
مقدمه
TFX یک پلت فرم یادگیری ماشینی (ML) در مقیاس تولید گوگل است که بر اساس TensorFlow است. این یک چارچوب پیکربندی و کتابخانه های مشترک را برای ادغام اجزای مشترک مورد نیاز برای تعریف، راه اندازی و نظارت بر سیستم یادگیری ماشین شما فراهم می کند.
TFX 1.0
ما خوشحالیم که در دسترس بودن TFX 1.0.0 را اعلام کنیم. این نسخه اولیه پس از بتا TFX است که APIها و مصنوعات عمومی پایداری را ارائه می دهد. می توانید مطمئن باشید که خطوط لوله TFX آینده شما پس از ارتقاء در محدوده سازگاری تعریف شده در این RFC به کار خود ادامه خواهند داد.
نصب و راه اندازی

![]()
pip install tfx
بسته های شبانه
TFX همچنین بسته های شبانه را در https://pypi-nightly.tensorflow.org در Google Cloud میزبانی می کند. برای نصب آخرین بسته شبانه لطفا از دستور زیر استفاده کنید:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
این بستههای شبانه را برای وابستگیهای اصلی TFX مانند تجزیه و تحلیل مدل TensorFlow (TFMA)، اعتبارسنجی دادههای TensorFlow (TFDV)، تبدیل TensorFlow (TFT)، کتابخانههای عمومی مشترک TFX (TFX-BSL)، ML Metadata (MLMD) نصب میکند.
درباره TFX
TFX پلت فرمی برای ایجاد و مدیریت گردش کار ML در محیط تولید است. TFX موارد زیر را ارائه می دهد:
یک جعبه ابزار برای ساخت خطوط لوله ML. خطوط لوله TFX به شما امکان می دهد گردش کار ML خود را بر روی چندین پلتفرم تنظیم کنید، مانند: Apache Airflow، Apache Beam و Kubeflow Pipelines.
مجموعه ای از اجزای استاندارد که می توانید به عنوان بخشی از خط لوله یا به عنوان بخشی از اسکریپت آموزش ML خود استفاده کنید. مؤلفه های استاندارد TFX عملکرد اثبات شده ای را ارائه می دهند تا به شما کمک کنند ساخت یک فرآیند ML را به راحتی شروع کنید.
کتابخانه هایی که عملکرد پایه بسیاری از اجزای استاندارد را فراهم می کنند. شما می توانید از کتابخانه های TFX برای افزودن این قابلیت به اجزای سفارشی خود استفاده کنید یا از آنها به طور جداگانه استفاده کنید.
TFX یک ابزار یادگیری ماشینی در مقیاس تولید گوگل است که بر اساس TensorFlow است. این یک چارچوب پیکربندی و کتابخانه های مشترک را برای ادغام اجزای مشترک مورد نیاز برای تعریف، راه اندازی و نظارت بر سیستم یادگیری ماشین شما فراهم می کند.
اجزای استاندارد TFX
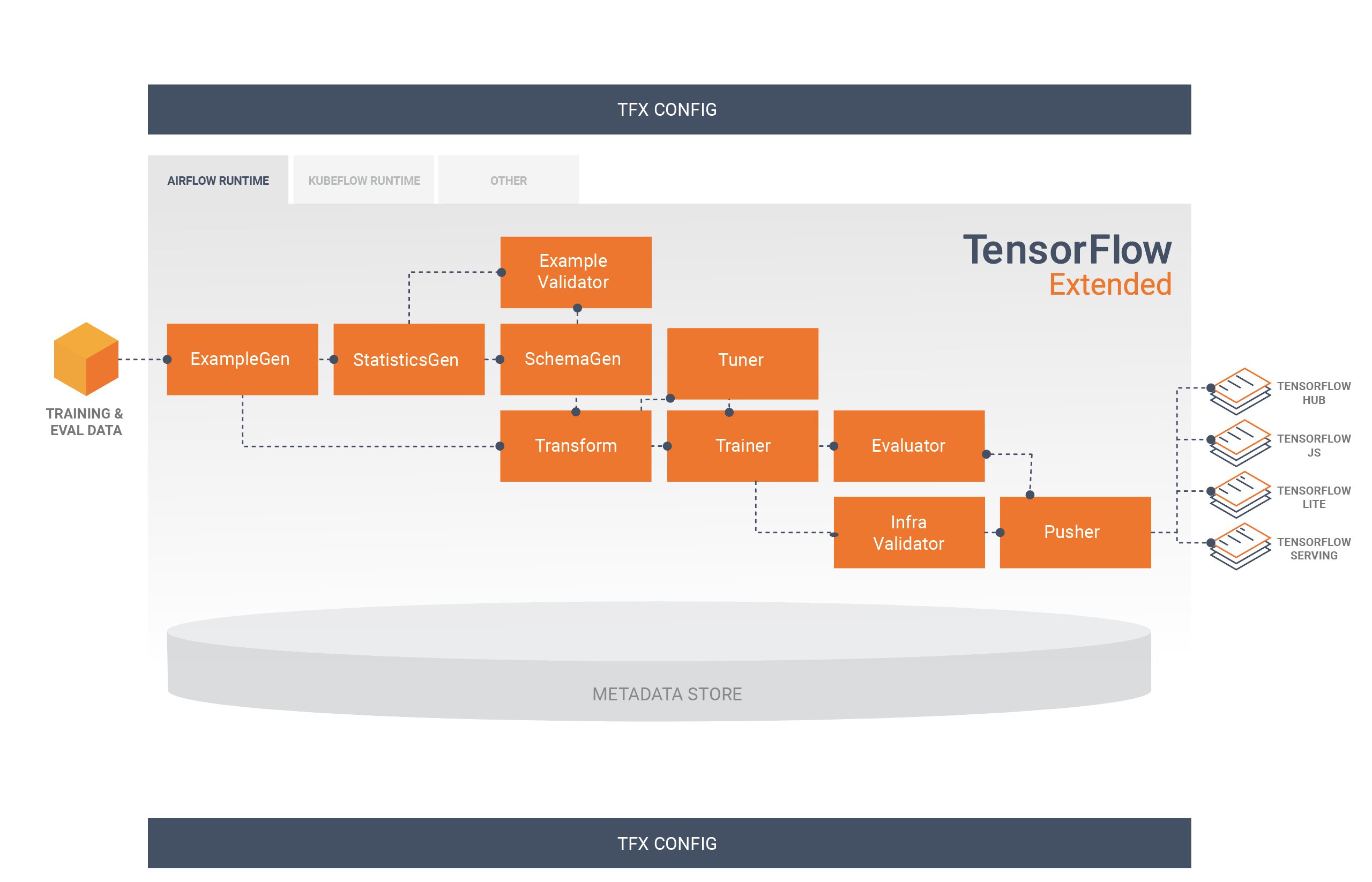
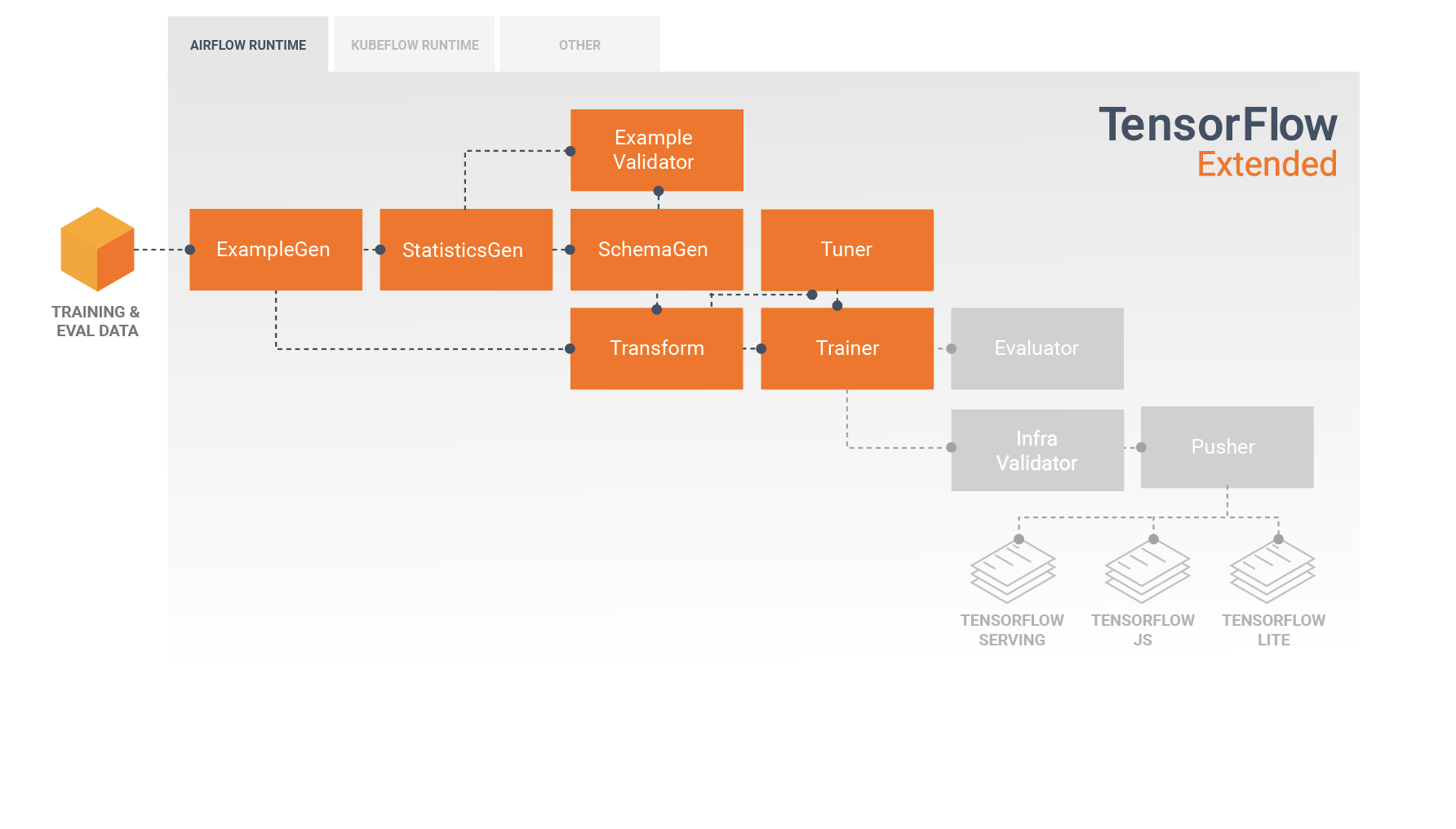
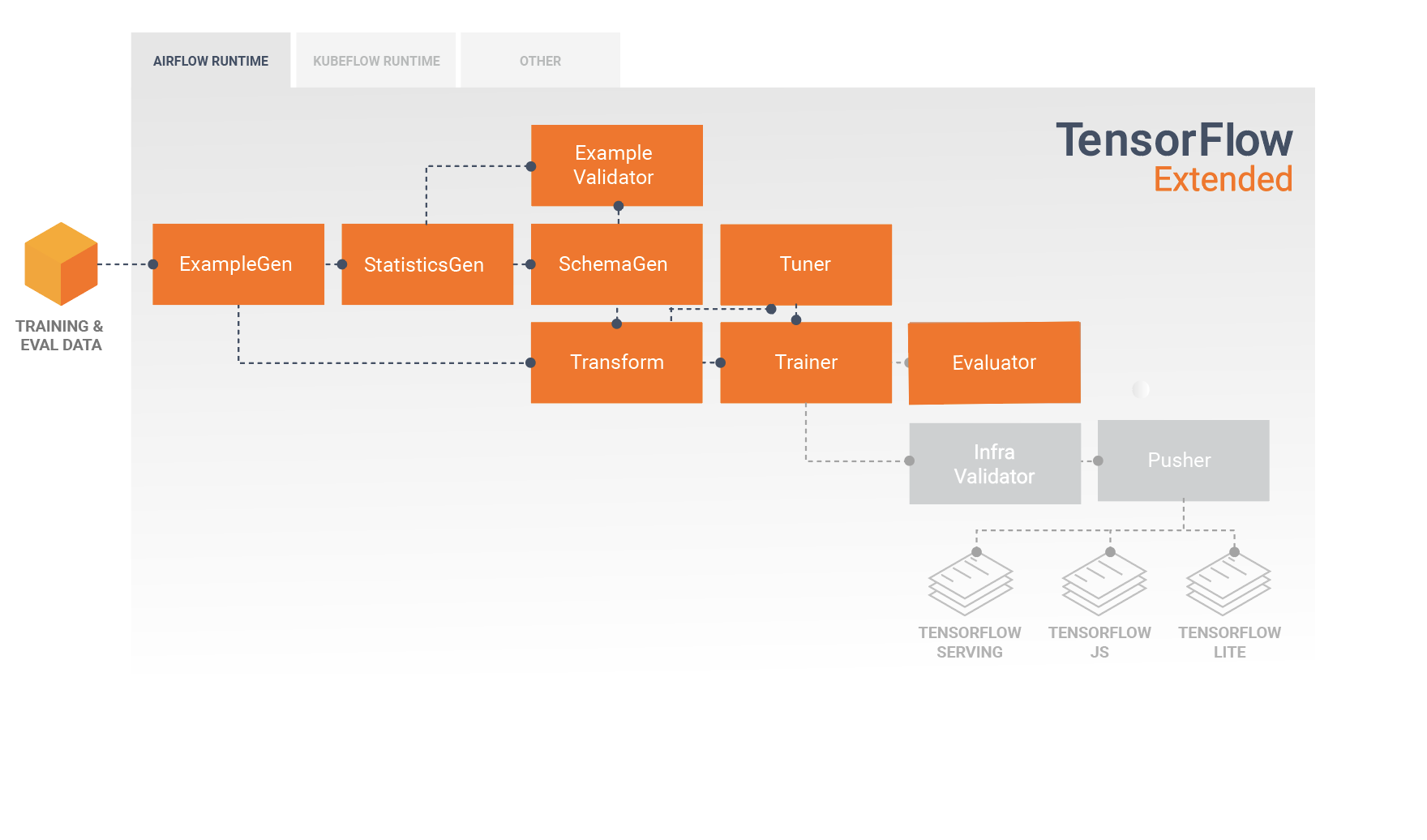
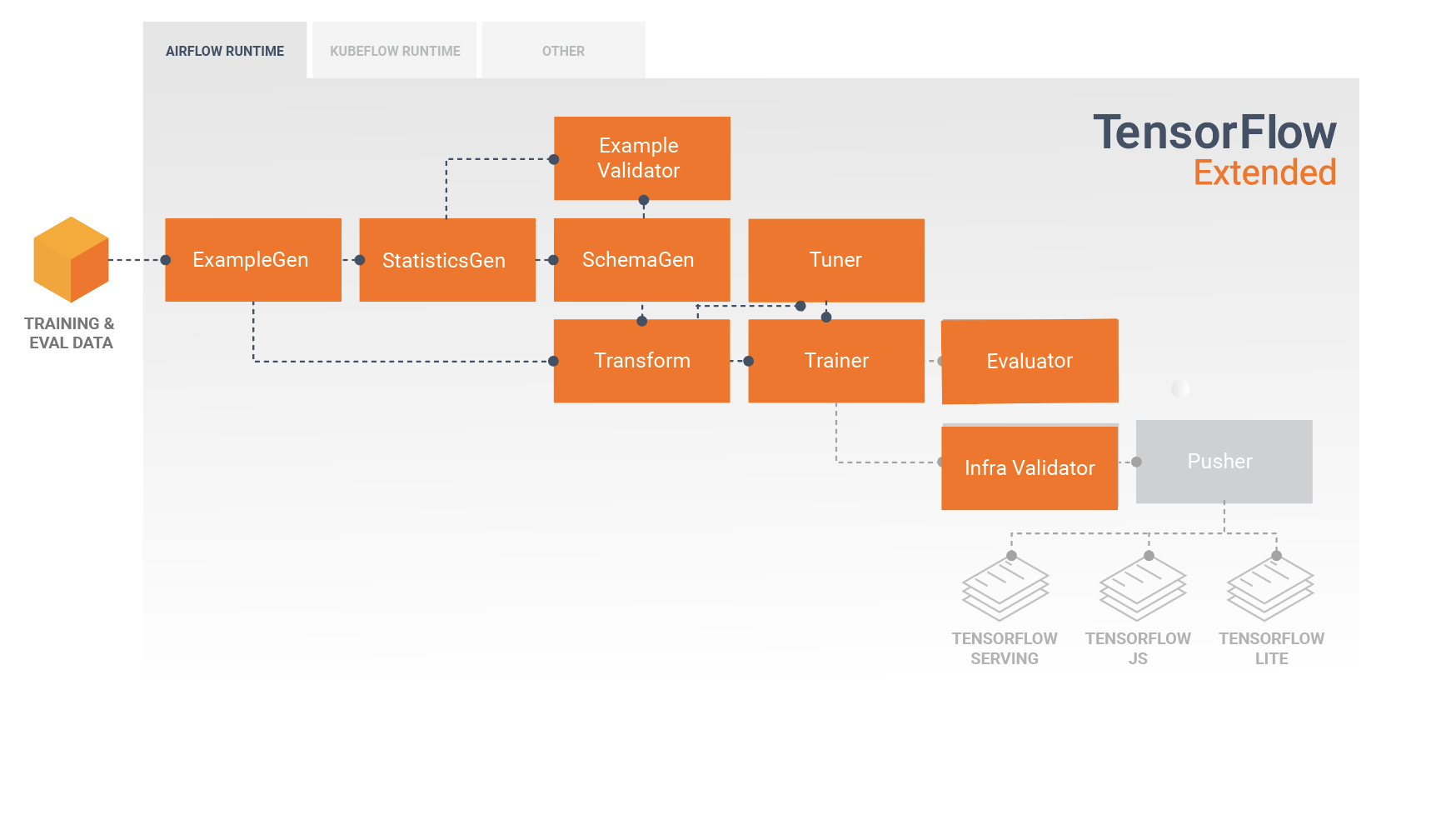
خط لوله TFX دنباله ای از اجزا است که خط لوله ML را پیاده سازی می کند که به طور خاص برای کارهای یادگیری ماشینی مقیاس پذیر و با کارایی بالا طراحی شده است. این شامل مدلسازی، آموزش، ارائه استنتاج و مدیریت استقرار در اهداف آنلاین، تلفن همراه بومی و جاوا اسکریپت است.
خط لوله TFX معمولاً شامل اجزای زیر است:
ExampleGen جزء ورودی اولیه یک خط لوله است که مجموعه داده ورودی را می خورد و به صورت اختیاری تقسیم می کند.
StatisticsGen آمار مجموعه داده را محاسبه می کند.
SchemaGen آمار را بررسی می کند و یک طرح داده ایجاد می کند.
ExampleValidator به دنبال ناهنجاری ها و مقادیر گم شده در مجموعه داده می گردد.
Transform مهندسی ویژگی را روی مجموعه داده انجام می دهد.
مربی مدل را آموزش می دهد.
تیونر هایپرپارامترهای مدل را تنظیم می کند.
ارزیاب تجزیه و تحلیل عمیقی از نتایج آموزشی انجام می دهد و به شما کمک می کند تا مدل های صادراتی خود را اعتبار سنجی کنید و اطمینان حاصل کنید که آنها "به اندازه کافی خوب" هستند تا به سمت تولید سوق داده شوند.
InfraValidator بررسی می کند که مدل واقعاً از زیرساخت قابل استفاده است و از فشار دادن مدل بد جلوگیری می کند.
Pusher مدل را بر روی یک زیرساخت سرویس دهی می کند.
BulkInferrer پردازش دسته ای را روی مدلی با درخواست های استنتاج بدون برچسب انجام می دهد.
این نمودار جریان داده بین این اجزا را نشان می دهد:
کتابخانه های TFX
TFX شامل کتابخانه ها و اجزای خط لوله است. این نمودار روابط بین کتابخانه های TFX و اجزای خط لوله را نشان می دهد:
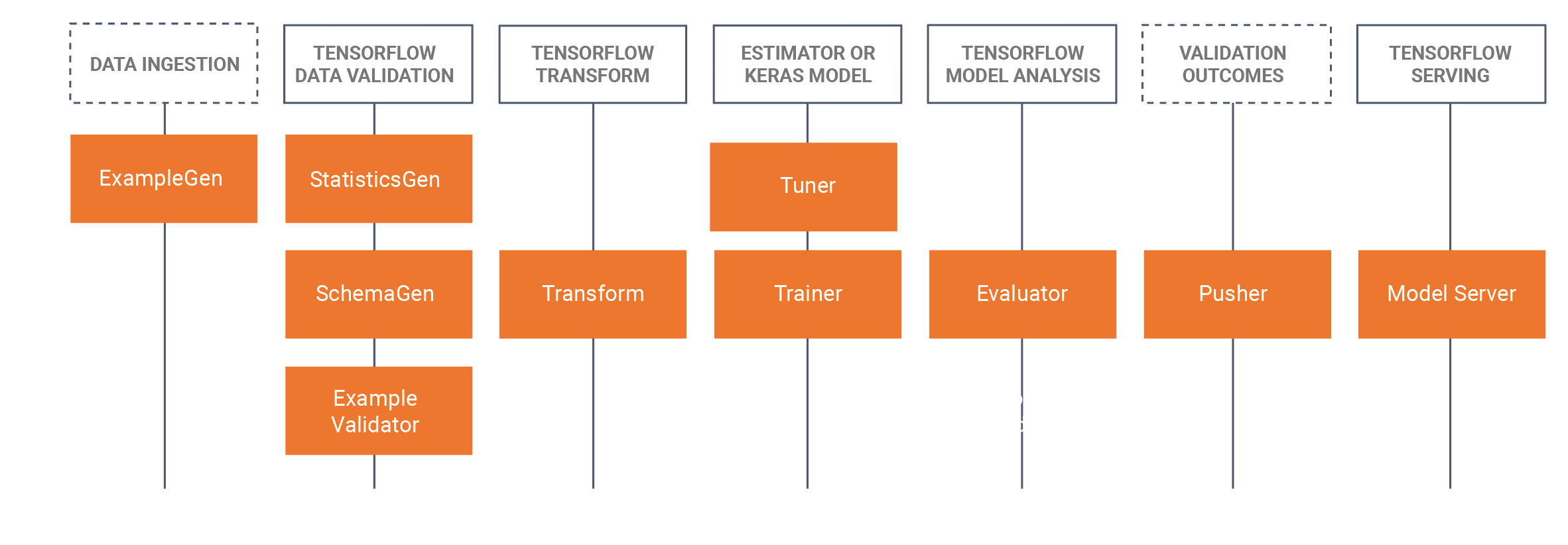
TFX چندین بسته پایتون را فراهم می کند که کتابخانه هایی هستند که برای ایجاد اجزای خط لوله استفاده می شوند. شما از این کتابخانه ها برای ایجاد اجزای خطوط لوله خود استفاده خواهید کرد تا کد شما بتواند بر جنبه های منحصر به فرد خط لوله شما تمرکز کند.
کتابخانه های TFX عبارتند از:
TensorFlow Data Validation (TFDV) کتابخانه ای برای تجزیه و تحلیل و اعتبارسنجی داده های یادگیری ماشین است. این طراحی شده است که بسیار مقیاس پذیر باشد و با TensorFlow و TFX به خوبی کار کند. TFDV شامل:
- محاسبه مقیاس پذیر آمار خلاصه داده های آموزش و آزمون.
- ادغام با یک بیننده برای توزیع داده ها و آمار، و همچنین مقایسه وجهی جفت مجموعه داده ها (Facets).
- تولید طرح واره داده خودکار برای توصیف انتظارات در مورد داده ها مانند مقادیر، محدوده ها و واژگان مورد نیاز.
- یک نمایشگر طرحواره برای کمک به شما در بررسی طرحواره.
- تشخیص ناهنجاری برای شناسایی ناهنجاریها، مانند ویژگیهای از دست رفته، مقادیر خارج از محدوده، یا انواع ویژگیهای اشتباه، به نام چند.
- نمایشگر ناهنجاری ها تا بتوانید ببینید چه ویژگی هایی دارای ناهنجاری هستند و برای اصلاح آنها بیشتر بدانید.
TensorFlow Transform (TFT) یک کتابخانه برای پیش پردازش داده ها با TensorFlow است. TensorFlow Transform برای داده هایی که نیاز به یک پاس کامل دارند مفید است، مانند:
- یک مقدار ورودی را با میانگین و انحراف استاندارد عادی کنید.
- با ایجاد یک واژگان بر روی تمام مقادیر ورودی، رشته ها را به اعداد صحیح تبدیل کنید.
- با اختصاص دادن آنها به سطل ها بر اساس توزیع داده های مشاهده شده، شناورها را به اعداد صحیح تبدیل کنید.
TensorFlow برای آموزش مدل های با TFX استفاده می شود. داده های آموزشی و کد مدل سازی را دریافت می کند و یک نتیجه SavedModel ایجاد می کند. همچنین یک خط لوله مهندسی ویژگی ایجاد شده توسط TensorFlow Transform را برای پیش پردازش داده های ورودی یکپارچه می کند.
KerasTuner برای تنظیم هایپرپارامترها برای مدل استفاده می شود.
تجزیه و تحلیل مدل TensorFlow (TFMA) کتابخانه ای برای ارزیابی مدل های TensorFlow است. از آن همراه با TensorFlow برای ایجاد EvalSavedModel استفاده میشود که مبنای تحلیل آن میشود. این به کاربران اجازه می دهد تا مدل های خود را بر روی مقادیر زیادی از داده ها به صورت توزیع شده، با استفاده از معیارهای مشابه تعریف شده در مربی خود ارزیابی کنند. این معیارها را می توان بر روی برش های مختلف داده محاسبه کرد و در نوت بوک های Jupyter تجسم کرد.
Metadata TensorFlow (TFMD) نمایشهای استانداردی را برای ابردادهها ارائه میکند که هنگام آموزش مدلهای یادگیری ماشین با TensorFlow مفید هستند. فراداده ممکن است به صورت دستی یا به صورت خودکار در طول تجزیه و تحلیل داده های ورودی تولید شود و ممکن است برای اعتبارسنجی، کاوش و تبدیل داده ها مصرف شود. فرمت های سریال سازی ابرداده عبارتند از:
- طرحی که داده های جدولی را توصیف می کند (مثلاً tf. Examples).
- مجموعه ای از آمار خلاصه در مورد این مجموعه داده ها.
فراداده ML (MLMD) کتابخانه ای برای ضبط و بازیابی ابرداده های مرتبط با گردش کار توسعه دهندگان ML و دانشمندان داده است. اغلب ابرداده ها از نمایش های TFMD استفاده می کنند. MLMD پایداری را با استفاده از SQL-Lite ، MySQL و سایر ذخیرههای داده مشابه مدیریت میکند.
فن آوری های حمایتی
ضروری
- Apache Beam یک مدل منبع باز و یکپارچه برای تعریف خطوط لوله پردازش موازی داده های دسته ای و جریانی است. TFX از Apache Beam برای پیاده سازی خطوط لوله موازی داده استفاده می کند. سپس خط لوله توسط یکی از پشتیبانهای پردازش توزیعشده پشتیبانی شده Beam اجرا میشود که شامل Apache Flink، Apache Spark، Google Cloud Dataflow و موارد دیگر میشود.
اختیاری
ارکستراتورهایی مانند Apache Airflow و Kubeflow پیکربندی، عملیات، نظارت و نگهداری خط لوله ML را آسانتر میکنند.
Apache Airflow پلتفرمی برای نوشتن، برنامهریزی و نظارت بر گردشهای کاری برنامهریزی شده است. TFX از Airflow برای نوشتن جریان های کاری به عنوان نمودارهای غیر چرخه ای جهت دار (DAG) از وظایف استفاده می کند. زمانبندی جریان هوا وظایف را روی آرایه ای از کارگران در حالی که وابستگی های مشخص شده را دنبال می کند، اجرا می کند. ابزارهای غنی خط فرمان، انجام جراحی های پیچیده بر روی DAG ها را به یک فوریت تبدیل می کند. رابط کاربری غنی، تجسم خطوط لوله در حال اجرا در تولید، نظارت بر پیشرفت و عیب یابی مشکلات را در صورت نیاز آسان می کند. وقتی گردش کار به عنوان کد تعریف می شود، قابل نگهداری، نسخه پذیرتر، آزمایش پذیرتر و مشارکتی تر می شود.
Kubeflow به ایجاد استقرار گردشهای کاری یادگیری ماشین (ML) در Kubernetes ساده، قابل حمل و مقیاسپذیر اختصاص دارد. هدف Kubeflow بازآفرینی خدمات دیگر نیست، بلکه ارائه راهی ساده برای استقرار بهترین سیستمهای منبع باز برای ML در زیرساختهای متنوع است. خطوط لوله Kubeflow ترکیب و اجرای گردشهای کاری تکرارپذیر را در Kubeflow، ادغام شده با تجربیات مبتنی بر نوتبوک، امکانپذیر میسازد. خدمات Kubeflow Pipelines در Kubernetes شامل فروشگاه ابرداده میزبان، موتور هماهنگ سازی مبتنی بر کانتینر، سرور نوت بوک و رابط کاربری است که به کاربران کمک می کند خطوط لوله پیچیده ML را در مقیاس توسعه دهند، اجرا کنند و مدیریت کنند. Kubeflow Pipelines SDK امکان ایجاد و اشتراک گذاری اجزا و ترکیب خطوط لوله را به صورت برنامه ای فراهم می کند.
قابل حمل و قابلیت همکاری
TFX به گونه ای طراحی شده است که برای محیط های مختلف و چارچوب های ارکستراسیون، از جمله Apache Airflow ، Apache Beam و Kubeflow قابل حمل باشد. همچنین برای پلتفرمهای محاسباتی مختلف، از جمله بسترهای داخلی، و پلتفرمهای ابری مانند Google Cloud Platform (GCP) قابل حمل است. به طور خاص، TFX با سرویسهای GCP مدیریتشده سرور، مانند پلتفرم هوش مصنوعی ابری برای آموزش و پیشبینی ، و Cloud Dataflow برای پردازش دادههای توزیعشده برای چندین جنبه دیگر از چرخه حیات ML تعامل دارد.
مدل در مقابل SavedModel
مدل
یک مدل خروجی فرآیند آموزش است. این رکورد سریالی از وزنه هایی است که در طول فرآیند آموزش آموخته شده است. این وزنها میتوانند متعاقباً برای محاسبه پیشبینیها برای نمونههای ورودی جدید استفاده شوند. برای TFX و TensorFlow، «مدل» به نقاط بازرسی اطلاق میشود که حاوی وزنهای آموختهشده تا آن نقطه است.
توجه داشته باشید که «مدل» ممکن است به تعریف نمودار محاسباتی TensorFlow (یعنی یک فایل پایتون) نیز اشاره داشته باشد که نحوه محاسبه یک پیشبینی را بیان میکند. این دو حس ممکن است به جای یکدیگر بر اساس زمینه مورد استفاده قرار گیرند.
SavedModel
- SavedModel چیست : سریالسازی جهانی، زبانی خنثی، هرمتیک و قابل بازیابی یک مدل TensorFlow.
- چرا مهم است : سیستم های سطح بالاتر را قادر می سازد تا مدل های TensorFlow را با استفاده از یک انتزاع واحد تولید، تبدیل و مصرف کنند.
SavedModel فرمت سریالسازی توصیهشده برای ارائه یک مدل TensorFlow در تولید، یا صادرات یک مدل آموزشدیده برای یک موبایل بومی یا برنامه جاوا اسکریپت است. به عنوان مثال، برای تبدیل یک مدل به یک سرویس REST برای انجام پیشبینی، میتوانید مدل را بهعنوان SavedModel سریال کنید و با استفاده از TensorFlow Serving آن را ارائه کنید. برای اطلاعات بیشتر به ارائه مدل TensorFlow مراجعه کنید.
طرحواره
برخی از مؤلفههای TFX از توصیفی از دادههای ورودی شما به نام طرحواره استفاده میکنند. این طرح یک نمونه از schema.proto است. طرحواره ها یک نوع بافر پروتکل هستند که به طور کلی به عنوان "protobuf" شناخته می شوند. این طرح میتواند انواع دادهها را برای مقادیر ویژگی مشخص کند، اینکه آیا یک ویژگی باید در همه مثالها وجود داشته باشد، محدوده مقادیر مجاز و سایر ویژگیها. یکی از مزایای استفاده از اعتبارسنجی داده های TensorFlow (TFDV) این است که به طور خودکار یک طرحواره را با استنباط انواع، دسته ها و محدوده ها از داده های آموزشی ایجاد می کند.
در اینجا گزیده ای از پروتوباف طرحواره آمده است:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
اجزای زیر از این طرح استفاده می کنند:
- اعتبارسنجی داده های TensorFlow
- تبدیل TensorFlow
در یک خط لوله TFX معمولی، اعتبارسنجی دادههای TensorFlow یک طرحواره ایجاد میکند که توسط سایر مؤلفهها مصرف میشود.
در حال توسعه با TFX
TFX یک پلت فرم قدرتمند برای هر مرحله از پروژه یادگیری ماشینی، از تحقیق، آزمایش و توسعه در ماشین محلی شما، از طریق استقرار، فراهم می کند. برای جلوگیری از تکرار کد و از بین بردن پتانسیل انحراف آموزش/خدمات ، اکیداً توصیه میشود که خط لوله TFX خود را هم برای آموزش مدل و هم برای استقرار مدلهای آموزشدیده پیادهسازی کنید و از مؤلفههای Transform استفاده کنید که از کتابخانه TensorFlow Transform هم برای آموزش و هم برای استنتاج استفاده میکنند. با انجام این کار، از کد پیش پردازش و تجزیه و تحلیل یکسانی به طور مداوم استفاده خواهید کرد، و از تفاوت بین داده های مورد استفاده برای آموزش و داده هایی که به مدل های آموزش دیده خود در تولید داده می شود، جلوگیری می کنید، و همچنین از یک بار نوشتن آن کد بهره مند می شوید.
کاوش، تجسم و پاکسازی داده ها
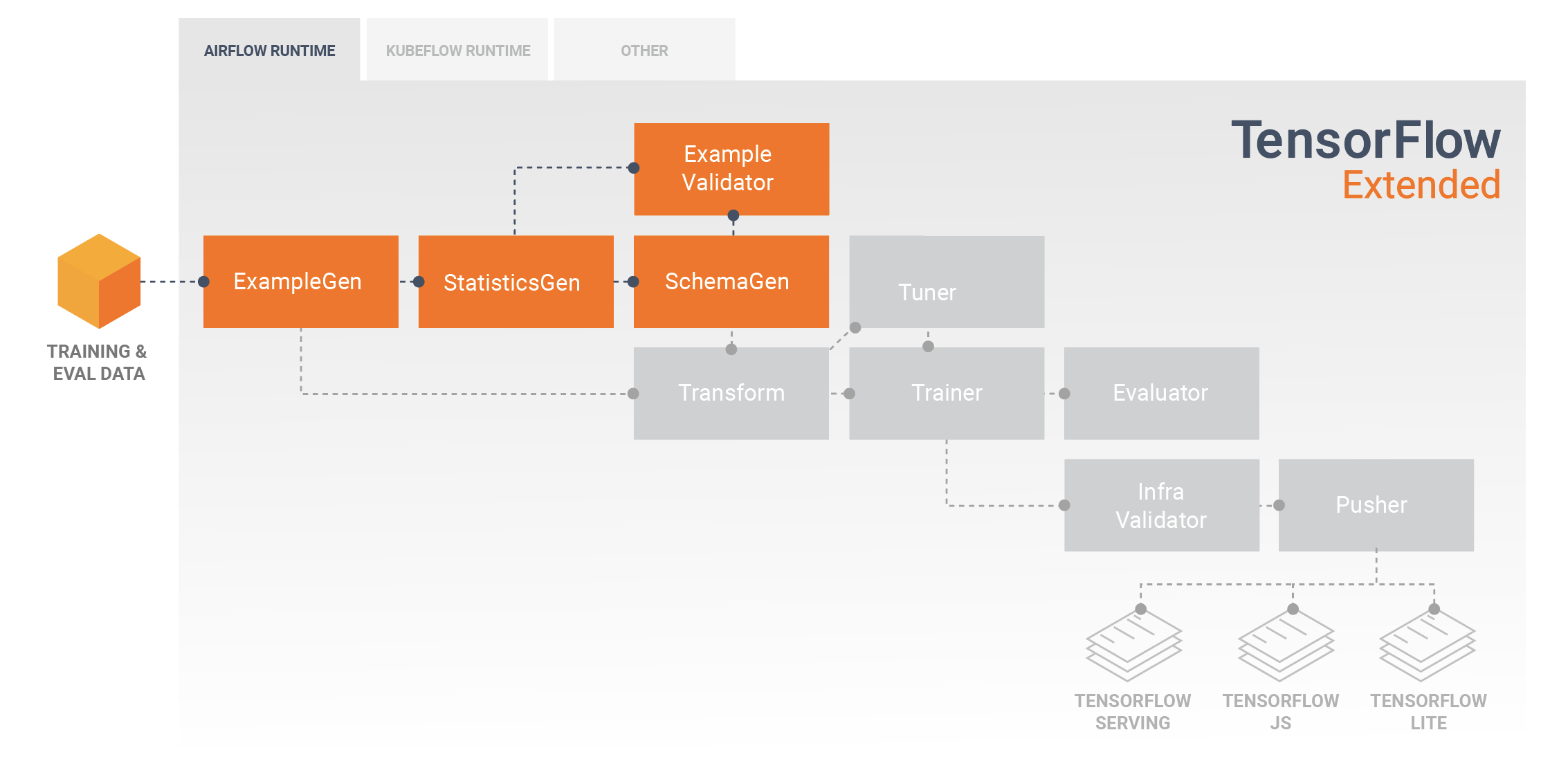
خطوط لوله TFX معمولا با یک جزء ExampleGen شروع می شود که داده های ورودی را می پذیرد و آنها را به عنوان tf.Examples قالب بندی می کند. اغلب این کار پس از تقسیم دادهها به مجموعه دادههای آموزشی و ارزیابی انجام میشود، به طوری که در واقع دو نسخه از مؤلفههای ExampleGen، یکی برای آموزش و ارزیابی وجود دارد. این معمولاً توسط یک مؤلفه StatisticsGen و یک مؤلفه SchemaGen دنبال می شود که داده های شما را بررسی می کند و یک طرح و آمار داده را استنباط می کند. طرح و آمار توسط یک جزء ExampleValidator مصرف می شود که به دنبال ناهنجاری ها، مقادیر از دست رفته و انواع داده های نادرست در داده های شما می شود. همه این مؤلفه ها از قابلیت های کتابخانه TensorFlow Data Validation استفاده می کنند.
اعتبارسنجی دادههای TensorFlow (TFDV) ابزاری ارزشمند در هنگام انجام کاوش اولیه، تجسم و تمیز کردن مجموعه داده شما است. TFDV داده های شما را بررسی می کند و انواع داده ها، دسته ها و محدوده ها را استنباط می کند، و سپس به طور خودکار به شناسایی ناهنجاری ها و مقادیر از دست رفته کمک می کند. همچنین ابزارهای تجسمی را فراهم می کند که می تواند به شما در بررسی و درک مجموعه داده خود کمک کند. پس از اتمام خط لوله شما می توانید متادیتا را از MLMD بخوانید و از ابزارهای تجسم TFDV در یک نوت بوک Jupyter برای تجزیه و تحلیل داده های خود استفاده کنید.
پس از آموزش و استقرار مدل اولیه، TFDV میتواند برای نظارت بر دادههای جدید از درخواستهای استنتاج به مدلهای مستقر شما، و جستجوی ناهنجاریها و/یا رانش استفاده شود. این به ویژه برای داده های سری زمانی مفید است که در طول زمان در نتیجه روند یا فصلی تغییر می کند، و می تواند به اطلاع رسانی در مورد مشکلات داده یا زمانی که مدل ها نیاز به آموزش مجدد بر روی داده های جدید دارند کمک کند.
تجسم داده ها
بعد از اینکه اولین اجرای داده های خود را از طریق بخشی از خط لوله خود که از TFDV استفاده می کند (معمولا StatisticsGen، SchemaGen و ExampleValidator) کامل کردید، می توانید نتایج را در یک نوت بوک سبک Jupyter تجسم کنید. برای اجراهای بیشتر، میتوانید این نتایج را با انجام تنظیمات مقایسه کنید، تا زمانی که دادههای شما برای مدل و برنامه شما بهینه شود.
شما ابتدا از ML Metadata (MLMD) پرس و جو می کنید تا نتایج اجرای این مؤلفه ها را بیابید و سپس از API پشتیبانی تصویری در TFDV برای ایجاد تجسم ها در نوت بوک خود استفاده کنید. این شامل tfdv.load_statistics() و tfdv.visualize_statistics() است با استفاده از این تجسم می توانید ویژگی های مجموعه داده خود را بهتر درک کنید و در صورت لزوم آن را اصلاح کنید.
توسعه و آموزش مدل ها
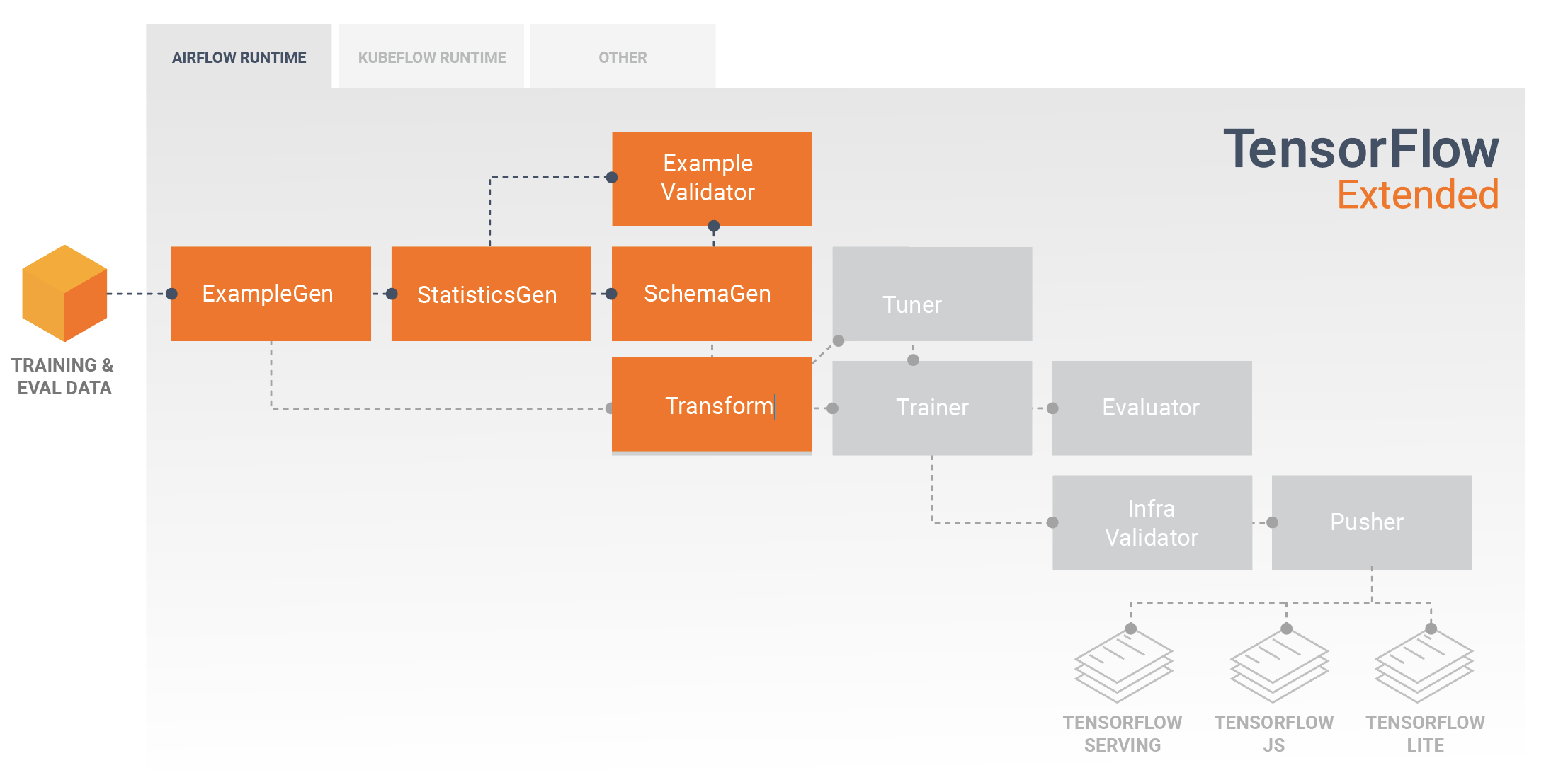
یک خط لوله TFX معمولی شامل یک جزء Transform است که مهندسی ویژگی را با استفاده از قابلیت های کتابخانه TensorFlow Transform (TFT) انجام می دهد. یک جزء Transform طرح ایجاد شده توسط یک جزء SchemaGen را مصرف می کند و از تبدیل داده ها برای ایجاد، ترکیب و تبدیل ویژگی هایی استفاده می کند که برای آموزش مدل شما استفاده می شود. پاکسازی مقادیر از دست رفته و تبدیل انواع نیز باید در مؤلفه Transform انجام شود، در صورتی که احتمال وجود این موارد در داده های ارسال شده برای درخواست استنتاج وجود داشته باشد. هنگام طراحی کد TensorFlow برای آموزش در TFX نکات مهمی وجود دارد .
نتیجه یک کامپوننت Transform یک SavedModel است که در کد مدلسازی شما در TensorFlow در طول یک جزء Trainer وارد و استفاده می شود. این SavedModel شامل تمام تبدیلهای مهندسی دادههایی است که در مؤلفه Transform ایجاد شدهاند، به طوری که تبدیلهای یکسان با استفاده از کد دقیقاً یکسان در طول آموزش و استنتاج انجام میشوند. با استفاده از کد مدل سازی، از جمله SavedModel از جزء Transform، می توانید داده های آموزش و ارزیابی خود را مصرف کرده و مدل خود را آموزش دهید.
هنگام کار با مدلهای مبتنی بر برآوردگر، آخرین بخش کد مدلسازی شما باید مدل شما را بهعنوان SavedModel و EvalSavedModel ذخیره کند. ذخیره بهعنوان EvalSavedModel تضمین میکند که معیارهای مورد استفاده در زمان آموزش نیز در طول ارزیابی در دسترس هستند (توجه داشته باشید که این برای مدلهای مبتنی بر keras لازم نیست). برای ذخیره EvalSavedModel باید کتابخانه TensorFlow Model Analysis (TFMA) را در جزء Trainer وارد کنید.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
یک جزء تیونر اختیاری را می توان قبل از Trainer اضافه کرد تا پارامترهای فراپارامترها (مثلاً تعداد لایه ها) را برای مدل تنظیم کند. با مدل داده شده و فضای جستجوی فراپارامترها، الگوریتم تنظیم بهترین هایپرپارامترها را بر اساس هدف پیدا می کند.
تجزیه و تحلیل و درک عملکرد مدل
پس از توسعه و آموزش مدل اولیه، تجزیه و تحلیل و درک واقعی عملکرد مدل مهم است. یک خط لوله معمولی TFX شامل یک جزء ارزیاب است که از قابلیت های کتابخانه تحلیل مدل TensorFlow (TFMA) استفاده می کند، که مجموعه ابزار قدرتی را برای این مرحله از توسعه فراهم می کند. یک مؤلفه Evaluator مدلی را که در بالا صادر کردید مصرف می کند و به شما امکان می دهد لیستی از tfma.SlicingSpec را مشخص کنید که می توانید هنگام تجسم و تجزیه و تحلیل عملکرد مدل خود از آن استفاده کنید. هر SlicingSpec بخشی از دادههای آموزشی شما را که میخواهید بررسی کنید، تعریف میکند، مانند دستههای خاص برای ویژگیهای طبقهبندی، یا محدودههای خاص برای ویژگیهای عددی.
به عنوان مثال، این برای تلاش برای درک عملکرد مدل شما برای بخشهای مختلف مشتریان، که میتواند بر اساس خریدهای سالانه، دادههای جغرافیایی، گروه سنی یا جنسیت تقسیمبندی شود، مهم است. این می تواند به ویژه برای مجموعه داده هایی با دنباله های بلند مهم باشد، جایی که عملکرد یک گروه غالب ممکن است عملکرد غیرقابل قبول برای گروه های مهم و در عین حال کوچکتر را پنهان کند. به عنوان مثال، مدل شما ممکن است برای کارمندان متوسط عملکرد خوبی داشته باشد، اما برای کارکنان اجرایی به طرز بدی شکست بخورد، و شاید دانستن این موضوع برای شما مهم باشد.
تحلیل و تجسم مدل
پس از اینکه اولین اجرای دادههای خود را از طریق آموزش مدل خود و اجرای مؤلفه Evaluator (که از TFMA استفاده میکند) بر روی نتایج آموزش کامل کردید، میتوانید نتایج را در یک نوت بوک سبک Jupyter تجسم کنید. برای اجراهای اضافی، میتوانید این نتایج را با انجام تنظیمات مقایسه کنید تا زمانی که نتایج شما برای مدل و کاربرد شما بهینه باشد.
شما ابتدا ML Metadata (MLMD) را پرس و جو می کنید تا نتایج اجرای این مؤلفه ها را پیدا کنید و سپس از API پشتیبانی تصویری در TFMA برای ایجاد تجسم ها در نوت بوک خود استفاده کنید. این شامل tfma.load_eval_results و tfma.view.render_slicing_metrics میشود. با استفاده از این تجسم، میتوانید ویژگیهای مدل خود را بهتر درک کنید و در صورت لزوم آن را اصلاح کنید.
اعتبارسنجی عملکرد مدل
به عنوان بخشی از تجزیه و تحلیل عملکرد یک مدل، ممکن است بخواهید عملکرد را در برابر یک خط پایه (مانند مدل در حال ارائه فعلی) اعتبارسنجی کنید. اعتبارسنجی مدل با ارسال هر دو مدل کاندید و پایه به مؤلفه Evaluator انجام می شود. ارزیاب معیارها (به عنوان مثال AUC، ضرر) را برای هر دو نامزد و خط مبنا همراه با مجموعه ای از معیارهای متفاوت محاسبه می کند. سپس ممکن است آستانه ها اعمال شوند و برای دریچه ای که مدل های شما را به سمت تولید سوق می دهد، استفاده شوند.
تأیید اینکه یک مدل می تواند ارائه شود
قبل از استقرار مدل آموزش دیده، ممکن است بخواهید اعتبارسنجی کنید که آیا مدل واقعاً در زیرساخت سرویس دهی قابل استفاده است یا خیر. این امر به ویژه در محیط های تولید مهم است تا اطمینان حاصل شود که مدل جدید منتشر شده مانع از ارائه پیش بینی های سیستم نمی شود. کامپوننت InfraValidator مدل شما را در یک محیط sandbox قرار می دهد و به صورت اختیاری درخواست های واقعی را ارسال می کند تا بررسی کند که مدل شما درست کار می کند.
اهداف استقرار
هنگامی که مدلی را توسعه دادید و آموزش دادید که از آن راضی هستید، اکنون زمان آن رسیده است که آن را در یک یا چند هدف استقرار، جایی که درخواست های استنتاج دریافت می کند، مستقر کنید. TFX از استقرار در سه کلاس از اهداف استقرار پشتیبانی می کند. مدلهای آموزشدیدهشده که بهعنوان SavedModels صادر شدهاند، میتوانند برای هر یک یا همه این اهداف استقرار مستقر شوند.
استنتاج: سرویس دهی تنسورفلو
TensorFlow Serving (TFS) یک سیستم خدمت رسانی انعطاف پذیر و با کارایی بالا برای مدل های یادگیری ماشین است که برای محیط های تولید طراحی شده است. این یک SavedModel را مصرف می کند و درخواست های استنتاج را از طریق رابط های REST یا gRPC می پذیرد. این به عنوان مجموعه ای از فرآیندها بر روی یک یا چند سرور شبکه اجرا می شود که از یکی از چندین معماری پیشرفته برای مدیریت همگام سازی و محاسبات توزیع شده استفاده می کند. برای اطلاعات بیشتر در مورد توسعه و استقرار راه حل های TFS به مستندات TFS مراجعه کنید.
در یک خط لوله معمولی، SavedModel که در یک جزء Trainer آموزش دیده است، ابتدا در یک جزء InfraValidator به صورت زیر اعتبارسنجی می شود. InfraValidator یک سرور مدل TFS قناری راه اندازی می کند تا در واقع به SavedModel خدمت کند. اگر اعتبارسنجی انجام شده باشد، یک جزء Pusher در نهایت SavedModel را در زیرساخت TFS شما مستقر می کند. این شامل مدیریت چندین نسخه و به روز رسانی مدل می شود.
استنباط در برنامه های بومی موبایل و اینترنت اشیا: TensorFlow Lite
TensorFlow Lite مجموعه ای از ابزارها است که به توسعه دهندگان کمک می کند تا از مدل های TensorFlow آموزش دیده خود در برنامه های تلفن همراه و اینترنت اشیا بومی استفاده کنند. این برنامه همان SavedModels را به عنوان سرویس TensorFlow مصرف میکند و بهینهسازیهایی مانند کوانتیزاسیون و هرس را برای بهینهسازی اندازه و عملکرد مدلهای بهدستآمده برای چالشهای اجرا در دستگاههای تلفن همراه و اینترنت اشیا اعمال میکند. برای اطلاعات بیشتر در مورد استفاده از TensorFlow Lite به مستندات TensorFlow Lite مراجعه کنید.
استنتاج در جاوا اسکریپت: TensorFlow JS
TensorFlow JS یک کتابخانه جاوا اسکریپت برای آموزش و استقرار مدل های ML در مرورگر و در Node.js است. این برنامه همان SavedModels را به عنوان سرویس TensorFlow و TensorFlow Lite مصرف می کند و آنها را به قالب وب TensorFlow.js تبدیل می کند. برای جزئیات بیشتر در مورد استفاده از TensorFlow JS به مستندات TensorFlow JS مراجعه کنید.
ایجاد یک خط لوله TFX با جریان هوا
کارگاه جریان هوا را برای جزئیات بررسی کنید
ایجاد خط لوله TFX با Kubeflow
برپایی
Kubeflow برای اجرای خطوط لوله در مقیاس به یک خوشه Kubernetes نیاز دارد. راهنمای استقرار Kubeflow را ببینید که گزینههای استقرار خوشه Kubeflow را راهنمایی میکند.
خط لوله TFX را پیکربندی و اجرا کنید
لطفاً برای اجرای خط لوله نمونه TFX در Kubeflow، آموزش TFX on Cloud AI Platform Pipeline را دنبال کنید. مؤلفههای TFX برای ترکیب خط لوله Kubeflow محفظهسازی شدهاند و نمونه توانایی پیکربندی خط لوله را برای خواندن مجموعه دادههای عمومی بزرگ و اجرای مراحل آموزش و پردازش داده در مقیاس در فضای ابری را نشان میدهد.
رابط خط فرمان برای اقدامات خط لوله
TFX یک CLI یکپارچه ارائه می دهد که به انجام طیف گسترده ای از اقدامات خط لوله مانند ایجاد، به روز رسانی، اجرا، فهرست کردن و حذف خطوط لوله در ارکسترهای مختلف از جمله Apache Airflow، Apache Beam و Kubeflow کمک می کند. برای جزئیات، لطفا این دستورالعمل ها را دنبال کنید.