: ResourceHandle, flowOut: Tensor<Float>)Parameters
handleThe handle to the forward TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
shape_to_prependAn int32 vector representing a shape. Elements in the gradient accumulator will have shape which is this shape_to_prepend value concatenated with shape of the elements in the TensorArray corresponding to the input handle.
-
Deprecated. Use TensorArrayReadV3
Declaration
public static func tensorArrayReadV2<Dtype: TensorFlowScalar>( handle: StringTensor, index: Tensor<Int32>, flowIn: Tensor<Float> ) -> Tensor<Dtype> -
Read an element from the TensorArray into output
value.Attr dtype: The type of the elem that is returned.
Output value: The tensor that is read from the TensorArray.
Declaration
public static func tensorArrayReadV3<Dtype: TensorFlowScalar>( handle: ResourceHandle, index: Tensor<Int32>, flowIn: Tensor<Float> ) -> Tensor<Dtype>Parameters
handleThe handle to a TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArrayScatterV3
Declaration
public static func tensorArrayScatterV2<T: TensorFlowScalar>( handle: StringTensor, indices: Tensor<Int32>, value: Tensor<T>, flowIn: Tensor<Float> ) -> Tensor<Float> -
Scatter the data from the input value into specific TensorArray elements.
indicesmust be a vector, its length must match the first dim ofvalue.Output flow_out: A float scalar that enforces proper chaining of operations.
Declaration
public static func tensorArrayScatterV3<T: TensorFlowScalar>( handle: ResourceHandle, indices: Tensor<Int32>, value: Tensor<T>, flowIn: Tensor<Float> ) -> Tensor<Float>Parameters
handleThe handle to a TensorArray.
indicesThe locations at which to write the tensor elements.
valueThe concatenated tensor to write to the TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArraySizeV3
Declaration
public static func tensorArraySizeV2( handle: StringTensor, flowIn: Tensor<Float> ) -> Tensor<Int32> -
Get the current size of the TensorArray.
Output size: The current size of the TensorArray.
Declaration
public static func tensorArraySizeV3( handle: ResourceHandle, flowIn: Tensor<Float> ) -> Tensor<Int32>Parameters
handleThe handle to a TensorArray (output of TensorArray or TensorArrayGrad).
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArraySplitV3
Declaration
public static func tensorArraySplitV2<T: TensorFlowScalar>( handle: StringTensor, value: Tensor<T>, lengths: Tensor<Int64>, flowIn: Tensor<Float> ) -> Tensor<Float> -
Split the data from the input value into TensorArray elements.
Assuming that
lengthstakes on values(n0, n1, ..., n(T-1))and that
valuehas shape(n0 + n1 + ... + n(T-1) x d0 x d1 x ...),this splits values into a TensorArray with T tensors.
TensorArray index t will be the subtensor of values with starting position
(n0 + n1 + ... + n(t-1), 0, 0, ...)and having size
nt x d0 x d1 x ...Output flow_out: A float scalar that enforces proper chaining of operations.
Declaration
public static func tensorArraySplitV3<T: TensorFlowScalar>( handle: ResourceHandle, value: Tensor<T>, lengths: Tensor<Int64>, flowIn: Tensor<Float> ) -> Tensor<Float>Parameters
handleThe handle to a TensorArray.
valueThe concatenated tensor to write to the TensorArray.
lengthsThe vector of lengths, how to split the rows of value into the TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Deprecated. Use TensorArrayV3
Declaration
public static func tensorArrayV2( size: Tensor<Int32>, dtype: TensorDataType, elementShape: TensorShape?, dynamicSize: Bool = false, clearAfterRead: Bool = true, tensorArrayName: String ) -> StringTensor -
tensorArrayV3(size:dtype:elementShape:dynamicSize:clearAfterRead:identicalElementShapes:tensorArrayName:)
An array of Tensors of given size.
Write data via Write and read via Read or Pack.
Attrs:
- dtype: The type of the elements on the tensor_array.
- element_shape: The expected shape of an element, if known. Used to validate the shapes of TensorArray elements. If this shape is not fully specified, gathering zero-size TensorArrays is an error.
- dynamic_size: A boolean that determines whether writes to the TensorArray are allowed to grow the size. By default, this is not allowed.
- clear_after_read: If true (default), Tensors in the TensorArray are cleared after being read. This disables multiple read semantics but allows early release of memory.
- identical_element_shapes: If true (default is false), then all elements in the TensorArray will be expected to have have identical shapes. This allows certain behaviors, like dynamically checking for consistent shapes on write, and being able to fill in properly shaped zero tensors on stack – even if the element_shape attribute is not fully defined.
- tensor_array_name: Overrides the name used for the temporary tensor_array resource. Default value is the name of the ‘TensorArray’ op (which is guaranteed unique).
Outputs:
- handle: The handle to the TensorArray.
- flow: A scalar used to control gradient flow.
Declaration
public static func tensorArrayV3( size: Tensor<Int32>, dtype: TensorDataType, elementShape: TensorShape?, dynamicSize: Bool = false, clearAfterRead: Bool = true, identicalElementShapes: Bool = false, tensorArrayName: String ) -> (handle: ResourceHandle, flow: Tensor<Float>)Parameters
sizeThe size of the array.
-
Deprecated. Use TensorArrayGradV3
Declaration
public static func tensorArrayWriteV2<T: TensorFlowScalar>( handle: StringTensor, index: Tensor<Int32>, value: Tensor<T>, flowIn: Tensor<Float> ) -> Tensor<Float> -
Push an element onto the tensor_array.
Output flow_out: A float scalar that enforces proper chaining of operations.
Declaration
public static func tensorArrayWriteV3<T: TensorFlowScalar>( handle: ResourceHandle, index: Tensor<Int32>, value: Tensor<T>, flowIn: Tensor<Float> ) -> Tensor<Float>Parameters
handleThe handle to a TensorArray.
indexThe position to write to inside the TensorArray.
valueThe tensor to write to the TensorArray.
flow_inA float scalar that enforces proper chaining of operations.
-
Creates a dataset that emits
componentsas a tuple of tensors once.Declaration
public static func tensorDataset<ToutputTypes: TensorArrayProtocol>( components: ToutputTypes, outputShapes: [TensorShape?] ) -> VariantHandle -
Creates a tree resource and returns a handle to it.
Declaration
public static func tensorForestCreateTreeVariable( treeHandle: ResourceHandle, treeConfig: StringTensor )Parameters
tree_handleHandle to the tree resource to be created.
tree_configSerialized proto string of the boosted_trees.Tree.
-
Deserializes a proto into the tree handle
Declaration
public static func tensorForestTreeDeserialize( treeHandle: ResourceHandle, treeConfig: StringTensor )Parameters
tree_handleHandle to the tree resource to be restored.
tree_configSerialied proto string of the boosted_trees.Tree proto.
-
Checks whether a tree has been initialized.
Output is_initialized: Whether the tree is initialized.
Declaration
public static func tensorForestTreeIsInitializedOp( treeHandle: ResourceHandle ) -> Tensor<Bool>Parameters
tree_handleHandle to the tree.
-
Output the logits for the given input data
Attr logits_dimension: Scalar, dimension of the logits.
Output logits: The logits predictions from the tree for each instance in the batch.
Declaration
public static func tensorForestTreePredict( treeHandle: ResourceHandle, denseFeatures: Tensor<Float>, logitsDimension: Int64 ) -> Tensor<Float>Parameters
tree_handleHandle to the tree resource.
dense_featuresRank 2 dense features tensor.
-
Creates a handle to a TensorForestTreeResource
Declaration
public static func tensorForestTreeResourceHandleOp( container: String, sharedName: String ) -> ResourceHandle -
Serializes the tree handle to a proto
Output tree_config: Serialied proto string of the tree resource.
Declaration
public static func tensorForestTreeSerialize( treeHandle: ResourceHandle ) -> StringTensorParameters
tree_handleHandle to the tree resource to be serialized.
-
Get the number of nodes in a tree
Output tree_size: The size of the tree.
Declaration
public static func tensorForestTreeSize( treeHandle: ResourceHandle ) -> Tensor<Int32>Parameters
tree_handleHandle to the tree resource.
-
Concats all tensors in the list along the 0th dimension.
Requires that all tensors have the same shape except the first dimension.
input_handle: The input list. tensor: The concated result. lengths: Output tensor containing sizes of the 0th dimension of tensors in the list, used for computing the gradient.
Declaration
public static func tensorListConcat<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, elementShape: TensorShape? ) -> (tensor: Tensor<ElementDtype>, lengths: Tensor<Int64>) -
Declaration
public static func tensorListConcatLists( inputA: VariantHandle, inputB: VariantHandle, elementDtype: TensorDataType ) -> VariantHandle -
Concats all tensors in the list along the 0th dimension.
Requires that all tensors have the same shape except the first dimension.
input_handle: The input list. element_shape: The shape of the uninitialized elements in the list. If the first dimension is not -1, it is assumed that all list elements have the same leading dim. leading_dims: The list of leading dims of uninitialized list elements. Used if the leading dim of input_handle.element_shape or the element_shape input arg is not already set. tensor: The concated result. lengths: Output tensor containing sizes of the 0th dimension of tensors in the list, used for computing the gradient.
Declaration
public static func tensorListConcatV2< ElementDtype: TensorFlowScalar, ShapeType: TensorFlowIndex >( inputHandle: VariantHandle, elementShape: Tensor<ShapeType>, leadingDims: Tensor<Int64> ) -> (tensor: Tensor<ElementDtype>, lengths: Tensor<Int64>) -
The shape of the elements of the given list, as a tensor.
input_handle: the list element_shape: the shape of elements of the list
Declaration
public static func tensorListElementShape<ShapeType: TensorFlowIndex>( inputHandle: VariantHandle ) -> Tensor<ShapeType> -
Creates a TensorList which, when stacked, has the value of
tensor.Each tensor in the result list corresponds to one row of the input tensor.
tensor: The input tensor. output_handle: The list.
Declaration
public static func tensorListFromTensor< ElementDtype: TensorFlowScalar, ShapeType: TensorFlowIndex >( _ tensor: Tensor<ElementDtype>, elementShape: Tensor<ShapeType> ) -> VariantHandle -
Creates a Tensor by indexing into the TensorList.
Each row in the produced Tensor corresponds to the element in the TensorList specified by the given index (see
tf.gather).input_handle: The input tensor list. indices: The indices used to index into the list. values: The tensor.
Declaration
public static func tensorListGather<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, indices: Tensor<Int32>, elementShape: Tensor<Int32> ) -> Tensor<ElementDtype> -
Declaration
public static func tensorListGetItem<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, index: Tensor<Int32>, elementShape: Tensor<Int32> ) -> Tensor<ElementDtype> -
Returns the number of tensors in the input tensor list.
input_handle: the input list length: the number of tensors in the list
Declaration
public static func tensorListLength( inputHandle: VariantHandle ) -> Tensor<Int32> -
Returns the last element of the input list as well as a list with all but that element.
Fails if the list is empty.
input_handle: the input list tensor: the withdrawn last element of the list element_dtype: the type of elements in the list element_shape: the shape of the output tensor
Declaration
public static func tensorListPopBack<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, elementShape: Tensor<Int32> ) -> (outputHandle: VariantHandle, tensor: Tensor<ElementDtype>) -
Returns a list which has the passed-in
Tensoras last element and the other elements of the given list ininput_handle.tensor: The tensor to put on the list. input_handle: The old list. output_handle: A list with the elements of the old list followed by tensor. element_dtype: the type of elements in the list. element_shape: a shape compatible with that of elements in the list.
Declaration
public static func tensorListPushBack<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, _ tensor: Tensor<ElementDtype> ) -> VariantHandle -
Declaration
public static func tensorListPushBackBatch<ElementDtype: TensorFlowScalar>( inputHandles: VariantHandle, _ tensor: Tensor<ElementDtype> ) -> VariantHandle -
List of the given size with empty elements.
element_shape: the shape of the future elements of the list num_elements: the number of elements to reserve handle: the output list element_dtype: the desired type of elements in the list.
Declaration
public static func tensorListReserve<ShapeType: TensorFlowIndex>( elementShape: Tensor<ShapeType>, numElements: Tensor<Int32>, elementDtype: TensorDataType ) -> VariantHandle -
Resizes the list.
input_handle: the input list size: size of the output list
Declaration
public static func tensorListResize( inputHandle: VariantHandle, size: Tensor<Int32> ) -> VariantHandle -
Creates a TensorList by indexing into a Tensor.
Each member of the TensorList corresponds to one row of the input tensor, specified by the given index (see
tf.gather).tensor: The input tensor. indices: The indices used to index into the list. element_shape: The shape of the elements in the list (can be less specified than the shape of the tensor). output_handle: The TensorList.
Declaration
public static func tensorListScatter< ElementDtype: TensorFlowScalar, ShapeType: TensorFlowIndex >( _ tensor: Tensor<ElementDtype>, indices: Tensor<Int32>, elementShape: Tensor<ShapeType> ) -> VariantHandle -
Scatters tensor at indices in an input list.
Each member of the TensorList corresponds to one row of the input tensor, specified by the given index (see
tf.gather).input_handle: The list to scatter into. tensor: The input tensor. indices: The indices used to index into the list. output_handle: The TensorList.
Declaration
public static func tensorListScatterIntoExistingList<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, _ tensor: Tensor<ElementDtype>, indices: Tensor<Int32> ) -> VariantHandle -
Creates a TensorList by indexing into a Tensor.
Each member of the TensorList corresponds to one row of the input tensor, specified by the given index (see
tf.gather).tensor: The input tensor. indices: The indices used to index into the list. element_shape: The shape of the elements in the list (can be less specified than the shape of the tensor). num_elements: The size of the output list. Must be large enough to accommodate the largest index in indices. If -1, the list is just large enough to include the largest index in indices. output_handle: The TensorList.
Declaration
public static func tensorListScatterV2< ElementDtype: TensorFlowScalar, ShapeType: TensorFlowIndex >( _ tensor: Tensor<ElementDtype>, indices: Tensor<Int32>, elementShape: Tensor<ShapeType>, numElements: Tensor<Int32> ) -> VariantHandle -
Declaration
public static func tensorListSetItem<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, index: Tensor<Int32>, item: Tensor<ElementDtype> ) -> VariantHandle -
Splits a tensor into a list.
list[i] corresponds to lengths[i] tensors from the input tensor. The tensor must have rank at least 1 and contain exactly sum(lengths) elements.
tensor: The input tensor. element_shape: A shape compatible with that of elements in the tensor. lengths: Vector of sizes of the 0th dimension of tensors in the list. output_handle: The list.
Declaration
public static func tensorListSplit< ElementDtype: TensorFlowScalar, ShapeType: TensorFlowIndex >( _ tensor: Tensor<ElementDtype>, elementShape: Tensor<ShapeType>, lengths: Tensor<Int64> ) -> VariantHandle -
Stacks all tensors in the list.
Requires that all tensors have the same shape.
input_handle: the input list tensor: the gathered result num_elements: optional. If not -1, the number of elements in the list.
Declaration
public static func tensorListStack<ElementDtype: TensorFlowScalar>( inputHandle: VariantHandle, elementShape: Tensor<Int32>, numElements: Int64 = -1 ) -> Tensor<ElementDtype> -
Adds sparse
updatesto an existing tensor according toindices.This operation creates a new tensor by adding sparse
updatesto the passed intensor. This operation is very similar totf.scatter_nd_add, except that the updates are added onto an existing tensor (as opposed to a variable). If the memory for the existing tensor cannot be re-used, a copy is made and updated.indicesis an integer tensor containing indices into a new tensor of shapeshape. The last dimension ofindicescan be at most the rank ofshape:indices.shape[-1] <= shape.rankThe last dimension of
indicescorresponds to indices into elements (ifindices.shape[-1] = shape.rank) or slices (ifindices.shape[-1] < shape.rank) along dimensionindices.shape[-1]ofshape.updatesis a tensor with shapeindices.shape[:-1] + shape[indices.shape[-1]:]The simplest form of tensor_scatter_add is to add individual elements to a tensor by index. For example, say we want to add 4 elements in a rank-1 tensor with 8 elements.
In Python, this scatter add operation would look like this:
indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) tensor = tf.ones([8], dtype=tf.int32) updated = tf.tensor_scatter_nd_add(tensor, indices, updates) print(updated)The resulting tensor would look like this:
[1, 12, 1, 11, 10, 1, 1, 13]We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter add operation would look like this:
indices = tf.constant([[0], [2]]) updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]]]) tensor = tf.ones([4, 4, 4],dtype=tf.int32) updated = tf.tensor_scatter_nd_add(tensor, indices, updates) print(updated)The resulting tensor would look like this:
[[[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]], [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]], [[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]], [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]]Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
Output output: A new tensor copied from tensor and updates added according to the indices.
Declaration
public static func tensorScatterAdd< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ tensor: Tensor<T>, indices: Tensor<Tindices>, updates: Tensor<T> ) -> Tensor<T>Parameters
tensorTensor to copy/update.
indicesIndex tensor.
updatesUpdates to scatter into output.
-
Subtracts sparse
updatesfrom an existing tensor according toindices.This operation creates a new tensor by subtracting sparse
updatesfrom the passed intensor. This operation is very similar totf.scatter_nd_sub, except that the updates are subtracted from an existing tensor (as opposed to a variable). If the memory for the existing tensor cannot be re-used, a copy is made and updated.indicesis an integer tensor containing indices into a new tensor of shapeshape. The last dimension ofindicescan be at most the rank ofshape:indices.shape[-1] <= shape.rankThe last dimension of
indicescorresponds to indices into elements (ifindices.shape[-1] = shape.rank) or slices (ifindices.shape[-1] < shape.rank) along dimensionindices.shape[-1]ofshape.updatesis a tensor with shapeindices.shape[:-1] + shape[indices.shape[-1]:]The simplest form of tensor_scatter_sub is to subtract individual elements from a tensor by index. For example, say we want to insert 4 scattered elements in a rank-1 tensor with 8 elements.
In Python, this scatter subtract operation would look like this:
indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) tensor = tf.ones([8], dtype=tf.int32) updated = tf.tensor_scatter_nd_sub(tensor, indices, updates) print(updated)The resulting tensor would look like this:
[1, -10, 1, -9, -8, 1, 1, -11]We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter add operation would look like this:
indices = tf.constant([[0], [2]]) updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]]]) tensor = tf.ones([4, 4, 4],dtype=tf.int32) updated = tf.tensor_scatter_nd_sub(tensor, indices, updates) print(updated)The resulting tensor would look like this:
[[[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]], [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]], [[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]], [[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]]Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
Output output: A new tensor copied from tensor and updates subtracted according to the indices.
Declaration
public static func tensorScatterSub< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ tensor: Tensor<T>, indices: Tensor<Tindices>, updates: Tensor<T> ) -> Tensor<T>Parameters
tensorTensor to copy/update.
indicesIndex tensor.
updatesUpdates to scatter into output.
-
Scatter
updatesinto an existing tensor according toindices.This operation creates a new tensor by applying sparse
updatesto the passed intensor. This operation is very similar totf.scatter_nd, except that the updates are scattered onto an existing tensor (as opposed to a zero-tensor). If the memory for the existing tensor cannot be re-used, a copy is made and updated.If
indicescontains duplicates, then their updates are accumulated (summed).WARNING: The order in which updates are applied is nondeterministic, so the output will be nondeterministic if
indicescontains duplicates – because of some numerical approximation issues, numbers summed in different order may yield different results.indicesis an integer tensor containing indices into a new tensor of shapeshape. The last dimension ofindicescan be at most the rank ofshape:indices.shape[-1] <= shape.rankThe last dimension of
indicescorresponds to indices into elements (ifindices.shape[-1] = shape.rank) or slices (ifindices.shape[-1] < shape.rank) along dimensionindices.shape[-1]ofshape.updatesis a tensor with shapeindices.shape[:-1] + shape[indices.shape[-1]:]The simplest form of scatter is to insert individual elements in a tensor by index. For example, say we want to insert 4 scattered elements in a rank-1 tensor with 8 elements.
In Python, this scatter operation would look like this:
>>> indices = tf.constant([[4], [3], [1], [7]]) >>> updates = tf.constant([9, 10, 11, 12]) >>> tensor = tf.ones([8], dtype=tf.int32) >>> print(tf.tensor_scatter_nd_update(tensor, indices, updates)) tf.Tensor([ 1 11 1 10 9 1 1 12], shape=(8,), dtype=int32)We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter operation would look like this:
>>> indices = tf.constant([[0], [2]]) >>> updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], ... [7, 7, 7, 7], [8, 8, 8, 8]], ... [[5, 5, 5, 5], [6, 6, 6, 6], ... [7, 7, 7, 7], [8, 8, 8, 8]]]) >>> tensor = tf.ones([4, 4, 4], dtype=tf.int32) >>> print(tf.tensor_scatter_nd_update(tensor, indices, updates).numpy()) [[[5 5 5 5] [6 6 6 6] [7 7 7 7] [8 8 8 8]] [[1 1 1 1] [1 1 1 1] [1 1 1 1] [1 1 1 1]] [[5 5 5 5] [6 6 6 6] [7 7 7 7] [8 8 8 8]] [[1 1 1 1] [1 1 1 1] [1 1 1 1] [1 1 1 1]]]Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
Output output: A new tensor with the given shape and updates applied according to the indices.
Declaration
public static func tensorScatterUpdate< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ tensor: Tensor<T>, indices: Tensor<Tindices>, updates: Tensor<T> ) -> Tensor<T>Parameters
tensorTensor to copy/update.
indicesIndex tensor.
updatesUpdates to scatter into output.
-
Creates a dataset that emits each dim-0 slice of
componentsonce.Declaration
public static func tensorSliceDataset<ToutputTypes: TensorArrayProtocol>( components: ToutputTypes, outputShapes: [TensorShape?] ) -> VariantHandle -
tensorStridedSliceUpdate(_:begin:end:strides:value:beginMask:endMask:ellipsisMask:newAxisMask:shrinkAxisMask:)
Assign
valueto the sliced l-value reference ofinput.The values of
valueare assigned to the positions in the tensorinputthat are selected by the slice parameters. The slice parametersbeginendstridesetc. work exactly as inStridedSlice.NOTE this op currently does not support broadcasting and so
value‘s shape must be exactly the shape produced by the slice ofinput.Declaration
public static func tensorStridedSliceUpdate< T: TensorFlowScalar, Index: TensorFlowIndex >( _ input: Tensor<T>, begin: Tensor<Index>, end: Tensor<Index>, strides: Tensor<Index>, value: Tensor<T>, beginMask: Int64 = 0, endMask: Int64 = 0, ellipsisMask: Int64 = 0, newAxisMask: Int64 = 0, shrinkAxisMask: Int64 = 0 ) -> Tensor<T> -
Outputs a
Summaryprotocol buffer with a tensor.This op is being phased out in favor of TensorSummaryV2, which lets callers pass a tag as well as a serialized SummaryMetadata proto string that contains plugin-specific data. We will keep this op to maintain backwards compatibility.
Attrs:
- description: A json-encoded SummaryDescription proto.
- labels: An unused list of strings.
- display_name: An unused string.
Declaration
public static func tensorSummary<T: TensorFlowScalar>( _ tensor: Tensor<T>, description: String, labels: [String], displayName: String ) -> StringTensorParameters
tensorA tensor to serialize.
-
Outputs a
Summaryprotocol buffer with a tensor and per-plugin data.Declaration
public static func tensorSummaryV2<T: TensorFlowScalar>( tag: StringTensor, _ tensor: Tensor<T>, serializedSummaryMetadata: StringTensor ) -> StringTensorParameters
tagA string attached to this summary. Used for organization in TensorBoard.
tensorA tensor to serialize.
serialized_summary_metadataA serialized SummaryMetadata proto. Contains plugin data.
-
Declaration
public static func testAttr<T>() -> Tensor<T> where T : FloatingPoint, T : TensorFlowScalar -
Declaration
public static func testStringOutput( _ input: Tensor<Float> ) -> (output1: Tensor<Float>, output2: StringTensor) -
Creates a dataset that emits the lines of one or more text files.
Declaration
public static func textLineDataset( filenames: StringTensor, compressionType: StringTensor, bufferSize: Tensor<Int64> ) -> VariantHandleParameters
filenamesA scalar or a vector containing the name(s) of the file(s) to be read.
compression_typeA scalar containing either (i) the empty string (no compression), (ii) “ZLIB”, or (iii) “GZIP”.
buffer_sizeA scalar containing the number of bytes to buffer.
-
A Reader that outputs the lines of a file delimited by ‘\n’.
Attrs:
- skip_header_lines: Number of lines to skip from the beginning of every file.
- container: If non-empty, this reader is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
Output reader_handle: The handle to reference the Reader.
Declaration
public static func textLineReaderV2( skipHeaderLines: Int64 = 0, container: String, sharedName: String ) -> ResourceHandle -
Creates a dataset that uses a custom thread pool to compute
input_dataset.Declaration
public static func threadPoolDataset( inputDataset: VariantHandle, threadPool: ResourceHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
thread_poolA resource produced by the ThreadPoolHandle op.
-
Creates a dataset that uses a custom thread pool to compute
input_dataset.Attrs:
- num_threads: The number of threads in the thread pool.
- max_intra_op_parallelism: The maximum degree of parallelism to use within operations that execute on this threadpool.
- display_name: A human-readable name for the threads that may be visible in some visualizations. threadpool.
Output handle: A resource that can be consumed by one or more ExperimentalThreadPoolDataset ops.
Declaration
public static func threadPoolHandle( numThreads: Int64, maxIntraOpParallelism: Int64 = 1, displayName: String, container: String, sharedName: String ) -> ResourceHandle -
Generates labels for candidate sampling with a learned unigram distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to randomly sample.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- range_max: The sampler will sample integers from the interval [0, range_max).
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
Constructs a tensor by tiling a given tensor.
This operation creates a new tensor by replicating
inputmultiplestimes. The output tensor’s i'th dimension hasinput.dims(i) * multiples[i]elements, and the values ofinputare replicatedmultiples[i]times along the ‘i'th dimension. For example, tiling[a b c d]by[2]produces[a b c d a b c d].a = tf.constant([[1,2,3],[4,5,6]], tf.int32) b = tf.constant([1,2], tf.int32) tf.tile(a, b)
Declaration
public static func tile< T: TensorFlowScalar, Tmultiples: TensorFlowIndex >( _ input: Tensor<T>, multiples: Tensor<Tmultiples> ) -> Tensor<T>Parameters
input1-D or higher.
multiples1-D. Length must be the same as the number of dimensions in
input -
Returns the gradient of
Tile.Since
Tiletakes an input and repeats the inputmultiplestimes along each dimension,TileGradtakes inmultiplesand aggregates each repeated tile ofinputintooutput.Declaration
public static func tileGrad<T: TensorFlowScalar>( _ input: Tensor<T>, multiples: Tensor<Int32> ) -> Tensor<T> -
Provides the time since epoch in seconds.
Returns the timestamp as a
float64for seconds since the Unix epoch.Note: the timestamp is computed when the op is executed, not when it is added to the graph.
Declaration
public static func timestamp() -> Tensor<Double> -
Finds values and indices of the
klargest elements for the last dimension.If the input is a vector (rank-1), finds the
klargest entries in the vector and outputs their values and indices as vectors. Thusvalues[j]is thej-th largest entry ininput, and its index isindices[j].For matrices (resp. higher rank input), computes the top
kentries in each row (resp. vector along the last dimension). Thus,values.shape = indices.shape = input.shape[:-1] + [k]If two elements are equal, the lower-index element appears first.
If
kvaries dynamically, useTopKV2below.Attrs:
- k: Number of top elements to look for along the last dimension (along each row for matrices).
- sorted: If true the resulting
kelements will be sorted by the values in descending order.
Outputs:
- values: The
klargest elements along each last dimensional slice. - indices: The indices of
valueswithin the last dimension ofinput.
- values: The
Declaration
public static func topK<T: TensorFlowNumeric>( _ input: Tensor<T>, k: Int64, sorted: Bool = true ) -> (values: Tensor<T>, indices: Tensor<Int32>)Parameters
input1-D or higher with last dimension at least
k. -
Finds values and indices of the
klargest elements for the last dimension.If the input is a vector (rank-1), finds the
klargest entries in the vector and outputs their values and indices as vectors. Thusvalues[j]is thej-th largest entry ininput, and its index isindices[j].For matrices (resp. higher rank input), computes the top
kentries in each row (resp. vector along the last dimension). Thus,values.shape = indices.shape = input.shape[:-1] + [k]If two elements are equal, the lower-index element appears first.
Attr sorted: If true the resulting
kelements will be sorted by the values in descending order.Outputs:
- values: The
klargest elements along each last dimensional slice. - indices: The indices of
valueswithin the last dimension ofinput.
- values: The
Declaration
public static func topKV2<T: TensorFlowNumeric>( _ input: Tensor<T>, k: Tensor<Int32>, sorted: Bool = true ) -> (values: Tensor<T>, indices: Tensor<Int32>)Parameters
input1-D or higher with last dimension at least
k.k0-D. Number of top elements to look for along the last dimension (along each row for matrices).
-
Shuffle dimensions of x according to a permutation.
The output
yhas the same rank asx. The shapes ofxandysatisfy:y.shape[i] == x.shape[perm[i]] for i in [0, 1, ..., rank(x) - 1]Declaration
public static func transpose< T: TensorFlowScalar, Tperm: TensorFlowIndex >( _ x: Tensor<T>, perm: Tensor<Tperm> ) -> Tensor<T> -
Calculate product with tridiagonal matrix.
Calculates product of two matrices, where left matrix is a tridiagonal matrix.
Output output: Tensor of shape
[..., M, N]containing the product.
Declaration
Parameters
superdiagTensor of shape
[..., 1, M], representing superdiagonals of tri-diagonal matrices to the left of multiplication. Last element is ingored.maindiagTensor of shape
[..., 1, M], representing main diagonals of tri-diagonal matrices to the left of multiplication.subdiagTensor of shape
[..., 1, M], representing subdiagonals of tri-diagonal matrices to the left of multiplication. First element is ingored.rhsTensor of shape
[..., M, N], representing MxN matrices to the right of multiplication. -
Solves tridiagonal systems of equations.
Solves tridiagonal systems of equations. Supports batch dimensions and multiple right-hand sides per each left-hand side. On CPU, solution is computed via Gaussian elimination with or without partial pivoting, depending on
partial_pivotingattribute. On GPU, Nvidia’s cuSPARSE library is used: https://docs.nvidia.com/cuda/cusparse/index.html#gtsvAttr partial_pivoting: Whether to apply partial pivoting. Partial pivoting makes the procedure more stable, but slower.
Output output: Tensor of shape
[..., M, K]containing the solutions
Declaration
public static func tridiagonalSolve<T: FloatingPoint & TensorFlowScalar>( diagonals: Tensor<T>, rhs: Tensor<T>, partialPivoting: Bool = true ) -> Tensor<T>Parameters
diagonalsTensor of shape
[..., 3, M]whose innermost 2 dimensions represent the tridiagonal matrices with three rows being the superdiagonal, diagonals, and subdiagonals, in order. The last element of the superdiagonal and the first element of the subdiagonal is ignored.rhsTensor of shape
[..., M, K], representing K right-hand sides per each left-hand side. -
Returns x / y element-wise for integer types.
Truncation designates that negative numbers will round fractional quantities toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different than Python semantics. See
FloorDivfor a division function that matches Python Semantics.NOTE:
TruncateDivsupports broadcasting. More about broadcasting hereDeclaration
public static func truncateDiv<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns element-wise remainder of division. This emulates C semantics in that
the result here is consistent with a truncating divide. E.g.
truncate(x / y) * y + truncate_mod(x, y) = x.NOTE:
TruncateModsupports broadcasting. More about broadcasting hereDeclaration
public static func truncateMod<T: TensorFlowNumeric>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Outputs random values from a truncated normal distribution.
The generated values follow a normal distribution with mean 0 and standard deviation 1, except that values whose magnitude is more than 2 standard deviations from the mean are dropped and re-picked.
Attrs:
- seed: If either
seedorseed2are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed. - seed2: A second seed to avoid seed collision.
- dtype: The type of the output.
- seed: If either
Output output: A tensor of the specified shape filled with random truncated normal values.
Declaration
public static func truncatedNormal< Dtype: FloatingPoint & TensorFlowScalar, T: TensorFlowIndex >( shape: Tensor<T>, seed: Int64 = 0, seed2: Int64 = 0 ) -> Tensor<Dtype>Parameters
shapeThe shape of the output tensor.
-
Perform batches of RPC requests.
This op asynchronously performs either a single RPC request, or a batch of requests. RPC requests are defined by three main parameters:
address(the host+port or BNS address of the request)method(the method name for the request)request(the serialized proto string, or vector of strings, of the RPC request argument).
For example, if you have an RPC service running on port localhost:2345, and its interface is configured with the following proto declaration:
service MyService { rpc MyMethod(MyRequestProto) returns (MyResponseProto) { } };then call this op with arguments:
address = "localhost:2345" method = "MyService/MyMethod"The
requesttensor is a string tensor representing serializedMyRequestProtostrings; and the output string tensorresponsewill have the same shape and contain (upon successful completion) corresponding serializedMyResponseProtostrings.For example, to send a single, empty,
MyRequestProto, call this op withrequest = "". To send 5 parallel empty requests, call this op withrequest = ["", "", "", "", ""].More generally, one can create a batch of
MyRequestProtoserialized protos from regular batched tensors using theencode_protoop, and convert the responseMyResponseProtoserialized protos to batched tensors using thedecode_protoop.NOTE Working with serialized proto strings is faster than instantiating actual proto objects in memory, so no performance degradation is expected compared to writing custom kernels for this workflow.
Unlike the standard
Rpcop, if the connection fails or the remote worker returns an error status, this op does not reraise the exception. Instead, thestatus_codeandstatus_messageentry for the corresponding RPC call is set with the error returned from the RPC call. Theresponsetensor will contain valid response values for those minibatch entries whose RPCs did not fail; the rest of the entries will have empty strings.Attrs:
- protocol: RPC protocol to use. Empty string means use the default protocol. Options include ‘grpc’.
- fail_fast:
boolean. Iftrue(default), then failures to connect (i.e., the server does not immediately respond) cause an RPC failure. - timeout_in_ms:
int. If0(default), then the kernel will run the RPC request and only time out if the RPC deadline passes or the session times out. If this value is greater than0, then the op will raise an exception if the RPC takes longer thantimeout_in_ms.
Outputs:
- response: Same shape as
request. Serialized proto strings: the rpc responses. - status_code: Same shape as
request. Values correspond to tensorflow Status enum codes. - status_message: Same shape as
request. Values correspond to Status messages returned from the RPC calls.
- response: Same shape as
Declaration
public static func tryRpc( address: StringTensor, method: StringTensor, request: StringTensor, protocol_: String, failFast: Bool = true, timeoutInMs: Int64 = 0 ) -> (response: StringTensor, statusCode: Tensor<Int32>, statusMessage: StringTensor)Parameters
address0-Dor1-D. The address (i.e. host_name:port) of the RPC server. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withmethodandrequest.method0-Dor1-D. The method address on the RPC server. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withaddressandrequest.request0-Dor1-D. Serialized proto strings: the rpc request argument. If this tensor has more than 1 element, then multiple parallel rpc requests are sent. This argument broadcasts withaddressandmethod. -
Declaration
public static func typeList<T: TensorArrayProtocol>( _ a: T ) -
Declaration
public static func typeListRestrict<T: TensorArrayProtocol>( _ a: T ) -
Declaration
public static func typeListTwice<T: TensorArrayProtocol>( _ a: T, _ b: T ) -
Declaration
public static func unary<T: TensorFlowScalar>( _ a: Tensor<T> ) -> Tensor<T> -
Reverses the operation of Batch for a single output Tensor.
An instance of Unbatch either receives an empty batched_tensor, in which case it asynchronously waits until the values become available from a concurrently running instance of Unbatch with the same container and shared_name, or receives a non-empty batched_tensor in which case it finalizes all other concurrently running instances and outputs its own element from the batch.
batched_tensor: The possibly transformed output of Batch. The size of the first dimension should remain unchanged by the transformations for the operation to work. batch_index: The matching batch_index obtained from Batch. id: The id scalar emitted by Batch. unbatched_tensor: The Tensor corresponding to this execution. timeout_micros: Maximum amount of time (in microseconds) to wait to receive the batched input tensor associated with a given invocation of the op. container: Container to control resource sharing. shared_name: Instances of Unbatch with the same container and shared_name are assumed to possibly belong to the same batch. If left empty, the op name will be used as the shared name.
Declaration
public static func unbatch<T: TensorFlowScalar>( batchedTensor: Tensor<T>, batchIndex: Tensor<Int64>, id: Tensor<Int64>, timeoutMicros: Int64, container: String, sharedName: String ) -> Tensor<T> -
A dataset that splits the elements of its input into multiple elements.
Declaration
public static func unbatchDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Gradient of Unbatch.
Acts like Batch but using the given batch_index index of batching things as they become available. This ensures that the gradients are propagated back in the same session which did the forward pass.
original_input: The input to the Unbatch operation this is the gradient of. batch_index: The batch_index given to the Unbatch operation this is the gradient of. grad: The downstream gradient. id: The id scalar emitted by Batch. batched_grad: The return value, either an empty tensor or the batched gradient. container: Container to control resource sharing. shared_name: Instances of UnbatchGrad with the same container and shared_name are assumed to possibly belong to the same batch. If left empty, the op name will be used as the shared name.
-
Decodes each string in
inputinto a sequence of Unicode code points.The character codepoints for all strings are returned using a single vector
char_values, with strings expanded to characters in row-major order.The
row_splitstensor indicates where the codepoints for each input string begin and end within thechar_valuestensor. In particular, the values for theith string (in row-major order) are stored in the slice[row_splits[i]:row_splits[i+1]]. Thus:char_values[row_splits[i]+j]is the Unicode codepoint for thejth character in theith string (in row-major order).row_splits[i+1] - row_splits[i]is the number of characters in theith string (in row-major order).Attrs:
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
"UTF-16", "US ASCII", "UTF-8". - errors: Error handling policy when there is invalid formatting found in the input.
The value of ‘strict’ will cause the operation to produce a InvalidArgument
error on any invalid input formatting. A value of ‘replace’ (the default) will
cause the operation to replace any invalid formatting in the input with the
replacement_charcodepoint. A value of ‘ignore’ will cause the operation to skip any invalid formatting in the input and produce no corresponding output character. - replacement_char: The replacement character codepoint to be used in place of any invalid
formatting in the input when
errors='replace'. Any valid unicode codepoint may be used. The default value is the default unicode replacement character is 0xFFFD or U+65533.) - replace_control_characters: Whether to replace the C0 control characters (00-1F) with the
replacement_char. Default is false.
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
Outputs:
- row_splits: A 1D int32 tensor containing the row splits.
- char_values: A 1D int32 Tensor containing the decoded codepoints.
Declaration
public static func unicodeDecode<Tsplits: TensorFlowIndex>( _ input: StringTensor, inputEncoding: String, errors: Errors = .replace, replacementChar: Int64 = 65533, replaceControlCharacters: Bool = false ) -> (rowSplits: Tensor<Tsplits>, charValues: Tensor<Int32>)Parameters
inputThe text to be decoded. Can have any shape. Note that the output is flattened to a vector of char values.
-
Decodes each string in
inputinto a sequence of Unicode code points.The character codepoints for all strings are returned using a single vector
char_values, with strings expanded to characters in row-major order. Similarly, the character start byte offsets are returned using a single vectorchar_to_byte_starts, with strings expanded in row-major order.The
row_splitstensor indicates where the codepoints and start offsets for each input string begin and end within thechar_valuesandchar_to_byte_startstensors. In particular, the values for theith string (in row-major order) are stored in the slice[row_splits[i]:row_splits[i+1]]. Thus:char_values[row_splits[i]+j]is the Unicode codepoint for thejth character in theith string (in row-major order).char_to_bytes_starts[row_splits[i]+j]is the start byte offset for thejth character in theith string (in row-major order).row_splits[i+1] - row_splits[i]is the number of characters in theith string (in row-major order).Attrs:
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
"UTF-16", "US ASCII", "UTF-8". - errors: Error handling policy when there is invalid formatting found in the input.
The value of ‘strict’ will cause the operation to produce a InvalidArgument
error on any invalid input formatting. A value of ‘replace’ (the default) will
cause the operation to replace any invalid formatting in the input with the
replacement_charcodepoint. A value of ‘ignore’ will cause the operation to skip any invalid formatting in the input and produce no corresponding output character. - replacement_char: The replacement character codepoint to be used in place of any invalid
formatting in the input when
errors='replace'. Any valid unicode codepoint may be used. The default value is the default unicode replacement character is 0xFFFD or U+65533.) - replace_control_characters: Whether to replace the C0 control characters (00-1F) with the
replacement_char. Default is false.
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
Outputs:
- row_splits: A 1D int32 tensor containing the row splits.
- char_values: A 1D int32 Tensor containing the decoded codepoints.
- char_to_byte_starts: A 1D int32 Tensor containing the byte index in the input string where each
character in
char_valuesstarts.
Declaration
public static func unicodeDecodeWithOffsets<Tsplits: TensorFlowIndex>( _ input: StringTensor, inputEncoding: String, errors: Errors = .replace, replacementChar: Int64 = 65533, replaceControlCharacters: Bool = false ) -> (rowSplits: Tensor<Tsplits>, charValues: Tensor<Int32>, charToByteStarts: Tensor<Int64>)Parameters
inputThe text to be decoded. Can have any shape. Note that the output is flattened to a vector of char values.
-
Encode a tensor of ints into unicode strings.
Returns a vector of strings, where
output[i]is constructed by encoding the Unicode codepoints ininput_values[input_splits[i]:input_splits[i+1]]usingoutput_encoding.
Example:
input_values = [72, 101, 108, 108, 111, 87, 111, 114, 108, 100] input_splits = [0, 5, 10] output_encoding = 'UTF-8' output = ['Hello', 'World']Attrs:
- errors: Error handling policy when there is invalid formatting found in the input.
The value of ‘strict’ will cause the operation to produce a InvalidArgument
error on any invalid input formatting. A value of ‘replace’ (the default) will
cause the operation to replace any invalid formatting in the input with the
replacement_charcodepoint. A value of ‘ignore’ will cause the operation to skip any invalid formatting in the input and produce no corresponding output character. - output_encoding: Unicode encoding of the output strings. Valid encodings are:
"UTF-8", "UTF-16-BE", and "UTF-32-BE". - replacement_char: The replacement character codepoint to be used in place of any invalid
formatting in the input when
errors='replace'. Any valid unicode codepoint may be used. The default value is the default unicode replacement character is 0xFFFD (U+65533).
- errors: Error handling policy when there is invalid formatting found in the input.
The value of ‘strict’ will cause the operation to produce a InvalidArgument
error on any invalid input formatting. A value of ‘replace’ (the default) will
cause the operation to replace any invalid formatting in the input with the
Output output: The 1-D Tensor of strings encoded from the provided unicode codepoints.
Declaration
public static func unicodeEncode<Tsplits: TensorFlowIndex>( inputValues: Tensor<Int32>, inputSplits: Tensor<Tsplits>, errors: Errors = .replace, outputEncoding: OutputEncoding, replacementChar: Int64 = 65533 ) -> StringTensorParameters
input_valuesA 1D tensor containing the unicode codepoints that should be encoded.
input_splitsA 1D tensor specifying how the unicode codepoints should be split into strings. In particular,
output[i]is constructed by encoding the codepoints in the sliceinput_values[input_splits[i]:input_splits[i+1]]. -
Determine the script codes of a given tensor of Unicode integer code points.
This operation converts Unicode code points to script codes corresponding to each code point. Script codes correspond to International Components for Unicode (ICU) UScriptCode values. See http://icu-project.org/apiref/icu4c/uscript_8h.html. Returns -1 (USCRIPT_INVALID_CODE) for invalid codepoints. Output shape will match input shape.
Output output: A Tensor of int32 script codes corresponding to each input code point.
Parameters
inputA Tensor of int32 Unicode code points.
-
Transcode the input text from a source encoding to a destination encoding.
The input is a string tensor of any shape. The output is a string tensor of the same shape containing the transcoded strings. Output strings are always valid unicode. If the input contains invalid encoding positions, the
errorsattribute sets the policy for how to deal with them. If the default error-handling policy is used, invalid formatting will be substituted in the output by thereplacement_char. If the errors policy is toignore, any invalid encoding positions in the input are skipped and not included in the output. If it set tostrictthen any invalid formatting will result in an InvalidArgument error.This operation can be used with
output_encoding = input_encodingto enforce correct formatting for inputs even if they are already in the desired encoding.If the input is prefixed by a Byte Order Mark needed to determine encoding (e.g. if the encoding is UTF-16 and the BOM indicates big-endian), then that BOM will be consumed and not emitted into the output. If the input encoding is marked with an explicit endianness (e.g. UTF-16-BE), then the BOM is interpreted as a non-breaking-space and is preserved in the output (including always for UTF-8).
The end result is that if the input is marked as an explicit endianness the transcoding is faithful to all codepoints in the source. If it is not marked with an explicit endianness, the BOM is not considered part of the string itself but as metadata, and so is not preserved in the output.
Attrs:
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
"UTF-16", "US ASCII", "UTF-8". - output_encoding: The unicode encoding to use in the output. Must be one of
"UTF-8", "UTF-16-BE", "UTF-32-BE". Multi-byte encodings will be big-endian. - errors: Error handling policy when there is invalid formatting found in the input.
The value of ‘strict’ will cause the operation to produce a InvalidArgument
error on any invalid input formatting. A value of ‘replace’ (the default) will
cause the operation to replace any invalid formatting in the input with the
replacement_charcodepoint. A value of ‘ignore’ will cause the operation to skip any invalid formatting in the input and produce no corresponding output character. replacement_char: The replacement character codepoint to be used in place of any invalid formatting in the input when
errors='replace'. Any valid unicode codepoint may be used. The default value is the default unicode replacement character is 0xFFFD or U+65533.)Note that for UTF-8, passing a replacement character expressible in 1 byte, such as ‘ ’, will preserve string alignment to the source since invalid bytes will be replaced with a 1-byte replacement. For UTF-16-BE and UTF-16-LE, any 1 or 2 byte replacement character will preserve byte alignment to the source.
replace_control_characters: Whether to replace the C0 control characters (00-1F) with the
replacement_char. Default is false.
- input_encoding: Text encoding of the input strings. This is any of the encodings supported
by ICU ucnv algorithmic converters. Examples:
Output output: A string tensor containing unicode text encoded using
output_encoding.
Declaration
public static func unicodeTranscode( _ input: StringTensor, inputEncoding: String, outputEncoding: OutputEncoding, errors: Errors = .replace, replacementChar: Int64 = 65533, replaceControlCharacters: Bool = false ) -> StringTensorParameters
inputThe text to be processed. Can have any shape.
-
Generates labels for candidate sampling with a uniform distribution.
See explanations of candidate sampling and the data formats at go/candidate-sampling.
For each batch, this op picks a single set of sampled candidate labels.
The advantages of sampling candidates per-batch are simplicity and the possibility of efficient dense matrix multiplication. The disadvantage is that the sampled candidates must be chosen independently of the context and of the true labels.
Attrs:
- num_true: Number of true labels per context.
- num_sampled: Number of candidates to randomly sample.
- unique: If unique is true, we sample with rejection, so that all sampled candidates in a batch are unique. This requires some approximation to estimate the post-rejection sampling probabilities.
- range_max: The sampler will sample integers from the interval [0, range_max).
- seed: If either seed or seed2 are set to be non-zero, the random number generator is seeded by the given seed. Otherwise, it is seeded by a random seed.
- seed2: An second seed to avoid seed collision.
Outputs:
- sampled_candidates: A vector of length num_sampled, in which each element is the ID of a sampled candidate.
- true_expected_count: A batch_size * num_true matrix, representing the number of times each candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
- sampled_expected_count: A vector of length num_sampled, for each sampled candidate representing the number of times the candidate is expected to occur in a batch of sampled candidates. If unique=true, then this is a probability.
Declaration
Parameters
true_classesA batch_size * num_true matrix, in which each row contains the IDs of the num_true target_classes in the corresponding original label.
-
Finds unique elements in a 1-D tensor.
This operation returns a tensor
ycontaining all of the unique elements ofxsorted in the same order that they occur inx;xdoes not need to be sorted. This operation also returns a tensoridxthe same size asxthat contains the index of each value ofxin the unique outputy. In other words:y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]Examples:
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx = unique(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]# tensor 'x' is [4, 5, 1, 2, 3, 3, 4, 5] y, idx = unique(x) y ==> [4, 5, 1, 2, 3] idx ==> [0, 1, 2, 3, 4, 4, 0, 1]Outputs:
- y: 1-D.
- idx: 1-D.
Declaration
public static func unique< T: TensorFlowScalar, OutIdx: TensorFlowIndex >( _ x: Tensor<T> ) -> (y: Tensor<T>, idx: Tensor<OutIdx>)Parameters
x1-D.
-
Creates a dataset that contains the unique elements of
input_dataset.Declaration
public static func uniqueDataset( inputDataset: VariantHandle, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandle -
Finds unique elements along an axis of a tensor.
This operation either returns a tensor
ycontaining unique elements along theaxisof a tensor. The returned unique elements is sorted in the same order as they occur alongaxisinx. This operation also returns a tensoridxthat is the same size as the number of the elements inxalong theaxisdimension. It contains the index in the unique outputy. In other words, for an1-Dtensorxwith `axis = None:y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]For example:
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx = unique(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]For an
2-Dtensorxwithaxis = 0:# tensor 'x' is [[1, 0, 0], # [1, 0, 0], # [2, 0, 0]] y, idx = unique(x, axis=0) y ==> [[1, 0, 0], [2, 0, 0]] idx ==> [0, 0, 1]For an
2-Dtensorxwithaxis = 1:# tensor 'x' is [[1, 0, 0], # [1, 0, 0], # [2, 0, 0]] y, idx = unique(x, axis=1) y ==> [[1, 0], [1, 0], [2, 0]] idx ==> [0, 1, 1]Declaration
public static func uniqueV2< T: TensorFlowScalar, Taxis: TensorFlowIndex, OutIdx: TensorFlowIndex >( _ x: Tensor<T>, axis: Tensor<Taxis> ) -> (y: Tensor<T>, idx: Tensor<OutIdx>) -
Finds unique elements in a 1-D tensor.
This operation returns a tensor
ycontaining all of the unique elements ofxsorted in the same order that they occur inx. This operation also returns a tensoridxthe same size asxthat contains the index of each value ofxin the unique outputy. Finally, it returns a third tensorcountthat contains the count of each element ofyinx. In other words:y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]For example:
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx, count = unique_with_counts(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] count ==> [2, 1, 3, 1, 2]Outputs:
- y: 1-D.
- idx: 1-D.
- count: 1-D.
Declaration
public static func uniqueWithCounts< T: TensorFlowScalar, OutIdx: TensorFlowIndex >( _ x: Tensor<T> ) -> (y: Tensor<T>, idx: Tensor<OutIdx>, count: Tensor<OutIdx>)Parameters
x1-D.
-
Finds unique elements along an axis of a tensor.
This operation either returns a tensor
ycontaining unique elements along theaxisof a tensor. The returned unique elements is sorted in the same order as they occur alongaxisinx. This operation also returns a tensoridxand a tensorcountthat are the same size as the number of the elements inxalong theaxisdimension. Theidxcontains the index in the unique outputyand thecountcontains the count in the unique outputy. In other words, for an1-Dtensorxwith `axis = None:y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]For example:
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8] y, idx, count = unique_with_counts(x) y ==> [1, 2, 4, 7, 8] idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4] count ==> [2, 1, 3, 1, 2]For an
2-Dtensorxwithaxis = 0:# tensor 'x' is [[1, 0, 0], # [1, 0, 0], # [2, 0, 0]] y, idx, count = unique_with_counts(x, axis=0) y ==> [[1, 0, 0], [2, 0, 0]] idx ==> [0, 0, 1] count ==> [2, 1]For an
2-Dtensorxwithaxis = 1:# tensor 'x' is [[1, 0, 0], # [1, 0, 0], # [2, 0, 0]] y, idx, count = unique_with_counts(x, axis=1) y ==> [[1, 0], [1, 0], [2, 0]] idx ==> [0, 1, 1] count ==> [1, 2]Declaration
public static func uniqueWithCountsV2< T: TensorFlowScalar, Taxis: TensorFlowIndex, OutIdx: TensorFlowIndex >( _ x: Tensor<T>, axis: Tensor<Taxis> ) -> (y: Tensor<T>, idx: Tensor<OutIdx>, count: Tensor<OutIdx>) -
Unpacks a given dimension of a rank-
Rtensor intonumrank-(R-1)tensors.Unpacks
numtensors fromvalueby chipping it along theaxisdimension. For example, given a tensor of shape(A, B, C, D);If
axis == 0then the i'th tensor inoutputis the slicevalue[i, :, :, :]and each tensor inoutputwill have shape(B, C, D). (Note that the dimension unpacked along is gone, unlikesplit).If
axis == 1then the i'th tensor inoutputis the slicevalue[:, i, :, :]and each tensor inoutputwill have shape(A, C, D). Etc.This is the opposite of
pack.Attr axis: Dimension along which to unpack. Negative values wrap around, so the valid range is
[-R, R).Output output: The list of tensors unpacked from
value.
Declaration
public static func unpack<T: TensorFlowScalar>( value: Tensor<T>, num: Int64, axis: Int64 = 0 ) -> [Tensor<T>]Parameters
value1-D or higher, with
axisdimension size equal tonum. -
Converts an array of flat indices into a tuple of coordinate arrays.
Example:
y = tf.unravel_index(indices=[2, 5, 7], dims=[3, 3]) # 'dims' represent a hypothetical (3, 3) tensor of indices: # [[0, 1, *2*], # [3, 4, *5*], # [6, *7*, 8]] # For each entry from 'indices', this operation returns # its coordinates (marked with '*'), such as # 2 ==> (0, 2) # 5 ==> (1, 2) # 7 ==> (2, 1) y ==> [[0, 1, 2], [2, 2, 1]]@compatibility(numpy) Equivalent to np.unravel_index @end_compatibility
Output output: An 2-D (or 1-D if indices is 0-D) tensor where each row has the same shape as the indices array.
Declaration
public static func unravelIndex<Tidx: TensorFlowIndex>( indices: Tensor<Tidx>, dims: Tensor<Tidx> ) -> Tensor<Tidx>Parameters
indicesAn 0-D or 1-D
intTensor whose elements are indices into the flattened version of an array of dimensions dims.dimsAn 1-D
intTensor. The shape of the array to use for unraveling indices. -
Joins the elements of
inputsbased onsegment_ids.Computes the string join along segments of a tensor. Given
segment_idswith rankNanddatawith rankN+M:`output[i, k1...kM] = strings.join([data[j1...jN, k1...kM])`where the join is over all [j1…jN] such that segment_ids[j1…jN] = i. Strings are joined in row-major order.
For example:
inputs = [['Y', 'q', 'c'], ['Y', '6', '6'], ['p', 'G', 'a']] output_array = string_ops.unsorted_segment_join(inputs=inputs, segment_ids=[1, 0, 1], num_segments=2, separator=':')) # output_array ==> [['Y', '6', '6'], ['Y:p', 'q:G', 'c:a']] inputs = ['this', 'is', 'a', 'test'] output_array = string_ops.unsorted_segment_join(inputs=inputs, segment_ids=[0, 0, 0, 0], num_segments=1, separator=':')) # output_array ==> ['this:is:a:test']Attr separator: The separator to use when joining.
Declaration
public static func unsortedSegmentJoin< Tindices: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( inputs: StringTensor, segmentIds: Tensor<Tindices>, numSegments: Tensor<Tnumsegments>, separator: String ) -> StringTensorParameters
inputsThe input to be joined.
segment_idsA tensor whose shape is a prefix of data.shape. Negative segment ids are not supported.
num_segmentsA scalar.
-
Computes the maximum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
This operator is similar to the unsorted segment sum operator found (here). Instead of computing the sum over segments, it computes the maximum such that:
\(output_i = \max_{j…} data[j…]\) where max is over tuples
j...such thatsegment_ids[j...] == i.If the maximum is empty for a given segment ID
i, it outputs the smallest possible value for the specific numeric type,output[i] = numeric_limits<T>::lowest().If the given segment ID
iis negative, then the corresponding value is dropped, and will not be included in the result.
For example:
c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) tf.unsorted_segment_max(c, tf.constant([0, 1, 0]), num_segments=2) # ==> [[ 4, 3, 3, 4], # [5, 6, 7, 8]]Output output: Has same shape as data, except for the first
segment_ids.rankdimensions, which are replaced with a single dimension which has sizenum_segments.
Declaration
public static func unsortedSegmentMax< T: TensorFlowNumeric, Tindices: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
segment_idsA tensor whose shape is a prefix of
data.shape. -
Computes the minimum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
This operator is similar to the unsorted segment sum operator found (here). Instead of computing the sum over segments, it computes the minimum such that:
\(output_i = \min_{j…} data_[j…]\) where min is over tuples
j...such thatsegment_ids[j...] == i.If the minimum is empty for a given segment ID
i, it outputs the largest possible value for the specific numeric type,output[i] = numeric_limits<T>::max().For example:
c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) tf.unsorted_segment_min(c, tf.constant([0, 1, 0]), num_segments=2) # ==> [[ 1, 2, 2, 1], # [5, 6, 7, 8]]If the given segment ID
iis negative, then the corresponding value is dropped, and will not be included in the result.Output output: Has same shape as data, except for the first
segment_ids.rankdimensions, which are replaced with a single dimension which has sizenum_segments.
Declaration
public static func unsortedSegmentMin< T: TensorFlowNumeric, Tindices: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
segment_idsA tensor whose shape is a prefix of
data.shape. -
Computes the product along segments of a tensor.
Read the section on segmentation for an explanation of segments.
This operator is similar to the unsorted segment sum operator found (here). Instead of computing the sum over segments, it computes the product of all entries belonging to a segment such that:
\(output_i = \prod_{j…} data[j…]\) where the product is over tuples
j...such thatsegment_ids[j...] == i.For example:
c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) tf.unsorted_segment_prod(c, tf.constant([0, 1, 0]), num_segments=2) # ==> [[ 4, 6, 6, 4], # [5, 6, 7, 8]]If there is no entry for a given segment ID
i, it outputs 1.If the given segment ID
iis negative, then the corresponding value is dropped, and will not be included in the result.Output output: Has same shape as data, except for the first
segment_ids.rankdimensions, which are replaced with a single dimension which has sizenum_segments.
Declaration
public static func unsortedSegmentProd< T: TensorFlowNumeric, Tindices: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
segment_idsA tensor whose shape is a prefix of
data.shape. -
Computes the sum along segments of a tensor.
Read the section on segmentation for an explanation of segments.
Computes a tensor such that \(output[i] = \sum_{j…} data[j…]\) where the sum is over tuples
j...such thatsegment_ids[j...] == i. UnlikeSegmentSum,segment_idsneed not be sorted and need not cover all values in the full range of valid values.If the sum is empty for a given segment ID
i,output[i] = 0. If the given segment IDiis negative, the value is dropped and will not be added to the sum of the segment.num_segmentsshould equal the number of distinct segment IDs.
c = tf.constant([[1,2,3,4], [5,6,7,8], [4,3,2,1]]) tf.unsorted_segment_sum(c, tf.constant([0, 1, 0]), num_segments=2) # ==> [[ 5, 5, 5, 5], # [5, 6, 7, 8]]Output output: Has same shape as data, except for the first
segment_ids.rankdimensions, which are replaced with a single dimension which has sizenum_segments.
Declaration
public static func unsortedSegmentSum< T: TensorFlowNumeric, Tindices: TensorFlowIndex, Tnumsegments: TensorFlowIndex >( data: Tensor<T>, segmentIds: Tensor<Tindices>, numSegments: Tensor<Tnumsegments> ) -> Tensor<T>Parameters
segment_idsA tensor whose shape is a prefix of
data.shape. -
Op is similar to a lightweight Dequeue.
The basic functionality is similar to dequeue with many fewer capabilities and options. This Op is optimized for performance.
Declaration
public static func unstage<Dtypes: TensorGroup>( capacity: Int64 = 0, memoryLimit: Int64 = 0, container: String, sharedName: String ) -> Dtypes -
Declaration
public static func unwrapDatasetVariant( inputHandle: VariantHandle ) -> VariantHandle -
Applies upper_bound(sorted_search_values, values) along each row.
Each set of rows with the same index in (sorted_inputs, values) is treated independently. The resulting row is the equivalent of calling
np.searchsorted(sorted_inputs, values, side='right').The result is not a global index to the entire
Tensor, but rather just the index in the last dimension.A 2-D example: sorted_sequence = [[0, 3, 9, 9, 10], [1, 2, 3, 4, 5]] values = [[2, 4, 9], [0, 2, 6]]
result = UpperBound(sorted_sequence, values)
result == [[1, 2, 4], [0, 2, 5]]
Output output: A
Tensorwith the same shape asvalues. It contains the last scalar index into the last dimension where values can be inserted without changing the ordered property.
Declaration
public static func upperBound< T: TensorFlowScalar, OutType: TensorFlowIndex >( sortedInputs: Tensor<T>, _ values: Tensor<T> ) -> Tensor<OutType>Parameters
sorted_inputs2-D Tensor where each row is ordered.
values2-D Tensor with the same numbers of rows as
sorted_search_values. Contains the values that will be searched for insorted_search_values. -
Creates a handle to a Variable resource.
- Attrs:
- container: the container this variable is placed in.
- shared_name: the name by which this variable is referred to.
- dtype: the type of this variable. Must agree with the dtypes of all ops using this variable.
- shape: The (possibly partially specified) shape of this variable.
Declaration
public static func varHandleOp( container: String, sharedName: String, dtype: TensorDataType, shape: TensorShape? ) -> ResourceHandle - Attrs:
-
Checks whether a resource handle-based variable has been initialized.
Output is_initialized: a scalar boolean which is true if the variable has been initialized.
Declaration
public static func varIsInitializedOp( resource: ResourceHandle ) -> Tensor<Bool>Parameters
resourcethe input resource handle.
-
Returns the shape of the variable pointed to by
resource.This operation returns a 1-D integer tensor representing the shape of
input.For example:
# 't' is [[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]] shape(t) ==> [2, 2, 3]Declaration
public static func variableShape<OutType: TensorFlowIndex>( _ input: ResourceHandle ) -> Tensor<OutType> -
Returns locations of nonzero / true values in a tensor.
This operation returns the coordinates of true elements in
condition. The coordinates are returned in a 2-D tensor where the first dimension (rows) represents the number of true elements, and the second dimension (columns) represents the coordinates of the true elements. Keep in mind, the shape of the output tensor can vary depending on how many true values there are incondition. Indices are output in row-major order.For example:
# 'input' tensor is [[True, False] # [True, False]] # 'input' has two true values, so output has two coordinates. # 'input' has rank of 2, so coordinates have two indices. where(input) ==> [[0, 0], [1, 0]] # `condition` tensor is [[[True, False] # [True, False]] # [[False, True] # [False, True]] # [[False, False] # [False, True]]] # 'input' has 5 true values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0], [0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]] # `condition` tensor is [[[1.5, 0.0] # [-0.5, 0.0]] # [[0.0, 0.25] # [0.0, 0.75]] # [[0.0, 0.0] # [0.0, 0.01]]] # 'input' has 5 nonzero values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0], [0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]] # `condition` tensor is [[[1.5 + 0.0j, 0.0 + 0.0j] # [0.0 + 0.5j, 0.0 + 0.0j]] # [[0.0 + 0.0j, 0.25 + 1.5j] # [0.0 + 0.0j, 0.75 + 0.0j]] # [[0.0 + 0.0j, 0.0 + 0.0j] # [0.0 + 0.0j, 0.01 + 0.0j]]] # 'input' has 5 nonzero magnitude values, so output has 5 coordinates. # 'input' has rank of 3, so coordinates have three indices. where(input) ==> [[0, 0, 0], [0, 1, 0], [1, 0, 1], [1, 1, 1], [2, 1, 1]]Declaration
public static func where_<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<Int64> -
output = input; While (Cond(output)) { output = Body(output) }
Attrs:
- T: dtype in use.
- cond: A function takes ‘input’ and returns a tensor. If the tensor is a scalar of non-boolean, the scalar is converted to a boolean according to the following rule: if the scalar is a numerical value, non-zero means True and zero means False; if the scalar is a string, non-empty means True and empty means False. If the tensor is not a scalar, non-emptiness means True and False otherwise.
- body: A function that takes a list of tensors and returns another list of tensors. Both lists have the same types as specified by T.
Output output: A list of output tensors whose types are T.
Declaration
public static func while_< T: TensorArrayProtocol, CondIn: TensorGroup, CondOut: TensorGroup, BodyIn: TensorGroup, BodyOut: TensorGroup >( _ input: T, cond: (CondIn) -> CondOut, body: (BodyIn) -> BodyOut, outputShapes: [TensorShape?], parallelIterations: Int64 = 10 ) -> TParameters
inputA list of input tensors whose types are T.
-
A Reader that outputs the entire contents of a file as a value.
To use, enqueue filenames in a Queue. The output of ReaderRead will be a filename (key) and the contents of that file (value).
Attrs:
- container: If non-empty, this reader is placed in the given container. Otherwise, a default container is used.
- shared_name: If non-empty, this reader is named in the given bucket with this shared_name. Otherwise, the node name is used instead.
Output reader_handle: The handle to reference the Reader.
Declaration
public static func wholeFileReaderV2( container: String, sharedName: String ) -> ResourceHandle -
A dataset that creates window datasets from the input dataset.
Declaration
public static func windowDataset( inputDataset: VariantHandle, size: Tensor<Int64>, shift: Tensor<Int64>, stride: Tensor<Int64>, dropRemainder: Tensor<Bool>, outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
sizeA scalar representing the number of elements to accumulate in a window.
shiftA scalar representing the steps moving the sliding window forward in one iteration. It must be positive.
strideA scalar representing the stride of the input elements of the sliding window. It must be positive.
drop_remainderA scalar representing whether a window should be dropped in case its size is smaller than desired.
-
Worker heartbeat op.
Heartbeats may be sent periodically to indicate the coordinator is still active, to retrieve the current worker status and to expedite shutdown when necessary.
Output response: A string tensor containing a serialized WorkerHeartbeatResponse
Declaration
public static func workerHeartbeat( request: StringTensor ) -> StringTensorParameters
requestA string tensor containing a serialized WorkerHeartbeatRequest
-
Declaration
public static func wrapDatasetVariant( inputHandle: VariantHandle ) -> VariantHandle -
Declaration
public static func writeAudioSummary( writer: ResourceHandle, step: Tensor<Int64>, tag: StringTensor, _ tensor: Tensor<Float>, sampleRate: Tensor<Float>, maxOutputs: Int64 = 3 ) -
Writes contents to the file at input filename. Creates file and recursively
creates directory if not existing.
Declaration
public static func writeFile( filename: StringTensor, contents: StringTensor )Parameters
filenamescalar. The name of the file to which we write the contents.
contentsscalar. The content to be written to the output file.
-
Declaration
public static func writeGraphSummary( writer: ResourceHandle, step: Tensor<Int64>, _ tensor: StringTensor ) -
Declaration
public static func writeHistogramSummary<T: TensorFlowNumeric>( writer: ResourceHandle, step: Tensor<Int64>, tag: StringTensor, _ values: Tensor<T> ) -
Declaration
public static func writeImageSummary<T: TensorFlowNumeric>( writer: ResourceHandle, step: Tensor<Int64>, tag: StringTensor, _ tensor: Tensor<T>, badColor: Tensor<UInt8>, maxImages: Int64 = 3 ) -
Declaration
public static func writeRawProtoSummary( writer: ResourceHandle, step: Tensor<Int64>, _ tensor: StringTensor ) -
Declaration
public static func writeScalarSummary<T: TensorFlowNumeric>( writer: ResourceHandle, step: Tensor<Int64>, tag: StringTensor, value: Tensor<T> ) -
Declaration
public static func writeSummary<T: TensorFlowScalar>( writer: ResourceHandle, step: Tensor<Int64>, _ tensor: Tensor<T>, tag: StringTensor, summaryMetadata: StringTensor ) -
Returns 0 if x == 0, and x / y otherwise, elementwise.
Declaration
public static func xdivy<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Helper operator for performing XLA-style broadcasts
Broadcasts
lhsandrhsto the same rank, by adding size 1 dimensions to whichever oflhsandrhshas the lower rank, using XLA’s broadcasting rules for binary operators.Outputs:
- lhs_output: the broadcasted LHS tensor
- rhs_output: the broadcasted RHS tensor
Declaration
public static func xlaBroadcastHelper< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( lhs: Tensor<T>, rhs: Tensor<T>, broadcastDims: Tensor<Tindices> ) -> (lhsOutput: Tensor<T>, rhsOutput: Tensor<T>)Parameters
lhsthe LHS input tensor
rhsthe RHS input tensor
broadcast_dimsan XLA-style broadcast dimension specification
-
xlaConv(lhs:rhs:windowStrides:padding:lhsDilation:rhsDilation:featureGroupCount:dimensionNumbers:precisionConfig:)
Wraps the XLA ConvGeneralDilated operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#conv_convolution .
Attrs:
- dimension_numbers: a serialized xla::ConvolutionDimensionNumbers proto.
- precision_config: a serialized xla::PrecisionConfig proto.
Declaration
public static func xlaConv< T: TensorFlowNumeric, Tindices: TensorFlowIndex >( lhs: Tensor<T>, rhs: Tensor<T>, windowStrides: Tensor<Tindices>, padding: Tensor<Tindices>, lhsDilation: Tensor<Tindices>, rhsDilation: Tensor<Tindices>, featureGroupCount: Tensor<Tindices>, dimensionNumbers: String, precisionConfig: String ) -> Tensor<T>Parameters
lhsthe input tensor
rhsthe kernel tensor
window_stridesthe inter-window strides
paddingthe padding to apply at the start and end of each input dimensions
lhs_dilationdilation to apply between input elements
rhs_dilationdilation to apply between kernel elements
feature_group_countnumber of feature groups for grouped convolution.
-
Wraps the XLA DotGeneral operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#dotgeneral .
Attrs:
- dimension_numbers: a serialized xla::DotDimensionNumbers proto.
- precision_config: a serialized xla::PrecisionConfig proto.
Declaration
public static func xlaDot<T: TensorFlowNumeric>( lhs: Tensor<T>, rhs: Tensor<T>, dimensionNumbers: String, precisionConfig: String ) -> Tensor<T>Parameters
lhsthe LHS tensor
rhsthe RHS tensor
-
Wraps the XLA DynamicSlice operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#dynamicslice .
DynamicSlice extracts a sub-array from the input array at dynamic start_indices. The size of the slice in each dimension is passed in size_indices, which specify the end point of exclusive slice intervals in each dimension – [start, start + size). The shape of start_indices must have rank 1, with dimension size equal to the rank of operand.
Declaration
public static func xlaDynamicSlice< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ input: Tensor<T>, startIndices: Tensor<Tindices>, sizeIndices: Tensor<Tindices> ) -> Tensor<T>Parameters
inputA
Tensorof type T.start_indicesList of N integers containing the slice size for each dimension. Each value must be strictly greater than zero, and start + size must be less than or equal to the size of the dimension to avoid implementation defined behavior.
-
Wraps the XLA DynamicUpdateSlice operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#dynamicupdateslice .
XlaDynamicUpdateSlice generates a result which is the value of the
inputoperand, with a slice update overwritten atindices. The shape ofupdatedetermines the shape of the sub-array of the result which is updated. The shape of indices must be rank == 1, with dimension size equal to the rank ofinput.Handling of out-of-bounds slice indices is implementation-defined.
Output output: A
Tensorof type T.
Declaration
public static func xlaDynamicUpdateSlice< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ input: Tensor<T>, update: Tensor<T>, indices: Tensor<Tindices> ) -> Tensor<T> -
An op which supports basic einsum op with 2 inputs and 1 output.
This op has better TPU performnce since it doesn’t have explicitly reshape and transpose operations as tf.einsum does.
Declaration
public static func xlaEinsum<T: FloatingPoint & TensorFlowScalar>( _ a: Tensor<T>, _ b: Tensor<T>, equation: String ) -> Tensor<T> -
output = cond ? then_branch(inputs) : else_branch(inputs).
Attrs:
- then_branch: A function takes ‘inputs’ and returns a list of tensors, whose types are the same as what else_branch returns.
- else_branch: A function takes ‘inputs’ and returns a list of tensors. whose types are the same as what then_branch returns.
Output output: A list of tensors returned by either then_branch(inputs) or else_branch(inputs). The input shapes of the then_branch and else_branch must match.
Declaration
public static func xlaIf< Tcond: TensorFlowScalar, ThenbranchIn: TensorGroup, ThenbranchOut: TensorGroup, ElsebranchIn: TensorGroup, ElsebranchOut: TensorGroup, Tin: TensorArrayProtocol, Tout: TensorGroup >( cond: Tensor<Tcond>, inputs: Tin, thenBranch: (ThenbranchIn) -> ThenbranchOut, elseBranch: (ElsebranchIn) -> ElsebranchOut ) -> ToutParameters
condA boolean scalar.
inputsA list of input tensors.
-
Wraps the XLA Sort operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#sort .
Sorts a tensor. Currently only sorts in ascending order are supported.
Declaration
public static func xlaKeyValueSort< K: TensorFlowNumeric, V: TensorFlowScalar >( keys: Tensor<K>, _ values: Tensor<V> ) -> (sortedKeys: Tensor<K>, sortedValues: Tensor<V>) -
Wraps the XLA Pad operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#pad .
Output output: A
Tensorof type T.
Declaration
public static func xlaPad< T: TensorFlowScalar, Tindices: TensorFlowIndex >( _ input: Tensor<T>, paddingValue: Tensor<T>, paddingLow: Tensor<Tindices>, paddingHigh: Tensor<Tindices>, paddingInterior: Tensor<Tindices> ) -> Tensor<T> -
Receives the named tensor from another XLA computation. Wraps the XLA Recv
operator documented at https://www.tensorflow.org/performance/xla/operation_semantics#recv .
Attrs:
- dtype: The type of the tensor.
- tensor_name: A string key that identifies the channel.
- shape: The shape of the tensor.
Output tensor: The tensor to receive.
Declaration
public static func xlaRecv<Dtype: TensorFlowScalar>( tensorName: String, shape: TensorShape? ) -> Tensor<Dtype> -
Wraps the XLA Reduce operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#reduce .
Attrs:
- dimensions_to_reduce: dimension numbers over which to reduce
- reducer: a reducer function to apply
Declaration
public static func xlaReduce< T: TensorFlowNumeric, ReducerIn: TensorGroup, ReducerOut: TensorGroup >( _ input: Tensor<T>, initValue: Tensor<T>, dimensionsToReduce: [Int32], reducer: (ReducerIn) -> ReducerOut ) -> Tensor<T>Parameters
inputthe input tensor
init_valuea scalar representing the initial value for the reduction
-
xlaReduceWindow(_:initValue:windowDimensions:windowStrides:baseDilations:windowDilations:padding:computation:)
Wraps the XLA ReduceWindow operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#reducewindow .
Attr computation: a reducer function to apply
Declaration
public static func xlaReduceWindow< T: TensorFlowNumeric, Tindices: TensorFlowIndex, ComputationIn: TensorGroup, ComputationOut: TensorGroup >( _ input: Tensor<T>, initValue: Tensor<T>, windowDimensions: Tensor<Tindices>, windowStrides: Tensor<Tindices>, baseDilations: Tensor<Tindices>, windowDilations: Tensor<Tindices>, padding: Tensor<Tindices>, computation: (ComputationIn) -> ComputationOut ) -> Tensor<T>Parameters
inputthe input tensor
init_valuea scalar representing the initial value for the reduction
window_dimensionsthe shape of the window
window_stridesthe inter-window strides
paddingthe padding to apply at the start and end of each input dimensions
-
Replica ID.
Declaration
public static func xlaReplicaId() -> Tensor<Int32> -
xlaSelectAndScatter(operand:windowDimensions:windowStrides:padding:source:initValue:select:scatter:)
Wraps the XLA SelectAndScatter operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#selectandscatter .
Attrs:
- select: a selection function to apply
- scatter: a scatter function to apply
Declaration
public static func xlaSelectAndScatter< T: TensorFlowNumeric, Tindices: TensorFlowIndex, SelectIn: TensorGroup, SelectOut: TensorGroup, ScatterIn: TensorGroup, ScatterOut: TensorGroup >( operand: Tensor<T>, windowDimensions: Tensor<Tindices>, windowStrides: Tensor<Tindices>, padding: Tensor<Tindices>, source: Tensor<T>, initValue: Tensor<T>, select: (SelectIn) -> SelectOut, scatter: (ScatterIn) -> ScatterOut ) -> Tensor<T>Parameters
operandthe input tensor
window_dimensionsthe shape of the window
window_stridesthe inter-window strides
paddingthe padding to apply at the start and end of each input dimensions
sourcea tensor of values to scatter
init_valuea scalar representing the initial value for the output tensor
-
Computes the eigen decomposition of a batch of self-adjoint matrices
(Note: Only real inputs are supported).
Computes the eigenvalues and eigenvectors of the innermost N-by-N matrices in tensor such that tensor[…,:,:] * v[…, :,i] = e[…, i] * v[…,:,i], for i=0…N-1.
Attrs:
- lower: a boolean specifies whether the calculation is done with the lower triangular part or the upper triangular part.
- max_iter: maximum number of sweep update, i.e., the whole lower triangular part or upper triangular part based on parameter lower. Heuristically, it has been argued that approximatly logN sweeps are needed in practice (Ref: Golub & van Loan “Matrix Computation”).
- epsilon: the tolerance ratio.
Outputs:
- w: The eigenvalues in ascending order, each repeated according to its multiplicity.
- v: The column v[…, :, i] is the normalized eigenvector corresponding to the eigenvalue w[…, i].
Declaration
public static func xlaSelfAdjointEig<T: TensorFlowNumeric>( _ a: Tensor<T>, lower: Bool, maxIter: Int64, epsilon: Double ) -> (w: Tensor<T>, v: Tensor<T>)Parameters
athe input tensor.
-
Sends the named tensor to another XLA computation. Wraps the XLA Send operator
documented at https://www.tensorflow.org/performance/xla/operation_semantics#send .
Attr tensor_name: A string key that identifies the channel.
Declaration
public static func xlaSend<T: TensorFlowScalar>( _ tensor: Tensor<T>, tensorName: String )Parameters
tensorThe tensor to send.
-
An op which shards the input based on the given sharding attribute.
Declaration
public static func xlaSharding<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T> -
Wraps the XLA Sort operator, documented at
https://www.tensorflow.org/performance/xla/operation_semantics#sort .
Sorts a tensor. Currently only sorts in ascending order are supported.
Output output: A
Tensorof type T.
Declaration
public static func xlaSort<T: TensorFlowScalar>( _ input: Tensor<T> ) -> Tensor<T>Parameters
inputA
Tensorof type T. -
Computes the eigen decomposition of a batch of self-adjoint matrices
(Note: Only real inputs are supported).
Computes the eigenvalues and eigenvectors of the innermost M-by-N matrices in tensor such that tensor[…,:,:] = u[…, :, :] * Diag(s[…, :]) * Transpose(v[…,:,:]).
Attrs:
- max_iter: maximum number of sweep update, i.e., the whole lower triangular part or upper triangular part based on parameter lower. Heuristically, it has been argued that approximatly log(min (M, N)) sweeps are needed in practice (Ref: Golub & van Loan “Matrix Computation”).
- epsilon: the tolerance ratio.
- precision_config: a serialized xla::PrecisionConfig proto.
Outputs:
- s: Singular values. The values are sorted in reverse order of magnitude, so s[…, 0] is the largest value, s[…, 1] is the second largest, etc.
- u: Left singular vectors.
- v: Right singular vectors.
Declaration
public static func xlaSvd<T: TensorFlowNumeric>( _ a: Tensor<T>, maxIter: Int64, epsilon: Double, precisionConfig: String ) -> (s: Tensor<T>, u: Tensor<T>, v: Tensor<T>)Parameters
athe input tensor.
-
output = input; While (Cond(output)) { output = Body(output) }
Attrs:
- cond: A function takes ‘input’ and returns a tensor. If the tensor is a scalar of non-boolean, the scalar is converted to a boolean according to the following rule: if the scalar is a numerical value, non-zero means True and zero means False; if the scalar is a string, non-empty means True and empty means False. If the tensor is not a scalar, non-emptiness means True and False otherwise.
- body: A function that takes a list of tensors and returns another list of tensors. Both lists have the same types as specified by T.
Output output: A list of output tensors whose types are T.
Declaration
public static func xlaWhile< T: TensorArrayProtocol, CondIn: TensorGroup, CondOut: TensorGroup, BodyIn: TensorGroup, BodyOut: TensorGroup >( _ input: T, cond: (CondIn) -> CondOut, body: (BodyIn) -> BodyOut ) -> TParameters
inputA list of input tensors whose types are T.
-
Returns 0 if x == 0, and x * log(y) otherwise, elementwise.
Declaration
public static func xlogy<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, _ y: Tensor<T> ) -> Tensor<T> -
Returns a tensor of zeros with the same shape and type as x.
Output y: a tensor of the same shape and type as x but filled with zeros.
Declaration
public static func zerosLike<T: TensorFlowScalar>( _ x: Tensor<T> ) -> Tensor<T>Parameters
xa tensor of type T.
-
Compute the Hurwitz zeta function \(\zeta(x, q)\).
The Hurwitz zeta function is defined as:
\(\zeta(x, q) = \sum_{n=0}^{\infty} (q + n)^{-x}\)
Declaration
public static func zeta<T: FloatingPoint & TensorFlowScalar>( _ x: Tensor<T>, q: Tensor<T> ) -> Tensor<T> -
Creates a dataset that zips together
input_datasets.The elements of the resulting dataset are created by zipping corresponding elements from each of the input datasets.
The size of the resulting dataset will match the size of the smallest input dataset, and no error will be raised if input datasets have different sizes.
Attr N: The length of
input_datasets
Declaration
public static func zipDataset( inputDatasets: [VariantHandle], outputTypes: [TensorDataType], outputShapes: [TensorShape?] ) -> VariantHandleParameters
input_datasetsList of
Nvariant Tensors representing datasets to be zipped together.