
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
Panduan ini memperkenalkan Swift untuk TensorFlow dengan membuat model pembelajaran mesin yang mengkategorikan bunga iris berdasarkan spesies. Ia menggunakan Swift untuk TensorFlow untuk:
- Membangun model,
- Latih model ini pada contoh data, dan
- Gunakan model untuk membuat prediksi tentang data yang tidak diketahui.
Pemrograman TensorFlow
Panduan ini menggunakan konsep Swift untuk TensorFlow tingkat tinggi berikut:
- Impor data dengan Epochs API.
- Bangun model menggunakan abstraksi Swift.
- Gunakan pustaka Python menggunakan interoperabilitas Python Swift ketika pustaka Swift murni tidak tersedia.
Tutorial ini disusun seperti kebanyakan program TensorFlow:
- Impor dan parsing kumpulan data.
- Pilih jenis model.
- Latih modelnya.
- Evaluasi efektivitas model.
- Gunakan model terlatih untuk membuat prediksi.
Program pengaturan
Konfigurasikan impor
Impor TensorFlow dan beberapa modul Python yang berguna.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Masalah klasifikasi iris
Bayangkan Anda seorang ahli botani yang mencari cara otomatis untuk mengkategorikan setiap bunga iris yang Anda temukan. Pembelajaran mesin menyediakan banyak algoritma untuk mengklasifikasikan bunga secara statistik. Misalnya, program pembelajaran mesin yang canggih dapat mengklasifikasikan bunga berdasarkan foto. Ambisi kami lebih sederhana—kami akan mengklasifikasikan bunga iris berdasarkan ukuran panjang dan lebar sepal dan kelopaknya .
Genus Iris mencakup sekitar 300 spesies, namun program kami hanya akan mengklasifikasikan tiga spesies berikut:
- Iris setosa
- Iris Virginia
- Iris versikolor
 |
| Gambar 1. Iris setosa (oleh Radomil , CC BY-SA 3.0), Iris versicolor , (oleh Dlanglois , CC BY-SA 3.0), dan Iris virginica (oleh Frank Mayfield , CC BY-SA 2.0). |
Untungnya, seseorang telah membuat kumpulan data 120 bunga iris dengan ukuran sepal dan kelopak. Ini adalah kumpulan data klasik yang populer untuk masalah klasifikasi pembelajaran mesin pemula.
Impor dan parsing kumpulan data pelatihan
Unduh file kumpulan data dan ubah menjadi struktur yang dapat digunakan oleh program Swift ini.
Unduh kumpulan data
Unduh file kumpulan data pelatihan dari http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Periksa datanya
Kumpulan data ini, iris_training.csv , adalah file teks biasa yang menyimpan data tabular yang diformat sebagai nilai yang dipisahkan koma (CSV). Mari kita lihat 5 entri pertama.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Dari tampilan kumpulan data ini, perhatikan hal berikut:
- Baris pertama adalah header yang berisi informasi tentang dataset:
- Ada 120 contoh total. Setiap contoh memiliki empat fitur dan satu dari tiga kemungkinan nama label.
- Baris berikutnya adalah catatan data, satu contoh per baris, di mana:
- Empat bidang pertama adalah fitur : ini adalah karakteristik sebuah contoh. Di sini, bidang tersebut berisi angka mengambang yang mewakili ukuran bunga.
- Kolom terakhir adalah label : ini adalah nilai yang ingin kita prediksi. Untuk kumpulan data ini, nilai bilangan bulatnya adalah 0, 1, atau 2 yang sesuai dengan nama bunga.
Mari kita tuliskan dalam kode:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Setiap label dikaitkan dengan nama string (misalnya, "setosa"), namun pembelajaran mesin biasanya bergantung pada nilai numerik. Nomor label dipetakan ke representasi bernama, seperti:
-
0: Iris setosa -
1: Iris versikolor -
2: Iris virginica
Untuk informasi lebih lanjut tentang fitur dan label, lihat bagian Terminologi ML pada Kursus Singkat Machine Learning .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Buat kumpulan data menggunakan Epochs API
Epochs API Swift untuk TensorFlow adalah API tingkat tinggi untuk membaca data dan mengubahnya menjadi bentuk yang digunakan untuk pelatihan.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Karena kumpulan data yang kita unduh dalam format CSV, mari kita tulis fungsi untuk memuat data sebagai daftar objek IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Sekarang kita dapat menggunakan fungsi pemuatan CSV untuk memuat kumpulan data pelatihan dan membuat objek TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
Objek TrainingEpochs adalah rangkaian zaman yang tak terbatas. Setiap zaman berisi es IrisBatch . Mari kita lihat elemen pertama dari zaman pertama.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Perhatikan bahwa fitur untuk contoh batchSize pertama dikelompokkan bersama (atau di-batch ) ke dalam firstTrainFeatures , dan label untuk contoh batchSize pertama dikelompokkan ke dalam firstTrainLabels .
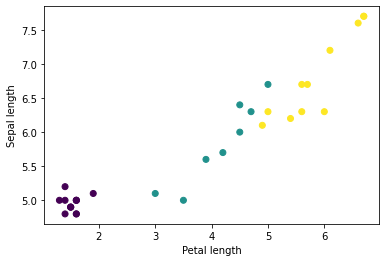
Anda dapat mulai melihat beberapa cluster dengan memplot beberapa fitur dari batch, menggunakan matplotlib Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
Pilih jenis model
Mengapa menjadi model?
Model adalah hubungan antara fitur dan label. Untuk masalah klasifikasi iris, model mendefinisikan hubungan antara pengukuran sepal dan kelopak serta prediksi spesies iris. Beberapa model sederhana dapat dijelaskan dengan beberapa baris aljabar, namun model pembelajaran mesin yang kompleks memiliki banyak parameter yang sulit untuk diringkas.
Bisakah Anda menentukan hubungan antara keempat fitur dan spesies iris mata tanpa menggunakan pembelajaran mesin? Artinya, bisakah Anda menggunakan teknik pemrograman tradisional (misalnya, banyak pernyataan kondisional) untuk membuat model? Mungkin—jika Anda menganalisis kumpulan data cukup lama untuk menentukan hubungan antara pengukuran kelopak dan sepal dengan spesies tertentu. Dan hal ini menjadi sulit—mungkin tidak mungkin—pada kumpulan data yang lebih rumit. Pendekatan pembelajaran mesin yang baik menentukan model untuk Anda . Jika Anda memasukkan cukup banyak contoh representatif ke dalam jenis model pembelajaran mesin yang tepat, program akan mengetahui hubungannya untuk Anda.
Pilih modelnya
Kita perlu memilih jenis model yang akan dilatih. Ada banyak jenis model dan memilih model yang bagus membutuhkan pengalaman. Tutorial ini menggunakan jaringan saraf untuk menyelesaikan masalah klasifikasi iris mata. Jaringan saraf dapat menemukan hubungan kompleks antara fitur dan label. Ini adalah grafik yang sangat terstruktur, disusun dalam satu atau lebih lapisan tersembunyi . Setiap lapisan tersembunyi terdiri dari satu atau lebih neuron . Ada beberapa kategori jaringan saraf dan program ini menggunakan jaringan saraf yang padat atau terhubung penuh : neuron dalam satu lapisan menerima koneksi input dari setiap neuron di lapisan sebelumnya. Misalnya, Gambar 2 mengilustrasikan jaringan saraf padat yang terdiri dari satu lapisan masukan, dua lapisan tersembunyi, dan satu lapisan keluaran:
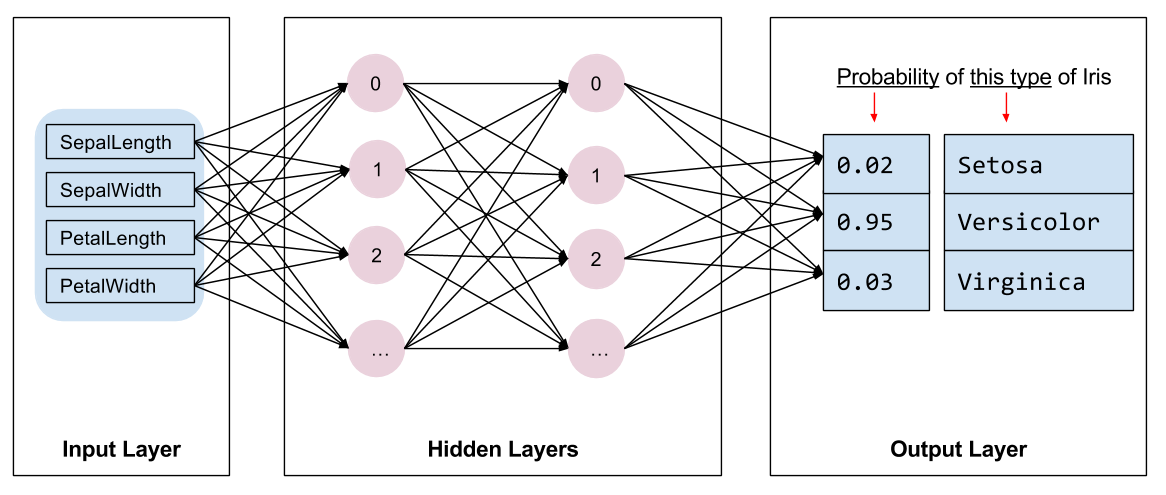 |
| Gambar 2. Jaringan saraf dengan fitur, lapisan tersembunyi, dan prediksi. |
Ketika model dari Gambar 2 dilatih dan diberi contoh yang tidak diberi label, model tersebut akan menghasilkan tiga prediksi: kemungkinan bahwa bunga ini adalah spesies iris yang diberikan. Prediksi ini disebut inferensi . Untuk contoh ini, jumlah prediksi keluarannya adalah 1,0. Pada Gambar 2, prediksi ini dipecah menjadi: 0.02 untuk Iris setosa , 0.95 untuk Iris versicolor , dan 0.03 untuk Iris virginica . Artinya, model tersebut memprediksi—dengan probabilitas 95%—bahwa contoh bunga yang tidak diberi label adalah Iris versicolor .
Buat model menggunakan Swift for TensorFlow Deep Learning Library
Swift for TensorFlow Deep Learning Library mendefinisikan lapisan dan konvensi primitif untuk menyatukannya, sehingga memudahkan pembuatan model dan eksperimen.
Model adalah struct yang sesuai dengan Layer , yang berarti model tersebut mendefinisikan metode callAsFunction(_:) yang memetakan input Tensor ke output Tensor s. Metode callAsFunction(_:) sering kali hanya mengurutkan input melalui sublapisan. Mari kita definisikan IrisModel yang mengurutkan input melalui tiga sublapisan Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
Fungsi aktivasi menentukan bentuk keluaran setiap node di lapisan. Non-linearitas ini penting—tanpanya, model akan setara dengan satu lapisan. Ada banyak aktivasi yang tersedia, tetapi ReLU umum untuk lapisan tersembunyi.
Jumlah ideal lapisan dan neuron tersembunyi bergantung pada masalah dan kumpulan data. Seperti banyak aspek pembelajaran mesin, memilih bentuk jaringan saraf terbaik memerlukan perpaduan antara pengetahuan dan eksperimen. Sebagai aturan praktis, peningkatan jumlah lapisan dan neuron tersembunyi biasanya akan menghasilkan model yang lebih kuat, yang memerlukan lebih banyak data untuk dilatih secara efektif.
Menggunakan model
Mari kita lihat sekilas apa yang dilakukan model ini terhadap sejumlah fitur:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Di sini, setiap contoh mengembalikan logit untuk setiap kelas.
Untuk mengonversi logit ini menjadi probabilitas untuk setiap kelas, gunakan fungsi softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Mengambil argmax di seluruh kelas memberi kita prediksi indeks kelas. Namun, modelnya belum dilatih, jadi ini bukanlah prediksi yang baik.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Latih modelnya
Pelatihan adalah tahap pembelajaran mesin ketika model dioptimalkan secara bertahap, atau model mempelajari kumpulan data. Tujuannya adalah untuk mempelajari cukup banyak tentang struktur kumpulan data pelatihan untuk membuat prediksi tentang data yang tidak terlihat. Jika Anda mempelajari terlalu banyak tentang kumpulan data pelatihan, maka prediksi hanya berfungsi untuk data yang telah dilihatnya dan tidak dapat digeneralisasikan. Masalah ini disebut overfitting —seperti menghafal jawaban alih-alih memahami cara memecahkan suatu masalah.
Masalah klasifikasi iris mata adalah contoh pembelajaran mesin yang diawasi : model dilatih dari contoh yang berisi label. Dalam pembelajaran mesin tanpa pengawasan , contoh tidak berisi label. Sebaliknya, model biasanya menemukan pola di antara fitur-fiturnya.
Pilih fungsi kerugian
Tahap pelatihan dan evaluasi perlu menghitung kerugian model. Hal ini mengukur seberapa menyimpang prediksi model dari label yang diinginkan, dengan kata lain, seberapa buruk performa model. Kami ingin meminimalkan, atau mengoptimalkan, nilai ini.
Model kita akan menghitung kerugiannya menggunakan fungsi softmaxCrossEntropy(logits:labels:) yang mengambil prediksi probabilitas kelas model dan label yang diinginkan, dan mengembalikan kerugian rata-rata di seluruh contoh.
Mari kita hitung kerugian untuk model yang tidak terlatih saat ini:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Buat pengoptimal
Pengoptimal menerapkan gradien yang dihitung ke variabel model untuk meminimalkan fungsi loss . Anda dapat membayangkan fungsi kerugian sebagai permukaan melengkung (lihat Gambar 3) dan kami ingin mencari titik terendahnya dengan berjalan-jalan. Gradiennya mengarah ke arah pendakian paling curam—jadi kita akan melakukan perjalanan ke arah sebaliknya dan menuruni bukit. Dengan menghitung kerugian dan gradien untuk setiap batch secara berulang, kami akan menyesuaikan model selama pelatihan. Secara bertahap, model akan menemukan kombinasi bobot dan bias terbaik untuk meminimalkan kerugian. Dan semakin rendah kerugiannya, semakin baik prediksi modelnya.
 |
| Gambar 3. Algoritma optimasi divisualisasikan dari waktu ke waktu dalam ruang 3D. (Sumber: Kelas Stanford CS231n , Lisensi MIT, Kredit gambar: Alec Radford ) |
Swift untuk TensorFlow memiliki banyak algoritma pengoptimalan yang tersedia untuk pelatihan. Model ini menggunakan pengoptimal SGD yang mengimplementasikan algoritma stochastic gradien descending (SGD). learningRate menetapkan ukuran langkah yang harus diambil untuk setiap iterasi menuruni bukit. Ini adalah hyperparameter yang biasanya Anda sesuaikan untuk mencapai hasil yang lebih baik.
let optimizer = SGD(for: model, learningRate: 0.01)
Mari gunakan optimizer untuk mengambil satu langkah penurunan gradien. Pertama, kita menghitung gradien kerugian terhadap model:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Selanjutnya, kita meneruskan gradien yang baru saja kita hitung ke pengoptimal, yang akan memperbarui variabel terdiferensiasi model:
optimizer.update(&model, along: grads)
Jika kita menghitung kerugiannya lagi, kerugiannya akan lebih kecil, karena langkah penurunan gradien (biasanya) mengurangi kerugian:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Lingkaran pelatihan
Dengan semua bagian sudah terpasang, model siap untuk pelatihan! Perulangan pelatihan memasukkan contoh kumpulan data ke dalam model untuk membantunya membuat prediksi yang lebih baik. Blok kode berikut menyiapkan langkah-langkah pelatihan ini:
- Ulangi setiap zaman . Suatu zaman adalah satu kali melewati kumpulan data.
- Dalam satu epoch, ulangi setiap batch dalam epoch pelatihan
- Susun batch dan ambil fiturnya (
x) dan label (y). - Dengan menggunakan fitur kumpulan yang disusun, buat prediksi dan bandingkan dengan label. Ukur ketidakakuratan prediksi dan gunakan itu untuk menghitung kerugian dan gradien model.
- Gunakan penurunan gradien untuk memperbarui variabel model.
- Pantau beberapa statistik untuk visualisasi.
- Ulangi untuk setiap zaman.
Variabel epochCount adalah berapa kali perulangan kumpulan dataset. Sebaliknya, melatih model lebih lama tidak menjamin model menjadi lebih baik. epochCount adalah hyperparameter yang dapat Anda sesuaikan. Memilih nomor yang tepat biasanya memerlukan pengalaman dan eksperimen.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
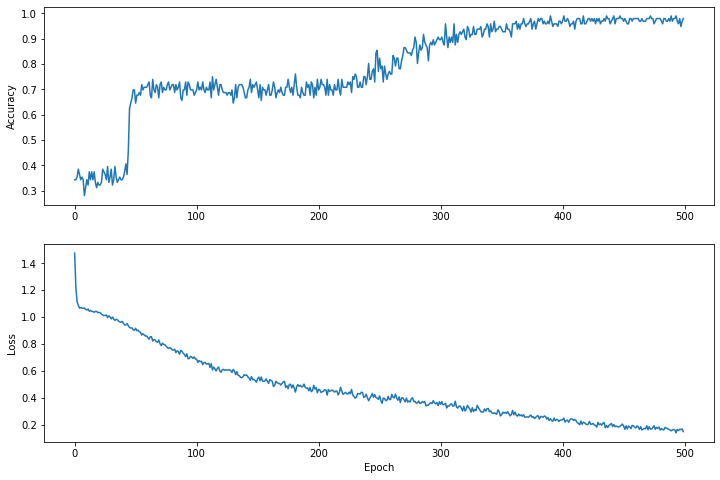
Visualisasikan fungsi kerugian dari waktu ke waktu
Meskipun mencetak kemajuan pelatihan model akan membantu, sering kali akan lebih membantu jika melihat kemajuan ini. Kita dapat membuat grafik dasar menggunakan modul matplotlib Python.
Menafsirkan grafik ini membutuhkan pengalaman, namun Anda benar-benar ingin melihat kerugiannya berkurang dan keakuratannya meningkat.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
Perhatikan bahwa sumbu y pada grafik tidak berbasis nol.
Evaluasi efektivitas model
Sekarang setelah model dilatih, kita bisa mendapatkan beberapa statistik tentang performanya.
Mengevaluasi berarti menentukan seberapa efektif model membuat prediksi. Untuk menentukan efektivitas model dalam klasifikasi iris mata, berikan beberapa pengukuran sepal dan kelopak ke model dan minta model untuk memprediksi spesies iris yang diwakilinya. Lalu bandingkan prediksi model dengan label sebenarnya. Misalnya, model yang memilih spesies yang benar dari separuh contoh masukan memiliki akurasi 0.5 . Gambar 4 menunjukkan model yang sedikit lebih efektif, menghasilkan 4 dari 5 prediksi yang benar dengan akurasi 80%:
| Contoh fitur | Label | Prediksi model | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Gambar 4. Pengklasifikasi iris mata yang 80% akurat. | |||||
Siapkan kumpulan data pengujian
Mengevaluasi model mirip dengan melatih model. Perbedaan terbesarnya adalah contoh berasal dari set pengujian terpisah, bukan dari set pelatihan. Untuk menilai efektivitas model secara adil, contoh yang digunakan untuk mengevaluasi model harus berbeda dari contoh yang digunakan untuk melatih model.
Penyiapan untuk kumpulan data pengujian serupa dengan penyiapan untuk kumpulan data pelatihan. Unduh set pengujian dari http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Sekarang muat ke dalam array IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Evaluasi model pada kumpulan data pengujian
Berbeda dengan tahap pelatihan, model hanya mengevaluasi satu periode data pengujian. Di sel kode berikut, kami mengulangi setiap contoh di set pengujian dan membandingkan prediksi model dengan label sebenarnya. Ini digunakan untuk mengukur akurasi model di seluruh set pengujian.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Kita bisa lihat di batch pertama, misalnya modelnya biasanya benar:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Gunakan model terlatih untuk membuat prediksi
Kami telah melatih seorang model dan menunjukkan bahwa model tersebut bagus—tetapi tidak sempurna—dalam mengklasifikasikan spesies iris. Sekarang mari kita gunakan model terlatih untuk membuat beberapa prediksi pada contoh yang tidak berlabel ; yaitu pada contoh yang mengandung fitur tetapi bukan label.
Dalam kehidupan nyata, contoh yang tidak berlabel dapat berasal dari berbagai sumber termasuk aplikasi, file CSV, dan data feed. Untuk saat ini, kami akan memberikan tiga contoh tanpa label secara manual untuk memprediksi labelnya. Ingat, nomor label dipetakan ke representasi bernama sebagai:
-
0: Iris setosa -
1: Iris versikolor -
2: Iris virginica
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])