
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
این راهنما با ساخت یک مدل یادگیری ماشینی که گلهای زنبق را بر اساس گونهها دستهبندی میکند، Swift را برای TensorFlow معرفی میکند. از Swift برای TensorFlow برای موارد زیر استفاده می کند:
- یک مدل بسازید،
- این مدل را بر روی داده های مثال آموزش دهید و
- از مدل برای پیش بینی داده های ناشناخته استفاده کنید.
برنامه نویسی TensorFlow
این راهنما از این Swift سطح بالا برای مفاهیم TensorFlow استفاده می کند:
- داده ها را با Epochs API وارد کنید.
- مدل ها را با استفاده از انتزاعات سوئیفت بسازید.
- زمانی که کتابخانههای سوئیفت خالص در دسترس نیستند، از کتابخانههای پایتون با استفاده از قابلیت همکاری پایتون سوئیفت استفاده کنید.
این آموزش مانند بسیاری از برنامه های TensorFlow ساختار یافته است:
- وارد کردن و تجزیه مجموعه داده ها.
- نوع مدل را انتخاب کنید.
- مدل را آموزش دهید.
- کارایی مدل را ارزیابی کنید.
- از مدل آموزش دیده برای پیش بینی استفاده کنید.
برنامه راه اندازی
پیکربندی واردات
TensorFlow و چند ماژول مفید پایتون را وارد کنید.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
مشکل طبقه بندی عنبیه
تصور کنید یک گیاه شناس هستید که به دنبال روشی خودکار برای دسته بندی هر گل زنبق می باشد. یادگیری ماشینی الگوریتم های زیادی را برای طبقه بندی آماری گل ها ارائه می دهد. به عنوان مثال، یک برنامه یادگیری ماشینی پیچیده می تواند گل ها را بر اساس عکس ها طبقه بندی کند. جاه طلبی های ما ساده تر است - ما گل های زنبق را بر اساس اندازه گیری طول و عرض کاسبرگ و گلبرگ آنها طبقه بندی می کنیم.
جنس زنبق شامل حدود 300 گونه است، اما برنامه ما فقط سه گونه زیر را طبقه بندی می کند:
- زنبق ستوزا
- زنبق ویرجینیکا
- زنبق ورسیکالر
 |
| شکل 1. Iris setosa (توسط Radomil ، CC BY-SA 3.0)، Iris versicolor ، (توسط Dlanglois ، CC BY-SA 3.0)، و Iris virginica (توسط Frank Mayfield ، CC BY-SA 2.0). |
خوشبختانه، شخصی قبلاً مجموعه ای از 120 گل زنبق را با اندازه های کاسبرگ و گلبرگ ایجاد کرده است. این یک مجموعه داده کلاسیک است که برای مشکلات طبقه بندی یادگیری ماشین مبتدی محبوب است.
مجموعه داده آموزشی را وارد و تجزیه کنید
فایل دیتاست را دانلود کرده و به ساختاری تبدیل کنید که توسط این برنامه سوئیفت قابل استفاده باشد.
مجموعه داده را دانلود کنید
فایل مجموعه داده آموزشی را از http://download.tensorflow.org/data/iris_training.csv دانلود کنید
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
داده ها را بررسی کنید
این مجموعه داده، iris_training.csv ، یک فایل متنی ساده است که داده های جدولی را به صورت مقادیر جدا شده با کاما (CSV) قالب بندی می کند. بیایید به 5 ورودی اول نگاه کنیم.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
از این نمای مجموعه داده، به موارد زیر توجه کنید:
- خط اول هدر حاوی اطلاعاتی در مورد مجموعه داده است:
- در مجموع 120 نمونه وجود دارد. هر نمونه دارای چهار ویژگی و یکی از سه نام برچسب ممکن است.
- ردیف های بعدی رکوردهای داده هستند، یک مثال در هر خط، که در آن:
بیایید آن را در کد بنویسیم:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
هر برچسب با نام رشته مرتبط است (به عنوان مثال، "setosa")، اما یادگیری ماشین معمولاً بر مقادیر عددی متکی است. اعداد برچسب به یک نمایش نامگذاری شده نگاشت می شوند، مانند:
-
0: زنبق ستوزا -
1: زنبق ورسیکالر -
2: زنبق ویرجینیکا
برای کسب اطلاعات بیشتر در مورد ویژگیها و برچسبها، به بخش اصطلاحات ML در دوره تصادف یادگیری ماشین مراجعه کنید.
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
با استفاده از Epochs API یک مجموعه داده ایجاد کنید
Swift for TensorFlow's Epochs API یک API سطح بالا برای خواندن داده ها و تبدیل آن به فرمی است که برای آموزش استفاده می شود.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
از آنجایی که مجموعه داده هایی که دانلود کردیم در قالب CSV هستند، اجازه دهید تابعی بنویسیم تا در داده ها به عنوان لیستی از اشیاء IrisBatch بارگذاری شود.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
اکنون می توانیم از تابع بارگذاری CSV برای بارگذاری مجموعه داده آموزشی و ایجاد یک شی TrainingEpochs استفاده کنیم.
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
شی TrainingEpochs یک دنباله نامتناهی از دوران است. هر دوره شامل IrisBatch es است. بیایید به اولین عنصر دوره اول نگاه کنیم.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
توجه داشته باشید که ویژگیهای اولین نمونههای batchSize با هم گروهبندی میشوند (یا دستهبندی میشوند ) در firstTrainFeatures ، و برچسبهای اولین نمونههای batchSize در firstTrainLabels دستهبندی میشوند.
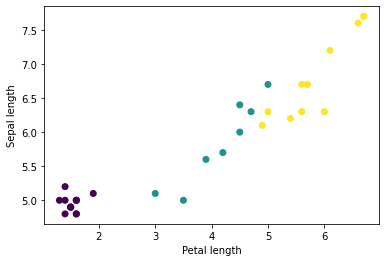
میتوانید با ترسیم چند ویژگی از دسته، با استفاده از matplotlib پایتون شروع به دیدن چند خوشه کنید:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
نوع مدل را انتخاب کنید
چرا مدل؟
مدل یک رابطه بین ویژگی ها و برچسب است. برای مشکل طبقهبندی عنبیه، مدل رابطه بین اندازهگیریهای کاسبرگ و گلبرگ و گونههای عنبیه پیشبینیشده را تعریف میکند. برخی از مدل های ساده را می توان با چند خط جبر توصیف کرد، اما مدل های پیچیده یادگیری ماشینی دارای تعداد زیادی پارامتر هستند که خلاصه کردن آنها دشوار است.
آیا می توانید ارتباط بین چهار ویژگی و گونه عنبیه را بدون استفاده از یادگیری ماشین تعیین کنید؟ یعنی آیا می توانید از تکنیک های برنامه نویسی سنتی (مثلاً بسیاری از دستورات شرطی) برای ایجاد یک مدل استفاده کنید؟ شاید اگر مجموعه داده را به اندازه کافی برای تعیین روابط بین اندازه گیری گلبرگ و کاسبرگ با یک گونه خاص تجزیه و تحلیل کنید. و این در مجموعه دادههای پیچیدهتر دشوار – شاید غیرممکن – میشود. یک رویکرد یادگیری ماشین خوب مدل را برای شما تعیین می کند . اگر نمونه های معرف کافی را در نوع مدل یادگیری ماشینی مناسب وارد کنید، برنامه روابط را برای شما مشخص خواهد کرد.
مدل را انتخاب کنید
ما باید نوع مدلی را برای آموزش انتخاب کنیم. انواع مختلفی از مدل ها وجود دارد و انتخاب یک مدل خوب نیاز به تجربه دارد. این آموزش از یک شبکه عصبی برای حل مشکل طبقه بندی عنبیه استفاده می کند. شبکه های عصبی می توانند روابط پیچیده ای بین ویژگی ها و برچسب پیدا کنند. این یک نمودار بسیار ساختار یافته است که در یک یا چند لایه پنهان سازماندهی شده است. هر لایه پنهان از یک یا چند نورون تشکیل شده است. چندین دسته از شبکه های عصبی وجود دارد و این برنامه از یک شبکه عصبی متراکم یا کاملاً متصل استفاده می کند: نورون های یک لایه اتصالات ورودی را از هر نورون در لایه قبلی دریافت می کنند. به عنوان مثال، شکل 2 یک شبکه عصبی متراکم متشکل از یک لایه ورودی، دو لایه پنهان و یک لایه خروجی را نشان می دهد:
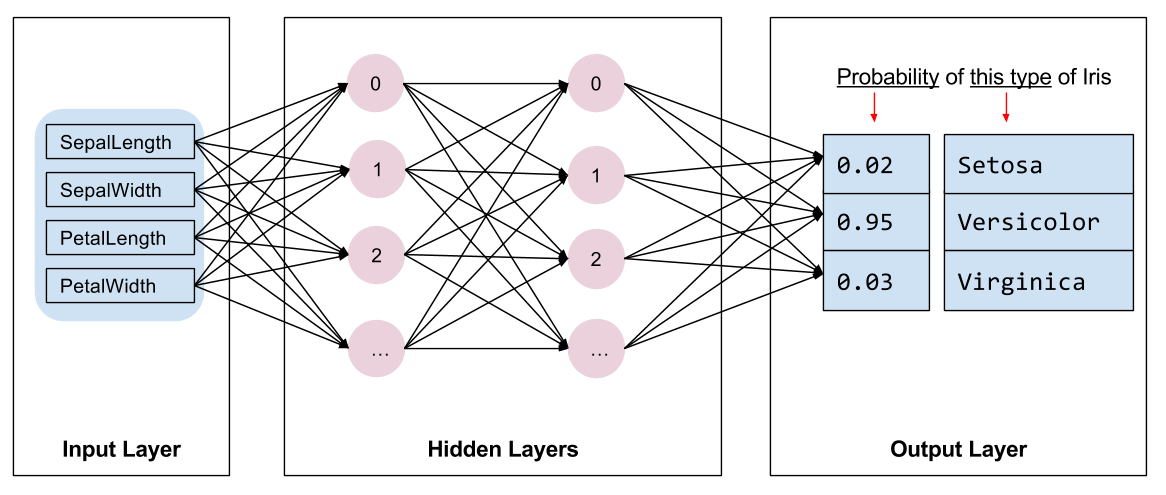 |
| شکل 2. یک شبکه عصبی با ویژگی ها، لایه های پنهان و پیش بینی ها. |
هنگامی که مدل شکل 2 آموزش داده می شود و با یک مثال بدون برچسب تغذیه می شود، سه پیش بینی به دست می دهد: احتمال اینکه این گل گونه عنبیه داده شده باشد. این پیش بینی استنتاج نامیده می شود. برای این مثال، مجموع پیشبینیهای خروجی 1.0 است. در شکل 2، این پیش بینی به صورت زیر تقسیم می شود: 0.02 برای Iris setosa ، 0.95 برای Iris versicolor و 0.03 برای Iris virginica . این به این معنی است که مدل پیشبینی میکند - با احتمال 95٪ - که یک گل نمونه بدون برچسب رنگ زنبق است.
با استفاده از کتابخانه Swift for TensorFlow Deep Learning یک مدل ایجاد کنید
کتابخانه Swift for TensorFlow Deep Learning لایه ها و قراردادهای اولیه را برای سیم کشی آنها با یکدیگر تعریف می کند که ساخت مدل ها و آزمایش را آسان می کند.
یک مدل struct است که با Layer مطابقت دارد، به این معنی که یک متد callAsFunction(_:) را تعریف می کند که Tensor ورودی s را به Tensor خروجی s نگاشت می کند. متد callAsFunction(_:) اغلب به سادگی ورودی را از طریق زیرلایه ها ترتیب می دهد. بیایید IrisModel تعریف کنیم که ورودی را از طریق سه لایه فرعی Dense ترتیب می دهد.
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
تابع فعال سازی شکل خروجی هر گره در لایه را تعیین می کند. این غیر خطی ها مهم هستند - بدون آنها مدل معادل یک لایه خواهد بود. فعالسازیهای زیادی وجود دارد، اما ReLU برای لایههای مخفی رایج است.
تعداد ایده آل لایه ها و نورون های پنهان به مشکل و مجموعه داده بستگی دارد. مانند بسیاری از جنبه های یادگیری ماشینی، انتخاب بهترین شکل شبکه عصبی به ترکیبی از دانش و آزمایش نیاز دارد. به عنوان یک قاعده کلی، افزایش تعداد لایههای پنهان و نورونها معمولاً مدل قدرتمندتری ایجاد میکند که برای آموزش مؤثر به دادههای بیشتری نیاز دارد.
با استفاده از مدل
بیایید نگاهی گذرا به عملکرد این مدل با مجموعه ای از ویژگی ها بیندازیم:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
در اینجا، هر مثال یک logit برای هر کلاس برمی گرداند.
برای تبدیل این logit ها به یک احتمال برای هر کلاس، از تابع softmax استفاده کنید:
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
در نظر گرفتن argmax در بین کلاس ها، شاخص کلاس پیش بینی شده را به ما می دهد. اما، این مدل هنوز آموزش ندیده است، بنابراین این ها پیش بینی های خوبی نیستند.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
مدل را آموزش دهید
آموزش مرحله ای از یادگیری ماشینی است که مدل به تدریج بهینه می شود یا مدل مجموعه داده را یاد می گیرد . هدف این است که به اندازه کافی در مورد ساختار مجموعه داده آموزشی یاد بگیریم تا بتوان در مورد داده های دیده نشده پیش بینی کرد. اگر بیش از حد در مورد مجموعه داده آموزشی یاد بگیرید، پیشبینیها فقط برای دادههایی که دیدهاند کار میکنند و قابل تعمیم نخواهند بود. این مشکل بیش از حد برازش نامیده می شود - مانند این است که به جای درک چگونگی حل یک مشکل، پاسخ ها را به خاطر بسپارید.
مشکل طبقهبندی عنبیه نمونهای از یادگیری ماشینی نظارت شده است: این مدل از نمونههایی که حاوی برچسب هستند آموزش داده میشود. در یادگیری ماشینی بدون نظارت ، نمونه ها دارای برچسب نیستند. در عوض، مدل معمولاً الگوهایی را در میان ویژگیها پیدا میکند.
یک تابع ضرر را انتخاب کنید
هر دو مرحله آموزش و ارزیابی نیاز به محاسبه ضرر مدل دارند. این نشان میدهد که پیشبینیهای یک مدل چقدر از برچسب مورد نظر خارج است، به عبارت دیگر، عملکرد مدل چقدر بد است. ما می خواهیم این مقدار را به حداقل برسانیم یا بهینه کنیم.
مدل ما تلفات خود را با استفاده از تابع softmaxCrossEntropy(logits:labels:) محاسبه میکند که پیشبینیهای احتمال کلاس مدل و برچسب مورد نظر را میگیرد و میانگین تلفات را در بین مثالها برمیگرداند.
بیایید زیان را برای مدل فعلی آموزش ندیده محاسبه کنیم:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
یک بهینه ساز ایجاد کنید
یک بهینه ساز، گرادیان های محاسبه شده را بر روی متغیرهای مدل اعمال می کند تا تابع loss را به حداقل برساند. میتوانید تابع تلفات را به عنوان یک سطح منحنی در نظر بگیرید (شکل 3 را ببینید) و ما میخواهیم با قدم زدن در اطراف، پایینترین نقطه آن را پیدا کنیم. شیب ها در جهت شیب دارترین صعود قرار دارند—بنابراین ما مسیر مخالف را طی می کنیم و از تپه پایین می رویم. با محاسبه مکرر تلفات و گرادیان برای هر دسته، مدل را در طول آموزش تنظیم می کنیم. به تدریج، مدل بهترین ترکیب وزن و سوگیری را برای به حداقل رساندن کاهش پیدا خواهد کرد. و هرچه ضرر کمتر باشد، پیشبینی مدل بهتر است.
 |
| شکل 3. الگوریتم های بهینه سازی که در طول زمان در فضای سه بعدی تجسم شده اند. (منبع: Stanford class CS231n ، مجوز MIT، اعتبار تصویر: Alec Radford ) |
Swift for TensorFlow دارای الگوریتم های بهینه سازی زیادی برای آموزش است. این مدل از بهینه ساز SGD استفاده می کند که الگوریتم شیب نزولی تصادفی (SGD) را پیاده سازی می کند. learningRate اندازه گام را برای هر تکرار در پایین تپه تعیین می کند. این یک فراپارامتر است که معمولاً برای دستیابی به نتایج بهتر آن را تنظیم می کنید.
let optimizer = SGD(for: model, learningRate: 0.01)
بیایید optimizer برای برداشتن یک گام شیب نزولی استفاده کنیم. ابتدا گرادیان ضرر را با توجه به مدل محاسبه می کنیم:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
سپس، گرادیانی را که بهتازگی محاسبه کردهایم به بهینهساز منتقل میکنیم، که بر این اساس متغیرهای متمایز مدل را بهروزرسانی میکند:
optimizer.update(&model, along: grads)
اگر تلفات را دوباره محاسبه کنیم، باید کوچکتر باشد، زیرا مراحل شیب نزول (معمولا) تلفات را کاهش می دهند:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
حلقه آموزشی
با تمام قطعات در جای خود، مدل برای آموزش آماده است! یک حلقه آموزشی، نمونههای مجموعه داده را به مدل تغذیه میکند تا به پیشبینی بهتر کمک کند. بلوک کد زیر این مراحل آموزشی را تنظیم می کند:
- در هر دوره تکرار کنید. یک دوره یک گذر از مجموعه داده است.
- در یک دوره، روی هر دسته در دوره آموزشی تکرار کنید
- دسته را جمع کنید و ویژگی های آن (
x) و برچسب (y) آن را بگیرید. - با استفاده از ویژگی های دسته بندی شده، یک پیش بینی انجام دهید و آن را با برچسب مقایسه کنید. عدم دقت پیشبینی را اندازهگیری کنید و از آن برای محاسبه تلفات و گرادیانهای مدل استفاده کنید.
- از گرادیان نزول برای به روز رسانی متغیرهای مدل استفاده کنید.
- برخی از آمارها را برای تجسم پیگیری کنید.
- برای هر دوره تکرار کنید.
متغیر epochCount تعداد دفعاتی است که روی مجموعه داده ها حلقه زده می شود. به طور غیر شهودی، آموزش طولانی تر یک مدل، مدل بهتر را تضمین نمی کند. epochCount یک فراپارامتر است که می توانید آن را تنظیم کنید. انتخاب عدد مناسب معمولا به تجربه و آزمایش نیاز دارد.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
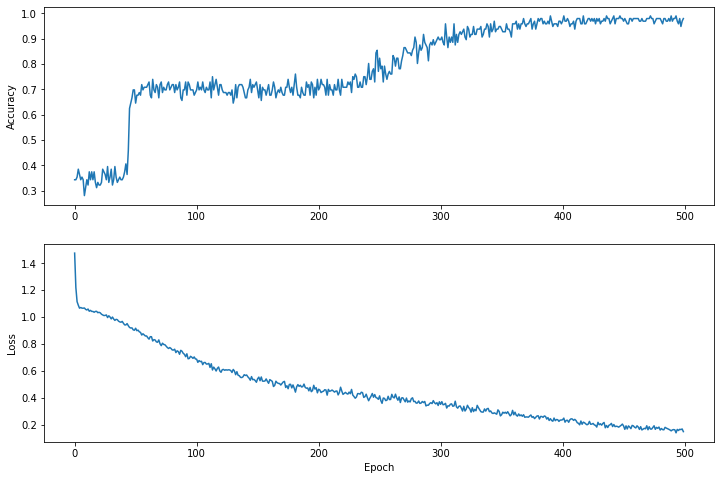
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
عملکرد ضرر را در طول زمان تجسم کنید
در حالی که چاپ کردن پیشرفت آموزش مدل مفید است، مشاهده این پیشرفت اغلب مفیدتر است. ما می توانیم نمودارهای اولیه را با استفاده از ماژول matplotlib پایتون ایجاد کنیم.
تفسیر این نمودارها به تجربه نیاز دارد، اما شما واقعاً می خواهید کاهش ضرر و افزایش دقت را ببینید.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
توجه داشته باشید که محورهای y نمودارها بر اساس صفر نیستند.
کارایی مدل را ارزیابی کنید
اکنون که مدل آموزش دیده است، می توانیم آماری از عملکرد آن به دست آوریم.
ارزیابی به معنای تعیین میزان موثر پیش بینی های مدل است. برای تعیین اثربخشی مدل در طبقهبندی عنبیه، اندازهگیریهای کاسبرگ و گلبرگ را به مدل منتقل کنید و از مدل بخواهید تا پیشبینی کند که چه گونههای عنبیه را نشان میدهند. سپس پیش بینی مدل را با برچسب واقعی مقایسه کنید. به عنوان مثال، مدلی که گونه های صحیح را روی نیمی از نمونه های ورودی انتخاب کرده است، دقت 0.5 دارد. شکل 4 یک مدل کمی موثرتر را نشان می دهد که 4 از 5 پیش بینی را با دقت 80 درصد درست می کند:
| ویژگی های نمونه | برچسب | پیش بینی مدل | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| شکل 4. طبقه بندی کننده عنبیه که 80% دقت دارد. | |||||
مجموعه داده آزمایشی را تنظیم کنید
ارزیابی مدل مشابه آموزش مدل است. بزرگترین تفاوت این است که نمونه ها از یک مجموعه تست جداگانه به جای مجموعه آموزشی آمده اند. برای ارزیابی منصفانه اثربخشی یک مدل، مثالهایی که برای ارزیابی یک مدل استفاده میشوند باید متفاوت از نمونههای مورد استفاده برای آموزش مدل باشند.
راهاندازی مجموعه داده آزمایشی مشابه راهاندازی مجموعه دادههای آموزشی است. مجموعه تست را از http://download.tensorflow.org/data/iris_test.csv دانلود کنید:
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
اکنون آن را در آرایه ای از IrisBatch es بارگذاری کنید:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
مدل را روی مجموعه داده آزمایشی ارزیابی کنید
برخلاف مرحله آموزش، مدل تنها یک دوره واحد از داده های آزمون را ارزیابی می کند. در سلول کد زیر، روی هر نمونه در مجموعه آزمایشی تکرار میکنیم و پیشبینی مدل را با برچسب واقعی مقایسه میکنیم. این برای اندازه گیری دقت مدل در کل مجموعه تست استفاده می شود.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
ما می توانیم در دسته اول ببینیم، به عنوان مثال، مدل معمولا درست است:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
از مدل آموزش دیده برای پیش بینی استفاده کنید
ما مدلی را آموزش دادهایم و نشان دادهایم که در طبقهبندی گونههای عنبیه خوب – اما نه کامل است. حال بیایید از مدل آموزشدیده برای پیشبینی نمونههای بدون برچسب استفاده کنیم. یعنی روی نمونه هایی که دارای ویژگی هستند اما برچسب ندارند.
در زندگی واقعی، نمونههای بدون برچسب میتوانند از منابع مختلفی از جمله برنامهها، فایلهای CSV و فیدهای دادهای بیایند. در حال حاضر، ما به صورت دستی سه نمونه بدون برچسب را برای پیش بینی برچسب آنها ارائه می کنیم. به یاد بیاورید، اعداد برچسب به یک نمایش نامگذاری شده به صورت زیر نگاشت می شوند:
-
0: زنبق ستوزا -
1: زنبق ورسیکالر -
2: زنبق ویرجینیکا
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])