
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Hướng dẫn này giới thiệu Swift cho TensorFlow bằng cách xây dựng mô hình học máy phân loại hoa diên vĩ theo loài. Nó sử dụng Swift cho TensorFlow để:
- Xây dựng mô hình,
- Huấn luyện mô hình này trên dữ liệu mẫu và
- Sử dụng mô hình để đưa ra dự đoán về dữ liệu chưa biết.
Lập trình TensorFlow
Hướng dẫn này sử dụng các khái niệm Swift for TensorFlow cấp cao sau:
- Nhập dữ liệu bằng API Epochs.
- Xây dựng mô hình bằng cách sử dụng trừu tượng Swift.
- Sử dụng thư viện Python bằng khả năng tương tác Python của Swift khi không có thư viện Swift thuần túy.
Hướng dẫn này có cấu trúc giống như nhiều chương trình TensorFlow:
- Nhập và phân tích các tập dữ liệu.
- Chọn loại mô hình.
- Đào tạo người mẫu.
- Đánh giá hiệu quả của mô hình.
- Sử dụng mô hình đã được huấn luyện để đưa ra dự đoán.
Chương trình cài đặt
Định cấu hình nhập
Nhập TensorFlow và một số mô-đun Python hữu ích.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Vấn đề phân loại mống mắt
Hãy tưởng tượng bạn là một nhà thực vật học đang tìm kiếm một cách tự động để phân loại từng bông hoa diên vĩ mà bạn tìm thấy. Học máy cung cấp nhiều thuật toán để phân loại hoa theo thống kê. Ví dụ, một chương trình máy học phức tạp có thể phân loại hoa dựa trên các bức ảnh. Tham vọng của chúng tôi khiêm tốn hơn—chúng tôi sẽ phân loại hoa diên vĩ dựa trên số đo chiều dài và chiều rộng của lá đài và cánh hoa của chúng.
Chi Iris bao gồm khoảng 300 loài, nhưng chương trình của chúng tôi sẽ chỉ phân loại ba loài sau:
- Iris setosa
- Iris virginica
- Iris nhiều màu
 |
| Hình 1. Iris setosa (bởi Radomil , CC BY-SA 3.0), Iris versicolor , (bởi Dlanglois , CC BY-SA 3.0) và Iris virginica (bởi Frank Mayfield , CC BY-SA 2.0). |
May mắn thay, ai đó đã tạo ra một bộ dữ liệu gồm 120 bông hoa diên vĩ với số đo đài hoa và cánh hoa. Đây là bộ dữ liệu cổ điển phổ biến cho các vấn đề phân loại máy học mới bắt đầu.
Nhập và phân tích tập dữ liệu huấn luyện
Tải xuống tệp dữ liệu và chuyển đổi nó thành cấu trúc mà chương trình Swift này có thể sử dụng.
Tải xuống tập dữ liệu
Tải xuống tệp dữ liệu đào tạo từ http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Kiểm tra dữ liệu
Tập dữ liệu này, iris_training.csv , là một tệp văn bản thuần túy lưu trữ dữ liệu dạng bảng được định dạng dưới dạng các giá trị được phân tách bằng dấu phẩy (CSV). Chúng ta hãy xem 5 mục đầu tiên.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Từ chế độ xem tập dữ liệu này, hãy lưu ý những điều sau:
- Dòng đầu tiên là tiêu đề chứa thông tin về tập dữ liệu:
- Có tổng số 120 ví dụ. Mỗi ví dụ có bốn đặc điểm và một trong ba tên nhãn có thể có.
- Các hàng tiếp theo là các bản ghi dữ liệu, mỗi dòng một ví dụ , trong đó:
- Bốn trường đầu tiên là các tính năng : đây là các đặc điểm của một ví dụ. Ở đây, các trường chứa số float biểu thị số đo hoa.
- Cột cuối cùng là nhãn : đây là giá trị mà chúng ta muốn dự đoán. Đối với tập dữ liệu này, giá trị nguyên là 0, 1 hoặc 2 tương ứng với tên loài hoa.
Hãy viết nó ra bằng mã:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Mỗi nhãn được liên kết với tên chuỗi (ví dụ: "setosa"), nhưng công nghệ học máy thường dựa vào các giá trị số. Số nhãn được ánh xạ tới một biểu diễn được đặt tên, chẳng hạn như:
-
0: Iris setosa -
1: Iris nhiều màu -
2: Hoa diên vĩ virginica
Để biết thêm thông tin về các tính năng và nhãn, hãy xem phần Thuật ngữ ML của Khóa học cấp tốc về học máy .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Tạo tập dữ liệu bằng API Epochs
API Epochs của Swift for TensorFlow là API cấp cao để đọc dữ liệu và chuyển đổi dữ liệu thành dạng dùng cho đào tạo.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Vì các tập dữ liệu chúng tôi đã tải xuống ở định dạng CSV, hãy viết một hàm để tải dữ liệu dưới dạng danh sách các đối tượng IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Bây giờ chúng ta có thể sử dụng chức năng tải CSV để tải tập dữ liệu huấn luyện và tạo đối tượng TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
Đối tượng TrainingEpochs là một chuỗi vô hạn các kỷ nguyên. Mỗi kỷ nguyên chứa IrisBatch es. Chúng ta hãy nhìn vào yếu tố đầu tiên của kỷ nguyên đầu tiên.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Lưu ý rằng các tính năng cho các ví dụ batchSize đầu tiên được nhóm lại với nhau (hoặc được nhóm ) thành firstTrainFeatures và các nhãn cho các ví dụ batchSize đầu tiên được nhóm thành firstTrainLabels .
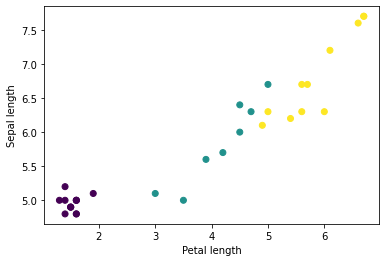
Bạn có thể bắt đầu thấy một số cụm bằng cách vẽ sơ đồ một số tính năng trong lô bằng cách sử dụng matplotlib của Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
Chọn loại mô hình
Tại sao lại là người mẫu?
Một mô hình là mối quan hệ giữa các tính năng và nhãn. Đối với bài toán phân loại mống mắt, mô hình xác định mối quan hệ giữa số đo đài hoa và cánh hoa với các loại mống mắt được dự đoán. Một số mô hình đơn giản có thể được mô tả bằng một vài dòng đại số, nhưng các mô hình học máy phức tạp có số lượng lớn các tham số rất khó tóm tắt.
Bạn có thể xác định mối quan hệ giữa bốn đặc điểm và loài mống mắt mà không cần sử dụng máy học không? Nghĩa là, bạn có thể sử dụng các kỹ thuật lập trình truyền thống (ví dụ: rất nhiều câu lệnh có điều kiện) để tạo mô hình không? Có lẽ—nếu bạn phân tích tập dữ liệu đủ lâu để xác định mối quan hệ giữa số đo cánh hoa và đài hoa với một loài cụ thể. Và điều này trở nên khó khăn—có thể là không thể—trên các tập dữ liệu phức tạp hơn. Phương pháp học máy tốt sẽ xác định mô hình cho bạn . Nếu bạn đưa đủ ví dụ đại diện vào loại mô hình học máy phù hợp, chương trình sẽ tìm ra mối quan hệ cho bạn.
Chọn mô hình
Chúng ta cần chọn loại mô hình để đào tạo. Có nhiều loại mô hình và việc chọn một mô hình tốt cần có kinh nghiệm. Hướng dẫn này sử dụng mạng lưới thần kinh để giải quyết vấn đề phân loại mống mắt. Mạng lưới thần kinh có thể tìm thấy mối quan hệ phức tạp giữa các tính năng và nhãn. Nó là một biểu đồ có cấu trúc cao, được tổ chức thành một hoặc nhiều lớp ẩn . Mỗi lớp ẩn bao gồm một hoặc nhiều nơ-ron . Có một số loại mạng thần kinh và chương trình này sử dụng mạng thần kinh dày đặc hoặc được kết nối đầy đủ : các nơ-ron trong một lớp nhận các kết nối đầu vào từ mọi nơ-ron ở lớp trước. Ví dụ: Hình 2 minh họa một mạng lưới thần kinh dày đặc bao gồm một lớp đầu vào, hai lớp ẩn và một lớp đầu ra:
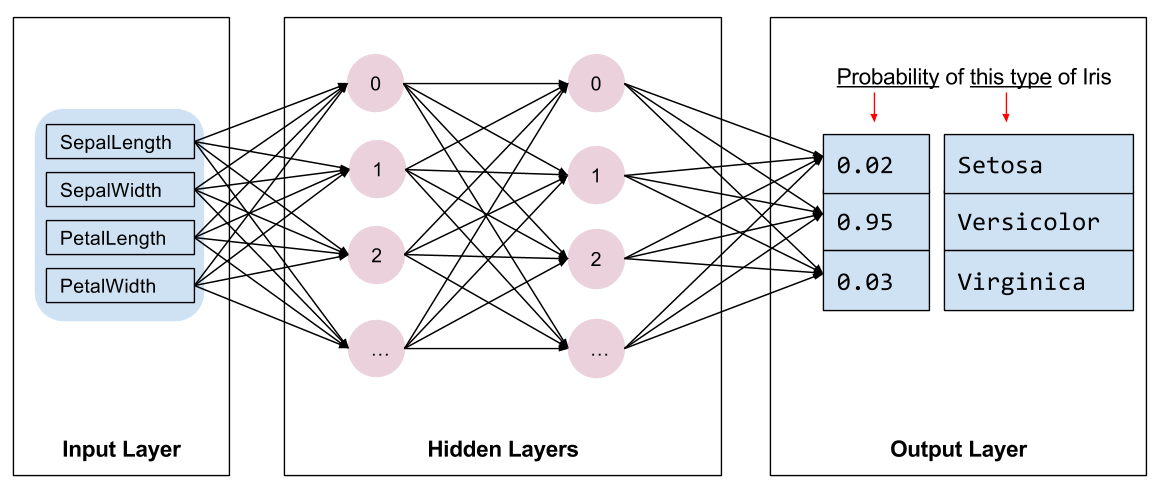 |
| Hình 2. Mạng nơ-ron với các tính năng, lớp ẩn và dự đoán. |
Khi mô hình trong Hình 2 được huấn luyện và cung cấp một mẫu không được gắn nhãn, nó mang lại ba dự đoán: khả năng bông hoa này là loài hoa diên vĩ nhất định. Dự đoán này được gọi là suy luận . Đối với ví dụ này, tổng dự đoán đầu ra là 1,0. Trong Hình 2, dự đoán này được chia thành: 0.02 đối với Iris setosa , 0.95 đối với Iris versicolor và 0.03 đối với Iris virginica . Điều này có nghĩa là mô hình dự đoán—với xác suất 95%—rằng một bông hoa mẫu không được gắn nhãn là một loài Iris nhiều màu .
Tạo mô hình bằng Swift cho Thư viện học sâu TensorFlow
Thư viện học sâu Swift cho TensorFlow xác định các lớp và quy ước nguyên thủy để kết nối chúng lại với nhau, giúp dễ dàng xây dựng mô hình và thử nghiệm.
Một mô hình là một struct tuân theo Layer , có nghĩa là nó xác định một phương thức callAsFunction(_:) để ánh xạ Tensor đầu vào thành các Tensor đầu ra. Phương thức callAsFunction(_:) thường chỉ đơn giản sắp xếp đầu vào thông qua các lớp con. Hãy xác định một IrisModel sắp xếp chuỗi đầu vào thông qua ba lớp con Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
Hàm kích hoạt xác định hình dạng đầu ra của mỗi nút trong lớp. Những điểm phi tuyến tính này rất quan trọng—nếu không có chúng, mô hình sẽ tương đương với một lớp duy nhất. Có nhiều kích hoạt có sẵn, nhưng ReLU phổ biến cho các lớp ẩn.
Số lượng lớp ẩn và nơ-ron lý tưởng phụ thuộc vào vấn đề và tập dữ liệu. Giống như nhiều khía cạnh của học máy, việc chọn hình dạng tốt nhất của mạng lưới thần kinh đòi hỏi sự kết hợp giữa kiến thức và thử nghiệm. Theo nguyên tắc chung, việc tăng số lượng lớp ẩn và nơ-ron thường tạo ra một mô hình mạnh hơn, đòi hỏi nhiều dữ liệu hơn để đào tạo hiệu quả.
Sử dụng mô hình
Chúng ta hãy xem nhanh chức năng của mô hình này đối với một loạt tính năng:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Ở đây, mỗi ví dụ trả về một logit cho mỗi lớp.
Để chuyển đổi các nhật ký này thành xác suất cho từng lớp, hãy sử dụng hàm softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Lấy argmax qua các lớp sẽ cho chúng ta chỉ số lớp được dự đoán. Tuy nhiên, mô hình chưa được huấn luyện nên đây không phải là những dự đoán tốt.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Đào tạo người mẫu
Đào tạo là giai đoạn học máy khi mô hình được tối ưu hóa dần dần hoặc mô hình học tập dữ liệu. Mục tiêu là tìm hiểu đủ về cấu trúc của tập dữ liệu huấn luyện để đưa ra dự đoán về dữ liệu chưa nhìn thấy. Nếu bạn tìm hiểu quá nhiều về tập dữ liệu huấn luyện thì dự đoán chỉ có tác dụng đối với dữ liệu mà nó đã thấy và sẽ không thể khái quát hóa được. Vấn đề này được gọi là trang bị quá mức —nó giống như việc ghi nhớ câu trả lời thay vì hiểu cách giải quyết vấn đề.
Bài toán phân loại mống mắt là một ví dụ về học máy có giám sát : mô hình được đào tạo từ các ví dụ có chứa nhãn. Trong học máy không giám sát , các ví dụ không chứa nhãn. Thay vào đó, mô hình thường tìm thấy các mẫu trong số các đặc điểm.
Chọn hàm mất mát
Cả hai giai đoạn huấn luyện và đánh giá đều cần tính toán tổn thất của mô hình. Điều này đo lường mức độ sai lệch của các dự đoán của mô hình so với nhãn mong muốn, nói cách khác, mô hình đang hoạt động tệ đến mức nào. Chúng tôi muốn giảm thiểu hoặc tối ưu hóa giá trị này.
Mô hình của chúng tôi sẽ tính toán tổn thất bằng cách sử dụng hàm softmaxCrossEntropy(logits:labels:) lấy dự đoán xác suất lớp của mô hình và nhãn mong muốn, đồng thời trả về tổn thất trung bình trên các ví dụ.
Hãy tính tổn thất cho mô hình chưa được đào tạo hiện tại:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Tạo trình tối ưu hóa
Trình tối ưu hóa áp dụng độ dốc được tính toán cho các biến của mô hình để giảm thiểu hàm loss . Bạn có thể coi hàm mất mát như một bề mặt cong (xem Hình 3) và chúng ta muốn tìm điểm thấp nhất của nó bằng cách đi vòng quanh. Độ dốc hướng về hướng đi lên dốc nhất—vì vậy chúng ta sẽ đi theo hướng ngược lại và di chuyển xuống đồi. Bằng cách tính toán lặp đi lặp lại độ mất và độ dốc cho từng lô, chúng tôi sẽ điều chỉnh mô hình trong quá trình đào tạo. Dần dần, mô hình sẽ tìm ra sự kết hợp tốt nhất giữa trọng số và độ lệch để giảm thiểu tổn thất. Và tổn thất càng thấp thì dự đoán của mô hình càng tốt.
 |
| Hình 3. Các thuật toán tối ưu hóa được hiển thị theo thời gian trong không gian 3D. (Nguồn: Lớp Stanford CS231n , Giấy phép MIT, Nguồn hình ảnh: Alec Radford ) |
Swift for TensorFlow có sẵn nhiều thuật toán tối ưu hóa để đào tạo. Mô hình này sử dụng trình tối ưu hóa SGD để thực hiện thuật toán giảm độ dốc ngẫu nhiên (SGD). learningRate đặt kích thước bước cần thực hiện cho mỗi lần lặp lại. Đây là siêu tham số mà bạn thường điều chỉnh để đạt được kết quả tốt hơn.
let optimizer = SGD(for: model, learningRate: 0.01)
Hãy sử dụng optimizer để thực hiện một bước giảm độ dốc duy nhất. Đầu tiên, chúng tôi tính toán độ dốc tổn thất đối với mô hình:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Tiếp theo, chúng tôi chuyển độ dốc mà chúng tôi vừa tính toán cho trình tối ưu hóa, trình tối ưu hóa này sẽ cập nhật các biến khả vi của mô hình tương ứng:
optimizer.update(&model, along: grads)
Nếu chúng ta tính toán lại tổn thất thì nó sẽ nhỏ hơn vì các bước giảm độ dốc (thường) sẽ làm giảm tổn thất:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Vòng đào tạo
Với tất cả các phần đã sẵn sàng, mô hình đã sẵn sàng để đào tạo! Vòng lặp huấn luyện cung cấp các ví dụ về tập dữ liệu vào mô hình để giúp mô hình đưa ra dự đoán tốt hơn. Khối mã sau thiết lập các bước đào tạo này:
- Lặp lại qua từng kỷ nguyên . Một kỷ nguyên là một lần đi qua tập dữ liệu.
- Trong một kỷ nguyên, lặp lại từng đợt trong kỷ nguyên huấn luyện
- Đối chiếu lô và lấy các tính năng của nó (
x) và nhãn (y). - Sử dụng các đặc điểm của lô đã đối chiếu, đưa ra dự đoán và so sánh với nhãn. Đo lường độ thiếu chính xác của dự đoán và sử dụng kết quả đó để tính toán độ suy hao và độ dốc của mô hình.
- Sử dụng phương pháp giảm độ dốc để cập nhật các biến của mô hình.
- Theo dõi một số số liệu thống kê để trực quan hóa.
- Lặp lại cho mỗi kỷ nguyên.
Biến epochCount là số lần lặp qua bộ sưu tập dữ liệu. Ngược lại, việc đào tạo một mô hình lâu hơn không đảm bảo một mô hình tốt hơn. epochCount là siêu tham số mà bạn có thể điều chỉnh. Việc chọn đúng số thường đòi hỏi cả kinh nghiệm và thử nghiệm.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
Trực quan hóa hàm mất mát theo thời gian
Mặc dù việc in ra tiến trình đào tạo của mô hình rất hữu ích nhưng việc xem tiến trình này thường hữu ích hơn . Chúng ta có thể tạo các biểu đồ cơ bản bằng mô-đun matplotlib của Python.
Việc giải thích các biểu đồ này cần một số kinh nghiệm, nhưng bạn thực sự muốn thấy mức lỗ giảm xuống và độ chính xác tăng lên.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
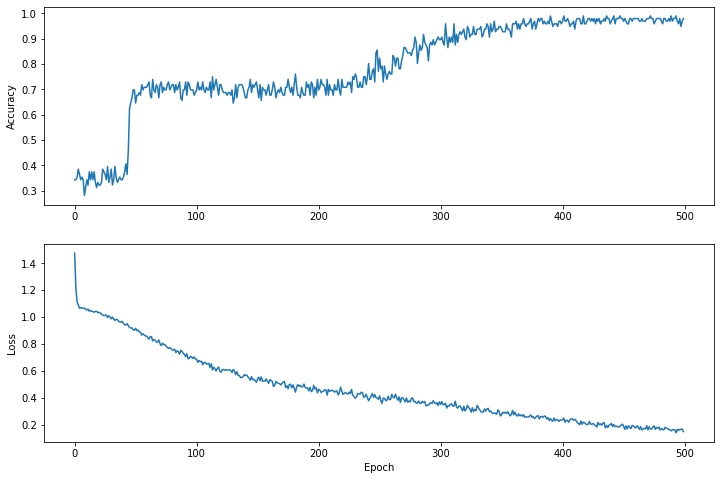
Use `print()` to show values.
Lưu ý rằng trục y của đồ thị không dựa trên 0.
Đánh giá hiệu quả mô hình
Bây giờ mô hình đã được huấn luyện, chúng ta có thể nhận được một số thống kê về hiệu suất của nó.
Đánh giá có nghĩa là xác định mức độ hiệu quả của mô hình đưa ra dự đoán. Để xác định tính hiệu quả của mô hình trong việc phân loại mống mắt, hãy chuyển một số phép đo lá đài và cánh hoa cho mô hình và yêu cầu mô hình dự đoán chúng đại diện cho loài mống mắt nào. Sau đó so sánh dự đoán của mô hình với nhãn thực tế. Ví dụ: một mô hình đã chọn đúng loài trên một nửa số mẫu đầu vào có độ chính xác là 0.5 . Hình 4 cho thấy một mô hình hiệu quả hơn một chút, nhận được 4 trên 5 dự đoán đúng với độ chính xác 80%:
| Tính năng ví dụ | Nhãn | Dự đoán mô hình | |||
|---|---|---|---|---|---|
| 5,9 | 3.0 | 4.3 | 1,5 | 1 | 1 |
| 6,9 | 3.1 | 5,4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3,4 | 4,5 | 1.6 | 1 | 2 |
| 5,5 | 2,5 | 4.0 | 1.3 | 1 | 1 |
| Hình 4. Bộ phân loại mống mắt có độ chính xác 80%. | |||||
Thiết lập tập dữ liệu thử nghiệm
Việc đánh giá mô hình cũng tương tự như việc huấn luyện mô hình. Sự khác biệt lớn nhất là các ví dụ đến từ một tập kiểm tra riêng biệt chứ không phải tập huấn luyện. Để đánh giá một cách công bằng hiệu quả của mô hình, các ví dụ dùng để đánh giá mô hình phải khác với các ví dụ dùng để huấn luyện mô hình.
Việc thiết lập tập dữ liệu thử nghiệm cũng tương tự như việc thiết lập tập dữ liệu huấn luyện. Tải xuống bộ kiểm tra từ http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Bây giờ hãy tải nó vào một mảng IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Đánh giá mô hình trên tập dữ liệu thử nghiệm
Không giống như giai đoạn huấn luyện, mô hình chỉ đánh giá một giai đoạn duy nhất của dữ liệu thử nghiệm. Trong ô mã sau đây, chúng tôi lặp lại từng ví dụ trong bộ kiểm tra và so sánh dự đoán của mô hình với nhãn thực tế. Điều này được sử dụng để đo độ chính xác của mô hình trên toàn bộ tập kiểm tra.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Ví dụ, chúng ta có thể thấy ở lô đầu tiên, mô hình thường đúng:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Sử dụng mô hình đã được huấn luyện để đưa ra dự đoán
Chúng tôi đã đào tạo một mô hình và chứng minh rằng nó tốt—nhưng không hoàn hảo—trong việc phân loại các loài mống mắt. Bây giờ, hãy sử dụng mô hình đã được huấn luyện để đưa ra một số dự đoán về các ví dụ chưa được gắn nhãn ; nghĩa là, trên các ví dụ có chứa các tính năng nhưng không có nhãn.
Trong thực tế, các ví dụ không được gắn nhãn có thể đến từ nhiều nguồn khác nhau bao gồm ứng dụng, tệp CSV và nguồn cấp dữ liệu. Hiện tại, chúng tôi sẽ cung cấp ba ví dụ chưa được gắn nhãn theo cách thủ công để dự đoán nhãn của chúng. Hãy nhớ lại, số nhãn được ánh xạ tới một biểu diễn được đặt tên là:
-
0: Iris setosa -
1: Iris nhiều màu -
2: Hoa diên vĩ virginica
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])