
Depois que seus dados estiverem em um pipeline do TFX, você poderá usar componentes do TFX para analisá-los e transformá-los. Você pode usar essas ferramentas antes mesmo de treinar um modelo.
Existem muitos motivos para analisar e transformar seus dados:
- Para encontrar problemas em seus dados. Problemas comuns incluem:
- Dados ausentes, como recursos com valores vazios.
- Rótulos tratados como recursos, para que seu modelo possa dar uma olhada na resposta certa durante o treinamento.
- Recursos com valores fora do intervalo esperado.
- Anomalias de dados.
- O modelo de transferência aprendida possui pré-processamento que não corresponde aos dados de treinamento.
- Para projetar conjuntos de recursos mais eficazes. Por exemplo, você pode identificar:
- Recursos especialmente informativos.
- Recursos redundantes.
- Recursos que variam tanto em escala que podem retardar o aprendizado.
- Recursos com pouca ou nenhuma informação preditiva exclusiva.
As ferramentas TFX podem ajudar a encontrar bugs de dados e ajudar na engenharia de recursos.
Validação de dados do TensorFlow
- Visão geral
- Validação de exemplo baseada em esquema
- Detecção de distorção de serviço de treinamento
- Detecção de deriva
Visão geral
A validação de dados do TensorFlow identifica anomalias no treinamento e no fornecimento de dados e pode criar automaticamente um esquema examinando os dados. O componente pode ser configurado para detectar diferentes classes de anomalias nos dados. Pode
- Execute verificações de validade comparando estatísticas de dados com um esquema que codifica as expectativas do usuário.
- Detecte distorções no fornecimento de treinamento comparando exemplos de treinamento e fornecimento de dados.
- Detecte desvios de dados observando uma série de dados.
Documentamos cada uma dessas funcionalidades de forma independente:
- Validação de exemplo baseada em esquema
- Detecção de distorção de serviço de treinamento
- Detecção de deriva
Validação de exemplo baseada em esquema
A validação de dados do TensorFlow identifica quaisquer anomalias nos dados de entrada comparando estatísticas de dados com um esquema. O esquema codifica propriedades que se espera que os dados de entrada satisfaçam, como tipos de dados ou valores categóricos, e podem ser modificados ou substituídos pelo usuário.
A validação de dados do Tensorflow normalmente é invocada várias vezes no contexto do pipeline do TFX: (i) para cada divisão obtida do ExampleGen, (ii) para todos os dados pré-transformados usados pelo Transform e (iii) para todos os dados pós-transformação gerados pelo Transformar. Quando invocado no contexto de Transform (ii-iii), as opções de estatísticas e restrições baseadas em esquema podem ser definidas definindo stats_options_updater_fn . Isto é particularmente útil ao validar dados não estruturados (por exemplo, recursos de texto). Veja o código do usuário como exemplo.
Recursos avançados de esquema
Esta seção aborda configurações de esquema mais avançadas que podem ajudar em configurações especiais.
Recursos esparsos
A codificação de recursos esparsos em Exemplos geralmente introduz vários Recursos que devem ter a mesma valência para todos os Exemplos. Por exemplo, o recurso esparso:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
A definição de recurso esparso requer um ou mais recursos de índice e um recurso de valor que se referem aos recursos que existem no esquema. Definir explicitamente recursos esparsos permite que o TFDV verifique se as valências de todos os recursos referidos correspondem.
Alguns casos de uso introduzem restrições de valência semelhantes entre recursos, mas não codificam necessariamente um recurso esparso. Usar o recurso esparso deve desbloquear você, mas não é o ideal.
Ambientes de esquema
Por padrão, as validações assumem que todos os exemplos em um pipeline aderem a um único esquema. Em alguns casos, é necessária a introdução de pequenas variações de esquema, por exemplo, recursos usados como rótulos são necessários durante o treinamento (e devem ser validados), mas estão faltando durante a veiculação. Os ambientes podem ser usados para expressar tais requisitos, em particular default_environment() , in_environment() , not_in_environment() .
Por exemplo, suponha que um recurso chamado 'LABEL' seja necessário para treinamento, mas espera-se que esteja ausente na veiculação. Isso pode ser expresso por:
- Defina dois ambientes distintos no esquema: ["SERVING", "TRAINING"] e associe 'LABEL' apenas ao ambiente "TRAINING".
- Associe os dados de treinamento ao ambiente "TRAINING" e os dados de serviço ao ambiente "SERVING".
Geração de esquema
O esquema de dados de entrada é especificado como uma instância do esquema TensorFlow.
Em vez de construir um esquema manualmente do zero, um desenvolvedor pode contar com a construção automática de esquema do TensorFlow Data Validation. Especificamente, o TensorFlow Data Validation constrói automaticamente um esquema inicial com base em estatísticas calculadas sobre dados de treinamento disponíveis no pipeline. Os usuários podem simplesmente revisar esse esquema gerado automaticamente, modificá-lo conforme necessário, registrá-lo em um sistema de controle de versão e enviá-lo explicitamente ao pipeline para validação adicional.
TFDV inclui infer_schema() para gerar um esquema automaticamente. Por exemplo:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Isso aciona uma geração automática de esquema com base nas seguintes regras:
Se um esquema já tiver sido gerado automaticamente, ele será usado como está.
Caso contrário, o TensorFlow Data Validation examina as estatísticas de dados disponíveis e calcula um esquema adequado para os dados.
Nota: O esquema gerado automaticamente é de melhor esforço e tenta apenas inferir propriedades básicas dos dados. Espera-se que os usuários o revisem e modifiquem conforme necessário.
Detecção de distorção de serviço de treinamento
Visão geral
A validação de dados do TensorFlow pode detectar distorções de distribuição entre o treinamento e o fornecimento de dados. A distorção de distribuição ocorre quando a distribuição de valores de recursos para dados de treinamento é significativamente diferente da distribuição de dados. Uma das principais causas da distorção da distribuição é usar um corpus completamente diferente para treinar a geração de dados para superar a falta de dados iniciais no corpus desejado. Outro motivo é um mecanismo de amostragem defeituoso que escolhe apenas uma subamostra dos dados de serviço para treinar.
Cenário de exemplo
Consulte o Guia de primeiros passos da validação de dados do TensorFlow para obter informações sobre como configurar a detecção de distorção de serviço de treinamento.
Detecção de deriva
A detecção de desvio é suportada entre intervalos consecutivos de dados (ou seja, entre o intervalo N e o intervalo N+1), como entre diferentes dias de dados de treinamento. Expressamos a deriva em termos de distância L-infinito para características categóricas e divergência aproximada de Jensen-Shannon para características numéricas. Você pode definir a distância limite para receber avisos quando o desvio for maior do que o aceitável. Definir a distância correta normalmente é um processo iterativo que requer conhecimento de domínio e experimentação.
Consulte o Guia de primeiros passos da validação de dados do TensorFlow para obter informações sobre como configurar a detecção de desvios.
Usando visualizações para verificar seus dados
A validação de dados do TensorFlow fornece ferramentas para visualizar a distribuição de valores de recursos. Ao examinar essas distribuições em um notebook Jupyter usando Facets, você pode detectar problemas comuns com dados.
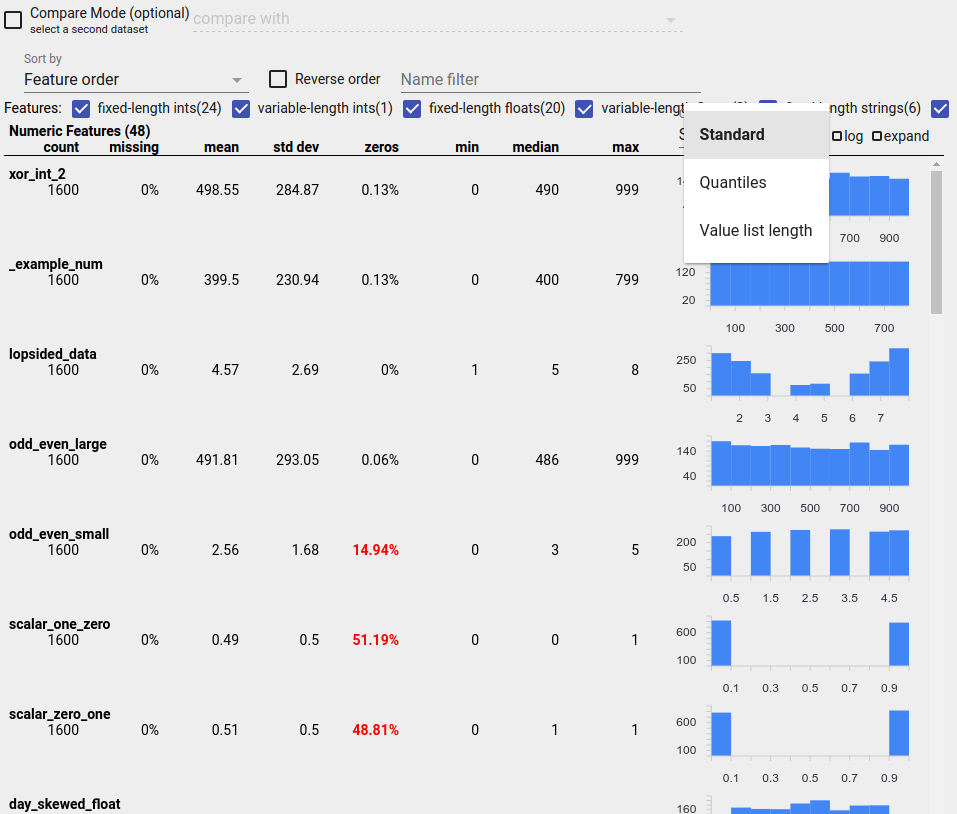
Identificando distribuições suspeitas
Você pode identificar bugs comuns em seus dados usando uma exibição Visão geral de facetas para procurar distribuições suspeitas de valores de recursos.
Dados desequilibrados
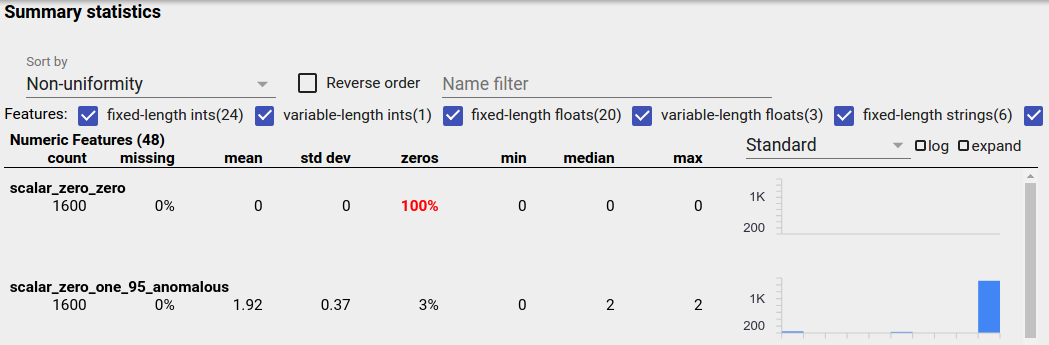
Um recurso desequilibrado é aquele para o qual um valor predomina. Recursos desequilibrados podem ocorrer naturalmente, mas se um recurso sempre tiver o mesmo valor, você poderá ter um bug de dados. Para detectar recursos desequilibrados em uma visão geral de facetas, escolha "Não uniformidade" no menu suspenso "Classificar por".
Os recursos mais desequilibrados serão listados no topo de cada lista de tipo de recurso. Por exemplo, a captura de tela a seguir mostra um recurso composto apenas por zeros e um segundo altamente desequilibrado, no topo da lista "Recursos numéricos":
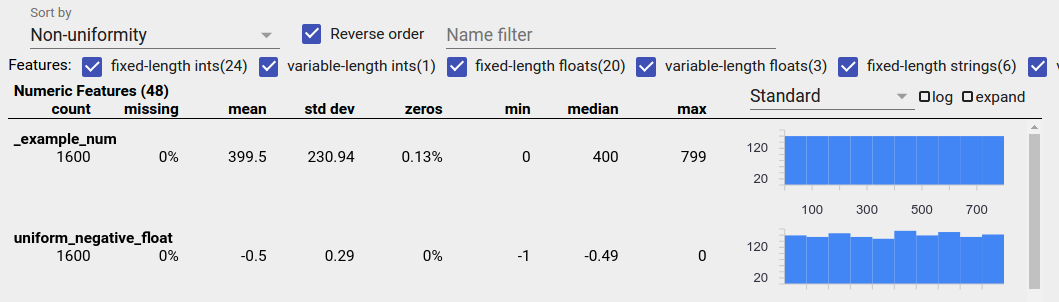
Dados distribuídos uniformemente
Um recurso uniformemente distribuído é aquele para o qual todos os valores possíveis aparecem quase com a mesma frequência. Tal como acontece com os dados desequilibrados, esta distribuição pode ocorrer naturalmente, mas também pode ser produzida por erros de dados.
Para detectar recursos distribuídos uniformemente em uma visão geral de facetas, escolha "Não uniformidade" no menu suspenso "Classificar por" e marque a caixa de seleção "Ordem reversa":
Os dados de string são representados usando gráficos de barras se houver 20 ou menos valores exclusivos e como um gráfico de distribuição cumulativa se houver mais de 20 valores exclusivos. Portanto, para dados de string, distribuições uniformes podem aparecer como gráficos de barras planas como o acima ou linhas retas como o abaixo:

Bugs que podem produzir dados distribuídos uniformemente
Aqui estão alguns bugs comuns que podem produzir dados distribuídos uniformemente:
Usando strings para representar tipos de dados que não sejam strings, como datas. Por exemplo, você terá muitos valores exclusivos para um recurso de data e hora com representações como "2017-03-01-11-45-03". Valores únicos serão distribuídos uniformemente.
Incluindo índices como "número da linha" como recursos. Aqui, novamente, você tem muitos valores exclusivos.
Dados ausentes
Para verificar se um recurso está totalmente ausente de valores:
- Escolha "Quantidade faltante/zero" no menu suspenso "Classificar por".
- Marque a caixa de seleção "Ordem inversa".
- Observe a coluna "ausente" para ver a porcentagem de instâncias com valores ausentes para um recurso.
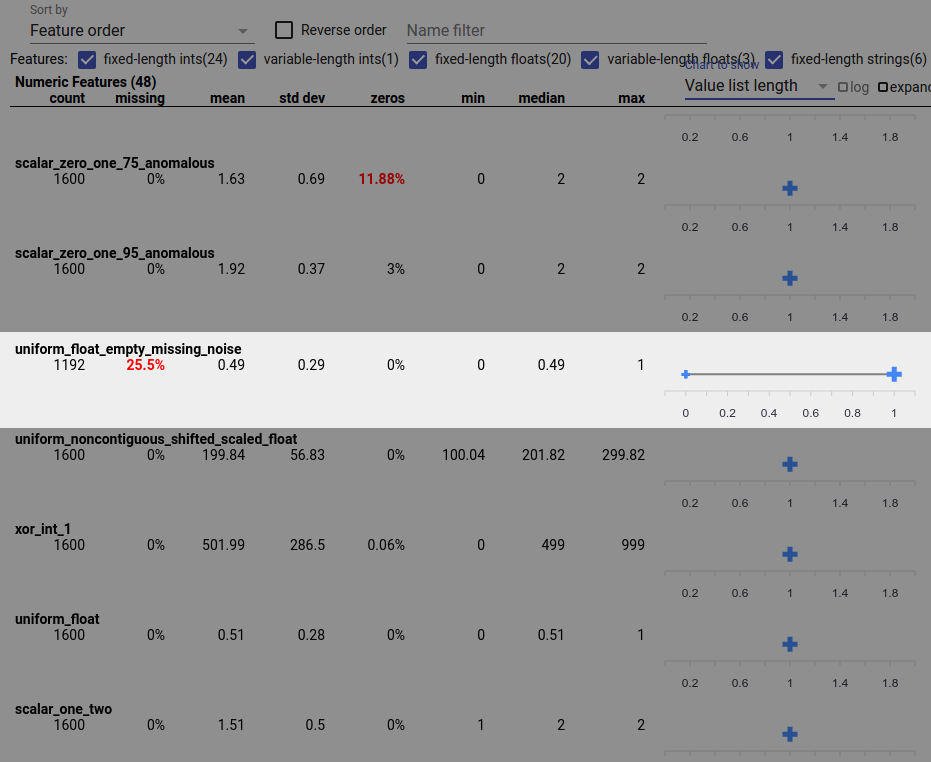
Um bug de dados também pode causar valores de recursos incompletos. Por exemplo, você pode esperar que a lista de valores de um recurso sempre tenha três elementos e descubra que às vezes ela possui apenas um. Para verificar valores incompletos ou outros casos em que as listas de valores de atributos não possuem o número esperado de elementos:
Escolha “Comprimento da lista de valores” no menu suspenso “Gráfico para mostrar” à direita.
Observe o gráfico à direita de cada linha de recurso. O gráfico mostra o intervalo de comprimentos da lista de valores para o recurso. Por exemplo, a linha destacada na captura de tela abaixo mostra um recurso que possui algumas listas de valores de comprimento zero:
Grandes diferenças de escala entre recursos
Se seus recursos variarem muito em escala, o modelo poderá ter dificuldades de aprendizado. Por exemplo, se alguns atributos variam de 0 a 1 e outros variam de 0 a 1.000.000.000, você tem uma grande diferença de escala. Compare as colunas "max" e "min" entre os recursos para encontrar escalas muito variadas.
Considere normalizar os valores dos recursos para reduzir essas grandes variações.
Etiquetas com etiquetas inválidas
Os estimadores do TensorFlow têm restrições quanto ao tipo de dados que aceitam como rótulos. Por exemplo, classificadores binários normalmente funcionam apenas com rótulos {0, 1}.
Revise os valores dos rótulos na Visão geral das facetas e certifique-se de que estejam em conformidade com os requisitos dos Estimadores .