
Introducción
TFX es una plataforma de aprendizaje automático (ML) a escala de producción de Google basada en TensorFlow. Proporciona un marco de configuración y bibliotecas compartidas para integrar componentes comunes necesarios para definir, iniciar y monitorear su sistema de aprendizaje automático.
TFX 1.0
Nos complace anunciar la disponibilidad de TFX 1.0.0 . Esta es la versión post-beta inicial de TFX, que proporciona artefactos y API públicas estables. Puede estar seguro de que sus futuras canalizaciones TFX seguirán funcionando después de una actualización dentro del alcance de compatibilidad definido en este RFC .
Instalación

![]()
pip install tfx
Paquetes Nocturnos
TFX también aloja paquetes nocturnos en https://pypi-nightly.tensorflow.org en Google Cloud. Para instalar el último paquete nocturno, utilice el siguiente comando:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Esto instalará los paquetes nocturnos para las principales dependencias de TFX, como TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
Acerca de TFX
TFX es una plataforma para crear y administrar flujos de trabajo de ML en un entorno de producción. TFX proporciona lo siguiente:
Un kit de herramientas para crear canalizaciones de aprendizaje automático. Las canalizaciones de TFX le permiten orquestar su flujo de trabajo de ML en varias plataformas, como: Apache Airflow, Apache Beam y Kubeflow Pipelines.
Un conjunto de componentes estándar que puede usar como parte de una canalización o como parte de su script de capacitación de ML. Los componentes estándar de TFX brindan una funcionalidad comprobada para ayudarlo a comenzar a crear un proceso de ML fácilmente.
Obtenga más información sobre los componentes estándar de TFX .
Bibliotecas que proporcionan la funcionalidad base para muchos de los componentes estándar. Puede utilizar las bibliotecas TFX para agregar esta funcionalidad a sus propios componentes personalizados o utilizarlos por separado.
TFX es un kit de herramientas de aprendizaje automático a escala de producción de Google basado en TensorFlow. Proporciona un marco de configuración y bibliotecas compartidas para integrar componentes comunes necesarios para definir, iniciar y monitorear su sistema de aprendizaje automático.
Componentes estándar TFX
Una canalización TFX es una secuencia de componentes que implementa una canalización ML que está diseñada específicamente para tareas de aprendizaje automático escalables y de alto rendimiento. Eso incluye el modelado, la capacitación, la inferencia de servicio y la administración de implementaciones para objetivos en línea, móviles nativos y JavaScript.
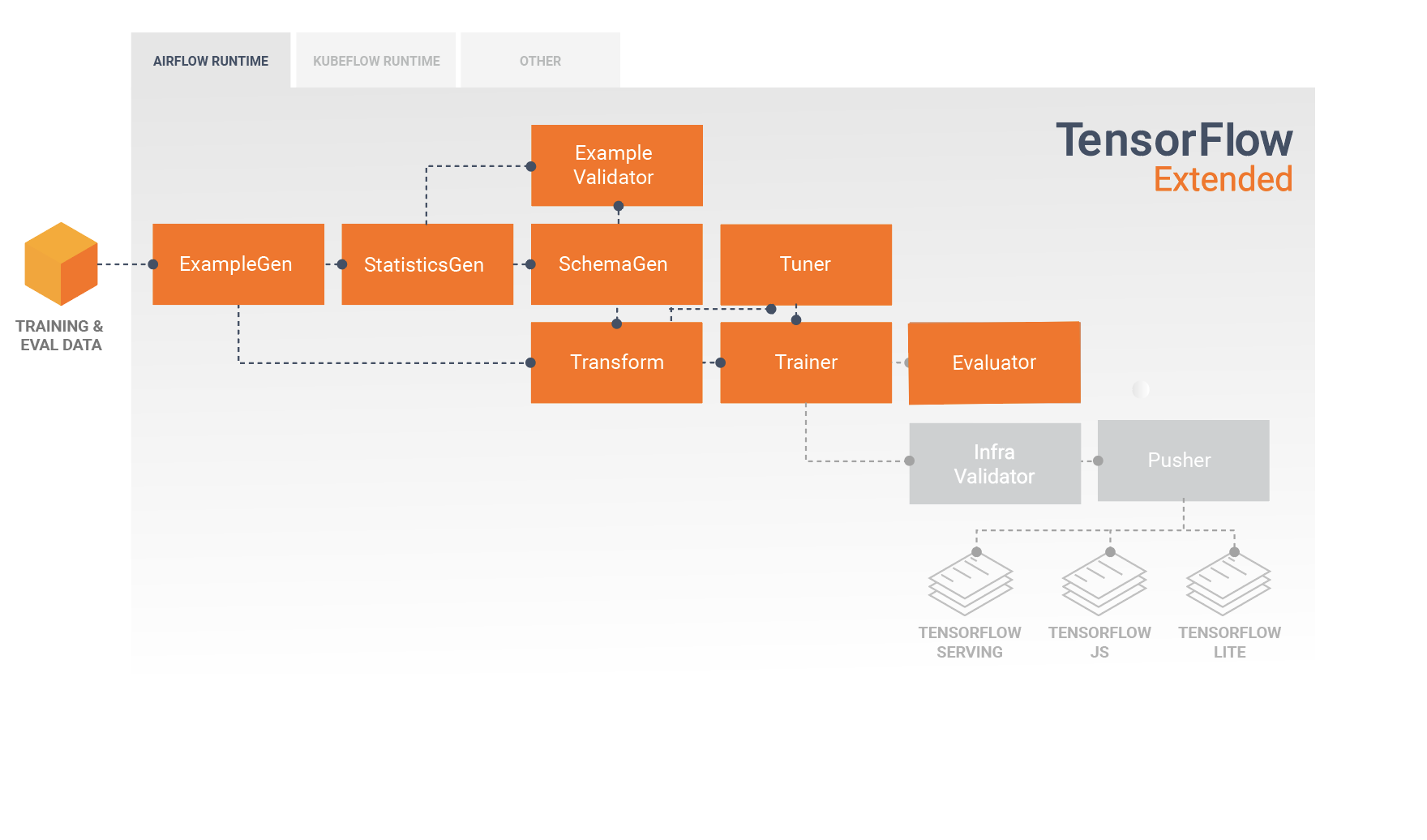
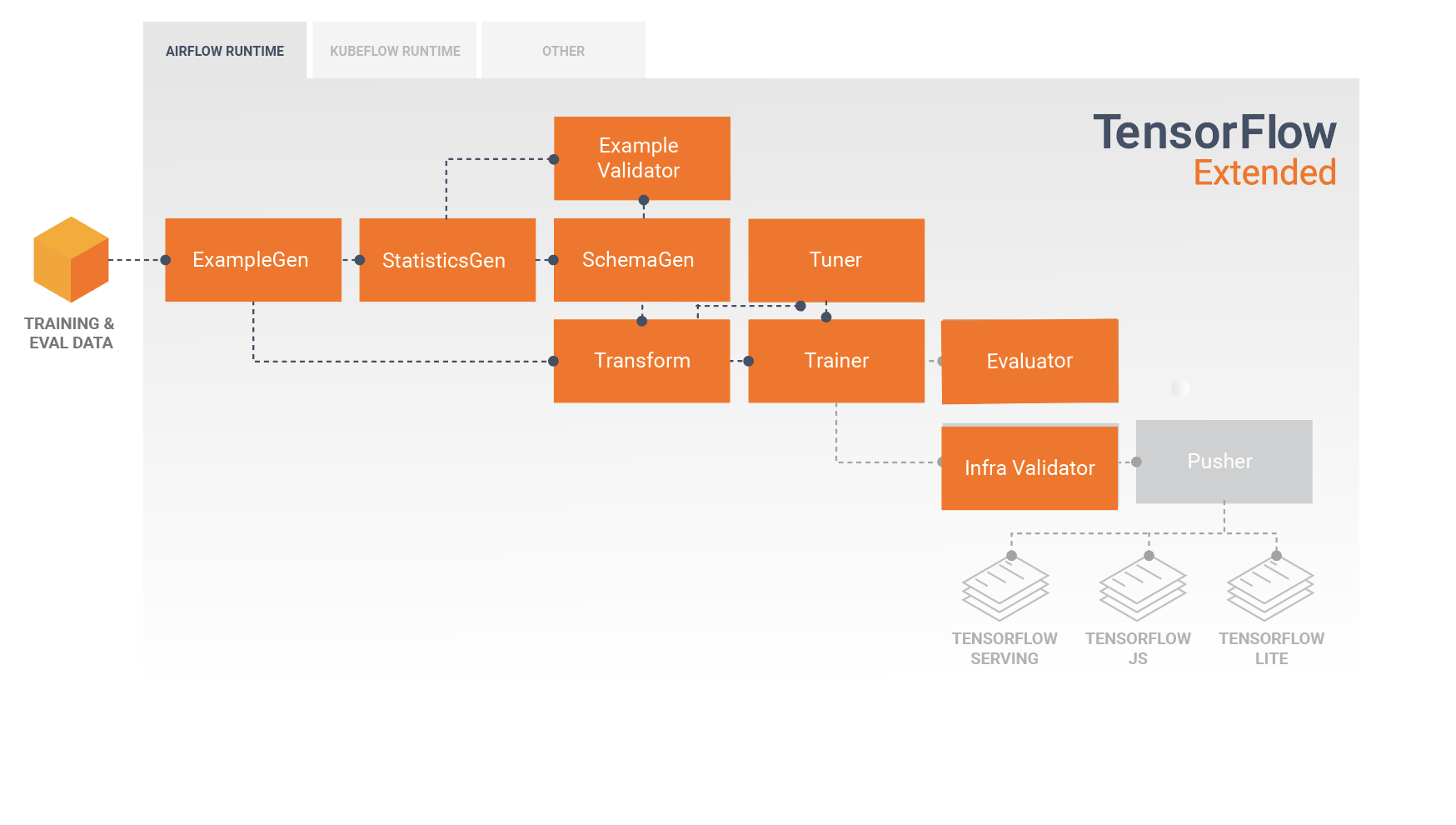
Una canalización TFX normalmente incluye los siguientes componentes:
ExampleGen es el componente de entrada inicial de una canalización que ingiere y, opcionalmente, divide el conjunto de datos de entrada.
StatisticsGen calcula estadísticas para el conjunto de datos.
SchemaGen examina las estadísticas y crea un esquema de datos.
ExampleValidator busca anomalías y valores faltantes en el conjunto de datos.
Transform realiza la ingeniería de características en el conjunto de datos.
El entrenador entrena al modelo.
Tuner ajusta los hiperparámetros del modelo.
Evaluator realiza un análisis profundo de los resultados del entrenamiento y lo ayuda a validar sus modelos exportados, asegurándose de que sean "lo suficientemente buenos" para pasar a producción.
InfraValidator verifica que el modelo realmente se pueda servir desde la infraestructura y evita que se envíe un modelo incorrecto.
Pusher implementa el modelo en una infraestructura de servicio.
BulkInferrer realiza el procesamiento por lotes en un modelo con solicitudes de inferencia sin etiquetar.
Este diagrama ilustra el flujo de datos entre estos componentes:
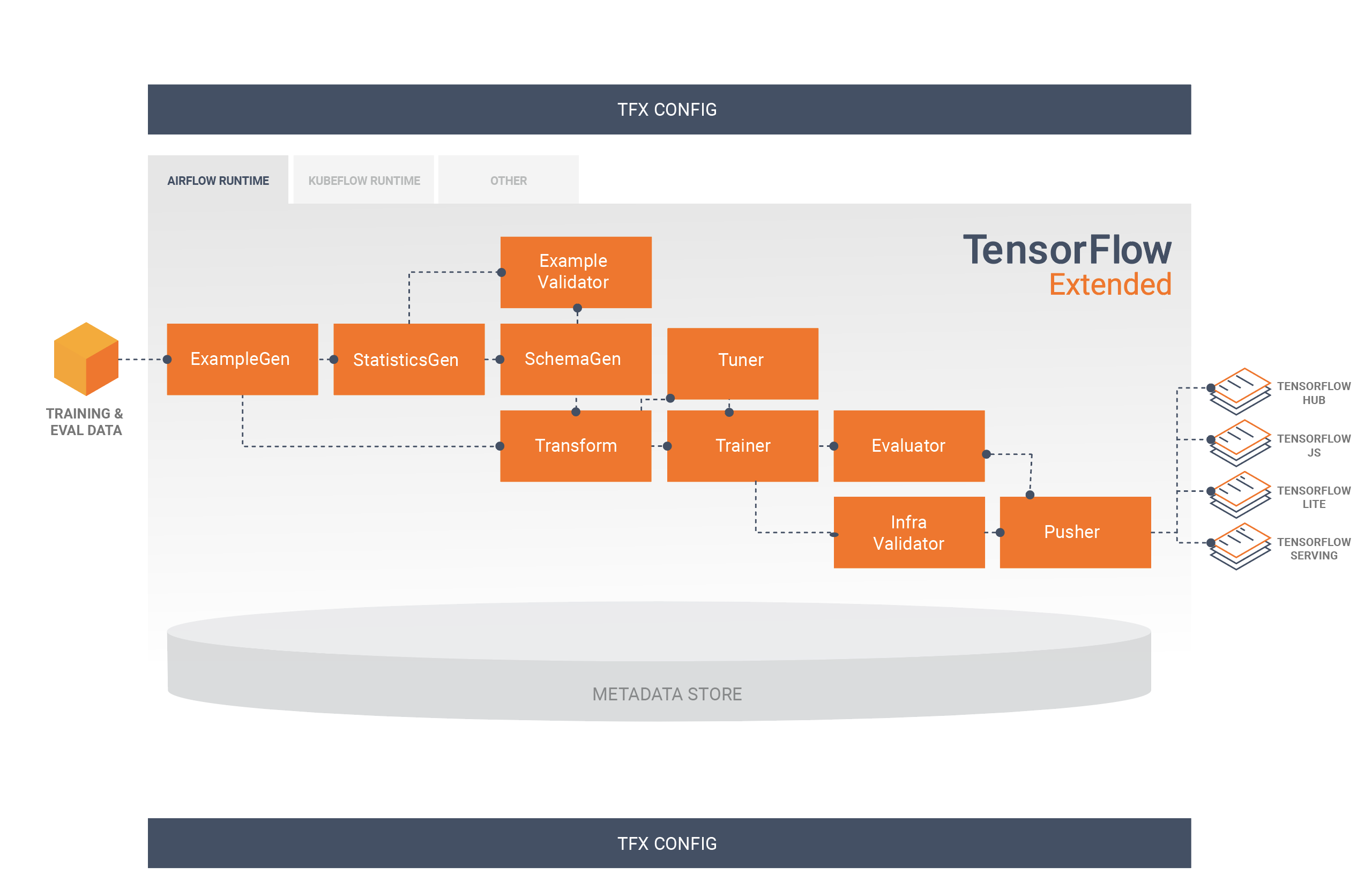
Bibliotecas TFX
TFX incluye bibliotecas y componentes de canalización. Este diagrama ilustra las relaciones entre las bibliotecas TFX y los componentes de canalización:
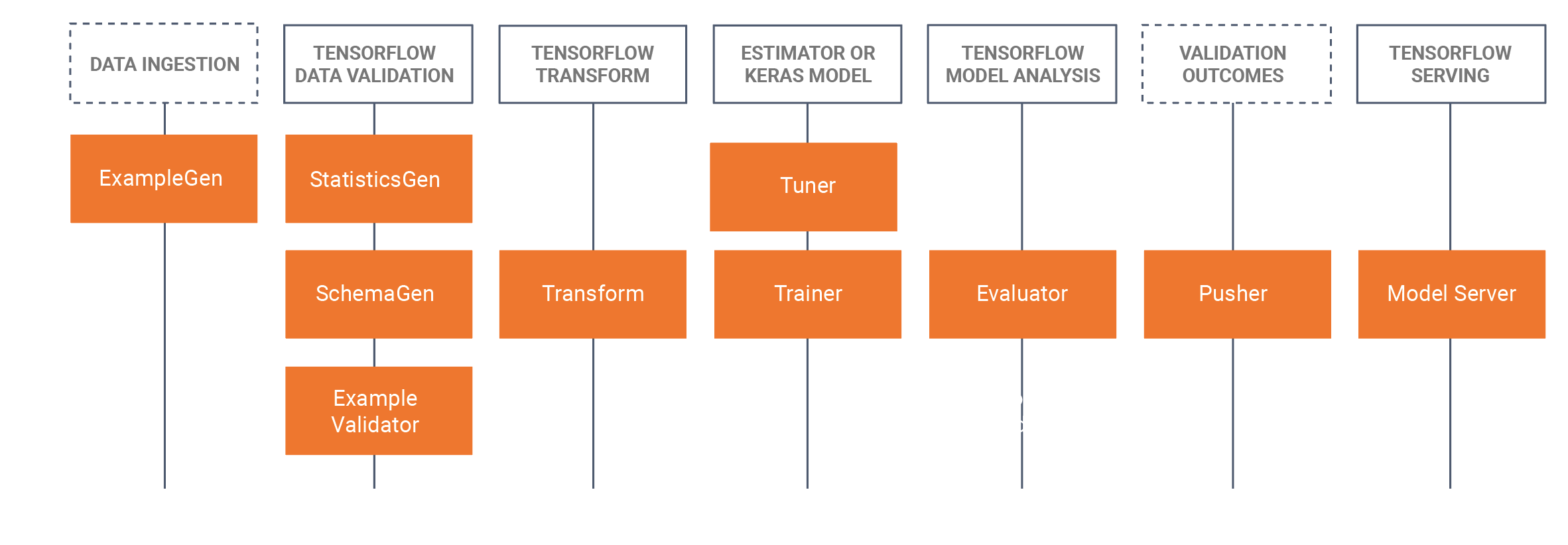
TFX proporciona varios paquetes de Python que son las bibliotecas que se utilizan para crear componentes de canalización. Utilizará estas bibliotecas para crear los componentes de sus canalizaciones para que su código pueda centrarse en los aspectos únicos de su canalización.
Las bibliotecas TFX incluyen:
TensorFlow Data Validation (TFDV) es una biblioteca para analizar y validar datos de aprendizaje automático. Está diseñado para ser altamente escalable y funcionar bien con TensorFlow y TFX. TFDV incluye:
- Cálculo escalable de estadísticas de resumen de datos de entrenamiento y prueba.
- Integración con un visor para distribuciones de datos y estadísticas, así como comparación facetada de pares de conjuntos de datos (Facets).
- Generación automatizada de esquemas de datos para describir expectativas sobre datos como valores requeridos, rangos y vocabularios.
- Un visor de esquemas para ayudarlo a inspeccionar el esquema.
- Detección de anomalías para identificar anomalías, como funciones faltantes, valores fuera de rango o tipos de funciones incorrectos, por nombrar algunas.
- Un visor de anomalías para que puedas ver qué características tienen anomalías y aprender más para corregirlas.
TensorFlow Transform (TFT) es una biblioteca para preprocesar datos con TensorFlow. TensorFlow Transform es útil para datos que requieren un pase completo, como:
- Normalice un valor de entrada por media y desviación estándar.
- Convierta cadenas en enteros generando un vocabulario sobre todos los valores de entrada.
- Convierta flotantes en números enteros asignándolos a depósitos en función de la distribución de datos observada.
TensorFlow se usa para entrenar modelos con TFX. Ingiere datos de entrenamiento y código de modelado y crea un resultado de modelo guardado. También integra una canalización de ingeniería de características creada por TensorFlow Transform para el preprocesamiento de datos de entrada.
KerasTuner se utiliza para ajustar hiperparámetros para el modelo.
TensorFlow Model Analysis (TFMA) es una biblioteca para evaluar modelos de TensorFlow. Se utiliza junto con TensorFlow para crear un EvalSavedModel, que se convierte en la base de su análisis. Permite a los usuarios evaluar sus modelos sobre grandes cantidades de datos de forma distribuida, utilizando las mismas métricas definidas en su entrenador. Estas métricas se pueden calcular en diferentes segmentos de datos y visualizarse en cuadernos de Jupyter.
TensorFlow Metadata (TFMD) proporciona representaciones estándar para metadatos que son útiles cuando se entrenan modelos de aprendizaje automático con TensorFlow. Los metadatos se pueden producir a mano o automáticamente durante el análisis de datos de entrada y se pueden consumir para la validación, exploración y transformación de datos. Los formatos de serialización de metadatos incluyen:
- Un esquema que describe datos tabulares (p. ej., tf.Examples).
- Una colección de estadísticas resumidas sobre dichos conjuntos de datos.
ML Metadata (MLMD) es una biblioteca para registrar y recuperar metadatos asociados con los flujos de trabajo de científicos de datos y desarrolladores de ML. La mayoría de las veces, los metadatos usan representaciones TFMD. MLMD administra la persistencia mediante SQL-Lite , MySQL y otros almacenes de datos similares.
Tecnologías de apoyo
Requerido
- Apache Beam es un modelo unificado de código abierto para definir canalizaciones de procesamiento paralelo de datos por lotes y de transmisión. TFX usa Apache Beam para implementar canalizaciones paralelas de datos. Luego, la canalización se ejecuta mediante uno de los back-end de procesamiento distribuido admitidos por Beam, que incluyen Apache Flink, Apache Spark, Google Cloud Dataflow y otros.
Opcional
Los orquestadores como Apache Airflow y Kubeflow facilitan la configuración, el funcionamiento, la supervisión y el mantenimiento de una canalización de aprendizaje automático.
Apache Airflow es una plataforma para crear, programar y monitorear flujos de trabajo mediante programación. TFX usa Airflow para crear flujos de trabajo como gráficos acíclicos dirigidos (DAG) de tareas. El programador de Airflow ejecuta tareas en una matriz de trabajadores mientras sigue las dependencias especificadas. Las ricas utilidades de la línea de comandos facilitan la realización de cirugías complejas en DAG. La interfaz de usuario enriquecida facilita la visualización de canalizaciones que se ejecutan en producción, supervisa el progreso y soluciona problemas cuando es necesario. Cuando los flujos de trabajo se definen como código, se vuelven más mantenibles, versionables, comprobables y colaborativos.
Kubeflow se dedica a hacer que las implementaciones de flujos de trabajo de aprendizaje automático (ML) en Kubernetes sean simples, portátiles y escalables. El objetivo de Kubeflow no es recrear otros servicios, sino proporcionar una forma sencilla de implementar los mejores sistemas de código abierto para ML en diversas infraestructuras. Kubeflow Pipelines permite la composición y ejecución de flujos de trabajo reproducibles en Kubeflow, integrados con experimentación y experiencias basadas en cuadernos. Los servicios de Kubeflow Pipelines en Kubernetes incluyen el almacén de metadatos alojado, el motor de orquestación basado en contenedores, el servidor portátil y la interfaz de usuario para ayudar a los usuarios a desarrollar, ejecutar y administrar canalizaciones de aprendizaje automático complejas a escala. El SDK de Kubeflow Pipelines permite la creación y el uso compartido de componentes y la composición de canalizaciones mediante programación.
Portabilidad e Interoperabilidad
TFX está diseñado para ser portátil a múltiples entornos y marcos de orquestación, incluidos Apache Airflow , Apache Beam y Kubeflow . También es portátil para diferentes plataformas informáticas, incluidas plataformas en las instalaciones y en la nube, como Google Cloud Platform (GCP) . En particular, TFX interactúa con varios servicios de GCP administrados, como Cloud AI Platform for Training and Prediction , y Cloud Dataflow para el procesamiento de datos distribuidos para varios otros aspectos del ciclo de vida de ML.
Modelo frente a modelo guardado
Modelo
Un modelo es el resultado del proceso de entrenamiento. Es el registro serializado de los pesos que se han aprendido durante el proceso de entrenamiento. Estos pesos se pueden usar posteriormente para calcular predicciones para nuevos ejemplos de entrada. Para TFX y TensorFlow, 'modelo' se refiere a los puntos de control que contienen los pesos aprendidos hasta ese momento.
Tenga en cuenta que 'modelo' también puede referirse a la definición del gráfico de cálculo de TensorFlow (es decir, un archivo de Python) que expresa cómo se calculará una predicción. Los dos sentidos se pueden usar indistintamente según el contexto.
Modelo guardado
- Qué es un modelo guardado : una serialización universal, independiente del idioma, hermética y recuperable de un modelo de TensorFlow.
- Por qué es importante : permite que los sistemas de nivel superior produzcan, transformen y consuman modelos de TensorFlow utilizando una sola abstracción.
El modelo guardado es el formato de serialización recomendado para entregar un modelo de TensorFlow en producción o exportar un modelo entrenado para una aplicación móvil nativa o de JavaScript. Por ejemplo, para convertir un modelo en un servicio REST para hacer predicciones, puede serializar el modelo como un modelo guardado y servirlo con TensorFlow Serving. Consulte Servir un modelo de TensorFlow para obtener más información.
Esquema
Algunos componentes TFX usan una descripción de sus datos de entrada llamada esquema . El esquema es una instancia de schema.proto . Los esquemas son un tipo de búfer de protocolo , más conocido como "protobuf". El esquema puede especificar tipos de datos para valores de características, si una característica debe estar presente en todos los ejemplos, rangos de valores permitidos y otras propiedades. Uno de los beneficios de usar TensorFlow Data Validation (TFDV) es que generará automáticamente un esquema al inferir tipos, categorías y rangos de los datos de entrenamiento.
Aquí hay un extracto de un protobuf de esquema:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Los siguientes componentes utilizan el esquema:
- Validación de datos de TensorFlow
- Transformación TensorFlow
En una canalización típica de TFX, TensorFlow Data Validation genera un esquema, que es consumido por los demás componentes.
Desarrollando con TFX
TFX proporciona una plataforma poderosa para cada fase de un proyecto de aprendizaje automático, desde la investigación, la experimentación y el desarrollo en su máquina local hasta la implementación. A fin de evitar la duplicación de código y eliminar la posibilidad de que se desvíe el entrenamiento/servicio , se recomienda enfáticamente implementar su canalización TFX tanto para el entrenamiento de modelos como para el despliegue de modelos entrenados, y usar componentes Transform que aprovechen la biblioteca TensorFlow Transform para entrenamiento e inferencia. Al hacerlo, utilizará el mismo código de preprocesamiento y análisis de forma consistente y evitará diferencias entre los datos utilizados para el entrenamiento y los datos que se alimentan a sus modelos entrenados en producción, además de beneficiarse de escribir ese código una vez.
Exploración, visualización y limpieza de datos
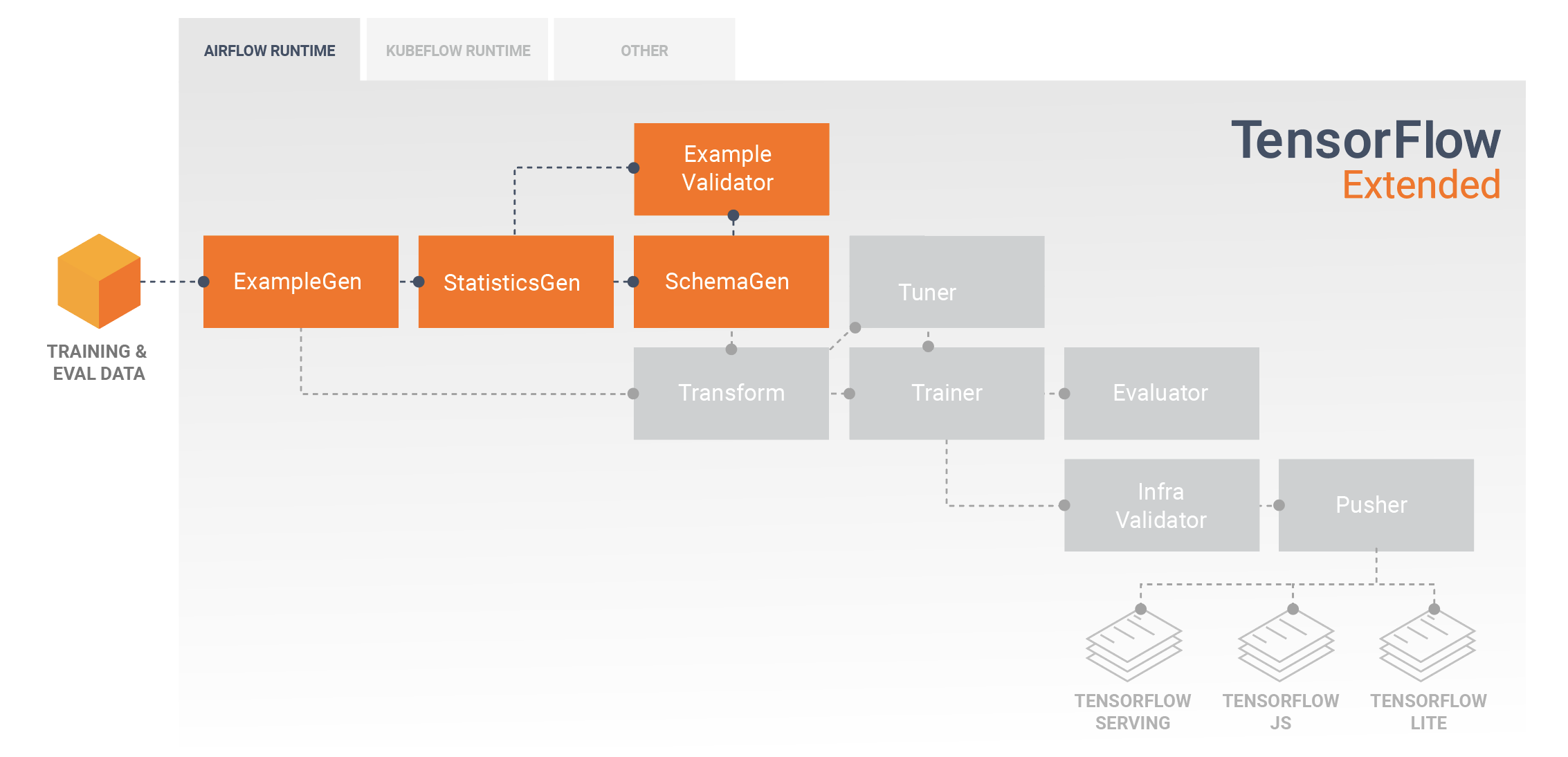
Las canalizaciones TFX generalmente comienzan con un componente ExampleGen , que acepta datos de entrada y los formatea como tf.Examples. A menudo, esto se hace después de que los datos se hayan dividido en conjuntos de datos de entrenamiento y evaluación para que en realidad haya dos copias de los componentes de ExampleGen, una para entrenamiento y otra para evaluación. Esto suele ir seguido de un componente StatisticsGen y un componente SchemaGen , que examinarán sus datos e inferirán un esquema de datos y estadísticas. El esquema y las estadísticas serán consumidos por un componente ExampleValidator , que buscará anomalías, valores faltantes y tipos de datos incorrectos en sus datos. Todos estos componentes aprovechan las capacidades de la biblioteca de validación de datos de TensorFlow .
TensorFlow Data Validation (TFDV) es una herramienta valiosa al realizar la exploración, visualización y limpieza iniciales de su conjunto de datos. TFDV examina sus datos e infiere los tipos de datos, categorías y rangos, y luego ayuda automáticamente a identificar anomalías y valores faltantes. También proporciona herramientas de visualización que pueden ayudarlo a examinar y comprender su conjunto de datos. Una vez completada la canalización, puede leer los metadatos de MLMD y usar las herramientas de visualización de TFDV en un cuaderno Jupyter para analizar sus datos.
Después de la capacitación y la implementación iniciales de su modelo, TFDV se puede usar para monitorear nuevos datos de solicitudes de inferencia a sus modelos implementados, y buscar anomalías o desviaciones. Esto es especialmente útil para los datos de series temporales que cambian con el tiempo como resultado de la tendencia o la estacionalidad, y puede ayudar a informar cuando hay problemas con los datos o cuando es necesario volver a entrenar los modelos con datos nuevos.
Visualización de datos
Una vez que haya completado su primera ejecución de sus datos a través de la sección de su canalización que usa TFDV (generalmente StatisticsGen, SchemaGen y ExampleValidator), puede visualizar los resultados en un cuaderno de estilo Jupyter. Para ejecuciones adicionales, puede comparar estos resultados a medida que realiza ajustes, hasta que sus datos sean óptimos para su modelo y aplicación.
Primero consultará los metadatos de ML (MLMD) para ubicar los resultados de estas ejecuciones de estos componentes y luego usará la API de soporte de visualización en TFDV para crear las visualizaciones en su cuaderno. Esto incluye tfdv.load_statistics() y tfdv.visualize_statistics() Con esta visualización, puede comprender mejor las características de su conjunto de datos y, si es necesario, modificarlo según sea necesario.
Modelos de desarrollo y entrenamiento
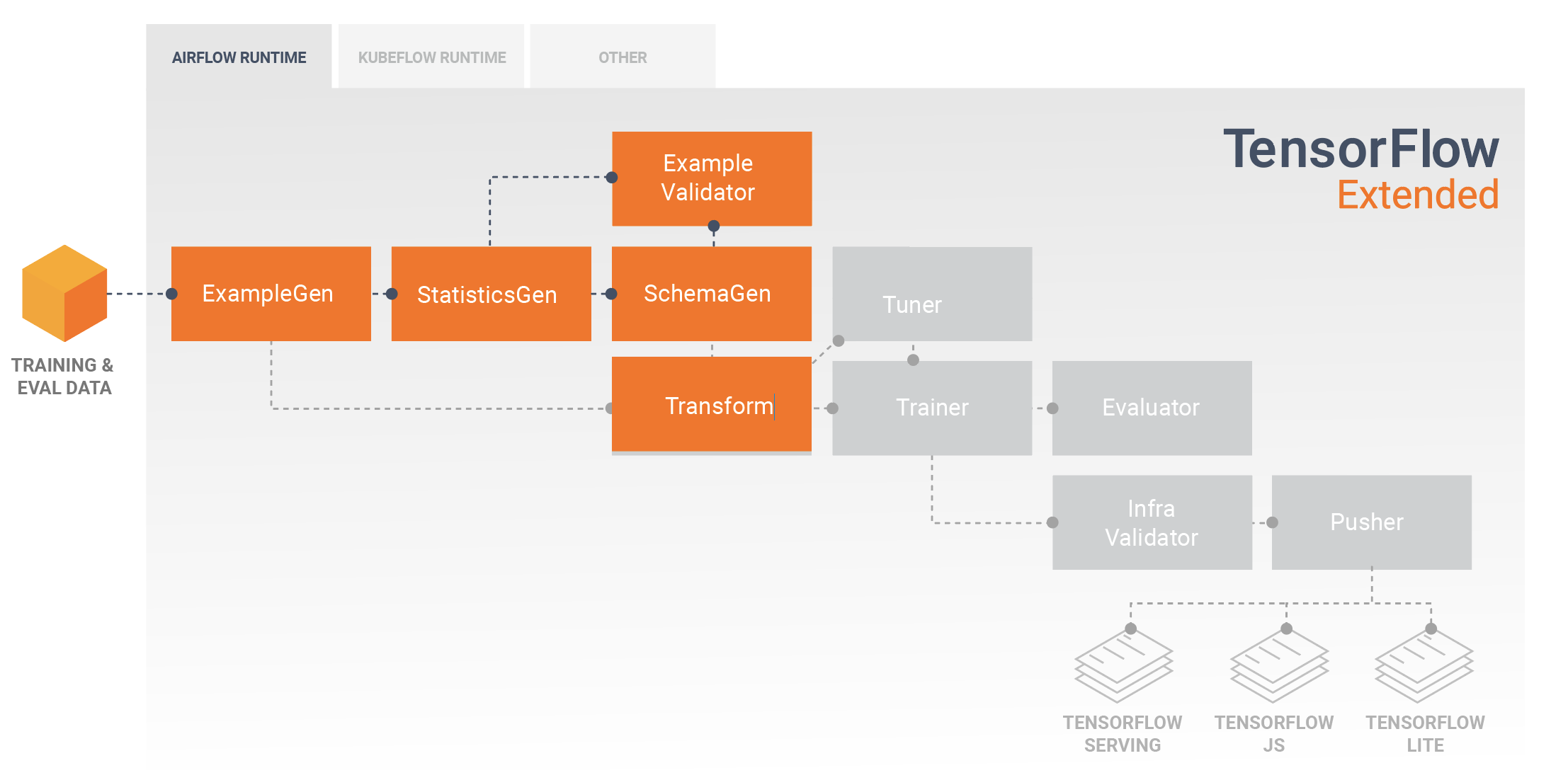
Una canalización típica de TFX incluirá un componente Transform , que realizará la ingeniería de funciones aprovechando las capacidades de la biblioteca TensorFlow Transform (TFT) . Un componente Transform consume el esquema creado por un componente SchemaGen y aplica transformaciones de datos para crear, combinar y transformar las funciones que se usarán para entrenar su modelo. La limpieza de los valores faltantes y la conversión de tipos también deben realizarse en el componente Transformar si alguna vez existe la posibilidad de que estos también estén presentes en los datos enviados para las solicitudes de inferencia. Hay algunas consideraciones importantes al diseñar el código de TensorFlow para el entrenamiento en TFX.

El resultado de un componente Transform es un modelo guardado que se importará y utilizará en su código de modelado en TensorFlow, durante un componente Trainer . Este modelo guardado incluye todas las transformaciones de ingeniería de datos que se crearon en el componente Transform, de modo que las transformaciones idénticas se realicen usando exactamente el mismo código durante el entrenamiento y la inferencia. Con el código de modelado, incluido el modelo guardado del componente Transform, puede consumir sus datos de entrenamiento y evaluación y entrenar su modelo.
Cuando trabaje con modelos basados en Estimator, la última sección de su código de modelado debe guardar su modelo como un modelo guardado y un modelo guardado de evaluación. Guardar como EvalSavedModel garantiza que las métricas utilizadas en el momento del entrenamiento también estén disponibles durante la evaluación (tenga en cuenta que esto no es necesario para los modelos basados en keras). Guardar un EvalSavedModel requiere que importe la biblioteca TensorFlow Model Analysis (TFMA) en su componente Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Se puede agregar un componente Tuner opcional antes de Trainer para ajustar los hiperparámetros (p. ej., número de capas) para el modelo. Con el modelo dado y el espacio de búsqueda de hiperparámetros, el algoritmo de ajuste encontrará los mejores hiperparámetros según el objetivo.
Análisis y comprensión del rendimiento del modelo
Después del desarrollo y entrenamiento inicial del modelo, es importante analizar y comprender realmente el rendimiento de su modelo. Una canalización TFX típica incluirá un componente Evaluator , que aprovecha las capacidades de la biblioteca TensorFlow Model Analysis (TFMA) , que proporciona un conjunto de herramientas potentes para esta fase de desarrollo. Un componente Evaluator consume el modelo que exportó anteriormente y le permite especificar una lista de tfma.SlicingSpec que puede usar al visualizar y analizar el rendimiento de su modelo. Cada SlicingSpec define una porción de sus datos de entrenamiento que desea examinar, como categorías particulares para características categóricas o rangos particulares para características numéricas.
Por ejemplo, esto sería importante para tratar de comprender el rendimiento de su modelo para diferentes segmentos de sus clientes, que podrían segmentarse por compras anuales, datos geográficos, grupo de edad o género. Esto puede ser especialmente importante para conjuntos de datos con colas largas, donde el desempeño de un grupo dominante puede enmascarar un desempeño inaceptable para grupos importantes pero más pequeños. Por ejemplo, su modelo puede funcionar bien para los empleados promedio pero fallar miserablemente para el personal ejecutivo, y puede ser importante que lo sepa.
Análisis y visualización de modelos
Una vez que haya completado su primera ejecución de sus datos a través de la capacitación de su modelo y la ejecución del componente Evaluator (que aprovecha TFMA ) en los resultados de la capacitación, puede visualizar los resultados en un cuaderno de estilo Jupyter. Para ejecuciones adicionales, puede comparar estos resultados a medida que realiza ajustes, hasta que sus resultados sean óptimos para su modelo y aplicación.
Primero consultará los metadatos de ML (MLMD) para ubicar los resultados de estas ejecuciones de estos componentes y luego usará la API de soporte de visualización en TFMA para crear las visualizaciones en su cuaderno. Esto incluye tfma.load_eval_results y tfma.view.render_slicing_metrics Con esta visualización, puede comprender mejor las características de su modelo y, si es necesario, modificarlo según sea necesario.
Validación del rendimiento del modelo
Como parte del análisis del rendimiento de un modelo, es posible que desee validar el rendimiento con respecto a una línea de base (como el modelo de servicio actual). La validación del modelo se realiza pasando un modelo candidato y de referencia al componente Evaluador . El Evaluador calcula las métricas (p. ej., AUC, pérdida) tanto para el candidato como para la línea de base junto con un conjunto correspondiente de métricas de diferencias. Luego, se pueden aplicar umbrales y utilizarlos para empujar sus modelos a producción.
Validación de que se puede servir un modelo
Antes de implementar el modelo entrenado, es posible que desee validar si el modelo es realmente útil en la infraestructura de servicio. Esto es especialmente importante en entornos de producción para garantizar que el modelo recién publicado no impida que el sistema sirva predicciones. El componente InfraValidator realizará una implementación canary de su modelo en un entorno de espacio aislado y, opcionalmente, enviará solicitudes reales para comprobar que su modelo funciona correctamente.
Objetivos de implementación
Una vez que haya desarrollado y entrenado un modelo con el que esté satisfecho, ahora es el momento de implementarlo en uno o más destinos de implementación donde recibirá solicitudes de inferencia. TFX admite la implementación en tres clases de destinos de implementación. Los modelos entrenados que se han exportado como modelos guardados se pueden implementar en cualquiera o en todos estos destinos de implementación.
Inferencia: servicio de TensorFlow
TensorFlow Serving (TFS) es un sistema de servicio flexible y de alto rendimiento para modelos de aprendizaje automático, diseñado para entornos de producción. Consume un modelo guardado y aceptará solicitudes de inferencia a través de interfaces REST o gRPC. Se ejecuta como un conjunto de procesos en uno o más servidores de red, usando una de varias arquitecturas avanzadas para manejar la sincronización y el cómputo distribuido. Consulte la documentación de TFS para obtener más información sobre el desarrollo y la implementación de soluciones TFS.
En una canalización típica, un modelo guardado que se ha entrenado en un componente Trainer primero se infravalidará en un componente InfraValidator . InfraValidator lanza un servidor modelo TFS canary para servir realmente al modelo guardado. Si ha pasado la validación, un componente Pusher finalmente implementará el modelo guardado en su infraestructura TFS. Esto incluye el manejo de múltiples versiones y actualizaciones de modelos.
Inferencia en aplicaciones móviles e IoT nativas: TensorFlow Lite
TensorFlow Lite es un conjunto de herramientas dedicado a ayudar a los desarrolladores a usar sus modelos de TensorFlow capacitados en aplicaciones móviles y de IoT nativas. Consume los mismos modelos guardados que TensorFlow Serving y aplica optimizaciones como la cuantificación y la poda para optimizar el tamaño y el rendimiento de los modelos resultantes para los desafíos de ejecutarse en dispositivos móviles y de IoT. Consulte la documentación de TensorFlow Lite para obtener más información sobre el uso de TensorFlow Lite.
Inferencia en JavaScript: TensorFlow JS
TensorFlow JS es una biblioteca de JavaScript para entrenar e implementar modelos ML en el navegador y en Node.js. Consume los mismos modelos guardados que TensorFlow Serving y TensorFlow Lite, y los convierte al formato web de TensorFlow.js. Consulte la documentación de TensorFlow JS para obtener más detalles sobre el uso de TensorFlow JS.
Creación de una canalización TFX con flujo de aire
Consulte el taller de flujo de aire para obtener más información.
Creación de una canalización TFX con Kubeflow
Configuración
Kubeflow requiere un clúster de Kubernetes para ejecutar las canalizaciones a escala. Consulte la pauta de implementación de Kubeflow que guía a través de las opciones para implementar el clúster de Kubeflow.
Configurar y ejecutar canalización TFX
Siga el tutorial sobre la canalización de TFX en Cloud AI Platform para ejecutar la canalización de ejemplo de TFX en Kubeflow. Los componentes de TFX se han incluido en contenedores para componer la canalización de Kubeflow y la muestra ilustra la capacidad de configurar la canalización para leer grandes conjuntos de datos públicos y ejecutar pasos de capacitación y procesamiento de datos a escala en la nube.
Interfaz de línea de comandos para acciones de canalización
TFX proporciona una CLI unificada que ayuda a realizar una gama completa de acciones de canalización, como crear, actualizar, ejecutar, enumerar y eliminar canalizaciones en varios orquestadores, incluidos Apache Airflow, Apache Beam y Kubeflow. Para obtener más información, siga estas instrucciones .