
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
في مشكلة الانحدار ، الهدف هو توقع ناتج قيمة مستمرة ، مثل السعر أو الاحتمال. قارن هذا بمشكلة التصنيف ، حيث يكون الهدف هو تحديد فئة من قائمة الفئات (على سبيل المثال ، عندما تحتوي الصورة على تفاحة أو برتقالة ، مع التعرف على الفاكهة الموجودة في الصورة).
يستخدم هذا البرنامج التعليمي مجموعة بيانات Auto MPG الكلاسيكية ويوضح كيفية بناء نماذج للتنبؤ بكفاءة استهلاك الوقود في أواخر السبعينيات وأوائل الثمانينيات من القرن الماضي. للقيام بذلك ، ستقدم للنماذج وصفًا للعديد من السيارات من تلك الفترة الزمنية. يتضمن هذا الوصف سمات مثل الأسطوانات والإزاحة والقدرة الحصانية والوزن.
يستخدم هذا المثال واجهة برمجة تطبيقات Keras. (قم بزيارة البرامج التعليمية والأدلة الخاصة بـ Keras لمعرفة المزيد.)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
مجموعة بيانات Auto MPG
تتوفر مجموعة البيانات من مستودع التعلم الآلي لـ UCI .
احصل على البيانات
قم أولاً بتنزيل مجموعة البيانات واستيرادها باستخدام الباندا:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
نظف البيانات
تحتوي مجموعة البيانات على بعض القيم غير المعروفة:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
قم بإسقاط هذه الصفوف للحفاظ على بساطة هذا البرنامج التعليمي الأولي:
dataset = dataset.dropna()
عمود "Origin" فئوي وليس رقمي. لذا فإن الخطوة التالية هي تشفير القيم الموجودة في العمود باستخدام pd.get_dummies .
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
قسّم البيانات إلى مجموعات تدريب واختبار
الآن ، قسّم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار. ستستخدم مجموعة الاختبار في التقييم النهائي لنماذجك.
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
افحص البيانات
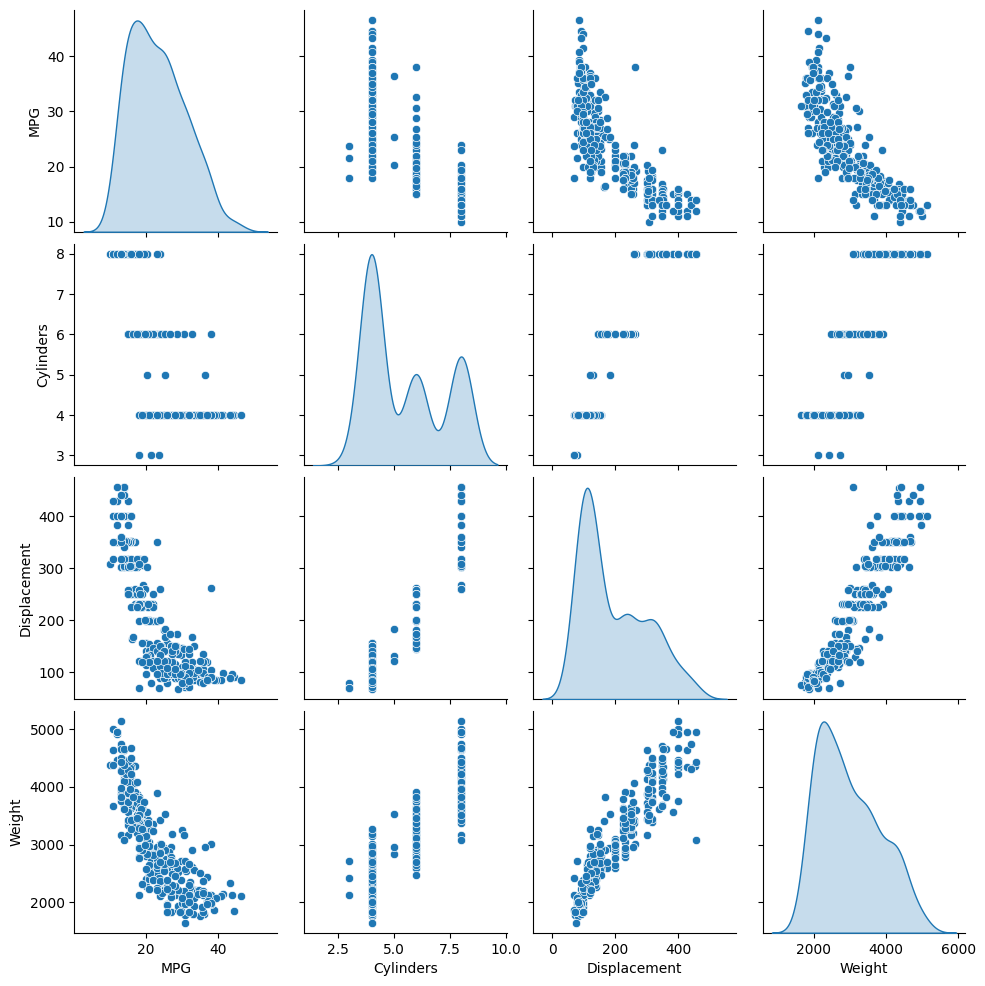
راجع التوزيع المشترك لبضعة أزواج من الأعمدة من مجموعة التدريب.
يشير الصف العلوي إلى أن كفاءة الوقود (MPG) هي دالة لجميع المعلمات الأخرى. تشير الصفوف الأخرى إلى أنها وظائف لبعضها البعض.
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>
دعنا نتحقق أيضًا من الإحصائيات الإجمالية. لاحظ كيف تغطي كل ميزة نطاقًا مختلفًا تمامًا:
train_dataset.describe().transpose()
تقسيم الميزات من التسميات
افصل القيمة الهدف — "التسمية" —من الميزات. هذه التسمية هي القيمة التي ستقوم بتدريب النموذج على التنبؤ بها.
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
تطبيع
من السهل معرفة مدى اختلاف نطاقات كل ميزة في جدول الإحصائيات:
train_dataset.describe().transpose()[['mean', 'std']]
من الممارسات الجيدة تسوية الميزات التي تستخدم مقاييس ونطاقات مختلفة.
أحد أسباب أهمية ذلك هو أن الميزات تتضاعف في أوزان النموذج. لذلك ، يتأثر حجم المخرجات ومقياس التدرجات بمقياس المدخلات.
على الرغم من أن النموذج قد يتقارب دون تطبيع الميزات ، فإن التطبيع يجعل التدريب أكثر استقرارًا.
طبقة التطبيع
يعد tf.keras.layers.Normalization طريقة نظيفة وبسيطة لإضافة ميزة تطبيع إلى نموذجك.
الخطوة الأولى هي إنشاء الطبقة:
normalizer = tf.keras.layers.Normalization(axis=-1)
بعد ذلك ، قم بملاءمة حالة طبقة المعالجة المسبقة للبيانات عن طريق استدعاء Normalization.adapt :
normalizer.adapt(np.array(train_features))
احسب المتوسط والتباين ، واحفظهما في الطبقة:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
عندما يتم استدعاء الطبقة ، تقوم بإرجاع بيانات الإدخال ، مع تسوية كل ميزة بشكل مستقل:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
الانحدارالخطي
قبل بناء نموذج شبكة عصبية عميقة ، ابدأ بالانحدار الخطي باستخدام متغير واحد أو عدة متغيرات.
الانحدار الخطي بمتغير واحد
ابدأ بانحدار خطي متغير واحد للتنبؤ بـ 'MPG' من 'Horsepower' .
يبدأ تدريب النموذج باستخدام tf.keras عادةً بتحديد بنية النموذج. استخدم نموذج tf.keras.Sequential ، والذي يمثل سلسلة من الخطوات .
هناك خطوتان في نموذج الانحدار الخطي المتغير الفردي الخاص بك:
- تطبيع ميزات إدخال
'Horsepower'القدرة الحصانية" باستخدامtf.keras.layers.Normalizationpreprocessing layer. - قم بتطبيق تحويل خطي (\(y = mx+b\)) لإنتاج خرج واحد باستخدام طبقة خطية (
tf.keras.layers.Dense).
يمكن تعيين عدد المدخلات بواسطة وسيطة input_shape ، أو تلقائيًا عند تشغيل النموذج لأول مرة.
أولاً ، قم بإنشاء مصفوفة NumPy مصنوعة من ميزات 'Horsepower' . ثم قم بإنشاء مثيل لـ tf.keras.layers.Normalization وتناسب حالته مع بيانات horsepower :
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
بناء نموذج Keras المتسلسل:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
سيتنبأ هذا النموذج بـ 'MPG' من 'Horsepower' .
قم بتشغيل النموذج غير المدرب على أول 10 قيم "أحصنة". لن يكون الإخراج جيدًا ، لكن لاحظ أنه بالشكل المتوقع (10, 1) :
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
بمجرد بناء النموذج ، قم بتكوين إجراء التدريب باستخدام طريقة Model.compile . أهم الحجج التي يجب تجميعها هي loss والمحسِّن ، حيث إنها تحدد ما سيتم optimizer ( mean_absolute_error ) وكيف (باستخدام tf.keras.optimizers.Adam ).
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
استخدم Keras Model.fit لتنفيذ التدريب لـ 100 عصر:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
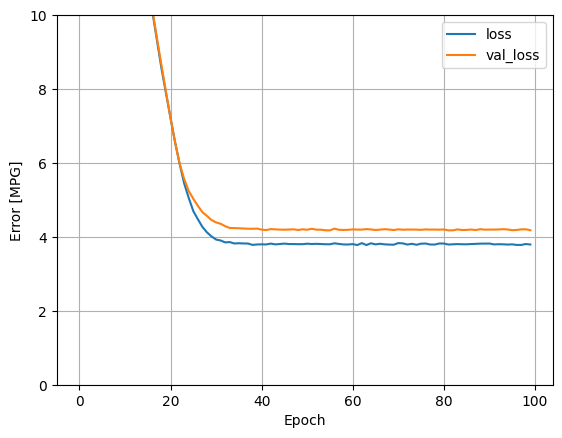
تصور تقدم تدريب النموذج باستخدام الإحصائيات المخزنة في كائن history :
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)
اجمع النتائج في مجموعة الاختبار لوقت لاحق:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
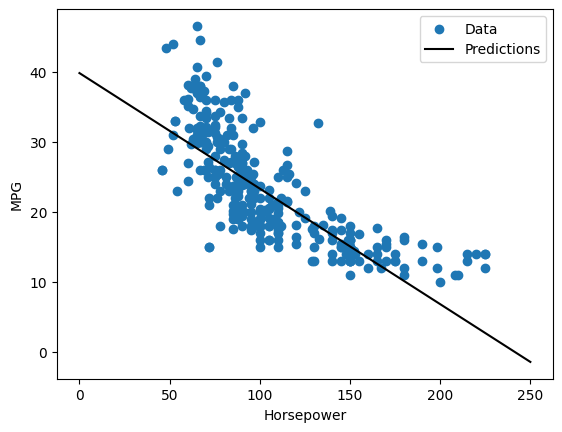
نظرًا لأن هذا هو انحدار متغير واحد ، فمن السهل عرض تنبؤات النموذج كدالة للإدخال:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)
الانحدار الخطي مع مدخلات متعددة
يمكنك استخدام إعداد متطابق تقريبًا لعمل تنبؤات بناءً على مدخلات متعددة. لا يزال هذا النموذج يقوم بعمل نفس \(y = mx+b\) فيما عدا أن \(m\) عبارة عن مصفوفة و \(b\) متجه.
قم بإنشاء نموذج Keras المتسلسل المكون من خطوتين مرة أخرى مع كون الطبقة الأولى بمثابة تسوية ( normalizer tf.keras.layers.Normalization(axis=-1) ) قمت بتعريفه مسبقًا وتكييفه مع مجموعة البيانات بأكملها:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
عند استدعاء Model.predict على مجموعة من المدخلات ، فإنه ينتج units=1 مخرجات لكل مثال:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
عند استدعاء النموذج ، سيتم بناء مصفوفات الوزن الخاصة به - تحقق من أن أوزان kernel ( \(m\) في \(y=mx+b\)) لها شكل (9, 1) :
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
قم بتكوين النموذج باستخدام Keras Model.compile وتدريب باستخدام Model.fit لـ 100 عصر:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
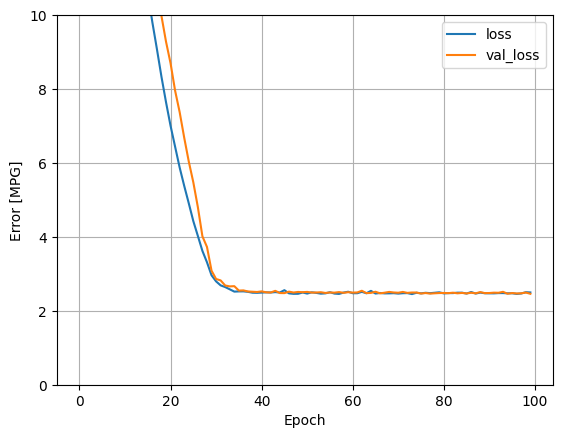
يؤدي استخدام جميع المدخلات في نموذج الانحدار هذا إلى تحقيق خطأ تدريب وتحقق أقل بكثير من نموذج horsepower_model ، الذي كان له مدخل واحد:
plot_loss(history)
اجمع النتائج في مجموعة الاختبار لوقت لاحق:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
الانحدار مع الشبكة العصبية العميقة (DNN)
في القسم السابق ، قمت بتنفيذ نموذجين خطيين لمدخلات فردية ومتعددة.
هنا ، ستقوم بتنفيذ نماذج DNN ذات المدخلات الفردية والمتعددة.
الشفرة هي نفسها بشكل أساسي باستثناء أن النموذج تم توسيعه ليشمل بعض الطبقات غير الخطية "المخفية". يعني الاسم "مخفي" هنا عدم الاتصال مباشرة بالمدخلات أو المخرجات.
ستحتوي هذه النماذج على طبقات قليلة أكثر من النموذج الخطي:
- طبقة
normalizer، كما كان من قبل (معhorsepower_normalizerلنموذج الإدخال الفردي والمعيار لنموذج متعدد المدخلات). - طبقتان مخفيتان غير
Denseكثيفتان مع وظيفة تنشيط ReLU (relu) غير الخطية. - طبقة أحادية الإخراج خطية
Dense.
سيستخدم كلا النموذجين نفس إجراءات التدريب بحيث يتم تضمين طريقة compile في دالة build_and_compile_model أدناه.
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
الانحدار باستخدام DNN ومدخل واحد
قم بإنشاء نموذج DNN باستخدام 'Horsepower' فقط كمدخلات و horsepower_normalizer (تم تعريفه سابقًا) كطبقة التسوية:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
يحتوي هذا النموذج على عدد قليل من المعلمات القابلة للتدريب أكثر من النماذج الخطية:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
تدريب النموذج باستخدام Keras Model.fit :
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
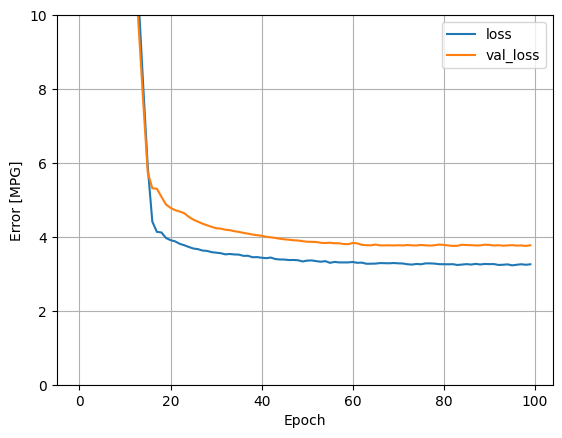
هذا النموذج يعمل بشكل أفضل قليلاً من horsepower_model الخطي أحادي الإدخال:
plot_loss(history)
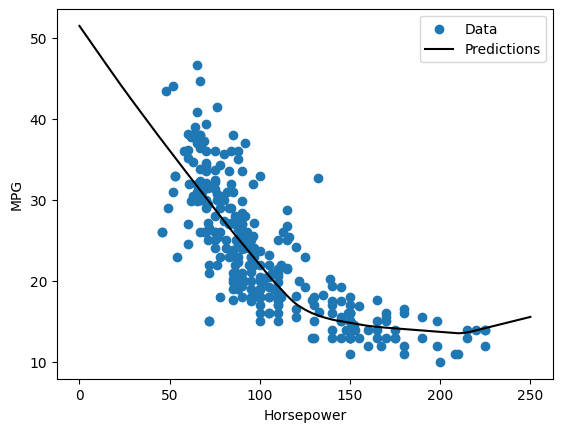
إذا قمت برسم التنبؤات كدالة لـ 'Horsepower' ، فيجب أن تلاحظ كيف يستفيد هذا النموذج من اللاخطية التي توفرها الطبقات المخفية:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)
اجمع النتائج في مجموعة الاختبار لوقت لاحق:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
الانحدار باستخدام DNN ومدخلات متعددة
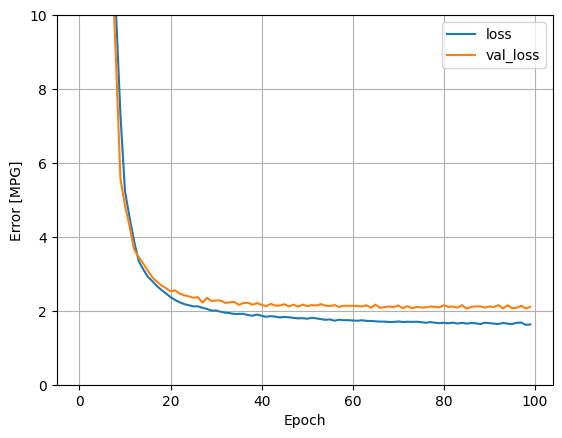
كرر العملية السابقة باستخدام جميع المدخلات. يتحسن أداء النموذج قليلاً في مجموعة بيانات التحقق.
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)
اجمع النتائج في مجموعة الاختبار:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
أداء
نظرًا لأنه تم تدريب جميع الطرز ، يمكنك مراجعة أداء مجموعة الاختبار الخاصة بهم:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
تتطابق هذه النتائج مع خطأ التحقق من الصحة الذي لوحظ أثناء التدريب.
قم بعمل تنبؤات
يمكنك الآن عمل تنبؤات باستخدام dnn_model في مجموعة الاختبار باستخدام Model.predict . توقع ومراجعة الخسارة:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)

يبدو أن النموذج يتنبأ بشكل معقول.
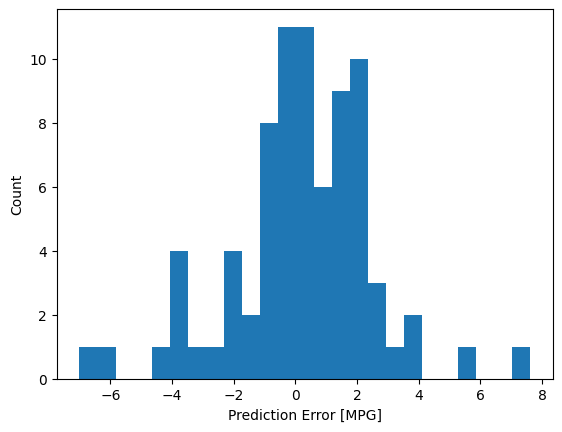
الآن ، تحقق من توزيع الخطأ:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
إذا كنت راضيًا عن النموذج ، فاحفظه لاستخدامه لاحقًا مع Model.save :
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
إذا قمت بإعادة تحميل النموذج ، فإنه يعطي إخراجًا متطابقًا:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
استنتاج
قدم هذا الكمبيوتر الدفتري بعض التقنيات للتعامل مع مشكلة الانحدار. إليك بعض النصائح الإضافية التي قد تساعدك:
- متوسط الخطأ التربيعي (MSE) (
tf.losses.MeanSquaredError) ومتوسط الخطأ المطلق (MAE) (tf.losses.MeanAbsoluteError) من وظائف الخسارة الشائعة المستخدمة لمشاكل الانحدار. MAE أقل حساسية للقيم المتطرفة. تستخدم وظائف الخسارة المختلفة لمشاكل التصنيف. - وبالمثل ، تختلف مقاييس التقييم المستخدمة للانحدار عن التصنيف.
- عندما تحتوي ميزات بيانات الإدخال الرقمية على قيم ذات نطاقات مختلفة ، يجب قياس كل ميزة بشكل مستقل إلى نفس النطاق.
- يعد التجهيز الزائد مشكلة شائعة لنماذج DNN ، على الرغم من أنها لم تكن مشكلة في هذا البرنامج التعليمي. قم بزيارة البرنامج التعليمي Overfit and underfit لمزيد من المساعدة في هذا الأمر.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.