
| | |  Afficher la source sur GitHub Afficher la source sur GitHub |
Ce guide présente Swift pour TensorFlow en créant un modèle d'apprentissage automatique qui classe les fleurs d'iris par espèce. Il utilise Swift pour TensorFlow pour :
- Construire un modèle,
- Entraînez ce modèle sur des exemples de données, et
- Utilisez le modèle pour faire des prédictions sur des données inconnues.
Programmation TensorFlow
Ce guide utilise ces concepts Swift de haut niveau pour TensorFlow :
- Importez des données avec l'API Epochs.
- Créez des modèles à l'aide des abstractions Swift.
- Utilisez les bibliothèques Python en utilisant l'interopérabilité Python de Swift lorsque les bibliothèques Swift pures ne sont pas disponibles.
Ce tutoriel est structuré comme de nombreux programmes TensorFlow :
- Importez et analysez les ensembles de données.
- Sélectionnez le type de modèle.
- Entraînez le modèle.
- Évaluez l’efficacité du modèle.
- Utilisez le modèle entraîné pour faire des prédictions.
Programme d'installation
Configurer les importations
Importez TensorFlow et quelques modules Python utiles.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Le problème de la classification de l'iris
Imaginez que vous êtes un botaniste à la recherche d'un moyen automatisé de classer chaque fleur d'iris que vous trouvez. L’apprentissage automatique fournit de nombreux algorithmes pour classer statistiquement les fleurs. Par exemple, un programme sophistiqué d’apprentissage automatique pourrait classer les fleurs sur la base de photographies. Nos ambitions sont plus modestes : nous allons classer les fleurs d'iris en fonction des mesures de longueur et de largeur de leurs sépales et pétales .
Le genre Iris comprend environ 300 espèces, mais notre programme ne classifiera que les trois suivantes :
- Iris setosa
- Iris de Virginie
- Iris versicolor
 |
| Figure 1. Iris setosa (par Radomil , CC BY-SA 3.0), Iris versicolor (par Dlanglois , CC BY-SA 3.0) et Iris virginica (par Frank Mayfield , CC BY-SA 2.0). |
Heureusement, quelqu'un a déjà créé un ensemble de données de 120 fleurs d'iris avec les mesures des sépales et des pétales. Il s'agit d'un ensemble de données classique qui est populaire pour les problèmes de classification d'apprentissage automatique pour débutants.
Importer et analyser l'ensemble de données d'entraînement
Téléchargez le fichier de l'ensemble de données et convertissez-le en une structure pouvant être utilisée par ce programme Swift.
Téléchargez l'ensemble de données
Téléchargez le fichier de l'ensemble de données de formation à partir de http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Inspecter les données
Cet ensemble de données, iris_training.csv , est un fichier texte brut qui stocke des données tabulaires au format CSV (valeurs séparées par des virgules). Regardons les 5 premières entrées.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
À partir de cette vue de l'ensemble de données, notez ce qui suit :
- La première ligne est un en-tête contenant des informations sur l'ensemble de données :
- Il y a 120 exemples au total. Chaque exemple comporte quatre fonctionnalités et l'un des trois noms d'étiquette possibles.
- Les lignes suivantes sont des enregistrements de données, un exemple par ligne, où :
- Les quatre premiers champs sont des fonctionnalités : ce sont les caractéristiques d'un exemple. Ici, les champs contiennent des nombres flottants représentant les mesures des fleurs.
- La dernière colonne est le label : c'est la valeur que nous voulons prédire. Pour cet ensemble de données, il s'agit d'une valeur entière de 0, 1 ou 2 qui correspond au nom d'une fleur.
Écrivons cela dans le code :
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Chaque étiquette est associée à un nom de chaîne (par exemple, « setosa »), mais l'apprentissage automatique repose généralement sur des valeurs numériques. Les numéros d'étiquette sont mappés à une représentation nommée, telle que :
-
0: Iris setosa -
1: Iris versicolor -
2: Iris de Virginie
Pour plus d'informations sur les fonctionnalités et les étiquettes, consultez la section Terminologie ML du cours intensif d'apprentissage automatique .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Créer un ensemble de données à l'aide de l'API Epochs
L'API Epochs de Swift pour TensorFlow est une API de haut niveau permettant de lire des données et de les transformer en un formulaire utilisé pour la formation.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Puisque les ensembles de données que nous avons téléchargés sont au format CSV, écrivons une fonction à charger dans les données sous forme de liste d'objets IrisBatch.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Nous pouvons maintenant utiliser la fonction de chargement CSV pour charger l'ensemble de données d'entraînement et créer un objet TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
L'objet TrainingEpochs est une séquence infinie d'époques. Chaque époque contient des IrisBatch . Regardons le premier élément de la première époque.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
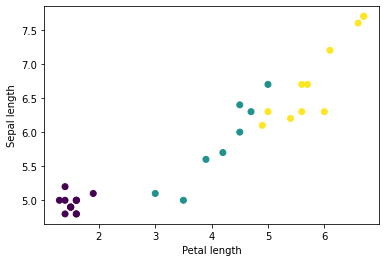
Notez que les fonctionnalités des premiers exemples batchSize sont regroupées (ou regroupées ) dans firstTrainFeatures , et que les étiquettes des premiers exemples batchSize sont regroupées dans firstTrainLabels .
Vous pouvez commencer à voir certains clusters en traçant quelques fonctionnalités du lot, à l'aide de matplotlib de Python :
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
Sélectionnez le type de modèle
Pourquoi modèle ?
Un modèle est une relation entre les fonctionnalités et l'étiquette. Pour le problème de classification de l'iris, le modèle définit la relation entre les mesures des sépales et des pétales et les espèces d'iris prédites. Certains modèles simples peuvent être décrits avec quelques lignes d’algèbre, mais les modèles complexes d’apprentissage automatique comportent un grand nombre de paramètres difficiles à résumer.
Pourriez-vous déterminer la relation entre les quatre caractéristiques et les espèces d’iris sans utiliser l’apprentissage automatique ? Autrement dit, pourriez-vous utiliser des techniques de programmation traditionnelles (par exemple, de nombreuses instructions conditionnelles) pour créer un modèle ? Peut-être, si vous avez analysé l'ensemble de données suffisamment longtemps pour déterminer les relations entre les mesures des pétales et des sépales pour une espèce particulière. Et cela devient difficile, voire impossible, sur des ensembles de données plus complexes. Une bonne approche d'apprentissage automatique détermine le modèle pour vous . Si vous introduisez suffisamment d'exemples représentatifs dans le bon type de modèle d'apprentissage automatique, le programme déterminera les relations pour vous.
Sélectionnez le modèle
Nous devons sélectionner le type de modèle à former. Il existe de nombreux types de modèles et choisir le bon demande de l’expérience. Ce tutoriel utilise un réseau de neurones pour résoudre le problème de classification de l'iris. Les réseaux de neurones peuvent trouver des relations complexes entre les fonctionnalités et l'étiquette. Il s'agit d'un graphique hautement structuré, organisé en une ou plusieurs couches cachées . Chaque couche cachée est constituée d'un ou plusieurs neurones . Il existe plusieurs catégories de réseaux de neurones et ce programme utilise un réseau de neurones dense ou entièrement connecté : les neurones d'une couche reçoivent des connexions d'entrée de chaque neurone de la couche précédente. Par exemple, la figure 2 illustre un réseau neuronal dense composé d'une couche d'entrée, de deux couches cachées et d'une couche de sortie :
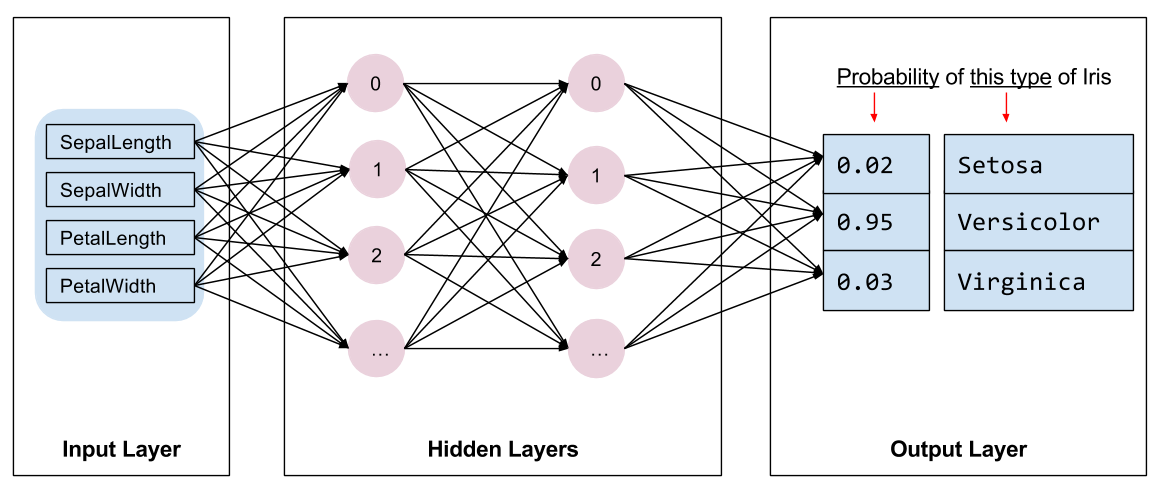 |
| Figure 2. Un réseau neuronal avec des fonctionnalités, des couches cachées et des prédictions. |
Lorsque le modèle de la figure 2 est entraîné et alimenté avec un exemple non étiqueté, il donne trois prédictions : la probabilité que cette fleur soit l'espèce d'iris donnée. Cette prédiction est appelée inférence . Pour cet exemple, la somme des prédictions de sortie est de 1,0. Dans la figure 2, cette prédiction se décompose comme suit : 0.02 pour Iris setosa , 0.95 pour Iris versicolor et 0.03 pour Iris virginica . Cela signifie que le modèle prédit, avec une probabilité de 95 %, qu'un exemple de fleur non étiqueté est un Iris versicolor .
Créer un modèle à l'aide de la bibliothèque Swift pour TensorFlow Deep Learning
La bibliothèque Swift pour TensorFlow Deep Learning définit des couches primitives et des conventions pour les relier ensemble, ce qui facilite la création de modèles et les expériences.
Un modèle est une struct conforme à Layer , ce qui signifie qu'il définit une méthode callAsFunction(_:) qui mappe les Tensor d'entrée aux Tensor de sortie. La méthode callAsFunction(_:) séquence souvent simplement l’entrée via des sous-couches. Définissons un IrisModel qui séquence l'entrée à travers trois sous-couches Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
La fonction d'activation détermine la forme de sortie de chaque nœud de la couche. Ces non-linéarités sont importantes : sans elles, le modèle serait équivalent à une seule couche. Il existe de nombreuses activations disponibles, mais ReLU est courant pour les couches cachées.
Le nombre idéal de couches et de neurones cachés dépend du problème et de l'ensemble de données. Comme de nombreux aspects de l’apprentissage automatique, choisir la meilleure forme de réseau neuronal nécessite un mélange de connaissances et d’expérimentation. En règle générale, l’augmentation du nombre de couches et de neurones cachés crée généralement un modèle plus puissant, qui nécessite davantage de données pour s’entraîner efficacement.
Utilisation du modèle
Jetons un coup d'œil rapide à ce que ce modèle fait à un lot de fonctionnalités :
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Ici, chaque exemple renvoie un logit pour chaque classe.
Pour convertir ces logits en probabilité pour chaque classe, utilisez la fonction softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Prendre l' argmax entre les classes nous donne l'indice de classe prédit. Mais le modèle n’a pas encore été entraîné, ce ne sont donc pas de bonnes prédictions.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Entraîner le modèle
La formation est l'étape de l'apprentissage automatique lorsque le modèle est progressivement optimisé ou que le modèle apprend l'ensemble de données. L'objectif est d'en apprendre suffisamment sur la structure de l'ensemble de données d'entraînement pour faire des prédictions sur les données invisibles. Si vous en apprenez trop sur l'ensemble de données d'entraînement, les prédictions ne fonctionnent que pour les données qu'il a vues et ne seront pas généralisables. Ce problème s'appelle le surapprentissage : c'est comme mémoriser les réponses au lieu de comprendre comment résoudre un problème.
Le problème de classification de l'iris est un exemple d' apprentissage automatique supervisé : le modèle est formé à partir d'exemples contenant des étiquettes. Dans le machine learning non supervisé , les exemples ne contiennent pas d'étiquettes. Au lieu de cela, le modèle recherche généralement des modèles parmi les fonctionnalités.
Choisissez une fonction de perte
Les étapes de formation et d'évaluation doivent calculer la perte du modèle. Cela mesure à quel point les prédictions d'un modèle sont éloignées de l'étiquette souhaitée, en d'autres termes, la mauvaise performance du modèle. Nous souhaitons minimiser ou optimiser cette valeur.
Notre modèle calculera sa perte à l'aide de la fonction softmaxCrossEntropy(logits:labels:) qui prend les prédictions de probabilité de classe du modèle et l'étiquette souhaitée, et renvoie la perte moyenne dans les exemples.
Calculons la perte pour le modèle actuel non entraîné :
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Créer un optimiseur
Un optimiseur applique les gradients calculés aux variables du modèle pour minimiser la fonction loss . Vous pouvez considérer la fonction de perte comme une surface courbe (voir Figure 3) et nous voulons trouver son point le plus bas en nous promenant. Les pentes pointent dans la direction de la montée la plus raide. Nous allons donc voyager dans le sens opposé et descendre la colline. En calculant de manière itérative la perte et le gradient pour chaque lot, nous ajusterons le modèle pendant l'entraînement. Progressivement, le modèle trouvera la meilleure combinaison de pondérations et de biais pour minimiser les pertes. Et plus la perte est faible, meilleures sont les prédictions du modèle.
 |
| Figure 3. Algorithmes d'optimisation visualisés au fil du temps dans l'espace 3D. (Source : classe Stanford CS231n , licence MIT, crédit image : Alec Radford ) |
Swift pour TensorFlow dispose de nombreux algorithmes d'optimisation disponibles pour la formation. Ce modèle utilise l'optimiseur SGD qui implémente l'algorithme de descente de gradient stochastique (SGD). Le learningRate définit la taille du pas à effectuer pour chaque itération en bas de la colline. Il s'agit d'un hyperparamètre que vous ajusterez généralement pour obtenir de meilleurs résultats.
let optimizer = SGD(for: model, learningRate: 0.01)
Utilisons optimizer pour effectuer une seule étape de descente de gradient. Tout d’abord, nous calculons le gradient de la perte par rapport au modèle :
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Ensuite, nous transmettons le gradient que nous venons de calculer à l'optimiseur, qui met à jour les variables différentiables du modèle en conséquence :
optimizer.update(&model, along: grads)
Si nous calculons à nouveau la perte, elle devrait être plus petite, car les étapes de descente de gradient diminuent (généralement) la perte :
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Boucle d'entraînement
Une fois toutes les pièces en place, le modèle est prêt pour l'entraînement ! Une boucle de formation alimente les exemples d’ensembles de données dans le modèle pour l’aider à faire de meilleures prédictions. Le bloc de code suivant configure ces étapes de formation :
- Parcourez chaque époque . Une époque est un passage dans l’ensemble de données.
- Au cours d'une époque, parcourez chaque lot de l'époque de formation
- Rassemblez le lot et récupérez ses caractéristiques (
x) et son étiquette (y). - À l'aide des caractéristiques du lot assemblé, faites une prédiction et comparez-la avec l'étiquette. Mesurez l'inexactitude de la prédiction et utilisez-la pour calculer la perte et les gradients du modèle.
- Utilisez la descente de gradient pour mettre à jour les variables du modèle.
- Gardez une trace de certaines statistiques pour la visualisation.
- Répétez pour chaque époque.
La variable epochCount correspond au nombre de fois où effectuer une boucle sur la collection d'ensembles de données. Contre-intuitivement, entraîner un modèle plus longtemps ne garantit pas un meilleur modèle. epochCount est un hyperparamètre que vous pouvez régler. Choisir le bon numéro nécessite généralement à la fois de l’expérience et de l’expérimentation.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
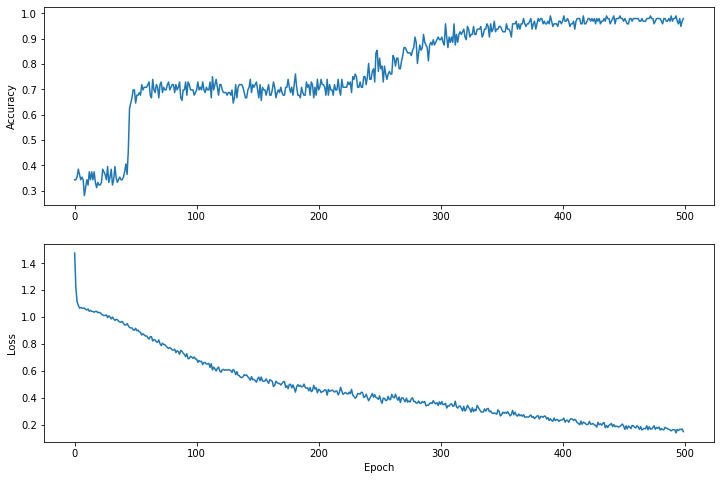
Visualisez la fonction de perte au fil du temps
Bien qu'il soit utile d'imprimer la progression de l'entraînement du modèle, il est souvent plus utile de voir cette progression. Nous pouvons créer des graphiques de base en utilisant le module matplotlib de Python.
L'interprétation de ces graphiques demande une certaine expérience, mais vous voulez vraiment voir la perte diminuer et la précision augmenter.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
Notez que les axes y des graphiques ne sont pas de base zéro.
Évaluer l'efficacité du modèle
Maintenant que le modèle est entraîné, nous pouvons obtenir quelques statistiques sur ses performances.
Évaluer signifie déterminer l’efficacité avec laquelle le modèle fait des prédictions. Pour déterminer l'efficacité du modèle en matière de classification de l'iris, transmettez quelques mesures de sépales et de pétales au modèle et demandez-lui de prédire quelles espèces d'iris ils représentent. Comparez ensuite la prédiction du modèle avec l'étiquette réelle. Par exemple, un modèle qui a sélectionné la bonne espèce dans la moitié des exemples d'entrée a une précision de 0.5 . La figure 4 montre un modèle légèrement plus efficace, obtenant 4 prédictions sur 5 correctes avec une précision de 80 % :
| Exemples de fonctionnalités | Étiquette | Prédiction du modèle | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1,5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figure 4. Un classificateur d'iris précis à 80 %. | |||||
Configurer l'ensemble de données de test
L'évaluation du modèle est similaire à la formation du modèle. La plus grande différence est que les exemples proviennent d'un ensemble de tests distinct plutôt que de l'ensemble de formation. Pour évaluer équitablement l'efficacité d'un modèle, les exemples utilisés pour évaluer un modèle doivent être différents des exemples utilisés pour entraîner le modèle.
La configuration de l'ensemble de données de test est similaire à la configuration de l'ensemble de données d'entraînement. Téléchargez l'ensemble de tests depuis http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Maintenant, chargez-le dans un tableau d' IrisBatch :
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Évaluer le modèle sur l'ensemble de données de test
Contrairement à l’étape de formation, le modèle n’évalue qu’une seule époque des données de test. Dans la cellule de code suivante, nous parcourons chaque exemple de l'ensemble de test et comparons la prédiction du modèle à l'étiquette réelle. Ceci est utilisé pour mesurer la précision du modèle sur l’ensemble de l’ensemble de tests.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
On peut voir sur le premier lot, par exemple, que le modèle est généralement correct :
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Utiliser le modèle entraîné pour faire des prédictions
Nous avons formé un modèle et démontré qu'il est efficace, mais pas parfait, pour classer les espèces d'iris. Utilisons maintenant le modèle entraîné pour faire des prédictions sur des exemples non étiquetés ; c'est-à-dire sur des exemples contenant des fonctionnalités mais pas d'étiquette.
Dans la vie réelle, les exemples non étiquetés peuvent provenir de nombreuses sources différentes, notamment des applications, des fichiers CSV et des flux de données. Pour l'instant, nous allons fournir manuellement trois exemples sans étiquette pour prédire leurs étiquettes. Rappelez-vous, les numéros d'étiquette sont mappés à une représentation nommée comme :
-
0: Iris setosa -
1: Iris versicolor -
2: Iris de Virginie
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])