
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra como construir e treinar uma rede adversarial generativa condicional (cGAN) chamada pix2pix que aprende um mapeamento de imagens de entrada para imagens de saída, conforme descrito em Tradução de imagem para imagem com redes adversariais condicionais por Isola et al. (2017). O pix2pix não é específico do aplicativo - ele pode ser aplicado a uma ampla variedade de tarefas, incluindo sintetizar fotos de mapas de etiquetas, gerar fotos coloridas a partir de imagens em preto e branco, transformar fotos do Google Maps em imagens aéreas e até mesmo transformar esboços em fotos.
Neste exemplo, sua rede irá gerar imagens de fachadas de edifícios usando o CMP Facade Database fornecido pelo Center for Machine Perception da Czech Technical University em Praga . Para mantê-lo curto, você usará uma cópia pré -processada desse conjunto de dados criado pelos autores do pix2pix.
No cGAN pix2pix, você condiciona as imagens de entrada e gera as imagens de saída correspondentes. cGANs foram propostos pela primeira vez em Redes Adversariais Generativas Condicionais (Mirza e Osindero, 2014)
A arquitetura da sua rede conterá:
- Um gerador com uma arquitetura baseada em U-Net .
- Um discriminador representado por um classificador convolucional do PatchGAN (proposto no artigo pix2pix ).
Observe que cada época pode levar cerca de 15 segundos em uma única GPU V100.
Abaixo estão alguns exemplos da saída gerada pelo pix2pix cGAN após o treinamento de 200 épocas no conjunto de dados de fachadas (80k etapas).


Importar TensorFlow e outras bibliotecas
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Carregar o conjunto de dados
Baixe os dados do banco de dados de fachada CMP (30 MB). Conjuntos de dados adicionais estão disponíveis no mesmo formato aqui . No Colab, você pode selecionar outros conjuntos de dados no menu suspenso. Observe que alguns dos outros conjuntos de dados são significativamente maiores ( edges2handbags é de 8 GB).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Cada imagem original tem o tamanho 256 x 512 contendo duas imagens de 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
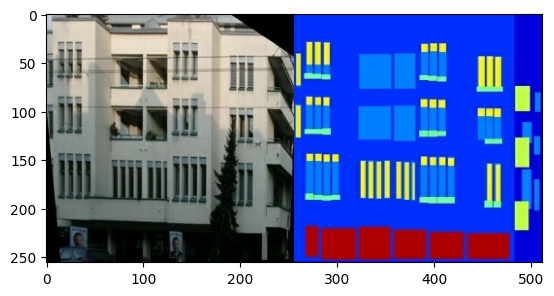
Você precisa separar as imagens reais da fachada do edifício das imagens do rótulo da arquitetura - todas com tamanho 256 x 256 .
Defina uma função que carrega arquivos de imagem e gera dois tensores de imagem:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Plote uma amostra das imagens de entrada (imagem do rótulo da arquitetura) e reais (foto da fachada do edifício):
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
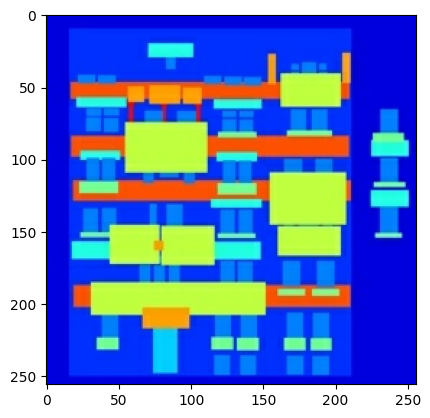
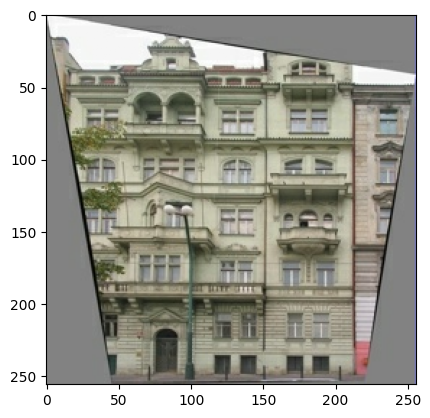
Conforme descrito no artigo pix2pix , você precisa aplicar jitter e espelhamento aleatórios para pré-processar o conjunto de treinamento.
Defina várias funções que:
- Redimensione cada imagem de
256 x 256para uma altura e largura maiores —286 x 286. - Recorte aleatoriamente para
256 x 256. - Inverta a imagem aleatoriamente na horizontal, ou seja, da esquerda para a direita (espelho aleatório).
- Normalize as imagens para o intervalo
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Você pode inspecionar algumas das saídas pré-processadas:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
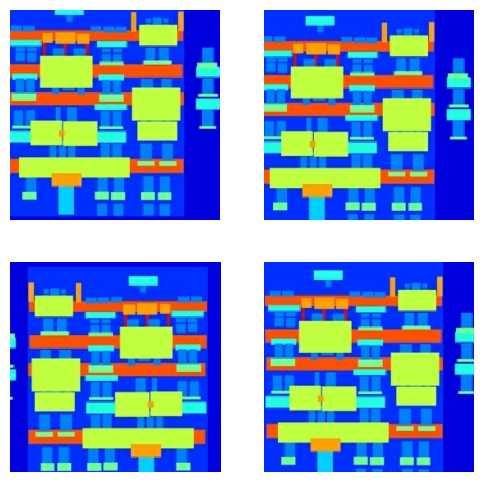
Tendo verificado que o carregamento e o pré-processamento funcionam, vamos definir algumas funções auxiliares que carregam e pré-processam os conjuntos de treinamento e teste:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Crie um pipeline de entrada com tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
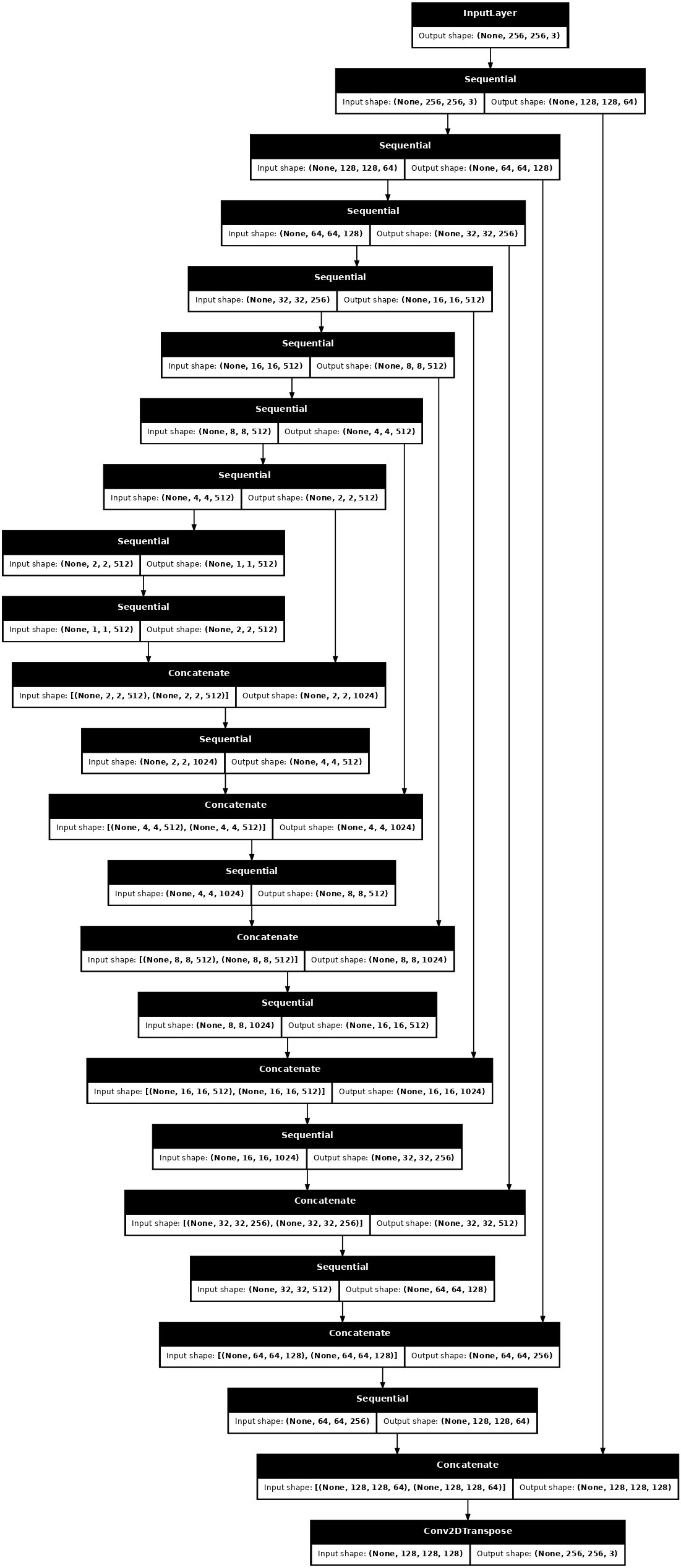
Construir o gerador
O gerador do seu pix2pix cGAN é um U-Net modificado . Uma U-Net consiste em um codificador (downsampler) e um decodificador (upsampler). (Você pode descobrir mais sobre isso no tutorial de segmentação de imagens e no site do projeto U-Net .)
- Cada bloco no codificador é: Convolution -> Batch normalization -> Leaky ReLU
- Cada bloco no decodificador é: Convolução transposta -> Normalização em lote -> Dropout (aplicado aos 3 primeiros blocos) -> ReLU
- Existem conexões de salto entre o codificador e o decodificador (como na U-Net).
Defina o downsampler (codificador):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Defina o upsampler (decodificador):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Defina o gerador com o downsampler e o upsampler:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Visualize a arquitetura do modelo do gerador:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
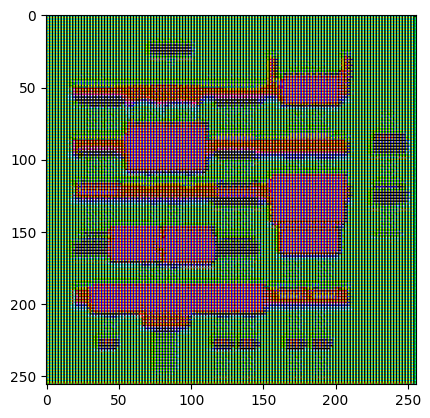
Teste o gerador:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Defina a perda do gerador
Os GANs aprendem uma perda que se adapta aos dados, enquanto os cGANs aprendem uma perda estruturada que penaliza uma possível estrutura que difere da saída da rede e da imagem de destino, conforme descrito no artigo pix2pix .
- A perda do gerador é uma perda de entropia cruzada sigmóide das imagens geradas e uma matriz de imagens.
- O artigo pix2pix também menciona a perda L1, que é um MAE (erro absoluto médio) entre a imagem gerada e a imagem alvo.
- Isso permite que a imagem gerada se torne estruturalmente semelhante à imagem de destino.
- A fórmula para calcular a perda total do gerador é
gan_loss + LAMBDA * l1_loss, ondeLAMBDA = 100. Este valor foi decidido pelos autores do artigo.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
O procedimento de treinamento para o gerador é o seguinte:

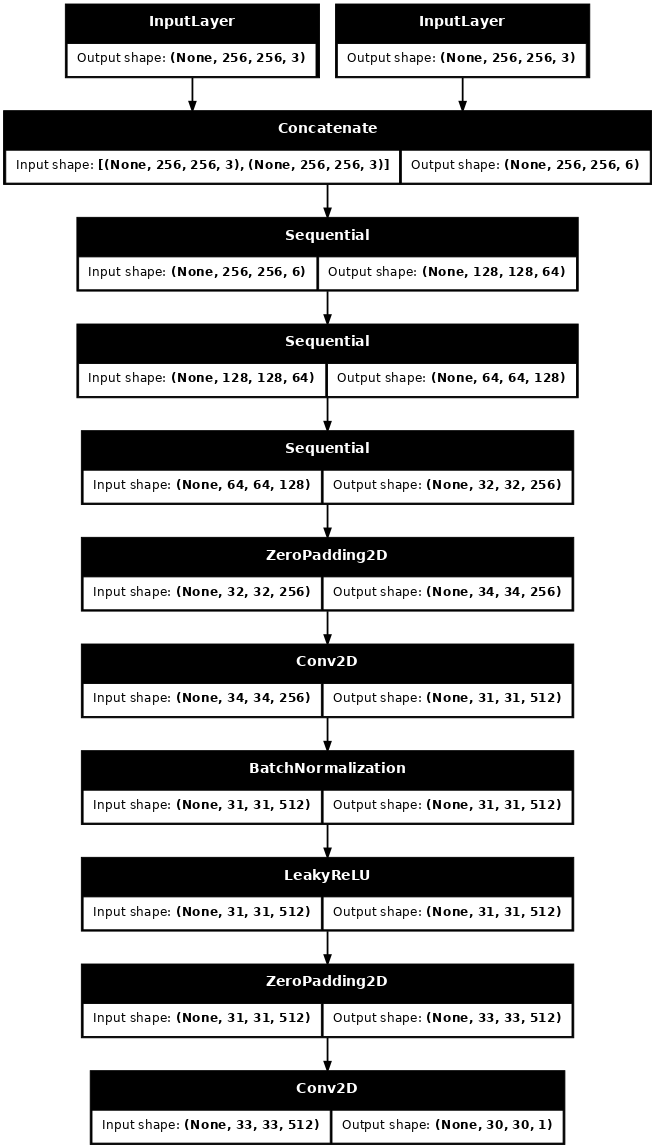
Construa o discriminador
O discriminador no pix2pix cGAN é um classificador convolucional do PatchGAN - ele tenta classificar se cada patch de imagem é real ou não real, conforme descrito no artigo pix2pix .
- Cada bloco no discriminador é: Convolution -> Batch normalization -> Leaky ReLU.
- A forma da saída após a última camada é
(batch_size, 30, 30, 1). - Cada patch de imagem de
30 x 30da saída classifica uma porção de70 x 70da imagem de entrada. - O discriminador recebe 2 entradas:
- A imagem de entrada e a imagem de destino, que deve classificar como real.
- A imagem de entrada e a imagem gerada (a saída do gerador), que deve ser classificada como falsa.
- Use
tf.concat([inp, tar], axis=-1)para concatenar essas 2 entradas juntas.
Vamos definir o discriminador:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Visualize a arquitetura do modelo discriminador:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
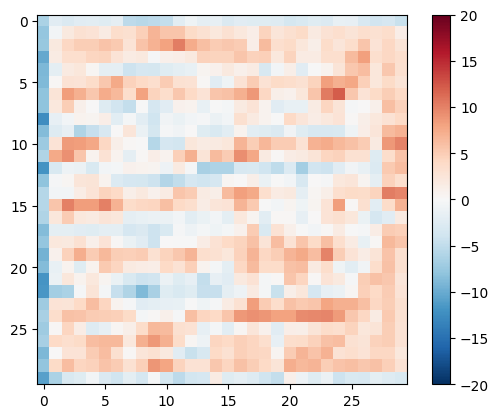
Teste o discriminador:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
Defina a perda do discriminador
- A função
discriminator_lossrecebe 2 entradas: imagens reais e imagens geradas . -
real_lossé uma perda de entropia cruzada sigmóide das imagens reais e uma matriz de imagens (já que essas são as imagens reais) . -
generated_lossé uma perda de entropia cruzada sigmóide das imagens geradas e uma matriz de zeros (já que essas são as imagens falsas) . - A
total_lossé a soma dereal_lossegenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
O procedimento de treinamento para o discriminador é mostrado abaixo.
Para saber mais sobre a arquitetura e os hiperparâmetros, você pode consultar o artigo pix2pix .

Defina os otimizadores e um protetor de ponto de verificação
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Gerar imagens
Escreva uma função para plotar algumas imagens durante o treinamento.
- Passe as imagens do conjunto de teste para o gerador.
- O gerador irá então traduzir a imagem de entrada na saída.
- O último passo é traçar as previsões e voila !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Teste a função:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Treinamento
- Para cada entrada de exemplo gera uma saída.
- O discriminador recebe a
input_imagee a imagem gerada como a primeira entrada. A segunda entrada é ainput_imagee atarget_image. - Em seguida, calcule a perda do gerador e do discriminador.
- Em seguida, calcule os gradientes de perda em relação às variáveis do gerador e do discriminador (entradas) e aplique-os ao otimizador.
- Por fim, registre as perdas no TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
O loop de treinamento real. Como este tutorial pode ser executado em mais de um conjunto de dados e os conjuntos de dados variam muito em tamanho, o loop de treinamento é configurado para funcionar em etapas em vez de épocas.
- Itera sobre o número de etapas.
- A cada 10 passos imprime um ponto (
.). - A cada 1k etapas: limpe a tela e execute
generate_imagespara mostrar o progresso. - A cada 5 mil passos: salve um checkpoint.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Esse loop de treinamento salva os logs que você pode visualizar no TensorBoard para monitorar o progresso do treinamento.
Se você trabalha em uma máquina local, deve iniciar um processo separado do TensorBoard. Ao trabalhar em um notebook, inicie o visualizador antes de iniciar o treinamento para monitorar com o TensorBoard.
Para iniciar o visualizador, cole o seguinte em uma célula de código:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Por fim, execute o loop de treinamento:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
Se você quiser compartilhar os resultados do TensorBoard publicamente , faça upload dos logs para o TensorBoard.dev copiando o seguinte em uma célula de código.
tensorboard dev upload --logdir {log_dir}
Você pode ver os resultados de uma execução anterior deste notebook em TensorBoard.dev .
O TensorBoard.dev é uma experiência gerenciada para hospedar, rastrear e compartilhar experimentos de ML com todos.
Também pode ser incluído inline usando um <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
A interpretação dos logs é mais sutil ao treinar um GAN (ou um cGAN como pix2pix) em comparação com uma classificação simples ou modelo de regressão. Coisas para procurar:
- Verifique se nem o gerador nem o modelo do discriminador "ganhou". Se o
gen_gan_lossou odisc_lossficar muito baixo, é um indicador de que este modelo está dominando o outro e você não está treinando com sucesso o modelo combinado. - O valor
log(2) = 0.69é um bom ponto de referência para essas perdas, pois indica uma perplexidade de 2 - o discriminador é, em média, igualmente incerto sobre as duas opções. - Para o
disc_loss, um valor abaixo de0.69significa que o discriminador está se saindo melhor que o aleatório no conjunto combinado de imagens reais e geradas. - Para o
gen_gan_loss, um valor abaixo de0.69significa que o gerador está se saindo melhor do que o aleatório em enganar o discriminador. - Conforme o treinamento progride, o
gen_l1_lossdeve diminuir.
Restaure o ponto de verificação mais recente e teste a rede
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Gere algumas imagens usando o conjunto de teste
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




