
| | |  Ver código fuente en GitHub Ver código fuente en GitHub |
Esta guía presenta Swift para TensorFlow mediante la creación de un modelo de aprendizaje automático que clasifica las flores de iris por especie. Utiliza Swift para TensorFlow para:
- Construir un modelo,
- Entrene este modelo con datos de ejemplo y
- Utilice el modelo para hacer predicciones sobre datos desconocidos.
Programación TensorFlow
Esta guía utiliza estos conceptos de alto nivel de Swift para TensorFlow:
- Importe datos con la API de Epochs.
- Construya modelos utilizando abstracciones Swift.
- Utilice bibliotecas de Python utilizando la interoperabilidad de Python de Swift cuando las bibliotecas de Swift puras no estén disponibles.
Este tutorial está estructurado como muchos programas de TensorFlow:
- Importe y analice los conjuntos de datos.
- Seleccione el tipo de modelo.
- Entrena el modelo.
- Evaluar la efectividad del modelo.
- Utilice el modelo entrenado para hacer predicciones.
programa de instalación
Configurar importaciones
Importe TensorFlow y algunos módulos útiles de Python.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
El problema de la clasificación del iris.
Imagine que es un botánico que busca una forma automatizada de clasificar cada flor de iris que encuentre. El aprendizaje automático proporciona muchos algoritmos para clasificar flores estadísticamente. Por ejemplo, un sofisticado programa de aprendizaje automático podría clasificar flores basándose en fotografías. Nuestras ambiciones son más modestas: clasificaremos las flores de iris según las medidas de largo y ancho de sus sépalos y pétalos .
El género Iris comprende alrededor de 300 especies, pero nuestro programa solo clasificará las tres siguientes:
- Iris setosa
- iris virginica
- iris versicolor
 |
| Figura 1. Iris setosa (por Radomil , CC BY-SA 3.0), Iris versicolor (por Dlanglois , CC BY-SA 3.0) e Iris virginica (por Frank Mayfield , CC BY-SA 2.0). |
Afortunadamente, alguien ya ha creado un conjunto de datos de 120 flores de iris con las medidas de sépalos y pétalos. Este es un conjunto de datos clásico que es popular para los problemas de clasificación de aprendizaje automático para principiantes.
Importar y analizar el conjunto de datos de entrenamiento
Descargue el archivo del conjunto de datos y conviértalo en una estructura que pueda ser utilizada por este programa Swift.
Descargar el conjunto de datos
Descargue el archivo del conjunto de datos de entrenamiento desde http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Inspeccionar los datos
Este conjunto de datos, iris_training.csv , es un archivo de texto sin formato que almacena datos tabulares formateados como valores separados por comas (CSV). Veamos las primeras 5 entradas.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Desde esta vista del conjunto de datos, observe lo siguiente:
- La primera línea es un encabezado que contiene información sobre el conjunto de datos:
- Hay 120 ejemplos en total. Cada ejemplo tiene cuatro características y uno de los tres nombres de etiquetas posibles.
- Las filas siguientes son registros de datos, un ejemplo por línea, donde:
- Los primeros cuatro campos son características : son características de un ejemplo. Aquí, los campos contienen números flotantes que representan las medidas de las flores.
- La última columna es la etiqueta : este es el valor que queremos predecir. Para este conjunto de datos, es un valor entero de 0, 1 o 2 que corresponde al nombre de una flor.
Escribamos eso en código:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Cada etiqueta está asociada con el nombre de la cadena (por ejemplo, "setosa"), pero el aprendizaje automático normalmente se basa en valores numéricos. Los números de etiqueta se asignan a una representación con nombre, como por ejemplo:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
Para obtener más información sobre características y etiquetas, consulte la sección Terminología de aprendizaje automático del curso intensivo de aprendizaje automático .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Cree un conjunto de datos utilizando la API de Epochs
Swift para la API Epochs de TensorFlow es una API de alto nivel para leer datos y transformarlos en un formulario utilizado para el entrenamiento.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Dado que los conjuntos de datos que descargamos están en formato CSV, escribamos una función para cargar los datos como una lista de objetos IrisBatch.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Ahora podemos usar la función de carga CSV para cargar el conjunto de datos de entrenamiento y crear un objeto TrainingEpochs .
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
El objeto TrainingEpochs es una secuencia infinita de épocas. Cada época contiene IrisBatch es. Veamos el primer elemento de la primera época.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Observe que las características de los primeros ejemplos batchSize se agrupan (o se agrupan por lotes ) en firstTrainFeatures y que las etiquetas de los primeros ejemplos batchSize se agrupan en firstTrainLabels .
Puede comenzar a ver algunos clústeres trazando algunas características del lote, usando matplotlib de Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
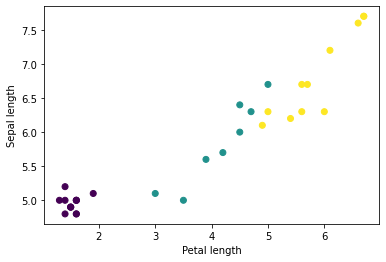
Use `print()` to show values.
Seleccione el tipo de modelo
¿Por qué modelo?
Un modelo es una relación entre las características y la etiqueta. Para el problema de clasificación del iris, el modelo define la relación entre las medidas de sépalos y pétalos y las especies de iris predichas. Algunos modelos simples se pueden describir con unas pocas líneas de álgebra, pero los modelos complejos de aprendizaje automático tienen una gran cantidad de parámetros que son difíciles de resumir.
¿Podrías determinar la relación entre las cuatro características y las especies de iris sin utilizar el aprendizaje automático? Es decir, ¿podría utilizar técnicas de programación tradicionales (por ejemplo, muchas declaraciones condicionales) para crear un modelo? Quizás, si analizaras el conjunto de datos el tiempo suficiente para determinar las relaciones entre las medidas de pétalos y sépalos de una especie en particular. Y esto se vuelve difícil, tal vez imposible, en conjuntos de datos más complicados. Un buen enfoque de aprendizaje automático determina el modelo por usted . Si introduce suficientes ejemplos representativos en el tipo de modelo de aprendizaje automático correcto, el programa descubrirá las relaciones por usted.
Selecciona el modelo
Necesitamos seleccionar el tipo de modelo a entrenar. Hay muchos tipos de modelos y elegir uno bueno requiere experiencia. Este tutorial utiliza una red neuronal para resolver el problema de clasificación del iris. Las redes neuronales pueden encontrar relaciones complejas entre las características y la etiqueta. Es un gráfico altamente estructurado, organizado en una o más capas ocultas . Cada capa oculta consta de una o más neuronas . Hay varias categorías de redes neuronales y este programa utiliza una red neuronal densa o completamente conectada : las neuronas de una capa reciben conexiones de entrada de cada neurona de la capa anterior. Por ejemplo, la Figura 2 ilustra una red neuronal densa que consta de una capa de entrada, dos capas ocultas y una capa de salida:
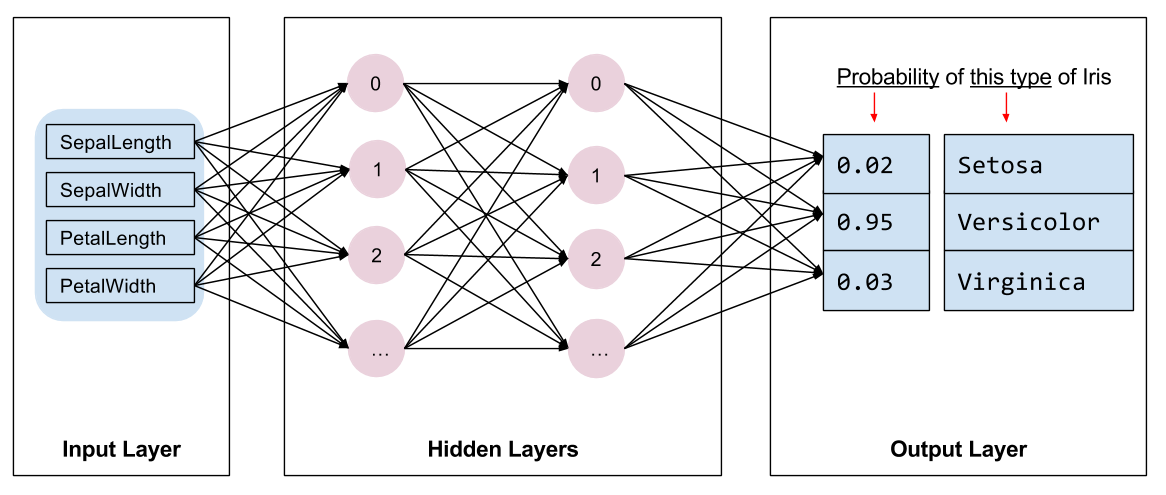 |
| Figura 2. Una red neuronal con características, capas ocultas y predicciones. |
Cuando el modelo de la Figura 2 se entrena y se alimenta con un ejemplo sin etiquetar, produce tres predicciones: la probabilidad de que esta flor sea de la especie de iris dada. Esta predicción se llama inferencia . Para este ejemplo, la suma de las predicciones de salida es 1,0. En la Figura 2, esta predicción se desglosa en: 0.02 para Iris setosa , 0.95 para Iris versicolor y 0.03 para Iris virginica . Esto significa que el modelo predice, con un 95% de probabilidad, que una flor de ejemplo sin etiquetar es un Iris versicolor .
Cree un modelo utilizando la biblioteca de aprendizaje profundo Swift para TensorFlow
La biblioteca de aprendizaje profundo Swift para TensorFlow define capas primitivas y convenciones para conectarlas, lo que facilita la creación de modelos y la experimentación.
Un modelo es una struct que se ajusta a Layer , lo que significa que define un método callAsFunction(_:) que asigna Tensor de entrada a Tensor de salida. El método callAsFunction(_:) a menudo simplemente secuencia la entrada a través de subcapas. Definamos un IrisModel que secuencia la entrada a través de tres subcapas Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
La función de activación determina la forma de salida de cada nodo en la capa. Estas no linealidades son importantes: sin ellas, el modelo sería equivalente a una sola capa. Hay muchas activaciones disponibles, pero ReLU es común para capas ocultas.
La cantidad ideal de capas y neuronas ocultas depende del problema y del conjunto de datos. Como muchos aspectos del aprendizaje automático, elegir la mejor forma de la red neuronal requiere una combinación de conocimiento y experimentación. Como regla general, aumentar la cantidad de capas y neuronas ocultas generalmente crea un modelo más poderoso, que requiere más datos para entrenar de manera efectiva.
Usando el modelo
Echemos un vistazo rápido a lo que este modelo hace con un conjunto de características:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Aquí, cada ejemplo devuelve un logit para cada clase.
Para convertir estos logits en una probabilidad para cada clase, use la función softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Tomar argmax entre clases nos da el índice de clase previsto. Pero el modelo aún no ha sido entrenado, por lo que estas no son buenas predicciones.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Entrenar el modelo
La capacitación es la etapa del aprendizaje automático en la que el modelo se optimiza gradualmente o el modelo aprende el conjunto de datos. El objetivo es aprender lo suficiente sobre la estructura del conjunto de datos de entrenamiento para hacer predicciones sobre datos invisibles. Si aprende demasiado sobre el conjunto de datos de entrenamiento, las predicciones solo funcionarán para los datos que ha visto y no serán generalizables. Este problema se llama sobreajuste : es como memorizar las respuestas en lugar de entender cómo resolver un problema.
El problema de clasificación del iris es un ejemplo de aprendizaje automático supervisado : el modelo se entrena a partir de ejemplos que contienen etiquetas. En el aprendizaje automático no supervisado , los ejemplos no contienen etiquetas. En cambio, el modelo normalmente encuentra patrones entre las características.
Elija una función de pérdida
Tanto la etapa de capacitación como la de evaluación necesitan calcular la pérdida del modelo. Esto mide qué tan alejadas están las predicciones de un modelo de la etiqueta deseada; en otras palabras, qué tan mal está funcionando el modelo. Queremos minimizar u optimizar este valor.
Nuestro modelo calculará su pérdida utilizando la función softmaxCrossEntropy(logits:labels:) que toma las predicciones de probabilidad de clase del modelo y la etiqueta deseada, y devuelve la pérdida promedio en todos los ejemplos.
Calculemos la pérdida para el modelo actual no entrenado:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Crear un optimizador
Un optimizador aplica los gradientes calculados a las variables del modelo para minimizar la función loss . Puede pensar en la función de pérdida como una superficie curva (ver Figura 3) y queremos encontrar su punto más bajo caminando. Las pendientes apuntan en la dirección del ascenso más empinado, por lo que viajaremos en sentido opuesto y bajaremos la colina. Al calcular iterativamente la pérdida y el gradiente de cada lote, ajustaremos el modelo durante el entrenamiento. Gradualmente, el modelo encontrará la mejor combinación de ponderaciones y sesgos para minimizar la pérdida. Y cuanto menor sea la pérdida, mejores serán las predicciones del modelo.
 |
| Figura 3. Algoritmos de optimización visualizados a lo largo del tiempo en un espacio 3D. (Fuente: clase CS231n de Stanford , licencia del MIT, crédito de la imagen: Alec Radford ) |
Swift para TensorFlow tiene muchos algoritmos de optimización disponibles para entrenamiento. Este modelo utiliza el optimizador SGD que implementa el algoritmo de descenso de gradiente estocástico (SGD). learningRate establece el tamaño del paso a seguir en cada iteración cuesta abajo. Este es un hiperparámetro que normalmente ajustará para lograr mejores resultados.
let optimizer = SGD(for: model, learningRate: 0.01)
Usemos optimizer para realizar un único paso de descenso de gradiente. Primero, calculamos el gradiente de pérdida con respecto al modelo:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
A continuación, pasamos el gradiente que acabamos de calcular al optimizador, que actualiza las variables diferenciables del modelo en consecuencia:
optimizer.update(&model, along: grads)
Si calculamos la pérdida nuevamente, debería ser menor, porque los pasos de descenso del gradiente (generalmente) disminuyen la pérdida:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Bucle de entrenamiento
Con todas las piezas en su lugar, ¡el modelo está listo para entrenar! Un bucle de entrenamiento introduce los ejemplos del conjunto de datos en el modelo para ayudarlo a realizar mejores predicciones. El siguiente bloque de código configura estos pasos de capacitación:
- Iterar sobre cada época . Una época es un paso por el conjunto de datos.
- Dentro de una época, iterar sobre cada lote en la época de entrenamiento
- Clasifique el lote y tome sus características (
x) y etiqueta (y). - Utilizando las características del lote recopilado, haga una predicción y compárela con la etiqueta. Mida la inexactitud de la predicción y utilícela para calcular la pérdida y los gradientes del modelo.
- Utilice el descenso de gradiente para actualizar las variables del modelo.
- Realice un seguimiento de algunas estadísticas para su visualización.
- Repita para cada época.
La variable epochCount es el número de veces que se recorre la colección del conjunto de datos. Contrariamente a la intuición, entrenar un modelo por más tiempo no garantiza un modelo mejor. epochCount es un hiperparámetro que puedes ajustar. Elegir el número correcto normalmente requiere experiencia y experimentación.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
Visualice la función de pérdida a lo largo del tiempo.
Si bien es útil imprimir el progreso del entrenamiento del modelo, a menudo es más útil ver este progreso. Podemos crear gráficos básicos usando el módulo matplotlib de Python.
Interpretar estos gráficos requiere algo de experiencia, pero lo que realmente desea es ver que la pérdida disminuye y la precisión aumenta.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
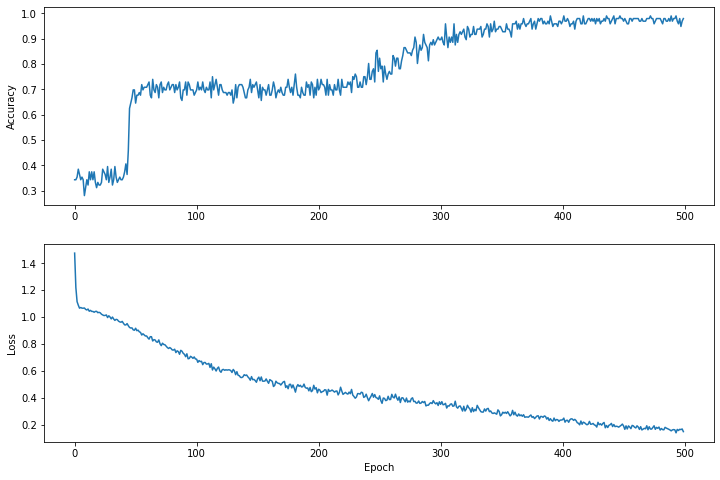
Use `print()` to show values.
Tenga en cuenta que los ejes y de los gráficos no tienen base cero.
Evaluar la efectividad del modelo.
Ahora que el modelo está entrenado, podemos obtener algunas estadísticas sobre su rendimiento.
Evaluar significa determinar con qué eficacia el modelo hace predicciones. Para determinar la efectividad del modelo en la clasificación del iris, pase algunas mediciones de sépalos y pétalos al modelo y pídale que prediga qué especies de iris representan. Luego compare la predicción del modelo con la etiqueta real. Por ejemplo, un modelo que eligió la especie correcta en la mitad de los ejemplos de entrada tiene una precisión de 0.5 . La Figura 4 muestra un modelo ligeramente más eficaz, que obtiene 4 de 5 predicciones correctas con un 80% de precisión:
| Funciones de ejemplo | Etiqueta | Predicción del modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Un clasificador de iris con una precisión del 80%. | |||||
Configurar el conjunto de datos de prueba
Evaluar el modelo es similar a entrenar el modelo. La mayor diferencia es que los ejemplos provienen de un conjunto de pruebas separado en lugar del conjunto de entrenamiento. Para evaluar de manera justa la efectividad de un modelo, los ejemplos utilizados para evaluar un modelo deben ser diferentes de los ejemplos utilizados para entrenar el modelo.
La configuración del conjunto de datos de prueba es similar a la configuración del conjunto de datos de entrenamiento. Descargue el conjunto de prueba desde http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Ahora cárguelo en una matriz de IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Evaluar el modelo en el conjunto de datos de prueba.
A diferencia de la etapa de entrenamiento, el modelo solo evalúa una única época de los datos de prueba. En la siguiente celda de código, iteramos sobre cada ejemplo en el conjunto de prueba y comparamos la predicción del modelo con la etiqueta real. Esto se utiliza para medir la precisión del modelo en todo el conjunto de pruebas.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Podemos ver en el primer lote, por ejemplo, que el modelo suele ser correcto:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Utilice el modelo entrenado para hacer predicciones.
Hemos entrenado un modelo y hemos demostrado que es bueno, aunque no perfecto, para clasificar las especies de iris. Ahora usemos el modelo entrenado para hacer algunas predicciones en ejemplos sin etiquetar ; es decir, en ejemplos que contienen características pero no una etiqueta.
En la vida real, los ejemplos sin etiquetar podrían provenir de muchas fuentes diferentes, incluidas aplicaciones, archivos CSV y fuentes de datos. Por ahora, proporcionaremos manualmente tres ejemplos sin etiquetar para predecir sus etiquetas. Recuerde, los números de etiqueta se asignan a una representación con nombre como:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])