
 GitHubでソースを表示 GitHubでソースを表示 |
このチュートリアルでは、単純な RNN(回帰型ニューラルネットワーク)を使用して楽譜を生成する方法を説明します。モデルは、MAESTRO データセットのピアノ MIDI ファイルのコレクションを使ってトレーニングします。ノートのシーケンスを与えられることで、モデルはそのシーケンスの次のノートを予測するように学習します。モデルを繰り返し呼び出すことで、より長いノートのシーケンスを生成できます。
このチュートリアルには、MIDI ファイルを解析して作成するための完全なコードが含まれます。RNN の仕組みについては、RNN によるテキスト生成をご覧ください。
MNIST モデルをビルドする
このチュートリアルでは、MIDI ファイルの作成と解析を行う pretty_midi ライブラリと、Colab でオーディオ再生を生成する pyfluidsynth を使用します。
sudo apt install -y fluidsynth
The following packages were automatically installed and are no longer required: libatasmart4 libblockdev-fs2 libblockdev-loop2 libblockdev-part-err2 libblockdev-part2 libblockdev-swap2 libblockdev-utils2 libblockdev2 libparted-fs-resize0 libxmlb2 Use 'sudo apt autoremove' to remove them. The following additional packages will be installed: fluid-soundfont-gm libdouble-conversion3 libfluidsynth2 libinstpatch-1.0-2 libpcre2-16-0 libqt5core5a libqt5dbus5 libqt5gui5 libqt5network5 libqt5svg5 libqt5widgets5 libsdl2-2.0-0 qsynth qt5-gtk-platformtheme qttranslations5-l10n timgm6mb-soundfont Suggested packages: fluid-soundfont-gs timidity qt5-image-formats-plugins qtwayland5 jackd musescore The following NEW packages will be installed: fluid-soundfont-gm fluidsynth libdouble-conversion3 libfluidsynth2 libinstpatch-1.0-2 libpcre2-16-0 libqt5core5a libqt5dbus5 libqt5gui5 libqt5network5 libqt5svg5 libqt5widgets5 libsdl2-2.0-0 qsynth qt5-gtk-platformtheme qttranslations5-l10n timgm6mb-soundfont 0 upgraded, 17 newly installed, 0 to remove and 128 not upgraded. Need to get 136 MB of archives. After this operation, 202 MB of additional disk space will be used. Get:1 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 libdouble-conversion3 amd64 3.1.5-4ubuntu1 [37.9 kB] Get:2 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/main amd64 libpcre2-16-0 amd64 10.34-7ubuntu0.1 [181 kB] Get:3 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 libqt5core5a amd64 5.12.8+dfsg-0ubuntu2.1 [2006 kB] Get:4 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 libqt5dbus5 amd64 5.12.8+dfsg-0ubuntu2.1 [208 kB] Get:5 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 libqt5network5 amd64 5.12.8+dfsg-0ubuntu2.1 [673 kB] Get:6 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 libqt5gui5 amd64 5.12.8+dfsg-0ubuntu2.1 [2971 kB] Get:7 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 libqt5widgets5 amd64 5.12.8+dfsg-0ubuntu2.1 [2295 kB] Get:8 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 libqt5svg5 amd64 5.12.8-0ubuntu1 [131 kB] Get:9 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 fluid-soundfont-gm all 3.1-5.1 [119 MB] Get:10 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 libinstpatch-1.0-2 amd64 1.1.2-2build1 [238 kB] Get:11 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 libsdl2-2.0-0 amd64 2.0.10+dfsg1-3 [407 kB] Get:12 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 timgm6mb-soundfont all 1.3-3 [5420 kB] Get:13 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 libfluidsynth2 amd64 2.1.1-2 [198 kB] Get:14 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 fluidsynth amd64 2.1.1-2 [25.6 kB] Get:15 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 qsynth amd64 0.6.1-1build1 [245 kB] Get:16 http://us-central1.gce.archive.ubuntu.com/ubuntu focal-updates/universe amd64 qt5-gtk-platformtheme amd64 5.12.8+dfsg-0ubuntu2.1 [124 kB] Get:17 http://us-central1.gce.archive.ubuntu.com/ubuntu focal/universe amd64 qttranslations5-l10n all 5.12.8-0ubuntu1 [1486 kB] Fetched 136 MB in 4s (38.8 MB/s) 7[0;23r8[1ASelecting previously unselected package libdouble-conversion3:amd64. (Reading database ... 145997 files and directories currently installed.) Preparing to unpack .../00-libdouble-conversion3_3.1.5-4ubuntu1_amd64.deb ... 7[24;0fProgress: [ 0%] [..........................................................] 87[24;0fProgress: [ 1%] [..........................................................] 8Unpacking libdouble-conversion3:amd64 (3.1.5-4ubuntu1) ... 7[24;0fProgress: [ 3%] [#.........................................................] 8Selecting previously unselected package libpcre2-16-0:amd64. Preparing to unpack .../01-libpcre2-16-0_10.34-7ubuntu0.1_amd64.deb ... 7[24;0fProgress: [ 4%] [##........................................................] 8Unpacking libpcre2-16-0:amd64 (10.34-7ubuntu0.1) ... 7[24;0fProgress: [ 6%] [###.......................................................] 8Selecting previously unselected package libqt5core5a:amd64. Preparing to unpack .../02-libqt5core5a_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 7%] [####......................................................] 8Unpacking libqt5core5a:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 9%] [#####.....................................................] 8Selecting previously unselected package libqt5dbus5:amd64. Preparing to unpack .../03-libqt5dbus5_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 10%] [#####.....................................................] 8Unpacking libqt5dbus5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 12%] [######....................................................] 8Selecting previously unselected package libqt5network5:amd64. Preparing to unpack .../04-libqt5network5_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 13%] [#######...................................................] 8Unpacking libqt5network5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 14%] [########..................................................] 8Selecting previously unselected package libqt5gui5:amd64. Preparing to unpack .../05-libqt5gui5_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 16%] [#########.................................................] 8Unpacking libqt5gui5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 17%] [##########................................................] 8Selecting previously unselected package libqt5widgets5:amd64. Preparing to unpack .../06-libqt5widgets5_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 19%] [##########................................................] 8Unpacking libqt5widgets5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 20%] [###########...............................................] 8Selecting previously unselected package libqt5svg5:amd64. Preparing to unpack .../07-libqt5svg5_5.12.8-0ubuntu1_amd64.deb ... 7[24;0fProgress: [ 22%] [############..............................................] 8Unpacking libqt5svg5:amd64 (5.12.8-0ubuntu1) ... 7[24;0fProgress: [ 23%] [#############.............................................] 8Selecting previously unselected package fluid-soundfont-gm. Preparing to unpack .../08-fluid-soundfont-gm_3.1-5.1_all.deb ... 7[24;0fProgress: [ 25%] [##############............................................] 8Unpacking fluid-soundfont-gm (3.1-5.1) ... 7[24;0fProgress: [ 26%] [###############...........................................] 8Selecting previously unselected package libinstpatch-1.0-2:amd64. Preparing to unpack .../09-libinstpatch-1.0-2_1.1.2-2build1_amd64.deb ... 7[24;0fProgress: [ 28%] [###############...........................................] 8Unpacking libinstpatch-1.0-2:amd64 (1.1.2-2build1) ... 7[24;0fProgress: [ 29%] [################..........................................] 8Selecting previously unselected package libsdl2-2.0-0:amd64. Preparing to unpack .../10-libsdl2-2.0-0_2.0.10+dfsg1-3_amd64.deb ... 7[24;0fProgress: [ 30%] [#################.........................................] 8Unpacking libsdl2-2.0-0:amd64 (2.0.10+dfsg1-3) ... 7[24;0fProgress: [ 32%] [##################........................................] 8Selecting previously unselected package timgm6mb-soundfont. Preparing to unpack .../11-timgm6mb-soundfont_1.3-3_all.deb ... 7[24;0fProgress: [ 33%] [###################.......................................] 8Unpacking timgm6mb-soundfont (1.3-3) ... 7[24;0fProgress: [ 35%] [####################......................................] 8Selecting previously unselected package libfluidsynth2:amd64. Preparing to unpack .../12-libfluidsynth2_2.1.1-2_amd64.deb ... 7[24;0fProgress: [ 36%] [#####################.....................................] 8Unpacking libfluidsynth2:amd64 (2.1.1-2) ... 7[24;0fProgress: [ 38%] [#####################.....................................] 8Selecting previously unselected package fluidsynth. Preparing to unpack .../13-fluidsynth_2.1.1-2_amd64.deb ... 7[24;0fProgress: [ 39%] [######################....................................] 8Unpacking fluidsynth (2.1.1-2) ... 7[24;0fProgress: [ 41%] [#######################...................................] 8Selecting previously unselected package qsynth. Preparing to unpack .../14-qsynth_0.6.1-1build1_amd64.deb ... 7[24;0fProgress: [ 42%] [########################..................................] 8Unpacking qsynth (0.6.1-1build1) ... 7[24;0fProgress: [ 43%] [#########################.................................] 8Selecting previously unselected package qt5-gtk-platformtheme:amd64. Preparing to unpack .../15-qt5-gtk-platformtheme_5.12.8+dfsg-0ubuntu2.1_amd64.deb ... 7[24;0fProgress: [ 45%] [##########################................................] 8Unpacking qt5-gtk-platformtheme:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 46%] [##########################................................] 8Selecting previously unselected package qttranslations5-l10n. Preparing to unpack .../16-qttranslations5-l10n_5.12.8-0ubuntu1_all.deb ... 7[24;0fProgress: [ 48%] [###########################...............................] 8Unpacking qttranslations5-l10n (5.12.8-0ubuntu1) ... 7[24;0fProgress: [ 49%] [############################..............................] 8Setting up libdouble-conversion3:amd64 (3.1.5-4ubuntu1) ... 7[24;0fProgress: [ 51%] [#############################.............................] 87[24;0fProgress: [ 52%] [##############################............................] 8Setting up libpcre2-16-0:amd64 (10.34-7ubuntu0.1) ... 7[24;0fProgress: [ 54%] [###############################...........................] 87[24;0fProgress: [ 55%] [###############################...........................] 8Setting up qttranslations5-l10n (5.12.8-0ubuntu1) ... 7[24;0fProgress: [ 57%] [################################..........................] 87[24;0fProgress: [ 58%] [#################################.........................] 8Setting up libqt5core5a:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 59%] [##################################........................] 87[24;0fProgress: [ 61%] [###################################.......................] 8Setting up libqt5dbus5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 62%] [####################################......................] 87[24;0fProgress: [ 64%] [####################################......................] 8Setting up fluid-soundfont-gm (3.1-5.1) ... 7[24;0fProgress: [ 65%] [#####################################.....................] 87[24;0fProgress: [ 67%] [######################################....................] 8Setting up libsdl2-2.0-0:amd64 (2.0.10+dfsg1-3) ... 7[24;0fProgress: [ 68%] [#######################################...................] 87[24;0fProgress: [ 70%] [########################################..................] 8Setting up timgm6mb-soundfont (1.3-3) ... 7[24;0fProgress: [ 71%] [#########################################.................] 8update-alternatives: using /usr/share/sounds/sf2/TimGM6mb.sf2 to provide /usr/share/sounds/sf2/default-GM.sf2 (default-GM.sf2) in auto mode update-alternatives: using /usr/share/sounds/sf2/TimGM6mb.sf2 to provide /usr/share/sounds/sf3/default-GM.sf3 (default-GM.sf3) in auto mode 7[24;0fProgress: [ 72%] [##########################################................] 8Setting up libinstpatch-1.0-2:amd64 (1.1.2-2build1) ... 7[24;0fProgress: [ 74%] [##########################################................] 87[24;0fProgress: [ 75%] [###########################################...............] 8Setting up libqt5network5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 77%] [############################################..............] 87[24;0fProgress: [ 78%] [#############################################.............] 8Setting up libfluidsynth2:amd64 (2.1.1-2) ... 7[24;0fProgress: [ 80%] [##############################################............] 87[24;0fProgress: [ 81%] [###############################################...........] 8Setting up libqt5gui5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 83%] [###############################################...........] 87[24;0fProgress: [ 84%] [################################################..........] 8Setting up libqt5widgets5:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 86%] [#################################################.........] 87[24;0fProgress: [ 87%] [##################################################........] 8Setting up qt5-gtk-platformtheme:amd64 (5.12.8+dfsg-0ubuntu2.1) ... 7[24;0fProgress: [ 88%] [###################################################.......] 87[24;0fProgress: [ 90%] [####################################################......] 8Setting up fluidsynth (2.1.1-2) ... 7[24;0fProgress: [ 91%] [####################################################......] 8Created symlink /etc/systemd/user/multi-user.target.wants/fluidsynth.service → /usr/lib/systemd/user/fluidsynth.service. 7[24;0fProgress: [ 93%] [#####################################################.....] 8Setting up libqt5svg5:amd64 (5.12.8-0ubuntu1) ... 7[24;0fProgress: [ 94%] [######################################################....] 87[24;0fProgress: [ 96%] [#######################################################...] 8Setting up qsynth (0.6.1-1build1) ... 7[24;0fProgress: [ 97%] [########################################################..] 87[24;0fProgress: [ 99%] [#########################################################.] 8Processing triggers for desktop-file-utils (0.24-1ubuntu3) ... Processing triggers for mime-support (3.64ubuntu1) ... Processing triggers for hicolor-icon-theme (0.17-2) ... Processing triggers for gnome-menus (3.36.0-1ubuntu1) ... Processing triggers for libc-bin (2.31-0ubuntu9.12) ... Processing triggers for man-db (2.9.1-1) ... 7[0;24r8[1A[J
pip install --upgrade pyfluidsynth
pip install pretty_midi
import collections
import datetime
import fluidsynth
import glob
import numpy as np
import pathlib
import pandas as pd
import pretty_midi
import seaborn as sns
import tensorflow as tf
from IPython import display
from matplotlib import pyplot as plt
from typing import Optional
2024-01-11 22:00:46.923423: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 22:00:46.923467: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 22:00:46.925019: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
# Sampling rate for audio playback
_SAMPLING_RATE = 16000
Maestro データセットをダウンロードする
data_dir = pathlib.Path('data/maestro-v2.0.0')
if not data_dir.exists():
tf.keras.utils.get_file(
'maestro-v2.0.0-midi.zip',
origin='https://storage.googleapis.com/magentadata/datasets/maestro/v2.0.0/maestro-v2.0.0-midi.zip',
extract=True,
cache_dir='.', cache_subdir='data',
)
Downloading data from https://storage.googleapis.com/magentadata/datasets/maestro/v2.0.0/maestro-v2.0.0-midi.zip 59243107/59243107 [==============================] - 1s 0us/step
データセットには、約 1,200 個の MIDI ファイルが含まれます。
filenames = glob.glob(str(data_dir/'**/*.mid*'))
print('Number of files:', len(filenames))
Number of files: 1282
MIDI ファイルを処理する
まず、pretty_midi を使用して、単一の MIDI ファイルを解析し、ノートのフォーマットを検査します。以下の MIDI ファイルをコンピュータにダウンロードして再生する場合は、Colab で files.download(sample_file) を記述してください。
sample_file = filenames[1]
print(sample_file)
data/maestro-v2.0.0/2008/MIDI-Unprocessed_15_R1_2008_01-04_ORIG_MID--AUDIO_15_R1_2008_wav--3.midi
サンプル MIDI ファイルの PrettyMIDI オブジェクトを生成します。
pm = pretty_midi.PrettyMIDI(sample_file)
サンプルファイルを再生します。再生ウィジェットの読み込みには数秒かかることがあります。
def display_audio(pm: pretty_midi.PrettyMIDI, seconds=30):
waveform = pm.fluidsynth(fs=_SAMPLING_RATE)
# Take a sample of the generated waveform to mitigate kernel resets
waveform_short = waveform[:seconds*_SAMPLING_RATE]
return display.Audio(waveform_short, rate=_SAMPLING_RATE)
display_audio(pm)
fluidsynth: warning: SDL2 not initialized, SDL2 audio driver won't be usable fluidsynth: error: Unknown integer parameter 'synth.sample-rate'
MIDI ファイルを検査します。どのような楽器が使用されていますか?
print('Number of instruments:', len(pm.instruments))
instrument = pm.instruments[0]
instrument_name = pretty_midi.program_to_instrument_name(instrument.program)
print('Instrument name:', instrument_name)
Number of instruments: 1 Instrument name: Acoustic Grand Piano
ノートを抽出する
for i, note in enumerate(instrument.notes[:10]):
note_name = pretty_midi.note_number_to_name(note.pitch)
duration = note.end - note.start
print(f'{i}: pitch={note.pitch}, note_name={note_name},'
f' duration={duration:.4f}')
0: pitch=60, note_name=C4, duration=0.1784 1: pitch=72, note_name=C5, duration=0.1953 2: pitch=72, note_name=C5, duration=0.2344 3: pitch=60, note_name=C4, duration=0.2578 4: pitch=60, note_name=C4, duration=0.0964 5: pitch=72, note_name=C5, duration=0.1393 6: pitch=72, note_name=C5, duration=0.2044 7: pitch=60, note_name=C4, duration=0.2031 8: pitch=72, note_name=C5, duration=0.1497 9: pitch=60, note_name=C4, duration=0.1510
モデルをトレーニングする際に、pitch、step、duration という 3 つの変数を使用してノートを表現します。pitch は、MIDI ノートナンバーとしてのサウンドの知覚的な質です。step は、前のノートまたは曲の始めから経過した時間です。duration は、ノートの再生秒数で、ノートの終了時間とノートの開始時間の差です。
サンプル MIDI ファイルからノートを抽出します。
def midi_to_notes(midi_file: str) -> pd.DataFrame:
pm = pretty_midi.PrettyMIDI(midi_file)
instrument = pm.instruments[0]
notes = collections.defaultdict(list)
# Sort the notes by start time
sorted_notes = sorted(instrument.notes, key=lambda note: note.start)
prev_start = sorted_notes[0].start
for note in sorted_notes:
start = note.start
end = note.end
notes['pitch'].append(note.pitch)
notes['start'].append(start)
notes['end'].append(end)
notes['step'].append(start - prev_start)
notes['duration'].append(end - start)
prev_start = start
return pd.DataFrame({name: np.array(value) for name, value in notes.items()})
raw_notes = midi_to_notes(sample_file)
raw_notes.head()
ピッチよりもノート名を解釈する方が簡単な場合があるため、以下の関数を使用して数値のピッチ値からノート名に変換します。ノート名は、ノートの種類、臨時記号、およびオクターブ番号(例: C#4)を示します。
get_note_names = np.vectorize(pretty_midi.note_number_to_name)
sample_note_names = get_note_names(raw_notes['pitch'])
sample_note_names[:10]
array(['C4', 'C5', 'C5', 'C4', 'C5', 'C4', 'C5', 'C4', 'C5', 'C4'],
dtype='<U3')
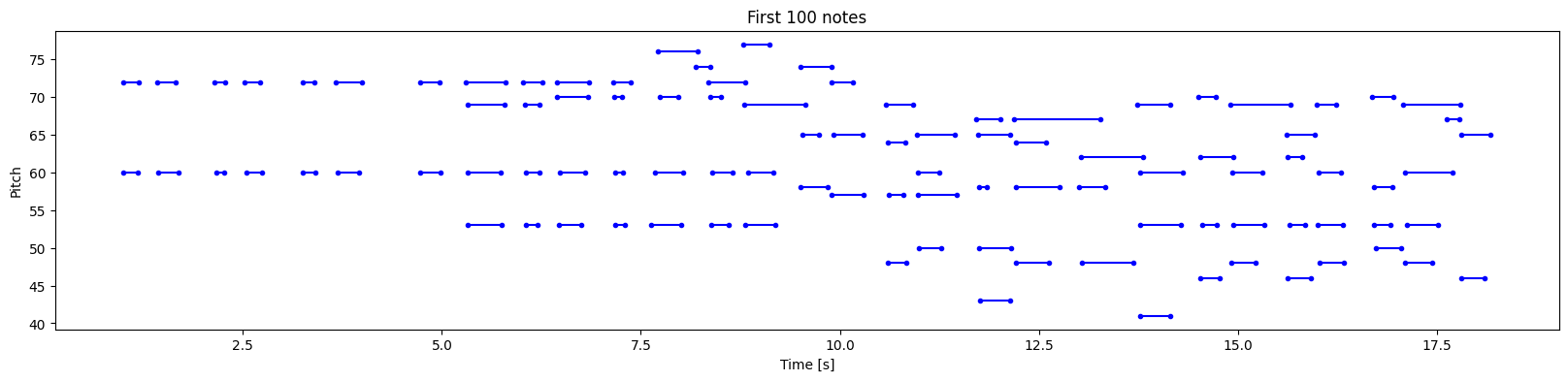
曲を視覚化するために、ノートピッチとトラック全体(ピアノロール)の開始と終了をプロットします。最初の 100 個のノートから始めます。
def plot_piano_roll(notes: pd.DataFrame, count: Optional[int] = None):
if count:
title = f'First {count} notes'
else:
title = f'Whole track'
count = len(notes['pitch'])
plt.figure(figsize=(20, 4))
plot_pitch = np.stack([notes['pitch'], notes['pitch']], axis=0)
plot_start_stop = np.stack([notes['start'], notes['end']], axis=0)
plt.plot(
plot_start_stop[:, :count], plot_pitch[:, :count], color="b", marker=".")
plt.xlabel('Time [s]')
plt.ylabel('Pitch')
_ = plt.title(title)
plot_piano_roll(raw_notes, count=100)
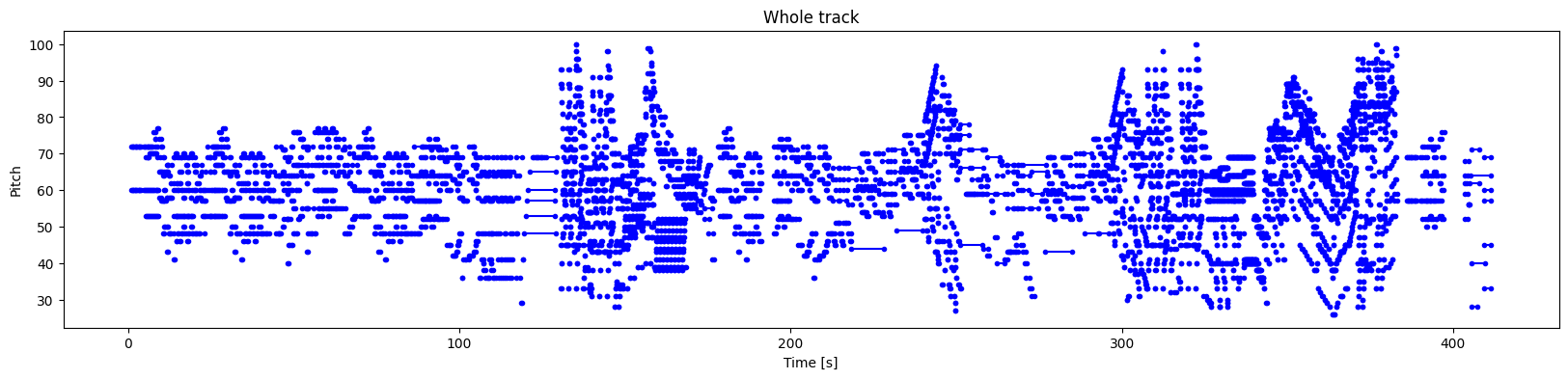
トラック全体のノートをプロットします。
plot_piano_roll(raw_notes)
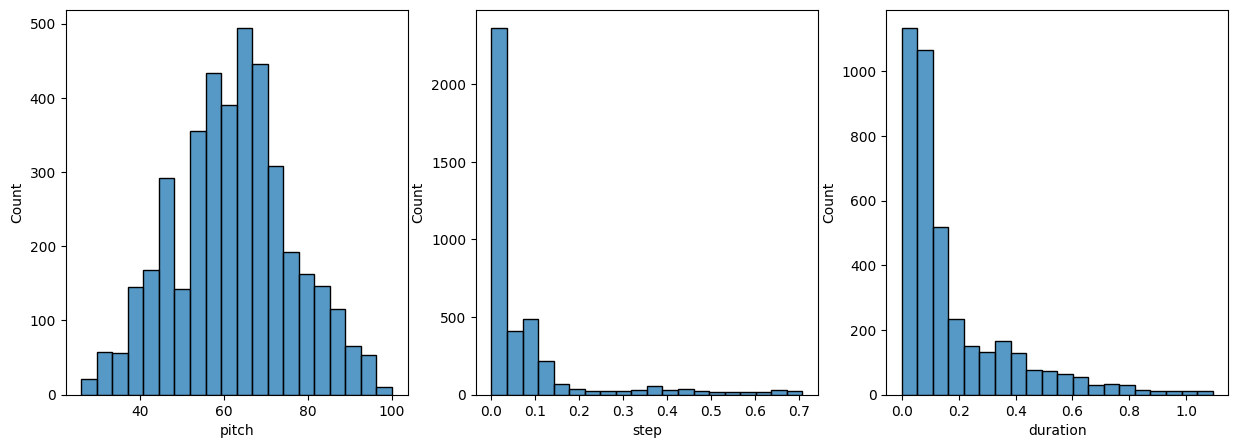
各ノート変数の分布を確認します。
def plot_distributions(notes: pd.DataFrame, drop_percentile=2.5):
plt.figure(figsize=[15, 5])
plt.subplot(1, 3, 1)
sns.histplot(notes, x="pitch", bins=20)
plt.subplot(1, 3, 2)
max_step = np.percentile(notes['step'], 100 - drop_percentile)
sns.histplot(notes, x="step", bins=np.linspace(0, max_step, 21))
plt.subplot(1, 3, 3)
max_duration = np.percentile(notes['duration'], 100 - drop_percentile)
sns.histplot(notes, x="duration", bins=np.linspace(0, max_duration, 21))
plot_distributions(raw_notes)
MIDI ファイルを作成する
以下の関数を使用して、ノートのリストから独自の MIDI を生成できます。
def notes_to_midi(
notes: pd.DataFrame,
out_file: str,
instrument_name: str,
velocity: int = 100, # note loudness
) -> pretty_midi.PrettyMIDI:
pm = pretty_midi.PrettyMIDI()
instrument = pretty_midi.Instrument(
program=pretty_midi.instrument_name_to_program(
instrument_name))
prev_start = 0
for i, note in notes.iterrows():
start = float(prev_start + note['step'])
end = float(start + note['duration'])
note = pretty_midi.Note(
velocity=velocity,
pitch=int(note['pitch']),
start=start,
end=end,
)
instrument.notes.append(note)
prev_start = start
pm.instruments.append(instrument)
pm.write(out_file)
return pm
example_file = 'example.midi'
example_pm = notes_to_midi(
raw_notes, out_file=example_file, instrument_name=instrument_name)
生成した MIDI ファイルを再生し、何らかの違いがないか確認します。
display_audio(example_pm)
fluidsynth: warning: SDL2 not initialized, SDL2 audio driver won't be usable fluidsynth: error: Unknown integer parameter 'synth.sample-rate'
前と同様に、files.download(example_file) を記述すると、このファイルをダウンロードして再生できます。
トレーニングデータセットを作成する
MIDI ファイルからノートを抽出して、トレーニングデータセットを作成します。まず、少数のファイルを使って作業を開始し、後の方でさらに他のファイルを使用して実験することができます。これには数分かかることがあります。
num_files = 5
all_notes = []
for f in filenames[:num_files]:
notes = midi_to_notes(f)
all_notes.append(notes)
all_notes = pd.concat(all_notes)
n_notes = len(all_notes)
print('Number of notes parsed:', n_notes)
Number of notes parsed: 16633
次に、解析したノートから tf.data.Dataset を作成します。
key_order = ['pitch', 'step', 'duration']
train_notes = np.stack([all_notes[key] for key in key_order], axis=1)
notes_ds = tf.data.Dataset.from_tensor_slices(train_notes)
notes_ds.element_spec
TensorSpec(shape=(3,), dtype=tf.float64, name=None)
バッチ化されたノートのシーケンスに対してモデルをトレーニングします。各 Example では、入力特徴量としてノートのシーケンス、ラベルとして次のノートが使用されます。このようにすることで、モデルはシーケンスの次のノートを予測するようにトレーニングされます。このプロセスを説明した図(およびその他の詳細)は、RNN によるテキスト分類をご覧ください。
このフォーマットで特徴量とラベルを作成するには、便利な window 関数とサイズ seq_length を使用できます。
def create_sequences(
dataset: tf.data.Dataset,
seq_length: int,
vocab_size = 128,
) -> tf.data.Dataset:
"""Returns TF Dataset of sequence and label examples."""
seq_length = seq_length+1
# Take 1 extra for the labels
windows = dataset.window(seq_length, shift=1, stride=1,
drop_remainder=True)
# `flat_map` flattens the" dataset of datasets" into a dataset of tensors
flatten = lambda x: x.batch(seq_length, drop_remainder=True)
sequences = windows.flat_map(flatten)
# Normalize note pitch
def scale_pitch(x):
x = x/[vocab_size,1.0,1.0]
return x
# Split the labels
def split_labels(sequences):
inputs = sequences[:-1]
labels_dense = sequences[-1]
labels = {key:labels_dense[i] for i,key in enumerate(key_order)}
return scale_pitch(inputs), labels
return sequences.map(split_labels, num_parallel_calls=tf.data.AUTOTUNE)
各 Example のシーケンスの長さを設定します。さまざまな長さ(50、100, 150 など)を試してデータに最適なものを確認するか、ハイパーパラメータのチューニングを行います。語彙のサイズ(vocab_size)は 128 で、pretty_midi がサポートするすべてのピッチを表します。
seq_length = 25
vocab_size = 128
seq_ds = create_sequences(notes_ds, seq_length, vocab_size)
seq_ds.element_spec
(TensorSpec(shape=(25, 3), dtype=tf.float64, name=None),
{'pitch': TensorSpec(shape=(), dtype=tf.float64, name=None),
'step': TensorSpec(shape=(), dtype=tf.float64, name=None),
'duration': TensorSpec(shape=(), dtype=tf.float64, name=None)})
データセットの形状は (100,1) で、モデルは 100 個のノートを入力として取り、出力として移行のノートの予測を学習します。
for seq, target in seq_ds.take(1):
print('sequence shape:', seq.shape)
print('sequence elements (first 10):', seq[0: 10])
print()
print('target:', target)
sequence shape: (25, 3)
sequence elements (first 10): tf.Tensor(
[[0.5390625 0. 2.37239583]
[0.390625 0.01302083 1.30859375]
[0.5078125 0.00390625 0.77604167]
[0.484375 0.00520833 0.42708333]
[0.46875 0.76041667 0.48046875]
[0.5 0.0234375 0.67838542]
[0.484375 0.82291667 1.03515625]
[0.4609375 0.00390625 1.09635417]
[0.40625 0.02213542 1.02473958]
[0.53125 0.70182292 0.37239583]], shape=(10, 3), dtype=float64)
target: {'pitch': <tf.Tensor: shape=(), dtype=float64, numpy=76.0>, 'step': <tf.Tensor: shape=(), dtype=float64, numpy=0.016927083333333925>, 'duration': <tf.Tensor: shape=(), dtype=float64, numpy=0.33984375>}
Example をバッチ処理し、パフォーマンスを得られるようにデータセットを構成します。
batch_size = 64
buffer_size = n_notes - seq_length # the number of items in the dataset
train_ds = (seq_ds
.shuffle(buffer_size)
.batch(batch_size, drop_remainder=True)
.cache()
.prefetch(tf.data.experimental.AUTOTUNE))
train_ds.element_spec
(TensorSpec(shape=(64, 25, 3), dtype=tf.float64, name=None),
{'pitch': TensorSpec(shape=(64,), dtype=tf.float64, name=None),
'step': TensorSpec(shape=(64,), dtype=tf.float64, name=None),
'duration': TensorSpec(shape=(64,), dtype=tf.float64, name=None)})
モデルを作成してトレーニングする
このモデルには、ノート変数あたり 1 つの出力、計 3 つの出力があります。step と duration については、モデルが負でない値を出力するように、平均二条誤差に基づくカスタム損失関数を使用します。
def mse_with_positive_pressure(y_true: tf.Tensor, y_pred: tf.Tensor):
mse = (y_true - y_pred) ** 2
positive_pressure = 10 * tf.maximum(-y_pred, 0.0)
return tf.reduce_mean(mse + positive_pressure)
input_shape = (seq_length, 3)
learning_rate = 0.005
inputs = tf.keras.Input(input_shape)
x = tf.keras.layers.LSTM(128)(inputs)
outputs = {
'pitch': tf.keras.layers.Dense(128, name='pitch')(x),
'step': tf.keras.layers.Dense(1, name='step')(x),
'duration': tf.keras.layers.Dense(1, name='duration')(x),
}
model = tf.keras.Model(inputs, outputs)
loss = {
'pitch': tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True),
'step': mse_with_positive_pressure,
'duration': mse_with_positive_pressure,
}
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
model.compile(loss=loss, optimizer=optimizer)
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 25, 3)] 0 []
lstm (LSTM) (None, 128) 67584 ['input_1[0][0]']
duration (Dense) (None, 1) 129 ['lstm[0][0]']
pitch (Dense) (None, 128) 16512 ['lstm[0][0]']
step (Dense) (None, 1) 129 ['lstm[0][0]']
==================================================================================================
Total params: 84354 (329.51 KB)
Trainable params: 84354 (329.51 KB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
model.evaluate 関数をテストすると、pitch の損失が step と duration の損失を大きく上回ることがわかります。loss はその他すべての損失を合計して算出された合計損失であり、現在 pitch 損失に占有されていることに注意してください。
losses = model.evaluate(train_ds, return_dict=True)
losses
259/259 [==============================] - 4s 3ms/step - loss: 5.1320 - duration_loss: 0.2264 - pitch_loss: 4.8492 - step_loss: 0.0565
{'loss': 5.132046222686768,
'duration_loss': 0.2263597846031189,
'pitch_loss': 4.849214553833008,
'step_loss': 0.056468527764081955}
これを平衡化する方法として、loss_weights 引数を使用してコンパイルする方法が挙げられます。
model.compile(
loss=loss,
loss_weights={
'pitch': 0.05,
'step': 1.0,
'duration':1.0,
},
optimizer=optimizer,
)
これにより、loss は個別の損失の重み付き合計になります。
model.evaluate(train_ds, return_dict=True)
259/259 [==============================] - 2s 3ms/step - loss: 0.5253 - duration_loss: 0.2264 - pitch_loss: 4.8492 - step_loss: 0.0565
{'loss': 0.5252891778945923,
'duration_loss': 0.2263597846031189,
'pitch_loss': 4.849214553833008,
'step_loss': 0.056468527764081955}
モデルをトレーニングする。
callbacks = [
tf.keras.callbacks.ModelCheckpoint(
filepath='./training_checkpoints/ckpt_{epoch}',
save_weights_only=True),
tf.keras.callbacks.EarlyStopping(
monitor='loss',
patience=5,
verbose=1,
restore_best_weights=True),
]
%%time
epochs = 50
history = model.fit(
train_ds,
epochs=epochs,
callbacks=callbacks,
)
Epoch 1/50 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1705010474.343264 988398 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 259/259 [==============================] - 4s 5ms/step - loss: 0.3892 - duration_loss: 0.1395 - pitch_loss: 4.0668 - step_loss: 0.0464 Epoch 2/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3665 - duration_loss: 0.1298 - pitch_loss: 3.8530 - step_loss: 0.0440 Epoch 3/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3638 - duration_loss: 0.1282 - pitch_loss: 3.8394 - step_loss: 0.0437 Epoch 4/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3615 - duration_loss: 0.1269 - pitch_loss: 3.8292 - step_loss: 0.0431 Epoch 5/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3601 - duration_loss: 0.1266 - pitch_loss: 3.8196 - step_loss: 0.0425 Epoch 6/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3568 - duration_loss: 0.1251 - pitch_loss: 3.8059 - step_loss: 0.0414 Epoch 7/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3527 - duration_loss: 0.1233 - pitch_loss: 3.7797 - step_loss: 0.0404 Epoch 8/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3483 - duration_loss: 0.1209 - pitch_loss: 3.7633 - step_loss: 0.0392 Epoch 9/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3463 - duration_loss: 0.1194 - pitch_loss: 3.7512 - step_loss: 0.0394 Epoch 10/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3438 - duration_loss: 0.1170 - pitch_loss: 3.7499 - step_loss: 0.0393 Epoch 11/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3418 - duration_loss: 0.1162 - pitch_loss: 3.7412 - step_loss: 0.0386 Epoch 12/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3363 - duration_loss: 0.1120 - pitch_loss: 3.7274 - step_loss: 0.0379 Epoch 13/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3345 - duration_loss: 0.1107 - pitch_loss: 3.7219 - step_loss: 0.0377 Epoch 14/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3302 - duration_loss: 0.1074 - pitch_loss: 3.7192 - step_loss: 0.0368 Epoch 15/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3291 - duration_loss: 0.1060 - pitch_loss: 3.7143 - step_loss: 0.0373 Epoch 16/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3187 - duration_loss: 0.0967 - pitch_loss: 3.7033 - step_loss: 0.0368 Epoch 17/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3190 - duration_loss: 0.0981 - pitch_loss: 3.6986 - step_loss: 0.0359 Epoch 18/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3174 - duration_loss: 0.0965 - pitch_loss: 3.6983 - step_loss: 0.0360 Epoch 19/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3120 - duration_loss: 0.0920 - pitch_loss: 3.6950 - step_loss: 0.0352 Epoch 20/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3130 - duration_loss: 0.0934 - pitch_loss: 3.6875 - step_loss: 0.0352 Epoch 21/50 259/259 [==============================] - 1s 4ms/step - loss: 0.3028 - duration_loss: 0.0849 - pitch_loss: 3.6768 - step_loss: 0.0341 Epoch 22/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2985 - duration_loss: 0.0802 - pitch_loss: 3.6725 - step_loss: 0.0347 Epoch 23/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2990 - duration_loss: 0.0824 - pitch_loss: 3.6729 - step_loss: 0.0330 Epoch 24/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2947 - duration_loss: 0.0786 - pitch_loss: 3.6707 - step_loss: 0.0325 Epoch 25/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2924 - duration_loss: 0.0754 - pitch_loss: 3.6746 - step_loss: 0.0333 Epoch 26/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2966 - duration_loss: 0.0804 - pitch_loss: 3.6682 - step_loss: 0.0328 Epoch 27/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2922 - duration_loss: 0.0753 - pitch_loss: 3.6686 - step_loss: 0.0335 Epoch 28/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2920 - duration_loss: 0.0754 - pitch_loss: 3.6733 - step_loss: 0.0329 Epoch 29/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2899 - duration_loss: 0.0745 - pitch_loss: 3.6665 - step_loss: 0.0320 Epoch 30/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2909 - duration_loss: 0.0745 - pitch_loss: 3.6554 - step_loss: 0.0337 Epoch 31/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2863 - duration_loss: 0.0729 - pitch_loss: 3.6492 - step_loss: 0.0310 Epoch 32/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2731 - duration_loss: 0.0611 - pitch_loss: 3.6419 - step_loss: 0.0299 Epoch 33/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2809 - duration_loss: 0.0669 - pitch_loss: 3.6548 - step_loss: 0.0312 Epoch 34/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2838 - duration_loss: 0.0686 - pitch_loss: 3.6560 - step_loss: 0.0323 Epoch 35/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2760 - duration_loss: 0.0630 - pitch_loss: 3.6470 - step_loss: 0.0307 Epoch 36/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2671 - duration_loss: 0.0561 - pitch_loss: 3.6333 - step_loss: 0.0294 Epoch 37/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2604 - duration_loss: 0.0496 - pitch_loss: 3.6252 - step_loss: 0.0295 Epoch 38/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2658 - duration_loss: 0.0539 - pitch_loss: 3.6387 - step_loss: 0.0299 Epoch 39/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2603 - duration_loss: 0.0507 - pitch_loss: 3.6214 - step_loss: 0.0286 Epoch 40/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2586 - duration_loss: 0.0493 - pitch_loss: 3.6172 - step_loss: 0.0284 Epoch 41/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2536 - duration_loss: 0.0457 - pitch_loss: 3.6104 - step_loss: 0.0274 Epoch 42/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2485 - duration_loss: 0.0417 - pitch_loss: 3.6006 - step_loss: 0.0268 Epoch 43/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2474 - duration_loss: 0.0413 - pitch_loss: 3.5935 - step_loss: 0.0265 Epoch 44/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2466 - duration_loss: 0.0404 - pitch_loss: 3.5902 - step_loss: 0.0267 Epoch 45/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2437 - duration_loss: 0.0382 - pitch_loss: 3.5853 - step_loss: 0.0263 Epoch 46/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2412 - duration_loss: 0.0364 - pitch_loss: 3.5831 - step_loss: 0.0256 Epoch 47/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2474 - duration_loss: 0.0413 - pitch_loss: 3.5942 - step_loss: 0.0264 Epoch 48/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2676 - duration_loss: 0.0580 - pitch_loss: 3.6133 - step_loss: 0.0289 Epoch 49/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2554 - duration_loss: 0.0485 - pitch_loss: 3.5879 - step_loss: 0.0275 Epoch 50/50 259/259 [==============================] - 1s 4ms/step - loss: 0.2463 - duration_loss: 0.0411 - pitch_loss: 3.5746 - step_loss: 0.0265 CPU times: user 1min 19s, sys: 10.3 s, total: 1min 29s Wall time: 58.8 s
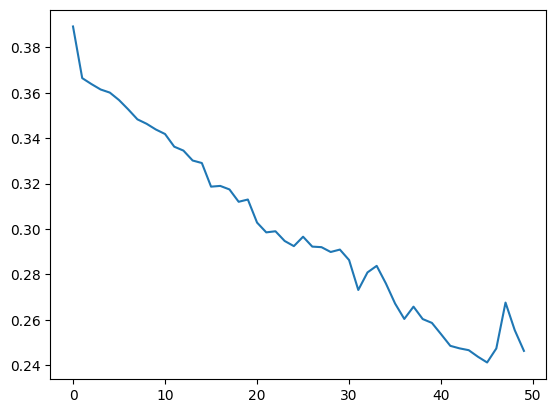
plt.plot(history.epoch, history.history['loss'], label='total loss')
plt.show()
ノートを生成する
モデルを使用してノートを生成するには、まず、ノートの開始シーケンスを指定する必要があります。以下の関数は、ノートのシーケンスから 1 つのノートを生成します。
ノートのピッチについては、モデルが生成するノートのソフトマックス分布からサンプルが取り出され、最も高い確率ののノートが拾われるわけではありません。常に最も高い確率のノートを拾ってしまうと、生成されるノートのシーケンスが繰り返されてしまいます。
生成されるノートのランダム性を制御するには、temperature パラメータを使用できます。temperature の詳細については、RNN によるテキスト生成をご覧ください。
def predict_next_note(
notes: np.ndarray,
keras_model: tf.keras.Model,
temperature: float = 1.0) -> tuple[int, float, float]:
"""Generates a note as a tuple of (pitch, step, duration), using a trained sequence model."""
assert temperature > 0
# Add batch dimension
inputs = tf.expand_dims(notes, 0)
predictions = model.predict(inputs)
pitch_logits = predictions['pitch']
step = predictions['step']
duration = predictions['duration']
pitch_logits /= temperature
pitch = tf.random.categorical(pitch_logits, num_samples=1)
pitch = tf.squeeze(pitch, axis=-1)
duration = tf.squeeze(duration, axis=-1)
step = tf.squeeze(step, axis=-1)
# `step` and `duration` values should be non-negative
step = tf.maximum(0, step)
duration = tf.maximum(0, duration)
return int(pitch), float(step), float(duration)
では、ノートを生成してみましょう。next_notes の temperature と開始シーケンスを変更しながら、どのような結果になるか確認します。
temperature = 2.0
num_predictions = 120
sample_notes = np.stack([raw_notes[key] for key in key_order], axis=1)
# The initial sequence of notes; pitch is normalized similar to training
# sequences
input_notes = (
sample_notes[:seq_length] / np.array([vocab_size, 1, 1]))
generated_notes = []
prev_start = 0
for _ in range(num_predictions):
pitch, step, duration = predict_next_note(input_notes, model, temperature)
start = prev_start + step
end = start + duration
input_note = (pitch, step, duration)
generated_notes.append((*input_note, start, end))
input_notes = np.delete(input_notes, 0, axis=0)
input_notes = np.append(input_notes, np.expand_dims(input_note, 0), axis=0)
prev_start = start
generated_notes = pd.DataFrame(
generated_notes, columns=(*key_order, 'start', 'end'))
1/1 [==============================] - 0s 391ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 46ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 46ms/step 1/1 [==============================] - 0s 46ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 45ms/step 1/1 [==============================] - 0s 46ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 44ms/step 1/1 [==============================] - 0s 43ms/step
generated_notes.head(10)
out_file = 'output.mid'
out_pm = notes_to_midi(
generated_notes, out_file=out_file, instrument_name=instrument_name)
display_audio(out_pm)
fluidsynth: warning: SDL2 not initialized, SDL2 audio driver won't be usable fluidsynth: error: Unknown integer parameter 'synth.sample-rate'
以下の 2 行を追加して、音声ファイルをダウンロードすることもできます。
from google.colab import files
files.download(out_file)
生成されたノートを視覚化します。
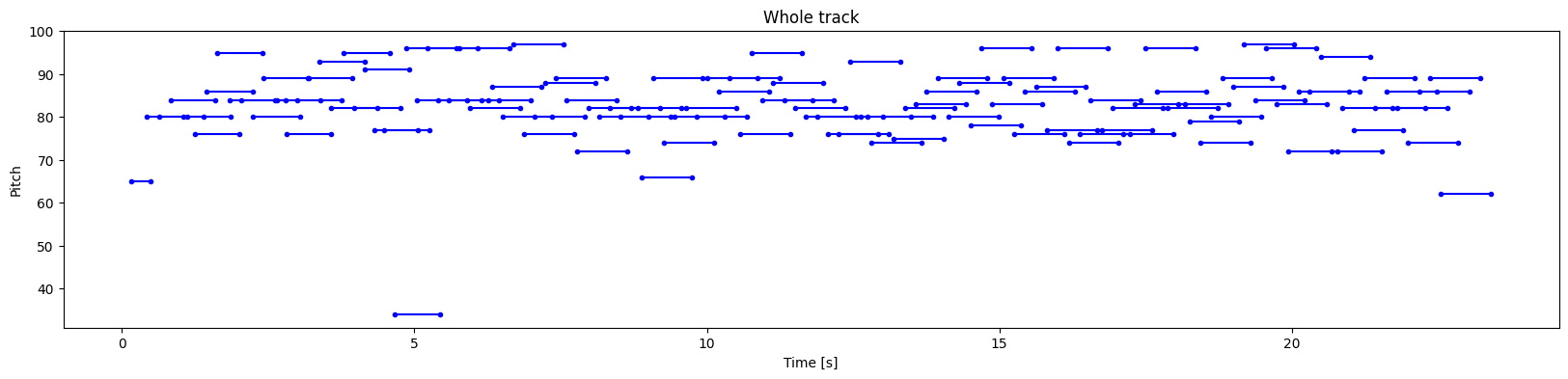
plot_piano_roll(generated_notes)
pitch、step、および duration の分布を確認します。
plot_distributions(generated_notes)
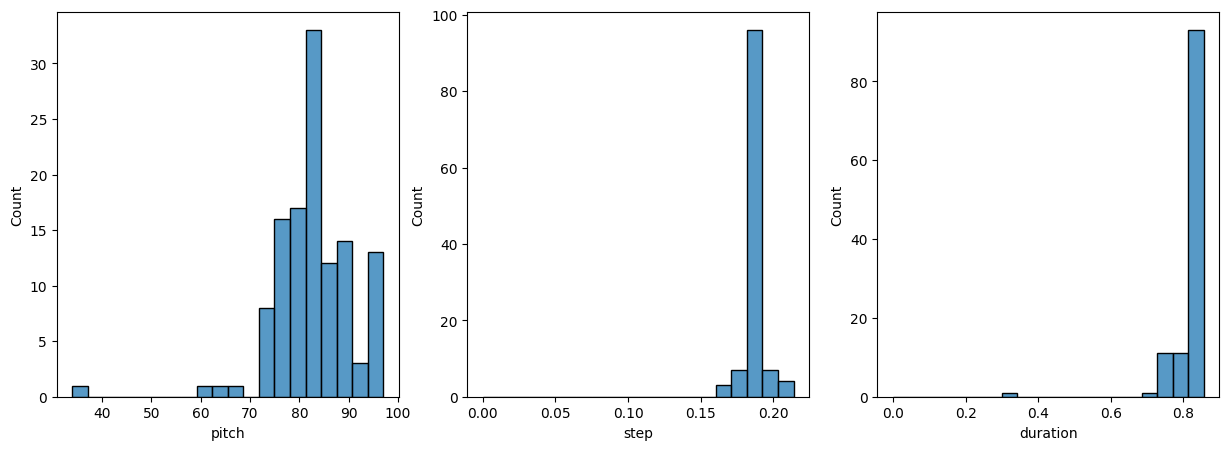
上記のプロットでは、ノート変数の分布の変化を確認できます。モデルの出力と入力の間にフィードバックループがあるため、モデルは、似たような出力のシーケンスを生成して損失を低下させる傾向にあります。これは特に、MSE 損失を使用する step と duration に関連しています。pitch については、predict_next_note の temperature を増加させて、ランダム性を高めることができます。
次のステップ
このチュートリアルでは、RNN を使用して、MIDI ファイルのデータセットからノートのシーケンスを生成する仕組みを説明しました。さらに詳しい内容については、関連性の高い RNN によるテキスト生成チュートリアルをご覧ください。追加のダイアグラムと説明が記載されています。
音楽生成では、RNN のほかに、GAN を使用することも可能です。GAN ベースのアプローチでは、オーディオを生成する代わりに、シーケンス全体を並行して生成することができます。Magenta チームは、GANSynth を使用してこのアプローチで圧巻の取り組みを達成しています。Magenta プロジェクトのウェブサイトには、素晴らしい音楽とアートのプロジェクトとオープンソースコードが多数掲載されています。